
Abstract
Remaining useful life (RUL) prediction is one of the key techniques in prognostics and health management (PHM). Deep learning-based prognostics methods, which can automatically mine useful degradation information from monitoring data and infer causal relationships, have received a lot of attention in RUL prediction of machinery. However, in some industrial application scenarios, the operating conditions of the actual data often differ significantly from those of the training data, which greatly limits the predictive performance of the prediction methods. To overcome the above limitations, an anti-adaptive residual life prediction framework is proposed for RUL prediction under different operating conditions. First, a new network, named bidirectional temporal convolutional network (BDTCN), is proposed to capture the interdependence of the input data on the time scale through forward and reverse convolution operations. Then, an anti-adaptive training strategy is developed to help the BDTCN further extract the operating condition invariant degradation features so that it can perform RUL prediction across operating conditions. The proposed framework is evaluated through ablation experiments and comparison with existing methods. The experimental results demonstrate the effectiveness and superiority of the framework in RUL prediction.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Remaining useful life (RUL) prediction is one of the key techniques for prognostics and health management (PHM), which can estimate the remaining time before damage develops beyond the failure threshold, thus avoiding unplanned downtime and improving the safety, reliability and durability of machinery [1, 2]. Generally, RUL prediction methods are developed based on first-principles, degradation mechanisms, or artificial intelligence (AI) techniques. With the wide application of Industrial Internet of Things (IoT), AI-based prediction methods have received more attention in RUL prediction of machinery than other methods because they can automatically mine useful degradation information from monitoring data and infer correlation and causation [3].
Existing AI-based prediction methods can be categorized into two main groups: shallow learning-based methods and deep learning-based methods [4]. Shallow learning-based methods are built on some traditional machine learning models. These models have limited representational learning capabilities and thus require a priori knowledge or domain expertise to preprocess the raw monitoring data from the machine. However, in the era of industrial IoT, where the amount of monitoring data grows exponentially over time, the process of sensitive feature extraction becomes increasingly difficult. To address the massive monitoring data and avoid labor-intensive feature extraction, deep learning, a special class of machine learning, is gradually being applied to RUL prediction of machinery [5].
Deep learning-based methods are constructed by stacking multiple nonlinear processing layers, which represent a stronger learning capability compared to shallow learning-based methods. As a result, deep learning-based methods get rid of the process of sensitive feature extraction and are able to directly use raw monitoring data as inputs for model training and RUL prediction. In the past few years, scholars have employed different types of deep learning models to accomplish the RUL prediction task. Wang et al. [6] constructed a multi-scale convolutional attention network to solve the problem of multi-sensor information fusion and applied it into RUL prediction of cutting tools. Ma et al. [5] proposed a convolution-based long short-term memory network for RUL prediction, in which the convolutional structure embedded in the LSTM is able to capture long-term dependencies while extracting features in the time-frequency domain. Wu et al. [7] built a LSTM autoencoder considering various degradation trends and adopted it to estimate the bearing RUL. Although deep learning-based prediction methods have achieved some state-of-the-art results, few studies have considered the prediction of machinery life under different operating conditions. In some industrial application scenarios, the operating conditions of the actual data often differ greatly from those of the training data, which greatly limits the prediction performance of the prediction methods.
Based on the above analysis, this paper proposes a new network called bidirectional temporal convolutional network (BDTCN), where the core layer of the network: the bidirectional temporal convolutional layer can be used for elaborate information mining and time series modeling along the forward and reverse directions to capture the i and efficiently capture the variation of operating conditions. In addition, to enable the network predict RUL using data from different operating conditions, this paper develops a new training strategy, namely the adversarial adaptation training strategy, which can help the network to extract operating condition-invariant degradation features for RUL prediction.
The remaining sections of this paper are summarized as follows. Section 2 describes in detail the proposed BDTCN and the adversarial adaptation training strategy for mechanical RUL prediction under different operating conditions. Section 3 validates the effectiveness of the proposed method by performing accelerated degradation experiments on rolling bearings. Finally, conclusions are given in Sect. 4.

The network structure of BDTCN
2 The BDTCN and the Adversarial Adaptation Training Strategy
In this section, a bidirectional temporal convolutional layer is first constructed to fully exploit the machine degradation information and efficiently capture the variation of operating conditions in RUL prediction. Then, an adversarial adaptation training strategy is developed to essentially enhance the robustness of BDTCN's RUL prediction under different operating conditions.
2.1 Proposed BDTCN
The network structure of BDTCN is shown in Fig. 1, which consists of a representation learning sub-network and a RUL prediction sub-network. The representation learning sub-network consists of D bidirectional temporal convolutional layers and D maximum pooling layers stacked alternately, after which the RUL prediction sub-network uses two fully connected layers for RUL prediction. Specifically, the proposed BDTCN embeds temporal information into the network inputs using a time window with a length of S. These input data have interdependencies on time scales, and such dependencies are crucial for accurate RUL prediction under different operating conditions. Therefore, the BDTCN constructs a new layer of the network, i.e., the bidirectional temporal convolutional layer to enhance the temporal information mining capability of the prognostics network.

Architecture of bidirectional temporal convolutional layer
As shown in Fig. 2, The bidirectional temporal convolutional layer contains a forward temporal convolution operation and a reverse temporal convolution operation. The process of bidirectional temporal convolution operation can be formulated as follows:
where \(\sigma_{{\text{r}}} \left( \cdot \right)\) is nonlinear activation function, \({\varvec{x}}_{t}^{l - 1}\) is the input tensor of l-th bi-directional temporal convolution layer at time t, \(\vec{z}_{n,t}^{l}\) is the output tensor of the forward temporal convolution at time t, \(\user2{\mathop{k}\limits^{\leftarrow} }_{n}^{l} *_{d}\) is the n-th reverse temporal convolution kernel with an expansion of d, \(\vec{b}_{n}^{l}\) and \( \overleftarrow {b} _{n}^{l} \) are the bias term. In particular, the number of forward and reverse temporal convolution kernels of the l-th bidirectional temporal convolution layer are both \(2^{{\left( {l - 1} \right)}} N\) and the expansion rate are both \(2^{{\left( {l - 1} \right)}}\). After that, the outputs of these two convolutions are fed separately to the maximum pooling layer, which is formulated as follows:
where p is the pooling size and s is the pooling stride. Note that in the example of Fig. 2, the number of convolution kernels is set to 1 for ease of observation and no maximum pooling layer is added.
2.2 Adversarial Adaptation Training for BDTCN
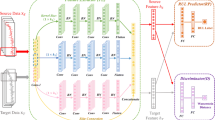
This section proposes the adversarial adaptation training strategy as shown in Fig. 3, which takes into account the variability between monitoring data with different working conditions, and adapts and fine-tunes the BDTCN to the operating conditions by generating adversarial training. The proposed adversarial adaptation strategy first initializes the BDTCN using the source operating condition dataset, and the initialized representation learning sub-networks \(F\left( \cdot \right)\) and RUL prediction sub-networks \(R\left( \cdot \right)\) can be obtained. Then, the generative adversarial network is constructed to obtain operating condition-invariant degradation features, specifically, the generator consists of the representation learning sub-network and the discriminator consists of three fully connected layers. The generator and the discriminator are independent of each other and optimize their respective network parameters alternately by means of adversarial training, and finally reach the Nash equilibrium, i.e., the generator outputs operating condition-invariant representations, so that the discriminator cannot judge its operating condition. And its objective function is defined as follows:

An illustration of adversarial adaptation training
where \({\varvec{X}}_{s}\) is the samples from the source operating condition dataset, \({\varvec{X}}_{t}\) is the samples from the target operating condition dataset, \(F^{*} \left( \cdot \right)\) is the generator after updating network parameters. The discriminator \(D\left( \cdot \right)\) is fixed when the parameters of the generator \(F\left( \cdot \right)\) are updated, and the objective function of the generator can be formulated as follows:
Similarly, the objective function of the discriminator can be expressed as follows:
The operating condition-invariant representations can be extracted by the above adversarial domain adaptation training strategy, thus realizing the RUL prediction under different operating conditions data.
Finally, the RUL prediction subnetwork is fine-tuned using the source operating condition dataset, noting that the parameters of the representation learning sub-network \(F^{*} \left( \cdot \right)\) are fixed in this process and only the parameters of the RUL prediction sub-network \(R\left( \cdot \right)\) are updated.
3 Experimental Results and Analysis
3.1 Data Description
To validate the effectiveness of the proposed method, accelerated degradation tests were performed on a rolling bearing testbed as shown in Fig. 4. The tested bearings were driven by an alternating current (AC) motor and the radial force was applied by a hydraulic loading device. The run-to-failure data of the tested bearings were collected by horizontal and vertical accelerometers with a sampling frequency of 25.6 kHz, a sampling interval of 12 s and a sampling time of 1.28 s each interval. As shown in Table 1, a total of 14 LDK UER204 ball bearings were subjected to accelerated degradation under three different operating conditions. The tested bearings under the first operating condition were used as the source-domain, and the tested bearings under the last two operating conditions were used as the target-domain data. In addition, the first two tested bearings in each target condition are used in adversarial domain adaptation, and the last three ones are used as testing set.

Rolling bearing testbed
3.2 Ablation Experiments
In order to validate the effectiveness of the BDTCN and adversarial adaptation training strategy, ablation experiments were performed in this section. Method 1 uses a standard convolutional layer instead of a bidirectional temporal convolutional layer and does not use the adversarial adaptation training strategy. Method 2 constructed by standard convolutional layer and trained by adversarial adaptation strategy. Method 3 retains the bidirectional temporal convolutional layer but does not use an adversarial adaptation training strategy. The performance of the compared methods is shown in Table 2, according to which the following analysis can be done: The RMSE of Method 1 is the largest among all compared methods, which indicates that if the network obtained by directly using the data trained from a single working condition is predicted under the new working condition, the network will be difficult to obtain good prediction results, which leads to a large error between the predicted value and the true value, whereas the BDTCN uses a bidirectional temporal convolutional layer for feature extraction and is trained using the antithetic adaptation strategy, so its RMSE is minimized among all the compared networks.
3.3 Comparison with Existing Methods
This section uses three existing prognostics methods for RUL prediction. Method 4 [8] is constructed based on sparse self-coding. Method 5 [9] and Method 6 [10] are built on top of convolutional neural networks and convolutional long- and short-term memory networks, respectively. Table 2 summarizes the performance evaluation results of the proposed methods and the three existing migration prediction methods. From the table, it can be seen that the proposed method obtains the minimum RMSE value in the RUL of the tested bearings for each operating condition. This indicates that compared to the other three existing methods, the proposed BDTCN is able to obtain higher prediction accuracy and more stable prediction results under different operating conditions. Therefore, the prediction performance of the proposed method is better than the other three existing methods.
4 Conclusion
An anti-adaptive remaining lifetime prediction framework is proposed for RUL prediction under different operating conditions. First, a new network, named BDTCN, is proposed to extract the interdependencies of input data on time scales through forward and reverse convolution operations to capture key degradation features associated with operating conditions. Then, an anti-adaptive training strategy is developed to help the BDTCN further extract the operating condition invariant degradation features. The proposed framework is evaluated through ablation experiments and comparison with existing methods. The experimental results demonstrate the effectiveness and superiority of the framework in RUL prediction.
References
Wang, W., Lei, Y., Yan, T., Li, N., Nandi, A.: Residual convolution long short-term memory network for machines remaining useful life prediction and uncertainty quantification. J. Dyn. Monitoring Diagnost. 1(1), 2–8 (2022)
Luo, P., Hu, J., Zhang, L., Hu, N., Yin, Z.: Research on remaining useful life prediction method of rolling bearing based on health indicator extraction and trajectory enhanced particle filter. J. Dyn. Monitoring Diagnost., 66–83 (2022)
Gebraeel, N., Lei, Y., Li, N., Si, X., Zio, E.: Prognostics and remaining useful life prediction of machinery: advances, opportunities and challenges. J. Dyn. Monitoring Diagnost. 2(1), 1–12 (2023)
Wang, B., Lei, Y., Yan, T., Li, N., Guo, L.: Recurrent convolutional neural network: a new framework for remaining useful life prediction of machinery. Neurocomputing 379, 117–129 (2020)
Ma, M., Mao, Z.: Deep-convolution-based LSTM network for remaining useful life prediction. IEEE Trans. Industr. Inf. 17(3), 1658–1667 (2020)
Wang, B., Lei, Y., Li, N., Wang, W.: Multiscale convolutional attention network for predicting remaining useful life of machinery. IEEE Trans. Industr. Electron. 68(8), 7496–7504 (2021)
Wu, J.-Y., Wu, M., Chen, Z., Li, X.-L., Yan, R.: Degradation-aware remaining useful life prediction with LSTM autoencoder. IEEE Trans. Instrum. Meas. 70, 1–10 (2021)
Sun, C., Ma, M., Zhao, Z., Tian, S., Yan, R., Chen, X.: Deep transfer learning based on sparse autoencoder for remaining useful life prediction of tool in manufacturing. IEEE Trans. Industr. Inf. 15(4), 2416–2425 (2018)
Cheng, H., Kong, X., Chen, G., Wang, Q., Wang, R.: Transferable convolutional neural network based remaining useful life prediction of bearing under multiple failure behaviors. Meas. Sci. Technol. 168, 108286 (2021)
Wu, Z., Yu, S., Zhu, X., Ji, Y., Pecht, M.: A weighted deep domain adaptation method for industrial fault prognostics according to prior distribution of complex working conditions. IEEE Access 7, 139802–139814 (2019)
Acknowledgments
The authors gratefully acknowledge the support provided by National Key R&D Program of China (No. 2022YFB4300602).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 Beijing Paike Culture Commu. Co., Ltd.
About this paper

Cite this paper
Guan, J., Gao, Y., Cheng, X., Wang, D., Wang, L., Ren, X. (2024). Adversarial Adaptation Based on Bidirectional Temporal Convolutional Network for RUL Prediction. In: Gong, M., Jia, L., Qin, Y., Yang, J., Liu, Z., An, M. (eds) Proceedings of the 6th International Conference on Electrical Engineering and Information Technologies for Rail Transportation (EITRT) 2023. EITRT 2023. Lecture Notes in Electrical Engineering, vol 1138. Springer, Singapore. https://doi.org/10.1007/978-981-99-9319-2_66
Download citation
DOI: https://doi.org/10.1007/978-981-99-9319-2_66
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-9318-5
Online ISBN: 978-981-99-9319-2
eBook Packages: EngineeringEngineering (R0)