
Abstract
A central claim of many embodied approaches to cognition is that understanding others’ actions is achieved by covertly simulating the observed actions and their consequences in one’s own motor system. If such a simulation occurs, it may be accomplished through forward models, a component of the motor system already known to perform simulations of actions and their consequences in order to support sensory-monitoring of one’s own actions. Forward-model simulations cause an attenuation of sensory intensity, so if the simulations hypothesized by embodied cognition are indeed provided by forward models, then action observation should trigger this sensory attenuation. To test this hypothesis, the experiments reported here measured the perceived intensity of a touch sensation on the finger when participants observed an active touch (a finger reaching to touch a ball) vs. a passive touch (a ball rolling to touch an unmoving finger). The touch sensation was perceived as less intense during observation of active touch in comparison with observation of passive touch, providing evidence that forward models are indeed engaged during action observation. The strength of this sensory attenuation is compared and contrasted with a well-established sensory-amplification effect caused by visual attention. This sensory-amplification effect has not generally been considered in studies related to sensory attenuation in action observation, which may explain conflicting results reported in the field.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Embodied theories of cognition often argue that we can gain a deeper understanding of others’ actions if we simulate those actions and their sensory consequences within our own motor-control system (Prinz 1987). Such hypothesized simulations are highly reminiscent of forward models, a well-established component of our motor-control system. Forward models (reviewed in more detail below) predict the sensory consequences of our own action plans (Aliu et al. 2009). These predictions are then used for several critical purposes, one of which is to prevent self-caused sensations from interfering with our ability to process sensations arising from external causes. Sensations which match forward-model predictions are tagged as ‘self-caused’ and their perceived intensity is attenuated, so that they are not confused with ‘other-caused’ sensations. This sensory attenuation is a hallmark of forward-model engagement. The similarity between forward-model simulations and the simulations hypothesized by embodied cognition leads to the proposition that these simulations are, in fact, the same thing. This proposal would simply mean that the role of the forward-model system has expanded from simulating one’s own actions to simulating others’ actions as well. If this is correct, then sensory attenuation should occur for an observer when watching another person performing an action. The experiments below test this prediction by comparing the perceived intensity of a touch stimulus when participants observe another person’s hand actively touching a ball vs. observing another person’s hand being passively touched by a ball. These experiments find that observing another’s actions does indeed cause sensory attenuation. This attenuation is contrasted with sensory amplification, an effect that has already been established to occur when a person pays visual attention to a touch event (Ro et al. 2004; Johnson et al. 2006). This amplification is shown in the experiments below by comparing the perceived intensity of a touch stimulus when the observer views a touch action (active or passive) in comparison with viewing an ‘empty’ video with no visual indication of a touch event.
The possible role of forward models as the mechanism of simulation in various forms of embodied cognition has been suggested by several researchers (e.g., Wolpert and Flanagan 2001; Grush 2004; Schubotz 2007), and previous work has addressed the question of whether action observation triggers forward models and consequent sensory attenuation. For example, Voisin et al. (2011), using electroencephalography (EEG), showed that participants’ somatosensory cortex was less responsive to a touch stimulus delivered to their fingers when they watched a touching action in comparison with when they watched an unrelated video. Similar brain-imaging studies have been done by Rossi et al. (2002) and Avikainen et al. (2002). This is important brain-imaging data which the current experiments seek to complement with behavioral data.
Embodied approaches to action observation
The idea that we understand others’ behavior by modeling that behavior within ourselves has a long history and is still hotly debated (Hickok 2014; Goldinger et al. 2016; Spaulding 2018).
First of all, there is evidence that seeing another person performing an action does indeed trigger related activity in the observer’s own motor system. Transcranial Magnetic Stimulation studies have provided much of this evidence, showing that motor evoked potentials for muscles are facilitated when participants watch actions that would involve those muscles, but muscles that would not be involved are not similarly facilitated (e.g., Fadiga et al. 1995; Strafella and Paus 2000; Enticott et al. 2010, 2011), though the degree to which this involves forward models is debated (Mathew et al. 2017).
Complementary evidence comes from brain imaging studies. Buccino et al. (2001), using functional Magnetic Resonance Imaging (fMRI), found that areas of the motor cortex activate in effector-specific patterns when participants view actions that are performed with various effectors. That is, mouth-relevant parts of the motor cortex activate when viewing actions involving the mouth (and similarly for foot and hand actions). That mouth-relevant parts of the motor cortex are activated by seeing actions involving the mouth (including speech—Pulvermüller et al. 2006) relates to embodied approaches to speech perception (e.g., Liberman and Mattingly 1985; Schwartz et al. 2008), many of which argue for a role of forward models (e.g., Skipper 2007; Hickok et al. 2011; Scott 2016; Yeung and Scott 2021).
Similarly, a large body of research has shown that somatosensory cortex is activated in humans when acting or when observing another person’s actions. This is related to the topic of mirror neurons which were first discovered in the macaque motor cortex and which are highly relevant to action observation—these neurons respond when the monkey performs an action or when it observes another agent performing the action (Pellegrino et al. 1992). There is significant research on mirror neurons in humans as well (reviewed in Molenberghs et al. 2012); however, most of this research is indirect in nature (stemming from ethical limitations on invasive studies in humans) and so the existence of mirror neurons in humans, while often assumed, has continued to be debated (Heyes and Catmur 2022). An overview of the neurophysiology of mirror neurons and action observation is provided in the General Discussion (Section “Neurophysiology”) below.
The overlap between the embodied cognition and mirror-neuron literatures is extensive (e.g., Caramazza et al. 2014; Keysers et al. 2018). While the experiments reported below are obviously compatible with a mirror-neuron explanation of action observation, they are not tied to such an interpretation. The experiments here test whether forward models are engaged by action observation—this activation may or may not turn out to be tied to mirror neurons, but that is an independent issue which these experiments do not address.
Forward models
Forward models are a component of our motor-control system whose function is to predict the sensory consequences of our own actions (Aliu et al. 2009). This simulation has several uses in motor-control and has proposed connections to many aspects of cognition (e.g., Haggard et al. 2002; Grush 2004; Sato 2009; Scott and Chiu 2021), but the key use, in terms of the theory explored here, is the ‘sensory-tagging’ function: Forward-models provide a way to ‘tag’ self-produced sensations as such and so avoid the confusion between self-caused and other-caused sensations that would otherwise occur. Confusing a self-caused sensation, such as the impact of the ground against one’s foot when walking, with an other-caused sensation, such as something on the ground attacking one’s foot, could have fatal consequences.
This tagging function is achieved, at least in part, by means of an attenuation of sensations that match the forward-model predictions. This sensory dampening is seen across sensory modalities (Schafer and Marcus 1973; Roy and Cullen 2004; Sylvester et al. 2005; Bristow 2006), and has been shown using both behavioral methods (Weiskrantz et al. 1971; Blakemore et al. 1999; Shergill et al. 2003; Voss et al. 2006; Scott 2013) and brain-imaging approaches (Blakemore et al. 1998; Eliades and Wang 2004; Bäss et al. 2008; Greenlee et al. 2011; Harrison et al. 2021). An overview of the neurophysiology of forward models is provided in the General Discussion (Section “Neurophysiology”) below.
The experiments reported here examine whether action observation (of a touch event) triggers forward models in the observer and leads to sensory attenuation of a simultaneously presented touch stimulus. This would support the embodied cognition view that we understand others by simulating their actions in ourselves, and that forward models are involved in this simulation.
Sensory amplification
A complication for trying to find sensory attenuation in action observation is that observing any instance of touch is known to actually amplify the perceived intensity of the touch. That is, when a person observes a hand being touched and feels a simultaneous touch on their own hand, they will report that the touch on their own hand seems more intense than in a control condition in which there is no touch event shown (Ro et al. 2004; Johnson et al. 2006). This sensory amplification is a potential confounding factor when examining sensory attenuation due to action observation, so the experiments below control for it by including a condition in which there is no observable action.
Prediction
The prediction tested in this paper is that when observing another person performing a touching action, participants will simulate the action in their own motor system and so engage their forward models, leading to a perceived attenuation of a simultaneously presented touch stimulus (in comparison with observing a person being passively touched). However, because of the amplification effects of visual attention, observing a touching action (active or passive) will result in sensory amplification in comparison with a control condition in which no touching action is shown.
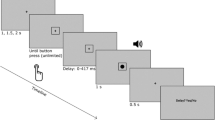
To test these predictions, throughout the experiments reported below, participants rested the tip of the middle finger of their left hand on a vibrotactile device that delivered a tap, while they watched videos of either active touch, passive touch, or no touch. Participants saw two of these videos in turn, one as the ‘Reference’ (first video) and the other as the ‘Target’ (second video). The participants’ task was to adjust the intensity of the tap they experienced during the Target video until it felt equal to the intensity of the tap during the Reference video.
If a Target video induces sensory attenuation, participants should need to raise the Target video intensity to compensate for the perceived attenuation, so that it feels equivalent to the unattenuated Reference video. In contrast, if a Target video induces sensory amplification, participants should need to lower the Target video intensity to compensate for its perceived amplification.
Experiment one
Participants
There were 25 female participants [age = 20.56 (1.65 sd), 4 left handers]. All were students at United Arab Emirates University (UAEU) who received course credit or monetary compensation for their participation. Only female participants were recruited as the department only has female students.
Participants signed a consent form to participate and both the experiment design and consent form had been approved by the UAEU ethics committee. There were no clear antecedent experiments to determine the likely size of the predicted attenuation effect and so the appropriate number of participants to be recruited could only be roughly estimated. The effect size was optimistically estimated at 0.6 and so to achieve a power of 0.8, power calculations showed that a minimum of 24 participants was needed. This was rounded up to 25 to add a small margin of safety.
Materials and apparatus
Videos
An animator (Berislav Curić) produced the three videos used: one ‘Active’, one ‘Passive’, and one ‘Empty’. The Active video showed a left hand with extended fingers moving toward a stationary ball and touching it (with the tip of the middle finger). The Passive video showed the inverse—a ball rolling (at the same speed as the hand movement in the Active video) toward a stationary hand and touching the tip of the extended middle finger. The Empty video simply showed an unchanging grey screen with an asterisk (as a fixation point) surrounded by hash-marks. The speed of movement for the ball and hand was made exactly the same (0.075 m/s), and the final frames (showing the contact between finger and ball) were identical in both videos. This was to give visual cues of equal tap force in the two videos.
There is evidence that ‘mirroring’ effects from observing others are stronger with greater similarity between the observer and the observed person (Serino et al. 2009), so the arm in the videos was designed to look like that of a woman wearing black clothing and with a skin complexion typical for the Gulf region. All participants were women who were students at UAEU (where the traditional black garb, while not a requirement, is very commonly worn), and most had a complexion similar to that shown in the video. Participants were not selected, or rejected, on the basis of their clothing or complexion, but designing the video stimuli in this way maximized the likelihood that participants would identify with the arm shown in the videos.
Figures 1, 2 and 3 show the first, middle and final frame of the three videos.

Active video, experiment one

Empty video, experiment one

Passive video, experiment one
Vibrotactile device
The tap stimulus was delivered by a vibrotactile device (bass shaker). This was a Clark Synthesis TST239 Silver Tactile Transducer. The device is 8 inches in diameter, but the point, where participants rested their fingers is a 9/16 inch raised knob in the centre. The bass shaker was encased in a sound absorbing box (a layered collection of fabric and plastic containers). For the range of intensities used, the bass shaker produced no measurable sound (as determined by a sound level meter); however, out of an abundance of caution, participants wore sound-isolating headphones (Extreme Isolation 30) playing white noise to mask any (unmeasurably) small amount of residual sound, ensuring that any effect was due to tactile perception alone and not to auditory perception.
Tap
The tap stimulus consisted of one cycle of a modified 15 Hz sine wave, rapidly fading out after the positive peak, so that there was only one pulse felt. The waveform of this modified sine-wave is shown in Fig. 4. As the tap stimulus was carried by audio circuitry, the intensity was easily modified by simply raising or lowering the volume of the audio in the experiment software. Participants did this using the ‘up’ and ‘down’ arrow keys with their right hand.
An intensity range for the tap was established, through piloting, in which the lowest starting intensity for the tap in any condition was easily felt by fingers resting on the bass shaker, but the maximum intensity of the tap did not produce any measurable sound (as measured by a sound level meter). On each trial the initial intensity of the Reference tap was either 50% or 60% (selected at random) of the established maximum. Similarly, on each trial, the initial intensity of the Target tap was randomly selected from one of four values (30%, 40%, 70% or 80% of the maximum) and so started above the Reference tap intensity for half of the trials and below for half the trials. These starting values for Reference and Target tap were counterbalanced across trials for each participant, so that all videos occurred with the same starting intensity levels (in Target and Reference videos) across the experiment for each participant. The maximum tap intensity corresponded to a force of c. 3 N.Footnote 1

Modified sine-wave for tap
Procedure
There were six conditions, consisting of each of the possible video comparisons in the Reference and Target positions (excluding comparing a video with itself).
Two of these conditions address the sensory-attenuation question:
-
Active-video Reference, Passive-video Target.
-
Passive-video Reference, Active-video Target.
Four of these conditions were included to replicate the sensory-amplification effect:
-
Active-video Reference, Empty-video Target.
-
Empty-video Reference, Active-video Target.
-
Passive-video Reference, Empty-video Target.
-
Empty-video Reference, Passive-video Target.
Participants rested the tip of the middle finger of their left hand (the location shown touching/being touched in the Active and Passive videos) on the vibrotactile device. This delivered a tap at the moment of contact between ball and finger in the Active and Passive videos. The tap also occurred at the same moment during the Empty video but, of course, there was no visual correlate of the touch in this condition.
The six conditions were presented eight times each in intermixed random order. Therefore, participants made eight intensity judgments for each condition and a total of forty-eight judgments overall. The Reference was played just once and then the Target was played on a loop. Participants adjusted the tap intensity using the ‘up’ and ‘down’ arrow keys on the keyboard with their right hand. Participants could replay the Reference video again at any point during a trial by hitting the ‘r’ key on the keyboard. When they considered the tap intensity to be equal in the two videos, participants hit the ‘enter’ key. Participants kept their finger on the vibrotactile device at all times.
The experiment started with a brief practice session (c. 3 min) to acclimatize participants to the set-up. The entire experiment lasted about 40 min. The experiment was run on the Psychopy experiment platform (Peirce 2007) in a sound-treated booth at UAEU.
A sketch of the experimental set-up is presented in Fig. 5 and a timeline of a single trial is shown in Fig. 6

Sketch of experimental set-up

Timeline of a single trial
Data analysis
All statistical tests reported in this article were conducted using the R statistical programming language (R Core Team 2014). For ANOVA, the “ez” package within R was used (Lawrence 2013). For power calculations the “pwr” package was used (Champely et al. 2018) and for the effect-size calculations, the “effsize” package was used (Torchiano 2017). Effect size calculations all used the classical Cohen’s d formula (Cohen 1988) with no correction for repeated measures, thus giving a conservative estimate of effect size. Statistical significance was defined as p < 0.05.
The dependent measure was a difference score between the Reference video’s tap intensity level and the final setting of the Target video’s tap intensity (final Target intensity—Reference intensity). These numbers, representing differences in intensity values in arbitrary units of computer system volume, were converted to z-scores.
A 1 \(\times\) 6 repeated-measures ANOVA was conducted to determine whether there were significant differences between the six conditions. This was followed by three planned t-tests (a Bonferroni correction was applied to all t-tests) comparing each pairing of conditions with its reverse pairing—thus the pairing of Active Reference video and Passive Target video was compared against the reverse pairing of Passive Reference video and Active Target video (and similarly for the other condition pairings).
The experiment was designed for such an analysis, because the Reference and Target videos are not perfectly equivalent in terms of the participants’ experience with them: The Reference video is seen first, it is seen just once (unless the participant decided to replay it) and it is treated conceptually as the “reference point”. The Target video is seen second, it is seen multiple times (played on a loop) and it is treated as the “manipulandum”. These differences may have an impact. Comparing each pair of conditions with its reverse allows these issues (and perhaps other unforeseen issues), to be counterbalanced, so that any potential influences cancel out across condition pairings.
Results
The 1 \(\times\) 6 repeated-measures ANOVA on the six conditions was significant [F(5, 120) = 10.59, p < 0.001]. An omnibus ANOVA found no interaction with handedness p = 0.896.
The mean and standard deviation for each condition and the results of the three t-test comparisons between conditions (as well as effect sizes) are reported in Table 1.Footnote 2
The key comparison for demonstrating sensory attenuation (Active–Passive comparison) is plotted in Fig. 7, the remaining four conditions, which demonstrate sensory amplification, are plotted in Fig. 8.
As predicted, when altering the intensity of the tap accompanying the Active Target video to match it to the tap accompanying the Passive Reference video, participants raised the intensity of the tap in comparison with the reverse pairing (Passive Target video and Active Reference video).Footnote 3 This means that they perceived the tap in the Active video as weaker than that in the Passive video (and so had to increase the intensity of the Active video tap to compensate for its lower perceived intensity). This is sensory attenuation.
Also as predicted, both the Active and Passive videos had the effect of increasing the perceived intensity of the accompanying tap in comparison with the Empty video – participants raised the intensity of the tap in the Empty videos in comparison with the other videos, indicating that they perceived the tap in the Active and Passive videos as more intense (and so the tap in the Empty video tap needed to be raised to match). As discussed above, this sensory amplification is the predicted result of visual attention to a touch event (whether active or passive).
A follow-up ANOVA was conducted on the difference scores between the various pairings to determine whether the smaller difference between the Active-Passive pairings on one hand (measuring sensory attenuation), and the various pairings with the Empty video on the other (measuring sensory amplification), was significant, i.e., whether there was an interaction. This was significant [F(2, 48) = 7.289, p < 0.01], showing that the amplification effect was significantly larger than the attenuation effect.

Results of Experiment One (Key Conditions for Demonstrating Sensory Attenuation)—SE bars are shown. These error bars were calculated using the Cousineau (2005), Morey (2008) method to adjust for repeated-measures design. Individual data-points are also shown, jittered on the horizontal axis for visibility

Results of Experiment One (Key Conditions for Demonstrating Sensory Amplification)—SE bars are shown. These error bars were calculated using the Cousineau (2005), Morey (2008) method to adjust for repeated-measures design. Individual data-points are also shown, jittered on the horizontal axis for visibility
Discussion
The experiment showed that seeing a video of a finger actively touching a ball (in comparison with a finger being passively touched by a ball) made a simultaneously presented tap to the finger seem less intense. This is sensory attenuation and so the results suggest that forward models are engaged when people view others’ actions.
In addition, this experiment showed that visual information about touch (active or passive) enhances the perceived intensity of the touch. That is, viewing either the Active or Passive touch videos led to a more intense perception of touch intensity than watching a non-touch video.
Thus, there are two effects working in opposite directions when participants view these videos: Observing a video showing any touch (active or passive) leads to amplification of the perceived intensity of the touch while observing a video of an active touch leads to attenuation of the perceived intensity in comparison with observing a video of passive touch. The sensory-amplification effect is significantly larger than the sensory-attenuation effect.
These issues are examined in greater detail in the General Discussion (Section “General discussion”) below.
Experiment two
Experiment One established that people perceive a tap as less intense when they observe video of a person performing a simultaneous touch action, suggesting that they are simulating that person’s actions and engaging forward models, which are known to attenuate sensations that are compatible with the forward-model predictions. However, this is a new finding and so needs replication. Furthermore, the videos used in Experiment One had a minor flaw—the point of contact between ball and hand was slightly off-centre, meaning that the total durations of hand motion and ball motion were not perfectly equal between the two videos. In order to ensure that this asymmetry was not a confound and to replicate the findings of Experiment One, a second experiment was conducted with a larger number of participants. This experiment was mostly identical to Experiment One with the exception of having improved video stimuli and a larger group of participants. In all other respects, the structure of the experiments was the same.
Participants
As the primary comparison of interest in Experiment One, the Active–Passive comparison, achieved significance with only a narrow margin, this replication recruited a larger number of participants to have sufficient power to reliably replicate the effect. An experimental power of 0.85 was targeted, and a power calculation for the Active–Passive comparison (which was the weakest effect in Experiment One) showed that 51 participants should achieve this. To include an extra margin of safety, a total of 55 participants were recruited, corresponding to an estimated power of 0.88.
All 55 participants were female students at UAEU [age = 21.33 (sd = 1.98), 4 left-handers] who received course credit or monetary compensation for their participation. Participants signed a consent form to participate and both the experiment design and consent form had been approved by the UAEU ethics committee. Only female participants were recruited as the department only has female students.
Materials and apparatus
The videos in Experiment One had the point of contact between finger and ball slightly off-centre. This probably would not matter, but it did mean that the arm seemed to travel a slightly greater distance than the ball and so there was an unnecessary asymmetry between the Active and Passive conditions. This was altered in the current experiment, so that the ball and hand met in the exact centre of the screen. Furthermore, a small amount of compression of the ball and finger-tip at the moment of contact was included in these videos (the same in both Active and Passive videos) so that there was a clear visual indication that the amount of force was the same in both conditions. As with Experiment One, the speed of movement for the ball and hand was made exactly the same (0.075 m/s). The Empty video remained identical. The first, mid-point of video, and point of contact frames of the new videos are shown in Figs. 9 and 10.

Active video, experiment two

Passive video, experiment two
Procedure
Aside from the the change in the stimuli, the procedure was otherwise identical to Experiment One.
Data analysis
As with Experiment One the experiment consisted of six conditions (all six possible combinations of the three videos in the Reference vs. Target positions, excluding comparing a video to itself) and the dependent measure was a difference score between the Reference video’s tap intensity level and final setting of the Target video’s tap intensity (final Target intensity—Reference intensity). These numbers were converted to z-scores.
A 1 \(\times\) 6 repeated-measures ANOVA was conducted to determine whether there were significant differences between the six conditions. This was followed by three planned t-tests, comparing each pairing of conditions with its reverse pairing, e.g., Active video Reference—Passive video Target compared with Passive video Reference—Active video Target. A Bonferroni correction was applied to all t-tests.
Results
The 1 \(\times\) 6 repeated-measures ANOVA on the six conditions was significant [F(5, 270) = 88.32, p < 0.001]. An omnibus ANOVA found no interaction with handedness p = 0.734.
The mean and standard deviation for each condition and the results of the three t-test comparisons between conditions (as well as effect sizes) are reported in Table 2.Footnote 4
The key comparison for demonstrating sensory attenuation (Active-Passive comparison) is plotted in Fig. 11, the remaining four conditions, demonstrating sensory amplification, are plotted in Fig. 12.
As with Experiment One, when altering the intensity of the tap accompanying the Active Target video to match it to the tap accompanying the Passive Reference video, participants increased the intensity of the tap (in comparison with the reverse pairing of Passive Target video and Active Reference video). This means that they perceived the tap in the Active video as weaker than that in the Passive video and so they needed to increase the intensity of the Active video tap to compensate for its perceived lower intensity. This is sensory attenuation.
Again, as predicted and as found in Experiment One, the presence of any touch video (Active or Passive) made the accompanying tap feel more intense in comparison to the Empty video – Participants raised the intensity of the tap accompanying the Empty Target videos in comparison with the other videos as Reference, indicating that they perceived the tap in the Active and Passive Reference videos as more intense (and so the tap in the Empty Target video needed to be increased to match).Footnote 5 This is sensory amplification.
A follow-up ANOVA was conducted on the difference scores between the various pairings to determine whether the smaller difference between the Active-Passive pairing (showing sensory attenuation) on one hand, and the various pairings with the Empty video (showing sensory amplification) on the other, was significant (i.e., whether there was an interaction). This was significant [F(2, 108) = 20.336, p < 0.001], showing that the amplification effect was significantly larger than the attenuation effect.

Results of Experiment Two (Key Conditions for Demonstrating Sensory Attenuation)—SE bars are shown. These error bars were calculated using the Cousineau (2005), Morey (2008) method to adjust for repeated-measures design. Individual data-points are also shown, jittered on the horizontal axis for visibility

Results of Experiment Two (Key Conditions for Demonstrating Sensory Amplification)—SE bars are shown. These error bars were calculated using the Cousineau (2005), Morey (2008) method to adjust for repeated-measures design. Individual data-points are also shown, jittered on the horizontal axis for visibility
Discussion
Experiment Two successfully replicated (using different videos) the findings of Experiment One, both the sensory-attenuation effect of active-touch vs. passive-touch observation and the sensory-amplification effect of watching a touch event. This both addresses the potential shortcomings of Experiment One and serves as a replication of its findings.
General discussion
Both of the experiments reported above successfully demonstrate the predicted sensory attenuation of a touch stimulus during observation of active touch in comparison with observation of passive touch. This attenuation is the predicted effect of forward-model engagement which lowers the perceived intensity of self-caused (or in this case, vicariously self-caused) sensations. This provides behavioural evidence that action observation engages forward models.
There are, however, two effects at work in these experiments altering the perceived intensity of the touch stimulus. In addition to sensory attenuation due to forward-model engagement, there is sensory amplification due to visual attention. Visual attention drawn to the moment of contact amplifies the perceived intensity of the touch in both Active and Passive conditions, in comparison with the Empty condition in which no action was shown. This appears to be a side-effect of directing attention to the event and is likely related to the visual enhancement of touch effect (reviewed in Serino and Haggard 2010; Eads et al. 2015), in which simply viewing a body part, with no visual indication of touch, is sufficient to improve tactile acuity for that body part. This effect occurs for viewing one’s own body or that of another person, though the effect appears to be stronger when the body is one’s own (Serino et al. 2008).
In summary, these experiments predicted and found two forms of sensory modulation as a result of action observation:
-
Attenuation of the perceived intensity of touch when the video was of active touch in comparison with passive touch. This showed an effect size of 0.43 in Experiment One and 0.32 in Experiment Two.
-
Amplification of the perceived intensity of touch when there was video showing a touching action (either active or passive). The difference between Active video and Empty video showed an effect size of 1.12 in Experiment One and 1.22 in Experiment Two. The difference between Passive video and Empty video showed an effect size of 1.15 in Experiment One and 1.51 in Experiment Two.
Sensory amplification is the larger of the two effects, underscoring the necessity of comparing active and passive touch observation when investigating sensory attenuation. Sensory attenuation is significantly weaker and so would get swamped by the amplification effect without control conditions that can separate out their contributions.
Several previous studies have examined the possibility of sensory attenuation from action observation. Thomas et al. (2013) looked at speech actions, testing whether observers would rate a tactile stimulation of their own lips as less intense when observing a speaker pronouncing a sound that involved lip movement. Rather than attenuation, they found an increase in the perceived intensity of the tactile stimulation during action observation. However, as they did not have a passive-touch control condition, the increase they found is likely due to the sensory-amplification effect.
Vastano et al. (2016) examined the modulation of the perceived intensity of a touch stimulus as a consequence of watching a video of a person performing a reaching action. They found lowered tactile sensitivity when participants watched the reaching phase of the action in comparison with the grasping phase (their video showed an arm grasping a cylinder). They interpreted their results as sensory attenuation caused by action observation; however, it is possible that participants in their study experienced sensory amplification in the ‘grasping phase’, rather than sensory attenuation in the ‘reaching phase’.
Finally, a set of experiments was recently conducted by Kilteni et al. (2021) (see also Burin et al. 2019 ). These experiments were very similar to the experiments reported in the current study and tested the same idea: Whether observation of a person performing an action would trigger sensory attenuation. In the Kilteni et al. (2021) experiments, participants rated the intensity of a touch stimulus while watching an actor perform a touch action. In their first experiment, Kilteni et al. (2021) found that observation of a touch action did induce attenuation, but not in comparison with a control condition (which had no action observation). They interpreted this lack of attenuation between their action-observation and control conditions as lack of evidence for sensory attenuation. However, if the sensory-amplification effect discussed above is taken into account, their data actually seem to support the finding of sensory attenuation reported in the current experiments.
Kilteni and Ehrsson (2017) performed another set of experiments that is similar to those reported here. In these experiments, they tested the degree to which incorporating a rubber hand into one’s own body schema (The ‘rubber hand illusion’ - Botvinick and Cohen 1998) influences sensory-attenuation effects. They found that sensory attenuation occurred when people observed a rubber hand being touched if they experienced the illusion that the rubber hand was their own, but if they did not experience this illusion (and so saw the rubber hand as being that of another person) the sensory attenuation was weakened. While this seems to argue against sensory attenuation due to action observation, it should be noted that, while their comparison showed that attenuation was weakened when participants considered the observed hand to be that of another person, it did not show that there was no attenuation. In fact, the graphs of their data suggest that attenuation, while weaker, did occur even when people viewed the rubber hand as belonging to another person. In an extension of the rubber-hand paradigm, Pyasik et al. (2021), using EEG, found almost identical reduction in somatosensory evoked potentials for self-caused stimuli and stimuli caused by an embodied rubber hand.
Neurophysiology
This section provides a brief summary of the neurophysiology relevant to mirror neurons, forward models and action observation.
Mirror neurons, first discovered in the brains of macaque monkeys, are active when the monkey either performs or observes an action (Pellegrino et al. 1992). This neural connection between action and observation has been tied to embodied cognition (Gallese 2005) and has spawned a vast research field. Mirror neurons were established through single-cell recordings; however, ethical considerations preclude such investigations in humans except where electrode implantation is medically required. Thus, evidence for mirror neurons in humans has primarily been through non-invasive brain-imaging, most commonly fMRI (reviewed in Molenberghs et al. 2012)—though there has been a single-cell recording study on humans providing support for the presence of mirror neurons (Mukamel et al. 2010). Given the dependence on largely indirect evidence, some debate remains about the status of mirror neurons in humans.
Mirror neurons were initially established in the ventral premotor cortex of macaque monkeys (Pellegrino et al. 1992; Gallese et al. 1996). However, subsequent research has found clear evidence of mirror neurons in the ‘lower-level’ motor areas of primary motor cortex (M1) (Kilner and Lemon 2013; Palmer et al. 2016). Similar cells have been found in sensory-related areas, such as ventral intraparietal area (Ishida et al. 2010) and lateral intraparietal area (Shepherd et al. 2009). The cells in these regions show common coding for self and other but they are not strictly motor neurons and so are sometimes referred to as ‘mirror neuron-like’ (Kilner and Lemon 2013).
Visual information about biological motion, upon which mirror neurons rely, likely originates in the superior temporal sulcus (STS) (Fogassi and Simone 2013). Interestingly, the STS has also been implicated in both forward models and action observation (e.g., Limanowski et al. 2018). This commonality between regions involved in mirror neurons and forward models is not surprising, as there have been many proposals linking forward models to mirror neurons (e.g., Wolpert et al. 2003; Iacoboni 2005; Kilner et al. 2007).
Evidence for forward models was initially behavioural (Sperry 1950; Von Holst 1954) and theoretical (Bridgeman 2007) and so the neurophysiology is still in somewhat early stages. Despite this, there is broad agreement that forward models involve, among other areas: Premotor cortex, supplementary motor area, cerebellum, sensorimotor cortex, and the previously discussed STS.
As forward models are part of the motor control system, the role of premotor cortex is well-established (e.g., Miall 2003; Iacoboni 2005; Welniarz et al. 2021; Takei et al. 2021). Electrophysiological studies have also shown that the supplementary motor area is involved in generating the sensory attenuation related to forward models (Haggard and Whitford 2004; Juravle 2017).
A large number of studies have argued for a role of the cerebellum in forward models (e.g., Wolpert et al. 1998; Miall et al. 1993; Ito 2008). In line with this, Blakemore et al. (1998) found, using fMRI, that the cerebellum was more active for self than for externally-produced touch sensations.
Finally, as forward models are sensory as well as motor, they necessarily involve somatosensory cortex. Many brain-imaging studies have shown reduced activation of sensorimotor cortex during active vs. passive movements (e.g., Jiang et al. 1991; Blakemore et al. 1998; Ackerley et al. 2012). In addition, because of its role in processing biological motion, the STS is also thought to be involved (Leube et al. 2003; Iacoboni 2005; Limanowski et al. 2018)
The sensory dimension of forward models leads to the topic of the sensory areas involved in action observation. A large body of research has shown that somatosensory cortex is activated in humans when acting or when observing another’s actions. In response to observation of touch, some studies have found activation in primary somatosensory cortex (S1) (Blakemore et al. 2005; Schaefer et al. 2009) others in secondary somatosensory cortex (S2) (Keysers et al. 2004; Del Vecchio et al. 2020), while others have found activation in both S1 and S2 (Ebisch et al. 2008). Some studies have failed to find significant activation in either S1 or S2 during action observation (Chan and Baker 2015; Sharma et al. 2018); however, as the location and extent of activation is dependent on the details of what is being observed (e.g., intentional touch vs. accidental touch, active vs. passive touch—Sharma et al. 2018) such null findings are perhaps due to choice of stimuli (Peled-Avron and Woolley 2022).
Limitations
The findings reported here are new and so the parameters need to be replicated and explored. In particular, there is evidence that vicarious activity in sensorimotor cortex caused by action observation is highly dependent on the details of the stimuli used (e.g., Sharma et al. 2018) and so it will be necessary to determine which features of the video stimuli are required to induce the effect.
While a sex-balanced sample would be more representative, the department where this research was conducted only has female students. However, research suggests that females show a stronger response to action observation (Cheng et al. 2008; Yang et al. 2009), and so the probability of finding the predicted effect may have been improved by testing females only (though, of course, this leaves open the question of how well these results would generalize to males).
Conclusions
Embodied cognition theorizes that to understand others’ actions we subconsciously simulate the actions we observe in our own motor system. The experiments reported here test whether these hypothesized simulations are carried out by the forward-model system, a system whose primary function is to simulate our own actions and their consequences in order to monitor our actions. As forward models induce sensory attenuation, if the forward-model system is used to understand others’ actions, then we should experience sensory attenuation when we observe others’ actions.
These experiments demonstrate that observing a hand performing active touching (moving to touch a ball) induces an attenuation of the perceived intensity of a touch in comparison with observing a hand being passively touched (remaining still while a ball rolls toward it and touches it). This finding supports the EEG results of Voisin et al. (2011) and supports the claim that observing an action engages the observer’s forward-model system. The forward models generate a prediction of the upcoming touch stimulus and, as is standard for forward-model sensory predictions, this prediction results in an attenuation of matching sensory signals. These experiments also replicate the established finding that increased attention to a touch event amplifies the perceived intensity of the touch (Ro et al. 2004; Johnson et al. 2006) and show that this sensory-amplification effect is significantly stronger than the sensory attenuation induced by watching active movement. Many experiments have not taken the amplification effect of action observation into account and this may explain why there have been conflicting results in the field. The results of these experiments provide strong support for the idea that action observation engages forward-model activity in the observer. This suggests that the subconscious simulations hypothesized by embodied cognition may be identified with the forward-model system.
Data and materials
The data and materials for all experiments are available at: osf.io/h9x8e.
Notes
N.B. The force was measured using a Boshi NK analog force gauge. Only the maximum force was measured to give a reference point for the range of forces involved in the experiment, the specific forces for each tap on each trial were not measured.
As detailed above because of the differences between Reference and Target, the experiment was designed to compare one pairing of conditions against its reverse. The 0 point is, therefore, unlikely to be a meaningful reference. Simply as part of data exploration, post-hoc t-tests were conducted comparing each of the two sensory attenuation conditions against 0. Neither was significant. Similarly, post-hoc t-tests were conducted comparing each of the four (sensory-amplification) conditions against 0. Only the conditions with Empty Target videos were significant after Bonferroni correction. Comparisons against 0 are unlikely to be meaningful and are reported here simply as part of data exploration.
Participants were free to repeat the Target video as often as necessary, so the number of repetitions of Reference and Target was not balanced; however, there were no statistically significant differences between conditions in number of repetitions.
As discussed above, 0 is unlikely to be a meaningful reference point. Simply as part of data exploration, post-hoc t-tests were conducted comparing each of the two sensory attenuation conditions against 0. Only the Active Reference—Passive Target condition was significant after Bonferroni correction (p = 0.0432). Similarly, post-hoc t-tests were conducted comparing each of the four sensory-amplification conditions against 0. All were significant after Bonferroni correction. Comparisons against 0 are unlikely to be meaningful and are reported here simply as part of data exploration.
Participants were free to repeat the Target video as often as necessary, so the number of repetitions of Reference and Target was not balanced; however, there were no statistically significant differences between conditions in number of repetitions.
References
Ackerley R, Hassan E, Curran A, Wessberg J, Olausson H, McGlone F (2012) An fMRI study on cortical responses during active self-touch and passive touch from others. Front Behav Neurosci 6:1–9
Aliu SO, Houde JF, Nagarajan SS (2009) Motor-induced suppression of the auditory cortex. J Cogn Neurosci 21(4):791–802
Avikainen S, Forss N, Hari R (2002) Modulated activation of the human SI and SII cortices during observation of hand actions. Neuroimage 15(3):640–646
Bäss P, Jacobsen T, Schröger E (2008) Suppression of the auditory N1 event-related potential component with unpredictable self-initiated tones: evidence for internal forward models with dynamic stimulation. Int J Psychophysiol 70(2):137–143
Blakemore S-J, Wolpert DM, Frith CD (1998) Central cancellation of self-produced tickle sensation. Nat Neurosci 1(7):635–40
Blakemore S-J, Frith CD, Wolpert DM (1999) Spatio-temporal prediction modulates the perception of self-produced stimuli. J Cogn Neurosci 11(5):551–559
Blakemore S-J, Bristow D, Bird G, Frith C, Ward J (2005) Somatosensory activations during the observation of touch and a case of vision-touch synaesthesia. Brain 128(7):1571–1583
Botvinick M, Cohen J (1998) Rubber hands ‘feel’ touch that eyes see. Nature 391(6669):756
Bridgeman B (2007) Efference copy and its limitations. Comput Biol Med 37(7):924–9
Bristow DJ (2006) Monitoring and predicting actions and their consequences. Ph.D., University College London
Buccino G, Binkofski F, Fink GR, Fadiga L, Fogassi L, Gallese V, Seitz RJ, Zilles K, Rizzolatti G, Freund H-J (2001) Action observation activates premotor and parietal areas in a somatotopic manner: an fMRI study. Eur J Neurosci 13(2):400–404
Burin D, Kilteni K, Rabuffetti M, Slater M, Pia L (2019) Body ownership increases the interference between observed and executed movements. PLoS One 14(1):1–16
Caramazza A, Anzellotti S, Strnad L, Lingnau A (2014) Embodied cognition and mirror neurons: a critical assessment. Annu Rev Neurosci 37:1–15
Champely S, Ekstrom C, Dalgaard P, Gill J, Weibelzahl S, Anandkumar A, Ford C, Volcic R (2018) Basic functions for power analysis. https://CRAN.R-project.org/package=pwr
Chan AW-Y, Baker CI (2015) Seeing is not feeling: posterior parietal but not somatosensory cortex engagement during touch observation. J Neurosci 35(4):1468–1480
Cheng Y, Lee P-L, Yang C-Y, Lin C-P, Hung D, Decety J (2008) Gender differences in the Mu rhythm of the human mirror-neuron system. PLoS One 3(5):e2113
Cohen J (1988) Statistical power analysis for the behavioral sciences, 2nd edn. Lawrence Erlbaum Associates
Cousineau D (2005) Confidence intervals in within-subject designs: a simpler solution to Loftus and Masson’s method. Tutur Quant Methods Psychol 1(1):42–45
Del Vecchio M, Caruana F, Sartori I, Pelliccia V, Zauli FM, Lo Russo G, Rizzolatti G, Avanzini P (2020) Action execution and action observation elicit mirror responses with the same temporal profile in human SII. Commun Biol 3(1):1–8
Eads J, Lorimer Moseley G, Hillier S (2015) Non-informative vision enhances tactile acuity: a systematic review and meta-analysis. Neuropsychologia 75:179–185
Ebisch SJ, Perrucci MG, Ferretti A, Del Gratta C, Romani GL, Gallese V (2008) The sense of touch: embodied simulation in a visuotactile mirroring mechanism for observed animate or inanimate touch. J Cogn Neurosci 20(9):1611–1623
Eliades SJ, Wang X (2004) The role of auditory-vocal interaction in hearing. In: Pressnitzer D, de Cheveigné A, McAdams S, Collet L (eds) Auditory signal processing: physiology, psychoacoustics, and models. Springer, New York, pp 292–298
Enticott PG, Kennedy HA, Bradshaw JL, Rinehart NJ, Fitzgerald PB (2010) Understanding mirror neurons: evidence for enhanced corticospinal excitability during the observation of transitive but not intransitive hand gestures. Neuropsychologia 48(9):2675–2680
Enticott PG, Kennedy HA, Bradshaw JL, Rinehart NJ, Fitzgerald PB (2011) Motor corticospinal excitability during the observation of interactive hand gestures. Brain Res Bull 85(3–4):89–95
Fadiga L, Fogassi L, Pavesi G, Rizzolatti G (1995) Motor facilitation during action observation: a magnetic stimulation study. J Neurophysiol 73(6):2608–2611
Fogassi L, Simone L (2013) The Mirror System in Monkeys and Humans and its Possible Motor-Based Functions. In: Richardson MJ, Riley MA, Shockley K (eds) Progress in motor control, advances in experimental medicine and biology. Springer, New York, pp 87–110
Gallese V (2005) Embodied simulation: from neurons to phenomenal experience. Phenomenol Cogn Sci 4(1):23–48
Gallese V, Fadiga L, Fogassi L, Rizzolatti G (1996) Action recognition in the premotor cortex. Brain 119(2):593–609
Goldinger SD, Papesh MH, Barnhart AS, Hansen WA, Hout MC (2016) The poverty of embodied cognition. Psychon Bull Rev 23(4):959–978
Greenlee JDW, Jackson AW, Chen F, Larson CR, Oya H, Kawasaki H, Chen H, Howard MA (2011) Human auditory cortical activation during self-vocalization. PLoS One 6(3):e14744
Grush R (2004) The emulation theory of representation: motor control, imagery, and perception. Behav Brain Sci 27(3):377–96 (discussion 396–442)
Haggard P, Whitford B (2004) Supplementary motor area provides an efferent signal for sensory suppression. Cogn Brain Res 19(1):52–58
Haggard P, Aschersleben G, Gehrke J, Prinz W (2002) Action, binding, and awareness. In: Prinz W, Hommel B (eds) Common mechanisms in perception and action: attention and performance, vol 19. Oxford University Press, pp 266–285
Harrison AW, Mannion DJ, Jack BN, Griffiths O, Hughes G, Whitford TJ (2021) Sensory attenuation is modulated by the contrasting effects of predictability and control. Neuroimage 237:118103
Heyes C, Catmur C (2022) What happened to mirror neurons? Perspect Psychol Sci 17(1):153–168
Hickok G (2014) The myth of mirror neurons: the real neuroscience of communication and cognition. W. W. Norton & Company, New York
Hickok G, Houde J, Rong F (2011) Sensorimotor integration in speech processing: computational basis and neural organization. Neuron 69(3):407–422
Iacoboni M (2005) Understanding others: mitation, language, and empathy. In: Hurley S, Chater N (eds) Perspectives on imitation: from neuroscience to social science: Vol. 1: mechanisms of imitation and imitation in animals. MIT Press, Cambridge, pp 77–99
Ishida H, Nakajima K, Inase M, Murata A (2010) Shared mapping of own and others’ bodies in visuotactile bimodal area of monkey parietal cortex. J Cogn Neurosci 22(1):83–96
Ito M (2008) Control of mental activities by internal models in the cerebellum. Nat Rev Neurosci 9(4):304–13
Jiang W, Chapman C, Lamarre Y (1991) Modulation of the cutaneous responsiveness of neurones in the primary somatosensory cortex during conditioned arm movements in the monkey. Exp Brain Res 84(2):342–54
Johnson RM, Burton PC, Ro T (2006) Visually induced feelings of touch. Brain Res 1073–1074:398–406
Juravle G, Gordon B, Charles S (2017) Tactile suppression in goal-directed movement. Psychon Bull Rev 24:1060–1076
Keysers C, Wicker B, Gazzola V, Anton J-L, Fogassi L, Gallese V (2004) A touching sight: SII/PV activation during the observation and experience of touch. Neuron 42(2):335–346
Keysers C, Paracampo R, Gazzola V (2018) What neuromodulation and Lesion studies tell us about the function of the mirror neuron system and embodied cognition. Curr Opin Psychol 24:35–40
Kilner JM, Lemon RN (2013) What we know currently about mirror neurons. Curr Biol 23(23):R1057–R1062
Kilner JM, Friston KJ, Frith CD (2007) Predictive coding: an account of the mirror neuron system. Cogn Process 8(3):159–166
Kilteni K, Ehrsson HH (2017) Body ownership determines the attenuation of self-generated tactile sensations. Proc Natl Acad Sci 114(31):8426–8431
Kilteni K, Engeler P, Boberg I, Maurex L, Ehrsson HH (2021) No evidence for somatosensory attenuation during action observation of self-touch. Eur J Neurosci 54(7):6422–6444
Lawrence MA (2013) ez: easy analysis and visualization of factorial experiments. R package version 4.2-2
Leube DT, Knoblich G, Erb M, Grodd W, Kirchera TT (2003) The neural correlates of perceiving one’s own movements. Neuroimage 20(4):2084–2090
Liberman AM, Mattingly IG (1985) The motor theory of speech perception revised. Cognition 21(1):1–36
Limanowski J, Sarasso P, Blankenburg F (2018) Different responses of the right superior temporal sulcus to visual movement feedback during self-generated vs. externally generated hand movements. Eur J Neurosci 47(4):314–320
Mathew J, Eusebio A, Danion F (2017) Limited Contribution of primary motor cortex in eye-hand coordination: a TMS study. J Neurosci 37(40):9730–9740
Miall RC (2003) Connecting mirror neurons and forward models. NeuroReport 14(17):2135–7
Miall RC, Weir DJ, Wolpert DM, Stein JF (1993) Is the cerebellum a smith predictor? J Mot Behav 25(3):203–216
Molenberghs P, Cunnington R, Mattingley JB (2012) Brain regions with mirror properties: a meta-analysis of 125 human fMRI studies. Neurosci Biobehav Rev 36(1):341–349
Morey RD (2008) Confidence intervals from normalized data: a correction to Cousineau (2005). Tutor Quant Methods Psychol 4(2):61–64
Mukamel R, Ekstrom AD, Kaplan J, Iacoboni M, Fried I (2010) Single-neuron responses in humans during execution and observation of actions. Curr Biol 20(8):750–756
Palmer CE, Bunday KL, Davare M, Kilner JM (2016) A causal role for primary motor cortex in perception of observed actions. J Cogn Neurosci 28(12):2021–2029
Peirce JW (2007) PsychoPy—psychophysics software in Python. J Neurosci Methods 162(1–2):8–13
Peled-Avron L, Woolley JD (2022) Understanding others through observed touch: neural correlates, developmental aspects, and psychopathology. Curr Opin Behav Sci 43:152–158
Pellegrino F, Fadiga L, Fogassi L, Gallese V, Rizzolatti G (1992) Understanding motor events: a neurophysiological study. Exp Brain Res 91:176–180
Prinz W (1987) Ideo-motor action. In: Heuer H, Sanders AF (eds) Perspectives on perception and action. Erlbaum, Hillsdale, pp 47–76
Pulvermüller F, Huss M, Kherif F, del Prado Moscoso, Martin F, Hauk O, Shtyrov Y (2006) Motor cortex maps articulatory features of speech sounds. Proc Natl Acad Sci USA 103(20):7865–70
Pyasik M, Ronga I, Burin D, Salatino A, Sarasso P, Garbarini F, Ricci R, Pia L (2021) I’m a believer: Illusory self-generated touch elicits sensory attenuation and somatosensory evoked potentials similar to the real self-touch. Neuroimage 229:117727
R Core Team (2014) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna
Ro T, Wallace R, Hagedorn J, Farne A, Pienkos E (2004) Visual enhancing of tactile perception in the posterior parietal cortex. J Cogn Neurosci 16(1):24–30
Rossi S, Tecchio F, Pasqualetti P, Ulivelli M, Pizzella V, Romani GL, Passero S, Battistini N, Rossini PM (2002) Somatosensory processing during movement observation in humans. Clin Neurophysiol 113(1):16–24
Roy JE, Cullen KE (2004) Dissociating self-generated from passively applied head motion: neural mechanisms in the vestibular nuclei. J Neurosci 24(9):2102–11
Sato A (2009) Both motor prediction and conceptual congruency between preview and action-effect contribute to explicit judgment of agency. Cognition 110(1):74–83
Schaefer M, Xu B, Flor H, Cohen LG (2009) Effects of different viewing perspectives on somatosensory activations during observation of touch. Hum Brain Mapp 30(9):2722–2730
Schafer EWP, Marcus MM (1973) Self-stimulation alters human sensory brain responses. Science 181(95):175–177
Schubotz RI (2007) Prediction of external events with our motor system: towards a new framework. Trends Cogn Sci 11(5):211–218
Schwartz J-l, Sato M, Fadiga L (2008) The common language of speech perception and action: a neurocognitive perspective. Revue française de linguistique appliquée 13:9–22
Scott M (2013) Corollary discharge provides the sensory content of inner speech. Psychol Sci 24(9):1824–1830
Scott M (2016) Speech imagery recalibrates speech-perception boundaries. Atten Percept Psychophys 78(5):1496–1511
Scott M, Chiu C (2021) Temporal binding and agency under startle. Exp Brain Res 239(1):289–300
Serino A, Haggard P (2010) Touch and the body. Neurosci Biobehav Rev 34(2):224–236
Serino A, Pizzoferrato F, Ladavas E (2008) Viewing a face (Especially One’s Own Face) being touched enhances tactile perception on the face. Psychol Sci 19(5):434–438
Serino A, Giovagnoli G, Làdavas E (2009) I feel what you feel if you are similar to me. PLoS One 4(3):e4930
Sharma S, Fiave PA, Nelissen K (2018) Functional MRI responses to passive, active, and observed touch in somatosensory and insular cortices of the macaque monkey. J Neurosci 38(15):3689–3707
Shepherd SV, Klein JT, Deaner RO, Platt ML (2009) Mirroring of attention by neurons in macaque parietal cortex. Proc Natl Acad Sci 106(23):9489–9494
Shergill SS, Bays PM, Frith CD, Wolpert DM (2003) Two eyes for an eye: the neuroscience of force escalation. Science 301(5630):187
Skipper JI, van Wassenhove V, Nusbaum HC, Small SL (2007) Hearing lips and seeing voices: how cortical areas supporting speech production mediate audiovisual speech perception. Cereb Cortex (New York, N.Y. : 1991) 17(10):2387–99
Spaulding S (2018) How we understand others: philosophy and social cognition. Routledge, London
Sperry RW (1950) Neural basis of the spontaneous optokinetic response produced by visual inversion. J Comp Physiol Psychol 43(6):482–489
Strafella AP, Paus T (2000) Modulation of cortical excitability during action observation: a transcranial magnetic stimulation study. NeuroReport 11(10):2289–2292
Sylvester R, Haynes J-D, Rees G (2005) Saccades differentially modulate human LGN and V1 responses in the presence and absence of visual stimulation. Current 15:37–41
Takei T, Lomber SG, Cook DJ, Scott SH (2021) Transient deactivation of dorsal premotor cortex or parietal area 5 impairs feedback control of the limb in macaques. Curr Biol 31(7):1476–1487
Thomas R, Sink J, Haggard P (2013) Sensory effects of action observation: Evidence for perceptual enhancement driven by sensory rather than motor simulation. Exp Psychol 60(5):335–346
Torchiano M (2017) Efficient effect size computation. http://cran.r-project.org/web/packages/effsize/index.html
Vastano R, Inuggi A, Vargas CD, Baud-Bovy G, Jacono M, Pozzo T (2016) Tactile perception during action observation. Exp Brain Res 234(9):2585–2594
Voisin JIA, Rodrigues EC, Hétu S, Jackson PL, Vargas CD, Malouin F, Chapman CE, Mercier C (2011) Modulation of the response to a somatosensory stimulation of the hand during the observation of manual actions. Exp Brain Res 208(1):11–19
Von Holst E (1954) Relations between the central nervous system and the peripheral organs. Br J Anim Behav 2(3):89–94
Voss M, Ingram JN, Haggard P, Wolpert DM (2006) Sensorimotor attenuation by central motor command signals in the absence of movement. Nat Neurosci 9(1):26–27
Weiskrantz L, Elliott J, Darlington C (1971) Preliminary observations on tickling oneself. Nature 230:598–599
Welniarz Q, Worbe Y, Gallea C (2021) The forward model: a unifying theory for the role of the cerebellum in motor control and sense of agency. Front Syst Neurosci 15:644059
Wolpert DM, Flanagan JR (2001) Motor prediction. Curr Biol 11(18):729–732
Wolpert DM, Miall RC, Kawato M (1998) Internal models in the cerebellum. Trends Cogn Sci 2(9):338–347
Wolpert DM, Doya K, Kawato M (2003) A unifying computational framework for motor control and social interaction. Philos Trans R Soc Lond Ser B Biol Sci 358(1431):593–602
Yang C-Y, Decety J, Lee S, Chen C, Cheng Y (2009) Gender differences in the mu rhythm during empathy for pain: an electroencephalographic study. Brain Res 1251:176–184
Yeung HH, Scott M (2021) Postural control of the vocal tract affects auditory speech perception. J Exp Psychol Gen 150(5):983–995
Acknowledgements
This research was supported by UAEU Grant 31h076 (College of Humanities and Social Sciences) to Mark Scott and Ali Idrissi. I would like to thank my Research Assistant, Souad Al Helou.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author states that there is no conflict of interest.
Additional information
Communicated by Francesca Frassinetti.
This research was supported by start-up research grant 31h060 from UAEU.
Formerly at United Arab Emirates University, Al Ain, United Arab Emirates.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Scott, M. Sensory attenuation from action observation. Exp Brain Res 240, 2923–2937 (2022). https://doi.org/10.1007/s00221-022-06460-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-022-06460-1