
Abstract
Object detection algorithms can benefit from multi-level features, which encompass both high-level semantic information and low-level location details. However, existing detection methods face numerous challenges in effectively utilizing these multi-level features. Most existing detection techniques utilize simplistic operations such as feature addition or concatenation to fuse multi-level features, thereby failing to effectively suppress redundant information. Consequently, the performance of these algorithms is significantly constrained in complex scenarios. To address these limitations, this paper presents a novel feature extraction network that incorporates joint modeling and multi-dimensional feature fusion. Specifically, the network partitions the features of each level into tiles and employs hybrid self-attention mechanisms to extract these grouped features more comprehensively. Additionally, a hybrid cross-attention-based approach is utilized to regulate the transmission proportion of each grouped feature, facilitating the seamless integration of high-level semantic features obtained from deep encoders and the low-level position details retained by the pipeline. Consequently, the network effectively suppresses noise and enhances performance. Experimental evaluation on the MS COCO dataset demonstrates the effectiveness of the proposed approach, achieving an impressive accuracy of 54.3%. Notably, the algorithm showcases exceptional performance in detecting small-scale targets, surpassing the capabilities of other state-of-the-art technologies.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
The integration of multi-level features, encompassing both high-level semantic information and low-level location details, is pivotal in bolstering the performance of object detection algorithms. However, existing detection methods encounter several challenges in effectively harnessing these multi-level features. Firstly, conventional object detection networks primarily rely on the final convolution features for detection while neglecting intermediate pooling operations that lead to a substantial reduction in feature size, often dwindling to just 1/32 of the input image size. This significant reduction presents a formidable obstacle to detection accuracy. Consequently, two categories of methods have been proposed to address this issue. The first category [1], focuses on leveraging high-resolution features to mitigate information loss. The second category [2], combines high-level features and low-level features to enhance the semantic information for detection. In this paper, our proposed method draws inspiration from both categories of networks. It not only constructs high-resolution end features but also progressively incorporates semantic knowledge from high-level features to enhance the localization accuracy of low-level features during the feature extraction process.
Secondly, in many detection methods [10, 19], high-level features and low-level features are often fused using simple cascading or addition operations, without effectively suppressing redundant information. Consequently, the performance of the network is significantly restricted, particularly in complex scenarios. To address this limitation, the approach presented in this paper employs feature grouping to organize multi-level feature information and utilizes cross-attention to regulate the transmission proportion within each feature group. This approach facilitates the effective transmission of information that is crucial for detection.
This paper presents a novel approach for feature extraction in which joint modeling and multi-dimensional feature fusion techniques are employed. The proposed network takes advantage of the attention mechanism for global modeling and the convolutional mechanism for local modeling, facilitating the effective learning of spatial and semantic information at different levels. By using self-attention, the network captures global context information and establishes long-range dependencies, enabling the extraction of valuable features. Additionally, cross-attention is utilized to adjust the contribution of each feature group, highlighting relevant information while suppressing redundant information. The network is composed of three key modules: the Hybrid Self-Attention Module, the Hybrid Cross-Attention Module, and the Encoder-Decoder Module. The hybrid self-attention and cross-attention modules play vital roles in the feature extraction and fusion reconstruction processes at each layer. The encoder module is designed based on hybrid self-attention, and the decoder module employs hybrid cross-attention. This architecture enables the network to effectively capture and combine relevant information from multiple dimensions, enhancing the overall feature extraction capabilities.
In summary, our contributions are as follows:
-
We introduce cross-attention mechanisms in object detection that highlight relevant information and suppress redundant information by adjusting the contributions of each feature group. This multi-dimensional feature fusion method can make full use of multiple feature dimensions, improve the consistency and richness of feature expression.
-
We propose Hybrid Self-Attention Module, the Hybrid Cross-Attention Module, and the Encoder-Decoder Module. This approach successfully integrates local information with global information and merges high-level features with low-level features.
-
We design STFormer which achieves an impressive accuracy of 54.3% on the MS COCO dataset, demonstrates the effectiveness of our approach. This achievement serves as compelling evidence in support of the efficacy and effectiveness of our approach.
2 Related Work
CNN and Variants. CNNs serve as the standard network model throughout computer vision. Until the introduction of AlexNet [13] that CNN took off and became mainstream. Since then, deeper and more effective convolutional neural architectures [21] have been proposed to further propel the deep learning wave in computer vision, e.g. ResNet [11], Faster-RCNN [22], and EfficientNet [24]. In addition to these architectural advances, there has also been much work on improving individual convolution layers, such as depthwise convolution and deformable convolution. While CNN and its variants are still the primary backbone architectures for computer vision applications, we highlight the strong potential of Transformer-like architectures for unified modeling between vision and language. Our work achieves strong performance on several basic visual recognition tasks, and we hope it will contribute to a modeling shift.
Self-attention for Object Detection. Also inspired by the success of self-attention layers and Transformer architectures in the NLP field, some works [4, 5] employ self-attention layers to replace some or all of the spatial convolution layers in the popular ResNet. In these works, the self-attention is computed within a local window of each pixel to expedite optimization, and they achieve slightly better accuracy/FLOPs trade-offs than the counterpart ResNet architecture. However, their costly memory access causes their actual latency to be significantly larger than that of the convolutional networks. Instead of using sliding windows, we propose to shift windows between consecutive layers, which allows for a more efficient implementation in general hardware. Another work is to augment a standard CNN architecture with self-attention layers or Transformers. The self-attention layers can complement backbones or head networks by providing the capability to encode distant dependencies or heterogeneous interactions. More recently, the encoder-decoder design in Transformer has been applied for object detection and instance segmentation tasks. Our work explores the adaptation of Transformers for basic visual feature extraction and is complementary to these works.
Transformer Based Vision Backbones. Most related to our work is the Vision Transformer [27] (ViT) and its follow-ups. The pioneering work of ViT directly applies a Transformer architecture on nonoverlapping medium-sized image patches for image classification. It achieves an impressive speed-accuracy tradeoff in image classification compared to convolutional networks. While ViT requires large-scale training datasets (i.e., JFT-300M [23]) to perform well, DeiT introduces several training strategies that allow ViT to also be effective using the smaller ImageNet-1K dataset [6]. The results of ViT on image classification are encouraging, but its architecture is unsuitable for use as a general-purpose backbone network on dense vision tasks or when the input image resolution is high, due to its low-resolution feature maps and the quadratic increase in complexity with image size. Empirically, we find Swin Transformer [20] approach is both efficient and effective, achieving state-of-the-art accuracy on both MS COCO dataset [18] and ADE20K [29] semantic segmentation.
3 Method
On the basis of the above solutions, we propose STFormer framework. We format our framework into three parts: Hybrid Self-Attention Module, Hybrid Cross-Attention Module, and the Encoder-Decoder Module. In this section, we will introduce the main components of STFormer.
3.1 Overall Architecture

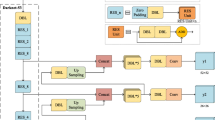
The architecture of Transformer Encoder-Decoder Net.
Figure 1 depicts the design framework of the proposed feature fusion network, STFormer. The RGB input image is divided into non-overlapping patches using patch partitioning. Each patch comprises 16 (\(4\,\times \,4\)) adjacent pixels, encompassing the top, bottom, left, and right regions, resulting in a total of 48 (\(4\,\times \,4\times \,3\)) dimensional feature information. Subsequently, the original feature information of each patch is mapped to a predefined dimension, C, using Linear embedding.
To address the loss of spatial information during bottom-up reasoning, it becomes necessary to incorporate a mechanism that effectively processes and integrates cross-scale features during top-down reasoning. To achieve this, we adopt a single pipeline approach with skip layers, akin to the Hourglass network, which helps retain spatial information at each resolution. This ensures the preservation of crucial spatial details throughout the reasoning process.
3.2 Transformer Encoder-Decoder Blocks
The proposed Transformer Encoder-Decoder blocks in this section, featuring an encoder that performs bottom-up reasoning, a decoder that operates in a bottom-down manner, and a pipeline that connects the encoder and decoder. The encoder incorporates the tile merging module for downsampling the features, followed by the feature extraction module based on the hybrid self-attention module design. Conversely, the decoder utilizes the feature reconstruction module, designed with the hybrid cross-attention module, for feature fusion and reconstruction. Subsequently, the tile recombination module is employed for feature upsampling. To retain information lost during feature downsampling, the pipeline section employs a single pipe with skip layers. This design ensures effective feature processing and integration throughout the encoder-decoder structure.

A set of corresponding Transformer Encoder-Decoder blocks (notation presented with Eq. 1). SATT is the Hybrid self-attention module, XATT is the Hybrid cross-attention module.
As shown in Fig. 2, the strategy of window division in the first group of encoder modules divides the \(16\times 16\) feature map into \(4\,\times \,4\) windows (each window consists of \(4\,\times \,4\) patches). The corresponding last group of decoder modules uses the same window division strategy to divide the feature map of the same size into \(4\,\times \,4\) windows.
A set of corresponding Transformer Encoder-Decoder blocks are calculated as follows:
where \(z^{el}\) and \(z^{dl}\) mean a set of corresponding output feature maps of the Encoder module and the Decoder module. IG represents our image fusion module, SATT and XATT respectively represent our Hybrid self-attention module and Hybrid cross-attention module, Res represents residual blocks, and Std represents the standardization operation.
3.3 Patch Merge and Patch Demerge
In contrast to conventional convolutional neural networks that employ maximum pooling for downsampling and depooling for upsampling, this section introduces the Patch Merge module for downsampling and Patch Demerg module for upsampling. This choice is motivated by the fact that the fundamental unit of self-attention operation is the tile vector, and sampling involves rearranging and mapping the tile vectors. Similarly, Patch Merge and Patch Demerg modules serve the purpose of rearranging and mapping the tile vectors, aligning them with the underlying principles of self-attention.
The patch merge method will rearrange input feature maps of shape \(h\,\times \,w\,\times \,C\) into output feature maps of shape \(\frac{h}{r} \times \frac{w}{r} \times 2C\).
The patch demerge method and the patch merge method are inverse operations of each other and will rearrange the input feature map of shape \(h\times w\times C\) into an output feature map of shape \(rh\times rw\times \frac{C}{2}\).
The variables w, h, and c denote the dimensions of the input data T in the graph structure. T represents a matrix or tensor. h is the vector representation of the matrix T on the abscissa, w is the vector representation of the matrix T on the ordinate, c is the vector representation of the matrix T on the feature dimension.
3.4 Hybrid Self-attention Module
The hybrid self-attention module proposed in this section is a modular unit composed of a window division module, spatial self-attention module, and channel self-attention module. It consists of multiple sets of linear mapping, L2 regularization operations, and matrix operations. Unlike the self-attention module in the Swin-Transformer [20] network, we add channel attention to ensure equal attention to both spatial and channel dimensions. However, the introduction of the channel self-attention module doubles the computational complexity, slows down network prediction time, and increases training difficulty. To mitigate these challenges, we employ a window mechanism and the linear attention mechanism concurrently [15] to maintain computational complexity on a linear scale. The hybrid self-attention module proposed in this chapter exhibits stronger information processing capabilities compared to the self-attention module in the Swin-Transformer network, achieving a smaller computing scale while preserving consistent input and output. The structural differences between the self-attention module in the Swin-Transformer network and the hybrid self-attention module in this chapter can be observed in the comparison Fig. 3, illustrating the overall operation process of input information after passing through different modules.

Hybrid self-attention module
Figure 3(left) shows the calculation process of the Swin-Transfromer network self-attention module, which splits the image into several non-overlapping independent windows through the window division mechanism, and divides a calculation problem into \((\frac{h}{M}\times \frac{w}{M})\) sub-problems, which greatly reduces the computational complexity. The formula (3) shows the computational complexity of the self-attention module, where h represents the input image length, w represents the input image width, C represents the number of channels of the input image, and M represents the window length and width (M is set to 7 in the experiment).
Figure 3(right) shows the calculation process of the mixed self-attention module proposed in this chapter, which relies on the window mechanism to reduce the complexity, and reduces the calculation scale of the attention inside the window from the original inner attention \(O(4M^2C^2+2M^4C)\) to the current linear attention \(O(4M^2C^2+2M^2C)\) by expanding the first-order Taylor formula to taking approximations and multiplexing intermediate results. After further adding the channel attention module, the computational complexity of the mixed attention module is described in the Eq. (4). Considering M = 7 in the experiment, the final hybrid self-attention module pays attention to the channel dimension information while the computational scale also decreases.
The formula (5) shows the function expression of the spatial self-attention module, and the formula (6) shows the jth column of the attention function. Due to the intermediate result produced in the operation \({\textstyle \sum _{i=1}^{C}v_{i}(\frac{k_i}{\left| k_i \right| _2 })^T}\) and \({\textstyle \sum _{i=1}^{C}(\frac{k_i}{\left| k_i \right| _2 })^T}\) can be reused, so the two intermediate results are the same as \( \frac{q_j}{\left| q_j \right| _2 }\) together introduce the computational complexity of \(O(2M^2C)\). where \(Q\in R^{M^2C}\), \(K\in R^{M^2C}\), and \(V\in R^{M^2C}\), respectively, are query matrices, key matrices, and value matrices constructed by the spatial self-attention module, and \(q_j\in R^{M^2}\), \(k_i\in R^{M^2}\), and \(v_i\in R^{M^2}\) are column vectors in the Q matrix, K matrix, and V matrix, respectively.
The formula (7) shows the function expression of the channel from the attention module, and the formula (8) shows the ith line of the attention function. Due to the intermediate result produced in the operation \({\textstyle \sum _{j=1}^{M^2}(\frac{k_j}{\left| k_j \right| _2 } )v_j^T}\) and \({\textstyle \sum _{j=1}^{M^2}(\frac{k_j}{\left| k_j \right| _2 } )}\) can be reused, so the two intermediate results are the same as \(( \frac{q_i}{\left| q_i \right| _2 })^T\) together introduce the computational complexity of \(O(2M^2C)\). where \(q_i\in R^{C}\), \(k_j\in R^{C}\), and \(v_j\in R^{C}\), respectively, are column vectors in the \(Q^T\) matrix, the \(K^T\) matrix, and the \(V^T\) matrix.
3.5 Hybrid Cross-Attention Module
The proposed hybrid cross-attention module in this section is a modular unit that combines a window division module, spatial cross-attention module, spatial self-attention module, channel cross-attention module, and channel self-attention module. It aims to jointly decode and align the semantic information obtained from network forward propagation with the supplementary information saved from the residual structure. The output features of the module are then transmitted to the deep network for further processing.
The spatial cross-attention component facilitates the exchange of spatial information, establishing internal connections between semantic information and supplementary information from shallow networks, thereby achieving joint encoding in the spatial dimension. By fusing the semantic feature X and the supplementary feature \(F_{r}\), a new feature I is obtained through spatial cross-attention coding, representing the joint encoding of the two types of information. Specifically, the semantic feature X and the supplementary feature \(F_{r}\) are initially mapped to two distinct feature spaces using fully connected layers, resulting in Q, K, V, \(Q_{r}\), \(K_{r}\), and \(V_{r}\) as defined in formula (9).
Using Q, K, V, and \(Q_{r}\),\(K_{r}\),\(V_{r}\), the whole calculation process is shown in the formula (10), where \(lambda _{r}\) is a custom constant.
\(I_s\) is obtained by going through the fully connected layer and normalization, and the calculation process is shown in the formula (11), where \(A_1\) and \(B_1\) are the parameters to be learned.
To enhance the retrieval of contextual information, the output \(I_s\) from the spatial cross-attention module is fed into the spatial self-attention module. Initially, the input feature \(I_s\) undergoes linear mapping to obtain the feature vectors \(Q_s\), \(K_s\), and \(V_s\). These vectors are then used to calculate the self-attention weights. Subsequently, the resulting feature vector \(F_s\) from the spatial self-attention module is further processed by the channel cross-attention module and the channel self-attention module, undergoing a similar fusion process. The entire procedure is represented by formula (12), with \(A_2\) and \(B_2\) denoting the learnable parameters.
4 Experiments
Our experimental evaluation conducted on the widely recognized MS COCO dataset [18] forms the foundation of our study. These findings confirm that our STFormer architecture aligns with, and even surpasses, the performance levels achieved by prevailing and widely adopted backbone structures.
4.1 Object Detection on MS COCO Dataset
In order to verify the effectiveness of the backbone network STFormer, the proposed backbone is combined with CenterNet [8], SR-CenterNet, and MR-CenterNet [9] detection methods, and the hyperparameter settings of all experimental models use the hyperparameters provided by MR-CenterNet. Training uses the adam optimizer with an epochs of 300, a batch size of 16 (on both GPUs), a base learning rate of 0.0005, and a learning rate decay strategy using cosine with a weight decay of 0.05, dropout of 0.1, and warmup epochs of 5. The image was randomly cropped and scaled to a size of 511 \(\times \) 511, while some common data enhancement methods such as color dithering and brightness dithering were applied. During the test, the resolution of the original input image is kept unchanged and filled to a fixed size with zeros before feeding into the network. The detection results are given in the Table 1, and compared with other object detection models, mainly involving DeNet [25], Faster R-CNN [22], Faster R-CNN w/FPN and other models.
The two-stage detection method typically employs a significantly higher number of anchor boxes compared to the one-stage method, leading to more precise detection results at the cost of lower efficiency. While STFormer-SR-CenterNet serves as a one-stage detection method, it exhibits a notable advantage over certain two-stage detection methods such as Faster R-CNN [22], Cascade R-CNN [3], and Cascade Mask R-CNN. However, it still lags behind other two-stage detection methods like Cascade Mask R-CNN+Swin Transformer, GFLV2 [16], and LSNet [30]. It is noteworthy that these methods utilize deep residual networks as backbone networks and employ feature pyramid structures for detecting targets of varying scales. For instance, the GFLV2 network achieves a detection accuracy of 53.3% using the Res2Net-101-DCN backbone, while the LSNet network achieves a detection accuracy of 53.5% using the same backbone. As a one-stage detection method, STFormer-MR-CenterNet leverages a pyramid inference structure, enabling it to outperform Cascade Mask R-CNN - Swin Transformer, GFLV2, and LSNet networks, particularly in detecting small targets. We also found that STFormer has a stronger ability to detect small objects compared to conventional networks. In the detection based on the MS COCO dataset, we compared the performance difference between Hourglass and STFormer. When compared to various one-stage detection methods including RetinaNet [17], RefineDet [28], CornerNet [14], ExtremeNet [32], CenterNet [8], SR-CenterNet [9], CentripetalNet [7], and MR-CenterNet, the STFormer method exhibits clear advantages across all evaluation criteria. The table highlights these advantages, showing that when the STFormer backbone network proposed in this chapter is applied, it achieves a performance improvement of nearly 4% compared to methods that detect key points on a single-resolution feature map, such as CenterNet (Objects as Points) and SR-CenterNet. Additionally, when compared to the method of detecting key points on a feature pyramid structure map, such as MR-CenterNet, the STFormer backbone network proposed in this chapter outperforms Res2Net-101-DCN, which also employs a feature pyramid structure, by 0.6%. These results emphasize the superior performance of the STFormer method in enhancing detection accuracy.
5 Conclusion
This paper introduces STFormer, a novel feature extraction network that leverages joint modeling and multi-dimensional feature fusion technology to integrate low-level and high-level features, as well as global and local information. This approach significantly enhances the accuracy of detection algorithms, particularly in small target detection scenarios. By employing encoders to process high semantic features and preserving high-resolution target details through pipelines, followed by feature fusion using decoders at different levels, the model facilitates information exchange. Furthermore, attention and convolution mechanisms are utilized to extract comprehensive global and local information, resulting in a comprehensive model that improves detection accuracy and efficiency. Compared to mainstream detection networks, the combination of MR CenterNet and STFormer achieves superior results on both the PASCAL VOC and MS COCO datasets. Ablation experiments clearly demonstrate the performance of the three modules, supported by graphs and data visualization. The results illustrate the significant improvement in detection accuracy achieved by the proposed modules.
References
Bao, H., et al.: UniLMv2: pseudo-masked language models for unified language model pre-training. In: International Conference on Machine Learning, pp. 642–652. PMLR (2020)
Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M.: YOLOv4: optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020)
Cai, Z., Vasconcelos, N.: Cascade R-CNN: delving into high quality object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6154–6162 (2018)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. arXiv preprint arXiv:2005.12872 (2020)
Chi, C., Wei, F., Hu, H.: RelationNet++: bridging visual representations for object detection via transformer decoder. Adv. Neural. Inf. Process. Syst. 33, 13564–13574 (2020)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
Dong, Z., Li, G., Liao, Y., Wang, F., Ren, P., Qian, C.: CentripetalNet: pursuing high-quality keypoint pairs for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10519–10528 (2020)
Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., Tian, Q.: CenterNet: keypoint triplets for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6569–6578 (2019)
Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., Tian, Q.: CenterNet++ for object detection. arXiv preprint arXiv:2204.08394 (2022)
Ghiasi, G., Lin, T.Y., Le, Q.V.: NAS-FPN: learning scalable feature pyramid architecture for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7036–7045 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708 (2017)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2012)
Law, H., Deng, J.: CornerNet: detecting objects as paired keypoints. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 734–750 (2018)
Li, R., Zheng, S., Duan, C., Su, J., Zhang, C.: Multistage attention ResU-Net for semantic segmentation of fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2021)
Li, X., Wang, W., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss V2: learning reliable localization quality estimation for dense object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11632–11641 (2021)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Lin, T.-Y., et al.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Liu, Z., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10012–10022 (2021)
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems, pp. 91–99 (2015)
Sun, C., Shrivastava, A., Singh, S., Gupta, A.: Revisiting unreasonable effectiveness of data in deep learning era. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 843–852 (2017)
Tan, M., Pang, R., Le, Q.V.: EfficientDet: scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10781–10790 (2020)
Tychsen-Smith, L., Petersson, L.: DeNet: scalable real-time object detection with directed sparse sampling. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 428–436 (2017)
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492–1500 (2017)
Yuan, L., et al.: Tokens-to-token ViT: training vision transformers from scratch on ImageNet. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 558–567 (2021)
Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S.Z.: Single-shot refinement neural network for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4203–4212 (2018)
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing through ADE20K dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 633–641 (2017)
Zhou, W., Zhu, Y., Lei, J., Yang, R., Yu, L.: LSNet: lightweight spatial boosting network for detecting salient objects in RGB-thermal images. IEEE Trans. Image Process. 32, 1329–1340 (2023)
Zhou, X., Wang, D., Krähenbühl, P.: Objects as points. arXiv preprint arXiv:1904.07850 (2019)
Zhou, X., Zhuo, J., Krahenbuhl, P.: Bottom-up object detection by grouping extreme and center points. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 850–859 (2019)
Acknowledgment
Project supported by the National Natural Science Foundation of China (No. 62072333).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Wang, S., Chen, R., Guo, T., Feng, Z. (2024). STFormer: Cross-Level Feature Fusion in Object Detection. In: Luo, B., Cheng, L., Wu, ZG., Li, H., Li, C. (eds) Neural Information Processing. ICONIP 2023. Communications in Computer and Information Science, vol 1967. Springer, Singapore. https://doi.org/10.1007/978-981-99-8178-6_40
Download citation
DOI: https://doi.org/10.1007/978-981-99-8178-6_40
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8177-9
Online ISBN: 978-981-99-8178-6
eBook Packages: Computer ScienceComputer Science (R0)