
Abstract
This paper presents a low-power multi-rate clock and data recovery (CDR) for receivers of serial links. Its basic structure includes a current-mode logic bang–bang phase detector sampled by low-mismatch half-rate quadrature clocks, which are generated by voltage-controlled delay line (VCDL) and two-stage time-average circuits. The total delay of VCDL can be adjusted to accommodate a wide frequency range by its bias voltage, which is generated by a delay-locked-loop-based bias generator. The quadrature clocks are 64-phase adjustable with high linearity, which is realized by phase interpolator with a compensating structure. The parameters of phase detection loop are well designed to satisfy both high jitter tolerance and low clock jitter. Fabricated in a 40 nm CMOS technology, the CDR occupies an active area of 0.036 mm\(^2\) only. With a wide operating range of 2–20 Gb/s, the chip consumes 62.5 mW, corresponding to an energy efficiency of 3.1 pJ/bit. The measured root-mean-square jitter and peak-to-peak jitter for the recovered clock at 9 GHz are 1.9 and 10.8 ps, respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the increasing demand for high-speed communication, clock and data recovery (CDR) is playing more and more important roles in receivers of serial links. There are various kinds of CDRs for different application scenarios, some of which require CDRs to be able to work in a wide rate range for different communication protocols. Although reference-less CDRs eliminate the need for an external clock by a voltage-controlled oscillator (VCO) or digital-controlled oscillator (DCO) [11, 16], their capture range and locking time are generally not as good as CDRs with a reference clock. Besides, the oscillation frequency of oscillators is vulnerable to external interference and variations of process, voltage, and temperature (PVT). Among different CDR schemes, phase-interpolator (PI)-based CDR is simple in structure, all-digital or mixed-signal driven, and insensitive to PVT variations, which is well suited for multi-rate very-large-scale-integration (VLSI) systems and applicable to different technologies. Thus, it has become the focus of our research, which aims to design a PI-based CDR with 2–20 Gb/s operation range in a 40 nm CMOS process.
The clock phase locking and data recovery of the CDR are implemented by dynamically adjusting the tail current array of PI. Nevertheless, the output phase of PI does not change linearly with the switching of PI tail currents. There are some methods to solve this problem, such as splitting differential-pair structure [14] and twin-PI structure [13]. Compensating twin-PI technique is preferred in this design for lower mismatch, lower output parasitic capacitance, and higher integration. Furthermore, the generation of low-mismatch multi-phase clocks for PI is another critical consideration for high-quality data sampling. There are widely adopted solutions such as phase lock loop (PLL) [17], delay locked loop (DLL) [2], and multiplying delay locked loop (MDLL) [4], among which DLL-based solution is more appropriate for this design because of its fast locking and low mismatch. Finally, the design of the phase detection loop also plays a major role in the CDR performance [10]. Instead of introducing proportional and integral paths to the digital loop filter (DLF) in some researches [12], this design simply adopts first-order DLF to realize the trade-off between jitter tolerance and clock jitter.
The remainder of this article is organized as follows. The system architecture, design of major modules, principles, and simulations are detailed in Sect. 2. Chip measurement setup, results, and performance comparison to other related works are analyzed in Sect. 3, and conclusions are finally drawn in Sect. 4.

System architecture of the proposed CDR
2 System Architecture and Circuit Design
As depicted in Fig. 1, the system is divided into a DLL-based shared bias generator, a time-average-cell (TA)-based quadrature clock generator, and a PI-based clock and data recovery. For the clock path, a buffer is used at the input to reshape and amplify the clock signal and drive two voltage-controlled delay lines (VCDLs). Current-mode logic (CML) to CMOS conversion circuit is based on symmetrical operational transconductance amplifier (OTA) with push–pull inverter output stage, which converts differential sinusoidal outputs of VCDL (N< 8:0> and P< 8:0>) to single-end CMOS logical levels Q<8:0>. The false lock protection circuit has a function to determine whether the total delay from Q<0> to Q<8> is too long or too short compared to the period of input clock. In addition, it generates control signals for the phase and frequency detector (PFD) to prevent false locking or harmonic locking. PFD detects the phase and frequency of input clock, and generates control signals for the charge pump (CP) to charge and discharge a load capacitor. The “Vc gen” circuit converts the voltage on the capacitor to global bias voltages Vcn and Vcp, which are shared by VCDL, two-stage TA block, CML-to-CMOS conversion circuit, and CP circuit. After the DLL is locked, the delay of each stage in VCDL will be one-eighth of the clock cycle. The two-stage TA block has four TA cells in the first stage and two TA cells in the second stage to convert the output of each stage in VCDL (AN<7:0> and AP<7:0>) into low-mismatch quadrature clock signals. The adoption of two VCDLs for different paths is necessary because a fan-out-of-2 load of delay cells in VCDL will deteriorate its bandwidth and reduce its operating range.
The input data is equalized by a continuous time linear equalizer (CTLE) and sampled by a half-rate bang–bang phase detector (BBPD). The 2-bit 1–10 Gb/s lead and lag signals from BBPD are slowed down to 16 bits 0.125–1.25 Gb/s by two serial-structure 1:8 demultiplexers (DEMUX) and processed by clock recovery unit (CRU). The CRU consists of a digital loop filter and PI phase controller, which adjusts the 64-bit control codes according to the lead and lag signals. The clock output of the PI is 64-phase tunable through the control codes. And the recovered clock and data can be obtained by adjusting the phase of PI output and tracking the input data in BBPD.

Schematic of a voltage-controlled delay line and CML-to-CMOS block; b false lock protection; c phase and frequency detector; d charge pump

The shift of bias voltage Vc in “Vc gen” with variations of input clock frequency
2.1 Delay Locked Loop
As shown in Fig. 2a, the VCDL consists of 10 voltage-controlled delay cells, which are based on differential pairs with PMOS symmetric loads. Each delay cell delays the clock by one-eighth of a cycle when biased at proper \(V_\textrm{cn}\) and \(V_\textrm{cp}\). Then, even stages of “CML-to-CMOS” block outputs are fed into the false lock protection circuit, as shown in Fig. 2b. It detects VCDL delay \(T_\textrm{d}\) from N< 0>/P<0> to N<8>/P<8> and sets the LOWER or UPPER signals for the PFD, which indicate that \(T_\textrm{d}\) is smaller than \(0.5\times T_\textrm{clk}\) or larger than \(1.5\times T_\textrm{clk}\) (\(T_\textrm{clk}\) is the clock cycle) and may cause false locking or harmonic locking of the DLL [9]. In these conditions, LOCK_PRE is “0,” which indicates that the DLL is far from being locked. So LOCK, RESET_Q0, RESET_Q8, QL0, and QL8 are all “0.” The UP and DN outputs of PFD in Fig. 2c will depend on UPPER and LOWER. When \(T_\textrm{d}\) is within \(0.5\times T_\textrm{clk}\) and \(1.5\times T_\textrm{clk}\), on the other hand, UPPER and LOWER are “0,” and LOCK_PRE and LOCK are “1.” Thus, UP and DN are determined by QL0 and QL8, which are slowed down by 1:2 dividers from Q< 0> and Q< 8> to reduce the working rate of PFD and realize sufficient charging and discharging time of CP. And the delay cell in PFD is used for eliminating the dead zone of CP and keeping CP turned on. The schematic of CP is shown in Fig. 2d, which works in the four conditions as follows:
-
When UP is “1” and DN is “0,” M3 and M11 are turned on, M7 and M13 are turned off. \(C_\textrm{L}\) is charged by the current mirror M6. \(V_\textrm{c}\) increases.
-
When UP is “0” and DN is “1,” M7 and M13 are turned on, M3 and M11 are turned off. \(C_\textrm{L}\) is discharged by the switch M13. \(V_\textrm{c}\) decreases.
-
When UP and DN are “0,” M7 and M11 are turned on, M3 and M13 are turned off. The charging path and discharging path are turned off simultaneously. The charging and discharging currents are bypassed by M7 and M11. \(V_\textrm{c}\) remains unchanged.
-
When UP and DN are “1,” M3 and M13 are turned on, M7 and M11 are turned off. The charging path and discharging path are turned on simultaneously. \(C_\textrm{L}\) is neither charging nor discharging. \(V_\textrm{c}\) remains unchanged.
In order to satisfy the high switching rate, all the transistors in the charge pump circuit of Fig. 2d are set to a minimum gate length. Given the current mismatch caused by channel length modulation, negative feedback is implemented by a rail-to-rail operational amplifier [3] which has a structure of complementary differential pair with cascode output stage, and achieves 59 dB gain and 83\(^{\circ }\) phase margin. Its loop stability is maintained by Miller capacitor \(C_\textrm{c}\) and resistor \(R_\textrm{c}\). For the sake of the loop stability, \(C_\textrm{L}\) is set to 2.3 pF. \(V_\textrm{cn}\) and \(V_\textrm{cp}\) with high noise rejection capability and wide range are finally generated by a bias generator proposed in [8]. The bias voltages can be stabilized within 30 ns after DLL starts to work. And they basically shift linearly with the frequency of the input clock, as shown in Fig. 3.
2.2 Quadrature Clock Generator and Compensating Phase Interpolator
The TA-based quadrature clock generator and PI follow the structure proposed in [7]. The schematic of the basic TA block is shown in Fig. 4a. In the quadrature clock generator, each TA block in the first stage combines two in-phase VCDL outputs into clock signals with a corrected duty cycle. The second-stage TA blocks convert the eight-phase clock into a quadrature clock with reduced I, Q mismatch. In addition, symmetrical layout and high-speed interconnects are also critical to low clock mismatch.

a Schematic of the TA block; b Schematic of the PI block; c Structure of compensating PI and clock buffer

Phase DNL and INL of single PI and compensating PI at 10GHz
The basic structure of PI is four differential amplifiers with tied output node and the same PMOS symmetric loads, as shown in Fig. 4b. Their inputs are provided with 0\(^{\circ }\), 180\(^{\circ }\), 90\(^{\circ }\), and 270\(^{\circ }\) clocks. Each differential amplifier is supplied by an adjustable current array with 16 switches to adjust tail current, and consequently, change the transconductance of differential MOS transistors for amplification. After superposition, the output phase can be adjusted according to the switches. However, traditional PI suffers from phase nonlinearity because the superposed output phase is not shifted linearly by the switching of the tail current. By contrast, compensating PI adopts a TA block to combine two PIs with a 45\(^{\circ }\) phase difference, which exactly compensates for the nonlinearity. Its structure is shown in Fig. 4c, where the 45\(^{\circ }\) phase difference is realized by rotating eight control codes between the two PIs. The clock buffer converts the output of the TA block from CML-to-CMOS logic by an AC-coupling capacitor. A feed-forward resistor connected in parallel to an inverter helps rectify the clock duty cycle, and two cross-coupled inverters inserted between CKP and CKN paths help maintain differential clock symmetry [5]. The simulated 10 GHz phase differential nonlinearity (DNL) and integral nonlinearity (INL) of a single PI and compensating PI are shown in Fig. 5. The optimized DNL and INL is within +0.24/\(-\)0.2 LSB and +0.9/\(-\)0.1 LSB, which indicates that the compensating PI reduces the phase deviation immensely.
2.3 Phase Detection
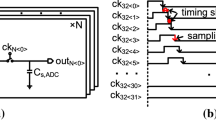
As shown in Fig. 6, the half-rate BBPD has a simple structure with eight CML latches and two exclusive-or gates (XOR), which solves the Alexander equations as follows: [1]
The first two latches in each data path can be regarded as D-flip-flops (DFFs) to sample the center of the nth and (n + 1)th data (\(D_{n}\), \(D_{n+1}\)) and the edge between nth and (\(n+1\))th data (\(E_{n}\)), while the last latch is pulsed by the same clock to generate synchronous output. The latch-based PD has the advantages of a low-speed sampling clock, high phase detection gain, and insensitivity to process. But it cannot reflect the size of phase error and suffers from nonideal characteristics such as DFF metastability and hysteresis [6].

Schematic of half-rate BBPD

Block diagram of the CRU
As shown in Fig. 7, the CRU firstly compares the number of “1” from eight “UP” and eight “DN” signals of the DEMUX and decides phase is “early” or “late” by a majority voter [15]. The DLF defers phase rotation by a decimation factor of \(K_\textrm{F}\). The internal 6-bit binary phase control code will increase or decrease 1 after DLF receives an “early” or “late” signal for \(1/K_\textrm{F}\) times successively. The PI controller converts the 6-bit control codes into 64-bit control codes to control the tail currents of PIs.
The transfer function H(z) of the phase detection circuits is mainly determined by the gain of majority voter (\(K_\textrm{V}\)), \(K_\textrm{F}\), and the phase step of PI (\(K_\textrm{PI}\)), which is expressed as follows:
Assuming \({\phi _\textrm{in}}(t) = {\phi _{\textrm{in}, \textrm{p}}}\cos {\omega _\phi }t\) is the input sinusoidal phase jitter, \(\phi _{\textrm{in},\textrm{p}}\) and \(\omega _\phi \) are the amplitude and angular frequency of the jitter, respectively, the peak value of output jitter \({\phi _{\textrm{out}, \textrm{p}}}\) occurs at the one-fourth cycle of the sinusoidal phase jitter, that is
\(T_\textrm{F}\) is the update cycle of the DLF. The jitter transfer can be expressed by the ratio of \({\phi _{\textrm{out}, \textrm{p}}}\) and \({\phi _{\textrm{in}, \textrm{p}}}\), that is
Then, the -3 dB bandwidth of the jitter transfer can be derived in terms of \({\omega _\phi }\):
In order to realize high loop bandwidth and good jitter tolerance, \(K_\textrm{V}\), \(K_\textrm{F}\), and \(K_\textrm{PI}\) are expected to be high. However, it may increase design complexity and aggravate dithering jitter in the locked condition. To obtain a trade-off among the performance requirements, \(K_\textrm{V}\), \(K_\textrm{F}\), and \(K_\textrm{PI}\) are set to 1/8, 1/3, and \(2\pi /2^6\), and \(T_\textrm{F}\) is set to be one-eighth of the input clock cycle. Theoretically, the phase detection loop can be locked within \(2^4\times 8\times 3=384\) clock cycles. Given the lock time of DLL, the CDR can be locked within 50 ns at 20 Gb/s.
To verify its jitter tolerance (JTOL) performance, simulation is conducted under the condition of 10 Gb/s \(2^{23}-1\) pseudo-random binary sequence (PRBS) pattern input with sinusoidal jitter. The maximum jitter amplitude at each jitter frequency without any error detected during 5 \(\upmu \)s transient analyses is plotted in Fig. 8. It indicates that the jitter tolerance curve exceeds the SONET OC-192 mask at least by 0.25 UI at high frequencies (4–100 MHz).

Simulated jitter tolerance at 10 Gb/s and \(2^{23}-1\) PRBS data

Micrograph and layout of the CDR

Measurement setup of the CDR

Eye diagram of the recovered data at a 3 Gb/s, b 10 Gb/s, c 20 Gb/s, and d Recovered clock at 9 GHz
3 Measurement Results
The CDR is fabricated in a 40 nm CMOS technology, which occupies an active area of 180\(\times \)200 \(\upmu \textrm{m}^2\) (=0.036 mm\(^2\)). The chip micrograph and the layout of each block are shown in Fig. 9. The pads have a configuration that is suitable for on-wafer measurement. The measurement setup is shown in Fig. 10. The CDR operates from a power supply of 1.1 V and consumes a total of around 56.8 mW across the entire data rate range. When the signal quality analyzer MP1900A generates a 500 \(\textrm{mV}_{\textrm{pp}}\) half-rate clock and 2.4–20 Gb/s 600\(\textrm{mV}_{\textrm{ppd}}\) NRZ data with \(2^{23}-1\) PRBS pattern, the eye diagram of the recovered data can be observed by the DCA-X 86100D Oscilloscope, as shown in Fig. 11a–c. At the data rate below 3 Gb/s, the clock generator and balun nearly reach their lower limits, which may deteriorate chip performance. At the data rate above 20 Gb/s, the CDR can still enter a locked state but its jitter performance continues to degenerate due to the speed limit of digital circuits. The measured eye diagrams show that the CDR works well within the set frequency range, while the best root-mean-square (rms) and the peak-to-peak (p-p) jitter of the recovered clock is captured at 9 GHz in Fig. 11d, which are 1.9 and 10.8 ps, respectively. Table 1 summarizes the performance of the proposed CDR and other PI-based researches. In comparison, our solution is featured with a wide data range, compact silicon area, and low-power consumption.
4 Conclusion
A DLL-and-PI-based CDR fabricated in 40 nm CMOS technology is presented in this paper. It has a wide operating range of 2–20 Gb/s by employing a half-rate reference clock. The measurement results show that it achieves 1.9\(\textrm{ps}_{\textrm{rms}}\) and 10.8\(\textrm{ps}_{\textrm{pp}}\) clock jitter and 3.1 pJ/bit power efficiency. High-linearity low-mismatch 64-phase quadrature clock is generated by compensating PI with duty cycle correction circuits. High jitter tolerance, low clock jitter, and fast lock time have been achieved by careful selection of phase detection loop parameters. Due to its simple structure, it has the advantages of high power and area efficiency and shows certain significance for research in multi-rate serial link communications.
Data Availability
Data will be made available on reasonable request.
References
J.D.H. Alexander, Clock recovery from random binary signals. Electron. Lett. 11(22), 541–542 (1975). https://doi.org/10.1049/el:19750415
Y. Chen, Y. Zhuang, Analysis and design of a delay-locked loop with multiple radiation-hardened techniques. Circuits Syst. Signal Process. 42(1), 130–146 (2023). https://doi.org/10.1007/s00034-022-02151-y
N. Hou, Z. Li, Design of high performance CMOS charge pump for phase-locked loops synthesizer, in 2009 15th Asia-Pacific Conference on Communications, pp. 209–212 (2009). https://doi.org/10.1109/APCC.2009.5375655
H. Hwang, J. Kim, A 100 Gb/s quad-lane Serdes receiver with a PI-based quarter-rate all-digital CDR. Electronics 9(7), 1113 (2020). https://doi.org/10.3390/electronics9071113
M.M. Khanghah, K.D. Sadeghipour, D. Kelly, C. Antony, P. Ossieur, P.D. Townsend, A 7-bit 7-GHz multiphase interpolator-based DPC for CDR applications. IEEE Trans. Circuits Syst. I Regul. Pap 69(10), 3976–3988 (2022). https://doi.org/10.1109/TCSI.2022.3191229
J. Lee, K.S. Kundert, B. Razavi, Analysis and modeling of Bang-Bang clock and data recovery circuits. IEEE J. Solid-State Circuits 39(9), 1571–1580 (2004). https://doi.org/10.1109/JSSC.2004.831600
F. Lv, X. Zheng, F. Zhao, J. Wang, S. Yue, Z. Wang, W. Cao, Y. He, C. Zhang, H. Jiang, Z. Wang, A power scalable 2–10 Gb/s PI-based clock data recovery for multilane applications. Microelectron. J. 82, 36–45 (2018). https://doi.org/10.1016/j.mejo.2018.10.007
J.G. Maneatis, Low-jitter process-independent DLL and PLL based on self-biased techniques. IEEE J. Solid-State Circuits 31(11), 1723–1732 (1996). https://doi.org/10.1109/JSSC.1996.542317
S. Ok, K. Chung, J. Koo, C. Kim, An antiharmonic, programmable, DLL-based frequency multiplier for dynamic frequency scaling. IEEE Trans. Very Large Scale Integr. Syst 18(7), 1130–1134 (2010). https://doi.org/10.1109/TVLSI.2009.2019757
P. Palestri, A. Elnaqib, D. Menin, K. Shyti, F. Brandonisio, A. Bandiziol, D. Rossi, R. Nonis, Analytical modeling of jitter in Bang–Bang CDR circuits featuring phase interpolation. IEEE Trans. Very Large Scale Integr. Syst 29(7), 1392–1401 (2021). https://doi.org/10.1109/TVLSI.2021.3068450
W. Rahman, D. Yoo, J. Liang, A. Sheikholeslami, H. Tamura, T. Shibasaki, H. Yamaguchi, A 22.5-to-32-Gb/s 3.2-pJ/b referenceless baud-rate digital CDR with DFE and CTLE in 28-nm CMOS. IEEE J. Solid-State Circuits 52(12), 3517–3531 (2017). https://doi.org/10.1109/JSSC.2017.2744661
Z. Shu, S. Huang, Z. Li, P. Yin, J. Zang, D. Fu, F. Tang, A. Bermak, A 5-13.5 Gb/s multistandard receiver with high jitter tolerance digital CDR in 40-nm CMOS process. IEEE Trans. Circuits Syst. I Regul. Pap 67(10), 3378–3388 (2020). https://doi.org/10.1109/TCSI.2020.2991253
Z. Wang, P.R. Kinget, A very high linearity twin phase interpolator with a low-noise and wideband delta quadrature DLL for high-speed data link clocking. IEEE J. Solid-State Circuits 58(4), 1172–1184 (2023). https://doi.org/10.1109/JSSC.2022.3197061
G. Wu, D. Huang, J. Li, P. Gui, T. Liu, S. Guo, R. Wang, Y. Fan, S. Chakraborty, M. Morgan, A 1-16 Gb/s all-digital clock and data recovery with a wideband high-linearity phase interpolator. IEEE Trans. Very Large Scale Integr. Syst 24(7), 2511–2520 (2016). https://doi.org/10.1109/TVLSI.2015.2508045
Y. Xia, Z. Shu, T. Shen, P. Yin, F. Tang, X. Zhou, A. Bermak, A 10-GHz low-power serial digital majority voter based on moving accumulative sign filter in a PS-/PI-based CDR. IEEE Trans. Microw. Theory Tech. 68(12), 5432–5442 (2020). https://doi.org/10.1109/TMTT.2020.3029188
C. Yu, E. Sa, S. Jin, H. Park, J. Shin, J. Burm, A 6.5-12.5-Gb/s half-rate single-loop all-digital referenceless CDR in 28-nm CMOS. IEEE J. Solid-State Circuits 55(10), 2831–2841 (2020). https://doi.org/10.1109/JSSC.2020.3005750
H. Yuan, H. Sang, B. Liang, J. Chen, Y. Chi, W. Xu, Y. Guo, A SET-tolerant high-frequency multibiased multiphase voltage-controlled oscillator for phase interpolator-based clock and data recovery. IEEE Trans. Nucl. Sci. 69(7), 1725–1732 (2022). https://doi.org/10.1109/TNS.2022.3172401
Acknowledgements
This work was supported by the National Major Research and Development Program (Grant No. 2022YFB2803100) and National Natural Science Foundation of China (Grant No. 61974022).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, Y., Chen, Y., Fan, W. et al. A 2–20 Gbps Clock and Data Recovery Based on Phase Interpolation and Delay Locked Loop. Circuits Syst Signal Process 43, 318–330 (2024). https://doi.org/10.1007/s00034-023-02473-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-023-02473-5