
Abstract
Due to the many applications in Magnetic Resonance Imaging (MRI), Nuclear Magnetic Resonance (NMR), radio interferometry, helium atom scattering etc., the theory of compressed sensing with Fourier transform measurements has reached a mature level. However, for binary measurements via the Walsh transform, the theory has long been merely non-existent, despite the large number of applications such as fluorescence microscopy, single pixel cameras, lensless cameras, compressive holography, laser-based failure-analysis etc. Binary measurements are a mainstay in signal and image processing and can be modelled by the Walsh transform and Walsh series that are binary cousins of the respective Fourier counterparts. We help bridging the theoretical gap by providing non-uniform recovery guarantees for infinite-dimensional compressed sensing with Walsh samples and wavelet reconstruction. The theoretical results demonstrate that compressed sensing with Walsh samples, as long as the sampling strategy is highly structured and follows the structured sparsity of the signal, is as effective as in the Fourier case. However, there is a fundamental difference in the asymptotic results when the smoothness and vanishing moments of the wavelet increase. In the Fourier case, this changes the optimal sampling patterns, whereas this is not the case in the Walsh setting.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since Shannon’s classical sampling theorem [59, 64], sampling theory has been a widely studied field in signal and image processing. Infinite-dimensional compressed sensing [7, 9, 18, 43, 44, 56, 57] is part of this rich theory and offers a method that allows for infinite-dimensional signals to be recovered from undersampled linear measurements. This gives a non-linear alternative to other methods like generalized sampling [3, 4, 6, 8, 39, 41, 49] and the Parametrized-Background Data-Weak (PBDW)-method [15, 16, 27, 50,51,52] that reconstruct infinite-dimensional objects from linear measurement. However, these methods do not allow for subsampling, and hence are dependent on consecutive samples of, for example, the Fourier transform. Infinite-dimensional compressed sensing, on the other hand, is similar to generalized sampling and the PBDW-method but utilises an \(\ell ^1\) optimisation problem that allows for subsampling.
Beside the typical flagship of modern compressed sensing, namely MRI [37, 48], there is also a myriad of other applications, like fluorescence microscopy [55, 60], single pixel cameras [33], medical imaging devices like computer tomography [22], electron microscopy [45], lensless cameras [42], compressive holography [23] and laser-based failure-analysis [61] among others. The applications divide themselves in three different groups: those that are modelled by Fourier measurements, like MRI [48], those that are based on the Radon transform, as in CT imaging [22, 58], and those that are represented by binary measurements, which are named above. For Fourier measurements there exists a large history of research. However, for Radon measurements, the theoretical results are scarce and for binary measurements results have only evolved recently. In this paper we consider binary measurements and provide the first non-uniform recovery guarantees in one dimension for infinite-dimensional compressed sensing with the reconstruction with boundary corrected Daubechies wavelets.
The setup of infinite-dimensional compressed sensing is as follows. We consider an orthonormal basis \(\left\{ \varphi _j\right\} _{j \in \mathbb {N}}\) of a Hilbert space \(\mathcal {H}\) and an element \(f \in \mathcal {H}\) with its representation
to be recovered from measurements given by linear operators working on f. That is, we have another orthonormal basis \(\left\{ \omega _i\right\} _{i \in \mathbb {N}}\) of \(\mathcal {H}\) and we can access the linear measurements given by \(l_i(f) = \langle f, \omega _i \rangle \). Although the Hilbert space can be arbitrary, we will in applications mostly consider function spaces. Hence, we will often refer to the object f as well as the basis elements as functions. We call the functions \(\omega _i\), \(i \in \mathbb {N}\) sampling functions and the space spanned by them \({\mathcal {S}} = \overline{{\text {span}}}\left\{ \omega _i : i \in \mathbb {N}\right\} \) sampling space. Accordingly, \(\varphi _j\), \(j \in \mathbb {N}\) are called reconstruction functions and \({\mathcal {R}} = \overline{{\text {span}}}\left\{ \varphi _j : j \in \mathbb {N}\right\} \) reconstruction space. Generalized sampling [2, 6, 7] and the PBDW-method [52] use the change of basis matrix \(U = \{u_{i,j}\}_{i,j \in \mathbb {N}} \in {\mathcal {B}} ( \ell ^2(\mathbb {N}))\) with \(u_{i,j} = \langle \omega _i, \varphi _j \rangle \) to find a solution to the problem of reconstructing coefficients in the reconstruction space from measurements in the sampling space. This is also the case in infinite-dimensional compressed sensing. In particular, we consider the following reconstruction problem. Let \(\Omega \subset \left\{ 0,1, \ldots , N_r \right\} \) be the subsampling set, where the elements are ordered canonically when needed, and let \(P_\Omega \) the orthogonal projection onto the elements indexed by \(\Omega \) and \(||z||_2 \le \delta \) some additional noise. For a fixed signal \(f = \sum _j x_j \varphi _j\) and the measurements \(g = P_\Omega U f + z\) the reconstruction problem is to find a minimiser of
2 Preliminaries
2.1 Setting and Definitions
In this section we recall the settings from [9] that are needed to establish the main results. First, note that we will use \(a \lesssim b\) to describe that a is smaller b modulo a constant, i.e. there exists some \(C >0\) such that \(a \le Cb\). Moreover, for a set \(\Omega \subset \mathbb {N}\) the orthogonal projection corresponding to the elements of the canonical bases of \(\ell ^2(\mathbb {N})\) with the indices of \(\Omega \) is denoted by \(P_\Omega \). Similar, for \(N \in \mathbb {N}\) the orthogonal projection onto the first N elements of the canonical basis of \(\ell ^2(\mathbb {N})\) and \(\ell ^1(\mathbb {N})\) is represented by \(P_N\) and the projection on the orthogonal complement by \(P_N^\perp \). If we project onto the sampling space \(\mathcal {S}_N\) this is denoted by \(P_{\mathcal {S}_N}\) and as before the complement by \(P_{\mathcal {S}_N}^\perp \). Finally, \(P_b^a\) stands for the orthogonal projection onto the basis vectors related to the indices \(\left\{ a+1, \ldots , b \right\} \).
Note that (1.1) is an infinite-dimensional optimisation problem, however, in practice (1.1) is replaced by
As \(L \rightarrow \infty \) one recovers minimisers of (1.1) (see §4.3. in [7] for details).
X-lets such as wavelets [53], Shearlets [25, 26] and Curvelets [19,20,21] yield a specific sparsity structure. The construction includes a scaling function which allows to divide them into several levels. The same levels also dominate the sparsity structure. To describe this phenomena the notation of \(({\mathbf {s}}, {\mathbf {M}})\)-sparsity is introduced instead of global sparsity.
Definition 1
(Def. 3.3 [9]) Let \(x \in \ell ^2(\mathbb {N})\). For \(r \in \mathbb {N}\) let \({\mathbf {M}} = (M_1, \ldots , M_r) \in \mathbb {N}\) with \(1 \le M_1< \ldots < M_r\) and \({\mathbf {s}} = (s_1, \ldots , s_r) \in \mathbb {N}^r\), with \(s_k \le M_k-M_{k-1}\), \(k=1,\ldots ,r\) where \(M_0 =0\). We say that x is \(({\mathbf {s}}, {\mathbf {M}})\)-sparse if, for each \(k=1, \ldots ,r\),
satisfies \(| \Delta _k| \le s_k\). We denote the set of \(({\mathbf {s}}, {\mathbf {M}})\)- sparse vectors by \(\Sigma _{{\mathbf {s}}, {\mathbf {M}}}\).
Most natural signals are not perfectly sparse. But they can be represented with a small tail in the X-let bases, or with the according ordering in other sparsifying representation systems. Hence, in a large number of applications it is unlikely to ask for sparsity but compressibility.
Definition 2
(Def. 3.4 [9]) Let \(f = \sum _{j \in \mathbb {N}} x_j \varphi _j\), where \(x= (x_j)_{j\in \mathbb {N}} \in \ell ^2(\mathbb {N})\). We say that f is \(({\mathbf {s}}, {\mathbf {M}})\)- compressible with respect to \(\left\{ \varphi _j \right\} _{j \in \mathbb {N}}\) if \(\sigma _{{\mathbf {s}},{\mathbf {M}}}(f)\) is small, where
In terms of this more detailed description of the signal instead of classical sparsity it is possible to adapt the sampling scheme accordingly. Complete random sampling will be substituted by the setting of multilevel random sampling. This allows us later to treat the different levels separately. Moreover, this represents sampling schemes that are used in practice.
Definition 3
(Def 3.2 [9]) Let \(r \in \mathbb {N}, {\mathbf {N}} = (N_1, \ldots , N_r) \in \mathbb {N}^r\) with \(1 \le N_1< \ldots <N_r\), \({\mathbf {m}} = (m_1, \ldots , m_r) \in \mathbb {N}^r\), with \(m_k \le N_k - N_{k-1}\), \(k=1, \ldots ,r\), and suppose that
are chosen uniformly at random without replacement, where \(N_0 =0\). We refer to the set
as an \(({\mathbf {N}}, {\mathbf {m}})\)- multilevel sampling scheme.
Remark 1
To avoid pathological examples, we assume as in §4 in [9] that we have for the total sparsity \(s = s_1 + \ldots s_r \ge 3\). This results in the fact that \(\log (s) \ge 1\) and therefore also \(m_k\ge 1\) for all \(k=1,\ldots ,r\).
3 Main Results: Non-uniform Recovery for the Walsh-Wavelet Case
In this paper we focus on the reconstruction of one-dimensional signals from binary measurements, which can be modelled as inner products of the signal with functions that take only values in \(\left\{ 0,1\right\} \). This arises naturally in examples like those mentioned in the introduction. We focus on the setting of recovering data in \(L^2([0,1])\). However, the theory from [9] also applies to general results for Hilbert spaces. Linear measurements are typically represented by inner products between sampling functions and the data of interest. Binary measurements can be represented with functions that take values in \(\left\{ 0,1\right\} \), or, after a well-known and convenient trick of subtracting constant one measurements, with functions that take values in \(\left\{ -1,1\right\} \). For practical reasons it is sensible to consider functions for the sampling bases that provide fast transforms. Additionally, the function system should correspond well to the chosen representation system of the reconstruction space. For the reconstruction with wavelets, Walsh functions have proven to be a sensible choice, and are discussed in more detail in §3.2.1. Sampling from binary measurements has been analysed for linear reconstruction methods in [12, 40, 63] and for non-linear reconstruction methods in [1, 54]. We extend these results to the non-uniform recovery guarantees for non-linear methods. The combined work result in broad knowledge about linear and non-linear reconstruction for two of the three main measurement systems: Fourier and binary.
In the following we consider for the change of basis matrix
where \(\{\omega _j\}_{j \in \mathbb {N}}\) denotes the Walsh functions on [0, 1] as described in §3.2.1, and \(\{\varphi _i\}_{i \in \mathbb {N}}\) demotes the Daubecies boundary wavelets on [0, 1] of order \(p \ge 3\) described in §3.2.2. For the sake of readability, we always consider Daubechies boundary corrected wavelets in the following if we say wavelets.
We are now able to state the recovery guarantees for the Walsh-wavelet case.
Theorem 1
(Main Theorem) Given the notation above, let \({\mathbf {N}} = (N_0,\ldots ,N_r)\) define the sampling levels as in (3.8) and \({\mathbf {M}} = (M_0, \ldots , M_r)\) represent the levels of the reconstruction space as in (3.7). Consider U as in (3.1), \(\epsilon >0\) and let \(\Omega = \Omega _{N,m}\) be a multilevel sampling scheme such that the following holds:
-
(1)
Let \(N=N_r\), \(K= \max _{k=1,\ldots ,r} \left\{ \frac{N_{k}-N_{k-1}}{m_k} \right\} \), \(M=M_r\), \(s= s_1 + \ldots +s_r\) such that
$$\begin{aligned} N \gtrsim M^{2} \cdot \log (4MK\sqrt{s}). \end{aligned}$$(3.2) -
(2)
For each \(k =1, \ldots , r\),
$$\begin{aligned} m_k \gtrsim \log (\epsilon ^{-1}) \log \left( K^3s^{3/2} N \right) \cdot \frac{N_k - N_{k-1}}{N_{k-1}} \cdot \left( \sum _{l=1}^r 2^{-|k-l|/2}s_l \right) \end{aligned}$$(3.3)
Then with probability exceeding \(1-s\epsilon \), any minimizer \(\xi \in \ell ^2(\mathbb {N})\) of (1.1) satisfies
for some constant c, where \(L = c \cdot \left( 1 + \frac{\sqrt{\log (6 \epsilon ^{-1})}}{\log (4KM \sqrt{s})} \right) \). If \(m_k = N_{k} - N_{k-1}\) for \(1 \le k \le r\) then this holds with probability 1.
This result allows one to exploit the asymptotic sparsity structure of most natural images under the wavelet transform. It was observed in Fig. 3 in [9] that the ratio of non-zero coefficients per level decreases very fast with increasing level and at the same time the level size increases. Hence, most images are not that sparse in the first levels and sampling patterns should adapt to that. However, they are very sparse in the higher levels. This difference in the sparsity is used in the theorem. The number of samples per level \(m_k\) depends mainly on the sparsity in the related level \(s_k\). The other sparsity terms \(s_l\) with \(l \ne k\) come in with a scaling of \(2^{-|k-l|}\). This means that the impact of levels which are far away decays exponentially.
The number of samples \(m_k\) in relation to the level size \(N_k - N_{k-1}\) also impacts the probability of an accurate reconstruction. Hence, in case the number of samples is very small the theorem still holds true but the probability that the algorithm succeeds becomes very small and the error large. Therefore, it is of high importance to choose the number of samples according to the desired accuracy and success probability. This is always a balancing act. The relationship also comes into play for the size of K. For large levels with very few measurements this value can become larger. Nevertheless, even if the largest levels are subsampled with only \(1\%\) we get that \(K = 100\). Additionally, the value K only comes into play in a logarithmic term. Therefore, the impact of K reduces to a reasonable size and the number of necessary samples or the relationship between N and M stays small.
Remark 2
For awareness of potential extensions of this work to higher dimensions or other reconstruction and sampling spaces we kept the factor \((N_k - N_{k-1})/N_{k-1}\) in (3.3). However, for the Walsh-wavelet case in one dimension this factor reduces to 1. Hence, the Equation (3.3) can be further simplified to
however, in general one needs the factor \((N_k - N_{k-1})/N_{k-1}\).
Remark 3
We would like to highlight the differences to the Fourier-wavelet case, i.e. to Theorem 6.2. in [9]. The most striking difference is the squared factor in (3.2). In the Fourier-wavelet case this is dependent on the smoothness of the wavelet and shown to be \( N \gtrsim M^{1 + 1/(2\alpha -1)} \cdot (\log (4MK\sqrt{s} ))^{1/(2\alpha -1)},\) where \(\alpha \) denotes the decay rate under the Fourier transform, i.e. the smoothness of the wavelet. For very smooth wavelets this can be improved to
Hence, for very smooth wavelets we get the optimal linear relation, beside log terms. However, for non-smooth wavelets like the Haar wavelet, we get a squared relation instead of linear. The reason why we do not observe a similar dependence on the smoothness in terms of the sampling relation is that smoothness of a wavelet does not relate to a faster decay under the Walsh transform. This is also related to the fact that for Fourier measurements (3.3) become
where \(A_{k,l}\) and \(B_{k,l}\) are positive numbers, \({\tilde{N}} = (K\sqrt{s})^{1+ 1/v} N\), where v denotes the number of vanishing moments, and \({\hat{s}}_k = \max \{s_{k-1},s_k,s_{k+1}\}.\) In particular, smoothness and vanishing moments of the wavelet does have an impact in the Fourier case, but not in the Walsh case. This is also confirmed in Fig. 1, where we have plotted the absolute values of sections of U, where U is the infinite matrix from (3.1). As can be seen in Fig. 1, the matrix U gets more block diagonal in the Fourier case with more vanishing moments confirming the dependence of \(\alpha \) and v in (3.4). Note that for a completely block diagonal matrix U the \(m_k\) in (3.4) will only depend on \(s_k\) and not any of the \(s_l\) when \(l \ne k\). In contrast this effect is not visible in the Walsh situation suggesting that the estimate in (3.3) captures the correct behaviour by not depending on \(\alpha \) and v. The reason why is that a function needs to be smooth in the dyadic sense to have a faster decay rate under the Walsh transform. However, this is not related to classical smoothness but dyadic smoothness. So far it is not known which wavelets behave better under the Walsh transform. Therefore, it is possible that the estimate is not sharp and that we can get faster decay rates for specific wavelet orders.
Finally, we want to highlight that this unknown relationship also leads to the squared factor in the relationship of N and M in (3.2). However, numerical examples in §5 suggest that this relation is not sharp. The experiments show that coefficients up to N can be reconstructed, hence it is possible to reconstruct images with a reduced relation between the maximal sample and the maximal reconstructed coefficient.

Absolute values of \(P_NUP_N\) with \(N = 256\), where U is the infinite matrix from (3.1), with boundary corrected Daubechies wavelets with different numbers of vanishing moments, and Walsh (upper row) and Fourier measurements (lower row). In the Fourier case, U becomes more block diagonal as smoothness and the number of vanishing moments increase. This is not the case in the Walsh setting, suggesting that the non-dependence of smoothness and order (if higher than \(p\ge 3\)) in the estimate (3.3) is correct
3.1 Connection to Related Works
Reconstruction methods are mainly divided in two major classes of linear and non-linear methods. For the linear methods generalized sampling [6] and the PBDW-method [52] are prominent examples.
Generalized sampling has evolved over time. The first closely related method is the finite section methods introduced and analysed in [17, 36, 38, 47]. This was further extended to consistent sampling investigated by Aldroubi et al. [11, 29,30,31,32, 65]. Finally generalized sampling has been studied by Adcock et al. in [3, 4, 6, 8, 39, 41, 49]. This works includes estimates for the general case of arbitrary sampling and reconstruction basis as well as more application focussed analysis.
The PBDW-method evolved from the work of Maday et al. in [51] first under the name generalized empirical interpolation method. This was then further analysed and extended to the PBDW-method by Binev et al. [15, 16, 27, 50, 52].
Both methods have in common that the relationship between the number of samples and reconstructed coefficients, the so called stable sampling rate (SSR), controls the numerical stability and accuracy. The SSR has to be analysed for different application with their related sampling and reconstruction bases. It was shown that the SSR is linear for the Fourier-wavelet [5], Fourier-shearlet [49] and Walsh-wavelet case [40]. However, this is not always the case as for the Fourier-polynomial situation [41].
In the non-linear setting the most prominent reconstruction technique is infinite-dimensional compressed sensing [18] with its extension to structured CS as introduced in [9]. Here, the analysis relies on the properties of the change of basis matrix and the sparsity of the signal. Early results have promoted random samples which have later been shown to be not as efficient for signals with a structured sparsity.
Similar to the linear methods the analysis for general sampling and reconstruction bases has been extended to the special applications. The Fourier case for different reconstruction systems has been analysed by Adcock et al. [7, 9, 44, 56, 57]. Closely related to the recovery guarantees in this paper the following guarantees have been provided. For the Fourier wavelet case we know uniform recovery guarantees [46] and non-uniform recovery guarantees [9, 10]. For Walsh measurements we have coherence estimates by Antun [12], uniform recovery guarantees from Adcock et al.[1] and an analysis for variable and multilevel density sampling strategies for the Walsh-Haar case and finite-dimensional signals by Moshtaghpour et al. [54]. In this paper we present the non-uniform results for the Walsh-wavelet case as has been studied for the Fourier case in [9, 10].
3.2 Sampling and Reconstruction Space
3.2.1 Sampling Space
We start with the sampling space. To model binary measurements Walsh functions have proven to be a good choice. They behave similar to Fourier measurements with the difference that they work in the dyadic rather than the decimal analysis. They also have an increasing number of zero crossing. This leads to the fact that the change of basis matrix U gets a block diagonal structure, as can be seen in Fig. 1. Moreover, it can be observed that U is asymptotic incoherent. The incoherence of the matrix together with the asymptotic sparsity can be exploited in the reconstruction part. However, the fact that sampling functions are defined in the dyadic analysis leads to some difficulties and specialities in the proof.

Different orderings of first 32 Walsh functions
Let us now define the Walsh functions, which form the kernel of the Hadamard matrix. Then we proceed with their properties and the definition of the Walsh transform.
Definition 4
(§9.2 [35]) Let \(z =\sum _{i\in \mathbb {Z}} z_i 2^{i-1}\) with \(n_i \in \left\{ 0,1 \right\} \) be the dyadic expansion of \(z \in \mathbb {R}_+\). Analogously, let \(x = \sum _{i \in \mathbb {Z}} x_i 2^{i-1}\) with the dyadic expansion \(x_i \in \left\{ 0,1 \right\} \). The generalized Walsh functions in \(L^2([0,1])\) are given by
This definition can also be extended to negative inputs by \({\text {Wal}}(-z,x) = {\text {Wal}}(z,-x) = -{\text {Wal}}(z,x)\). Walsh functions are one-periodic in the second input if the first one is an integer. The first input z is commonly denoted as parameter or sequency because of its relation to the number of zero crossings. For a fixed z the function is then treated like a one-dimensional function with its input x which could be interpreted as time as in the Fourier case.
The definition is extended to arbitrary inputs \(z \in \mathbb {R}\) instead of the more classical definition for \(z \in \mathbb {N}\). We would like to make the reader aware of different orderings of the Walsh functions. The one presented here is the Walsh-Kaczmarz ordering in Fig. 2a. It is ordered in terms of increasing number of zero crossings. This has the advantage that it relates nicely to the scaling of wavelets. Two other possible orderings are presented in [35]. We have Walsh-Paley in Fig. 2b with
and Walsh-Kronecker in Fig. 2c with
Both have the drawback that the number of zero crossings is not increasing. This is the reason why we are not able to get the block diagonal structure in the change of basis matrix and hence do not get as much structure to exploit. The Walsh-Kronecker ordering has another disadvantage and is not often used in practice. The definition of the function includes knowledge about the length d of the maximum sequence \(z_{\max } \le 2^d\) we are interested in. Depending on this value the function change also for smaller inputs \(z \le z_{\max }\), i.e. there is a third input d which also leads to changes. Hence, in case one wants to change the number of samples and also increase the largest value for the samples all functions and measurements have to be recomputed, which is undesirable in practice, where measurements are expensive and time consuming.
For the sampling pattern we divide the sequency parameter z into blocks of doubling size. This is a natural division for two reasons. First, the size of the smallest constant interval decreases after every block. Second and more importantly, these blocks relate nicely into the level structure of the wavelets, discussed in the following chapter. We can see in Fig. 1 that the blocks relate nicely to the visible block structure of the change of basis matrix U.
After the small excursion on orderings we now define the sampling space in one dimension by
where \(\overline{{\text {span}}}\) denotes the closure of the set of linear combinations of the elements. In general, it is not possible to acquire or save an infinite number of samples. Therefore, we restrict ourselves to the sampling space according to \(\Omega _{N,m}\) or \(\left\{ 1,\ldots ,N\right\} \), i.e.
The Walsh functions obey some interesting properties which have been shown in §2.2. in [40]: the scaling property, i.e. \({\text {Wal}}(2^jz,x) = {\text {Wal}}(z,2^jx)\) for all \(j \in \mathbb {N}\) and \(n, x \in \mathbb {R}\) and the multiplicative identity, i.e. \({\text {Wal}}(z,x){\text {Wal}}(z,y) = {\text {Wal}}(z,x \oplus y)\), where \(\oplus \) is the dyadic addition. With the Walsh functions we are able to define the continuous Walsh transform as a mapping from \(L^1([0,1]) \mapsto L^1([0,1])\) by
We will also use the notation \({\mathcal {W}}\) for the Walsh transform, similar to the Fourier operator \({\mathcal {F}}\), with
The properties from the Walsh functions are easily transferred to the Walsh transform. We state now some more statements about the Walsh functions and the Walsh transform, which are necessary for the main proof.
Lemma 1
(Cor. 4.3 [40]) Let \(t \in \mathbb {N}\) and \(x \in [0,1)\), then the following holds:
Remark that this only holds because x and t do not have non-zero elements in their dyadic representation at the same spot and therefore the dyadic addition equals the decimal addition. Next, we consider Walsh polynomials and see how we can relate the sum of squares of the polynomial to the sum of squares of its coefficients.
Lemma 2
(Lem. 4.6 [40]) Let \(A,B \in \mathbb {Z}\) such that \(A \le B\) and consider the Walsh polynomial \(\Phi (z) = \sum _{j=A}^{B} \alpha _{j} {\text {Wal}}(j,z)\) for \(z \in \mathbb {R}_+\). If \(L = 2^{n}\), \(n \in \mathbb {N}\) such that \(2L \ge B - A +1\), then
In the proof of Lemma 4 we analyse the inner product of the wavelets with the Walsh function. For this we will combine the shifts in the wavelet into a Walsh polynomial. With this lemma at hand this is then easily bounded.
3.2.2 Reconstruction Space
Next, we define the reconstruction space. As we are mainly interested in the reconstruction of natural signals in one dimension, we use Daubechies wavelets [53] and their boundary corrected versions [24]. They provide good smoothness and support properties. Moreover, they obey the Multi-resolution analysis (MRA). This results in the fact that the coefficients of natural signals obey a special sparsity structure with a lot of coefficients in the first part and fewer non-zero elements in the later coefficients.
We start with the definition of classical Daubechies wavelet and then discuss the restriction to boundary corrected ones. The wavelet space is described by the wavelet \(\psi \) at different levels and shifts \(\psi _{j,m}(x) = 2^{j/2} \psi (2^j x -m )\) for \(j, m \in \mathbb {N}\), i.e. we have the wavelet space at level j
They build a representation system for \(L^2(\mathbb {R})\), i.e. \(\overline{\bigcup _{j\in {\mathbb {N}}}} W_j = L^2({\mathbb {R}})\). For the MRA we also define the scaling function \(\phi \) and the according scaling space
where \(\phi _{j,m} (x) = 2^{j/2} \phi (2^j x - m)\). We then have that \(V_j = V_{j-1} \oplus W_{j-1}\) and \(L^2({\mathbb {R}}) = {\text {closure}}\left\{ V_{J} \oplus \bigcup _{j \ge J} W_{j} \right\} \). The Daubechies scaling function and wavelet have the same smoothness properties. Therefore, they also have the same decay rate under the Walsh transform. The decay rate is of high importance for the analysis of the properties of the change of basis matrix.
The classical definition of Daubechies wavelets has a large drawback for our setting. Normally, they are defined on the whole line \(\mathbb {R}\). Due to the fact that Walsh functions are defined on [0, 1] it is necessary to restrict the wavelets also to [0, 1]. Otherwise there will be elements in the reconstruction space which are not in the sampling space and therefore the solution could not be unique. Hence, we are using boundary corrected wavelets (§4 [24]).
For the definition of boundary wavelets, we have to correct those that intersect with the boundary. We start with the definition of the scaling space and continue with the wavelet space. For the discussion we consider for now the adaptation for the left boundary zero. If we remove all scaling functions which intersect with zero, the new function set does not even represent polynomial functions. Therefore, we have added the following functions.
These functions together with the translates of the scaling function with support on the positive line span all polynomials with degree smaller or equal to \(p-1\) on \([0,\infty )\), where p is the order of the scaling function. Next, we do the analogue for the right boundary. For this sake we first construct the functions for \((-\infty ,0]\) simply by mirroring the \(\widetilde{\phi }^{\text {left}}_n(x)\). To have the discussion on [0, 1] we shift the function to the right, such that we get
Now, consider the lowest level \(J_0\) such that the scaling functions do only intersect with one boundary 0 or 1, i.e. \(2^{J_0} \ge 2p-1\). Then the interior scaling functions together with the the newly defined functions span \(L^2([0,1])\). However, they are not orthogonal. Therefore, we apply the Gram-Schmidt procedure and obtain the function \(\phi ^{\text {right}}\) and \(\phi ^{\text {left}}\). The new functions have staggered support and a maximal support size of \(2p-1\) and hence still have the desired property of a small support. The new function system contains at every level \(2^j+2\) functions. However, in most applications it is desirable to only have \(2^j\) many. Therefore, we remove the two outermost inner scaling functions. The new scaling space at level j is given by:
where
The new system still obeys the MRA. Hence, the boundary wavelets can be deduced from the boundary corrected scaling functions as
Fortunately, we only need the smoothness properties of the wavelet, especially only the knowledge if the function is Lipschitz continuous, for the decay rate under the Walsh transform in Lemma 3. This is preserved also after the modification to the boundary corrected wavelets. The boundary wavelet will be denoted by \(\psi ^b\) and \(\psi _{j,m}^b(x) = 2^{j/2} \psi ^b (2^j x -m)\). Because we will use in the analysis the MRA property and hence replace the elements from the reconstruction space by the scaling function, as presented in the next paragraph, we do not need the details about the construction of the wavelet. The interested reader should seek out for [24] for a detailed analysis.
We now want to consider the reconstruction space. Let \(R \in \mathbb {N}\) and \(M=2^R\) than we have that the reconstruction space of size M is given by
This representation with the scaling function and wavelet suggests the ordering in different level according to the index j in the next Sect. 3.2.3.
It was proved in [24] that \(V_R\) can be spanned by the scaling function, its translates and the reflected version \(\phi ^\#(x) = \phi (-x+1)\), i.e.
With this representation of the reconstruction space we are able to present \(\varphi \in \mathcal {R}_M\) with \(||\varphi ||_2 =1\) as
Remark 4
We consider here only the case of Daubechies wavelets of order \(p \ge 3\) and \(p=1\), i.e. the Haar wavelet. The theory also holds for the case for order \(p=2\). Nevertheless, we get unpleasant exponents \(\alpha \) depending on the wavelet and different cases to consider. The results do not improve with more smoothness for the higher order wavelets. In contrast for the Haar wavelet, we can get even better estimates due to the perfect block structure of the change of basis matrix in that case. A detailed analysis of the relation between Haar wavelets and Walsh functions can be found in [63] and we discuss the recovery guarantees for this special case in §4.4.
For the evaluation of the change of basis matrix we investigate its elements, i.e. the inner product between the Walsh function and wavelet or scaling function, respectively. To ease this analysis we use the reconstruction space representation as in (3.6). This reduces the analysis to the scaling function. However, to avoid a lot of different cases we aim to take the shifts out of the inner product. To do this we will introduce Corollary 1. However, in the assumptions we have that \(t \in \mathbb {N}\) and \(x \in (0,1]\). And because we also transfer the scaling factor \(2^R\) out of the scaling function. The scaling function in level 0 has that its support is larger than [0, 1]. Therefore, Lemma 1 could not be used, i.e.
Therefore, we have to separate the scaling function into parts which have support in [0, 1]. Remark that this is not a contradiction to the construction of the boundary wavelets. They are indeed supported in [0, 1]. However, only from the beginning of the scaling \(J_0\) and not the scaling function at level 0. Therefore, we use the representation of the scaling function at level 0 from [40] as
and
This can also be done accordingly for the reflected function \(\phi ^\#\). More detailed information about this problem can be found in [40].
3.2.3 Ordering
We are now discussing the ordering of the sampling and reconstruction basis functions. We order the reconstruction functions according to the levels, as in (3.5). With this we get the multilevel subsampling scheme with the level structure. For this sake, we bring the scaling function at level \(J_0\) and the wavelet at level \(J_0\) together into one block of size \(2^{J_0+1}\). The next level constitutes of the wavelets of order \(J_0+1\) of size \(2^{J_0+1}\) and so forth. Therefore, we define
to represent the level structure of the reconstruction space. For the sampling space we use the same partition. We only allow by the choice of \(q \ge 0\) oversampling. Let
We then get for the reconstruction matrix U in (3.1) with \(u_{i,j} = \langle \omega _i, \varphi _j \rangle \) that \(\omega _j(x) = {\text {Wal}}(j,x)\) and for the first block we have
For the next levels, i.e. for \(i \ge 2^{J_0}\) we get for l with \(2^l \le i <2^{l+1}\) and \(m = i -2^l\) that \(\varphi _i = \psi _{l,m}^b\).
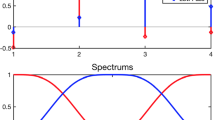
The proof of the main theorem relies mainly on the analysis of the change of basis matrix. Numerical examples and rigour mathematics [63] show that it is perfectly block diagonal for the Walsh-Haar case. And it is also close to block diagonality for other Daubechies wavelets, which can be seen in Fig. 1. We highlight the different parts of the change of basis matrix with respect to the ordering in Fig. 3.

Blocks for the ordering of Walsh functions in blue and wavelets in red (Color figure online)
An intuition about this phenomena is given in Fig. 4. We plotted Haar wavelets at different scales with Walsh functions at different sequencies. In Fig. 4a the scaling of the Haar wavelet is higher than the sequency of the Walsh function. Therefore, the Walsh function does not change the wavelet on its support and hence it integrates to zero. The next one Fig. 4b shows a wavelet and Walsh function at similar scale and sequency which relates to parts of the change of basis function in the inner block. Here, the two functions multiply nicely to get a non-zero inner product. Last, we have in Fig. 4c that the Walsh functions oscillate faster than the wavelet and hence the Walsh function is not disturbed by the wavelet and can integrate to zero.
Remark 5
The main theorem only holds for the case of one dimensional signals. One reason why it is difficult to extend the results to higher dimensions is the choice of the ordering. It is possible to use tensor products of the one dimensional basis functions to get a basis in higher dimensions. However, this includes that we have to tensor faster oscillating functions with slower oscillating ones. As a consequence one has an exponentially increasing number of non-zero or slow decaying coefficients to consider. This makes the analysis very cumbersome and probably also results in the curse of dimensionality in terms of the relationship of samples and reconstructed coefficients.

Intuition for block diagonal structure of the change of basis matrix with Haar wavelet \(\psi _{j,m}\) (red, dashed line) and Walsh functions of order n (blue) (Color figure online)
4 Proof of the Main Result
The proof of the main theorem relies on the investigation of the change of basis matrix as well as the relative sparsity of signals. With this analysis it is possible to use the results from [9] to prove the non-uniform recovery guarantees.
The section is structured as follows: We start with the definition of the analysis tools for the change of basis matrix and the signal. Then, we are able to present Theorem 5.3 from [9]. In section “key estimates” we evaluate the necessary analysis values for the Walsh-wavelet case, i.e. the local coherence, relative sparsity and strong balancing property. For the local coherence we use estimates from [1]. The analysis of the relative sparsity is related to the Fourier-Haar case in [10] and the proof techniques of Lemma 4 are similar to the ones in the main proof of [40]. For the final analysis of the relative sparsity also the previous estimate on the local coherence come into play. This is also the case for the estimate of \({\tilde{M}}\). Finally, the proof of the strong balancing property follows fast with the results from §4.2.2. In §4.3 these results are combined to get the main result.
Haar wavelets play a special role in the setting of Walsh functions, as they are structurally very similar. This is the reason why the main theorem can be shortened in this application. This is presented in the final subsection of this section.
4.1 Preliminaries
In this section we introduce Theorem 5.3 from [9]. To do so we first introduce the definitions of the different elements therein.
We start with the balancing property. To be able to solve (1.1) it is important that the uneven finite section of the change of basis matrix is close to an isometry. The balancing property controls the relation between the number of samples and reconstructed coefficients, such that the matrix \(P_N U P_M\) is close to an isometry.
Definition 5
(Def. 5.1 [7]) Let \(U \in {\mathcal {B}} ( \ell ^2(\mathbb {N}))\) be an isometry. Then \(N \in \mathbb {N}\) and \(K \ge 1\) satisfy the strong balancing property with respect to \(U,M \in \mathbb {N}\) and \(s \in \mathbb {N}\) if
where \(|| \cdot ||_{\ell ^\infty \rightarrow \ell ^\infty }\) is the norm on \({\mathcal {B}} (\ell ^\infty (\mathbb {N}))\).
This topic not only arises for the non-linear reconstruction but also for the linear reconstruction. In the finite-dimensional setting this is assured by the SSR. The SSR has been analysed for different applications, like Walsh-wavelet [40], Fourier-wavelet [5, 34] and Fourier-shearlet [49].
Next, we use the notation as in [9]. Let
In the rest of the analysis we are interested in the number of samples needed for stable and accurate recovery. This value depends besides known values on the local coherence and the relative sparsity which are defined next. We start with the (global) coherence.
Definition 6
(Def. 2.1 [9]) Let \(U = (u_{i,j})_{i,j=1}^N \in {\mathbb {C}} ^{N \times N}\) be an isometry. The coherence of U is
With this it is possible to define the local coherence for every level band.
Definition 7
(Def. 4.2 [9]) Let \(U \in {\mathcal {B}} ( \ell ^2(\mathbb {N}))\) be an isometry. The \((k,l)^{th}\) local coherence of U with respect to \(\mathbf {M}, \mathbf {N}\) is given by
We also define
The local coherence will be evaluated for the Walsh-wavelet case in Corollary 2 and Corollary 3.
Definition 8
(Def. 4.3 [9]) Let \(U \in {\mathcal {B}} ( \ell ^2(\mathbb {N}))\) be an isometry and \(\mathbf {s} = (s_1, \ldots , s_r) \in \mathbb {N}^r\) and \(1 \le k \le r\) the \(k^{th}\) relative sparsity is given by
with
We devote §4.2.2 to the analysis of the relative sparsity for our application type. The estimate can be found in Corollary 4.
After clarifying the notation and settings we are now able to state the main theorem from [9].
Theorem 2
(Theo. 5.3 [9]) Let \(U \in \mathcal {B}(\ell ^2(\mathbb {N}))\) be an isometry and \(x \in \ell ^1(\mathbb {N})\). Suppose that \(\Omega = \Omega _{N,m}\) is a multilevel sampling scheme, where \(\mathbf {N} = (N_1, \ldots , N_r) \in \mathbb {N}^r\) and \({\mathbf {m}} = (m_1, \ldots , m_r) \in \mathbb {N}^r\). Let \(({\mathbf {s}}, {\mathbf {M}})\), where \(\mathbf {M} = (M_1, \ldots , M_r) \in \mathbb {N}^r\), \(M_1< \ldots < M_r\) and \({\mathbf {s}} = (s_1, \ldots , s_r)\in \mathbb {N}^r\), be any pair such that the following holds:
-
(1)
The parameters
$$\begin{aligned} N = N_r , \quad K = \max _{k=1, \ldots , r} \left\{ \frac{N_{k}- N_{k-1}}{m_k} \right\} , \end{aligned}$$satisfy the strong balancing property with respect to \(U, M :=M_r\) and \(s:= s_1 + \ldots + s_r\);
-
(2)
For \(\epsilon \in (0, e^{-1}]\) and \(1 \le k \le r\),
$$\begin{aligned} 1 \gtrsim \frac{N_k - N_{k-1}}{m_k} \cdot \log (\epsilon ^{-1}) \left( \sum _{l=1}^r \mu _{\mathbf {N},\mathbf {M}}(k,l) s_l \right) \cdot \log (K \tilde{M} \sqrt{s}), \end{aligned}$$(4.3)(with \(\mu _{\mathbf {N},\mathbf {M}}(k,r)\) replaced by \(\mu _{\mathbf {N},\mathbf {M}}(k, \infty )\)) and \(m_k \gtrsim {\hat{m}} _k\log (\epsilon ^{-1})\log (K\tilde{M}\sqrt{s})\), where \({\hat{m}}_k \) is such that
$$\begin{aligned} 1 \gtrsim \sum _{k=1}^r \left( \frac{N_k - N_{k-1}}{{\hat{m}} _k} -1 \right) \cdot \mu _{\mathbf {N},\mathbf {M}} (k,l) {\tilde{s}} _k, \end{aligned}$$(4.4)for all \(l=1, \ldots , r\) and all \({\tilde{s}} _1, \ldots , {\tilde{s}} _r \in (0, \infty )\) satisfying
$$\begin{aligned} {\tilde{s}} _1 + \ldots + {\tilde{s}} _r = s_1 + \ldots + s_r, \quad {\tilde{s}} _k \le S_k(\mathbf {N}, {\mathbf {N}}, {\mathbf {s}}). \end{aligned}$$
Suppose that \(\xi \in \ell ^1(\mathbb {N})\) is a minimizer of (1.1). Then, with probability exceeding \(1 - s \epsilon \),
for some constant c and \(L = c \cdot \left( 1+ \frac{\sqrt{\log (6 \epsilon ^{-1})}}{\log (4KM\sqrt{s})} \right) \). If \(m_k = N_k - N_{k-1}\) for \(1 \le k \le r\) then this holds with probability 1.
It is a mathematical justification to use structured sampling schemes as discussed in [9] in contrast to the first compressed sensing results which promoted the use of random sampling masks [18, 28]. In the next section we will transfer this result to the Walsh-wavelet case. For this sake we investigate the previously defined values for this case.
4.2 Key Estimates
In this chapter we discuss the important estimates that are needed for the proof of Theorem 1. They are also interesting for themselves and allow a deeper understanding of the relation between Walsh functions and wavelets.
4.2.1 Local Coherence Estimate
For the local coherence we are interested in the largest value of section of U. For this investigation we need to gain insight into the value of \(|\langle \varphi , {\text {Wal}}(k,\cdot ) \rangle |\) for \(\varphi \) being a Daubechies wavelet and \(k \in \mathbb {N}\). Therefore, we start with restating the results about the decay rate of functions under the Walsh transform.
Lemma 3
(Lem. 4.7 [40]) Let \(\phi \) be the mother scaling function of order \(p \ge 3\) and \(\phi ^\#\) be its reflected version. Moreover, let \(\psi \) be the corresponding mother wavelet. Then we have that \(C_\varphi = \sup _{t \in \mathbb {R}} |\varphi '(t)|\) exist and
We denote by \(C_{\phi ,\psi }\) the maximum of \(\left\{ C_\phi , C_{\phi ^\#},C_\psi , \right\} \).
Remark that Lemma 4.7 is stated only for inputs of the type \(\frac{j}{L} + m\), where \(L= 2^R\) for some \(R \in \mathbb {N}\) and \(j =0, \ldots , L-1\). However, the proof lines follow equivalently for general inputs \(z \in \mathbb {R}\). Moreover, the constant \(C_\varphi \) can be easily reduced from the proof lines.
This Lemma is not explicitly used in the analysis of the local coherence. However, the next Theorem also relies on this knowledge. Moreover, we will use Lemma 3 for the relative sparsity.
Now, we recall Proposition 4.5 from [1] about the local coherence. Note that the local coherence has a different definition in [9] and [1]. We will continue to use the one from [9] and adapt the results from [1] accordingly.
Theorem 3
(Prop. 4.5 [1]) Let U be the change of basis matrix for Walsh functions and boundary wavelets of order \(p \ge 3\) and minimal wavelet decomposition \(J_0\). Moreover, let \(\mathbf {M}\) and \(\mathbf {N}\) as in (3.7) and (3.8). Then we have that
for the constant \(C_{\mu }>0\) independent of k, l.
Remark 6
The definition of the constant \(C_\mu \) is not given in detail in [1]. However, following the discussion in Lemma 6.5. therein together with the estimate from Lemma 3 we get that
Beside of bounding the first factor in the local coherenc estimate. This theorem can also be used to bound the second factor of the local coherence. Afterwards we combine both results to the estimate of the local coherences in Corollary 2 and 3.
Corollary 1
Let U be the change of basis matrix for the boundary Daubechies wavelets and Walsh functions. Moreover, let \({\mathbf {M}}\) and \({\mathbf {N}}\) be defined by (3.7) and (3.8). Then we have that
Proof
Recall that
Hence, we get that
Next, we use Theorem 3 to obtain
\(\square \)
With these two theorems at hand we can now give an estimate for the local coherence.
Corollary 2
Let \(\mu _{\mathbf {N},\mathbf {M}}(k,l)\) be as in (4.1). Then,
Proof
Combining the estimate from Theorem 3, the result in Corollary 1 and the definition of the local coherence in 7 we get
\(\square \)
Because of the infinite-dimensional setting we also have to estimate \(\mu _{\mathbf {N},\mathbf {M}}(k,\infty )\) from (4.2). This is done in the following Corollary.
Corollary 3
Let \(\mu _{\mathbf {N},\mathbf {M}}(k, \infty )\) as in (4.2). Then,
Proof
We have that
We know from Corollary 1 that \(\mu (P_{N_k}^{N_{k-1}}U) \le C_{\mu }2^{-(J_0 + k-1)}\). Remark that \(k<r\). Hence, we have with Theorem 3 and the independence of the oversampling parameter q that
We get
\(\square \)
Note that the same local coherence estimate was found for the Fourier-Haar case in [10].
4.2.2 Relative Sparsity Estimate
Now, we want to estimate the relative sparsity of the change of basis matrix U in the Walsh-wavelet case. This is important to bound the local sparsity terms \({\tilde{s}}_k\) in Equation (4.4) in Theorem 2. To do so we recall from Definition 8 that
With the estimate from [10] in §4.3. we get
where we use that
Hence, we need to bound \(||P_{N_k}^{N_{k-1}}U P_{M_l}^{M_{l-1}}||_2\). For this sake we first bound \(||P_N^\perp U P_M ||_2\) and \(||P_{N_k}^{N_{k-1}}U P_{M_l}^{M_{l-1}}||_2\) in a second step in Lemma 5. That is then finally used to bound the relative sparsity in Corollary 4.
Lemma 4
Let U be the change of basis matrix for the Walsh measurements and boundary wavelets of order \(p \ge 3\). Let the number of samples N be larger than the number of reconstructed coefficients M. Then we have that
where \(C_{rs} = (16p-8)^2\max \left\{ C_\phi ^2,C_{\phi ^\#}^2\right\} \) is dependent on the wavelet.
Proof
We start with bounding \(||P_N^\perp U P_M ||_2 \). We rewrite it as follows
This value gets smaller if N grows in relation to M. However, from a practical perspective it is desirable to take as few samples N with in contrast a large number M. For the further analysis we define the fraction of these two by \(S = \frac{M}{N}\).
We include for completeness the intermediate steps, which are similar to the proof of the main theorem in [40]. However, we believe that this allows us to give a deeper understanding. Especially, the constant \(C_{rs}\) is interesting to understand and to see what impacts its size.
We first use the MRA property to rewrite \(\varphi \in \mathcal {R}_M\) as the sum of the elements in the related scaling space. Take in mind at this point that we only consider values of \(M = 2^R\). Hence, we only jump from level to level. We have from (4.6) for \(\varphi \in \mathcal {R}_M\) with \(||\varphi ||_2=1\)
This reduces the problem of the sum of the inner products for the orthogonal projection from a lot of different wavelets to shifted scaling function at the same level. We have
Hence, we start with controlling the inner product \(\langle {\text {Wal}}(k,\cdot ), \phi _{R,n} \rangle \) and analogously \(\langle {\text {Wal}}(k,\cdot ),\phi _{R,n}^\# \rangle \). Our aim is to remove the scaling and the shift from the wavelet and get instead the product between the Walsh transform of the original mother wavelet and a Walsh polynomial. For this we follow the ideas in [40]. Remember first, from the discussion in §3.2.2 that the mother scaling function is divided into the sum of functions that are supported in [0, 1], i.e. \(\phi (x) = \sum \limits _{i=-p+2}^p \phi _i (x-i+1)\) with \(\phi _i(x) = \phi (x+i-1) \mathcal {X}_{[0,1]}(x)\) and hence
This allows us to only deal with \(\langle {\text {Wal}}(k,\cdot ), \phi _{i,R,n} \rangle \). We get with a variable change
Next, we use Lemma 1 to get the shift out of the integral. We then only deal with the integral between the mother wavelet and the Walsh function independent on the summation factor n. For this we have to make sure that the second input is positive. We define \(p_R : {\mathbb {Z}} \rightarrow \mathbb {N}\) to map z to the the smallest integer with \(p_R(z)2^R + z > 0\). This allows us to use Lemma 1 because \(x \in [0,1]\) and \(n + i -1 +2^R p_R(n+i-1) \in \mathbb {N}\). We get
With this we are able to represent the inner product of every shifted version of \(\phi _{i,R,n}\) with the Walsh function as product of the Walsh transform of \(\phi _i\) and a Walsh function which contains the shift information. In the following we want to rewrite the inner products such that we are left with a Walsh polynomial and the Walsh transform of the mother scaling function. For this define
We get
and
After this evaluation we can go back to estimate the norm of \(||P_N^\perp U P_M||_2\). We have
where we used the presentation of \(\varphi \) from (4.6) and the Cauchy-Schwarz inequality in the third line. After multiplying out the brackets we are left with
Because \(\phi \) and \(\phi ^\#\) share the same decay rate, it is sufficient to only deal with (4.7) and deduce the rest from it. To estimate these values, we use the one-periodicity of the Walsh functions. For this sake let \(M=2^R\). We always reconstruct a full level as we do not know in which part of the level the information is located.
It can be observed that we divide k in both functions by \(2^R\). We want to separate the input \(k/2^R\) into its integer and rational part. This allows us to use the one-periodicity of the Walsh function and to work for the decay rate of the wavelet under the Walsh function only with the major integer part. For this we replace \(k = mM +j\), where \(j = 0, \ldots , M-1\) and \(m \ge S = N/M\). This leads to
We estimate with Lemma 3 and the integral bound for series
Here \(C_\phi \) depends on the choice of the wavelet. In contrast to the Fourier case there is no known relationship between the smoothness of the wavelet and the decay rate or the behaviour of \(C_\phi \), as discussed in Remark 3.
To estimate the sum over the Walsh polynomials we use Lemma 2 and (4.6). We get similar to computations in [40], that
and hence
The analogue holds true for the \(\phi ^\#\) part. We again replace \(k = mM +j\) and obtain
With the same reasoning as in (4.8) we get
Finally, for the Walsh polynomial we have
We get together
When we now replace \(S = N/M\) and set \(C_{rs} = (16p-8)^2\max \left\{ C_\phi ^2,{C_{\phi ^\#}}^2\right\} \) we get
\(\square \)
In the next Lemma we estimate \(||P_{N_k}^{N_{k-1}}U P_{M_l}^{M_{l-1}}||_2^2\) using the previous result.
Lemma 5
Let U be the change of basis matrix given by the Walsh measurements and boundary wavelets of order \(p \ge 3\). Then we have that
where \(C_{\max } = \max \left\{ C_{\mu }, C_{rs} \right\} \).
Proof
We use similar estimates as in Corollary 2. We know from Lemma 4 that \(||P_N^\perp U P_M ||_2^2 \le C_{rs} \cdot \left( \frac{M}{N}\right) \), whenever \(N \ge M\). With this we get for \(k > l\):
where the first inequality enlarges the section of the matrix and with it the norm. This allows to use Lemma 4. The rest follows from the definition of \(M_l\) and \(N_{k-1}\) in §3.2.3. For \(l \ge k\) we get from Theorem 3
With this we conclude
Both equations combined lead to the desired estimate with \(C_{\max } = \max \left\{ C_{\mu }, C_{rs} \right\} \). \(\square \)
With this Lemma at hand we can now bound the relative sparsity \(S_k({\mathbf {N}}, {\mathbf {M}}, {\mathbf {s}})\).
Corollary 4
For the setting as before we have
Proof
With the estimates from and Equation (4.5) we get
The third inequality follows from the Cauchy-Schwarz inequality and the last line from the fact the notation of \(\sum _{l=1}^r 2^{-|k-l|/2}= C_k \le C_{\text {geo}}\) for all k. \(\square \)
4.2.3 Bounding \({\tilde{M}}\)
In the estimate of Theorem 2 we have the value \(\tilde{M}\). We aim to bound this value to reduce the number of free parameters. Hence, we estimate
We start with the following calculation with \(m = 2^{(J_0+n)} = M_{n} \ge N\)
Hence, for \(2^{(J_0 +n)} \ge C_{\mu } \cdot N \cdot \left( 32 K \sqrt{s} \right) ^2\) we have
Therefore,
4.2.4 Balancing Property
In this chapter we show that the first assumption of Theorem 2 is fulfilled.
For this sake, we use the results from the previous chapter, especially Lemma 4. We start with relating a bound on \(||P_N^\perp U P_M||_2\) to the relationship between N and M.
Corollary 5
Let \(\mathcal {S}\) and \(\mathcal {R}\) be the sampling and reconstruction space spanned by the Walsh functions and separable boundary wavelets of order \(p \ge 3\) respectively. Moreover, let \(M = 2^{R}\) with \(R \in \mathbb {N}\). Then, we get for all \(\theta \in (1, \infty )\)
whenever
Proof
Rewriting \(N \ge C_{rs} \cdot M \cdot \theta ^{-2}\) gives us
And hence with Lemma 4 and \(\theta >1\) we get
\(\square \)
With this at hand we can now proof the relation between N, M such that the strong balancing property is satisfied.
Lemma 6
For the setting as before N, K satisfy the strong balancing property with respect to U, M and s whenever \(N \gtrsim M^2 (\log (4MK\sqrt{s} ))\).
Proof
From Lemma 5 we have that \(||P_N^\perp U P_M ||_2 \le \frac{1}{8 \sqrt{M}} \left( \log ^{1/2}(4 KM \sqrt{s})\right) ^{-1}\) whenever it holds that \(N \gtrsim M^{2} \left( \log (4 KM \sqrt{s})\right) \). Using additionally that U is an isometry we get
For the second inequality we have that
The last inequality follows from the fact that K, M, s are integers and therefore \(\log (4KM\sqrt{s}) \ge 1\). Hence, the strong balancing property is fulfilled. \(\square \)
4.3 Proof of the Main Theorem
In this chapter we bring the previous results together to proof Theorem 1.
Proof of Theorem 1
We show that the assumptions of Theorem 5.3. in [9] are fulfilled. Moreover, we follow the lines of [10].
With Lemma 6 we have that N, K satisfy the strong balancing property with respect to U, M and s. Hence, point (2) in Theorem 2 is fulfilled.
The last two steps show that (4.3) and (4.4) are fulfilled and Theorem 2 can be applied. We have
where we used the estimate of \(\mu _{\mathbf {N},\mathbf {M}}\) from Corollary 2 and 3, (3.3) and (4.9). Moreover, \( C_{\mu }\) is independent of \(k,l,{\mathbf {M}},{\mathbf {N}},{\mathbf {s}}\). Therefore,
and Equation (4.3) is fulfilled. Now, we consider Equation (4.4) we directly estimate \(\mu _{{\mathbf {N}},{\mathbf {M}}}(k,l)\) for \(k<r\) directly without the \(2^{-1/2}\) term to keep the sum notation.
Due to the fact that the geometric series is bounded we have
We are left with bounding \(\tilde{s_k}/\hat{m}_k\) for all \(k=1,\ldots ,r\). Denote the constant from \(\lesssim \) in Theorem 2 by C. With the estimate in Corollary 4 we can then bound \(\tilde{s_k}\) with (3.3) by
All together yields
\(\square \)
4.4 Recovery guarantees for the Walsh-Haar case
In this section we pay attention to the Walsh-Haar case. This relationship is of high interest because of the very similar behaviour of Walsh functions and Haar wavelets. As seen earlier this results in perfect block diagonality of the change of basis matrix, see Fig. 1a. This block diagonal structure has been analysed in [63] with a focus on its impact on linear reconstruction methods. In contrast to general Daubechies wavelets it is possible to evaluate the inner product between the Walsh function and Haar wavelet and scaling function exactly.
Lemma 7
(Lem. 1 [63]) Let \(\psi = \mathcal {X}_{[0,1/2]} - \mathcal {X}_{(1/2,1]}\) be the Haar wavelet. Then, we have that
For the scaling function we have
Lemma 8
(Lem. 2 [63]) Let \(\phi = \mathcal {X}_{[0,1]}\) be the Haar scaling function. Then, we have that the Walsh transform obeys the following block and decay structure
The order does not change from the one for general Daubechies wavelets and each level j contains \(2^j\) many elements. Due to the structure of the change of basis matrix U in the Walsh-Haar case, the off diagonal blocks do not impact the coherence and sparsity structure at one level. Therefore, the number of samples per level only depends on the incoherence in this given level and the relative sparsity within. With this the main theorem simplifies for the Walsh-Haar case to the next Corollary.
Corollary 6
Let the notation be as before, but let the wavelet be the Haar wavelet. Moreover, let \(\epsilon >0\) and \(\Omega = \Omega _{N,m}\) be a multilevel sampling scheme such that:
-
(1)
The number of samples is larger or equal the number of reconstructed coefficients, i.e. \(N \ge M\).
-
(2)
Let \(K = \max _{k=1, \ldots , r} \left\{ \frac{N_k - N_{k-1}}{m_k} \right\} \), \(M=M_r\), \(N=N_r\) and \(s= s_1 + \ldots + s_r\) and for each \(k=1,\ldots ,r\):
$$\begin{aligned} m_k \gtrsim \log (\epsilon ^{-1})\log (K \sqrt{s} N) \cdot s_k. \end{aligned}$$
Then, with probability exceeding \(1-s\epsilon \), any minimizer \(\xi \in \ell ^1(\mathbb {N})\) satisfies
for some constant c, where \(L = c \cdot \left( 1 + \frac{\sqrt{\log (6 \epsilon ^{-1})}}{\log (4KM \sqrt{s})} \right) \). If \(m_k = N_{k} - N_{k-1}\) for \(1 \le k \le r\) then this holds with probability 1.
Proof
The proof is separated in two parts. We first evaluate the analysis tools for the Walsh-Haar case. Second, we conclude that under our assumptions the requirements of theorem 2 are fulfilled, i.e. the balancing propery, equation (4.3) and (4.4).
For the analysis of the balancing property, let \(M=2^R\) and \(\varphi \in \mathcal {R}_M\) be represented as \(\varphi = \sum _{j =0}^{2^R-1} \alpha _j \phi _{R,j}\) with \(\sum _{j =0}^{2^R-1} |\alpha _j|^2 = 1\). Then we have for \(N \ge M\) that
because \(k > N \ge M = 2^R\) such that Lemma 8 applies. Hence, the balancing property is satisfied for any K and with it assumption (2) in 2 is fulfilled.
Next, we analyse \({\tilde{M}}\).
we have for \(m = 2^R + j\) with \(j \le 2^R-1\) that
We obtain that the minimal i is achieved for \(m = 2^{R+1}\) and therefore \(\tilde{M} =2N\). Similar to the above discussion we get that \(\mu _{{\mathbf {N}},{\mathbf {M}}} (k,l) = 0\) for \(k \ne l\). This removes the sum in (4.3) in theorem 2.
For the second Eq. (4.4) we get with the general estimate of the relative sparsity in Eq. (4.10)
With this we have seen that all assumptions of theorem 2 are fulfilled and the recovery is guaranteed. \(\square \)

Original functions

5 Numerical Experiments
In this section we demonstrate how the theoretical results can be used in practice. We investigate the reconstruction of two signals with different smoothness properties. We start the analysis with the impact of the sampling bandwidth N if we keep the number of samples constant. Further we compare the reconstruction with CS to the application of the inverse Walsh transform to the subsampled data. This highlights the subsampling possibilities of the method. Related to the discussion in Remark 3 we investigate the experimental differences between Fourier and Walsh measurements. Finally, we illustrate the importance of the structure of the sampling pattern with the flip test as introduced in [9].
To see the impact of the sparsity of the signal we consider two functions. We have
and
The first function is very smooth and hence obeys only very few non-zero coefficients in the wavelet domain which all are located in the first levels. In contrast the function g has a discontinuity at 0.5. This results to non-zero elements in the wavelet domain also in higher levels and hence a larger M for perfect or near perfect reconstruction. The sparsity structure of natural images behaves equally. The more discontinuities a signal has the more higher level coefficients need to be reconstructed. Therefore, a prior analysis on the signals that will be reconstructed is important, even though all natural signals have the same coefficient structure with a few very large ones in the beginning and fewer in the high levels. It only differs in the number of higher level coefficients. This can be seen for the two examples. For both functions we have that the first level is not sparse, and we therefore need to sample \(m_1\) fully. However, for \(m_k\) with \(k \ge 2\) we can use the main theorem and reduce the number of samples \(|m| = \sum _{k=1}^r m_k\). The sampling pattern is chosen such that the first level is sampled fully and that the rest of the possible samples is divided equally on all \(m_k\) and hence independent on the size of the level.
For the implementation of the optimization problem (1.1) we have chosen \(L = 2^{12}\) it can be observed that the reconstruction does not change from \(L=2^{10}\) onwards. Therefore, it can be assumed that the algorithm has converged at this point and that this finite setting resembles the infinite setting. We can see that the location of the highest level coefficients only depends on the choice of N. The code for the numerical experiments relies on the cww Matlab package for the reconstruction of wavelet coefficients from Walsh samples by Antun in [14]. The optimization problem is solved with SPGL-1 from Antun available at [13]. We adapted the code to include the infinite setting. It can be found in [62]. The wavelet in use is the Daubechies wavelet with \(p=4\) vanishing moments.
In Fig. 7 the reconstruction of g from \(|m|=256\) is presented for different choices of N. The related sampling pattern are shown in Fig. 6. The aim of this experiment is to show the impact of the balancing property. Hence, how the choice of N effects M the coefficient bandwidth. To make this more visible we have plotted the wavelet coefficients of the reconstruction next to the reconstructed signals. It can be seen that the coefficients with numbering larger than N cannot be reconstructed with CS. However, it can also be seen that the square relation between N and M in the balancing property in (3.2) is not sharp as we are able to reconstruct coefficients larger than \(\sqrt{N}\). The decay of the error terms with increasing N can be seen in Fig. 8f. Without increasing the number of samples we can decrease the error term in the reconstruction for CS and improve over the directed inversion of the samples.

Reconstruction of the signal g with \(|m| = 256\) and varying choices of N to visualize the impact of N on the maximal wavelet coefficients

CS reconstruction of f with its wavelet coefficients. TW reconstruction for f and g from the same number of samples as used in CS. CS and truncated Walsh series error values with \(|m| = 64\) for f and \(|m|=256\) for g. The x-axis represents the sampling bandwidth \(N=2^R\) and the y-axis the relative error term in the \(\ell _2\) norm
In Figs. 8a, b and 8e we see the related experiments for the continuous signal f. The signal only obtains a few non-zero coefficients in the first levels. Therefore, the increased number of N does not change the error or reconstruction which is already for the smallest choice \(N=2^6\) nearly invisible. That is the reason why we did not show the reconstruction for \(N=2^7, 2^8\) as there is no visible difference. But also in this case it can be seen that we only reconstruct coefficients indexed smaller than N but still larger than \(\sqrt{N}\) which implies that the bound for the balancing property is also not sharp in the continuous and very sparse setting.
After the analysis of the impact of the balancing property on the reconstruction, we show how the number of samples influences the reconstruction. As it has been shown in the main theorem we have to control two parts the balancing property which mainly aims at the bandwidth of the samples N and the related bandwidth of the reconstructed coefficients M. Here, the number of coefficients in each level is not considered. This is part of the second requirement on the number of samples in each level \(m_k\). It has been seen that beside other logarithmic factors this mainly depends on the sparsity \(s_k\) in that level and with exponentially decaying impact also on the sparsity in the neighbouring levels. It can be seen that the discontinuous function g has wavelet coefficients in higher levels. However, in every level there are only one or two and hence the signal is very sparse in those higher levels. This can be exploited to reduce the number of samples drastically as in Fig. 9b. Even though the error increases a small amount we were able to reduce the number of samples by to 64 and this is only \(25\%\) of the previous number of samples. In this case the contrast to the truncated Walsh transform gets even more obvious as in Fig. 9d. The continuous function in contrast has only non-zero coefficients until \(M=64\) however it is not very sparse up to this number. Therefore, the reconstruction from even less samples \(|m|=32\) obeys more artefacts than before, see Fig. 9a. Nevertheless, the general structure is still more visible than with the direct Walsh inverse transform in Fig. 9c.

CS and truncated Walsh series error values with \(|m| = 32\) for f and \(|m| = 64\) for g

CS reconstruction from Fourier samples and Walsh samples for Daubechies wavelets with 2 and 6 vanishing moments. The experiment is set up with \(N=2^{10}\), \(L=2^{13}\) and \(|m| = 128\) and \(|m|=256\). The relative \(\ell _2\)-error is denoted by \(\epsilon \)
The conducted experiments can be compared to the Fourier setting. In Remark 3 we have discussed the relationship between the theoretical results for both sampling modalities. It is important to recall that the theorems offer sufficient conditions for the reconstruction. Therefore, the theoretical differences do not have to become visible in the experiments. Nevertheless, we want to discuss the different aspects of the theory and what we can observe in numerical experiments. The code to produce the Fourier experiments is an adaptation of the one discussed in [34] and available at [62]. The most obvious difference is the squared versus linear relationship in the estimate of the balancing property. It has been shown in the previous examples that these bounds are not sharp for the Walsh setting. Hence, the difference in the balancing property cannot be observed in numerical experiments. Next, we know from the theory that the smoothness of the wavelet impacts the decay rate under the Fourier transform but not for the Walsh transform. This difference is clearly visible in the reconstruction matrix, see Fig. 1. Finally, there is also a difference in the number of necessary samples per level because of the number of vanishing moments. With more vanishing moments the impact of the other levels decreases exponentially for the Fourier case. Additionally, the location of the non-zero elements in the coefficient vector changes with the choice of the wavelet. In Fig. 10 we have illustrated the results of the reconstruction of the same function for Fourier measurements and Walsh measurements with wavelets of two different vanishing moments and also changing number of samples. The illustration shows us that for a small number of samples the reconstruction with Fourier gives better results and gives smaller relative error as well as less visible artefacts. However, for a large enough sampling size the reconstructions are in both cases very close to the original function. Moreover, it is possible to see that the different wavelets tend to different artefact types. It can be observed that the wavelets with 2 vanishing moments are able to recover the discontinuity very well and have less ringing artefacts around it in contrast to the case of wavelets with 6 vanishing moments. However, in the smoother areas the reconstruction with fewer vanishing moments leads to more artefacts as can be seen in Fig. 10a, b.
Finally, we demonstrate that the structure of the signal coefficients and the change of basis matrix are very important. For this sake we conducted the same experiment for the continuous function f with a flipped sampling pattern, see Fig. 11b. The reconstruction is nowhere close to perfect and the original signal is not even identifiable. Hence, it is important to take the structure into account.
The experiments show that both parts the number of samples per level and the balancing property are important for the success of the method. For the practical application it is very helpful to be able to estimate beforehand the size of M as well as the sparsity per level.

Reconstruction of f with flipped samples with \(N=2^8\) and \(|m|=64\)
6 Conclusion
In this paper we have analysed the reconstruction of a one-dimensional signal from binary measurements with structured CS. We gave non-uniform recovery guarantees for the reconstruction with boundary corrected Daubechies wavelets. Additionally, we showed the numerical gains and the problems that arise when the theory is not taken into account.
These result fit nicely in the theory of non-linear reconstruction. We now have knowledge about uniform and non-uniform recovery guarantees for two of the major measurement types: Fourier and binary with Daubechies wavelets. For the future it would be of interest to investigate the theory for Radon measurements. Additionally, the bounds for the recovery guarantees are not tight and hence it might be possible to improve them. This relates closely to the question which wavelet type is most suitable for the reconstruction from binary measurements. This, however, is so far not known. Therefore, a further investigation of the relationship between the different wavelet types and Walsh functions would be of interest as numerical experiments suggest that there exists a difference.
References
Adcock, B., Antun, V., Hansen, A.C.: Uniform recovery in infinite-dimensional compressed sensing and applications to structured binary sampling. arXiv preprint arXiv:1905.00126 (2019)
Adcock, B., Hansen, A.: Stable reconstructions in hilbert spaces and the resolution of the gibbs phenomenon. Appl. Comput. Harmon. Anal. 32(3), 357–388 (2012)
Adcock, B., Hansen, A., Kutyniok, G., Ma, J.: Linear stable sampling rate: optimality of 2d wavelet reconstructions from Fourier measurements. SIAM J. Math. Anal. 47(2), 1196–1233 (2015)
Adcock, B., Hansen, A., Poon, C.: Beyond consistent reconstructions: optimality and sharp bounds for generalized sampling, and application to the uniform resampling problem. SIAM J. Math. Anal. 45(5), 3132–3167 (2013)
Adcock, B., Hansen, A., Poon, C.: On optimal wavelet reconstructions from Fourier samples: linearity and universality. Appl. Comput. Harmon. Anal. 36(3), 387–415 (2014)
Adcock, B., Hansen, A.C.: A generalized sampling theorem for stable reconstructions in arbitrary bases. J. Fourier Anal. Appl. 18(4), 685–716 (2010)
Adcock, B., Hansen, A.C.: Generalized sampling and infinite-dimensional compressed sensing. Found. Comput. Math. 16(5), 1263–1323 (2016)
Adcock, B., Hansen, A.C., Poon, C.: On optimal wavelet reconstructions from Fourier samples: linearity and universality of the stable sampling rate. Appl. Comput. Harmon. Anal. 36(3), 387–415 (2014)
Adcock, B., Hansen, A. C., Poon, C., Roman, B.: Breaking the coherence barrier: A new theory for compressed sensing. In Forum of Mathematics, Sigma, volume 5. Cambridge University Press (2017)
Adcock, B., Hansen, A.C., Roman, B.: A note on compressed sensing of structured sparse wavelet coefficients from subsampled Fourier measurements. IEEE Signal Process. Lett. 23(5), 732–736 (2016)
Aldroubi, A., Unser, M.: A general sampling theory for nonideal acquisition devices. IEEE Trans. Signal Process. 42(11), 2915–2925 (1994)
Antun, V.: Coherence estimates between hadamard matrices and daubechies wavelets. Master’s thesis, University of Oslo (2016)
Antun, V.: Spgl1. https://github.com/vegarant/spgl1 (2017)
Antun, V.: cww-generalized sampling with walsh sampling. https://github.com/vegarant/cww, (2019)
Bachmayr, M., Cohen, A., DeVore, R., Migliorati, G.: Sparse polynomial approximation of parametric elliptic PDESD. Part II: lognormal coefficients. ESAIM 51(1), 341–363 (2017)
Binev, P., Cohen, A., Dahmen, W., DeVore, R., Petrova, G., Wojtaszczyk, P.: Data assimilation in reduced modeling. SIAM/ASA J. Uncertain. Quant. 5(1), 1–29 (2017)
Böttcher, A.: Infinite matrices and projection methods: in lectures on operator theory and its applications, fields inst. Am. Math. Soc 3, 1–27 (1996)
Candès, E., Romberg, J., Tao, T.: Robust uncertainty principles: exact signal reconstruction from highly incomplete Fourier information. IEEE Trans. Inform. Theory 52, 489–509 (2006)
Candès, E.J., Demanet, L.: Curvelets and Fourier integral operators. C. R. Acad. Sci. 336(1), 395–398 (2003)
Candès, E.J., Donoho, D.: New tight frames of curvelets and optimal representations of objects with piecewise \(c^2\) singularities. Commun. Pure Appl. Math. 57(2), 219–266 (2004)
Candès, E.J., Donoho, L.: Recovering edges in ill-posed inverse problems: optimality of curvelet frames. Ann. Stat. 30(3), 784–842 (2002)
Choi, K., Boyd, S., Wang, J., Xing, L., Zhu, L., Suh, T.S.: Compressed sensing based cone-beam computed tomography reconstruction with a first-order method. Med. Phys. 37(9), 5113–5125 (2010)
Clemente, P., Durán, V., Tajahuerce, E., Andrés, P., Climent, V., Lancis, J.: Compressive holography with a single-pixel detector. Opt. Lett. 38(14), 2524–2527 (2013)
Cohen, A., Daubechies, I., Vial, P.: Wavelets on the interval and fast wavelet transforms. Comput. Harmon. Anal. 1(1), 54–81 (1993)
Dahlke, S., Kutyniok, G., Maass, P., Sagiv, C., Stark, H.-G., Teschke, G.: The uncertainty principle associated with the continuous shearlet transform. Int. J. Wavelets Multiresolut. Inf. Process. 2(6), 157–181 (2008)
Dahlke, S., Kutyniok, G., Steidl, G., Teschke, G.: Shearlet coorbit spaces and associated banach frames. Appl. Comput. Harmon. Anal. 2(27), 195–214 (2009)
DeVore, R., Petrova, G., Wojtaszczyk, P.: Data assimilation and sampling in banach spaces. Calcolo 54(3), 963–1007 (2017)
Donoho, D.L.: Compressed sensing. IEEE Trans. Inform. theory 52(4), 1289–1306 (2006)
Dvorkind, T., Eldar, Y.C.: Robust and consistent sampling. IEEE Signal Process. Lett. 16(9), 739–742 (2009)
Eldar, Y.C.: Sampling with arbitrary sampling and reconstruction spaces and oblique dual frame vectors. J. Fourier Anal. Appl. 9(1), 77–96 (2003)
Eldar, Y.C.: Sampling without input constraints: consistent reconstruction in arbitrary spaces. Sampling, Wavelets and Tomography (2003)
Eldar, Y.C., Werther, T.: General framework for consistent sampling in hilbert spaces. Int. J. Wavelets Multiresolut. Inf. Process. 3(4), 497–509 (2005)
Foucart, S., Rauhut, H.: A Mathematical Introduction to Compressive Sensing. Springer, New York (2013)
Gataric, M., Poon, C.: A practical guide to the recovery of wavelet coefficients from Fourier measurements. SIAM J. Sci. Comput. 38(2), A1075–A1099 (2016)
Gauss, E.: Walsh Funktionen für Ingenieure und Naturwissenschaftler. Springer Fachmedien, Wiesbaden (1994)
Gröchenig, K., Rzeszotnik, Z., Strohmer, T.: Quantitative estimates for the finite section method and banach algebras of matrices. Integral Equ. Oper. Theory 2(67), 183–202 (2011)
Guerquin-Kern, M., Häberlin, M., Pruessmann, K., Unser, M.: A fast wavelet-based reconstruction method for magnetic resonance imaging. IEEE Trans. Med. Imaging 30(9), 1649–1660 (2011)
Hansen, A.C.: On the approximation of spectra of linear operators on hilbert spaces. J. Funct. Anal. 8(254), 2092–2126 (2008)
Hansen, A.C.: On the solvability complexity index, the \(n\)-pseudospectrum and approximations of spectra of operators. J. Am. Math. Soc. 24(1), 81–124 (2011)
Hansen, A.C., Thesing, L.: On the stable sampling rate for binary measurements and wavelet reconstruction. Appl. Comput. Harmon. Anal. 48(2), 630–654 (2020)
Hrycak, T., Gröchenig, K.: Pseudospectral Fourier reconstruction with the modified inverse polynomial reconstruction method. J. Comput. Phys. 229(3), 933–946 (2010)
Huang, G., Jiang, H., Matthews, K., Wilford, P.: Lensless imaging by compressive sensing. In 2013 IEEE International Conference on Image Processing, pp. 2101–2105. IEEE (2013)
Jones, A., Tamtögl, A., Calvo-Almazán, I., Hansen, A.C.: Continuous compressed sensing for surface dynamical processes with helium atom scattering. Nat. Sci. Rep., 6:27776 EP–06 (2016)
Kutyniok, G., Lim, W.-Q.: Optimal compressive imaging of Fourier data. SIAM J. Imaging Sci. 11(1), 507–546 (2018)
Leary, R., Saghi, Z., Midgley, P.A., Holland, D.J.: Compressed sensing electron tomography. Ultramicroscopy 131, 70–91 (2013)
Li, C., Adcock, B.: Compressed sensing with local structure: uniform recovery guarantees for the sparsity in levels class. Appl. Comput. Harmon. Anal. (2017)
Lindner, M.: Infinite Matrices and Their Finite Sections: An Introduction to the Limit Operator Method. Birkhäuser, Basel (2006)
Lustig, M., Donoho, D., Pauly, J.M.: Sparse MRI: the application of compressed sensing for rapid MR imaging. Magnet. Resonan. Med. 58(6), 1182–1195 (2007)
Ma, J.: Generalized sampling reconstruction from Fourier measurements using compactly supported shearlets. Appl. Comput. Harmon. Anal. 6(1), 1–52 (2015)
Maday, Y., Anthony, T., Penn, J.D., Yano, M.: PBDW state estimation: noisy observations; configuration-adaptive background spaces; physical interpretations. ESAIM 50, 144–168 (2015)
Maday, Y., Mula, O.: A generalized empirical interpolation method: application of reduced basis techniques to data assimilation. In Analysis and Numerics of Partial Differential Equations, pp 221–235. Springer (2013)
Maday, Y., Patera, A.T., Penn, J.D., Yano, M.: A parameterized-background data-weak approach to variational data assimilation: formulation, analysis, and application to acoustics. Int. J. Numer. Methods Eng. 102(5), 933–965 (2015)
Mallat, S.: A Wavelet Tour of Signal Processing. Academic Press, San Diego (1998)
Moshtaghpour, A., Bioucas-Dias, J.M., Jacques, L.: Close encounters of the binary kind: Signal reconstruction guarantees for compressive hadamard sampling with haar wavelet basis. IEEE Trans. Inform. Theory (2020)
Müller, M.: Introduction to Confocal Fluorescence Microscopy. SPIE, Bellingham (2006)
Poon, C.: A consistent and stable approach to generalized sampling. J. Fourier Anal. Appl. 20, 985–1019 (2014)
Poon, C.: Structure dependent sampling in compressed sensing: theoretical guarantees for tight frames. Appl. Comput. Harmon. Anal. 42(3), 402–451 (2017)
Quinto, E. T.: An introduction to X-ray tomography and Radon transforms. In The Radon Transform, Inverse Problems, and Tomography, vol. 63, pp. 1–23. American Mathematical Society (2006)
Shannon, C.: A mathematical theory of communication. Bell Syst. Tech. J. 27(379–423), 623–656 (1948)
Studer, V., Bobin, J., Chahid, M., Mousavi, H.S., Candes, E., Dahan, M.: Compressive fluorescence microscopy for biological and hyperspectral imaging. Proc. National Acad. Sci. 109(26), E1679–E1687 (2012)
Sun, T., Woods, G., Duarte, M.F., Kelly, K., Li, C., Zhang, Y.: Obic measurements without lasers or raster-scanning based on compressive sensing. In Int. Symposium for Testing and Failure Analysis (ISTFA), San Jose, CA, pp. 272–277 (2009)
Thesing, L.: infcs. https://github.com/laurathesing/infCS (2020)
Thesing, L., Hansen, A.C.: Linear reconstructions and the analysis of the stable sampling rate. Sampl. Theory Image Process. 17(1), 103–126 (2018)
Unser, M.: Sampling - 50 years after shannon. Proc. IEEE 4(88), 569–587 (2000)
Unser, M., Zerubia, J.: A generalized sampling theory without band-limiting constraints. IEEE Trans. Circuits Syst. II. 45(8), 959–969 (1998)
Acknowledgements
LT acknowledges support by the UK Engineering and Physical Sciences Research Council (EPSRC) grant EP/L016516/1 for the University of Cambridge Centre for Doctoral Training, the Cambridge Centre for Analysis. AH acknowledges support from a Royal Society University Research Fellowship
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Holger Rauhut.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Thesing, L., Hansen, A.C. Non-uniform Recovery Guarantees for Binary Measurements and Infinite-Dimensional Compressed Sensing. J Fourier Anal Appl 27, 14 (2021). https://doi.org/10.1007/s00041-021-09813-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00041-021-09813-6