
Abstract
High-efficiency video coding (HEVC), a video compression method is considered as the most capable descendant of the extensively deployed advanced VC (AVC). Compared with AVC, HEVC provides about twice the data compression ratio at the similar video quality level or considerably enhanced video quality at an equal bit rate. This paper proposes a novel enhanced holoentropy model for proficient systems for distributed VC (DVC). HEVC standard is considered as an archetypal system. The main contribution of this paper is the accomplishment of the encoding process in the HEVC system by enhanced holoentropy, which is linked with the proposed weighting tansig function. It necessitates considerable development when handling video sequences with high resolution. The pixel deviations under altering frames are grouped based on interest, and the outliers are eliminated with the aid of an enhanced entropy standard known as enhanced holoentropy. Here, the weight of tansig function is optimally tuned by whale optimization algorithm. To next of implementation, the suggested encoding scheme is compared with the conventional schemes concerning the number of compressed bits and computational time. By carrying out the encoding process, it reduces the video size with perceptually improved video quality or PSNR.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
HEVC is the novel VC standard developed in most recent times, and the improvement of this novel scheme was enthused by the requirement of video sequences with high resolution ahead of HD and for developments at the framework level [1,2,3,4,5]. It comprises of numerous coding equipments like CU, PU, and CTB partitioning device [6,7,8]. The process of HEVC is initiated by partitioning the image into a variety of blocks by quad tree mechanism followed by prediction and coding [9,10,11]. The intra-coding scheme in HEVC offers quality coding of videos. Accordingly, the HEVC performs better than the traditional VC standards [12, 13].
HEVC offers enhanced compression ratio and assistance for discriminated and multi-view encoding and premium 4 K content for online and broadcast retailers to offer additional content channels on conventional delivery channels [14–16]. For reducing the visual impacts and performance overheads, a solution for watermarking and encryption compliant with HEVC criterions is premeditated [17]. The evaluation of video quality could be categorized into objective and subjective quality measurements. The subjective evaluation is real and influential. Nevertheless, subjective quality estimation necessitates an enormous attempt to create an environment to estimate the quality of a video.
HEVC is currently being prepared as the newest video coding standard of the ITU-T Video Coding Experts Group and the ISO/IEC Moving Picture Experts Group [18–20]. The main goal of the HEVC standardization effort is to enable significantly improved compression performance relative to existing standards—in the range of 50% bit rate reduction for equal perceptual video quality [10]. The HEVC standard is the most recent joint video project of the ITU-T VCEG and the ISO/IEC MPEG standardization organizations, working together in a partnership known as the JCT [21–23]. There is no single coding element in the HEVC design that provides the majority of its significant improvement in compression efficiency in relation to prior video coding standards [24–26].
The main contribution of the presented model is listed below:
-
Introduces encoding process in HEVC system by enhanced holoentropy, which is linked with the proposed weighting tansig function.
-
The pixel deviations under altering frames are grouped on the basis of interest, and the outliers are eliminated with the aid of an enhanced entropy standard known as enhanced holoentropy.
-
The weight of tansig function is optimally tuned by whale optimization algorithm (WOA) for optimization purpose.
The paper is organized as follows. Section 2 portrays the related works reviewed under this topic. Section 3 demonstrates the modeling of HEVC: standard architecture with description and Sect. 4 portrays the enhanced holoentropy-based encoding for HEVC by WOA. Moreover, Sect. 5 explains the results and Sect. 6 concludes the paper.
2 Literature survey
2.1 Related works
Kalyan et al. [27] have established an approach depending on the detection of homogeneous and motionless texture-dependent areas in a specified format. Entropy is measured as an element for the examination of CU texture. An entropy differentiation among CU’s was designed for recognition of stationary areas in a video format.
Tanima and Hari [28] suggested a robust structure with a BE procedure for HEVC standards. A “readable watermark” was implanted imperceptibly in expected blocks of the video sequence. The experimental outcomes reveal that the anticipated work limits the augment in VBR and deprivation of perceptual quality.
Zhang et al. [29] implemented a fast 3D-HEVC encoder approach dependent on the depth map correlation and texture video to lessen computational complications. As the depth map and video texture correspond to a similar prospect at a similar time interval, it was not proficient to exploit the entire prediction modes in the adopted scheme.
Lin et al. [30] suggested a compressed video representation to forecast the SSIM metrics for HEVC and AVC videos. The representation adopted was SVR design. Moreover, the encoding decisions were only deployed while estimate the motions to carry out the prediction, and it does not require the data from the pixel domain
Guo et al. [31] established a method that measures not only the video content but also measures the position and significance of the corrupted portion and implements a hierarchical significance-dependent video quality evaluation. Accordingly, simulations were held to enumerate the hierarchical significance of corrupted content.
Shanshe Wang et al. [32] introduced an enhanced technique that intends to minimize the performance complication of 3D-HEVC. The fundamental inspiration of the suggested mechanism was to exploit the depth map variation feature.
Xiem et al. [33] suggested a new scalable VC solution by hybridizing the DVC techniques using a distributed coding layer and HEVC-compliant base layers. The suggested model tempts to offer reduced encoding intricacy and error while attaining an increased rate of compression.
Sunil Kumar et al. [34] suggested a scheme to enhance the benchmark entropy by establishing the optimized weighting constraints. According to the adopted scheme, an improved compression rate could be obtained over the benchmark entropy encoding. In addition, the optimization was carried out using the FF algorithm in recent times. Moreover, the trials were done for PSNR evaluation for altering the rate of data transmission.
In 2019, Choi et al. [35] have proposed an efficient perspective affine motion estimation/compensation for VVC standard. The PAMC method which can cope with more complex motions such as shear and shape distortion utilized perspective and affine motion model. The PAMC method uses four CPMVs to give degree of freedom to all four corner vertices. Besides, the proposed algorithm is integrated into the AMC structure so that the existing affine mode and the proposed perspective mode can be executed adaptively. The experimental results show that the BD rate reduction of the proposed technique can be achieved up to 0.45% and 0.30% on Y component for RA and LDP configurations, respectively.
In 2019, Yang et al. [36] have introduced a DSCNN approach to achieve quality enhancement for HEVC, which does not require any modification of the encoder. In particular, our DSCNN approach learns a model of CNN to reduce distortion of both I and B/P frames in HEVC. Furthermore, a scalable structure is included in our DSCNN, such that the computational complexity of our DSCNN approach is adjustable to the changing computational resources. Finally, the experimental results show the effectiveness of our DSCNN approach in enhancing quality for both I and B/P frames of HEVC.
In 2020, Lee et al. [37] have determined an efficient color artifact removal algorithm based on HEVC for high-dynamic range video sequences. A block-level QP offset-control-based efficient compression algorithm for the HDR sequence was proposed. The candidate CUs with the annoying area to the human eye based on the JND model were extracted. Subsequently, the chromatic distorted blocks are verified by the activity function as the chromatic artifact is observed at the nearby strong edge. Therefore, the proposed method provides pleasant viewing results by eliminating annoying color distortions and has better frame clarity, and compression efficiency in terms of video coding.
In 2018, Kalyan et al. [38] have established a fast HEVC scheme based on Markov Chain Monte Carlo model and Bayesian classifier. A novel way considering skip detection and CU termination as two-class decision-making problems in which Bayesian classifier is used for both of these approaches. Prior and class conditional probability values for a Bayesian classifier are not known at the time of encoding a video frame. Experimental results show that the proposed method provides significant time reduction for encoding with reasonably low loss in video quality.
In 2018, Jin et al. [39] have determined a novel post-processing technique using MPRGAN, for artifacts reduction and coding efficiency improvement in intra-frame coding. Furthermore, our network generates multi-level residues in one feed-forward pass through the progressive reconstruction. This coarse-to-fine work fashion, which makes our network have high flexibility, can make trade-off between enhanced quality and computational complexity. Extensive evaluations on benchmark datasets verify the superiority of our proposed MPRGAN model over the latest state-of-the-art methods with fast deployment running speed.
In 2018, Young et al. [40] have suggested a scheme to improve the visual quality of the video coding standard. We apply a CNN model to HEVC encoding system and suggest a combined coding scheme using a CNN model. The deterioration of the quality caused by compression can be improved through CNN, which does not require much computational complexity. Through experiment, we verify that the proposed scheme achieves up to 0.24 dB of the quality improvement on HM 16.10 reference software.
2.2 Review
Table 1 shows the methods, features, and challenges of conventional techniques based on HEVC encoding. At first, AMP was implemented in [27] that necessitates a lower bit rate along with minimized time for encoding. However, possibilities of error could be found that remains as a drawback for this scheme. In addition, video watermarking was deployed in [28], which offers better effectiveness with minimized computational complexity. However, there was no implementation on compressed domain watermarking using different codes. Moreover, the Mode decision scheme was suggested in [29] that offers reduced complexity with fast texture VC, but there were chances for false edge occurrence that reduces the accuracy. Also, SVR was implemented in [30], which minimizes the complexity, and there was no necessitation for decoding the entire bitstream. However, there was no exploration of various characteristics of HEVC and AVC. In [31], NN was exploited that increases the accuracy with better prediction of video quality. However, it does not involve the temporal features. Moreover, the Mode decision scheme was employed in [32], which provides minimized complexity and rate distortion loss, but the computation of depth region is complex. In addition, DVC was suggested in [33], which offers minimized complications with increased scalability and RD performance. However, it requires the implementation of the correlation process. Finally, FF was exploited in [34] that offer minimized performance complications with increased reliability. However, the compression effectiveness has to be enhanced more. PAMC method was implemented in [35] that have low delay, BD rate reduction and improved effectiveness. However, the higher-order motion models should be investigated and applied for three-dimensional modeling of motion. In addition, DSCNN approach was deployed in [36], which offers better performance, low computational complexity and quality enhancement. However, there is need to achieve computation-scalable quality enhancement for decoded images or videos that adapt to the varying computational resources. Moreover, HDR technique was suggested in [37] that offer average gain, increased bit rate, better frame clarity and compression efficiency, but the existence of a strong luminance edge does not necessarily coincide with a strong chrominance edge. Also, MCMC model was implemented in [38] involving significant time reduction for encoding, low loss in video quality, more robust and adaptive in nature. However, HEVC has high degree of computational complex. In [39], MPRGAN was exploited that high flexibility, superior performance and adjustable to resource-aware applications. However, there is need to simplify the network while boosting its visual quality and extend the methodology to more related applications. Moreover, CNN model was employed in [40], which provides low computational complexity and higher PSNR, but needs to improve the overall compression performance by improving the quality of inter-frame coding. Thus the challenges in various techniques have to be solved to improve the HEVC performance.
3 Modeling of HEVC: standard architecture with description
3.1 CABAC standard
HEVC utilizes a single entropy coding technique that is customized by counting the characteristics, namely coefficient coding, adaptive coefficient scanning, and CM, which is identified as CABAC. For raising the effectiveness of CABAC coding, CM is carried out. The CM indicators are obtained using the partitioning depth of transform tree or coding. The syntax components of the indices consist of unit-flag; skip flag, spli-coding, cbf-cr, cbf-luma, split-transform-flag and cbf-cb. The information is reduced for increasing throughput using HEVC along with the bypass approach of CABAC. Horizontal, vertical and decent scans are types of scanning techniques, which are done in 4 × 4 sub-blocks in the entire size of TB.
The HEVC include the capability to convey the location of the final NTC, sign bits, a noteworthy map, and stages of the TC. The significance map is deployed for sub-blocks of 4 × 4, and a group flag pointing out an NTC group is conveyed to the entire clusters that contain a coefficient before the final coefficient position. The sign bit of the initial NTC is assumed from the uniformity of whole amplitudes while the “sign data hiding” along with two NTC in a 4 × 4 block and distinction between the scan directions of initial and final NTC is higher than three.
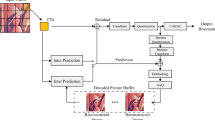
Figure 1 demonstrates the architecture diagram of HEVC. The HEVC [15, 16] scheme deploys inter- and intra-picture prediction models, which is dependent on the theory of the “video compression” principles. In the initial sequence of the video, the intra-picture prediction method is deployed to find out the spatial significance among the frame sections. The inter-picture prediction model portrays an MV and a reference frame depending on the association among the frames. The proposed MV is utilized to envisage the block samples of all the frames by mode decision data and MC. The coefficients of conversion obtained as a result are offered to entropy encoding, scaling, and quantization. The encoder includes a replicated decoder phase via which the reverse procedures of transformation and scaling are carried out to restructure the estimated left over the signal. The buffer accumulates the replica of the output of the decoder, and it is exploited to forecast the following frames. The combined VC context comprises numerous appealing characteristics, and constructive mechanisms like CU and CB, CTU and CTB, TU and TB, PU and PB, MC, MV signaling and so on.

Pictorial representation of HEVC encoder
The CTU is equal to the MB of the preceding coding principles. On the other hand, the CTU size is usually superior to the MB. In addition, the CTB includes luma and syntax elements and the related chroma CTBs. In general, the luma CTBs are huge in dimension and therefore it is divided into small blocks using quadtrees-like signaling and tree structure. The positions and size of chroma and luma CTBs of a CTU are generally described by the quad tree syntax. A CTB might contain either segregated multi-CUs or single CU. Every CU can be divided into TUs and PUs. The TU and PU encompass its origin at the level of CU. The PBsis utilized to envisage CB’s after the dividing process. The residual of luma CB is usually equal to luma TB, or it could be isolated into slighter luma TB’s.
The MV in HEVC integrates AMVP which is obtained from both PBs concerning spatial and temporal functions. However, partial sample locations with six-tap filtering are deployed for MV in “H.264/MPEG-4AVC”. In addition, numerous images are exploited in HEVC. HEVC considers thirty-three directional modes while evaluating intra-picture, in which 8 are acknowledged in “H.264/MPEG-4AVC.” The prediction directions prefer the intra-picture prediction encoding based on formerly decoded adjacent PBs.
Several alterations are performed in the CABAC escalating the compression performance in HEVC for better throughput and to reduce the context recall needs, and it is deployed for entropy coding. Similar to “H.264/MPEG-4AVC,” the deblocking filter functioned in the IPL remnants similar for HEVC. The operational outline is obstructed for filtering and decision-making procedure. Further than the deblocking filter, a “nonlinear amplitude mapping” is exploited in IPL. The major intention lies in reconstructing the amplitudes of signal with a look-up table that is described with novel constraints, which could be approximated using the histogram scrutiny close to the encoder side.
3.2 Enhancement model
CABAC is considered a throughput bottle neck in the VC model. On considering the count of bins that it practices for each second, the CABAC throughput could be evaluated. A rise in the number of bins will be almost equivalent to the rise in throughput. However, it is much complicated to deal with numerous bins analogous in CABAC. On concerning recursive time partition, the modified range is provided, and for accurate possibility approximation, the modified framework is provided. The assortment of context is made based on the kind of syntax and binIdx constituent. The range update and feedback loops-context updates were much effortlessly comprehended when compared with the context assortment loops. The calculation attempts are required if bin context is based on the various erstwhile bin values. Consequently, it’s an identified actuality that throughput blockage is owing to the bin based on context assortment.
The throughput crisis of CABAC has to be solved, which is a significant task. A variety of techniques are made for enhancing the throughput along with the least loss of coding. With the minimization of context coded bins, it was simpler to practice the coded bins in analogous, and as a result, the throughput could be enhanced. By means of “group bypass coded bins” practiced in similar rounds, the bins were rearranged to increase the probability of numerous bins developed in HEVC. Therefore, for this action, the tentative computation is essential. If bins are incorporated with altering context and its assortment logic, the quantity of tentative totaling increases and therefore to minimize it, the bins have to be rearranged. Hence, the throughput is augmented mechanically with reduced power convention. By minimizing the context assortment reliance, the entire amount of bins, parsing memory and reliance needs, throughput could be minimized with reduced cost and power. The entire amount of bins is minimized by deducing the values of the bin, evading signaling out moded bins and varying binarization by deploying advanced level flags. “Parsing” is the reason for minimized throughput, and hence, it has to be decoupled from various executions. Reducing memory capability is essential for rising throughput.
Figure 2 demonstrates the proposed architecture by incorporating WOA and optimization process. The traditional block-dependent hybrid VC technique is deployed in HEVC before the standardization procedure. Numerous developments are done for structuring an HEVC method. In terms of color video signals, YCbCr color space will be deployed by HEVC that partition a color to three elements—(luma) Y indicates brightness and Cr and Cb symbolize the color variation from gray in the direction of red and blue correspondingly. The video images are split and sampled into CTU that comprises of luma CTBs and chroma CTBs. Moreover, CTU is exploited by HEVC for the decoding region. The CTBs are deployed as CBs and separated using quad tree syntax. The size of CB is reduced until the fitness is attained. By deploying residual quad tree, the CBs are separated into TB’s. For enlarging the coding effectiveness, the HEVC deploys a TB to shift across a lot of PBs of inter-picture assumed CUs. The image is divided into numerous segments that are deployed deliberately for resynchronization following a data loss. In addition, HEVC strips are employed for facilitating the parallel processing framework for decoding and encoding. Moreover, the intra-picture and inter-picture predictions are carried out.

Proposed architecture using WOA optimization algorithm
In intra-picture estimation, the decoded boundary samples of adjacent blocks are used as reference data for spatial prediction in regions where inter-picture prediction is not performed. Intra-picture prediction supports 33 directional modes (compared to eight such modes in H.264/MPEG-4 AVC), plus planar (surface fitting) and DC (flat) prediction modes. The selected intra-picture prediction modes are encoded by deriving most probable modes (e.g., prediction directions) based on those of previously decoded neighboring PBs. In inter-picture estimation, the PB partitioning is compared to intra-picture-predicted CBs; HEVC supports more PB partition shapes for inter-picture-predicted CBs. The samples of the PB for an intra-picture-predicted CB are obtained from those of a corresponding block region in the reference picture identified by a reference picture index, which is at a position displaced by the horizontal and vertical components of the motion vector. In motion compensation, the Quarter-sample precision is used for the MVs, and 7-tap or 8-tap filters are used for interpolation of fractional-sample positions (compared to six-tap filtering of half-sample positions followed by linear interpolation for quarter-sample positions in H.264/MPEG-4 AVC). As in H.264/MPEG-4 AVC, a scaling and offset operation may be applied to the prediction signal(s) in a manner known as weighted prediction. Furthermore, the encoder needs to perform motion estimation, which is one of the most computationally expensive operations in the encoder, and complexity is reduced by allowing a small number of candidates. When the reference index of the neighboring PU is not equal to that of the current PU, a scaled version of the motion vector is used. In HEVC, the processing order of the deblocking filter is defined as horizontal filtering for vertical edges for the entire picture was followed by vertical filtering for horizontal edges. This specific order enables either multiple horizontal filtering or vertical filtering processes to be applied in parallel threads or can still be implemented on a CTB-by-CTB basis with only a small processing latency. The deblocking filter is applied to all samples adjacent to a PU or TU boundary except the case when the boundary is also a picture boundary or when deblocking is disabled across slice or tile boundaries. It should be noted that both PU and TU boundaries should be considered since PU boundaries are not always aligned with TU boundaries in some cases of inter-picture-predicted CBs. SAO is a process that modifies the decoded samples by conditionally adding an offset value to each sample after the application of the deblocking filter, based on values in look-up tables transmitted by the encoder. SAO filtering is performed on a region basis, based on a filtering type selected per CTB by a syntax element. As in H.264/MPEG-4 AVC, a scaling and offset operation may be applied to the prediction signal(s) in a manner known as weighted prediction. At this point in the process, that weighted prediction is applied when selected by the encoder. Whereas H.264/MPEG-4 AVC supported both temporally implicit and explicit weighted prediction, in HEVC only explicit weighted prediction is applied, by scaling and offsetting the prediction with values sent explicitly by the encoder.
3.3 Probability estimation
Context modeling: The bin value in CABAC is processed depending on the related coding mode decisions, namely regular or bypass mode. The later one is predominantly preferred than the former one for CM.
Probability assignment and estimation: The probabilistic scheme of CABAC is based on the adaptive constraints of bin source that performs on a “bin-by-bin basis” in the harmonized and adaptive manner (backward) in decoding and encoding procedure. The whole procedure is denoted as probability estimation, which is given by Eq. (1),
where \( t \) time interval, \( a \) indicates scaling factor, \( b \) indicates bin, \( p_{\text{SL}} \) indicates of least probable sign, and \( p_{\text{ML}} \) indicates the probability of most probable sign.
4 Enhanced Holoentropy-based encoding for HEVC by whale optimization algorithm
4.1 Proposed holoentropy for CABAC
Entropy measurement for detecting outliers is not sufficient. The total correlation is also necessary to get better outlier candidates. Likewise, contribution of holoentropy along with entropy and total correlation helps in giving appropriate results for outlier detection. The holoentropy is defined as the sum of entropy and total correlation of random vector \( Y \). Here, \( HLx\left( Y \right) \) can be expressed using Eq. (2).
where \( Cx\left( Y \right) \) indicates the total correlation and \( Hx\left( Y \right) \) indicates the total entropy. However, this paper proposes a nonlinear relationship operator to determine the correlation, rather than statistical correlation function. Moreover, the nonlinear relationship operator is further intended to tune by advanced soft computing algorithm called as WOA.
The formulation of holoentropy is given by Eq. (3), where the weighted tansig function, \( w_{x} \left( i \right) \) is determined using Eq. (4) in which \( i = 1, \ldots N \).
where \( E_{i} \) denotes the ith entropy value.
The term peak signal-to-noise ratio (PSNR) is an expression for the ratio between the maximum possible value (power) of a signal and the power of distorting noise that affects the quality of its representation. For color images with three RGB values per pixel, the definition of PSNR is the same except the MSE is the sum over all squared value differences (now for each color, i.e., three times as many differences as in a monochrome image) divided by image size and by three. The PSNR block computes the peak signal-to-noise ratio, in decibels, between two images. This ratio is used as a quality measurement between the original and a compressed image. The higher the PSNR, the better the quality of the compressed or reconstructed image.
In Eq. (5),\( v = 1,2, \ldots N_{v} \) in which \( N_{v} \) denotes the number of trial video sequences.\( {\text{MSE}}_{v} \) indicates the mean squared error value between the reconstructed trial video sequences and the original video sequence, and\( {\text{MAX}}_{I} \) is the maximum possible pixel value of the image and hence the pixels are represented using 8 bits per sample, (i.e., 255).
Here in the proposed framework, \( w_{x} \left( i \right) \) is determined by factorizing the weighting function \( \alpha_{i} \) with it as shown by Eq. (6).
The weighting function, \( \alpha_{i} \) has to be optimally tuned, for which the WOA optimization is exploited. Unlike other optimization algorithms, WOA uses a strong exploitation and exploration phase and its searching concept encircles the optimal point and so the convergence can be fast in less iterations. Hence it is considered to be well-suited for HEVC process, where high-resolution videos are encoded.
4.2 Objective model and solution encoding
The weight parameter, denoted by \( \alpha_{i} \), is given as input for solution encoding, in which \( i \) indicates the number of weights from 1 to \( n \). The diagrammatic representation of solution encoding is shown in Fig. 3. Here, \( Y \) indicates the position vector in order to update the subsistence of an enhanced solution. Accordingly, the objective function of the proposed work is to maximize the PSNR as shown by Eq. (7).

Solution encoding
4.3 Whale optimization algorithm
The weighting function \( \alpha_{i} \) is given as input to the WOA model for fine-tuning. Whales are accountable for emotions, judgment, and social performances as made by humans [14]. The major motivating thing regarding the humpback whales is the marvelous hunting system. They could identify the location of prey and enclose them. Following the portrayal of the fine search agent, the erstwhile search agents will attempt to modernize their locations toward the optimal agent for search. This behavior is indicated by Eqs. (8) and (9), in which \( t \) points out the present iteration, coefficient vectors are signified by \( \vec{A} \) and \( \vec{C} \), and \( Y^{ * } \) denotes the position vector of the most outstanding solution obtained so far; \( | { } | \) indicates the absolute value,\( Y \) symbolizes the position vector, and ‘·’ represents an element-by-element multiplication.
It is significant to note that \( Y^{ * } \) has to be updated in the entire iterations in the subsistence of an enhanced solution. The vectors \( A \) and \( J \) are evaluated as in Eqs. (10) and (11) in which \( \vec{f} \) is linearly reduced from two to zero for the course of iterations and \( \vec{r} \) denotes a random vector in [0, 1].
Exploitation phase: Shrinking encircling mechanism: This action is attained by reducing the value of \( \vec{f} \) in Eq. (10). Observe that the distinction of \( \vec{A} \) is further minimized by \( \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\rightharpoonup}$}} {f} \), that is \( \vec{A} \) is an arbitrary value that lies among \( \left[ { - \vec{f},\vec{f}} \right] \) in which \( \vec{f} \) is minimized from two to zero for further iterations.
Spiral updating position: Initially, this technique valuates the distance found among the whale positioned at \( \left( {Y,Z} \right) \) and prey at \( \left( {Y^{ * } ,Z^{ * } } \right) \). A spiral formula is also produced between the location of whale and prey as revealed in Eq. (12) in which \( \vec{V}' = \left| {\vec{Y}^{ * } (t) - \vec{Y}(t)} \right| \) and it denotes the distance of ith whale to prey, the variable for determining the shape of the logarithmic spiral is indicated by \( g \), ‘.’refers to an element by element multiplication, and \( l \) is an alternate value that ranges between [− 1,1].
It can be further designed as specified in Eq. (13) where \( p_{a} \) is an alternate number ranging between [0, 1], \( b \) is a constant for defining the shape of the logarithmic spiral.
Exploration phase: Here, an alternately chosen exploration agent rather than the best search agent is identified so far. This operation and \( \left| {\vec{A}} \right| > 1 \) highlights the exploration and permits the WOA method to carry out a wide-ranging search. It is explained as in Eqs. (14) and (15), where \( \vec{Y}_{rand} \) is a random whale selected from the present population.

5 Results and discussions
5.1 Simulation procedure
The proposed compression model using WOA for enhanced holoentropy depending on HEVC was implemented in JAVA, and the results were attained by exploiting 2 data sets. The data set 1 consist of the video in YUV file format such as Football, mobile, garden, coastguard, foreman, tennis, with a relevant count of sequences 125, 140, 115, 112, 300 and 300, which were obtained from (http://www.cipr.rpi.edu/resource/sequences/sif.html: Access date: 16-10-2018). The video sequences garden, Football, tennis, mobile, foreman and coast guards include a resolution of 352 × 240, and foreman and coastguard include a resolution of 352 × 288. The data set 2 is obtained from http://download.tsi.telecom-paristech.fr/gpac/dataset/dash/uhd/. Here, the video sequences such as UHD HEVC-720p-30 Hz, UHD HEVC-720p-60 Hz, UHD HEVC-1080p-30 Hz, UHD HEVC-1080p-60 Hz, UHD HEVC-2160p-30 Hz and UHD HEVC-2160p-60 Hz is used. This paper used the version 2 of HM software, which was established by the JCT-3 V to work on multi-view and 3D video coding extensions of HEVC and other video coding standards. It provides support for coding multiple views with inter-layer prediction. It is designed as a high-level syntax only extension to allow reuse of existing decoder components. The software can be accessible via https://hevc.hhi.fraunhofer.de/mvhevc. The performance of proposed and conventional compression models was validated by examining the PSNR of decoded video formats for a diverse count of encoded bits. The outcomes attained for the adopted scheme were distinguished with the traditional schemes like ABC [11], FF [41], GA [42], PSO [43], CSO [44], GSO [45], DE [46], and GWO [47].
5.2 Performance analysis
The performance of adopted enhanced holoentropy using WOA and other conventional algorithms with respect to PSNR value and the bit rate in compressed form for the entire collected video streams for data set 1 and 2 is specified in Figs. 4, 5, 6 and 7. Figure 4 shows the encoding performance in terms of bit rate in compressed form in compressed for the data set 1. From Fig. 4a, for block size 1 the bit rate in compressed form for presented WOA is 1.89% ((87.84–89.54)/89.54) better than ABC, 1.31% better than FF, 0.69% better than GA and 0.35% better than PSO algorithms. From Fig. 4b, for block size 2, the bit rate in compressed form for WOA is 3.57% better than ABC, 3.24% better than FF, 1.87% better than GA and 0.7% better than PSO algorithms. Also, from Fig. 4d, on considering block size 1, the presented WOA scheme is 0.68% better than ABC, 0.23% better than FF, 0.98% better than GA and 0.81% better than PSO algorithms.

Encoding performance of the proposed and conventional models with respect to bit rate in compressed form for data set 1. a Football, b mobile, c garden, d coastguard, e foreman and f tennis

Encoding performance of the proposed and conventional models with respect to PSNR for data set 1. a Football, b mobile, c garden, d coastguard, e foreman and f tennis

Encoding performance of the proposed and conventional models with respect to Bit rate in compressed form for data set 2 a UHD HEVC-720p-30 Hz, b UHD HEVC-720p-60 Hz, c UHD HEVC-1080p-30 Hz, d UHD HEVC-1080p-60 Hz, e UHD HEVC-2160p-30 Hz and f UHD HEVC-2160p-60 Hz

Encoding performance of the proposed and conventional models with respect to PSNR for data set 2. a UHD HEVC-720p-30 Hz, b UHD HEVC-720p-60 Hz, c UHD HEVC-1080p-30 Hz, d UHD HEVC-1080p-60 Hz, e UHD HEVC-2160p-30 Hz and f UHD HEVC-2160p-60 Hz
In Fig. 5a, the PSNR of the proposed method is 21.16% superior to ABC, 17.96% superior to FF, 15.81% superior to GA and 8.99% superior to PSO algorithms, 9.88% better than the GWO. Accordingly, the PSNR of the adopted scheme is 5.7% superior to ABC, 9.34% superior to FF, 3.16% superior to GA and 2.4% superior to PSO algorithms in Fig. 5b. In Fig. 5d, the PSNR of the adopted WOA scheme is 6.92% superior to ABC, 4.13% superior to FF, 2.34% superior to GA and 0.66% superior to PSO algorithms.
Similarly, the outcomes of the encoding process for data set 2 are presented in Figs. 6 and 7, respectively. Finally, it is known from the experimental outcomes that the proposed WOA has better PSNR and a bit rate in compressed form when compared with the conventional schemes.
Table 2 summarizes the performance analysis of the proposed and conventional methods in terms of SSIM, RMSE, UQI, VIF, bit rate (Kbps), and it is tested for data set 1. The overall analysis shows that the proposed method outperforms the conventional algorithms. The result analysis shows that the performance of the proposed method possess lower RMSE than that of the conventional models. The results obtained by the proposed method are far better when comparing with the conventional methods in terms of UQI. Moreover, the performance analysis of the proposed method and conventional methods in terms of bit rate. From the table, it is noticed that the bit rate values for the proposed method is higher than that of the conventional methods.
Table 3 shows the performance analysis of the proposed and conventional models in terms of data set 2. Here, the performance analysis is of the proposed method and conventional methods by evaluating the VQI. The overall analysis illustrates the performance of the proposed method is superior to the conventional models.
Tables 4 and 5 demonstrate the variation of the PSNR and SSIM versus the SNR of the proposed method for data set 1 and 2. For ease of observation, we have computed the PSNR and SSIM values for video sequences. From the tables, it can be see that the proposed method clearly outperforms all the conventional methods in terms of the PSNR and SSIM metrics.
5.3 Computational complexity
This section portrays the time which is consumed by the proposed and conventional schemes for the encoding process and it is shown in Tables 6 and 7. From Table 6, on considering the football video, the techniques have consumed the time of 7352525 ms, 7535655 ms, 7565415 ms and 7854611 ms for block sizes 1, 2, 4 and 8, correspondingly for data set 1. Likewise, Table 7 describes the time utilized for the encoding process by the UHD HEVC-720p-30 Hz, UHD HEVC-720p-60 Hz, UHD HEVC-1080p-30 Hz, UHD HEVC-1080p-60 Hz, UHD HEVC-2160p-30 Hz and UHD HEVC-2160p-60 Hz. Here, the computational complexity of the proposed method will be lesser than the other conventional models in both datasets for various block size such as 1,2, 4 and 8.
The computational complexity of the proposed method is stated in Eq. (14), where \( N \) denotes number of iterations, \( M \) denotes the population size, \( H \) denotes the HEVC functions.
5.4 Optimization details of algorithm convergence
Table 8 summarizes the review on optimization details included in algorithm convergence. The overall analysis of the proposed method as well as the conventional algorithms with parameters and its values were described. Here, the parameters used for every basic algorithms of both conventional methods such as ABC, FF, GA, PSO, CSO, GSO, DE and GWO and the proposed method were determined as shown below.
5.5 Outliers removal rate
The outlier removal rate is determined as the number of bits that are dropped out as redundant information by the proposed holoentropy based encoding method. This metric is inversely proportional to the number of bits transmitted after encoding process.
Figure 8 summarizes the Outliers removal rate of the proposed models for data set 2 using various block size. The overall analysis shows that the proposed method outperforms were analyzed for UHD HEVC-720p-30 Hz, UHD HEVC-720p-60 Hz, UHD HEVC-1080p-30 Hz, UHD HEVC-1080p-60 Hz, UHD HEVC-2160p-30 Hz and UHD HEVC-2160p-60 Hz using the block size 1,2 4 and 8. The result of the analysis shows that the performance of the proposed method is better for the UHD HEVC-1080p-30 Hz in dataset 2.

Outliers removal rate (%) of the proposed models for data set 2 using various block size
Figure 9 summarizes the outliers removal rate of the proposed models for data sets 1 using various block size. The overall analysis shows that the proposed method outperforms were analyzed for football, mobile, garden, coastguard, foreman and tennis using the block size 1, 2 4 and 8. The result analysis shows that the performance of the proposed method is better for the coastguard and hence the garden video sequence obtains the lower value in dataset 2.

Outliers removal rate (%) of the proposed models for data set 1 using various block size
6 Conclusion
This paper has presented an encoding process in HEVC using enhanced holoentropy for proficient compression. The process of encoding in the HEVC system was attained by enhanced holoentropy that was determined based on weighting tansig function. Accordingly, the weights of tansig function were optimally tuned using the WOA algorithm. When high-resolution video sequences were processed, it needs considerable development. The pixel deviations beneath altering frames were clustered depending on the interest, and accordingly, the outliers were eliminated using a sophisticated entropy standard known as enhanced holoentropy. Moreover, the adopted approach was distinguished with the traditional techniques namely, ABC, FF, PSO GA, CSO, GSO, DE and GWO in terms of PSNR, bit rate in compressed form, RMSE, SSIM, UQI, VIF and bit rate. From the analysis, for block size 1, the bit rate in compressed form for presented WOA was 1.89% better than ABC, 1.31% better than FF, 0.69% better than GA and 0.35% better than PSO algorithms. Likewise, the PSNR for offered WOA was 21.16% superior to ABC, 17.96% superior to FF, 15.81% superior to GA and 8.99% superior to PSO algorithms. Likewise, considering the football video in terms of time consumption analysis, the techniques have consumed the time of 7352525 ms, 7535655 ms, 7565415 ms and 7854611 ms for block sizes 1, 2, 4 and 8, correspondingly. Thus, by performing the encoding procedure, the proposed model was found to minimize the size of a video with perceptually enhanced PSNR or video quality with reduced computational time.
Abbreviations
- ABC:
-
Artificial bee colony
- AMVP:
-
Advanced MV prediction
- AVC:
-
Advanced VC
- BE:
-
Blind extraction
- CABAC:
-
Context-adaptive binary arithmetic coding
- CB:
-
Coding blocks
- CM:
-
Context modeling
- CTB:
-
Chroma tree block
- CTU:
-
Coding tree unit
- CU:
-
Coding unit
- CPMV:
-
Control point motion vectors
- DSCNN:
-
Decoder-side scalable convolutional neural network
- DVC:
-
Distributed VC
- FF:
-
Fire fly
- GA:
-
Genetic algorithm
- HEVC:
-
High efficiency video coding
- IPL:
-
Inter-picture prediction loop
- IRAP:
-
Intra-random access point
- JCT-VC:
-
Joint collaborative team on video coding
- JND:
-
Just noticeable distortion
- LC:
-
Luma coding
- LDP:
-
Low delay power
- MB:
-
Macro block
- MVD:
-
Multi-view video plus depth
- MPEG:
-
Moving picture experts group
- MPRGAN:
-
Multi-level progressive refinement network via an adversarial training approach
- MCMC:
-
Markov Chain Monte Carlo
- MC:
-
Motion compensation
- MV:
-
Motion vector
- NN:
-
Neural network
- NTC:
-
Nonzero transform coefficient
- PAMC:
-
Perspective affine motion compensation
- PB:
-
Prediction blocks
- PSNR:
-
Peak signal-to-noise ratio
- PSO:
-
Particle swarm optimization
- QP:
-
Quantization parameter
- RMSE:
-
Root mean squared error
- UQI:
-
Universal quality image index
- VIF:
-
Visual information fidelity
- PU:
-
Prediction units
- RD:
-
Rate distortion
- RA:
-
Random access
- SAO:
-
Sample adaptive offset
- SSIM:
-
Structural similarity index
- SVR:
-
Support vector regression
- TB:
-
Transform blocks
- TU:
-
Transform units
- VBR:
-
Video bit rate
- VCS:
-
Video constraint set
- VVC:
-
Versatile video coding
- VCEG:
-
Video coding experts group
- WOA:
-
Whale optimization algorithm
- 3D-HEVC:
-
Three-dimensional HEVC
References
Lin, J.L., Chen, Y.W., Chang, Y.L., An, J., Lei, S.: Advanced texture and depth coding in 3D-HEVC. J. Vis. Commun. Image Represent. 50, 83–92 (2018)
Pan, Z., Jin, P., Lei, J., Zhang, Y., Sun, X., Kwong, S.: Fast reference frame selection based on content similarity for low complexity HEVC encoder. J. Vis. Commun. Image Represent. 40, 516–524 (2016)
Migallón, H., Hernández-Losada, J.L., Cebrián-Márquez, G., Piñol, P., Malumbres, M.P.: Synchronous and asynchronous HEVC parallel encoder versions based on a GOP approach. Adv. Eng. Softw. 101, 37–49 (2016)
Mercat, A., Bonnot, J., Pelcat, M., Desnos, K., Menard, D.: Smart search space reduction for approximate computing: a low energy HEVC encoder case study. J. Syst. Arch. 80, 56–67 (2017)
Lee, D., Jeong, J.: Fast CU size decision algorithm using machine learning for HEVC intra coding. Signal Process. Image Commun. 62, 33–41 (2018)
Shen, L., Zhang, Z., Zhang, X., An, P., Liu, Z.: Fast TU size decision algorithm for HEVC encoders using Bayesian theorem detection. Signal Process. Image Commun. 32, 121–128 (2015)
Zhang, Q., Wang, X., Huang, X., Rijian, S., Gan, Y.: Fast mode decision algorithm for 3D-HEVC encoding optimization based on depth information. Digit. Signal Process. 44, 37–46 (2015)
Guarda, A.F., Santos, J.M., da Silva Cruz, L.A., Assunção, P.A., Rodrigues, N.M., de Faria, S.M.: A method to improve HEVC lossless coding of volumetric medical images. Signal Process. Image Commun. 59, 96–104 (2017)
Fernández, D.G., Del Barrio, A.A., Botella, G., García, C., Hermida, R.: Complexity reduction in the HEVC/H265 standard based on smooth region. Digit. Signal Process. 73, 24–39 (2018)
Sole, J., Joshi, R., Nguyen, N., Ji, T., Karczewicz, M., Clare, G., Duenas, A.: Transform coefficient coding in HEVC. IEEE Trans. Circuits Syst. Video Technol. 22(12), 1765–1777 (2012)
Kıran, M.S., Fındık, O.: A directed artificial bee colony algorithm. Appl. Soft Comput. 26, 454–462 (2015)
González-de-Suso, J.L., Martínez-Enríquez, E., Díaz-de-María, F.: Adaptive Lagrange multiplier estimation algorithm in HEVC. Signal Process. Image Commun. 56, 40–51 (2017)
Llamocca, D.: Self-reconfigurable architectures for HEVC forward and inverse transform. J. Parallel Distrib. Comput. 109, 178–192 (2017)
Mirjalili, S., Lewis, A.: The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016)
Sullivan, G., Ohm, J., Han, W.-J., Wiegand, T.: Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 22(12), 1649–1668 (2012)
Sullivan, G.J., Boyce, J.M., Chen, Y., Ohm, J.R., Segall, C.A., Vetro, A.: Standardized extensions of high efficiency video coding (HEVC). IEEE J. Select. Top. Signal Process. 7(6), 1001–1016 (2013)
Mostafa Bozorgi, S., Yazdani, S.: IWOA: an improved whale optimization algorithm for optimization problems. J. Comput. Des. Eng. 6(3), 243–259 (2019)
Liu, Z., Lin, T.-L., Chou, C.-C.: Efficient prediction of CU depth and PU mode for fast HEVC encoding using statistical analysis. J. Vis. Commun. Image Represent. 38, 474–486 (2016)
Xu, Z., Min, B., Cheung, R.C.: A fast inter CU decision algorithm for HEVC. Signal Process. Image Commun. 60, 211–223 (2018)
Masera, M., Fiorentin, L.R., Masala, E., Masera, G., Martina, M.: Analysis of HEVC transform throughput requirements for hardware implementations. Signal Process. Image Commun. 57, 173–182 (2017)
Tang, T., Li, L.: Rate control for non-uniform video in HEVC. J. Vis. Commun. Image Represent. 48, 254–267 (2017)
Chung, B., Yim, C.: Fast intra prediction method by adaptive number of candidate modes for RDO in HEVC. Inf. Process. Lett. 131, 20–25 (2018)
Ding, H., Huang, X., Zhang, Q.: The fast intra CU size decision algorithm using gray value range in HEVC. Opt. Int. J. Light Electron Opt. 127(18), 7155–7161 (2016)
Kuanar, S., Rao, K.R.: Christopher conly, fast mode decision in HEVC intra prediction, using region wise CNN feature classification. In: International Conference on Multimedia and Expo Workshops (ICMEW), San Diego, CA, pp. 1–4. IEEE (2018)
Kuanar, S., Rao, K.R., Bilas, M., Bredow, J.: Adaptive CU mode selection in HEVC intra prediction: a deep learning approach. Circuits Syst. Signal Process. 38(11), 5081–5102 (2019)
Kuanar, S., Conly, C., Rao, K.R.: Deep learning based HEVC in-loop filtering for decoder quality enhancement. In: Picture Coding Symposium (PCS), pp 164-168. IEEE (2018)
Goswami, K., Lee, J.H., Kim, B.G.: Fast algorithm for the high efficiency video coding (HEVC) encoder using texture analysis. Inf. Sci. 364, 72–90 (2016)
Dutta, T., Gupta, H.P.: A robust watermarking framework for high efficiency video coding (HEVC)-encoded video with blind extraction process. J. Vis. Commun. Image Represent. 38, 29–44 (2016)
Zhang, Q., Zhang, Z., Jiang, B., Zhao, X., Gan, Y.: Fast 3D-HEVC encoder algorithm for multiview video plus depth coding. Opt. Int. J. Light Electron Opt. 127(20), 8864–8873 (2016)
Lin, T.-L., Yang, N.-C., Syu, R.-H., Liao, C.-C., Chen, S.-L.: NR-bitstream video quality metrics for SSIM using encoding decisions in AVC and HEVC coded videos. J. Vis. Commun. Image Represent. 32, 257–271 (2015)
Guo, J., Gong, H., Weijian, X., Huang, L.: Hierarchical content importance-based video quality assessment for HEVC encoded videos transmitted over LTE networks. J. Vis. Commun. Image Represent. 43, 50–60 (2017)
Wang, S., Luo, F., Ma, S., Zhang, X., Gao, W.: Low complexity encoder optimization for HEVC. J. Vis. Commun. Image Represent. 35, 120–131 (2016)
Van, X.H., Ascenso, J., Pereira, F.: HEVC backward compatible scalability: a low encoding complexity distributed video coding based approach. Signal Process. Image Commun. 33, 51–70 (2015)
Kumar, B.S., Manjunath, A.S., Christopher, S.: Improved entropy encoding for high efficient video coding standard. Alex. Eng. J. 57(1), 1–9 (2018)
Choi, Y.J., Jun, D.S., Cheong, W.S., Kim, B.G.: Design of efficient perspective affine motion estimation/compensation for versatile video coding (VVC) standard. Electronics 8(9), 993 (2019). https://doi.org/10.3390/electronics8090993
Yang, R., Xu, M., Wang, Z.: Decoder-side HEVC quality enhancement with scalable convolutional neural network. In: IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, pp. 817–822 (2017). https://doi.org/10.1109/icme.2017.8019299
Lee, J.H., Lee, Y.W., Jun, D., Kim, B.G.: Efficient color artifact removal algorithm based on high-efficiency video coding (HEVC) for high-dynamic range video sequences. IEEE Access 8, 64099–64111 (2020). https://doi.org/10.1109/access.2020.2984012
Goswami, K., Kim, B.G.: A design of fast high-efficiency video coding scheme based on markov chain monte carlo model and Bayesian classifier. IEEE Trans. Ind. Electron. 65(11), 8861–8871 (2018). https://doi.org/10.1109/tie.2018.2815941
Jin, Z., An, P., Yang, C., Shen, L.: Quality enhancement for intra frame coding via CNNS: an adversarial approach. In: ICASSP, pp. 1368–1372 (2018)
Lee, Y.W., Kim, J.H., Choi, Y.J., Kim, B.G.: CNN-based approach for visual quality improvement on HEVC. In: IEEE International Conference on Consumer Electronics (ICCE 2018), pp. 498–500 (2018)
Fister, I., Fister, I., Yang, X.-S., Brest, J.: A comprehensive review of firefly algorithms. Swarm Evolut. Comput. 13, 34–46 (2013)
McCall, J.: Genetic algorithms for modelling and optimisation. J. Comput. Appl. Math. 184(1), 205–222 (2005)
Zhang, J., Xia, P.: An improved PSO algorithm for parameter identification of nonlinear dynamic hysteretic models. J. Sound Vib. 389, 153–167 (2017)
Sarangi, A., Sarangi, S.K., Mukherjee, M., Panigrahi, S.P.: System identification by Crazy-cat swarm optimization. In: 2015 International Conference on Microwave, Optical and Communication Engineering (ICMOCE), pp. 439–442. IEEE (2015)
Hatamlou, A., Abdullah, S., Othman, Z.: Gravitational search algorithm with heuristic search for clustering problems. In: 2011 3rd Conference on Data Mining and Optimization (DMO), Putrajaya, pp. 190–193 (2011)
Mohamad, Z.S., Darvish, A., Rahnamayan, S.: Eye illusion enhancement using interactive differential evolution. In 2011 IEEE Symposium on Differential Evolution (SDE), pp. 1–7. IEEE (2011)
Gu, W., Zhou, B.: Improved grey wolf optimization based on the quantum-behaved mechanism. In: 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, pp. 1537–1540 (2019)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This paper does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Munagala, V., Kodati, S. Enhanced holoentropy-based encoding via whale optimization for highly efficient video coding. Vis Comput 37, 2173–2194 (2021). https://doi.org/10.1007/s00371-020-01978-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-020-01978-3