
Abstract
This study presents an innovative approach to predicting the quality of finished parts in top milling processes by integrating robust parameter design with artificial intelligence techniques. A central composite design was used to combine controllable variables (cutting speed, tooth advance, milled width, and cutting depth) with noise variables (tool flank wear, fluid flow, and cantilevered length). Duplex stainless steel was milled under each experimental setup, and roughness data were collected. These data were used to train three machine learning models: random forest, decision tree, and support vector machine. The models predicted surface roughness, and their predictions were validated through experimental tests. The root means square error values were 0.031 for the random forest, 0.038 for the decision tree, and 0.066 for the support vector machine, indicating that the random forest model performed the best. This innovative study highlights the importance of including noise variables along with controllable factors in machine learning models, significantly improving prediction accuracy and making them more reflective of real-world results. Including these variables is crucial, as neglecting them can lead to inaccurate predictions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Duplex stainless steels are widely used in various industries due to their balanced combination of ferrite and austenite, giving them desirable properties such as ductility, toughness, and resistance to stress corrosion [24]. However, machining these alloys is challenging due to their low machinability, which results in problems such as crunching, low thermal conductivity, and high strength, leading to tool wear and compromise of workpiece integrity. These stainless-steel alloys are widely used in various industrial fields such as automotive, aerospace, medical, chemical, and petrochemical [37].
Milling is a subtractive machining process that uses a rotating tool to cut flat surfaces. There are two main milling methods: up milling and down milling. In down milling, the cutting tool and the workpiece rotate in the same direction, which eliminates the possibility of chatter, as the tool’s teeth cut into the workpiece and deposit the cut chips behind the cutter. The chip thickness starts at its maximum and decreases as the cut progresses. Due to the complexity of machining duplex stainless steels, down milling methods often do not provide the required level of finish. CNC machining (up milling) stands out as a superior alternative, offering much higher surface quality and finish compared to traditional methods and is widely used in modern industry for producing mechanical parts with high precision and quality [26].
In the context of milling, surface quality monitoring is essential due to the significant investment of time and money in this process. The average surface roughness, measured by the Ra parameter, plays a crucial role in the esthetics of the products, as well as in the resistance to corrosion, fatigue, and tribological properties. The Ra value is influenced by several factors, such as feed rate, cutting speed, cutting depth, tool geometry, tool wear, temperature, and false edge formation.
There has been a growing interest in predicting surface roughness through artificial intelligence techniques, as this would bring significant benefits to the industry, including reducing waste, production costs, and increasing accuracy [22]. Recent studies have indicated that the application of machine learning techniques has demonstrated high capabilities to make accurate predictions as to surface roughness during the milling process [19].
Pimenov et al. [28] tested different machine learning models, such as random forest, standard multilayer perceptron (MLP), decision trees, and radial-based functions, for real-time prediction of surface roughness deviations from faceting machining processes. The results show that the random forest has the highest comparative precision followed by the decision trees, exhibiting higher precision than the standard MLP and radial-base function.
34 applied predictive models of trees with reinforced gradient for surface roughness in high-speed milling in the steel and aluminum metallurgical industry. The results show accuracy ranging from 61.54% to 88.51% in the datasets, which are competitive results when compared to the other approaches, the axial cutting depth is the most influential feature for the slot datasets, and the hardness and diameter of the cutting tool are the most influential features for the geometry datasets. [16] studied the effect of machinability, microstructure, and hardness of deep cryogenic treatment on the hard turning of AISI D2 steel with ceramic cutting. The artificial intelligence method known as artificial neural networks (ANN) was used to estimate surface roughness based on cutting speed, cutting tool, part, cutting depth, and feed rate.
[7] used three machine learning algorithms, namely polynomial regression (PR), SVR, and Gaussian process regression (GPR), to predict cutting force and cutting power in the milling of AISI 1045 under minimal quantity lubrication and cutting environments with high pressure cooling. For the development of the predictive models, the machining parameters cutting speed, cutting depth, and feed rate were considered as control factors. The results showed that the SVR and GPR models have better performances when compared to the PR model. The results revealed that the ANN-based model has slightly better results in terms of accuracy than the other machine learning methods studied when estimating the quality trait. The authors further reinforce that the selected machine learning techniques produce adequate results when compared to the experimental results. Thus, using developed models, acceptable results can be estimated rather than obtained experimentally, which consequently reduces the cost and time of testing. The application of artificial intelligence algorithms to milling processes is significant.
[12] estimated the surface roughness of AA6061 alloy in milling using artificial neural networks and response surface methodology. For these models, cutting speed, cutting depth, and feed rate were evaluated as input parameters for the experimental design. The results of neural networks showed that R2, MAE, and RMSE were calculated as 92.7%, 28.11, and 0.185, respectively. According to the results of the response surface methodology modeling, R2, MAE, and RMSE were calculated as 99.9%, 2.17, and 0.016, respectively. Karthik et al. (2021) performed the prediction and optimization of surface roughness and flank wear during high-speed milling of aluminum alloy 6061. Four factors were examined: feed rate, cutting speed, cutting depth, and cutting length. For the prediction, four algorithms were used: linear regression (LIN), support vector machine regression, a gradient augmentation tree (GBR), and an artificial neural network (ANN). The results showed that support vector machine and neural networks presented the best predictive performance surface roughness and maximum flank wear.
[13] performed a multiobjective optimization of surface roughness and tool wear in high-speed milling of AA6061 by machine learning techniques and NSGA-II. SVR and ANN showed the best predictive performance for surface roughness and maximum flank wear. [15] studied machine learning-based quality prediction for milling processes using internal machine tool data. The results show that ensemble methods such as Random Forest and Extra Trees, as well as the deep learning inception time and ResNet algorithms achieve the best performances for the data-driven quality prediction. [31] studied tool wear prediction in stainless steel faceting using singular generative adversarial network and LSTM deep learning models. The authors portray that the stacked LSTM model better predicts tool wear compared to other LSTM models.
[36] conducted a study on cutting forces in the milling process of functionally classified materials using machine learning. The authors developed Gaussian process regression models to perform the prediction of the main cutting force and its components in three directions (Fx, Fy, and Fz) in a coordinate system. This prediction was based on two predictors: the cutting depth (ap) and the feed rate (f), in milling processes of functionally classified materials. The model results demonstrated high precision and stability, indicating that these models have the potential to quickly, economically, and reliably estimate cutting force and its components.
It is also possible to note that there are many published works using machine learning to predict the characteristics of pieces in the literature. [23] carried out a modeling and tagging of time sequence signals in the milling process based on an improved hidden semi-Markov model. [35] evaluated ensemble learning with a genetic algorithm for surface roughness prediction in multi-jet polishing. [10] studied the online monitoring model of micro-milling force incorporating tool wear prediction process.
Based on literature reviews, it is evident that the use of machine learning algorithms has been shown to be effective in predicting important characteristics in milling machining operations, such as surface roughness. These approaches have been widely applied in several studies, bringing competitive and promising results in relation to other traditional modeling techniques.
However, the differentiator of this study is the addition of uncontrollable variables (noise) to the controllable variables of the process for creating machine learning models. Noise represents external or random factors that can influence the quality characteristics of the machining process, but which are outside the direct control of the operators or the pre-established settings. The consideration of these uncontrollable variables in creating machine learning models is extremely relevant, as it more accurately reflects the real operating conditions in manufacturing industries, where there are multiple sources of variation and uncertainty.
This article is divided in 5 sections: Sect. 2 presents a literature review. Section 3 then discusses the research methodology adopted, offering valuable insights into the process and procedures used. Section 4 presents the results and discussions, providing a critical and enlightening analysis of the collected data. Finally, Sect. 5 brings the conclusions of this work, offering an engaging synthesis of all the elements addressed and culminating in a satisfactory and significant outcome.
2 Theoretical framework
2.1 Design of experiments
Design of experiments (DOE) is a statistical methodology used to plan, conduct, and analyze experiments efficiently and systematically. The goal of DOE is to gain valuable and relevant information about how specific variables affect a process or system. With this methodology, researchers can optimize processes, improve products, and identify critical factors that influence the outcome of the experiment 25.
In the context of design of experiments, the factorial design is a very useful strategy for investigating the effect of multiple factors on an experimental system. The factorial design involves testing all possible combinations of the levels of each factor, which allows you to analyze the main effects of each factor and also the interactions between them. This method is particularly useful when you want to identify which factors have the greatest influence on the outcome of the experiment and how they might interact with each other.
The fractional factorial design is an extension of the concept of factorial design that is used when the number of combinations of factor levels is too large to be tested in a complete design. In some situations, testing every possible combination can be expensive, time-consuming, or impractical. In this scenario, the researchers use a fractional factorial design, which consists of selecting only a subset of the total combinations to be tested. This selection is made strategically, using a fraction plan of the full design.
For example, consider an experiment with three factors, each with two levels (high and low). In the full factorial design, 23 = 8 combinations would be required, but a fractional plan could select only 4 combinations, saving time and resources. The fractional factorial design can provide important information about the main effects of the factors, but some interactions may not be completely identified due to the lack of testing with all possible combinations. The choice of fractional plan depends on the nature of the experiment, the number of factors, and the purpose of the research.
In summary, both the full factorial design and the fractional factorial design are design of experiments techniques that allow to study the effect of multiple factors on a system. The first covers all possible combinations, while the second selects a strategic subset of these combinations to save resources but still provide relevant information about the factors and their interactions.
Going further, the combined design is used to study how controllable and noise factors affect the response or variable of interest in the experiment. The main idea is to create an experimental plan that allows you to control and measure both types of factors to analyze their impact on the outcome. A practical example would be a manufacturing study in which the goal is to optimize roughness in machining processes. In this case, the controllable factors can be cutting speed, advance, depth, etc. Noise factors can include variations in raw material quality, tool wear, etc.
The combined design would allow to design an experiment that controls the selected (controllable) factors while recording and considering the random variations (noise). This would provide a more complete analysis of the effects of the factors on the roughness of the product and would help identify the best configuration to achieve the least roughness.
In summary, the combined design is a powerful approach to design experiments that involves the combination of controllable and noise factors. This technique allows you to understand how these factors influence the outcome of the experiment and helps you make more informed decisions to optimize the process or product under study.
2.2 Decision tree regression
Decision trees are classic machine learning algorithms that can be used for both classification and regression. Although their learning ability is not excellent when considered individually, they are known for their ability to generalize and filter features. When applied to regression tasks, they are called regression trees 27. Compared to other algorithms that require data preprocessing, the decision tree algorithm requires less effort in this process. There is no need to perform normalization or scaling of the data. In addition, decision trees can handle incomplete data. In terms of disadvantages, a small change in the data may require several changes to the structure of the decision tree, which can cause instability. The computational time required to train a decision tree is often high.
The process of algorithm training begins with the entire dataset at the root node of the tree. The algorithm searches for the feature and the corresponding value that can best split the data into two or more subsets in a way that minimizes the variance of the target variable within each subset. After finding the best split, the algorithm creates child nodes, each representing a subset of the data based on the split criterion. It continues this process recursively for each child node until a stopping condition is met, such as reaching a maximum tree depth or a minimum number of samples required to create a node. At each terminal node (leaf), instead of returning a class label as in classification tasks, a regression decision tree returns the predicted value for the target variable. This value is usually the mean or median value of the target variable in that subset.
To make predictions, new data points are passed down the tree, and at each node, the algorithm evaluates the corresponding feature’s value. It follows the branches based on the feature values until it reaches a leaf node. The value at the leaf node becomes the prediction for the target variable for that particular data point.
Like other decision trees, regression decision trees are easy to understand and interpret. The tree structure can be visualized, allowing users to see how the decision-making process flows. Regression decision trees can capture non-linear relationships between features and the target variable, which can be challenging for linear regression models. Decision trees can naturally handle feature interactions without requiring feature engineering. Regression decision trees are less affected by outliers compared to some other regression techniques, as the splitting process is based on data percentiles.
Just like classification decision trees, regression decision trees are prone to overfitting when the tree becomes too complex and captures noise in the training data. Small changes in the data can lead to significantly different trees, making the model unstable and sensitive to data variations. Regression decision trees cannot accurately predict values outside the range of the training data, as they make predictions based on the mean or median values within the training subsets.
To address the limitations of a single regression decision tree, ensemble techniques like Random Forests is often used. These methods combine the predictions of multiple decision trees to improve the model’s accuracy, generalization, and robustness. Ensemble techniques help reduce overfitting, provide better stability, and enable improved predictions for both the data points within the training range and those slightly beyond it.
2.3 Random Forest
The Random Forest algorithm is a powerful approach to the field of machine learning that has proven extremely efficient for solving complex problems in several areas of engineering. It belongs to the category of ensemble methods, which combine several individual predictions of simpler models to achieve more reliable and accurate results [6].
Random Forest is built on decision trees, which are hierarchical decision structures that divide the dataset into more homogeneous subsets. Each tree is trained on a random subset of the dataset, through replacement sampling [32]. The decision nodes and leaves represent the structure of the decision tree, where the leaves represent the final results and the decision nodes are points where the data is divided. This randomness and diversity of trees ensure that the ensemble has less tendency to overfitting, making it more generalizable. This model is widely used due to its simplicity and diversity, being applied to both regression and classification problems [4].
The Random Forest training process is divided into two main stages: creating the set of trees and combining the predictions. In the first step, several decision trees are constructed using different samples from the training dataset. For each tree, recursive division is applied iteratively until the nodes are purely homogeneous (for classification tasks) or a maximum depth is reached. In the second step, the predictions of all trees are combined through voting (for classification) or mean (for regression) to produce the final answer [32].
Random Forest is widely used in engineering in various applications, such as equipment failure prediction, industrial process optimization, time series analysis, and maintenance decision-making, among others. Its ability to handle complex, multidimensional data sets makes it especially useful for problems with uncertainties and variations. Considered one of the most powerful and versatile machine learning techniques, Random Forest has advantages such as reduced overfitting, high precision, missing data handling, and high dimensionality, as well as providing measures of importance of variables. Its applicability in large-scale and complex problems makes it an essential tool in modern engineering 14.
2.4 Support vector machine
Based on the theory of statistical learning, the support vector machine (SVM) was developed by [9], in order to solve problems of classification and regression. The support vector regression is a specific technique within SVM developed by Drucker et. al. (1997). Its main goal is to find the best fit line represented by a hyperplane with the most points. To determine this hyperplane, the support vector regression selects extreme points/vectors, known as support vectors, that justify the nomenclature of the technique. Support vector regression aims to fit the ideal line within a limit value range, which is the distance between the boundary line and the hyperplane [20].
In real-world situations, it is rare to find applications where the data is linearly separable. This is due to various factors, such as the presence of noise and outliers in the data or the inherently non-linear nature of the problem. To address these challenges, it is allowed for some data to violate the constraint\({y}_{i}(\mathrm{w}.{\mathrm{x}}_{i}+b)-1\ge 0, \forall i=1,...,n\). This is done by introducing slack variables\({\xi }_{i}\), for all i = 1, …, n [1]. These variables relax the constraints imposed on the primal optimization problem, resulting in a more flexible approach as shown in Eq. (1) 3:
The application of this procedure smooths the margins of the linear classifier, allowing some data to remain between the hyperplanes H1 and H2 and also permitting some classification errors. For this reason, the SVMs obtained in this case can also be referred to as SVMs with soft margins. An error in the training set is indicated by a value of ξi may than 1. Thus, the sum of the ξi represents a limit on the number of training errors [8]. To account for this term, thereby minimizing the error on the training data, we have Eq. (2):
The constant C is a regularization term that weights the minimization of errors in the training set relative to the minimization of model complexity [2]. The presence of this term \(\sum_{i=1}^{n}{\xi }_{i}\) in the optimization problem can also be seen as a minimization of marginal errors, as a value of \({\xi }_{i}\)∈ (0,1) indicates data between the margins.
SVM training involves choosing the optimal hyperplane that best separates the training data in your classes. For this, SVM uses an optimization process that seeks to maximize the margin between the points of each class and the separation hyperplane. For a nonlinear regression, the concept of Kernel function is introduced, which serves to implicitly map the feature vectors to a larger space where it is assumed that the data are linearly separable. By mapping the vectors in a nonlinear way and applying the technique, a nonlinear function results in the original space, even if it is linear in another space.
SVM is widely applied in engineering in various scenarios, such as fault diagnosis in complex systems, pattern classification in images and signal processing, event prediction and decision-making in control, and automation engineering, among others. Its ability to handle high-dimensional data and the ability to adapt to nonlinear problems make it especially useful in engineering applications [26].
In terms of advantages, SVM can work very well with high-dimensional input space and is relatively memory efficient. In terms of disadvantages, SVM is not suitable for large data sets; it does not work well with any data type (e.g., dataset with more noise) [30].
2.5 Performance indicators
Three distinct performance indicators were chosen to evaluate the accuracy of the models in predicting surface roughness values. These indicators are the coefficient of determination (R2), the mean square error (MAE), and the root of the mean square error (RMSE), as shown in Eqs. (3) to (5), respectively:
where n is the number of data points, Yi represents observed values, Ŷ represents predicted values, and Ȳ means the mean value of Y.
When comparing the values of the metrics, priority will be given to the evaluation criteria chosen for the RMSE, since it is a more appropriate method than the MAE when the errors of the model follow a normal distribution. In addition, RMSE has a significant advantage over MAE as it avoids the use of absolute values, which may be undesirable in many mathematical calculations 33. Therefore, when comparing the accuracy of various regression models, RMSE is a more suitable choice because it is easy to calculate and has differentiability. In addition, a higher value for R2 is considered desirable.
Importantly, we will do an initial analysis on the data before using it in machine learning models. Outliers, for example, can have a significant impact on the accuracy of machine learning models. They can skew the results and negatively affect the model’s ability to correctly generalize patterns in the data. Outliers can violate these assumptions, compromising the validity of statistical analyses and the results obtained. Therefore, it is important to identify and deal with outliers to ensure that model assumptions are met [29].
Some algorithms are sensitive to outliers, meaning their performance can be severely affected by the presence of these outliers. Outliers may arise due to measurement errors or data corruption. Identifying and correcting these outliers is essential to ensuring the quality and integrity of the data used in model training. Therefore, doing the analysis of outliers in the data before applying machine learning algorithms is fundamental to obtain more accurate, robust and reliable models, as well as ensuring the validity of the statistical analyses and the quality of the data used.
In model performance evaluation, overfitting occurs when a model overfits the training data, capturing even the noise and outliers present in them. This results in a model that does not generalize well to new data. By treating outliers, it is possible to reduce the risk of overfitting and improve the model's ability to make accurate predictions on unseen data 5.
Finally, ML model optimization is the main challenge to achieve an effective machine learning solution. Hyperparameter optimization aims to find the optimal values for the model parameters, resulting in the best performance as assessed by the validation set, within a given machine learning algorithm. These hyper parameters are responsible for controlling the learning process and have a significant impact on predictive performance. In addition, an appropriate selection can avoid problems of overfitting and underfitting, thus increasing the accuracy of predictions (Nguyen et al., 2020). In the present study, several hyperparameters were analyzed and the best ones were chosen to be used.
3 Methodology
The top milling operation was performed in a ROMI D600 machining center, as shown in Fig. 1, with a power of 15 kW and a maximum rotation of 10,000 rpm. The part to be machined is duplex stainless steel, which has low machinability due to its low thermal conductivity. The chemical structure of duplex stainless steel UNS S32205 is mentioned in Table 1. The insert used in the cutting operation was the CoroMill R390-11T308M-MM 2030, made of carbide and with double layer of titanium nitride (TiN) and aluminum titanium nitride (TiNAl), coated by the process of physical vapor deposition (PVD), fixed in the CoroMill®® R390-025A25-11 M support, with a diameter of 25 mm, position angle χr = 90°, cylindrical rod, with 3 inserts and mechanical fixation by tweezers. Both the inserts and the tool holder were provided by Sandvik Coromant.

ROMI® D 600 machining center
The data that will be used as the database for the creation of machine learning algorithms will be obtained through an experimental design, in which a combined arrangement was chosen. A half-fraction factorial design was created, containing both control and noise variables.
The controllable factors of the process were cutting speed, tooth advance, cutting width, and cutting depth, and the selected levels are shown in Table 2. The uncontrollable parameters were the cantilevered length of the tool, the flow of the cutting fluid, and the flank wear, as shown in Table 3, while surface roughness was considered the response parameter. The experimental execution was carried out randomly, in order to minimize errors from other variables that were not considered, due to the impossibility of being measured and/or because they are unknown. Table 4 shows the experimental matrix used to collect data on surface roughness.
To control the overhang length (lt0) during the experimental tests, a set of clamping devices was used, as shown in Fig. 2. The value of lt0 was verified using a Digimess® analog caliper with a resolution of 0.05 mm.

Tool holder cone and cutting tool
Regarding the amount of fluid (Q), two regulating valves (1 and 2) were used to control the flow during the top milling of duplex stainless steel UNS S32205. To ensure minimal flow in the machine tool, a small opening was made in valve 1, and the flow rate was measured using a graduated beaker. For maximum flow, both valves were fully opened. In the case of “dry” machining, the valves were closed to prevent the fluid from being directed to the cutting area. The valves used to control the fluid quantity in the process can be observed as shown in Fig. 3.

Fluid quantity control
During the execution of the experiments, the measurements of tool flank wear (vb) were obtained using the image analyzer (Global Image Analyzer), the Global Lab 97 Image software, and the stereoscopic microscope model SZ 61 (with 45 times magnification), as shown in Fig. 4.

Flank wear of cutting inserts
Surface roughness measurements were obtained using a calibrated Mitutoyo Surftest 201 portable roughness tester before the start of measurements, as shown in Fig. 5. The cutoff parameter was set to 0.8 mm for all measurements, as for this sampling length, roughness values of Ra are expected to vary between 0.1 and 2 µm-meter. The measurements were taken perpendicular to the machining groove. Measurements were made at the beginning, in the middle, and at the end. Table 4 displays the experimental matrix used for collecting surface roughness data. The axial points of the noise were excluded from this matrix, as machining them is physically impossible.

Roughness measurement
After performing the experiments, we move on to the construction part of the machine learning model. The experimental data were divided into training and test sets, representing respectively 70% and 30% of the total number of experiments performed, which corresponds to 50 training attempts and 22 test attempts. All models were built using the Python language. The resulting dataset was normalized to ensure a consistent scale and distribution of all variables.
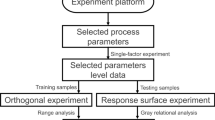
The training data were used to train three regression algorithms: support vector machine, Random Forest, and decision tree regression. The test data were used to validate the performance of the model. To evaluate the accuracy of the proposed model, error metrics such as root mean square error (RMSE), mean absolute error (MAE), and R2 parameter were used. Figure 6 shows the flowchart of the methodology applied in this article.

General methodology used in this study
There are several common strategies for optimizing hyper parameters, including manual fit, grid search, random search, Bayesian optimization, gradient-based optimization, and evolutionary optimization [18]. In this study, we used grid search using the GridSearch CV method, a traditional technique for adjusting hyper parameters. This approach allows to find the best hyperparameters through a grid of combinations in each order [17]. Several hyperparameters were tested for the algorithms, and the best grid values found for the models are presented in Table 5.
Finally, it is important to mention that the method of cross-validation of ten times repeated 10 times was used to train and validate the models. The original dataset is randomly divided into 10 sets of equal size, called folds. The regressor is trained nine times using nine folds as the training set and the last fold as the validation set. The accuracy of the regressor is evaluated in instances that were not used for training. This process is repeated 10 times, using a different fold for validation each time, and the mean RMSE (mean quadratic error) of the validation folds in the 10 repetitions is calculated. In this way, the variance of the regressor’s precision is reduced, and its prediction results can be generalized.
4 Results and discussion
4.1 Outliers precision in machine learning models
The analyses of the outliers of the controllable variables of this study can be seen in Fig. 7. It is possible to notice that there are no outliers in the controllable variables. It is worth mentioning that in noise variables, outlier analysis is usually not done because these variables are usually considered to be random and uncontrollable. Noise in a dataset is a source of variation not explained by the independent variables and the model itself. Outliers in noise variables are treated differently from outliers in variables of interest. Generally, outliers in noise variables are not considered outliers that need to be corrected or removed. They are seen as a natural part of random variation and do not have a significant influence on model interpretation or performance.

Analyze of outliers for a cutting speed, b feed per tooth, c cutting width, and d cutting depth
4.2 Correlation analysis
Figure 8 analyzes the correlations between roughness and other variables (flank wear, tooth advance, cutting speed, cutting depth, cantilevered length, and milled width). By looking at the graph, it is possible to identify the intensity of the correlations and their directions. The result shows that the variable that has the highest positive correlation with roughness is flank wear (vb). This indicates that with increased flank wear, the cutting edge of the tool becomes damaged or worn, which results in lower cutting efficiency, with the tool failing to cut the material properly, leading to a less uniform and rougher machined surface.

Correlation analysis between controllable and uncontrollable factors
Next, the variable that presents the second highest correlation with roughness is feed rate (fz), again indicating a positive relationship. This can be explained by the fact that when the feed rate increases, a greater load is applied to the cutting tool, especially when machining harder materials. This additional load can cause vibrations and deformations in the tool, resulting in imperfections in the machined surface and, consequently, greater roughness.
Similarly, the other variables, such as cutting speed (vc), cutting depth (ap), cantilevered length (lt0), and milled width (ae), also show some degree of correlation with roughness, but at lower intensities.
4.3 Predictive performance of models
Table 6 presents the performance of the three machine learning models in predicting Ra for the test suites. Based on the results presented and considering the criterion of choosing the best algorithm such as RMSE, we observed that Random Forest obtained the lowest RMSE value, with a result of 0.031. In addition, Random Forest also had the lowest MAE value, with a result of 0.001. In terms of R2, both the Decision Tree and the Random Forest obtained high results, with values of 0.96 and 0.97, respectively.
We can conclude that Random Forest presented the best overall performance in relation to the other algorithms (SVM and Decision Tree) for the prediction of surface roughness in the duplex stainless steel top milling process. Figures 9, 10, and 11 illustrate the line and scatterplots of the predicted and observed values of Ra for the test sets.

Comparison of experimental measurement and prediction using Ra x SVM on the test dataset

Comparison of experimental measurement and prediction using Ra x DTR on the test dataset

Comparison of experimental measurement and prediction using Ra x RF on the test dataset
4.4 Validation of predicted results
To assess the efficiency of the predictions made by the machine learning algorithms, confirmatory experiments were conducted. The objective of these experiments was to verify the machine learning model’s capability to predict surface roughness in the top milling process of duplex stainless steel UNS S32205 concerning noise variables. The first step of the optimization was to establish the objective function, as shown in Eq. 6.
Applying the concept of robust parameter design (RPD) through a combined arrangement, the optimization of the variables involved two functions, requiring the application of a dual method. In this study, the concept of mean squared error was used, which aims to jointly minimize the bias and variance of the factors. Therefore, the mean and variance models were developed as per Eqs. (7) and (8), based on the regression model presented in Eq. (6):
Equations (7) and (8) are written solely in terms of the control variables, although the noise variables are tested at different levels during the experiments. The target (T) for the mean of Ra was estimated by performing individual optimization using the system of Eq. (9) through the Generalized Reduced Gradient (GRG) algorithm, available in the Excel® package. According to 21, GRG is one of the most robust and efficient methods for constrained nonlinear optimization.
where \({\hat{y}}_{i}\) represents the model for the mean of Ra and \({\sigma }^{2}{}_{i}\) represents the model for the variance of Ra. The constraint xTx ≤ ρ2 represents the set of convex constraints of the experimental region, and for the CCD adopted in this work, ρ = α, where α corresponds to the axial distance of the experimental arrangement. Once the target (T) for roughness was defined, the mean squared error (MSE) equation was established as shown in Eq. (10).
Finally, the optimization was performed using the GRG algorithm from the Solver® add-in program in the Excel® package, respecting the constraint of Eq. (10):
The optimal parameters for the control variables, as shown in Table 7, were then set in the CNC machining center command. A Taguchi L9 matrix was created for the levels of the noise variables. The results of the predictions with the experimental data are compared in Table 8.
The results indicate that the experimental data closely match the predicted values obtained through the confirmatory experiments. The largest percentage errors of Ra are 2.4% and 1.5%. Therefore, it is possible to assert that machine learning techniques can be used to achieve the desired Ra in the top milling process of duplex stainless steel, as the differences found between the actual (experimental) value and the predictions are very small.
5 Conclusions
In this study, three machine learning models (SVM, DRT, and RF) were employed to predict surface roughness in the milling process of duplex stainless steel UNS S32205. The performance of these models was evaluated through experimental tests using three quality metrics: RMSE, MAE, and R2.
It was observed that the number of experiments was sufficient for training the models. Data normalization was performed, and although the presence of outliers was analyzed, no values were excluded on that basis. Validation tests were conducted to ensure the consistency of the models with reality, and the results demonstrated highly accurate predictions.
The analysis of the results revealed that the RMSE values of the models were quite close, suggesting that all models are significant. However, the RF model showed the best performance, with an RMSE value of 0.031, followed by the DTR (0.038) and SVM (0.066) models. Experimental verification indicated that the percentage errors between the actual (experimental) and predicted Ra values were 2.35%, 2.4%, and 1.15%, respectively. These results confirm the effectiveness of the machine learning models in predicting surface roughness for the milling of duplex stainless steel.
In summary, this study compares the predictive accuracy of different machine learning models based on RMSE values and percentage errors. The RF model demonstrated superior precision, making it the most reliable for this application.
These results highlight the importance of considering noise during the training of machine learning models. This consideration allows artificial intelligence to better understand real-world processes, encompassing both controllable factors and the presence of noise, resulting in predictions that are more precise and aligned with reality.
References
Smola AJ, Barlett P, Schölkopf B, Schuurmans D (1999) Introduction to large mar-gin classifiers. In A. J. Smola, P. Barlett, B. Schölkopf, and D. Schuurmans, editors,Advances in Large Margin Classifiers, pages 1–28. MIT Press, https://doi.org/10.7551/mitpress/1113.001.0001
Passerini Kernel A (2004) Methods, multiclass classification and applications to computational molecular biology. PhD thesis, Università Degli Studi di Firenze
Smola AJ, Schölkopf B (2002) Learning with Kernels. The MIT Press, Cambridge, MA
Azure JWA, Ayawah PEA, Kaba AGA, Kadingdi FA, Frimpong S (2021) Hydraulic shovel digging phase simulation and force prediction using machine learning techniques. Mining Metall Explor 38:2393–2404
Boukerche A, Zheng L (2020) Alfandi, Outlier detection: methods, models, and classification. Computing ACM Sobreviver 53:1–37
Bustillo A, Reis R, Machado AR, Pimenov DY (2022) Improving the accuracy of machine-learning models with data from machine test repetitions. J Intell Manuf 33:203–221
Cica D, Sredanovic B, Tesic S, Kramar D (2020) Predictive modeling of turning operations under different cooling/lubrication conditions for sustainable manufacturing using machine learning techniques. Appl Comput Informar
Burges CJC (1998) A tutorial on support vector machines for pattern recognition.Know-ledge Discovery and Data Mining, 2(2):1–43
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BF00994018
Ding P, Huang X, Zhao C, Liu H, Zhang X (2023) Online monitoring model of micro-milling force incorporating tool wear prediction process. Expert Syst Appl 223:119886
Drucker H, Burges CJ, Kaufman L, Smola A, Vapnik V (1997) Support vector regression machines. Adv Neural Inf Process Syst 9:155–161
Eser E Aşkar Ayyıldız M, Ayyıldız and Kara F (2021) “Artificial intelligence-based surface roughness estimation modelling for milling of AA6061 alloy,” Adv Mater Sci Eng 2021:5576600. 10 pages
Anh-Tu Nguyen, Van-Hai Nguyen, Tien-Thinh Le, Nhu-Tung Nguyen, "Multiobjective optimization of surface roughness and tool wear in high-speed milling of AA6061 by machine learning and NSGA-II", Adv Mater Sci Eng 2022:5406570, 21 pages. https://doi.org/10.1155/2022/5406570
Fernández-Delgado M, Cernadas E, Barro S, Amorin D (2014) Do we need hundreds of classifiers to solve real world classification problems. J Mach Learn Res 15:3133–3181
Fertig Weigold M, Chen Y (2022) Machine Learning based quality prediction for milling processes using internal machine tool data, Advances in Industrial and Manufacturing Engineering, 4:100074, ISSN 2666–9129. https://doi.org/10.1016/j.aime.2022.100074
Fuat Kara, Mustafa Karabatak, Mustafa Ayyıldız, Engin Nas, Effect of machinability, microstructure and hardness of deep cryogenic treatment in hard turning of AISI D2 steel with ceramic cutting, Journal of Materials Research and Technology, Volume 9, Issue 1, 2020, Pages 969–983, ISSN 2238–7854, https://doi.org/10.1016/j.jmrt.2019.11.037
Injadat, M., Moubayed, A., Nassif, A. B., & Shami, A. (2020). Systematic ensemble model selection approach for educational data mining. Knowledge-Based Systems 200:105992. https://doi.org/10.1016/j.knosys.2020.105992
Wu J, Chen X-Y, Zhang H, Xiong L-D, Lei H, Deng S-H (2019) Hyperparameter optimization for machine learning models based on Bayesian optimization. J Electron Sci Technol 17:26–40
Jumare AI et al (2018) Prediction model for single-point diamond tool-tip wear during machining of optical grade silicon. Int J Adv Manuf Technol 98(9):2519–2529
Jurkovic Z, Cukor G, Brezocnik M, Brajkovic T (2018) A comparison of machine learning methods for cutting parameters prediction in high-speed turning process. J Intell Manuf 29:1683–1693
KOKSOY O, (2006) Multiresponse robust design: mean square error (MSE) criterion. Appl Mathemat Comput 175:1716–1729
Kuntoğlu M, Aslan A, Pimenov DY, Usca ÜA, Salur E, Gupta MK et al (2021) A review of indirect tool condition monitoring systems and decision-making methods in turning: critical analysis and trends. Sensors 21(1):108. https://doi.org/10.3390/s21010108
Li K, Qiu C, Zhou X, Chen M, Lin Y, Jia X, Li B (2022) Modeling and tagging of time sequence signals in the milling process based on an improved hidden semi-Markov model. Expert Syst Appl 205:117758
Martinho RP, Silva FJG, Martins C, Lopes H (2019) Comparative study of PVD and CVD cutting tools in milling of duplex stainless steel. Int J Adv Manuf Technol 102(5–8):2423–2439
MONTGOMERY DC (2017) Designs and analysis of experiments. 9th. ed. USA: John Wiley & Sons
Nguyen NT, Tien DH, Tung NT, Luan ND (2021) Analysis of tool wear and surface roughness in high-speed milling process of aluminum alloy Al6061. EUREKA: Phys Eng (3), 71–84
Maimon OZ, Rokach L (2014) Data mining with decision trees: theory and applications. World Scientific, Singapore
Pimenov DY, Bustillo A, Mikolajczyk T (2018) Artificial intelligence for automatic prediction of required surface roughness by monitoring wear on face mill teeth. J Intell Manuf 29:1045–1061. https://doi.org/10.1007/s10845-017-1381-8
Ramírez-Gallego S, Krawczyk B, García S, Woźniak M, Herrera F (2017) A survey on data preprocessing for data stream mining: current status and future directions. Neurocomputing 239:39–57
Saravanamurugan S, Thiyagu S, Sakthivel NR, Nair BB (2017) Chatter prediction in boring process using machine learning technique. Int J Manuf Res 12(4):405–422
Shah M, Vakharia V, Chaudhari R et al (2022) Predicting tool wear in stainless steel face milling using a singular generative adversarial network and LSTM deep learning models. Int J Adv Manuf Technol 121, 723–736. https://doi.org/10.1007/s00170-022-09356-0
Speiser JL, Durkalsky VL, Lee WM (2015) Random forest classification of etiologies for an orphan disease. Statustucs in Medicine 34(5):887–899
Chai T, Draxler RR (2014) Root mean square error (RMSE) or mean absolute error (MAE) arguments against avoiding RMSE in the literature. Geoscientific Model Development 7(3):1247–1250
Flores V, Keith B (2019) “Gradient boosted trees predictive models for surface roughness in high-speed milling in the steel and aluminum metalworking industry”, Gradient Boosted Trees Predictive Models for Surface Roughness in High-Speed Milling in the Steel and Aluminum Metalworking Industry
Wang R, Cheng MN, Loh YM, Wang C, Cheung CF (2022) Ensemble learning with a genetic algorithm for surface roughness prediction in multi-jet polishing. Expert Syst Appl 207:118024
Xu X, Zhang Y, Li Y et al (2022) Cutting forces in functionally graded material milling using machine learning. Adv em Comp Int 2:25. https://doi.org/10.1007/s43674-022-00036-w
Zhang L, Zhong ZQ, Qiu LC, Shi HD, Layyous A, Liu SP (2019) Coated cemented carbide tool life extension accompanied by comb cracks: the milling case of 316L stainless steel. Wear, 418–419, n. November 2018, p. 133–139
Funding
I want to thank the Foundation for Research Support of the State of Minas Gerais (FAPEMIG) for the funding in projects APQ 02290–23 and APQ-03036–23.
Author information
Authors and Affiliations
Contributions
The work is divided into (i) literature review, (ii) background, (iii) statistical analysis, and (iv) writing and review. The work was divided as follows:
G.V.: literature review, background, statistical analysis, writing, and review.
M.B.: literature review, statistical analysis, writing, and review.
C.H.d.O.: background, statistical analysis, and review.
E.L.B.: background, statistical analysis, and review.
L.G.P.d.S.: background, statistical analysis, and review.
M.M.: Literature review, background, and review.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Vasconcelos, G.A.V.B., Francisco, M.B., de Oliveira, C.H. et al. Prediction of surface roughness in duplex stainless steel top milling using machine learning techniques. Int J Adv Manuf Technol 134, 2939–2953 (2024). https://doi.org/10.1007/s00170-024-14290-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-024-14290-4