
Abstract
Probabilistic seismic hazard assessment (PSHA) for the Kashmir region located in the northwestern Himalayas has been performed to quantitatively estimate the probability of exceedance of various ground-shaking levels. An updated earthquake catalog composed of 7826 events was prepared by combining historical events (from 1250 BC) and instrumental events (1900–2020). Kijko's maximum likelihood technique yielded seismicity parameter b-value 0.92–1.05 and mmax ~ 7.98 for the entire Kashmir region. A comparison of three seismicity delustering methods has been presented based on the resulting seismicity parameters. PSHA computations were conducted using RCRISIS software based on a logic tree approach to account for the model uncertainties in attenuation models and epistemic uncertainties due to declustering methods. Seismic hazard maps at bedrock for four return periods of 475, 950, 2475, and 4950 years were prepared using peak ground accelerations (PGA) as well as short- (0.2 s) and long-period (1 s) spectral accelerations (Sa). Sensitivity analysis of the computed hazard revealed the substantial effect of attenuation relationships as well as declustering methods on the outcomes. Furthermore, hazard curves and uniform hazard response spectra at each of the 1228 grid points were developed. The southwestern, northwestern, and northern regions of the valley including Pulwama, Shopian, Kulgam, and Budgam were found to have the highest hazard as opposed to the central regions like Ganderbal and parts of Baramula. Kashmir region was divided into five zones (ZA-ZE) of high to low seismicity with mean PGA values of 0.175, 0.258, 0.379, 0.456, and 0.514 g, respectively, for the 2475-year return period.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Seismic hazard assessment is carried out using the two most widely used approaches—Deterministic Seismic Hazard Assessment (DSHA) and the Probabilistic Seismic Hazard Assessment (PSHA) approaches. DSHA considers a single earthquake scenario, with the maximum magnitude, Maximum Credible Earthquake (MCE), and minimum source-to-site distance, as the most critical for a site. Probabilistic hazard analysis approach, on the other hand, considers all probable earthquake magnitude and distance combinations as opposed to a single critical earthquake in the case of DSHA. In simple terms, it incorporates all spatial and temporal uncertainties, along with the uncertainties in the assessment of the ground motion parameter at the site, combined using the total probability theorem. Following the pioneering work of Cornell (1968), PSHA has been widely employed in numerous regions around the world. Besides, several PSHA studies have also been conducted using the software RCRISIS (formerly CRISIS), e.g., in Pakistan (PMD and NORSAR, 2006), Saudi Arabia (Al-Arifi et al., 2013), Himachal Pradesh (Patil et al., 2014), Central Asia (Ischuk et al., 2017), Argentina (Gregori & Christiansen, 2018), Nepal (Rahman and Bai, 2018), Himalayan region (Rout et al., 2018), and UK (Aldama-Bustos et al., 2019).
The Global Seismic Hazard Assessment Program (GSHAP) categorises the Himalayan belt into a zone of highest seismic hazard with PGA between 0.20–0.50 g for a 475-year return period (Bhatia et al., 1999). Seismic hazard studies in India started in the 1960s when the Bureau of Indian Standards (BIS) developed the seismic zonation map for India. The BIS code (IS-1893:2016) divides the country of India into four seismic zones (II, III, IV, and V) based on the expected maximum PGA estimated from seismic hazard analysis. This remains the most widely used reference of peak ground accelerations for seismic design of buildings in India. The zonation map, however, is not based on detailed seismic hazard analysis; rather it only utilizes the knowledge of seismotectonic and geophysical data in India to determine peak ground accelerations at bedrock corresponding to the maximum credible and design basis earthquakes. Subsequently, several PSHA studies were conducted to develop a complete PGA map for the whole of India (e.g., Khattri et al., 1984; Bhatia et al., 1999; NDMA, 2012).
In addition to nationwide seismic hazard studies, several PSHA studies on individual cities or regions have been conducted. Major studies have especially been conducted at IIT Delhi on several cities in India, producing a valuable resource for the country, e.g., in Delhi (Rao, 2003; Rao and Satyam, 2005; Satyam, 2006), NCR of Delhi (Rao & Rathod, 2014; Rathod, 2011), Ahmedabad (Trivedi, 2011), Surat and surrounding region (Thaker et al., 2010, Thaker and Rao 2014), northeast states (Rebecca and Rao, 2017), and Jammu (Ansari et al., 2022).
Kashmir region falls in seismic zones IV and V of the IS 1893:2016 zonation map, which corresponds to peak ground acceleration (PGA) of 0.24–0.36 g. Seismic hazard studies conducted in India have predicted a wide range of PGA values (0.16–0.70 g) for the Himalayan region (e.g., Mahajan et al., 2010; NDMA, 2011). Studies conducted in Pakistan (e.g., Hashash et al., 2012; Waseem & Erdik, 2021) report maximum hazard in the NW Himalayan region specifically owing to the presence of active faults like the Main Boundary Thrust and Main Mantle Thrust. PGA values of 0.60 g and 1.00 g were reported for 475- and 2475-year return periods, respectively, for Muzaffarabad, corroborating well with the measurements of ground motions experienced during the October 8 2005 Kashmir earthquake in the city. Hashash et al. (2012) proposed PGA values as high as 0.80 g for a 475-year return period along the MMT (Main Mantle Thrust) and 0.40–0.60 g along the MBT (Main Boundary Thrust). Waseem and Erdik (2021) reported PGA values of 0.24–0.45 g for the 475-year return period and 0.55–1.02 g for the 2475-year return period in the northern and western parts of Pakistan, which basically share borders with the southwestern margin of Kashmir Valley.
These studies call attention to the risk of high hazards in the Kashmir region, which is located within the tectonically active NW Himalayas. For the Kashmir region specifically, attempts at conducting probabilistic seismic hazard studies have been mostly preliminary, not producing any specific information useful for the seismic design of buildings (e.g., Chandra et al., 2018; Dar & Dubey, 2015). Sana (2019) conducted a comprehensive study for Kashmir region addressing the uncertainties associated with sources and model uncertainties of ground motion prediction equations in a logic tree framework. However, the outcomes are only focused on a few districts of Kashmir, limiting the application. Yousuf and Bukhari (2020) provided hazard curves and uniform hazard response spectra (UHRS) which are beneficial for building design; however, the development of an updated earthquake catalogue and derivation of seismicity parameters thereof are not considered in their study. Instead, the seismic zones and seismicity parameters generalized by National Disaster Management Authority of India (NDMA, 2011) for the Himalayan region were directly used. Moreover, disregarding the uncertainties in the attenuation models, they considered a single ground motion prediction equation (GMPE) by NDMA (2011).
In light of the high seismic hazard in the NW Himalayan region, the present study aims at conducting a comprehensive seismic hazard analysis for the Kashmir region using RCRISIS software (Ordaz et al., 2017). An updated earthquake catalogue (1900–2020) was prepared which is further used to determine the seismicity parameters for the Kashmir region. Linear sources along with newly delineated fault systems are included as seismogenic sources. The selection of GMPEs as well as the description of the seismic activity for a region is critical in the overall estimation of results in PSHA because of the substantial influence on the resulting hazard, especially for low seismicity areas (Atkinson & Goda, 2011; Sabetta et al., 2005). Therefore, in this study, we consider the use of a logic tree to include more than one GMPE together with the incorporation of the variability in seismicity parameters produced by different declustering techniques. Three GMPEs (one global and two regional) along with three declustering approaches are considered in the branches of a logic tree model in the RCRISIS software to account for the model uncertainties and the epistemic uncertainties, respectively. The effect of the declustering methods adopted in this study is assessed through a comparison of completeness periods, seismicity parameters, and the final horizontal peak ground acceleration values. Several other studies have compared the seismic declustering methods (Talbi et al., 2013; Telesca et al., 2016) and their effect on the seismic hazard (Atkinson & Goda, 2011; Eroglu Azak et al., 2018; Sabetta et al., 2005). A sensitivity analysis is thus performed in this study to assess the effect of the choice of GMPEs and declustering methods on the output hazard. The results are presented in the form of hazard maps using PGA (at T = 0 s) and spectral accelerations at a short period (0.2 s) and at long period (1 s) for 2% and 10% probability of exceedance (PE) in 50- and 100-year time frames. Additionally, hazard curves as well as UHRS for each district are presented. Based on the PGA values attained, the complete Kashmir region is divided into five seismic zones and the corresponding hazard curves and UHRS for each zone produced. Disaggregation charts showing the relative contribution of magnitude and distance combinations of sources are also provided. The results presented herein form a practical and beneficial resource for the appropriate seismic design of buildings and other infrastructure in the region.
2 Tectonic Framework of Kashmir Region (NW Himalayas)
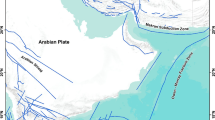
Situated in the northwesternmost segment of the Himalayan arc, the Kashmir region is one of the most earthquake-prone regions in the world. The collision of the Indian and Eurasian Plates that started over 50 Ma has resulted in the formation of the Himalayan Mountain range and the subsequent high seismicity in the area (Searle et al., 1986). The plates are converging at a rate of ~ 30–40 mm/year towards the NNE (Stevens & Avouac, 2015), about half of which is accommodated along the MHT (Main Himalayan Thrust) in the Himalayas (Bettinelli et al., 2006). The Greater Himalaya, Lesser Himalaya, and Inner Himalaya represent the major tectonic components of the Himalayas (Karan, 1966). These ranges are separated by three major NW–SE-trending thrust systems (from north to south), namely the Main Central Thrust (MCT), Main Boundary Thrust (MBT), and Main Frontal Thrust (MFT). These thrust systems have played a major role in the formation of the parallel Himalayan ranges and the geomorphological evolution of the Kashmir basin as well as the Himalayan relief in general (Vassallo et al., 2015). The principal thrust systems in the region along with the cross section from Jammu to Kashmir basin are shown in Fig. 1. The thrust systems merge with a deep-seated decollement—the Main Himalayan Thrust (MHT)—which acts as a separation between the Indian Plate from the overriding Himalayan orogeny (Nabelek et al., 2009). The Kashmir Valley is also affected by the confluence of three major mountain ranges, viz., the Himalayan range, Hindu Kush range, and Pamir range.

Tectonic framework of the Kashmir Himalayas. a Simplified structural map of the Northwestern Himalayas. b Principal tectonic structures in the region. c Crustal cross section of line AA’ in B extending from Jammu to Kashmir (Vassallo et al., 2015)
Kashmir Basin lies between the major deep-seated Panjal Thrust (MCT) and the Zanskar Thrust (ZT) and is surrounded on the northern end by the Main Karakoram Thrust (MKT) and the Main Mantle Thrust (MMT). The MKT forms the southern boundary of the Hindu Kush and the Karakoram, accommodating the thrusting of the Karakoram Plate southwards over the Ladakh block (Rex et al., 1988). The MMT is considered the western extension of the MCT and lies within the Hazara-Kashmir Syntaxis. The Karakorum Fault (KF) forms a major dextral strike-slip system running almost parallel to the northwestern Himalaya (Chevalier et al., 2005) and separates the tectonic regimes of western Tibet and NW Himalaya (Houlie and Phillip, 2013). Kashmir Basin is further laced by Indus Tsangpo Suture Zone (ITSZ), Indus Kohistan Seismic Zone (IKSZ), and Himalaya Hazara Thrust System (HTS) in the north. The northwesternmost segment of the Himalayas, known as Hazara Kashmir syntaxis (HKS), is a zone for major earthquakes in the region due to the activity of MBT, MCT, and MFT at this junction. The syntaxial bend is a result of the pushing of the westernmost end of the Indian Plate into the Eurasian Plate and hosted the epicenter of the devastating 2005 Kashmir earthquake. Yeats et al. (1992) identified two main active fault systems within the syntaxis, the NW–SE-trending Balakot Bagh Fault (Hussain & Yeats, 2006) and the south-trending Jhelum Fault.
Most of the stress accumulated along the plate boundaries in the Himalayas is released through the rupture of the major thrust systems (MBT, MCT, MMT); however, some portion of the stress is also released through several out-of-sequence smaller faults, like Reasi Thrust (RT), Kishtawar Thrust (KT), Kotli Thrust (KoT), and Balakot Bagh Fault (BBF), including strike-slip faults like Jhelum Fault (JF) and Shinkiari Fault (SF) (Tapponnier & Molnar, 1977; Panday et al., 2017). The 8 October 2005 Kashmir earthquake reactivated the Tanda and Muzaffarabad Faults (Zare & Karimi-Paridari, 2008) in HKS, which were subsequently renamed together as the Balakot-Bagh Fault (BBF). BBF is an out-of-sequence reverse fault (Perumal and Thakur, 2008), which is thought to be extending as a subsurface fault and emerging as the Riasi Thrust in Jammu (Gavillot et al., 2016).
2.1 Recently Delineated Seismogenic Structures
A number of faults have been delineated within the Kashmir basin itself (e.g., Alam et al., 2015; Ganju & Khar, 1984; Yeats et al., 1992), many of which however lack support from appropriate field investigations. The Balapur Fault (BF) is the only tectonic structure within the Kashmir basin that has been properly established through thorough field investigations, paleoseismic observations, and geomorphic methods (Ahmad et al., 2015, 2017a; Madden et al., 2010). It is a NW–SE-trending fault that passes through the highly populated cities of Shopian, Pulwama, Anantnag, Kulgam, and Budgam in South Kashmir. Being present within the Kashmir Basin, and having an identified length of 95 km (Ahmad et al., 2017a), BF could be a source of significant seismic hazard in the region. Moreover, Ahmad et al. (2015) suggested the presence of a strike-slip fault, which they named as Central Kashmir Fault, to be passing almost through the centre of the Kashmir region. Furthermore, positive anomalies detected from observations of gravity data (Qureshi, 1969) as well as information on a deep-seated fault structure almost parallel to Jhelum River (Kaila et al., 1978) provide substantial evidence for the presence of large structures like the Central Kashmir Fault (CKF) within the Kashmir Basin. Ahmad et al. (2015) established the strike of the CKF using geomorphic indicators and outlined its role in the formation of the Kashmir region. Shah and Malik (2017) delineated four new curvilinear faults striking NE–NW through geomorphic analysis of the landforms in Jammu and Kashmir, indicating thrusting along the faults with a small component of sinistral faulting. These faults, namely Tunda Fault, Mawer Fault Zone, Gulmarg Fault Zone, and Udhampur Fault Zone, are mainly NW–SE trending. Sharma et al. (2014) noted a concentrated seismicity within the area bounded between MBT and MCT within Kishtwar and Doda districts of Jammu. This region between the Panjal Thrust (PT) and the Kishtwar Window is highly active with 200 earthquakes recorded from March to September 2013 (Coordinated Universal Time, UTC), including the Mw 5.7 earthquake on 1 May 2013 and Mw 5.1 earthquake on 2 August 2013 (Sharma et al., 2014). Such occurrence of earthquakes at shallow depth (7–12 km) indicates the presence of an active zone above the region of decollement (Panday et al., 2017).
Kashmir is also affected by the Hindu Kush region, which is a far-field seismic source for the region. Hindu Kush is an east–west-trending, very rugged, and complex mountain range system created by the clockwise rotation of the Indian Plate into the Eurasian Plate (Burtman & Molnar, 1993). It stretches over about 800 km along the Afghanistan-Pakistan border and is a junction of three main mountain ranges—Hindu Kush, Karakorum, and the Himalayas—resulting from the India-Eurasia collision. It is tectonically active with mostly intermediate-to-deep foci (70–300 km) earthquakes (Pavlis & Das, 2000) occurring at a high rate of over 100 earthquakes of magnitude Mw 4 and above in a year. A number of studies proposed the theory of continental subduction beneath the Pamirs and Hindu Kush (e.g., Burtman & Molnar, 1993), while others proposed the hypothesis of a sinking blob (Molnar & Bendick, 2019) creating a vertically dipping seismic zone in which the material is being stretched at a rate of 100 mm/year. Hazard studies in Afghanistan (e.g., Waseem et al., 2018) have pointed out the high hazard generated by the seismically active Hindu Kush and Pamir regions.
3 Seismicity in and Around the Kashmir Region
Kashmir has a long history of seismic activity and resulting extreme damages. Documentation of the devastating earthquakes in the historical records of Kashmir and their profound effects on the life and property in the valley provides a clear picture of the high seismic hazard to which the region is exposed. The particulars of the historical earthquakes in Kashmir regarding the damage witnessed by people have been reported widely in the literature, mostly in the Sanskrit and Persian records of the region. The most important source of information on historical earthquake events in Kashmir is a four-part series of an ancient Sanskrit work collectively known as Rajtarangini. The first part, Rajtarangini, written by Kalhana Pandit, gives an account of historical events from the remote past to 1148 AD; the second part, Rajavali, by Jonaraja, extended the records up to 1459 AD; the third part, Jainrajtarangini, by his pupil Srivara, mentions events up to 1477 AD, and the last part, Rajavali Pitaka, by Prajya Bhatt and Suka, covers the period up to 1587. Another significant historical record is a Persian manuscript, Tarikh-e-Hasan, by Pir Hasan Shah (nineteenth century AD), which documents 13 earthquakes from 1250 BC to 1885 AD. Recent works on the compilation of historical earthquakes include the likes of Oldham (1883), Iyengar et al. (1999), Ambraseys and Douglas (2003), and Ahmad et al. (2009).
Oldham (1883), in his catalogue of Indian earthquakes, documents three historical earthquakes (1552, 1669, and 1828) in the valley of Kashmir. Iyengar et al. (1999) collected information on earthquakes in the medieval period (1200–1800) in India after a review of various historical records. They provide a database of 12 historical earthquake records in the Kashmir Valley. An elaborate study by Ahmad et al. (2009) is yet another major attempt at preparing a comprehensive catalogue of historical earthquakes from the medieval period up to 1900 AD. They retrieved information on around 17 earthquakes from an exhaustive perusal of Sanskrit and Persian historical literature. Ahmad and Shafi (2014) further modified and updated this catalogue by adding missing earthquakes from 1128 to 1570 retrieved from various Persian and other historical records. Later, Ahmad et al. (2015) added six more previously unreported historical earthquakes. In addition to these catalogues, works are available related to detailed study of some major historical earthquakes in Kashmir like the 883 earthquake (Bilham and Bali, 2013), 1555 earthquake (Ambraseys and Douglas, 2003), 1885 earthquake (Jones, 1885; Ahmad et al., 2014), 1828 earthquake (Bilham et al., 2010) and so on. The particulars of these earthquakes regarding the damage witnessed by people and documented in historical records are presented in Table 1.
The October 8 2005 Kashmir earthquake is proof of the accumulation of stress along the plate boundaries especially along the Hazara-Kashmir Syntaxis (HKS) in the NW Himalayan region. Since this event occurred on a fault that was formerly believed to be inactive, it is a prime example of the dynamic nature of the active tectonics in the Himalayas. Around 80,000 people are reported to have been killed in the event, and thousands of buildings collapsed. A spatial concentration of the earthquakes (both recent and historical) is observed in the HKS (Ahmad et al., 2017b), the most remarkable being 1501, 1555, 1669, 1736, 1779, 1824, 1828, 1885, and the recent 2005 Muzaffarabad and 2019 Mirpur earthquakes.
Furthermore, the events seem to be concentrated along a NNW and SSE-orientation within the Kashmir Valley, which may suggest the presence of tectonic structures within the basin like the Central Kashmir Fault, Balapur Fault, and so on (Ahmad et al., 2017a; Alam et al., 2015). Other significant events in the recent history of the Kashmir region include the 1905 Kangra, 1963 Budgam, 1967 Anantnag, and 1974 Pattan earthquakes. The records of the devastating nature of the earthquakes and their overwhelming effects provide a glimpse into the future seismicity and associated risks to which the Kashmir region is exposed. Most recently, the 24 September 2019 Mirpur earthquake caused large ground shaking and deformations in the area.
Earthquakes occurring in the Hindu Kush-Pamir region are also felt significantly in Srinagar, Jammu, and Kashmir, even though the regions are ~ 500 km apart. This is because the earthquakes have deep foci, characterized by low attenuation of seismic waves (Oliver and Isacks, 1967) and high wave speeds (Mitronovas and Isacks, 1971). Thus, they show a greater effect at larger distances from the epicentres than at the surface directly above their foci. Several major earthquakes have occurred in the Hindu Kush, Afghanistan, causing a significant hazard in Jammu and Kashmir. The 3 March 2002, M 7.4 earthquake at a depth of 225.6 km and the 26 October 2015, M 7.5 earthquake with a focal depth of 231 km are the most recent ones.
4 Seismic Hazard Assessment
The probabilistic seismic hazard analysis procedure outlined by Cornell (1968) and later by McGuire (2004) has been adopted in this study. The readers are requested to refer to the studies which summarize the computations and complete equations involved in PSHA in detail (e.g., Baker, 2015; Kramer, 1996, etc.). The outputs are expressed in terms of parameters like peak ground acceleration (PGA), peak spectral acceleration (Sa), disaggregation charts, seismic hazard curves (SHC), and uniform hazard response spectra (UHRS).
4.1 Development of Tectonic Map
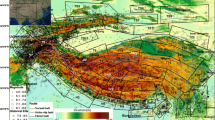
Seismic sources within a radius of ~ 350 km were considered around Kashmir region with Srinagar as the centre (coordinates 34.06°N and 74.82°E) for this study. The main source of information considered was the Seismotectonic Atlas of India (GSI, 2000), which includes the details of thrusts, lineaments, and other fault systems for the whole of India. This database was supplemented by the information on new faults delineated in and around the Kashmir region since 2000. Several active faults have been delineated within the Kashmir Basin itself through geomorphological investigations or using remote sensing techniques and digital elevation models. Figure 2 shows the seismotectonic map generated in this study for the region, representing all the major faults and seismic sources within a 350-km radius of the Kashmir region.

Tectonic map for Kashmir region. The dashed circle represents the 350-km radius around Srinagar city within which the faults have been considered. Major tectonic features of the northwestern Himalaya include the Main Central Thrust (MCT), Main Boundary Thrust (MBT), Main Karakoram Thrust (MKT), Himalayan Frontal Thrust (HFT), Main Mantle Thrust (MMT), Hazara Kashmir Syntaxis (HKS), Karakoram Fault (KF), Shinkiari Fault (SF), Salt Range Thrust (SRT), Jhelum Fault (JF), Jwalamukhi Thrust (JT), Kishtawar Thrust (KT), Kishtawar Window (KW), Balakot Bagh Fault (BBF), BF (Balapur Fault), Reasi Thrust (RT), Udhampur Fault Zone (UFZ), Mawer Fault Zone (MFZ), Central Kashmir Fault (CKF), and Kamila Shear Zone (KSZ). Yellow stars represent epicentres of earthquakes with Mw > 6. Focal mechanisms of major earthquakes have been included
In this study, individual linear sources and two area sources—Hindu Kush and Kishtawar Window—have been considered. Based on the observations in the available literature, Hindu Kush cannot be represented by a single thrust or suture; instead, it needs to be considered as a source zone spread over some area. Similarly, Kishtawar Window is also considered an area source zone.
4.2 Development of the Earthquake Catalogue
Earthquake records of seismographs worldwide form a comprehensive database of instrumental earthquakes for the development of an earthquake catalogue in any region. Events within the 350 km radius around the study region (Fig. 2) were collected starting from the year 1900 till 30 September 2020 from open access online sources like the United States Geological Survey (USGS) and the International Seismological Center (ISC). Data were also gathered from the Indian Meteorological Department (IMD) through personal communication with the department.
These databases provide detailed information about time including year, month, day, hours, minutes, and seconds of occurrence; location including longitude, latitude, and depth of epicentre; as well as magnitude including various available scales like Ms, mb, ML, MD, and Mw (surface, body-wave, local, duration, moment), and so on. The earthquake data from the different sources were combined and duplicate events were removed. Twenty-six documented historical earthquakes have been collected from the detailed literature survey (Table 2). Along with the instrumental data, the events add up to a total of around 7386 events, forming the raw dataset for this study, which was further used for the final catalogue generation. The event data for Mw < 3.5 is incomplete because of the dearth of instrumentation in the region. The instrumentation for recording earthquakes is minimal within the Jammu and Kashmir region itself, and therefore the only records available are through the open-source information from the USGS seismic stations and those installed in the neighbouring regions. It is indeed the lack of events of small magnitude in the region which leads to the relatively smaller number of events in the earthquake catalogue (i.e., 7386).
4.2.1 Magnitude Homogenization
Since earthquake data are collected from different sources which in turn acquire data from various seismic stations having varying methods of measurement of magnitude of earthquakes, the data are highly non-homogeneous. Thus, the magnitudes need to be converted to a common scale to homogenize the data. All other scales (mb, MS, ML, MD, etc.) have been converted to Mw using magnitude conversion equations developed by Scordilis (2006) and Deniz and Yuceman (2010). Based on the preference given to different magnitude scales, the procedure outlined by Karimiparidari et al. (2013) has been adopted for magnitude conversion.
4.2.2 Declustering
Seismicity consists of independent/background events, which are the mainshocks, and dependent events, which include the after- or foreshocks (Wyss & Toya, 2000). It is argued that consideration of the aftershock sequence would lead to an overestimation of the rate of occurrence of earthquakes around a fault, in other words overpredicting the activity of the faults. In statistical terms, the presence of these clustered events causes seismicity to have a non-poissonian distribution. The process of separating dependent earthquakes from independent earthquakes is called declustering and forms an essential part of processing an earthquake catalogue for seismic hazard assessment.
van Stiphout et al. (2012) have presented a review of around 25 available declustering methods. In this study, the Gardner and Knopoff (1974), Urhammer (1986), and Gruenthal (1985) methods were used amongst the window methods, whereas Reasenberg algorithm (1985) was chosen amongst the cluster methods for declustering the earthquake data for the region. The 26 historical earthquakes were excluded from the declustering procedure since these were collected directly from historical records and are definitely main events that must be retained within the catalogue. The combined and homogenized earthquake catalogue obtained from online sources thus has about 7360 events. An updated set of MATLAB codes for major declustering techniques was obtained through personal communication from Dr. Jiancang Zhuang (Institute of Statistical Mathematics, Japan, and a member of the Community Online Resource for Statistical Seismicity Analysis, CORSSA).
Table 2 presents the results of the application of declustering algorithms to the raw database of earthquakes utilizing the mentioned MATLAB code. For simplicity, these methods will hereafter be represented by the respective codes as mentioned in the table. There is no single method which can be classified as best for declustering of earthquakes in general. The suitability and effectiveness of a declustering method vary for different regions. Therefore, the catalogue obtained after employing the three declustering procedures was checked and compared for the efficiency in removal of aftershocks as well as the retention of mainshocks. All algorithms retain the main earthquakes that have occurred during the time period. However, the number of events identified as after- and foreshocks differs considerably. In addition to the results of this study, the results from two more studies—Eroglu Azak et al. (2018) and Galina et al. (2019)—are included in Table 2 to compare the percentages of earthquakes eliminated in the declustering process. The percentages removed vary with the region for each of the methods. The Reas85 method, however, shows a similar trend in Eroglu Azak et al. (2018) with minimal elimination of aftershocks.
4.2.3 Influence of Declustering Methods on Earthquake Catalogue
A comparison of the declustering methods in Table 2 indicates that Gru85 removes the maximum number of events as aftershocks, followed by GK74 and then Uhr85. In the window-based methods, the detection of dependent events is solely a function of the size of the defined magnitude and temporal windows. In general, bigger time windows are specified from Gru85 compared to GK74 and Uhr86 at smaller magnitudes (Eroglu Azak et al., 2018), which in turn causes more events to be classified as after- and foreshocks in the former. This is reflected in the higher percentage of data being removed through the procedure (Table 2). This feature may, however, cause the algorithm to misinterpret and discard several main events as dependent events (Eroglu Azak et al., 2018). In comparison, GK74 was found to perform better, and the results also agreed well with the seismotectonic structure. Moreover, it is evident that for this study region the effect of the Reas85 algorithm on the earthquake catalogue is not significant. The algorithm removes only 8–15% of events as aftershocks. Clusters of main events associated with dependent events are still seen in the results of the Reas85.
To compare the working of the declustering methods, a manual check was performed for the aftershocks of the 8 October 2005 Kashmir earthquake. This cluster of selected earthquakes was examined in terms of the spread of the earthquakes over space and time. After the main event, an increased seismicity is observed in the raw catalogue, obviously due to the aftershock sequence that followed. The Reasenberg algorithm fails to remove these aftershocks around the epicentre of the main event, while the other methods are fairly successful in identifying them as aftershocks. A similar observation about Reas85 was made for other regions like New Zealand (Christophersen et al., 2011) and Turkey (Eroglu Azak et al., 2018). This is due to the inefficiently small spatial extent considered in the method (Eroglu Azak et al., 2018), particularly for small to intermediate earthquakes. Thus, according to their conclusive studies, Eroglu Azak et al., (2018) suggested that the Reas85 algorithm may perform better for complete catalogues and may not work well on incomplete catalogues. Since the earthquake catalogues are not complete over the entire duration of time considered, due to the paucity of instrumentation in earlier times, this becomes an issue for the application of the Reas85 algorithm. Moreover, the outcome of the Reas85 algorithm depends on the input parameters, which thus need to be chosen carefully. For these reasons, the results from the Reas85 algorithm have been dropped from further analysis in this study.
For further comparison among the three declustering methods (i.e., GK74, Gru85, Uhr86), the seismicity maps for the region derived by plotting earthquake events regarding their coordinates are presented in Fig. 3. A comparison of the maps illustrates the level of reduction in background seismicity after the application of the three declustering procedures. The map from Gru85 clearly indicates lower seismicity, Uhr85 shows the most events on the map, whereas GK74 gives intermediate results.

Seismicity maps for Kashmir region using a GK74, b Gru85, and c Uhr86. Yellow stars represent events with Mw ≥ 6, whereas blue dots represent events with Mw < 6
The magnitude histograms for each catalogue have been plotted to demonstrate the distribution of the number of events over various magnitude ranges (Fig. 4). Observing the effect on the number of events in different magnitude bins (Fig. 4), it is found that similar window sizes are attained at larger magnitudes (Mw > 6). The histograms also indicate that the proportion of smaller magnitude earthquakes (< 4 Mw) in the declustered catalogues from GK74 and Gru85 methods is much less than in Uhr86.

Magnitude histograms of GK74, Gru85, and Uhr86 catalogues
The cumulative graph of earthquake events with time gives an idea about the rate of occurrence of earthquakes and any major changes therein. A sudden change in the slope of the graph could suggest a change in the rate of earthquake occurrence. A comparison of these cumulative graphs for the declustered catalogues regarding that of the raw catalogue for the study region is shown in Fig. 5. The arrows represent the change in slope in the catalogues. The sudden spurt in events around 1970, however, is indicative of the increase in instrumentation worldwide and hence a better recording of the earthquakes.

Plot of the cumulative number of earthquakes with time for GK74, Gru85, Uhr86, and raw catalogues. Arrows indicate the years when the declustering algorithms start diverging significantly in their results of cumulative number of earthquakes
It is evident that the cumulative number in all the catalogues before 1960s is very small and they mostly contain information on large magnitudes which are probably the main events. Therefore, the effect of the declustering algorithms is insignificant before the 1960s. Beyond this point, the differences introduced by the declustering methods can be clearly seen. The cumulative number of earthquakes reduces in the catalogues after declustering compared to the raw catalogue. Moreover, the plots for declustered catalogues also deviate with respect to each other and to the plot of raw data after around the year 1970 when the instrumentation era started. This deviation increases with years and becomes more pronounced after the year 1999, after which smaller and smaller events are recorded, which are most sensitive to being removed as aftershocks. Similar observations have been made by Mizrahi et al. (2021) for California earthquakes.
In general, declustering of earthquake catalogues is far from being a straightforward procedure thought to yield exact results. This is mainly because most of the declustering techniques rely on subjective guidelines and definitions to discriminate between main events and the associated dependent events. As a result, the final catalogues derived using various declustering approaches significantly differ in various aspects. In the absence of a single standardized procedure, the selection of the best declustering method and assessment of the effects on the final seismic hazard assessment are major concerns. Moreover, the proportion in which large and small magnitude earthquakes are removed has a serious impact on the calculation of a and b seismicity parameters. In this study, therefore, we utilize all three declustering methods (i.e., GK74, Gru85, and Uhr86) in a logic tree framework, as described later, such that the epistemic uncertainties associated with these algorithms are accounted for.
4.2.4 Completeness Analysis
Completeness analysis is an important step in the development of a complete earthquake catalogue. The cumulative visual investigation method (CUVI) by Tinti and Mulargia (1985) has been used in this study. It is a simple graphical procedure and was applied individually to the earthquake catalogues derived from the three declustering methods (GK74, Gru85, Uhr86). The catalogues were divided into 12 magnitude bins and the cumulative number of events was plotted against the years for each bin. The completeness intervals are determined from the visual investigation of the plots. The results from this method have been compiled in Table 3. The values imply that the completeness interval is a function of the declustering method used.
The low magnitudes are incomplete because of the unavailability of such data in the region arising from the lack of proper instrumentation. Moreover, the interval is higher for Uhr86 than GK74 and Gru85 at smaller magnitude bins (Mw < 4). This is as expected, because the removal of a larger number of low magnitude earthquakes as dependent events in Gru85 and GK74 reduces the completeness interval. For these reasons, the completeness intervals for magnitude (Mw < 3.5) are not reliable and must not be used for further analysis. Contrarily, the influence of the selection of a declustering procedure is negligible for higher magnitudes as is also noticed from the similar completeness periods at magnitudes Mw > 5. The estimated completeness intervals suggest that the data are complete for higher magnitude earthquakes.
4.3 Recurrence Parameters Using Gutenberg-Richter Equation
The mean annual rate of exceedance of earthquakes λm is the number of earthquakes greater than ‘m’ divided by the time period. The logarithm of the rate of exceedance of the earthquakes is plotted against the magnitude. The equation of the straight line representing these points is the Gutenberg-Richter (GR) equation, which is defined by the intercept ‘a’ and slope ‘b’ as follows
The magnitude of completeness (Mc) for a catalogue is the magnitude above which the catalogue is considered complete. Thus, for further analysis, only events with Mw ≥ Mc are considered (Wiemer & Wyss, 2000). The GR line has been plotted for the three declustered catalogues (Fig. 6). The point where the GR line becomes nonlinear is marked as MC. MC is assumed as 4 for all three catalogues from an observation of the recurrence plots (Fig. 6).

Gutenberg-Richter recurrence relations for GK74, Gru85, and Uhr86 catalogues
The summary of the seismicity parameters derived from the GR equation is presented in Table 4. A comparison of the results of the CUVI method applied to catalogues derived using the three declustering techniques shows clear differences. Uhr86 gives a larger b-value (b = 1.202) than GK74 (b = 1.1) and Gru (b = 1.03) methods. This was expected since the former retained more small magnitude earthquakes than the latter two in the declustered catalogue. For the same reason, ‘a’ parameter is also higher as derived from Uhr86.
4.4 Estimation of MC Using Maximum Curvature Method (Wyss and Weimer, 2000)
The maximum curvature (MAXC) technique proposed by Wiemer and Wyss (2000) was also used to determine a more appropriate estimate of MC. In this method, the Gutenberg-Richter model is fixed to the observed frequency magnitude distribution (FMD). Mignan and Woessner (2012) provide the complete details of MAXC method along with a summary of other available techniques. The magnitude at which the lower end of the FMD departs from the linear trend in the log-lin plot is considered the Mc (Zuniga and Wyss, 1995). Alternatively, the cumulative FMD plots can also be used for the estimation. In addition to the standard cumulative FMD, a non-cumulative FMD is plotted to overcome errors due to cumulation. Through simple visual evaluation, the point of maximum curvature is easily detected in the dataset.
Figure 7 presents the cumulative FMD plots for the three declustering methods. The summary of the outcome of the maximum curvature method in terms of magnitude of completeness (MC), a and b values, and the annual rate of exceedance (λ) for the three catalogues is presented in Table 5. Notably, declustering procedures have a significant impact on the final estimates of seismicity in a region. Since Uhr86 retains more small magnitude earthquakes than GK74 and Gru85, MC turns out to be less in the former catalogue, signifying that the catalogue is complete for smaller magnitudes.

Comparison of FMD plots for a GK74, b Gru85, and c Uhr86 catalogues. Filled squares are number of earthquakes of each magnitude bin; empty squares are cumulative number of earthquakes equal to or larger than each magnitude. Red solid lines represent the best-fit linear regression and Mc is the magnitude of completeness
The maximum curvature method (MAXC) is one of the simplest techniques for estimating MC. Furthermore, it is considered more vigorous and better than the least square regression method (Xie et al., 2019). Therefore, this method was finally selected for estimating MC, which was further used as an input in the calculation of the seismicity parameters mmax, λ, and b value through the Kijko and Sellevol (1992) method.
4.5 Calculation of Seismicity Parameters, m max, λ, and b-Value (Kijko et al., 2016)
The seismic catalogue for this region is incomplete, especially for the time period before the instrumental era started. For this reason, the classical Aki-Utsu estimator or the Gutenberg-Richter recurrence model for the b-value is not appropriate for these data. The maximum likelihood procedure proposed by Kijko and Sellevoll (1989), KS-I, allows for the inclusion of incomplete catalogues composed of historical as well as instrumental events. This helps to incorporate the uncertainty due to the incompleteness of earthquake catalogues. The input catalogue is divided into two parts, complete and extreme. Extreme input includes prehistorical and historical events, whereas complete input consists of events which were recorded after the beginning of the instrumental era and is usually available for relatively short periods of time. The complete part is further divided into sub-catalogues such that these are complete for different time intervals and minimum magnitude levels (MC). This allows for the consideration of missing records by permitting for occurrence of gaps (Kijko & Sellevoll, 1989).
The method KS-I was later modified by Kijko and Sellevoll (1992), KS-II, to account for the errors in earthquake magnitude and further by Kijko et al. (2016), KS-III, to account for the uncertainty in the earthquake model itself. This modified procedure is perhaps the only technique that allows the incorporation of complete and incomplete catalogues in the hazard assessment, in addition to accounting for magnitude and model uncertainties (Kadiri & Kijko, 2021). Thus, this updated method has been selected for λ, b-value, and mmax determination in the current study. User-friendly MATLAB codes developed by Professor Andrzej Kijko and his co-workers at the University of Pretoria Natural Hazard Centre were acquired from Professor Kijko. For a complete review of the procedure, the reader is referred to Kijko and Sellevoll (2016).
4.5.1 Input Parameters
The HA3 code provided by Prof. Kijko allows for the input of the earthquake events as separate catalogues based on completeness. As per the specified procedure, the dataset for this region was divided into three sub-catalogues—one historical (H1) and two instrumental/complete catalogues (C1, C2). The temporal extent of historical, and complete catalogue is decided based on the examination of sharp changes in slopes in the cumulative plots for earthquakes obtained for the whole catalogue. From the observation of the plots of the catalogues derived from the three declustering methods (Fig. 5), the historical catalogue was considered to extend till the year 1970 and the complete part of the catalogue to start from the year 1971, after which instrumental records are available for the region. The complete catalogue-1 (C1) was assumed to start in 1971 and end in 1999, whereas the complete catalogue-2 (C2) was assumed to begin in 1999.
Threshold magnitude was checked separately for each individual sub-catalogue (incomplete and complete). The threshold magnitude (Mmin) for the historical catalogue (H1) is higher than that for the complete catalogues. Accordingly, the values for threshold magnitude were assumed for the catalogues as given in Table 6. This was anticipated since the historical records are complete for strong events which are easily detectable. Next, the input file is to be constructed in such a way that only magnitudes greater than the threshold magnitude are included in the file. Furthermore, the error in magnitude determination was assumed to be highest (~ 0.3) in H1. It was assumed to be less in the complete datasets (Giardini et al., 2004)—0.2 in C1 and 0.1 in C2. Once the catalogue is divided in time, and all the parameters are fixed, the standard computer programme (Kijko and Sellevoll, 2016) is used to determine the earthquake recurrence relation. The respective magnitudes of completeness of each sub-catalogue (MC), maximum expected magnitude (Mmax), magnitude errors considered, the time windows, and so on, are summarized in Table 6. The MC value for each catalogue is selected from the results obtained by employing the MAXC (Wiemer & Wyss, 2000) method (Table 5).
When the catalogues are input into the programme, it asks the user if an a priori value of b-parameter is available, which is important to stabilize the results from the code. In this study, the first estimate of b-value from the MAXC method (Table 5) was used as the initial value. Furthermore, the programme gives an option to select the method of analysis from a list of choices as follows, out of which, the Kijko-Sellevoll-Bayes was used as per the recommendation in the manual. This method helps to keep the whole analysis based on Bayesian principles for consistency. The final results are attained after a number of iterations. The analysis is performed using the least value of threshold magnitudes in all the catalogues.
4.5.2 Outcomes
The recurrence parameters (b-value, λ, and mmax) estimated through the implementation of Kijko and Sellevol (2016) procedure on the catalogues GK74, Gru85, and Uhr86 in this study, are presented in Table 7. The results reveal that the recurrence parameters vary for each catalogue. The conclusions drawn from the results are encapsulated in the following points:
1. The maximum possible earthquake (mmax) is the largest earthquake that is expected to occur in a specific seismotectonic framework. mmax for the complete Kashmir region computed in this study is in the range of 7.97–7.98, whereas the b-value ranges between 0.92 and 1.05 for the three catalogues (Table 7). These values fall within the general range for the region as obtained by other studies (Chandra et al., 2018; NDMA, 2011; Sana & Nath, 2017). The global b-value is said to range between 0.45 and 1.5 (Gutenberg & Richter, 1954). In general, the b-value is close to 1.0 in active tectonic regimes (Reasenberg & Jones, 1989). Fundamentally, a low b-value represents higher stress and the possibility of higher magnitude events in the future (Weimer and Wyss, 1997). The activity rate λ varies by a huge margin between 3.878 and 13.53. Furthermore, it can be observed that the variance in the b-value is much smaller than in the values of activity rate and mmax.
2. The seismic hazard curves and return period curves for the region using the three catalogues are shown in supplementary material (Figs. S1–S3). Table 8 includes the values of the mean rate of exceedance, return periods, and corresponding probability for time periods 1, 50, 100, and 1000 years for various magnitudes of earthquakes. A cursory look at the results suggests that λ (activity rate) reduces as the magnitude of earthquakes increases. Moreover, the probability of exceedance (PE) for the same catalogue reduces as the magnitude level increases. In simple terms, this means that larger magnitudes occur less often than smaller magnitudes.
3. For activity rate, a specific trend amongst the respective results of the three catalogues in Table 8 is absent. On the other hand, the PE of the earthquakes is highest for Uhr86, followed by Gru85, then by GK74 for 50-, 100-, and 1000-year time periods. It can be stated that the PE of an earthquake of magnitude 7 is 87% in 50 years, 97% in 100 years, and 100% in 1000 years for GK74; 88% in 50 years, 98% in 100 years, and 100% in 1000 years for Gru85; and 97% in 50 years, 99% in 100 years, and 100% in 1000 years for Uhr86 in the region. Similar statements can be made for other magnitudes.
Conversely, the return period of the earthquake magnitudes follows an opposite trend and is, in general, largest for GK74, then for Gru86, and smallest for Uhr85. The hazard values are in line with the seismicity parameter b-value calculated from Kijko and Sellevoll method, i.e., lowest for Uhr86 and highest for GK74. The low b-value in Uhr86 is manifested as a higher hazard in terms of the probability of exceedance of the magnitudes. However, it is observed that the exceedance rates at higher return periods are influenced less by the declustering methods.
4.6 Selection of GMPEs for the Region
Strong ground motion data for the Jammu and Kashmir region are scarce; therefore, no particular GMPE has been specifically developed for this region. In such a case where regional GMPE is not available, relations developed for other tectonically similar regions are selected. In this study, the best suited three GMPEs have been selected out of which two are applicable for the Himalayas and the third one is based on a global dataset. The three sets of ground motion prediction equations (GMPEs) have been combined using a standard logic tree structure in the RCRISIS software to capture the epistemic uncertainties associated with the models.
One Next Generation Attenuation (NGA-west2) model, which Idriss (2008) developed from a global dataset, and two models developed for the Himalayan region—NDMA (2011) and Raghukanth and Kavitha (2014)—have been selected. The details of the selected attenuation relationships are provided in Table 9. Initially, Sharma et al.'s (2009) attenuation relationship was also included in the analysis. However, the DSHA calculations using this equation resulted in extremely high PGA values (> 2.00 g), which are unusual for any region. The reason for these unexpected results could be that Sharma et al. (2009) borrowed the strong motion data for the Himalayan region from the Zagros region of Iran assuming that the tectonic region is similar. We thus excluded the Sharma et al. (2009) equation after concluding that it is not suitable for the Kashmir Himalayas. Similarly, the GMPE developed for the Himalayas by Rao and Rathod (2011) could not be used even though it yielded good results. This is because one of the primary aims of PSHA in this region was to develop UHRS for all sites. GMPE by Rao and Rathod (2011) is limited to the calculation of PGA at T = 0 s, whereas the requirement to construct a UHRS is the calculation of peak spectral accelerations at different time periods. Therefore, these two equations had to be excluded from the analysis, reducing the logic tree branches to three GMPEs.
Hindu Kush is characterized by intermediate-depth earthquakes; therefore, GMPEs developed for a similar tectonic setup must be used. The GMPEs considered for the faults in the Kashmir region are for active shallow crustal zones, which are not applicable for Hindu Kush. Danciu et al. (2016) and Waseem et al. (2018) used GMPEs proposed by Youngs et al. (1997) and Lin and Lee (2008) for deep subduction earthquakes, following the recommendations of Danciu and Woessner (2014) for deep seismicity in Varancea. Along similar lines, in this study, we used the inbuilt GMPE in RCRISIS proposed by Montalva et al. (2017) for deep subduction earthquakes for both the Hindu Kush region and the Kishtwar seismic zone. The attenuation relationship by Montalva et al. (2017) was proposed for the Chilean subduction zone for deep depth events that occurred between 1985 and 2015. It was chosen because of its simple functional form and being inbuilt within RCRISIS making it relatively easier to use.
4.7 DSHA
The deterministic method is applied as a precursor to the probabilistic method and several studies consider both equally important (Bommer, 2003). For seismic hazard estimation, the entire study region was divided into small grids of 0.04˚ × 0.04˚ size resulting in a total number of grid points equal to 1228. At each grid point, the PGA values are computed using the maximum magnitude (Mmax) and shortest source-site distance (Rmin) using an attenuation relationship (Reiter, 1990). Mmax is computed from the length of the fault using the Wells and Coppersmith (1994) empirical relationship. This becomes the controlling earthquake which produces the maximum expected ground motion parameter at the site. Multiple GMPEs, as discussed in the previous section, have been used to estimate the PGA at each grid point. Finally, the maximum PGA obtained amongst all the GMPEs has been selected as the resultant PGA at the site in this study.
The Central Kashmir Fault (CKF) is critical for all the districts since it is an important fault of substantial length passing through the entire length of the valley. The spatial distribution of PGA values determined throughout the Kashmir region from DSHA has been plotted in the form of a colour relief map (Fig. 8). The PGA values for the whole region range between 0.50 and 1.30 g indicating very high hazard potential. The spatial distribution makes it clear that the southwestern flank of the valley is exposed to a high hazard because of the presence of faults within the valley like CKF, BF, and the major thrusts MCT, MBT running along the length of the valley. The northwestern end of the valley being located near the Hazara-Kashmir syntaxis and incised by faults like MFZ, TF also shows high PGA values. The central part of the valley has a relatively low hazard, whereas the northern part is again exposed to a high hazard because of the presence of MMT and Kamila shear zone nearby.

Hazard map at bedrock for the Kashmir region showing the spatial distribution of the map estimated using DSHA
4.8 PSHA Using RCRISIS Software
Initially developed as CRISIS software (Ordaz, 1991) and modified into RCRISIS in later versions (Ordaz et al., 2017), the software is highly versatile and efficient for the probabilistic seismic hazard analysis based on the standard Cornell-McGuire approach. It involves options for the input of different types of seismic sources—point, line, area, and volume—with an option to specify the seismicity parameters to each individual source.
The software treats all points within a seismic source as a potential focus of the earthquake thus assuming an even distribution of seismicity within the source zone. It then carries out a spatial integration process to account for all possible focal locations within the source. RCRISIS has a large database of inbuilt global and regional GMPEs for different tectonic regimes (active shallow crustal, subduction/deep zones) from which the user can select as per requirement. It also has the option of adding user-specified GMPEs through the input of attenuation tables.
In RCRISIS software, the input was specified in detail in the following steps. The area of study was first defined in the software in the form of a shapefile, followed by a specification of grid points. The results of DSHA have been used to sort the seismic sources for further use in PSHA. From a structural point of view, PGAs < 0.03 g are insignificant even for weak buildings constructed using poor construction practices and sub-standard materials (Gabor, 2010). Thus, for conducting PSHA at a site, faults producing significant ground motion (> 0.09 g) are sorted using DSHA and input in RCRISIS. Table 10 shows the faults producing PGA > 0.09 g selected for PSHA and the related information. Then, seismicity parameters a, b-values, λ, and mmax were entered for each seismic source.
The b-value for all faults is considered to be constant and equal to the b-value for the whole of the Kashmir region (Table 7) following the guidelines of Iyengar and Ghosh (2004). One may estimate the a- and b-values separately for each fault in a region; however, due to the lack of knowledge on precise and allowable slip rates for the faults, this information is unavailable in the Kashmir region. Even for clearly identified active faults, this knowledge gap is unlikely to be closed very soon. Therefore, even if the arguments were to be heuristic, it is crucial to find an acceptable approach to get over this challenge (Iyengar and Ghosh, 2004); therefore, a constant b-value is assumed.
The mmax for each fault is as in Table 7. The activity rate, λS(m0), for each source is calculated by multiplying a weighting factor to the activity rate of the whole region. These weighting factors are estimated using the deaggregation procedure of Iyengar and Ghosh (2004). Furthermore, the set of return periods for which the analysis needs to be conducted is stated and the spectral parameters for the construction of a uniform hazard response spectrum (UHRS) are specified.
Based on the observations in the available literature, Hindu Kush cannot be represented by a single thrust or suture; instead, it needs to be considered as a source zone extending over some area. For area sources—Hindu Kush and Kishtwar Window—the seismicity parameters and other particulars are retrieved from the literature (Table 11). To use the logic tree feature, the different branches of the logic tree are to be prepared as separate projects within the software. These separate projects are then combined after assigning weights to each project/branch in the form of a logic tree. This logic tree is then run as a whole, such that it gives the combined hazard results as well as the individual results for each branch/project.
4.8.1 Logic Tree in RCRISIS Software
In this study, we have used three declustering algorithms (Table 2) and three sets of GMPEs for active shallow zones (Table 9) to account for the epistemic uncertainties in the declustering techniques as well as the model uncertainties in the GMPEs. Nine individual projects are created using the combination of the three sets of GMPEs along with three declustering methods. The logic tree approach in this study includes three GMPEs developed for the active shallow regions to represent fault tectonics in the Himalayan belt only. To simplify the analysis, the variation in GMPEs is considered only for the faults in the Himalayan source zone, which contributes a major part of the seismicity in the region. A single GMPE, i.e., M17, has been used for the deep subduction zones of Hindu Kush and Kishtwar zones. To avoid the unwarranted large number of combinations and logic tree branches, requiring unnecessary huge computation time and effort, the GMPE for the deep subduction zones (Hindu Kush and Kishtawar sources) has been kept the same throughout (M17). The incorporation of models as branches in a logic tree allows us to account for the epistemic uncertainties in the models (Sabetta et al., 2005). The weightage assigned to the branches is based on the confidence in each in terms of its likelihood of being correct.
A cursory look at Table 2 indicates that the declustering methods create obvious variations in the values of seismicity parameters. These differences generate significant distinctions in the resulting seismic hazard for a region (Christopherson et al., 2011; Kadiri & Kijko, 2021). Therefore, the concept of the logic tree has been used to consider the uncertainties associated with the declustering method used. Even though the declustering methods present significant disparity (as previously discussed), a single method may not necessarily be better than the others. Studies in the literature (e.g., Eroglu Azak et al., 2018) only discuss the stark variation in the results of the methods without explicitly grading the methods based on their performance. As such, it is not a straightforward task to assign a particular weightage based on individual performance and additional specific research may be required in this regard for future studies (van Stiphout et al., 2012). Each declustering method has therefore been assigned equal weightage since there is no clear evidence of one being better than the other.
The compatibility among the three selected GMPEs is checked in the RCRISIS programme. The ranking of the GMPEs has been decided based on the selection requirements for the choice of models outlined by Cotton et al. (2006) and Bommer et al. (2010). Since Idriss (2008) is a peer-reviewed attenuation model, it has been assigned a higher weightage. Ragukanth and Kavitha (2014) used a regional model providing weightage equal to Idriss (2008), although it is not peer reviewed. Finally, NDMA (2011), despite being a regional model, has been given less weightage than the other two, based on a comparison of the values obtained in DSHA. NDMA (2011) gives high values (> 2.00 g) of PGA at a few sites within the Kashmir region. Therefore, the weightage has been reduced. However, since such values are attained at only a few sites, this GMPE has not been dropped from the analysis. The branches of the logic tree and the corresponding weights assigned to each of the source models are presented in Fig. 9.

Logic tree framework showing the nine branches obtained from the combination of three GMPEs with three declustering methods, GK74, Gru85, and Uhr86, used for the computation of seismic hazard in for Kashmir region in RCRISIS
5 Results of PSHA
The PGA values (T = 0 s) and Sa values at other time periods at each grid point are computed at the seismic bedrock in the RCRISIS software. Seismic bedrock is the interface between the sedimentary layers and the upper earth crust usually having shear wave velocity > 3000–3500 m/s (Morikawa et al., 2011). The contribution of all the specified sources to hazard is considered.
The RCRISIS module computes the hazard at each grid point for each of the nine branches specified in the logic tree. These estimates are then combined in the logic tree framework by employing the weights defined for each to estimate the final hazard value. The results are generated in the form of PGA and Sa values at each grid point and for the set of return periods provided by the user. Furthermore, hazard curves and UHRS are also generated at each grid point. RCRISIS also generates disaggregation charts for the specified return periods and probability of exceedances.
5.1 PGA and Sa Spatial Distribution Maps
A set of seismic hazard maps for peak ground acceleration, PGA at T = 0 s (Fig. 10) and spectral acceleration, Sa, at short period, T = 0.2 s (Fig. 11) and long-period, T = 1 s (Fig. 12) are produced in this study for a better understanding of the spatial variation of seismic hazard. The hazard (in terms of PGA and Sa) is computed for 2% and 10% probability of exceedance (PE) in 50-year as well as 100-year time frames, which correspond to 2475-, 475-, 4950-, and 950-year return periods (RP), respectively. These combinations are used owing to their widespread use in the seismic design of buildings.

Seismic hazard maps of Kashmir region for PGA obtained from PSHA for a 475-, b 950-, c 2475-, and d 4950-year return periods at bedrock

Seismic hazard maps of Kashmir region for a short period Sa (0.2 s) obtained from PSHA for a 475-, b 950-, c 2475-, and d 4950-year return periods at bedrock

Seismic hazard maps of Kashmir region for a long period Sa (1 s) obtained from PSHA for a 475-, b 950-, c 2475-, and d 4950-year return periods at bedrock
Several inferences can be made from the study of the PGA and Sa spatial distribution maps. A few of these are as follows:
1. Figures 10, 11 and 12 indicate that the overall spatial distribution of hazard (PGA and Sa) is non-uniform because of the heterogeneous seismotectonic characteristics within the region. The hazard distribution pattern clearly follows the seismicity distribution and the spread of faults across the study area. The regions of the highest hazard are present near the faults and thrust systems. A close inspection of the maps indicates that a higher hazard is attained on the southwestern end of the region, which is flanked by the major fault systems. Faults like Central Kashmir Fault and Balapur Fault contribute the most to the hazard within the region on the southwestern end, along with the major thrust systems like MBT, MCT, and the Hazara Kashmir syntaxis on the northwestern extremity.
These faults contribute to a significant hazard in the districts in South Kashmir like Budgam, Pulwama, Shopian, Kulgam, and Anantnag. Higher PGA values are also observed in a part of north Kashmir because of the presence of MMT and Kamila Shear Zone. The central parts of the region, especially the districts of Ganderbal and Bandipora, have a comparatively lower seismic hazard in terms of PGA. Table 12 presents the PGA values for the ten districts of the Kashmir region from PSHA as well as DSHA. The values corroborate the higher hazard observed in Figs. 10, 11 and 12 for districts in south Kashmir, whereas districts in central Kashmir show less hazard.
2. Sa values are maximum at 0.2-s time period for all the cities. The Sa ranges between 0.098 and 0.766 g at zero period; 0.216–1.214 g for short period (T = 0.2 s); and 0.100–0.534 g for long period (T = 1 s). The Sa values at different periods are required for the seismic design of buildings based on the time period of a structure.
3. A comparison between the PGA values attained through DSHA and PSHA in the region is presented here. The maximum, minimum, and average PGA values and the standard deviations attained in DSHA and for all the return periods in PSHA are summarized in Table 13. It is observed that the PGA values obtained from DSHA are much higher than the values predicted from PSHA because DSHA considers the worst-case scenario (largest magnitude and shortest distance combination). The range of PGA attained within the region is 0.113–0.766 g over all the return periods considered in PSHA, whereas in DSHA the range is 0.198–1.270 g.
The large difference between DSHA and PSHA values of PGA is due to the nature of the methods involved. DSHA produces hazard for the maximum controlling earthquake at the shortest distance because of the most significant fault in the region. On the other hand, PSHA considers the aggregate hazard at a point considering all the big and small faults for varying magnitude distance combinations. This results in a much lower value in PSHA than in DSHA; in fact, DSHA is used as a cap for the hazard estimated through PSHA. Moreover, in this study, a logic tree approach has been used giving due weightage to different GMPEs in the PSHA method. In the DSHA method, however, the maximum PGA attained amongst the considered GMPEs has been selected as the final value of PGA. This may also be considered a reason for the stark variation between the two methods.
4. PGA values are lower for smaller return periods compared to longer return periods (Fig. S4, supplementary material). This means that shorter return periods correspond to a lower hazard in terms of PGA. In other words, a larger PGA intensity is expected to occur after long periods of time since its probability of occurrence is less than that of the lower PGA intensity.
5.2 Seismic Zonation Map for Kashmir Region
Based on the spatial distribution of PGA for all the return periods, the Kashmir region has been divided into five seismic zones, ZA–ZE (Fig. 13), having different ranges of PGA. ZA represents the zone of highest seismicity within the region whereas ZE represents the zone of lowest seismicity. As per the seismic zonation presented in IS Code (IS 1893:2016), the Kashmir region falls in seismic zones IV and V, which assigns a maximum PGA of 0.240–0.360 g. In this study, however, we have attained a wider range of PGA (0.098–0.766 g) for all return periods.

Seismic zonation map proposed for Kashmir region based on PGA values computed in PSHA
This information has been presented in graphical form in Fig. 14. Figure 14 indicates larger values of PGA for zone ZA decreasing progressively towards zone ZE. Moreover, as expected, the mean PGA values of each set increase with the increase of the return period. This is because higher PGA/hazard is expected after long intervals of time whereas lower PGA has a greater occurrence rate. These values for the various return periods can be used for design purposes in the different zones (ZA-ZE) in the Kashmir region.

Range of PGA values for zones ZA-ZE for 475-, 950-, 2475-, and 4950-year return periods
According to IBC 2003, Maximum Credible Earthquake (MCE) corresponds to a 2475-year return period (i.e., 2% probability of exceedance in 50 years), whereas Design Basis Earthquake (DBE) corresponds to a 10% probability of exceedance in 50 years (475-year return period). On the other hand, PGA values in IS code do not correspond to any specific return period since it is not based on PSHA (Jain, 2003). The spectral accelerations attained from the response spectra in IS 1893 (2016) are said to correspond to MCE, which are then multiplied by a factor to reduce them to the DBE scenario. As per this concept, the PGA values as per IS code for the 2475-year return period and 475-year return period are 0.360 g and 0.240 g, respectively, for zone V. Hence, for a better comparison with the codal response spectra, the hazard at the 2475-year return period can be compared with IS Code hazard for a region.
Comparing the zonation map of this study with that of the IS code, we find several differences. The seismic zones II-V in IS code are assigned uniform PGA values of 0.100 g, 0.160 g, 0.240 g, and 0.360 g, respectively, representing zones of low to high seismicity. The zones ZE through ZA in this study, also arranged according to increasing seismicity, have mean PGA values of 0.175 g, 0.258 g, 0.379 g, 0.456 g, and 0.514 g, respectively. We find that the predicted mean values of PGA for zones ZA-ZC for the 2475-year period in this study are much larger (0.379–0.514 g) than the 0.36 g specified for Zone V in IS 1893 such that these can be categorized as high seismicity zones. For zones ZD-ZE, the values are slightly smaller (0.175–0.258 g) such that these zones can be categorized as low seismicity zones. The comparison draws attention to the limitation of the seismic macrozonation resorted to by the IS code and hence the need for conducting site-specific PSHA before any important construction.
5.3 Seismic Hazard Curves at Each Grid Point
The seismic hazard curves in terms of the mean annual rate of exceedance λm of PGA are presented in Fig. 15a for each city in the ten districts of the Kashmir region. Results are provided for 50-year time frames. It is noted that Kulgam, Shopian, Budgam, and Baramula show the highest λm whereas Ganderbal, Bandipora, and Srinagar show low values. Figure 15b includes hazard curves for the five zones delineated within the region for the 50-year frames. ZA being a high seismicity zone shows a higher mean annual rate of exceedance for all PGA values for both time frames. The λm decreases as we go from ZA to ZE, yet again indicating higher seismic hazard in zones ZA-ZC compared to zones ZD-ZE. These curves will be useful for future structural design in the region in terms of selecting discrete hazard levels for the proper design and performance of buildings as well as risk assement procedures.

Seismic hazard curves for the a zones ZA-ZE and b the ten districts of Kashmir for the 50-year time frame
5.4 UHRS at Each Grid Point
UHRS represents the spectral acceleration values for a wide range of structural periods for a single hazard level in a single plot. These are essentially derived from the hazard curves which give the exceedance probability of various peak ground acceleration values. Since a design response spectrum is an essential input for both structural and geotechnical design, a UHRS which is a response spectrum at a uniform hazard level forms a valuable key element of seismic design like the International Building Code (IBC 2000). The physical significance of a UHRS is that it embodies the aggregate effects of earthquakes of varying magnitudes (M) and source-to-site distances (R) instead of a single earthquake scenario. A comparison of the IS code response spectrum and the 2475-year return period UHRS for the different districts as well as zones is shown in Fig. 16. A cursory look at the Fig. 16a reveals that the IS code spectrum for zone V matches the UHRS for seismic zones ZA-ZC fairly well whereas that for zone IV envelopes the UHRS for zones ZD-ZE in this study. Figure 16b indicates that the zone V spectrum matches fairly well with the South Kashmir districts whereas the zone IV spectrum represents the UHRS for the Srinagar, Ganderbal, and Bandipora districts well.

Comparison of UHRS for 2475-year return period for Kashmir region for a the five seismic zones and b for the ten districts, with response spectrum in IS 1893 for at bedrock
The UHRS for the four return periods (475, 950, 2475, and 4950 years) for all districts have been presented in Fig. S5 (a–b) (supplementary material). The figures indicate that, in general, the city in Kulgam shows the highest spectral accelerations, followed by Shopian, Baramula, and Pulwama. This is expected because of the presence of the CKF, BF, and MCT in close proximity. The fewest accelerations are observed in Bandipora, followed by Ganderbal, Srinagar, and Kupwara. The rest of the districts show moderate spectral acceleration in between these extreme low and high values.
Furthermore, UHRSs for the five zones have been estimated and presented in Fig. S6 (supplementary material) for all four return periods (475, 950, 2475, and 4950 years). It is evident from the figure that zone ZA has the highest hazard in terms of spectral acceleration at all return periods, and it decreases towards ZE. Furthermore, lower return periods are associated with shorter spectral accelerations compared to longer return periods. Higher spectral accelerations (Sa) are attained at 0.2 s than at 0 s and 1 s, which can also be seen from spatial distribution plots in Figs. 10, 11, 12.
5.5 Disaggregation Plots
The disaggregation was carried out on one particular branch of the logic tree considered in this study. More specifically, the logic tree could not be utilised for the disaggregation process since the values of hazard are estimated through a combination of all the branches. This problem has also been discussed by Barani et al. (2009), who then used a single logic tree path producing hazard values closest to those obtained through the entire logic tree for the disaggregation process. Following Barani et al.’s (2019) approach, we utilised a single logic tree path—I08_Uhr86—whose hazard values showed the least difference (~ 26%) from the logic tree values. The difference of each individual branch from the logic tree hazard has been discussed in detail in the next section (Sect. 5.6).
The disaggregation plots for zones ZA and ZE are presented in Fig. 17 for comparison. Disaggregation charts give exceedance probabilities of magnitude and distance combinations (Bazzurro and Cornell, 1999). This helps to recognize the most critical combination of magnitude and distance making the greatest contribution to the hazard at a particular site. Since hazard curves and UHRS represent aggregate effects from several earthquake scenarios, a disaggregation of the hazard results is required to understand the effect of individual M and R combinations.

Disaggregation plots for zones ZA and ZE showing the contribution of various magnitude and distance ranges towards seismic hazard for the 2475-year return period
The plots in Fig. 17 suggest that the maximum contribution to the hazard is from nearfield faults, except in districts like Ganderbal and Bandipora where some significant contribution can be seen from larger hypocentral distances. This trend continues for all return periods. This is because the Kashmir region is laced by nearfield faults, especially in the northwestern and southwestern parts. In central parts like Ganderbal and Baramulla, the faults are at larger distances, thus making the contribution from larger epicentral distances significant. Zone ZE shows a significant contribution to the hazard from large epicentral distances due to the faults being present at larger distances from these areas. It is evident that Mw 4.0–7.7 and R 0–100 km form the dominant magnitude and distance range combinations for near-field seismic sources. For far-field sources, especially in zones ZD and ZE, the combination of Mw > 6.0 and R 200–400 km contributes the most to the hazard.
The disaggregation results complement the accounts of historical earthquakes already discussed in Sect. 2. The southern parts of Kashmir (seismic zones ZA, ZB) have been affected by near-field earthquakes like the 1555 Kashmir earthquake, 1828, 1885 Baramulla earthquake, 1963 Budgam earthquake, 2005 Kashmir earthquake, and 2019 Mirpur earthquake. The far-field earthquakes are represented by the earthquakes generated in the Hindu Kush region. Historical records do not show major events with epicentres within the central portions of the Kashmir region falling in zones ZD and ZE (e.g., Ganderbal, etc.). Hence, as concluded from the disaggregation results, these zones are most likely to be affected by far-field earthquakes.
5.6 Effect of Selection of GMPEs and Declustering Methods on Seismic Hazard
The selection of declustering algorithms has a direct impact on the completeness periods of small magnitude events in a catalogue since these are removed to varying extents (Eroglu Azak et al., 2018). The choice of declustering algorithm has, therefore, an effect on the seismicity parameters for a region which depend on the relative number of small and moderate to large magnitude events that occur in a region (Eroglu Azak et al., 2018; van Stiphout et al., 2012). The a- and b-values show variations in GK74, Gru85, and Uhr86 catalogues, and especially the activity rate λ is seen to vary substantially (Table 7). The b-value from catalogue GK74 is the highest, whereas from Uhr86 is the lowest, reflecting the effect of the percentage removal of aftershocks from the catalogue. On the other hand, λ and a-value are highest for Uhr86 since it retains a larger number of events as the main seismicity.
These variations in seismicity parameters are subsequently exhibited in the differences in the estimated seismic hazard. The various branches of the logic tree, which represent different declustering methods, show considerable variations in the estimated hazard in terms of PGA. This has been quantified in terms of the percentage variation in the mean values of PGA attained in each logic tree branch with respect to the PGA obtained from the logic tree approach combining all the branches (Fig. 18). The difference of PGA values in the individual nine branches regarding the final PGA obtained by combining all the branches in the logic tree has been calculated. This difference from the main logic tree branch has been presented in the form of histograms for each of the nine branches in the figure. This helps to visualise the influence of the declustering methods and GMPEs on the estimated hazard. Considering the logic tree values as the point of comparison, the PGA values may vary up to 20–40% on average from the logic tree values. GK74 and Gru86 yield similar results in terms of hazard whereas Uhr86 shows a significant deviation from the two. The graph shows that in general, for most of the cases, I08_Uhr86 shows the least variation from the logic tree PGA values.

Comparative analysis of PGA values obtained in the individual nine logic tree branches with respect to the combined hazard obtained a logic tree approach, illustrating the sensitivity of seismic hazard to declustering methods and GMPEs
It is evident from Fig. 19 that the GMPE used in combination with the declustering method also controls the hazard values obtained. Hence, the selection of an appropriate GMPE in addition to declustering method is important. Owing to this variation in the results, various combinations of GMPEs with declustering methods have been incorporated by considering the logic tree approach. In general, Uhr86 gives higher hazard in terms of PGA, followed by Gru85, and then GK74. Furthermore, the GMPE RK14 gives lower PGA compared to NDMA11 and I08.

Comparison of mean PGA values showing the effect of GMPEs and declustering methods for a 475-year, b 95-year, c 2475-year, and 4950-year return period
6 Discussion and Conclusions
Seismic hazard assessment for the Kashmir valley using deterministic as well as probabilistic approaches has been performed using the current available methodology in the field. The study and its results will prove to be a useful resource of information on the seismic hazard and related aspects in the Kashmir region of the northwestern Himalayas.
An earthquake catalogue containing events from the years 1500–2019 has been prepared, including updated knowledge of seismicity. Three declustering procedures have been used—GK74, Gru85, and Uhr86—to process the catalogue, and sensitivity analysis has been conducted to understand the effect of the declustering methods on the seismicity parameters as well as the resulting seismic hazard. It was found that the choice of declustering methods has a significant effect on both seismicity parameters as well as hazard. Gru85 removed the maximum number of earthquakes as dependent events, followed by GK74, and then Uhr86.
Seismicity parameters (a-, b-value, λ, MC, and mmax) have been estimated for the entire Kashmir region. For the Kashmir region, the completeness magnitude MC from the MAXC technique (Wyss and Wiemer, 2000) is estimated to be 4.3–4.9, b-value is 0.92–1.05, mmax estimated from Kijko and Sellevol (1989, 1992, 2016) procedure is 7.97–7.98, and activity rate λ is 3.87–13.53. The variation in the seismicity parameters for the three catalogues highlights the influence of the declustering methods suggesting that the logic tree approach should be used to reduce the epistemic uncertainty.
Deterministic seismic hazard assessment of the Kashmir valley yielded very high values ~ 0.5–1.3 g. Three attenuation relationships—one global (I08) and two regional (NDMA11, RK14)—have been used to compute the hazard parameters. A logic tree framework was utilised in the RCRISIS software (Ordaz et al., 2017), incorporating the epistemic uncertainties associated with different models of attenuation relationships as well as the algorithms for declustering. These values are much higher than the values specified for zones IV and V of IS code (IS:1893–2016). The hazard maps for 2% and 10% probability of exceedance for 50 and 100 years are presented in this study, in terms of both PGA and PSA (Sa) at short (0 s) and long (1 s) periods. The PGA ranges between 0.098 and 0.766 g; Sa at the short period is between 0.216 and 1.214 g, whereas for the long period, Ss is 0.100–0.534 g.
The spatial distribution of the values indicates high hazards on the southwestern end of the valley, which is flanked by the major fault systems. CKF and BF contribute the most to the hazard within the valley on the southwestern end; MFZ and TF in northwestern Kashmir, in addition to the major thrust systems (MBT, MCT) and the Hazara Kashmir syntaxis; and the KSZ and ITSZ in the northern parts. The districts of Baramula, Budgam, Pulwama, Shopian, Kulgam and Anantnag show the highest PGA values. Higher PGA values are also observed in a part of north Kashmir because of the presence of MMT and KSZ. The central parts of the region, especially the districts of Ganderbal and Bandipora, have a comparatively lower seismic hazard in terms of PGA because of larger distances from faults.
Seismic zonation of the Kashmir valley has been conducted based on the PGA values attained in PSHA, dividing the region into five zones, namely ZA-ZE, representing high to low seismicity zones. The mean PGA values derived from PSHA at a 2475-year return period for the five zones are 0.514 g, 0.456 g, 0.379 g, 0.258 g, and 0.175 g, respectively. Seismic hazard curves, as well as UHRS developed for the region, suggest higher hazards in zones ZA-ZC compared to ZC-ZD.
A comparison of the hazard values from the nine logic tree branches with the combined hazard from the logic tree reveals that the differences are substantial. In general, the branch I08_Uhr86 shows the least variation from the logic tree PGA values. This branch has thus been used to produce the disaggregation plots for the seismic zones ZA-ZE and all ten districts of the region have been provided for the 2475-year return period. The magnitude and distance combination of 4.0–7.7 Mw and 0–100 km, respectively, is the most critical for the region for all zones, ZA-ZE. For far-field sources, especially in zones ZD and ZE, the critical combination of magnitude and distance is Mw > 6 and 200–400 km, respectively.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Ahmad, B., Ahmad, S., Alam, A., Wang, S., & Sultan Bhat, M. S. (2015). Looking for missing links in Kashmir: An update on nineteenth-century seismicity. Seismological Research Letters, 86(4), 1219–1224. https://doi.org/10.1785/0220140105
Ahmad, B., Alam, A., Bhat, M. S., Ahmad, S., Shafi, M., & Rasool, R. (2017a). Seismic risk reduction through indigenous architecture in Kashmir Valley. International Journal of Disaster Risk Reduction, 21, 110–117. https://doi.org/10.1016/j.ijdrr.2016.11.005
Ahmad, B., Bhat, M. I., & Bali, B. S. (2009). Historical record of Earthquakes in the Kashmir Valley. Himalayan Geology, 30(1), 75–84.
Ahmad, B., & Shafi, M. (2014). Some more earthquakes from medieval Kashmir. Journal of Seismology, 18(3), 681–686. https://doi.org/10.1007/s10950-014-9427-2
Ahmad, S., Bhat, M. I., Bhat, M. S., Alam, A., Ahmad, B., Rasool, A., Ahmad, H. F., Ali, U., & Afzal, A. (2017b). Geomorphic indicators of Balapur Fault in Kashmir Basin and kinematic analysis with respect to NW Himalaya. Journal of Himalayan Ecolology and Sustainable Development, 12, 72–88.
Alam, A., Ahmad, S., Bhat, M. S., & Ahmad, B. (2015). Tectonic evolution of Kashmir basin in northwest Himalayas. Geomorphology, 239, 114–126. https://doi.org/10.1016/j.geomorph.2015.03.025
Al-Arifi, N. S., Fat-Helbary, R. E., Khalil, A. R., & Lashin, A. A. (2013). A new evaluation of seismic hazard for the northwestern part of Saudi Arabia. Natural Hazards, 69(3), 1435–1457. https://doi.org/10.1007/s11069-013-0756-1
Aldama-Bustos, G., Tromans, I. J., Strasser, F., Garrard, G., Green, G., Rivers, L., Douglas, J., Musson, R. M. W., Hunt, S., Lessi-Cheimariou, A., Daví, M., & Robertson, C. (2019). A streamlined approach for the seismic hazard assessment of a new nuclear power plant in the UK. Bulletin of Earthquake Engineering, 17(1), 37–54. https://doi.org/10.1007/s10518-018-0442-5
Ansari, A., Zahoor, F., Rao, K. S., & Jain, A. K. (2022). Deterministic approach for seismic hazard assessment of Jammu region, Jammu and Kashmir. In Geo-Congress, 2022, 590–598. https://doi.org/10.1061/9780784484043.057
Atkinson, G. M., & Goda, K. (2011). Effects of seismicity models and new ground-motion prediction equations on seismic hazard assessment for four Canadian cities. Bulletin of the Seismological Society of America, 101(1), 176–189. https://doi.org/10.1785/0120100093
Baker, J. W. (2015). Introduction to probabilistic seismic hazard analysis. White Paper Version, 2, 1.
Barani, S., Spallarossa, D., & Bazzurro, P. (2009). Disaggregation of probabilistic ground-motion hazard in Italy. Bulletin of the Seismological Society of America, 99(5), 2638–2661. https://doi.org/10.1785/0120080348
Bazzurro, P., & Allin Cornell, C. (1999). Disaggregation of seismic hazard. Bulletin of the Seismological Society of America, 89(2), 501–520. https://doi.org/10.1785/BSSA0890020501
Bettinelli, P., Avouac, J. P., Flouzat, M., Jouanne, F., Bollinger, L., Willis, P., & Chitrakar, G. R. (2006). Plate motion of India and interseismic strain in the Nepal Himalaya from GPS and DORIS measurements. Journal of Geodesy, 80(8–11), 567–589. https://doi.org/10.1007/s00190-006-0030-3
Bhatia, S. C., Kumar, M. R., & Gupta, H. K. (1999). A probabilistic seismic hazard map of India and adjoining regions.
Bilham, R., & Bali, B. S. (2014). A ninth century earthquake-induced landslide and flood in the Kashmir Valley, and earthquake damage to Kashmir’s Medieval temples. Bulletin of Earthquake Engineering, 12(1), 79–109. https://doi.org/10.1007/s10518-013-9504-x
Bommer, J. J. (2003). Uncertainty about the uncertainty in seismic hazard analysis. Engineering Geology, 70(1–2), 165–168. https://doi.org/10.1016/S0013-7952(02)00278-8
Bommer, J. J., Douglas, J., Scherbaum, F., Cotton, F., Bungum, H., & Fäh, D. (2010). On the selection of ground-motion prediction equations for seismic hazard analysis. Seismological Research Letters, 81(5), 783–793. https://doi.org/10.1785/gssrl.81.5.783
Burtman, V. S., & Molnar, P. (1993). Geological and geophysical evidence for deep subduction of continental crust beneath the Pamir. Geological Society of America special papers. Geological Society of America Special Papers, 281(76), 1–76. https://doi.org/10.1130/SPE281-p1
Chandra, R., Dar, J. A., Romshoo, S. A., Rashid, I., Parvez, I. A., Mir, S. A., & Fayaz, M. (2018). Seismic hazard and probability assessment of Kashmir valley, northwest Himalaya. India. Natural Hazards, 93(3), 1451–1477. https://doi.org/10.1007/s11069-018-3362-4
Chevalier, M. L., Ryerson, F. J., Tapponnier, P., Finkel, R. C., Van Der Woerd, J., Haibing, L., & Qing, L. (2005). Slip-rate measurements on the Karakorum fault may imply secular variations in fault motion. Science, 307(5708), 411–414. https://doi.org/10.1126/science.1105466. PubMed: 15662010.
Christophersen, A., Gerstenberger, M. C., Rhoades, D. A., & Stirling, M. W. (2011). Quantifying the effect of declustering on probabilistic seismic hazard. In Proceedings of the of the Ninth Pacific Conference on Earthquake Engineering: Building an Earthquake-Resilient Society.
Cornell, C. A. (1968). Engineering seismic risk analysis. Bulletin of the Seismological Society of America, 58(5), 1583–1606. https://doi.org/10.1785/BSSA0580051583
Cotton, F., Scherbaum, F., Bommer, J. J., & Bungum, H. (2006). Criteria for selecting and adjusting ground-motion models for specific target applications: Applications to Central Europe and rock sites. Journal of Seismology, 10(2), 137–156. https://doi.org/10.1007/s10950-005-9006-7
Danciu, L., & Woessner, J. (2014). Pseudo probabilistic seismic hazard sources for Vrancea deep seismicity. In Proceedings of the 2. Second europa conference on earthquake engineering and engineering seismology ECEES, August 24–29, Turkey, 2014.
Danciu, L., Kale, Ö., & Akkar, S. (2016). The 2014 earthquake model of middle east region: Ground motion model and uncertainties. Bulletin of Earthquake Engineering, 16, 3497–3533.
Dar, J. A., & Dubey, R. K. (2015). Probabilistic seismic hazard analyses (PSHA) and liquefaction susceptibility evaluation of Kashmir Valley, India. Proceedings of the National Academy of Sciences, India Section A, 85(1), 177–186. https://doi.org/10.1007/s40010-014-0180-2
Deniz, A., & Yucemen, M. S. (2010). Magnitude conversion problem for the Turkish earthquake data. Natural Hazards, 55(2), 333–352. https://doi.org/10.1007/s11069-010-9531-8
Eroglu Azak, T., Kalafat, D., Şeşetyan, K., & Demircioğlu, M. B. (2018). Effects of seismic declustering on seismic hazard assessment: A sensitivity study using the Turkish earthquake catalogue. Bulletin of Earthquake Engineering, 16(8), 3339–3366. https://doi.org/10.1007/s10518-017-0174-y
Gabor, L. (2010). Seismic design principles whole building design guide. National institute of building sciences. Retrieved March 15, 2011.
Galina, N. A., Bykova, V. V., Vakarchuk, R. N., & Tatevosian, R. E. (2019). Effect of earthquake catalog declustering on seismic hazard assessment. Seismic Instruments, 55(1), 59–69. https://doi.org/10.3103/S0747923919010079
Ganju, J. L., & Khar, B. M. (1984). Tectonic and hydrocarbon prospecting of Kashmir Valley, Exploration tasks. Pet Asia, 207–201.
Gardner, J. K., & Knopoff, L. (1974). Is the sequence of earthquakes in Southern California, with aftershocks removed, Poissonian? Bulletin of the Seismological Society of America, 64(5), 1363–1367. https://doi.org/10.1785/BSSA0640051363
Gavillot, Y. G., Meigs, A., Yule, D., Heermance, R., Rittenour, T., Madugo, C., & Malik, M. (2016). Shortening rate and Holocene surface rupture on the Riasi fault system in the Kashmir Himalaya: Active thrusting within the Northwest Himalayan orogenic wedge. Geological Society of America Bulletin, 128(7–8), 1070–1094. https://doi.org/10.1130/B31281.1
Gregori, S. D., & Christiansen, R. (2018). Seismic hazard analysis for central-western Argentina. Geodesy and Geodynamics, 9(1), 25–33. https://doi.org/10.1016/j.geog.2017.07.006
Gruenthal, G. (1985). The updated earthquake catalogue for the German Democratic Republic and adjacent areas – Statistical data characteristics and conclusions for hazard assessment. 3rd International Symposium on the Analysis of Seismicity and Seismic Risk, June 17–22. Liblice.
Gutenberg, B., & Richter, C. F. (1954). Seismicity of the earth and associated phenomena. Princeton University Press.
Hashash, Y. M. A., Kim, B., Olson, S. M., & Ahmad, I. (2012). Seismic hazard analysis using discrete faults in Northwestern Pakistan: Part II, 2012. -. (2012). Seismic Hazard Analysis Using Discrete Faults in Northwestern Pakistan: Part II – Results of seismic hazard analysis. Journal of Earthquake Engineering, 16(8), 1161–1183. https://doi.org/10.1080/13632469.2012.681424
Hough, S., Bilham, R., & Bhat, I. (2009). Kashmir valley megaearthquakes. American Scientist, 97(1), 42–49. https://doi.org/10.1511/2009.76.42
Houlié, N., & Phillips, R. J. (2013). Quaternary rupture behavior of the Karakoram Fault and its relation to the dynamics of the continental lithosphere, NW Himalaya–western Tibet. Tectonophysics, 599, 1–7. https://doi.org/10.1016/j.tecto.2013.03.029
Hussain, A., & Yeats, R. S. (2006). The Balakot–bagh fault that triggered the October 8, earthquake and other active faults in the Himalayan foreland region. Pakistan extended abstract. international Conference on 8 October, 2005 earthquake in Pakistan: Its implications and hazard mitigation. Islamabad (pp. 125–126). Geological Survey of Pakistan.
Hussain, A., Yeats, R. S., & Lisa, M. (2009). Geological setting of the 8th October 2005 Kashmir earthquake. Journal of Seismology, 13, 315–325.
Idriss, I. M. (2008). An NGA empirical model for estimating the horizontal spectral values generated by shallow crustal earthquakes. Earthquake Spectra, 24(1), 217–242. https://doi.org/10.1193/1.2924362
International Code Council. (2000). International. Dearborn Trade Publishing.
Ischuk, A., Bjerrum, L. W., Kamchybekov, M., Abdrakhmatov, K., & Lindholm, C. (2018). Probabilistic seismic hazard assessment for the area of Kyrgyzstan, Tajikistan, and Eastern Uzbekistan, Central Asia. Bulletin of the Seismological Society of America, 108(1), 130–144. https://doi.org/10.1785/0120160330
IS1893 (20162) Indian standard criteria for earthquake resistant design of structures, Part 1-general provisions and buildings. New Delhi: Bureau of Indian Standards.
Iyengar, R. N., Sharma, D., & Siddiqui, J. M. (1999). Earthquake history of India in medieval times. Indian Journal of History of Science, 34(3).
Jain. (2003). Review of Indian seismic code, IS 1893 (Part 1):2002. Indian Concrete Journal, 77(11), 1414–1422
Jayangondaperumal, R., & Thakur, V. C. (2008). Co-seismic secondary surface fractures on southeastward extension of the rupture zone of the 2005 Kashmir earthquake. Tectonophysics, 446(1–4), 61–76. https://doi.org/10.1016/j.tecto.2007.10.006
Jones, E. A. (1885). Records of the Geological Survey of India. XVII, I(4), 221–227.
Joshi, M., & Thakur, V. C. (2016). Signatures of 1905 Kangra and 1555 Kashmir earthquakes in medieval period temples of Chamba region, northwest Himalaya. Seismological Research Letters, 87(5), 1150–1160. https://doi.org/10.1785/0220160033
Kadiri, A. U., & Kijko, A. (2021). Seismicity and seismic hazard assessment in West Africa. Journal of African Earth Sciences, 183. https://doi.org/10.1016/j.jafrearsci.2021.104305, PubMed: 104305
Kaila, K. L., Krishna, V. G., Roychowdhry, K., & Norin, M. (1978). Structure of the Kashmir Himalayas from deep seismic sounding. Journal of the Geological Society of India, 19, 1–20.
Karan, P. P. (1966). Geographic regions of the Himalaya. Bulletin of Tibetology, 3, 5–25.
Karimiparidari, S., Zaré, M., Memarian, H., & Kijko, A. (2013). Iranian earthquakes, a uniform catalog with moment magnitudes. Journal of Seismology, 17(3), 897–911. https://doi.org/10.1007/s10950-013-9360-9
(1992). Estimation of earthquake hazard parameters from incomplete data files. Part II. Incorporation of magnitude heterogeneity. Bulletin of the Seismological Society of America, 82(1), 120–134.
Khattri, K. N., Rogers, A. M., Perkins, D. M., & Algermissen, S. T. (1984). A seismic hazard map of India and adjacent areas. Tectonophysics, 108(1–2), 93–134. https://doi.org/10.1016/0040-1951(84)90156-2
Kijko, A., & Sellevoll, M. A. (1989). Estimation of earthquake hazard parameters from incomplete data files. Part I. Utilization of extreme and complete catalogs with different threshold magnitudes. Bulletin of the Seismological Society of America, 79(3), 645–654. https://doi.org/10.1785/BSSA0790030645
Kijko, A., Smit, A., & Sellevoll, M. A. (2016). Estimation of earthquake hazard parameters from incomplete data files. Part III. Incorporation of uncertainty of earthquake-occurrence model. Bulletin of the Seismological Society of America, 106(3), 1210–1222. https://doi.org/10.1785/0120150252
Kramer, S. L. (1996). Geotechnical earthquake engineering. Pearson Education.
Lin, P.-S., & Lee, C.-T. (2008). Ground-motion attenuation relationships for subduction zone earthquakes in northeastern Taiwan. Bulletin of the Seismological Society of America, 98(1), 220–240. https://doi.org/10.1785/0120060002
Madden, C., Trench, D., Meigs, A., Ahmad, S., Bhat, M. I., & Yule, J. D. (2010). Late Quaternary shortening and earthquake chronology of an active fault in the Kashmir Basin, northwest Himalaya. Seismological Research Letters, 81(2), 346.
Mahajan, A. K., Thakur, V. C., Sharma, M. L., & Chauhan, M. (2010). Probabilistic seismic hazard map of NW Himalaya and its adjoining area. India. Natural Hazards, 53(3), 443–457. https://doi.org/10.1007/s11069-009-9439-3
McGuire, R. K. (2004). Seismic hazard and risk analysis. Earthquake Engineering Research Institute, EERI Monograph MNO-10.
Mignan, A., & Woessner, J. (2012). Estimating the Magnitude of Completeness for Earthquake Catalogs, Community Online Resource for Statistical Seismicity Analysis. http://www.corssa.org. https://doi.org/10.5078/corssa-00180805
Mitronovas, W., & Isacks, B. L. (1971). Seismic velocity anomalies in the upper mantle beneath the Tonga-Kermadec island arc. Journal of Geophysical Research, 76(29), 7154–7180. https://doi.org/10.1029/JB076i029p07154
Mizrahi, L., Nandan, S., & Wiemer, S. (2021). The effect of declustering on the size distribution of mainshocks. Seismological Research Letters, 92(4), 2333–2342. https://doi.org/10.1785/0220200231
Moklesur Rahman, M. M., & Bai, L. (2018). Probabilistic seismic hazard assessment of Nepal using multiple seismic source models. Earth and Planetary Physics, 2(4), 327–341. https://doi.org/10.26464/epp2018030
Molnar, P., & Bendick, R. (2019). Seismic moments of intermediate-depth earthquakes beneath the Hindu Kush: Active stretching of a blob of sinking thickened mantle lithosphere? Tectonics, 38(5), 1651–1665. https://doi.org/10.1029/2018TC005336
Montalva, G. A., Bastías, N., & Rodriguez-Marek, A. (2017). Ground-motion prediction equation for the Chilean subduction zone. Bulletin of the Seismological Society of America, 107(2), 901–911. https://doi.org/10.1785/0120160221
Morikawa, N., Senna, S., Hayakawa, Y., & Fujiwara, H. (2011). Shaking maps for scenario earthquakes by applying the upgraded version of the strong ground motion prediction method “recipe.” Pure and Applied Geophysics, 168(3–4), 645–657. https://doi.org/10.1007/s00024-010-0147-4
Nábělek, J., Hetényi, G., Vergne, J., Sapkota, S., Kafle, B., Jiang, M., Su, H., Chen, J., Huang, B. S., & Hi-CLIMB Team. (2009). Underplating in the Himalaya-Tibet collision zone revealed by the Hi-CLIMB experiment. Science, 325(5946), 1371–1374. https://doi.org/10.1126/science.1167719, PubMed: 19745147
NDMA. (2011). Development of probabilistic seismic hazard map of India. Technical Report of the working Committee of Experts (WCE). National Disaster Management Authority, Govt. of India.
Oliver, J., & Isacks, B. (1967). Deep earthquake zones, anomalous structures in the upper mantle, and the lithosphere. Journal of Geophysical Research, 72(16), 4259–4275. https://doi.org/10.1029/JZ072i016p04259
Ordaz, M. (1991). Crisis. Brief description of program CRISIS p. 16. Institute of Solid Earth Physics, University of Bergen.
Ordaz, M., Martinelli, F., Aguilar, A., Arboleda, J., Meletti, C., & D’Amico, V. (2017). R-CRISIS. Program and platform for computing seismic hazard.
Pandey, S. J., Bhat, G. M., Puri, S., Raina, N., Singh, Y., Pandita, S. K., Verma, M., Bansal, B. K., & Sutar, A. (2017). Seismotectonic study of Kishtwar region of Jammu Province using local broadband seismic data. Journal of Seismology, 21(3), 525–538. https://doi.org/10.1007/s10950-016-9614-4
Patil, N. S., Das, J., Kumar, A., Rout, M. M., & Das, R. (2014). Probabilistic seismic hazard assessment of Himachal Pradesh and adjoining regions. Journal of Earth System Science, 123(1), 49–62. https://doi.org/10.1007/s12040-013-0378-8
Pavlis, G. L., & Das, S. (2000). The Pamir-Hindu Kush Seismic zone as a strain marker for flow in the upper mantle. Tectonics, 19(1), 103–115. https://doi.org/10.1029/1999TC900062
PMD and NORSAR. (2007). Seismic hazard analysis and zonation for Pakistan. Azad Jammu and Kashmir [Technical report p. 156].
Qureshi, M. N., Venkatachalam, S., & Subrahmanyam, C. (1974). Vertical tectonics in the Middle Himalayas: An approach from recent gravity data. Bulletin of the Seismological Society of America, 85, 921–926.
Qureshy, M. N. (1969). Thickening of a basalt layer as a possible cause for the uplift of the Himalayas—A suggestion based on gravity data. Tectonophysics, 7(2), 137–157. https://doi.org/10.1016/0040-1951(69)90003-1
Raghukanth, S. T. G., & Kavitha, B. (2014). Ground motion relations for active regions in India. Pure and Applied Geophysics, 171(9), 2241–2275. https://doi.org/10.1007/s00024-014-0807-x
Rao, K. S. (2003). Evaluation of liquefaction potential for seismic microzonation of Delhi region. In Proceedings of the Twelfth Asian Regional Conference on Soil Mechanics and Geotechnical Engineering, 1.
Rao, K. S., & Neelima Satyam, D. (2005). Seismic microzonation studies for Delhi region. In Symposium on seismic hazard analysis and microzonation, September, 2324.
Rao, K. S., & Ramhmachhuani, R. (2017). Site specific seismic input for structures on hill slopes. Procedia Engineering, 173, 1747–1754. https://doi.org/10.1016/j.proeng.2016.12.212
Rao, K. S., & Rathod, G. W. (2014). Seismic microzonation of Indian megacities: A case study of NCR Delhi. Indian Geotechnical Journal, 44(2), 132–148. https://doi.org/10.1007/s40098-013-0084-0
Rathod, G. W. (2011) Seismic hazard assessment and development of attenuation relationship for NCR of Delhi (Doctoral dissertation, IIT Delhi).
Reasenberg, P. (1985). Second-order moment of central California seismicity, 1969–1982. Journal of Geophysical Research: Solid Earth, 90(B7), 5479–5495. https://doi.org/10.1029/JB090iB07p05479
Reasenberg, P. A., & Jones, L. M. (1989). Earthquake hazard after a mainshock in California. Science, 243(4895), 1173–1176. https://doi.org/10.1126/science.243.4895.1173. PubMed: 17799897.
Rehman, K., Ali, W., Ali, A., Ali, A., & Barkat, A. (2017). Shallow and intermediate depth earthquakes in the Hindu Kush region across the Afghan-Pakistan border. Journal of Asian Earth Sciences, 148, 241–253. https://doi.org/10.1016/j.jseaes.2017.09.005
Reiter, L. (1990). Earthquake hazard analysis: Issues and insights. Columbia University Press.
Rex, A. J., Searle, M. P., Tirrul, R., Crawford, M. B., Prior, D. J., Rex, D. C., & Barnicoat, A. (1988). The geochemical and tectonic evolution of the central Karakoram, north Pakistan. Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences, 326(1589), 229–255. https://doi.org/10.1098/rsta.1988.0086
Rout, M. M., Das, J., & Kamal,. (2018). Probabilistic seismic hazard for Himalayan region using kernel estimation method (zone-free method). Natural Hazards, 93(2), 967–985. https://doi.org/10.1007/s11069-018-3336-6
Sabetta, F., Lucantoni, A., Bungum, H., & Bommer, J. J. (2005). Sensitivity of PSHA results to ground motion prediction relations and logic-tree weights. Soil Dynamics and Earthquake Engineering, 25(4), 317–329. https://doi.org/10.1016/j.soildyn.2005.02.002
Sana, H. (2019). A probabilistic approach to the seismic hazard in Kashmir basin. NW Himalaya. Geoscience Letters, 6(1), 1–11.
Sana, H., & Nath, S. K. (2017). Seismic source zoning and maximum credible earthquake prognosis of the Greater Kashmir Territory, NW Himalaya. Journal of Seismology, 21(2), 411–424. https://doi.org/10.1007/s10950-016-9608-2
Satyam, D. N. (2006). Seismic microzonation of Delhi region [Doctoral Dissertation].
Scordilis, E. M. (2006). Empirical Global Relations Converting ms and mb to Moment Magnitude. Journal of Seismology, 10(2), 225–236. https://doi.org/10.1007/s10950-006-9012-4
Searle, M. P. (1996). Geological evidence against large-scale pre-Holocene offsets along the Karakoram Fault: Implications for the limited extrusion of the Tibetan Plateau. Tectonics, 15(1), 171–186. https://doi.org/10.1029/95TC01693
Searle, M. P., Windley, B. F., Coward, M. P., Cooper, D. J. W., Rex, A. J., Rex, D., Tingdong, L., Xuchang, X., Jan, M. Q., Thakur, V. C., & Kumar, S. (1987). The closing of Tethys and the tectonics of the Himalaya. Geological Society of America Bulletin, 98(6), 678–701. https://doi.org/10.1130/0016-7606(1987)98%3c678:TCOTAT%3e2.0.CO;2
SEISAT. (2000). Seismotectonic Atlas of India and its environs. Geological Survey of India.
Shah, A. (2016). The Kashmir Basin fault and its influence on fluvial flooding in the Kashmir Basin, NW Himalaya. Special Papers of Geological Society of America, 520, 321–334.
Shah, A. A., & Malik, J. N. (2017). Four major unknown active faults identified, using satellite data, in India and Pakistan portions of NW Himalaya. Natural Hazards, 88(3), 1845–1865. https://doi.org/10.1007/s11069-017-2949-5
Sharma, M. L., Douglas, J., Bungum, H., & Kotadia, J. (2009). Ground-motion prediction equations based on data from the Himalayan and Zagros regions. Journal of Earthquake Engineering, 13(8), 1191–1210. https://doi.org/10.1080/13632460902859151
Sharma, S., Dasgupta, A., Kumar, A., Bharanidharan, B., Mittal, H., & Sachdeva, R. (2014). Earthquake Activity in Kishtwar –Dharamshala Region of North-West Himalaya Seismic gaps. International Journal of Advanced Research, 2(8), 463–470.
Sharma, S., Kumar, A., & Ghangas, V. (2013). Seismicity in Jammu and Kashmir region with special reference to Kishtwar. International Journal of Scientific and Research Publications, 3(9), 1–5.
Stevens, V. L., & Avouac, J. P. (2015). Interseismic coupling on the main Himalayan thrust. Geophysical Research Letters, 42(14), 5828–5837. https://doi.org/10.1002/2015GL064845
Talbi, A., Nanjo, K., Satake, K., Zhuang, J., & Hamdache, M. (2013). Comparison of seismicity declustering methods using a probabilistic measure of clustering. Journal of Seismology, 17(3), 1041–1061. https://doi.org/10.1007/s10950-013-9371-6
Tapponnier, P., & Molnar, P. (1977). Active faulting and tectonics in China. Journal of Geophysical Research, 82(20), 2905–2930. https://doi.org/10.1029/JB082i020p02905
Telesca, L., Lovallo, M., Golay, J., & Kanevski, M. (2016). Comparing seismicity declustering techniques by means of the joint use of Allan Factor and Morisita index. Stochastic Environmental Research and Risk Assessment, 30(1), 77–90. https://doi.org/10.1007/s00477-015-1030-8
Thaker, T. P., Rao, K. S., & Gupta, K. K. (2010). Seismic hazard analysis for Surat City and its surrounding region, Gujarat. In Indian Geotechnical Conference (pp. 163–166).
Thaker, T. P., & Rao, K. S. (2012). Seismic hazard analysis for urban territories: A case study of Ahmedabad region in the state of Gujarat, India. Advanced Soil Dynamics and Foundation Engineering, 19–228.
Tinti, S., & Mulargia, F. (1985). Effects of magnitude uncertainties on estimating the parameters in the Gutenberg-Richter frequency-magnitude law. Bulletin of the Seismological Society of America, 75(6), 1681–1697. https://doi.org/10.1785/BSSA0750061681
Trivedi, S. S., Rao, K. S., Gupta, K. K., & Patel, P. V. (2007). Development of site specific response spectra for Ahmedabad soil sites. In Proceedings of the 1st Srilankan International Conference on Soil Mechanics and Rock Engineering, Colombo, Sri Lanka.
Uhrhammer, R. (1986) Characteristics of northern and central California seismicity. Earthquake Notes, 57(1)
United States Geological Survey. (2014). Understanding plate motions. Accessed March 19, 2022 at. https://pubs.usgs.gov/publications/text/understanding.html
van Stiphout, T., Zhuang, J., & Marsan, D. (2012). Seismicity declustering. Community Online Resource for Statistical Seismicity Analysis, 10(1), 1–25.
Vassallo, R., Mugnier, J.-L., Vignon, V., Malik, M. A., Jayangondaperumal, R., Srivastava, P., Jouanne, F., & Carcaillet, J. (2015). Distribution of the Late-Quaternary deformation in Northwestern Himalaya. Earth and Planetary Science Letters, 411, 241–252. https://doi.org/10.1016/j.epsl.2014.11.030
Waseem, M., & Erdik, M. (2021) Updated probabilistic seismic hazard assessment of Pakistan https://doi.org/10.21203/rs.3.rs-1146457/v1.
Waseem, M., Lateef, A., Ahmad, I., Khan, S., & Ahmed, W. (2019). Seismic hazard assessment of Afghanistan. Journal of Seismology, 23(2), 217–242. https://doi.org/10.1007/s10950-018-9802-5
Wells, D. L., & Coppersmith, K. J. (1994). New empirical relationships among magnitude, rupture length, rupture width, rupture area, and surface displacement. Bulletin of the Seismological Society of America, 84(4), 974–1002.
Wiemer, S., & Wyss, M. (1994). Seismic quiescence before the Landers (M =7.5) and Big Bear (6.5) 1992 earthquakes. Bulletin of the Seismological Society of America, 84, 900–916.
Wiemer, S., & Wyss, M. (2000). Minimum magnitude of complete reporting in earthquake catalogs: Examples from Alaska, the Western United States, and Japan. Bulletin of the Seismological Society of America, 90, 859–869.
Wyss, M., Wiemer, S., & Zuniga, R. (2001). ZMAP A tool for analysis of seismicity patterns: Typical Applications and Uses A cookbook 2001 Retrieved August 29, 2019. https://www.researchgate.net/publication/261170802
Wyss, M., & Toya, Y. (2000). Is background seismicity produced at a stationary Poissonian rate? Bulletin of the Seismological Society of America, 90(5), 1174–1187. https://doi.org/10.1785/0119990158
Xie, W., Hattori, K., & Han, P. (2019). Temporal variation and statistical Assessment of the b Value off the Pacific Coast of Tokachi, Hokkaido. Japan. Entropy, 21(3), 249. https://doi.org/10.3390/e21030249
Yeats, R. S., Nakata, T., Farah, A., Mizra, M. A., Pandey, M. R., & Stein, R. S. (1992). The Himalayan frontal fault system Geodynamics of Pakistan, Geological Survey of Pakistan: Seismicity of the Hazara arc in northern Pakistan: Décollement vs. basement faulting. Annals of Tectonophysics [special Issue], 6, 85–98.
Youngs, R. R., Chiou, S.-J., Silva, W. J., & Humphrey, J. R. (1997). Strong ground motion attenuation relationships for subduction zone earthquakes. Seismological Research Letters, 68(1), 58–73. https://doi.org/10.1785/gssrl.68.1.58
Yousuf, M., & Bukhari, K. (2020). Hazard estimation of Kashmir Basin, NW Himalaya using probabilistic seismic hazard assessment. Acta Geophysica, 68(5), 1295–1316. https://doi.org/10.1007/s11600-020-00485-2
Zare, M., & Karimi-Paridari, S. (2008). Balakot, Muzaffarabad earthquake of 8 October 2005, Mw 7.6 field observations on geological aspects, 14th World Conference on Earthquake Engineering, October 12–17, 2008, Beijing, China.
Zúñiga, F. R., & Wyss, M. (1995). Inadvertent changes in magnitude reported in earthquake catalogs: their evaluation through b-value estimates. Bulletin of the Seismological Society of America, 85(6), 1858–1866. https://doi.org/10.1785/BSSA0850061858
Acknowledgements
The authors extend special thanks to Prof. Andrzej Kijko (University of Pretoria, South Africa) for generously providing the HA3 and AU3 MATLAB codes developed based on the maximum likelihood method (Kijko and Sellevoll 1982). Furthermore, we acknowledge the help of the Indian Meteorological Department (MoES) for providing the raw earthquake catalogue; Dr. Jiancang Zhuang (ISM, Japan) for furnishing the MATLAB codes for declustering algorithms; and Prof. Mario Ordaz (UNAM) for making the RCRISIS software available. The analysis presented herein has been conducted using the ZMAP tool (Wyss et al. 2001) in addition to the above-mentioned software.
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by FZ. Data processing was conducted by AA. The first draft of the manuscript was written by FZ, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zahoor, F., Ansari, A., Rao, K.S. et al. Seismic Hazard Assessment of Kashmir Region Using Logic Tree Approach: Focus on Sensitivity of PSHA Results Towards Declustering Procedures and GMPEs. Pure Appl. Geophys. 180, 789–827 (2023). https://doi.org/10.1007/s00024-023-03239-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-023-03239-5