
Abstract
Objectives
To systematically review the literature and compare response rates (RRs) of web surveys to alternative data collection methods in the context of epidemiologic and public health studies.
Methods
We reviewed the literature using PubMed, LILACS, SciELO, WebSM, and Google Scholar databases. We selected epidemiologic and public health studies that considered the general population and used two parallel data collection methods, being one web-based. RR differences were analyzed using two-sample test of proportions, and pooled using random effects. We investigated agreement using Bland-and-Altman, and correlation using Pearson’s coefficient.
Results
We selected 19 studies (nine randomized trials). The RR of the web-based data collection was 12.9 percentage points (p.p.) lower (95% CI = − 19.0, − 6.8) than the alternative methods, and 15.7 p.p. lower (95% CI = − 24.2, − 7.3) considering only randomized trials. Monetary incentives did not reduce the RR differences. A strong positive correlation (r = 0.83) between the RRs was observed.
Conclusions
Web-based data collection present lower RRs compared to alternative methods. However, it is not recommended to interpret this as a meta-analytical evidence due to the high heterogeneity of the studies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Much of the epidemiologic and public health findings are dependent on interviewing individuals. The main objective of the interviews is to produce a combined estimate that can be generalized to a broader population. To achieve this goal, it is very important to reduce the total survey error (TSE) (Biemer 2010). One of the main components of the TSE is the nonresponse error, which is the failure to obtain data from all the members of a sample (Groves 2004). If the non-respondents are different from the respondents on characteristics that are important to the study objectives, this could skew the results and limit the generalization of the findings (Beebe et al. 2012; Keiding and Louis 2016). The nonresponse error is related to the survey response rate (RR), as low RRs increase the probability of occurring this error (Groves 2004). Recently, epidemiologic and public health studies are facing a constant reduction on their RRs, which lies between one (Morton et al. 2006) and two percentage points (p.p.) per year (Wallander et al. 2015). Several aspects can influence the RR, including the data collection method (Galea and Tracy 2007).
Face-to-face interviews are commonly used to collect data; however, the complicated logistics and the elevated costs are turning this methodology prohibitive (Dillman et al. 2014). Questionnaires sent via mail are also widely used among high-income populations, where the mailing system works and the costs related to printing and sending questionnaires via traditional mail are not a problem (Hardigan et al. 2012). Another data collection method is the telephone, which involves simple logistics but is compromised by the massive reduction of landline phones (Blumberg et al. 2013). The Internet is a natural candidate to overcome the disadvantages of the alternative data collection methods, as its coverage is in constant growth worldwide (The World Bank 2018). Web surveys are defined as instruments located in a server in the World Wide Web (WWW), where the questionnaire lies in a web page and is accessed using a web browser (Bethlehem and Biffignandi 2012). This method can facilitate the logistics (Sax et al. 2003) and reduce costs, since there is only the survey setup cost, which does not increase with the number of persons interviewed (Hardigan et al. 2012).
The number of epidemiologic and public health surveys using the web to collect data is growing. From 2007 to 2014, there was a 400% increase on the number of randomized trials using the web (Brice et al. 2015). However, the web still is a novel approach to collect epidemiologic data; thus, it is important to compare the quality of web surveys to alternative data collection methods. There are several survey quality factors that constitute the TSE, but in this study, we will focus on the nonresponse component and use the RR as its indicator.
The goal of this study was to systematically review the epidemiologic and public health literature to compare RRs of web surveys and alternative data collection methods applied to the general population, and check whether there is enough evidence about how the different approaches differ in relation to this indicator.
Methods
The literature review was based on PubMed, LILACS, SciELO, WebSM, and Google Scholar databases. The search ended in March-2017 and was limited to human populations. No date limit or language restriction was used. The list of references of all selected articles was checked to find potential studies of interest not yet identified through our search.
The expression used to search the databases was constructed as follows: [(Internet OR web OR online OR www) AND (response OR return OR completion) AND (rate OR proportion)]. The search for the terms was limited to the title and abstract of the studies. To search the WebSM database, we used the following filters: “Mode comparison”, “Web Surveys”, “Mixed-Mode Surveys”, “Journal article”, “Conference proceedings”, “Book”, “Edited book”, “Book section”, and “Thesis/diplomas”.
To be included, a study had to report the RRs of at least two data collection methods, being one of them a self-administered web survey. To be considered a web survey, it should be a questionnaire located in a web page accessible using a web-browser (Bethlehem and Biffignandi 2012). The web-based and the alternative data collection methods had to be concurrently administered. The studies had to be about health-related topics, based on representative samples, not including, for example, case reports or studies based on convenience samples. Studies that targeted specific populations such as professional groups, students, and persons with a given disease or any other specific group were excluded. These specific groups were not included in the review, since they are more likely to respond compared to the general population (Lozar Manfreda et al. 2008).
Every search result was added to a Zotero 4.0 (Zotero, Virginia, USA) database, where duplicates were removed. If different studies were based on the same survey or inquiry, only one study was selected. This exclusion occurred to avoid duplicates in terms of RRs, since different studies that used the same survey or inquiry have the same estimates. In this case, the earliest study, according to the publication year, was selected. Following the exclusion of duplicates, the titles and abstracts of the studies were checked according to the selection criteria. Finally, the full text of the articles was read to confirm their eligibility, to check the reference list, and to extract the results of the studies. If any relevant detail was not described in the full text, an email was sent to the first author of the study to achieve such information.
Descriptive variables
Among the 19 selected studies, two types of study designs were identified: cross-sectional and randomized trials. To be considered a randomized trial, the participants had to be randomly assigned to one of the different data collection methods compared by the study. The web recruitment method describes the mean through which the participants were invited to respond the web survey. E-mails had to contain a link pointing to the web survey, letters had to be sent via traditional mail, and the other category included virtual banners and phone calls. A study was considered to provide monetary incentives if any money amount or monetary gift cards were given. Lottery entrance, donations, or points were considered non-monetary. The use of reminders consisted on any attempt to contact the non-respondents after the initial recruitment. Finally, the type of RR calculation was analyzed according to the Standard Definitions of the American Association for Public Opinion Research (AAPOR) (The American Association for Public Opinion Research 2016). If the study did not provide the RR considered, the type of calculation was assessed using the formulas of the AAPOR publication.
To account for the differences in Internet coverage and use that might occur across the years, the mean RRs considering two different publication periods were analyzed. The first period was from 2002 to 2009, while the second was from 2010 to 2015. These periods were chosen, because they are from two different decades, and because the Internet coverage suffered important changes. In 2002, only 10.6% of the world population had Internet access, reaching 25.5% in 2009. While in 2010, 28.9% of the population had Internet access, reaching 43.2% of the population in 2015 (The World Bank 2018). The whole decade period (e.g., 2000–2009 and 2010–2020) was not considered, since no studies were published before 2002, neither after 2015.
Statistical analyses
The selected studies were organized in an Excel 2010 (Microsoft Corp., Washington, USA) spreadsheet, where the relevant methodological aspects of the studies were extracted. Statistical analyses were performed using Stata 13.1 (Stata Corp., Texas, USA). The difference between the RR estimates of the web-based and the alternative data collection methods was assessed via two-sample test of proportions. The pooled RR differences were estimated using random effects, and the percentage of variation among the studies due to heterogeneity was analyzed using the i2 statistic (Higgins and Thompson 2002). The agreement between RR estimates was analyzed using the Bland and Altman (1999) method, and the correlation was analyzed using Pearson’s correlation coefficient. It was considered a significance level equal to 5%.
Results
Selection process
The search among the five databases returned 4707 studies. All titles and abstracts were checked, and 4689 studies were excluded: 46.2% did not target the general population, 23.7% were not health-related, 21.4% did not report RRs of at least two data collection methods, 4.2% were based on the same survey with identical RRs, 3.6% did not use web surveys, and 0.9% did not use concurrent data collection methods. A total of 18 eligible studies were selected according to the selection criteria. After reading their full text, one additional study was selected via the reference list, totalizing 19 eligible studies, as shown in Fig. 1.

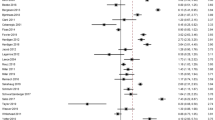
Flow chart of the study selection process (Denmark, 2013; Finland, 2014; The Netherlands, 2009, 2013; South Korea, 2015; Sweden, 2002, 2005, 2011, 2012; United States, 2004, 2005, 2007, 2008, 2012, 2013, 2014)
Description of the selected studies
A complete list of the selected studies is provided in Online Resource 1. Some of the studies used more than one alternative method to the web-based data collection method, and also more than one web-based approach compared to the alternative methods. This is the reason why we describe the studies more than once, adding up to 28 groups assessed. All the selected studies were conducted in high-income countries, almost half of them (nine studies) being based in the United States, one conducted in South Korea, and the remaining nine studies were performed in four European countries (one in Denmark, one in Finland, two in The Netherlands, and five in Sweden). Mail questionnaires were the most used alternative to the web-based method, being employed 11 times.
In Table 1, we describe the methodological characteristics of the selected studies. Only nine studies formally compared the RRs by randomizing the participants between the different data collection methods. Only six studies explicitly provided the type of RR calculation according to the AAPOR Standard Definitions (The American Association for Public Opinion Research 2016). Almost half of the studies calculated the RRs assuming that there were no eligible cases among the cases of unknown eligibility (RR5), and two other studies adopted the same methodology but also considered partial respondents as complete respondents (RR6). Two studies also considered the partial respondents as complete ones, but one included the real number of cases of unknown eligibility in the calculation (RR2), and the other performed an estimate of this number (RR4). Six studies calculated the minimum RR (RR1). Although there were differences between the RR calculations used by the studies, we directly compared the estimates, since there was not enough information in the manuscript, or provided by the authors, to standardize the types of RR for all the studies. In Table 2, we present the mean and median sample sizes and RRs for the web-based and the alternative data collection methods. The different number of groups assessed is to avoid repeated RR and sample size estimates for studies that compared more than two alternative or web-based approaches. The studies had a wide range of sample sizes, regardless of the data collection method used. The difference between the mean and median indicate the asymmetry of the distribution of sample sizes for the web-based and the alternative data collection methods. This difference was not as large for the RR values, but still assumed an asymmetric distribution. However, to simplify the interpretation and to enable comparisons with other studies, we adopt the mean to perform the RR analyses.
Response rate analyses
The difference between the RRs of the web-based and the alternative data collection methods is presented in Fig. 2. The RR was higher for the web-based data collection method only in four comparisons, two times compared to telephone interviews, one time compared to cell phone interviews, and one time compared to IVR interviews. The pooled mean RR difference considering all 28 groups was 12.9 p.p. (95% CI = − 19.0, − 6.8; i2 = 99.6%) lower for the web-based method compared to the alternative data collection methods. A similar result was found when pooling only the estimates of the randomized trials, 15.7 p.p. (95% CI = − 24.2, − 7.3; i2 = 98.5%) lower compared to the alternative methods. We also analyzed the pooled RR differences comparing web-based and the alternative methods according to the reward of monetary incentives and reminders (calculated as: web RR − alternative methods RR). Providing monetary incentives did not influence the RR differences, as they were − 11.1 p.p. (95% CI = − 26.8, 4.5) for studies that provided incentives, and − 13.2 p.p. (95% CI = − 19.6, − 6.8) for those not providing. However, the pooled RR difference was lower among studies that did not send reminders (RRdiff. = − 2.0; 95% CI = − 19.0, 9.5) compared to the ones that sent reminders for the non-respondents (RRdiff. = − 14.2; 95% CI = − 20.7, − 7.7). As shown in Table 3, the mean RRs increased from the 2002–2009 period to the 2010–2015 period. The absolute RR difference comparing web-based to alternative data collection methods remained constant. The agreement analysis is presented in Fig. 3. The majority of the points lie below the line that indicates RR equality (y = 0), demonstrating the superiority of the RRs of the alternative methods compared to the web-based data collection. The points are well distributed along the x-axis, illustrating that the RR differences are not dependent on the study mean RR. Thus, independently if the study achieves a high or a low RR, the difference between the web-based and the alternative data collection methods (regardless of the data collection method used) is, on average, similar. The correlation between the web-based and the alternative methods RR was r = 0.83 (95% CI = 0.66, 0.92).

Response rate difference in percentage points between web-based and alternative data collection methods. Randomized trials are marked with an asterisk (*) (Denmark, 2013; Finland, 2014; The Netherlands, 2009, 2013; South Korea, 2015; Sweden, 2002, 2005, 2011, 2012; United States, 2004, 2005, 2007, 2008, 2012, 2013, 2014)

Bland and Altman plot between response rates estimates of the web-based and the alternative data collection methods (Denmark, 2013; Finland, 2014; The Netherlands, 2009, 2013; South Korea, 2015; Sweden, 2002, 2005, 2011, 2012; United States, 2004, 2005, 2007, 2008, 2012, 2013, 2014)
Discussion
Our systematic literature review found that RRs of web surveys are systematically lower compared to RRs of alternative data collection methods. A similar difference was found when we considered only randomized trials. However, it is not possible to consider these results meta-analytical evidences due to the high degree of heterogeneity of the studies: i2 = 99.6% considering all the studies, and i2 = 98.5% for randomized trial only. Our study limited the analysis of survey quality to a single component of the TSE (nonresponse error), and used the RR as its indicator. This was a methodological choice to achieve the study goal and also to simplify the analyses, since the RR is usually available on published articles. However, we identified five different RR formulas among the selected studies, and few that explicitly described the type of RR calculation used. To standardize the estimates and enable better comparisons, the use of the AAPOR Standard Definitions (The American Association for Public Opinion Research 2016) is strongly recommended.
Other literature reviews and meta-analyses comparing RRs estimates are already published in the literature, but our study differs from those, since it focused exclusively on epidemiologic and public health studies that had the general population as their target. Considering the general population is important, since the variability of the Internet access and coverage in this group is higher compared to other specific groups (Pew Research Center 2016). For this reason, it is important to understand if web surveys are feasible to be used as the main data collection method in the general population. Focusing on public health and epidemiologic studies is important, since the use of the web as mean of data collection is fast increasing in these areas (Brice et al. 2015). Furthermore, health surveys usually require more sensitive and personal information than other survey subjects (i.e., market research and opinion polls); hence, the cooperation and RRs should be studied. A meta-analysis published by Shih and Fan (2008) found a mean RR 11.0 p.p. lower for the web-based data collection compared to mail surveys and a similar heterogeneity i2 = 98.9%. However, besides comparing the web only to mail data collection, the authors included specific groups such as students and professional parties, which are known to have higher RRs than the general population (Lozar Manfreda et al. 2008; Shih and Fan 2008). Another meta-analysis conducted by Lozar Manfreda et al. (2008) investigated the RR differences between concurrently administered web surveys and alternative data collection methods. Among the general population, the RR difference was 19.0 p.p. lower for the web surveys. Different from our study, Lozar Manfreda and colleagues did not limit their review to studies that investigated health-related subjects, what might explain the differences between the pooled estimations.
Although there were methodological variations between ours and the other reviews, they were consistent in concluding that the RR of the web-based data collection method is lower than the alternative methods. The lower RRs of web-based methods held from 2002 to 2015, even when we considered the publication year as a proxy to account for the differences in Internet coverage and use across the years. We also found that the mean difference between the web-based and the alternative data collection methods does not vary according to the RR level (high or low). For this reason, it is clear that other methodological aspects, such as the type of recruitment method (Brown et al. 2015; Akmatov et al. 2015), giving incentives (Gajic et al. 2012; Holland et al. 2015), and sending reminders for the non-respondents (Van Mol 2016; Sebo et al. 2017), play an important role to define the RR of both web-based and alternative data collection methods.
Edwards et al. (2009) described the failure to increase web survey RRs by giving monetary incentives, but identified an increase on the traditional mail RR estimates. This is in line to our findings, showing that giving monetary incentives fail to reduce the RR gap between the data collection methods, and hence, other types of incentives and rewards should be explored (Edwards et al. 2009). Our results also showed that the use of reminders may be less effective for web-based data collection methods than for alternative methods, since the gap between RRs is higher when a reminder is sent. We did not analyze the recruitment methods, since they were very different between the web-based and the alternative data collection methods.
Although achieving high RRs reduces the probability of nonresponse error, it is important to note that lower RRs do not invalidate survey results (Groves 2004). If non-respondents are not different from the respondents regarding to aspects that are relevant to the study objectives, this will not bias the results, but could only cause loss of precision (Dillman et al. 2014). In addition, Groves and Peytcheva (2008) describe that nonresponse bias can affect studies with high or low RRs. However, the gap between RRs of web-based and alternative methods tends to be reduced. With more users looking for medical information through web (Tonsaker et al. 2014), the increase of Internet banking use (Yuen et al. 2010), and more sales being performed online (United Problem Solvers (UPS) 2016), it is expected a more confident relation between respondents and web surveys. To further increase the confidence of participants on web surveys, it is encouraged to adopt the web as main, or part of a mixed-mode survey, to disseminate its use as a data collection method. In addition, web surveys bring further advantages like cheaper data collection (Greenlaw and Brown-Welty 2009; Huybrechts et al. 2010), results of better quality (Barrios et al. 2011; Shin et al. 2012), the possibility to use audio and visual resources, asynchronous participation, and the possibility to provide instant feedback to the participant. In addition, with the recent increase of Internet coverage around the globe (The World Bank 2018), this is a good opportunity for low- and middle-income countries to collect health-related data using web-based surveys.
Our study presents some limitations. Using binary variables to indicate the use of reminders and monetary incentives made impossible for us to analyze the differences between the number of reminders sent and the amount of the incentive. This could not be done, since this information was not available for some studies. Finally, our study compared different types of RRs without standardization. We could not standardize the estimates due to the lack of information provided in the manuscript, or by authors, of the selected studies. However, our study also presents some strengths. We adopted a comprehensive approach by including both observational and experimental studies. In addition, this is one of the first studies to analyze web survey RRs in the context of health-related studies that focused on the general population.
Conclusions
This review fills a gap in the epidemiologic and public health literature in the sense that it compared the RRs of web surveys to alternative data collection methods. We show that web RRs are systematically lower than the ones achieved using traditional data collection methods and that there is a high variability of the RR estimates between the studies reviewed. Although the web fails to achieve a comparable RR to traditional methods, it involves lower costs and other advantages like validation during data collection, structured data collection, and more efficient data consistency leading to better quality results. Considering these advantages and also the constant growth of the Internet use worldwide, it might be beneficial to use the web other than alternative data collection methods for epidemiologic research.
References
Akmatov MK, Rübsamen N, Schultze A et al (2015) Diverse recruitment strategies result in different participation percentages in a web-based study, but in similar compliance. Int J Public Health 60:937–943. https://doi.org/10.1007/s00038-015-0737-0
Andersson G, Lindvall N, Hursti T, Carlbring P (2002) Hypersensitivity to sound (hyperacusis): a prevalence study conducted via the Internet and post. Int J Audiol 41:545–554
Bälter KA, Bälter O, Fondell E, Lagerros YT (2005) Web-based and mailed questionnaires: a comparison of response rates and compliance. Epidemiol Camb Mass 16:577–579
Barrios M, Villarroya A, Borrego A, Olle C (2011) Response rates and data quality in web and mail surveys administered to PhD holders. Soc Sci Comput Rev 29:208–220. https://doi.org/10.1177/0894439310368031
Beebe TJ, McAlpine DD, Ziegenfuss JY et al (2012) Deployment of a mixed-mode data collection strategy does not reduce nonresponse bias in a general population health survey. Health Serv Res 47:1739–1754. https://doi.org/10.1111/j.1475-6773.2011.01369.x
Bethell C, Fiorillo J, Lansky D et al (2004) Online consumer surveys as a methodology for assessing the quality of the united states health care system. J Med Internet Res 6:e2. https://doi.org/10.2196/jmir.6.1.e2
Bethlehem JG, Biffignandi S (2012) Handbook of web surveys. Wiley, Hoboken
Biemer PP (2010) Total survey error: design, implementation, and evaluation. Public Opin Q 74:817–848. https://doi.org/10.1093/poq/nfq058
Bland JM, Altman DG (1999) Measuring agreement in method comparison studies. Stat Methods Med Res 8:135–160
Blumberg SJ, Ganesh N, Luke JV, Gonzales G (2013) Wireless substitution: state-level estimates from the National Health Interview Survey, 2012. Natl Health Stat Rep 70:1–16
Braunsberger K, Wybenga H, Gates R (2007) A comparison of reliability between telephone and web-based surveys. J Bus Res 60:758–764. https://doi.org/10.1016/j.jbusres.2007.02.015
Brice A, Price A, Burls A (2015) Creating a database of Internet-based clinical trials to support a public-led research programme: a descriptive analysis. Digit Health. https://doi.org/10.1177/2055207615617854
Brown O, Quick V, Colby S et al (2015) Recruitment lessons learned from a tailored web-based health intervention Project Y.E.A.H. (Young Adults Eating and Active for Health). Health Educ 115:470–479. https://doi.org/10.1108/he-06-2014-0075
Dillman DA, Smyth JD, Christian LM (2014) Internet, phone, mail, and mixed-mode surveys: the tailored design method, 4th edn. Wiley, Hoboken
Dinitto DM, Bridget Busch-Armendariz N, Bender K et al (2008) Testing telephone and web surveys for studying men’s sexual assault perpetration behaviors. J Interpers Violence 23:1483–1493. https://doi.org/10.1177/0886260508314341
Edwards PJ, Roberts I, Clarke MJ et al (2009) Methods to increase response to postal and electronic questionnaires. In: The Cochrane Collaboration (ed) Cochrane database of systematic reviews. Wiley, Chichester
Gajic A, Cameron D, Hurley J (2012) The cost-effectiveness of cash versus lottery incentives for a web-based, stated-preference community survey. Eur J Health Econ HEPAC Health Econ Prev Care 13:789–799. https://doi.org/10.1007/s10198-011-0332-0
Galea S, Tracy M (2007) Participation rates in epidemiologic studies. Ann Epidemiol 17:643–653. https://doi.org/10.1016/j.annepidem.2007.03.013
Greenlaw C, Brown-Welty S (2009) A comparison of web-based and paper-based survey methods: testing assumptions of survey mode and response cost. Eval Rev 33:464–480. https://doi.org/10.1177/0193841x09340214
Groves RM (2004) Survey errors and survey costs. Wiley, Hoboken
Groves RM, Peytcheva E (2008) The impact of nonresponse rates on nonresponse bias: a meta-analysis. Public Opin Q 72:167–189. https://doi.org/10.1093/poq/nfn011
Haider S, Dodge LE, Brown BA et al (2013) Evaluation of e-mail contact to conduct follow-up among adolescent women participating in a longitudinal cohort study of contraceptive use. Contraception 88:18–23. https://doi.org/10.1016/j.contraception.2012.11.016
Hardigan PC, Succar CT, Fleisher JM (2012) An analysis of response rate and economic costs between mail and web-based surveys among practicing dentists: a randomized trial. J Community Health 37:383–394. https://doi.org/10.1007/s10900-011-9455-6
Higgins JPT, Thompson SG (2002) Quantifying heterogeneity in a meta-analysis. Stat Med 21:1539–1558. https://doi.org/10.1002/sim.1186
Hohwü L, Lyshol H, Gissler M et al (2013) Web-based versus traditional paper questionnaires: a mixed-mode survey with a nordic perspective. J Med Internet Res 15:e173. https://doi.org/10.2196/jmir.2595
Holland CM, Ritchie ND, Du Bois SN (2015) iTunes song-gifting is a low-cost, efficient recruitment tool to engage high-risk MSM in Internet research. AIDS Behav 19:1914–1918. https://doi.org/10.1007/s10461-015-1130-y
Huybrechts KF, Mikkelsen EM, Christensen T et al (2010) A successful implementation of e-epidemiology: the Danish pregnancy planning study “Snart-Gravid”. Eur J Epidemiol 25:297–304. https://doi.org/10.1007/s10654-010-9431-y
Källmén H, Sinadinovic K, Berman A, Wennberg P (2011) Risky drinking of alcohol in Sweden: a randomized population survey comparing web- and paper-based self-reports. Nord Stud Alcohol Drugs. https://doi.org/10.2478/v10199-011-0013-4
Keiding N, Louis TA (2016) Perils and potentials of self-selected entry to epidemiological studies and surveys. J R Stat Soc Ser A (Statistics in Society) 179:319–376. https://doi.org/10.1111/rssa.12136
Klausch T, Hox JJ, Schouten B (2013) Measurement effects of survey mode on the equivalence of attitudinal rating scale questions. Sociol Methods Res 42:227–263. https://doi.org/10.1177/0049124113500480
Laaksonen S, Heiskanen M (2014) Comparison of three modes for a crime victimization survey. J Surv Stat Methodol 2:459–483. https://doi.org/10.1093/jssam/smu018
Lagerros YT, Sandin S, Bexelius C et al (2012) Estimating physical activity using a cell phone questionnaire sent by means of short message service (SMS): a randomized population-based study. Eur J Epidemiol 27:561–566. https://doi.org/10.1007/s10654-012-9708-4
Lee C-K, Back K-J, Williams RJ, Ahn S-S (2015) Comparison of telephone RDD and online panel survey modes on CPGI scores and co-morbidities. Int Gambl Stud 15:435–449. https://doi.org/10.1080/14459795.2015.1068353
Link MW, Mokdad AH (2005) Alternative modes for health surveillance surveys: an experiment with web, mail, and telephone. Epidemiol Camb Mass 16:701–704
Lozar Manfreda K, Bosnjak M, Berzelak J et al (2008) Web surveys versus other survey modes: a meta-analysis comparing response rates. Int J Mark Res 50:79–104
McCormack LA, Friedrich C, Fahrenwald N, Specker B (2014) Feasibility and acceptability of alternate methods of postnatal data collection. Matern Child Health J 18:852–857. https://doi.org/10.1007/s10995-013-1310-1
McMillen RC, Winickoff JP, Wilson K et al (2013) A dual-frame sampling methodology to address landline replacement in tobacco control research. Tob Control 24:7–10. https://doi.org/10.1136/tobaccocontrol-2012-050727
Morton LM, Cahill J, Hartge P (2006) Reporting participation in epidemiologic studies: a survey of practice. Am J Epidemiol 163:197–203. https://doi.org/10.1093/aje/kwj036
Pew Research Center (2016) Smartphone ownership and internet usage continues to climb in emerging economies. Pew Research Center
Sax LJ, Gilmartin SK, Bryant AN (2003) Assessing response rates and nonresponse bias in web and paper surveys. Res High Educ 44:409–432. https://doi.org/10.1023/a:1024232915870
Schonlau M, Zapert K, Simon LP et al (2004) A comparison between responses from a propensity-weighted web survey and an identical RDD survey. Soc Sci Comput Rev 22:128–138. https://doi.org/10.1177/0894439303256551
Sebo P, Maisonneuve H, Cerutti B et al (2017) Rates, delays, and completeness of general practitioners’ responses to a postal versus web-based survey: a randomized trial. J Med Internet Res 19:e83. https://doi.org/10.2196/jmir.6308
Shih T-H, Fan Xitao (2008) Comparing response rates from web and mail surveys: a meta-analysis. Field Methods 20:249–271. https://doi.org/10.1177/1525822x08317085
Shin E, Johnson TP, Rao K (2012) Survey mode effects on data quality: comparison of web and mail modes in a U.S. National Panel Survey. Soc Sci Comput Rev 30:212–228. https://doi.org/10.1177/0894439311404508
Sinadinovic K, Wennberg P, Berman AH (2011) Population screening of risky alcohol and drug use via Internet and interactive voice response (IVR): a feasibility and psychometric study in a random sample. Drug Alcohol Depend 114:55–60. https://doi.org/10.1016/j.drugalcdep.2010.09.004
Spijkerman R, Knibbe R, Knoops K et al (2009) The utility of online panel surveys versus computer-assisted interviews in obtaining substance-use prevalence estimates in the Netherlands. Addiction 104:1641–1645. https://doi.org/10.1111/j.1360-0443.2009.02642.x
The American Association for Public Opinion Research (2016) Standard definitions: final dispositions of case codes and outcome rates for surveys, 9th edn. AAPOR
The World Bank (2018) Internet users (per 100 people). World Bank. http://data.worldbank.org/indicator/IT.NET.USER.P2?end=2014&start=2014&view=bar. Accessed 21 Feb 2018
Tonsaker T, Bartlett G, Trpkov C (2014) Health information on the internet: gold mine or minefield? Can Fam Physician Med Fam Can 60:407–408
United Problem Solvers (UPS) (2016) UPS pulse of the online shopper: tech-savvy shoppers transforming retail—a UPS white paper. United Problem Solvers (UPS)
Van Mol C (2016) Improving web survey efficiency: the impact of an extra reminder and reminder content on web survey response. Int J Soc Res Methodol. https://doi.org/10.1080/13645579.2016.1185255
Wallander L, Tikkanen RH, Mannheimer LN et al (2015) The problem of non-response in population surveys on the topic of HIV and sexuality: a comparative study. Eur J Public Health 25:172–177. https://doi.org/10.1093/eurpub/cku154
Yuen YY, Yeow PHP, Lim N, Saylani N (2010) Internet banking adoption: comparing developed and developing countries. J Comput Inf Syst 51:52–61. https://doi.org/10.1080/08874417.2010.11645449
Funding
No funding was received to execute this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Ethical statement
This article does not contain any studies with human participants or animals performed by any of the authors.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Blumenberg, C., Barros, A.J.D. Response rate differences between web and alternative data collection methods for public health research: a systematic review of the literature. Int J Public Health 63, 765–773 (2018). https://doi.org/10.1007/s00038-018-1108-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00038-018-1108-4