
Abstract
Introduction and hypothesis
The Prolapse/Incontinence Sexual Questionnaire–International Urogynecology Association (IUGA) Revised (PISQ-IR) measures sexual function in women with pelvic floor disorders (PFDs) yet is unwieldy, with six individual subscale scores for sexually active women and four for women who are not. We hypothesized that a valid and responsive summary score could be created for the PISQ-IR.
Methods
Item response data from participating women who completed a revised version of the PISQ-IR at three clinical sites were used to generate item weights using a magnitude estimation (ME) and Q-sort (Q) approaches. Item weights were applied to data from the original PISQ-IR validation to generate summary scores. Correlation and factor analysis methods were used to evaluate validity and responsiveness of summary scores.
Results
Weighted and nonweighted summary scores for the sexually active PISQ-IR demonstrated good criterion validity with condition-specific measures: Incontinence Severity Index = 0.12, 0.11, 0.11; Pelvic Floor Distress Inventory-20 = 0.39, 0.39, 0.12; Epidemiology of Prolapse and Incontinence Questionnaire-Q35 = 0.26 0,.25, 0.40); Female Sexual Functioning Index subscale total score = 0.72, 0.75, 0.72 for nonweighted, ME, and Q summary scores, respectively. Responsiveness evaluation showed weighted and nonweighted summary scores detected moderate effect sizes (Cohen’s d > 0.5). Weighted items for those NSA demonstrated significant floor effects and did not meet criterion validity.
Conclusions
A PISQ-IR summary score for use with sexually active women, nonweighted or calculated with ME or Q item weights, is a valid and reliable measure for clinical use. The summary scores provide value for assesing clinical treatment of pelvic floor disorders.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
To evaluate the impact of pelvic floor disorders (PFDs) and their treatment options in relation to women’s sexual function, several questionnaires are commonly used. The Pelvic Organ Prolapse/Incontinence Sexual Questionnaire–International Urogynecologic Association (IUGA) Revised (PISQ-IR) was designed to improve upon prior sexual function questionnaires by including women who experience anal incontinence and evaluate potential PFD impact on women who are not sexually active (NSA). Since completion of this work in 2012, 25 translations and validations have been conducted across 25 cultural populations in 20 different languages (http://www.iuga.org/?page=pisqir).
Despite benefits of the PISQ-IR over prior questionnaires, the current scoring is cumbersome and unwieldy in clinical practice. For women who are SA, it contains 21 items covering six domains: arousal/orgasm, partner related, condition specific, global quality rating, condition impact, and desire. For women who are not SA, it contains 12 items covering four domains: condition specific, partner related, global quality, and condition impact. Each domain receives a separate score [1]. One approach to improving its clinical utility with a single summary score rather than individual subscale scores. Questionnaire scoring is complex; while summary scores may be desirable from the perspective of a clinician or researcher who is reporting changes in sexual function as one of many measures of changes in quality of life (QoL), a simple summary score may not be adequately representative of data collected with the entire instrument. For example, not all questions (or domains) may be equally important to patients, and questions (or domains) of more importance may need to be weighted more heavily so that their importance is represented.
We aimed to develop an algorithm to generate a single summary score for each of the two PISQ-IR scales: SA and NSA. This would simplify its in clinical practice and improve its clinical relevance and utility. We hypothesized that a valid and responsive single summary score could be created for both scales.
Materials and methods
This study was conducted in two phases: development of weights to apply to the original PISQ-IR items to generate a summary score, and evaluation of the psychometric properties of a summary score. The first phase, development of question item weights, used two different weighting methodologies: magnitude estimation (ME) and Q-sort (Q). Both ME and Q facilitates identification of the relative importance of each item to the understanding of global sexual function as measured by the PISQ-IR.
Phase 1
Sample and data collection
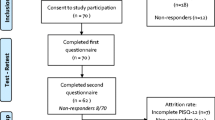
Women seeking care for PFDs were recruited from two institutions: the University of New Mexico, and TriHealth, Inc. Institutional Review Board approval was obtained by both sites, as well as at the University of Minnesota, the data coordination site. All women signed informed consent prior to participation. Eligible participants who could read and understand English and were ≥18 years seeking care for PFDs including urinary incontinence (UI) and/or anal incontinence (AI) and/or pelvic organ prolapse (POP). Exclusion criteria were a diagnosis of vulvodynia, painful bladder syndrome, or chronic pelvic pain (defined as pelvic pain for >6 months) as determined by the consenting physician. Both SA and NSA women were evaluated. Sequential clinical enrollment was used, with eligible women identified by one of the study investigators. The sample of women who provided response data for the ME approach completed a self-administered paper survey for data collection with a drop-off/mail-back method with the option to complete the survey in the clinic. The sample of women who provided response data for the Q approach used an online sorting program, completed in the clinic, with an option to schedule from other locations using an online interface.
ME requires using response categories for each question item that reflect the magnitude of the importance of each item to the respondent. To achieve this, ME used a 7-point item-response format. Women were asked to identify the importance to their sexual function of each individual PISQ-IR item using a numeric rating scale (e.g., 1 = not important at all to 7 = extremely important) [2]. The content and meaning of the PISQ-IR item stems were not changed, although minor grammatical modifications were required in a few instances, e.g., “Due to UI/FI/POP, how frustrated are you with your sex life?” was reworded as “How important is the frustration caused by UI/DI/POP, to understanding your overall sex life?” Six of the 12 NSA scale items and three of the 12 SA scale items use a semantic differential format for questions identifying respondents’ reasons for not being SA. Semantic differential is itself a form of ME. Therefore, the response option format from the original PISQ-IR were retained for these items for the development of ME item weights.
The second approach employed to generate item weights was Q. In contrast to ME, Q is based on a comparative ranking approach [3, 4], with women ranking the importance of each of the original PISQ-IR scale items relative to other scale items.
Analysis
The development of item weights for scoring typically occurs in conjunction with the initial scale validation such that the study is powered according to the needs of validation (psychometric analysis) [5]. The determination of adequate sample size in such instances is dependent on multiple criteria primarily related to the associated psychometric approach. However, for developing item weight for generating a summary score algorithm for an existing validated instrument, the notion of power does not apply. Power analysis is used to determine a sample size that is needed to detect a significant difference using specific statistical tests. The development of item weights does not require detecting a statistical difference. Standard R methodological (conventional factor analysis) approaches use representative sampling methods to ensure representation of the target population units, i.e., women with PFDs. The target population units for Q methods are the known viewpoints represented in the Q set—in this case, all PISQ-IR items. Therefore, it is usual using Q methods for the number of respondents or completed sorts to be fewer than the number of statements ranked. Respondents’ Q are subject to correlation and factor analysis techniques. Q are expected to group together with similar sorts into factors. The group of individual rankings are factor analyzed using Varimax rotation, and a single simple factor solution is forced. Item weights are calculated based on item factor scores, standardized to z-scores [6]. Q weights were developed using PCQ for Windows. Development of ME weights was conducted using SAS 9.4®.
Phase 2
Sample data
Phase 2 involved applying MR and Q weights, developed in Phase 1, to the individual scale item responses collected in the original validation of the PISQ-IR. Briefly, data from this cross-cultural English-language validation included survey and clinical data from 589 women recruited from 12 sites across the United States (n = 427) and five in the United Kingdom (n = 162). Participants completed self-administered baseline surveys. The study had a 67% response rate and included 188 women who reported as not being SA and 401 women who were. Inclusion/exclusion criteria were identical to those used in Phase 1. All participating sites obtained institutional review board approval, and all women gave written informed consent. In addition to completion of the PISQ-IR, women also completed the Incontinence Severity Index (ISI), Pelvic Floor Distress Inventory (PFDI-20), the Female Sexual Functioning Index (FSFI), and a single question from the Epidemiology of Prolapse and Incontinence Questionnaire (EPIQ), which is used to screen for POP symptoms and underwent Pelvic Organ Prolapse Quantification scoring system (POP-Q) measurements and assessment of pelvic floor muscle strength. Respondents also provided basic sociodemographic information. Women completed baseline and 6-month survey data. A complete description of the data collection protocol is reported elsewhere [1].
Analysis
The basic rule of thumb in psychometric analysis used with scale development and validation is that ten subjects per item are needed for analyses [7]. The sample size for PISQ-IR validation (n = 589) was more than adequate for the final 42-item pool selected for evaluation. The responsiveness and test–retest components of the PISQ-IR validation was based on an alpha of 0.05, a targeted power of 0.80, and an assumed change of 20% from baseline to follow-up. This phase of the study—validation of a summary score—used the sample that was used to validate the original PISQ-IR. The mean of each weighted item was calculated, and summary scores for both ME- and Q-weighted items were generated as the mean of their combined means. As noted above, the nonweighted summary score was also evaluated, which is equivalent to assigning a weight of 1 to each item. Distributional properties of weighted items were evaluated, with specific focus on item variance that could indicate ceiling or floor effects (majority of responses as extreme high or low values) and regression to the mean (clustering of most responses around midrange values).
Evaluation of ME- and Q- weighted summary scores replicated criterion validity and responsiveness evaluations from the original PISQ-IR validation using correlation analysis. Criterion measures include self-reported change in anatomical/physiological indicators (e.g., PFDI, ISI, EPIQ) and the FSFI (ratings of global change in health, POP, and/or UI/FI and sexual desire and activity over the past 6 months). Responsiveness of summary scores was evaluated using correlation of the change in PISQ-IR measures relative to change in PFDI, ISI, EPIQ (Q 35 only), and the FSFI. Change for PISQ-IR and criteria measures was assessed 6 months following initial data collection. Change is defined as the difference in score between baseline and 6-month follow-up values. Responsiveness, or sensitivity to detect change, was evaluated using two distribution-based indices: Cohen’s d and standard response mean (SRM). The following effect size (ES) magnitude thresholds were used as criteria for both ES indices :< 0.20 = trivial, ≥ 0.20 to < 0.50 = small, ≥ 0.50 < .80 = medium, and ≥0.80 = large [8].Validation and responsiveness analyses were performed on each PISQ-IR subscale and total summary scale scores: nonweighted, ME weighted, and Q weighted.
Where applicable, standardized terms for PFDs were used [9]. Analysis of all weighted items was conducted using SAS 9.4®.
Results
Phase 1
A total of 141 women completed surveys for the ME-weighted sample, with73 women who self-reported as SA, 46 as not SA, and 22 who did not identify activity status. All eligible women recruited for the Q sample completed the Q in clinic. A total of 31 were completed by women who self-reported as SA and 32 as NSA. Results from each scale are presented separately. Patient characteristics of the original PISQ-IR, ME, and Q samples (Table 1) are similar, except for education, with ME and Q samples indicating higher educational attainment than the original PISQ-IR validation sample.
Sexually active
The item distributions for ME- and Q-weighted items of the PISQ-IR scale for women who are SA demonstrate good distributional properties, i.e., no ceiling effect and a small chance of some regression (Fig. 1). Distributions support the use of the data for evaluating a summary score.

Floor effects demonstrated by item distributions with magnitude estimation (ME) weights: item mean and standard deviation
Phase 2
Table 2 presents the criterion validity evaluation using correlations of summary scores for both weighting approaches and the nonweighted summary score for SA women. Of note is the similarity between the nonweighted ME-weighted, and Q-weighted scores. In all instances, the summary score demonstrated significant relationships with both condition-related measures and the FSFI. Except for the PFDI-20 and the EPIQ Q 35, comparison of summary measures to individual subscales in the PISQ-IR show minor variance between original subscale correlations and summary scores reported in the PISQ-IR validation paper. However, summary scores demonstrate the same criterion validity, with the Q score demonstrating a moderately improved relationship with the EPIQ (Q 35) and a moderately worsened relationship with the PFDI than did subscale scores.
Table 3 presents the responsiveness evaluation based on the correlation of change in criterion validity measures with change in each PISQ-IR subscale and all three summary scores. Responsiveness for nonspecific treatment-related change show both Q- and ME-weighted summary scores detected moderate ES, a sensitivity comparable with the sensitivity to change of the PISQ-IR subscale scores. In general, the change in pre- and posttreatment summary scores and in condition-related measures demonstrate stronger correlations than individual subscales, indicating the value of the summary score when evaluating condition severity on self-reported condition measures.
Effect size, often thought of as a responsiveness measure, is an indicator of meaningful or relevant difference: the amount of change in scores or the magnitude of change within and between groups. It is an indicator of clinical utility. Weighted and nonweighted summary scores for all women demonstrate small to medium ES for both ES indices (Table 4). The nonweighted summary score demonstrated greater ES than do either of the weighted summary scores.
Not sexually active
Preliminary evaluation of weighted ME item distributions revealed four of the six items from the NSA scale, with ≥50% of responses in the lowest response category (not important at all) and 49% in the remaining two items falling into the lowest response category (Fig. 1). These items are also ranked as unimportant by the NSA Q. These significant floor effects indicate the items are not important to respondent understanding or appraisal of their sexual life. Items from the NSA PISQ-IR scale not weighted by ME, reasons for sexual inactivity including lack of interest, and satisfaction with being NSA are the most highly ranked items in the Q-weight sorts. These results are suggestive of a lack of practical significance in consideration of the use of a summary score for the NSA PISQ-IR scale.
Discussion
A PISQ-IR summary score for use with SA women—nonweighted or calculated with ME or Q item weights—is a valid and reliable measure for clinical use. A PISQ-IR summary score in NSA women did not meet criterion to be considered a valid measure.
Transition to a summary score using multiple domain-specific subscale scores for a multidimensional scale such as the PISQ-IR requires three fundamental considerations: the relative importance of each scale item to the understanding of overall sexual function; the extent to which a summary score retains the fundamental validity and responsiveness demonstrated by each subscale; the most efficient means of calculating the summary score. Criteria for all considerations was met by the summary score for SA women. Summary scores would provide value when assessing clinical treatment of UI/FI/POP.
While ME is a well-established method for deriving relative item weights, one drawback is that respondents rate items individually rather than comparatively, potentially obscuring important differences between items. Additionally, an ME approach invokes a potential for emergence of ceiling effects or a regression to the mean [10, 11]. Ceiling effects, resulting from acquiescence or social desirability in response, as well as regression to the mean, are risks that are present when respondents are presented with a large number of consecutive question items that use the same response rating format. Such a format imposes a greater than desirable respondent burden. Item responses demonstrating a floor effect, resulting from low (negative) ratings, are also potentially problematic. While floor effects are less susceptible to known sources of error in survey response [12, 13], they are considered an indicator of an item’s lack of relevance rather than a function of item response formation. To overcome these weaknesses in an ME approach, Q was employed as a second weighting approach.
Evaluating distributional properties of weighted items for the NSA scale, addressing the first consideration, indicate floor effects (majority of responses as extreme low values), suggesting continued difficulty in measuring sexual function for women who do not consider themselves to be SA. Responsiveness evaluation of summary scores suggests that while the scores function moderately well, their use may hide potentially important relationships relative to specific aspects of sexual function. Therefore, for use with outcomes research or even clinical-trial research, the summary score is likely to hide specific effects of a given intervention. Unless an intervention is curative for all PFDs, important effects—either positive or negative—are likely to go undetected. Individual consideration of research study outcomes is recommended when considering the use of summary versus individual scale scores for research purposes.
We recommend a mean calculation be used for the summary score. While one of two methods are recommended to score the PISQ-IR—either a mean calculation or a transformed sum—the goal of efficiency in calculation of a summary score is best met my using a mean calculation rather than a transformed sum. As indicated in our earlier work [14], there is very little variation between final scores generated by the two scoring approaches.
Further consideration of efficiency supports preferred use of the nonweighted summary score rather than either weighted scores, each of which require the additional step of weight application prior to scoring. The summary score calculation for the SA scale should use a mean calculation by first summing the valid responses to items in the scale and then dividing the result by the number of items with valid responses. These findings are based on the assumption that the rules for generating a subscale score for the PISQ-IR still hold, i.e., a valid response is provided for at least half the items of the SA scale. Missing values for an items should not be imputed. Prior to calculation of the mean summary score, items 11, 14a, 14b, 16, 17, 18, 19a, 19b, and 19c are reversed scored. Step-by-step scoring instructions are provided in Appendix A.
Differences in educational attainment between weighting samples and the original PISQ-IR study sample is likely attributable due to the ME and Q sample being recruited exclusively from the United States, whereas the original validation study included women recruited from the UK. Educational attainment was not found to be a factor in original PISQ-IR scale structure, minimizing any concern about the difference in study samples.
Distributional properties of scale items for NSA women, both weighted and nonweighted, support the need for further evaluation of understanding the role of PFDs for this population. Data from this study suggest the primary factor associated with lack of sexual activity for women with PFDs is lack of interest and that those women are satisfied with their NSA status; thus, other condition-related factors are not important. Scale development and validation is based on correlational analysis, which limits evaluation of any causative role of PFDs on women’s sexual activity status. Our earlier work evaluating scale responsiveness to treatment for PFD found no change from NSA to SA status among women who experienced some improvement from treatment [1]. While this finding is important, the study was not designed or powered to determine causative influences; however, a study designed to evaluate the causal impact of PFDs on women’s sexual activity status would be useful.
References
Rogers RG, Rockwood TH, Constantine ML, Thakar R, Kammerer-Doak DN, Pauls RN, et al. A new measure of sexual function in women with pelvic floor disorders (PFD): the pelvic organ prolapse/incontinence sexual questionnaire, IUGA-revised (PISQ-IR). Int Urogynecol J Pelvic Floor Dysfunct. 2013;24(7):1091–103.
Lodge M. Magnitude scaling, quantitative measurement of opinions. Beverly Hills: Sage Publications; 1981.
Brown SR. Political subjectivity: applications of Q methodology in political science. New Haven: Yale University Press; 1980.
Watts S, Stenner P. Doing Q methodological research: theory, method and interpretation. London: Singapore Sage Publications; 2012.
Hersen M. Comprehensive handbook of psychological assessment, behavioral assessment. Hokoben: Wiley; 2004.
McKeown B, Thomas D. Q methodology. Series 66: quantitative applications in the social sciences. Thousand Oaks: Sage Publications; 1988.
Pett MA, Lackey NR, Sullivan JJ. Making sense of factor analysis: the use of factor analysis for instrument development in health care research. Thousand Oaks: Sage Publications; 2003.
Cohen J. Statistical power analysis for the behavioral science. New York: Academic Press; 1977.
Haylen BT, de Ridder D, Freeman RM, Swift SE, Berghmans B, Lee J, et al. An international urogynecologic association (IUGA)/international continence society (ICS) joint report on the terminology for female pelvic floor dysfunction. Int Urogynecol J. 2010;21:5–26.
Campbell DT, Russo MJ. Social measurement. Thousand Oaks: Sage Publications Inc; 2001.
Tversky A, Shafir E. Preference, belief, and similarity: selected writings. Cambridge: MIT Press; 2004.
Schwarz N, Bienias J. What mediates the impact of response alternatives on frequency reports of mundane behaviors? Appl Cogn Psychol. 2006;4(1):61–72.
Schwarz N, Sudman S. Context effects in social and psychological research. New York: Springer-Verlag; 1992.
Rockwood TH, Constantine ML, Adegoke O, Rogers RG, McDermott E, Davila GW, et al. The PISQ-IR: considerations in scale scoring and development. Int Urogynecol J. 2013;24(7):1105–22.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
Dr. Rogers has received paid travel expenses or honoraria from UptoDate, ABOG, AUGS, and IUGA. He is on the Board of ABOG, AUGS, and IUGA.
Funding statement
No funding was received for this study.
Additional information
This work was presented as an oral poster at the American Urogynecologic Society annual meeting, 29 September, 2016, Denver, CO, USA.
Electronic supplementary material
ESM 1
(DOCX 15 kb)
Rights and permissions
About this article

Cite this article
Constantine, M.L., Pauls, R.N., Rogers, R.R. et al. Validation of a single summary score for the Prolapse/Incontinence Sexual Questionnaire–IUGA revised (PISQ-IR). Int Urogynecol J 28, 1901–1907 (2017). https://doi.org/10.1007/s00192-017-3373-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00192-017-3373-9