
Abstract
Anomaly detection stands as a crucial facet within the domain of data quality assurance. Notably, significant strides have been made within the realm of existing anomaly detection algorithms, encompassing notable techniques such as Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and anomaly detection models founded upon Generative Adversarial Networks (GANs). However, a notable gap lies in the inadequate consideration of interdependencies and correlations inherent in multidimensional time-series data. This becomes particularly pronounced within the context of industrial evolution, where industrial data burgeons in complexity. To address this lacuna, a novel hybrid model has been introduced, synergizing the capabilities of GRU with structural learning methodologies and graph neural networks. The model capitalizes on graph structural learning to unearth dependencies linking data points across distinct spatial dimensions. Concurrently, GRU extracts temporal correlations embedded within data along a single dimension. Through the incorporation of graph attention networks, the model employs a dual-faceted correlation perspective for data prediction. Discrepancies between predicted values and ground truth are utilized to gauge errors. The amalgamation of predictive and scoring mechanisms enhances the model’s versatility. Empirical validation on two authentic sensor datasets unequivocally demonstrates the superior efficacy of this approach in anomaly detection compared to alternative methodologies. A notable augmentation is observed particularly in the recall rate, underscoring the method’s potency in identifying anomalies.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Anomaly detection plays a pivotal role in industrial data, with far-reaching implications for ensuring production safety, enhancing efficiency, and reducing costs. Data in the industrial domain spans various aspects from production equipment and supply chains to product quality. Anomalies within this data often signify potential issues or machinery malfunctions. The significance of anomaly detection manifests in several key aspects. Primarily, anomaly detection facilitates the early identification of anomalies within equipment or production processes, such as machinery failures or disruptions in the supply chain. Through real-time monitoring and data analysis, anomaly detection systems can capture deviations from normal patterns, enabling timely interventions before issues propagate and preempting potential production interruptions and quality concerns. Furthermore, anomaly detection significantly contributes to the enhancement of production efficiency. By monitoring data along production lines and identifying anomalies, engineers can pinpoint underlying causes of potential issues. Timely adjustments of parameters and process optimization can effectively minimize resource wastage and energy consumption during production, leading to heightened efficiency. In essence, the role of anomaly detection in industrial data is pivotal, safeguarding operations, driving efficiency gains, and ultimately supporting the overarching goal of sustainable development within the industrial sector.
There are three problems for anomaly detection: 1. It needs to combine domain knowledge [1]; Data anomaly detection needs to emphasize the deep integration of causality, domain knowledge and data analysis process. In the face of complex scene rules contained in data, insufficient scene investigation and preparation often lead to an increase in the probability of failure of the designed anomaly detection method in application. 2. Lack of appropriate datasets [1,2,3,4]; Big data is composed of traditional relational data and temporal data, but there are many problems in data such as insufficient annotation and imbalance between classes. However, the artificial intelligence method of anomaly detection is often strict in the preset of model training data, and the existence of biased heterogeneous data makes the model training very difficult. 3. Large scale and complex model [5,6,7,8]; There are some hidden correlations between data, and the patterns of big data and ordinary data are not interconnected.
The existing anomaly detection models are mainly divided into traditional algorithms and deep learning algorithms.
Traditional algorithms, such as cluster-based, proximity based, binary classification algorithm, etc., have also been widely used in some scenarios due to the improvement of existing researchers. For example, in the partition clustering algorithm, the density function is fused to select the optimal cluster center to avoid the dilemma of local minimization; For the proximity based algorithm, the reverse K-nearest neighbor is used to redetermine the K-nearest neighbor of the abnormal cluster, which also avoids local optimization. These traditional algorithms cannot play their advantages in the context of big data. Large-scale data will lead to great complexity of the algorithm. Therefore, the deep learning algorithm is developed in the big data scenario.
At present, the deep learning algorithms for solving the anomaly detection of sequential data, such as LSTM, self-coder and other models, have developed very rapidly. Because of the characteristics of data timing, LSTM (short and long term memory network) has been widely used and produced many variations. For example, the GAN model based on LSTM applies LSTM to the generator and discriminator that generate the confrontation network, and adds its time correlation to the data [9]; Stacked LSTM plus full connection layer for data prediction; Using the same encoding and decoding architecture as the self-coder, its neurons are replaced with multiple LSTM units. There are many improved applications that utilize the generation of confrontation networks, Lee [10] proposed a framework to compare different models based on generating confrontation networks, concluded that anomaly detection based on GAN has a good prediction performance, and found that adjusting the number of back-propagation of back-mapping technology can improve the prediction performance. Bashar et al. [11] used the Generative adversarial network to complete the task of anomaly detection in the extreme case that only a few data are available. Xu L [12] and others put forward a generation countermine network model based on transformer for the problem that GAN cannot process high-dimensional data. The transformer module is used to replace the generator and discriminator of GAN, and the loss function of the generator and discriminator is used as the abnormal score, which ultimately has a good efficiency. Amarbayasgalan T [3]. proposed a new unsupervised anomaly detection method for time series data based on deep learning. The model consists of two modules: time series reconstructor and anomaly detector. The time series reconstructor module uses the autoregressive model to find the optimal window width, and prepares the subsequence according to the width for further analysis. Then, it uses the depth automatic encoder model to learn the data distribution, and then uses the data distribution to reconstruct the near-normal time series. Wu [13] et al. utilized stacked GRUs to process temporal data with seasonal features and developed an anomaly detection method using matrix operations.
For solving the problem of correlation, there are many models using graph neural network to extract the correlation, Deng A [4] et al. proposed a method combining structural learning method and graph neural network, and used attention weight to provide the interpretation of detected anomalies, but the accuracy of anomaly detection was not significantly improved compared with the generation of confrontation networks. Guan, S [5] and others proposed to extract spatial correlation using graph attention network and temporal correlation using time convolution network, and finally reconstruct and predict the data. The result shows that the effect of anomaly detection has been greatly improved, but the complexity is high and the efficiency is low.
Therefore, this paper proposes a model that combines GRU, graph structure learning, and graph neural networks. This model can obtain multiple correlations while obtaining temporal correlations, and has better results for data with complex hidden relationships. The contributions of this article are summarized as follows:
-
Firstly, use graph structure learning to process data, process each node into multiple feature vectors to represent the adjacency relationship among them, and then use GRU to extract temporal features from nodes with new features and splice them with the original features.
-
Add a residual module to achieve depth feature extraction, while preventing gradient disappearance, gradient explosion, over fitting, and network degradation, accelerating model convergence
2 Related Work
In this chapter, we introduce the relevant content of anomaly detection for multivariate temporal data, introduce the concepts and common methods of temporal correlation and multivariate correlation, and focus on the following figure of neural network processing for multivariate data.
2.1 Multivariate Time Series Anomaly Detection
Anomaly detection is the identification of items, events or observations that do not match the expected pattern or other items in the data set. Anomalies are also referred to as outliers, novelties, noise, biases, and exceptions. Classical methods include traditional classical algorithms, heuristic algorithms, deep learning methods, etc. The current considerations of these algorithms are not comprehensive for multidimensional time-series data, including two dimensions of relevance, the first is on the temporal dimension, for which deep learning has made good progress, and the second is on the spatial dimension, for example, Chen et al. [14] conducted spatial and temporal anomaly detection in the time slice anomaly detection module, graph neural networks, graph attention networks The graph neural network, the graph attention network, has also performed very well in this dimension. Therefore, our goal is to use graph attention networks and recurrent neural networks together to complete the processing of multidimensional temporal data in two dimensions.
2.2 Time Correlations
For time-series data, temporal correlation is the most important factor, and deep learning models are widely used in large-scale time-series data processing. Nowadays, the mainstream models such as, GAN, VAE, LSTM, GRU, Transformer, and other variants and synthesis of these models are more widely used and mature, and Guo Y et al. [15] proposed an anomaly detection for GRU-based Gaussian hybrid VAE system, where GRU units are used to discover correlations between time series. A Gaussian mixed prior in the potential space is then used to characterize multimodal data. Tang C et al. [16] proposed GRN, an interpretable multivariate time series anomaly detection method based on neural graph networks and gated recurrent units GRU, which retains the original advantages of processing sequences and capturing time series correlations, and addresses the problems of gradient disappearance and gradient explosion. However, these models perform well for time series only, and still take the form of parallel processing for multidimensional time series.
2.3 Multiple Correlations
Multiple correlation means for having correlation and dependency between different dimensions in multiple dimensional data, for example, in a water tank, the data collected by the upper pressure sensor and the lower sensor is a pair of positive correlation, for dealing with multiple correlation, there are many methods, for example, using matrix to process data, self-attention mechanism, graph neural network, etc., among which graph neural network is more effective for modeling complex patterns More effective, graph neural network assumes that there are connections between nodes, and represents the characteristics of nodes by aggregating the neighbors between nodes, based on graph neural network, graph attention network uses attention mechanism to calculate the weights between neighboring nodes. Where the input of the graph neural network should be a graph structure, but the data we use is an \(n \times m\) matrix in which there are no connections, so the graph neural network is preceded by using the graph structure learning method GRU to compose a list of temporal and spatial features for the graph neural network training and prediction.
3 Method
In this chapter, the problems to be solved and the model architecture are introduced, including the entire process of feature extraction, prediction, and scoring of data.
3.1 Problem Definition
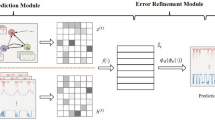
The time series comprises observations at regularly spaced time intervals, and our research objective is a multivariate time series denoted as \(x\in R^{N\times K}\), where N represents the length of the time series and K represents the dimension of each sample at a given moment. The training set, \(x_{T}\in R^{M\times K}\), is used where M (M < N) represents the length of the training set, and the remaining data serves as the testing set. The training set consists solely of normal samples, while the testing set includes both normal and abnormal samples. The model takes input in the form of a sliding window of data, denoted as \(x_{L}\in R^{K\times L}\), where L represents the length of the sliding window. We utilize the graph deviation score as a criterion for identifying anomalies. If the score surpasses the threshold, the sample is labeled as an anomaly; otherwise, it is classified as normal (Fig. 1).

Data formulation of the multivariate time series.
3.2 Model Architecture
The model is divided into three parts: feature extraction, prediction and scoring.
-
Feature extraction:Use graph structure learning to determine the correlation between nodes and extract node spatial features; use GRU to process data and obtain local features and temporal information features of time series
-
Prediction: Using Graph Attention Networks for Predicting Graph Data with Temporal and Correlation Features
-
Scoring: Using the graph deviation scores as the final anomaly scores, the errors for each dimension are calculated for the final merge, and to prevent the deviations caused by any one sensor from being overly dominant relative to the others, we perform a robust normalization of the error values for each sensor (Fig. 2)

Overall framework of anomaly detection model for multivariate time series
Feature Extraction. Feature extraction in the model is divided into extracting time features and correlation features, where GRU is utilized to extract time features, and graph structure learning is used to construct correlation graphs representing relationships among different dimensions.
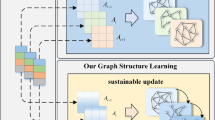
Graph Structure Learning
The main objective of the first part of feature extraction is to learn the relationship between sensors in the form of graph structures. Initially, the raw data is aggregated and then modeled using the normalized dot product of the behavioral features of each dimension with respect to other dimensions. An adjacency matrix A is constructed to store strongly correlated adjacent dimensions, where \(A^{ij}\) denotes the existence of a connection from node i to node j.
We embed the normalized dot product (\(e^{ij}\)) between dimension i and the vectors of other dimensions into node i. m such normalized dot products are selected, where m refers to the top m dimensions with strong correlation, and the value of m can be adjusted to meet different requirements for the sparsity of the graph specified by the user.
Gated Recurrent Unit
The main objective of the second part of feature extraction is to extract the temporal features of the data using GRU. In GRU, the reset gate \(r_t\) and update gate \(z_t\) are used to control the interaction between the input \(x_t\) and the previous hidden state \(h_{t-1}\). Therefore, the time features can be obtained by merging the input of the current time step and the hidden state of the previous time step, and then embedding the resulting hidden vector \(h_t\) into node i at time t.
Reset gate: \(r_{t}=\sigma (W_{r}[x_{t},h_{t-1}])\). Update gate:\(z_{t}=\sigma (W_z[x_t,h_{t-1}])\). By using reset gate and update gate, the model can choose whether to retain the previous information or update it. Here, \(\sigma \) represents the sigmoid function, and \(W_r\) and \(W_z\) are weight matrices.
Based on the reset gate, we can compute the candidate hidden state \(\widetilde{h}\) at the current time step, which is obtained by multiplying the previous hidden state with the reset gate, allowing the time step to intervene and preserve the information that could affect the subsequent computation. Finally, the new hidden state \(h_t\) is calculated as the weighted average of the new candidate hidden state \(\widetilde{h}\) and the past hidden state.
Prediction. To identify whether the data is anomalous, we employ a predictive method to forecast future time points and determine if the actual values deviate from the predicted values. The preprocessed data is transformed into a graph structure with time features, where each node possesses a set of features and interacts with other nodes. The interactions should be meaningful, with more attention given to important node interactions. Therefore, a graph attention network is utilized to calculate the importance of each node by an algorithm and generate representations for each node based on its importance.
Graph Attention Network
The input of a GAT layer is a set of node features \(h= \left\{ \vec {h_{1} }, \vec {h_{2} },\dots ,\vec {h_{k} },\vec {h_{i} }\in R^{F} \right\} \), where k represents the number of nodes and F represents the number of features per node, and the output is a set of new node features \(h^{'}= \left\{ \vec {h^{'}_{1} }, \vec {h^{'}_{2} },\dots ,\vec {h^{'}_{k} },\vec {h^{'}_{i} }\in R^{F^{'}} \right\} \). To obtain sufficient expressiveness and transform the input features into higher-level representations, at least one learnable linear transformation is required. Therefore, as a first step, a shared linear transformation, parameterized by a weight matrix, \(W\in R^{F^{'}\times F}\), is applied to each node. Then, a self-attention mechanism, a shared attention mechanism, is applied to the nodes to compute the attention coefficients.
\(e_{ij}\) represents the importance of the characteristics of node j to node i. In GAT, each node is allowed to participate in the activity of other nodes by injecting the graph structure into the mechanism using a masked attention mechanism. The coefficient \(e_{ij}\) is computed for node i’s neighbor j, in the graph, this corresponds to the first-order neighborhood of node i (including i). To make the coefficients easily comparable across different nodes, we normalize all j options using the softmax function and use LeakyReLU as the non-linear activation function to compute attention coefficients.
With the normalization of attention coefficients, the final output feature \( \vec {h^{'}_{1}}\) for each node can be computed. Subsequently, the results from all nodes are utilized as input to a stacked fully connected layer with an output dimension of N, for the purpose of predicting the vector of sensor values at time step t, denoted as \(x_{pre}\). The mean square error between the predicted output and observed data is employed as the loss function.
Scoring. Our model computes individual anomaly scores for each dimension and combines them to form a single anomaly score for each time step, enabling the user to identify which sensors are anomalous. The anomaly score compares the expected behavior at time t with the observed behavior, calculating the error fall at time t and dimension i. Due to the differing magnitudes of data fluctuations across each dimension, in order to mitigate the influence of certain dimensions on the overall result, we normalize the error values for each dimension:
where \(\tilde{\mu _{i} }\) and \(\tilde{\sigma _{i} }\) are the median and interquartile range of the \(fal_{i}(t)\) values at the time step. We use the median and instead of the mean and interquartile range standard deviation, as they are more robust to outliers.
Subsequently, we simply select the maximum value as the overall anomaly at time t, as anomalies are rare events that may only affect a small subset of dimensions. Finally, we use a simple moving average (SMA) to generate a smoothed score As(t), and set a fixed threshold for anomalies to be detected when As(t) exceeds the threshold value.
3.3 Residual Network
We incorporated a residual network into the graph attention network to address the problem of network degradation in multi-layer neural networks. Forward information transmission filters out irrelevant information, while backward information transmission represents an error. In fact, as the network depth increases, the training error also increases. Excessive network layers lead to identity mapping in subsequent layers, causing resource waste.
4 Experiment
In this chapter, the relevant contents of the experiment are introduced, including the data set experiment results and result analysis.
4.1 Datasets
We utilized two sensor datasets related to water treatment: SWaT and WADI. The data size and composition of the datasets are presented in Table 1. Among them, Swat contains 92501 pieces of data, and WADI contains 136070 pieces of data.
The Secure Water Treatment (SWaT) dataset comes from a water treatment test-bed coordinated by Singapore’s Public Utility Board (Mathur and Tippenhauer 2016). It represents a small-scale version of a realistic modern Cyber-Physical system, integrating digital and physical elements to control and monitor system behaviors. As an extension of SWaT, Water Distribution (WADI) is a distribution system comprising a larger number of water distribution pipelines (Ahmed, Palleti, and Mathur 2017). Thus WADI forms a more complete and realistic water treatment, storage and distribution network. The datasets contain two weeks of data from normal operations, which are used as training data for the respective models. A number of controlled, physical attacks are conducted at different intervals in the following days, which correspond to the anomalies in the test set.
4.2 Baselines
We have compared the performance of this method with several popular anomaly detection methods and the original method, including:
AE: Automatic encoder, wherein the encoder is used for dimensionality reduction of data, and the decoder is used for dimensionality enhancement to complete data reconstruction, using the reconstruction error as an abnormality score.
DAGMM: [17] The automatic encoding Gaussian model combines a depth automatic encoder and a Gaussian mixture model, using the reconstruction error of the self encoder and the likelihood function of the Gaussian model to determine anomalies.
LSTM-VAE: [18] The variational self encoded hidden variable is used as the input to LSTM to predict the next hidden variable, and the prediction error is finally taken as an outlier.
MAD-GAN: [19] Using the LSTM layer as the generator and discriminator of the GAN model, anomaly detection is performed through prediction and reconstruction methods.
GDN: [4]Using Graph Structure Learning and Graph Attention Network for Correlation Learning to Predict and Judge Anomalies.
4.3 Experimental Setup
We implement our method and its variants in PyTorch version 1.5.1 with CUDA 10.2 and PyTorch Geometric Library version 1.5.0, and train them on a server with Intel(R) Core(TM) i7-8750H CPU @ 2.20 GHz and 4 NVIDIA RTX 1060 graphics cards. The models are trained using the Adam optimizer with learning rate \( 1\times 10^{-3} \) and \((\beta 1 , \beta 2)\) = (0.9, 0.99). We train models for up to 30 epochs. We use embedding vectors with length of 64, k with 15 and hidden layers of 64 neurons for the datasets, corresponding to their difference in input dimensionality. We set the sliding window size w as 5 for both datasets.
4.4 Evaluation Metrics
We employ precision (Prec), recall (Rec), and F1-Score (F1) to evaluate our approach and baseline models, where \(F1=\frac{2\times Prec\times Rec}{Prec+Rec}\), \(Prec=\frac{TP}{TP+FP}\), and \(Rec=\frac{TP}{TP+FN}\). Here, TP, TN, FP, and FN represent the numbers of true positives, true negatives, false positives, and false negatives, respectively. To detect anomalies, we set the threshold using the maximum anomaly score on the validation dataset. During testing, any time step exceeding the threshold will be classified as an anomaly.
4.5 Results
In Table 2, we show the anomaly detection accuracy in terms of precision, recall and F1-score, of our GRU-GDN method and the baselines, on the SWaT and WADI datasets. The results show that GRU-GDN outperforms the baselines in both datasets, with high precision in both datasets of 0.95 on SWaT and 0.87 on WADI. The recall rate on SWaT has increased significantly, by 14%, and the accuracy rate on WADI has increased significantly, by 9%.
In the context of industrial data, the emphasis lies in effectively detecting genuine anomalies, making the recall rate a crucial metric of interest. Specifically, concerning the SWaT dataset, the GRU-GDN model exhibits superior performance in terms of recall. Additionally, when dealing with the more complex and voluminous WADI dataset characterized by higher dimensions, the GRU-GDN model demonstrates a comprehensive improvement across all three evaluation metrics. These outcomes underscore the significance of the model’s ability to extract temporal correlations and multidimensional spatial relationships, thereby enhancing the accuracy of anomaly detection. Furthermore, these results provide a substantiated rationale for the observed superiority of the GRU-GDN model over the baseline techniques.
4.6 Ablation Experiment
In order to study the effectiveness of the method in improving the effectiveness of anomaly detection, we separately excluded these components to observe the decline in model performance. First, we replace GRU with LSTM to extract temporal features. Secondly, we eliminate the attention mechanism and assign the same weight to different nodes. The results are summarized as follows(Table 3):
5 Conclusions
In this work, we use the framework of graph structure learning and graph attention networks to complete the extraction and prediction of spatial features. We propose to combine GRU to extract temporal features in parallel, and complete data anomaly detection tasks with long time series, complex features, and multiple dimensions. Experimental validation on data sets shows that the GRU-GDN method outperforms the baseline method in terms of accuracy, recall, and F-score, Future work can simplify the model and use it online, improving the practicality of the method
References
Zhao, P., Chang, X., Wang, M.: A novel multivariate time-series anomaly detection approach using an unsupervised deep neural network. IEEE Access 9, 109025–109041 (2021)
Schmidl, S., Wenig, P., Papenbrock, T.: Anomaly detection in time series: a comprehensive evaluation. Proc. VLDB Endow. 15(9), 1779–1797 (2022)
Amarbayasgalan, T., Pham, V.H., Theera-Umpon, N., et al.: Unsupervised anomaly detection approach for time-series in multi-domains using deep reconstruction error. Symmetry 12(8), 1251 (2020)
Deng, A., Hooi, B.: Graph neural network-based anomaly detection in multivariate time series. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 5, pp. 4027–4035 (2021)
Guan, S., Zhao, B., Dong, Z., Gao, M., He, Z.: GTAD: graph and temporal neural network for multivariate time series anomaly detection. Entropy 24(6), 759 (2022)
Zhou, H., Yu, K., Zhang, X., et al.: Contrastive autoencoder for anomaly detection in multivariate time series. Inf. Sci. 610, 266–280 (2022)
Almardeny, Y., Boujnah, N., Cleary, F.: A novel outlier detection method for multivariate data. IEEE Trans. Knowl. Data Eng. 1 (2020). https://doi.org/10.1109/tkde.2020.3036524
Pasini, K., Khouadjia, M., Samé, A., et al.: Contextual anomaly detection on time series: a case study of metro ridership analysis. Neural Comput. Appl. 34(2), 1483–1507 (2022)
Niu, Z., Yu, K., Wu, X.: LSTM-based VAE-GAN for time-series anomaly detection. Sensors 20(13), 3738 (2020). https://doi.org/10.3390/s20133738
Lee, C.K., Cheon, Y.J., Hwang, W.Y.: Studies on the GAN-based anomaly detection methods for the time series data. IEEE Access 9, 73201–73215 (2021)
Bashar, M.A., Nayak, R.: TAnoGAN: time series anomaly detection with generative adversarial networks. In: 2020 IEEE Symposium Series on Computational Intelligence (SSCI), pp. 1778–1785. IEEE (2020)
Xu, L., Xu, K., Qin, Y., et al.: TGAN-AD: transformer-based GAN for anomaly detection of time series data. Appl. Sci. 12(16), 8085 (2022)
Wu, W., He, L., Lin, W., et al.: Developing an unsupervised real-time anomaly detection scheme for time series with multi-seasonality. IEEE Trans. Knowl. Data Eng. (2020)
Chen, L.J., Ho, Y.H., Hsieh, H.H., et al.: ADF: an anomaly detection framework for large-scale PM2. 5 sensing systems. IEEE Internet Things J. 5(2), 559–570 (2017)
Guo, Y., Liao, W., Wang, Q., et al.: Multidimensional time series anomaly detection: a GRU-based gaussian mixture variational autoencoder approach. In: Asian Conference on Machine Learning, pp. 97–112. PMLR (2018)
Tang, C., Xu, L., Yang, B., et al.: GRU-based interpretable multivariate time series anomaly detection in industrial control system. Comput. Secur. 103094 (2023)
Zong, B., et al.: Deep autoencoding Gaussian mixture model for unsupervised anomaly detection. In: International Conference on Learning Representations, February 2018
Park, D., Hoshi, Y., Kemp, C.C.: A multimodal anomaly detector for robot-assisted feeding using an LSTM-based variational autoencoder. IEEE Robot. Autom. Lett. 3(3), 1544–1551 (2018)
Li, D., Chen, D., Jin, B., Shi, L., Goh, J., Ng, S.-K.: MAD-GAN: multivariate anomaly detection for time series data with generative adversarial networks. In: Tetko, I.V., Kůrková, V., Karpov, P., Theis, F. (eds.) ICANN 2019. LNCS, vol. 11730, pp. 703–716. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-30490-4_56
Acknowledgments
This work was supported by the National Key R &D Program of China under Grant No. 2020YFB1710200. The datasets are provided by iTrust, Centre for Research in Cyber Security, Singapore University of Technology and Design.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Lu, D., Li, S., Zhao, Y., Han, Q. (2024). Anomaly Detection of Industrial Data Based on Multivariate Multi Scale Analysis. In: Jin, H., Yu, Z., Yu, C., Zhou, X., Lu, Z., Song, X. (eds) Green, Pervasive, and Cloud Computing. GPC 2023. Lecture Notes in Computer Science, vol 14503. Springer, Singapore. https://doi.org/10.1007/978-981-99-9893-7_7
Download citation
DOI: https://doi.org/10.1007/978-981-99-9893-7_7
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-9892-0
Online ISBN: 978-981-99-9893-7
eBook Packages: Computer ScienceComputer Science (R0)