
Abstract
The study’s main objective is to develop a ROS compatible local planner and controller for autonomous mobile robots based on reinforcement learning. Reinforcement learning based local planner and controller differs from classical linear or nonlinear deterministic control approaches using flexibility on newly encountered conditions and model free learning process. Two different reinforcement learning approaches are utilized in the study, namely Q-Learning and DQN, which are then compared with deterministic local planners such as TEB and DWA. Q-Learning agent is trained by positive reward on reaching goal point and negative reward on colliding obstacles or reaching the outer limits of the restricted movable area. The Q-Learning approach can reach an acceptable behaviour at around 70000 episodes, where the long training times are related to large state space that Q-Learning cannot handle well. The second employed DQN method can handle this large state space more easily, as an acceptable behaviour is reached around 7000 episodes, enabling the model to include the global path as a secondary measure for reward. Both models assume the map is fully or partially known and both models are supplied with a global plan that does not aware of the obstacle ahead. Both methods are expected to learn the required speed controls to be able to reach the goal point as soon as possible, avoiding the obstacles. Promising results from the study reflect the possibility of a more generic local planner that can consume in-between waypoints on the global path, even in dynamic environments, based on reinforcement learning.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- q-learning
- deep reinforcement learning
- DQN (deep q-learning)
- ROS (robot operating system)
- navigation
- local planner
1 Introduction
In recent years, Autonomous Mobile Robots (AMR) have started to be preferred to improve operational efficiency, increase speed, provide precision, and increase safety in many intralogistics operations, like manufacturing, warehousing, and hospitals [1]. AMRs are a type of robot that can understand its environment and act independently. In order for AMR to understand the environment and act independently, it must know where it is and how to navigate. This topic has attracted the attention of many researchers and various methods have been proposed. One of the most widely accepted and used methods today is to first map the environment and use this map for localization and navigation. Localization and mapping play a key role in autonomous mobile robots. Simultaneous localization and mapping (SLAM) is a process by which a mobile robot can build a map of an unknown environment using sensors which perceive the environment and at the same time use this map to deduce its location [2]. For this task, sensors such as cameras, range finders using sonar, laser, and GPS are widely used. Localization can be defined as the information of where the robot is on the map. Localization information can be obtained from the wheel odometer. But the error in the wheel odometer is incremental over time [3]. Therefore, robot position can be found with triangulation formula by using beacon [4] or reflector [3]. In addition, it is possible to improve the position with object detection using a depth camera [5] or by matching the measurements taken from the real environment with the map using lidar sensors. Navigation can be defined as the process of generating the speed commands necessary for a robot to reach a destination successfully. The navigation methods for mobile robots can roughly be divided into two categories: global planner and local planner. Global planner methods such as A*, Dijkstra and Rapidly exploring Random Tree (RRT) aim to find a path consisting of free space between start and goal. The second submodule in navigation is a local planner. Local planner methods such as Artificial Potential Field, Dynamic Window Approach (DWA), Time Elastic Band (TEB) and Model Predictive Control (MPC) aim to create the necessary velocity commands to follow the collision free trajectory that respects the kinematic and dynamic motion constraints.
In the last decade, Reinforcement Learning (RL) methods have been used for navigation [6, 7] RL is an area of machine learning concerned with how agents take actions in an environment by trial and error to maximize cumulative rewards [8]. Many methods such as Value Function, Monte Carlo Methods, Temporal Difference Methods, and Model-based algorithms have been proposed to maximize the cumulative rewards for agents. Q-learning learning proceeds similarly to method of temporal differences (TD) is a form of model-free reinforcement learning [9]. However, since these models are insufficient in the complexity of the real world, more results are obtained with deep learning-based reinforcement learning methods such as Deep Q-Network (DQN) [1, 10]. In this study, a new local planner method called dqn_local_planner is proposed using the DQN algorithm. For DQN algorithm, a fully connected deep-network is used to generate velocity data for autonomous mobile robots using laser field scanner data, robot position and global path after a series of preprocessing. ROS framework, gazebo simulation and gym environment are used for model training and testing. To compare the proposed model with teb_local_planner and dwa_local_planner, static and dynamic environments are created in the gazebo. The paper is structured as follows: in Sect. 2, algorithms used for proposed method and comparison are mentioned, the explanation of proposed method is mentioned in Sect. 3, the experimental environment set up to test the model is mentioned in Sect. 4, the results obtained and the evaluation of the results are mentioned in Sect. 5 and a general evaluation is made in Sect. 6.
2 Methodology
2.1 Time Elastic Band
Time Elastic Band (TEB) is a motion planning method for local navigation. The classic ‘elastic band’ is described as a sequence of \(n\) intermediate robot poses. TEB is augmented by the time that the robot requires to transit from one configuration to the next configuration in sequence. Its purpose is to produce the most ideal velocity command for mobile robots by optimizing both the configuration and the time interval with weighted multi-objective optimization in real-time considering the kino-dynamic constraints such as velocity and acceleration limits. The objective function is defined as in Eq. (1), in which \(\gamma \) denotes weights and \({f}_{k}\) denotes the constraints and objectives with respect to trajectory such as obstacle and fastest path.
The \({f}_{k}\) are generalized in TEB as in Eq. (2), in which \({x}_{\mathfrak{r}}\) denotes the bound, \(S\) denotes the scaling and \(n\) denotes the polynomial order and \(\epsilon \) denotes the small translation of the approximation.
2.2 Dynamic Window Approach
Dynamic Window Approach (DWA) aims to find the ideal velocity \((v,w)\) search space containing the obstacles-safe areas under the dynamic constraints of the robot and find the maximum velocity in this space using objective function. To get the velocity search space, circular trajectories (curvatures) consisting of pairs \(\left(v,w\right)\) of translational and rotational velocities are determined. Then, this space is constrained by the admissible velocity at which it can stop without reaching the closed obstacle on the corresponding curvature. Finally, this space is constrained by the dynamic window which restricts the admissible velocities to those that can be reached within a brief time interval given the limited accelerations of the robot. The objective function as shown in Eq. (3) is maximized.
The target heading, \(heading\left(v,w\right)\), measures the alignment of the robot with the target direction. It is maximal if the robot moves directly towards the target. The clearance, \(dist\left(v,w\right)\), is the distance to the closest obstacle that intersects with curvature. \(vel\left(v,w\right)\) Function represents the forward velocity of robot.
2.3 Deep Q-Network
DQN is one of the methods of learning optimum behavior by interacting with environment by taking action, observing the environment, and rewarding. In general, observation at time \(t\) does not summarize the entire process, so previous observations and actions also should be included in the process. In DQN method, sequences of actions and observations, \({s}_{t}={x}_{1},{a}_{1},{x}_{2},\colon\colon :{a}_{t-1},{x}_{t}\) are included as inputs. The agent’s goal is to choose actions that will maximize future rewards as shown in Eq. (4), in which \(T\) is the time-step and \(\gamma \) is the discounted factor.
The optimal action-value function \({\mathcal{Q}}^{*}(s,a)\) allows us to determine the maximum reward we get when we take action a while in state \(s\). The optimal action-value function can be explained as Eq. (5) with the Bellman equation.
This can be obtained by iterative methods such as the value iteration algorithms, but it is impractical. It is more common to estimate the action-value function \(\mathcal{Q}\left(s,a;\theta \right)\approx {\mathcal{Q}}^{*}\left(s,a\right)\) usually using linear function approximators and sometimes nonlinear approximators instead, such as neural network. Neural network function approximator with weights \(\theta \) is used as Q-network. However, nonlinear approximators may cause reinforcement learning to be unstable or even to diverge. As a solution to this, replay memory is used that updates iteratively the target values periodically towards action-values \(\mathcal{Q}\). Deep Q-learning with experience replay algorithm can be given as follows:

3 Proposed Method
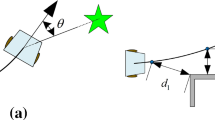
This study proposes a new local planner for Mobile Robots using the DQN method. The state space consists of 14 values. The continuous state space that consists of sensor measurements and robot-path measures is sampled at a certain resolution to obtain a discrete state space. One of the state space parameters is the angle difference as shown in Fig. 1a. The vector passing from the intermediate point as far as the lookahead distance of global path and robot’s position is obtained. The angle difference (\(\theta \)) is the difference between this vector and robot angle. The resolution of the angle difference is 0.35 rad. The second is the distance (\(L\)) of the robot to its closest point on the global path as shown in Fig. 1b the resolution of the distance is 0.2 m.

Two of the state space parameters a) angle difference between lookahead distance and robot heading, b) the distance (L) of the robot to its closest point on the global path.
The third is the sensor data obtained from the preprocessed laser scanner. The 360-degree sensor data is divided into 12 sectors as shown in Fig. 2a. The smallest distance data in each sector is a state in the state space as shown in Fig. 2b. The resolution of this distance is determined according to Table 1. Thus, the model is able to review its decisions more precisely as it gets closer to the obstacle.

a) sector tiling around the robot, b) smallest distances of laser data on each sector
3 actions have been determined for our model. Go forward at 1 m/s linear velocity, slowly turn right at −0.5 rad/s angular velocity and 0.3 m/s linear velocity, slowly turn left at 0.5 rad/s angular velocity and 0.3 m/s linear velocity. Our agent is rewarded with an inverse ratio to the closest distance to the global path, an inverse ratio to the angular difference and a reward if the robot reaches the goal. However, a negative reward is given if it is 3m away from the global path, if it got too close to the obstacle or if the angle difference was more than 2.44 rad. Expect for the first two rewards, the episode ends in other positive/negative reward cases. There are 3 fully connected layers with a rectified linear activation function in our network used for DQN agent. These layers consist of 64, 128, 32 and 3 output layers neurons as shown in Fig. 3.

Network architecture of DQN agent
4 Experimental Setup
The experiment is carried out in a simulation environment. Gazebo, an open-source robotic simulator, is chosen to simulate the environment. Turtlebot3 is chosen for mobile robot. The Turtlebot3 robot is both physically available and has a model in the gazebo environment. It is also compatible with the Robot Operating System (ROS). ROS, which we also use as our experimental setup, is a widely used open-source software for mobile robots. It allows complex algorithms developed for topics that form the basis of robotics such as mapping, localization, navigation used in robots to communicate with each other. In our study, we used ‘gmapping’ for mapping, ‘amcl’ for localization and ‘move_base’ for navigation. We used ‘gym’, the standard API for reinforcement learning, to observe the environment and determine the next action. We used the ‘keras’ library for model training. DQN was used as the reinforcement learning model.
In gazebo environment, a (1, 3, 1) size box is placed in the center of the empty space as an obstacle. In each episode, the robot starts from the point (−3.9, 0) and is expected to navigate to the goal at (3, 0). In this way, DQN model is trained for about 5000 episodes. At the end of 5000 episodes, it is observed that the robot mostly navigates to the goal point. As the second stage, the location of the obstacle and goal point is changed in each episode. The obstacle is randomly generated between (−0.5, 0.5) on the x-axis and (−2, 2) on the y-axis. Path given to system as a global path is the straight line between the start point and the target point with 0.2 m waypoints. In this way, the model is trained for about 5000 more episodes. The trained model is integrated into ROS as local planner with the name dqn_local_planner. Scenarios in Table 2 are created to test our model and to compare it with teb_local_planner and dwa_local_planner.

2D representation of a) scenario 1, b) scenario 2, c) scenario 3, d) scenario 4
To compare the local planners, the number of times the goal is successfully achieved, the total execution time and the sum of absolute areas between the planned path and the executed path metrics are used. Experiments are repeated 5 times. Reaching a 0.2 m radius circle with the goal in the center is classified as an achieved goal. Final heading angle is not considered.
5 Results and Discussion
The graph in Fig. 5 depicts the reward during the training of our model. The model is trained in 10050 episodes. At around episode 4000, our model has learned to go to a fixed goal in a static environment. Then the obstacles and the goal point are randomly generated in a large area and the model is trained for about 2000 more episodes. The drop on reward observed around episode 5000 is due to change in policy, but the robot quickly adapts to the unfamiliar environment. During the training, it is also observed that there was usually no obstacle between the robot and its goal. So, this area is narrowed. Therefore, the model training decreased again after around episode 6000, but the robot quickly adapts again. It is observed that the model success does not increase after around episode10050, so the model training is terminated here.

Cumulative reward graph of proposed model
In the figures below, the blue line represents the global path, green arrows represent the robot’s movement and red dots represent the laser sensor readings from the obstacle. Within the scope of scenario 1, the robot is given (4, 0) as goal point. The scenario is repeated 5 times. As shown in Fig. 6a and Fig. 6b, teb_local_planner and dwa_local_planner respectively, fails to pass the obstacle in any of the trials.teb_local_palnner and dwa_local_planner can trigger the move_base to recalculate the path in the case of suddenly encountering an obstacle, however DQN does not have this feature. Normally, there is a parameter in the ROS navigation stack for the global planner to detect dynamic obstacles as well. But here we have turned off that parameter to observe the performance of the pure local planner. As shown in Fig. 6c, the dqn_local_planner reaches the goal in an average of \(33.59\mp 3.468 \) s. The robot has moved in an average of \(12.032\mp 1.121\) m away from its path during its entire movement. After passing the obstacle in each attempt, it does not immediately enter the path and goes directly to the goal point.

Scenario 1b results for a) teb_local_planner, b) dwa_local_planner, c) dqn_local_planner
However, as shown in Fig. 7a, when the goal point is given as (2, 0), the robot could not reach the goal in all trials. If the projection of the robot’s position to the path at any time becomes the goal point, it cannot reach the goal. When the goal point is given as (11, 0) as shown in Fig. 7b, the dqn_local_planner reaches the goal in an average of \(57.395\mp 1.492\) s. The robot has moved an average of \(14.18\mp 1.876\) m away from its path during its entire movement. The robot enters the path after passing the obstacle and continues to follow the path. In one of the experiments, the robot passed the goal without reaching the goal, so the experiment was terminated.

dqn_local_planner behaviours for a) scenario 1a, b) scenario 1c
In scenario 2, the target is given when the obstacle is in various positions. The local path differs because the obstacle was a moving object as shown in Fig. 8a and Fig. 8b. The dqn_loca_planner reached the target with an average of \(38.88\mp 11.040\) s. The robot has moved an average of \(13.07\mp 16.86\) m away from its path during its entire movement. It encounters an obstacle once and the alternative path cannot be reproduced. After the obstacle moves away from the robot, the robot continues its path as shown in Fig. 8c.

dqn_local_planner behaviours from different runs for scenario 2 when obstacle is encountered at, a) \(y>0\), b) \(y\cong 0\), c) \(y<0\)
As shown in Fig. 9a, the teb_local_planner reaches the goal in an average of \(25.9\mp 1.1\,\text{s}\). The robot has moved an average of \(1.71\mp 0.244\) m away from its path during its entire movement. When an obstacle is in front of the Robot, teb_local_planner waits until it gets out of the way. After the obstacle is removed, it continues its movement. As shown in Fig. 9b, the dwa_local_planner reaches the goal in an average of \(25.13\mp 4.995\,\text{s}\). The robot has moved an average of \(1.41\mp 1.374\) m away from its path during its entire movement. DWA waits when an obstacle is in front of it and continues after it is removed. However, while the obstacle is moving towards the robot from the side of the robot, it cannot react adequately, and the obstacle hits the robot.

Scenario 2 behaviours for, a) teb_local_planner, b) dwa_local_planner
In scenario 3, the teb_local_planner and dwa_local_planner could not pass the obstacle as in the first scenario. As shown in Fig. 10, the dqn_local_planner reached the goal in an average of \(49.23\mp 0.959\,\text{s}\). The robot has moved an average of \(22.02\mp 5.17\) m away from its path during its entire movement. Dqn_local_planner can easily pass slower objects in the same direction.

Scenario 3 behaviour of dqn_local_planner.
Scenario 4 gave equivalent results to scenario 3. Thanks to the robot dqn_local_planner, it easily passed an obstacle coming towards it with a speed of 0.1 m/s.
To summarize the outputs of all scenarios, although teb_local_planner and dwa_local_planner give much better results when there are no obstacles or small obstacles on the path, dqn_local_planner gives better results if there are large obstacles on the robot’s path. However, in the current model, if the robot accidentally passes the goal point while following the path, it is exceedingly difficult to return and reach the goal point again. It is usually stuck at the local minimum point as shown in Fig. 7a. The robot may also not take the shortest path while avoiding obstacles. If the robot is too close to the obstacle, it waits until the obstacle disappears and continues its movement. If the obstacle moves to the right in the y-axis forever and the robot encounters the obstacle, if it turns to pass to the right of the obstacle in the first step, they will go together forever in this way. The robot prefers not to go left at any given moment. Table 3 summarizes the result of DQN based local planner, when five tests are carried out for each scenario, by means of successful navigations, path execution times and error measure about the area between planned and executed paths.
6 Conclusion
In conclusion, a new method developed with DQN, which is a reinforcement learning method, is proposed for the local planner. In this method, the environment is first taught to the robot by using sensor data, robot location and global path. For testing the model, fixed, and moving (toward the robot, moving away from the robot, moving vertically) objects that are not in the environment map are added and it is observed whether the robot could reach the goal by avoiding obstacles. The same experiments are also performed with TEB and DWA. To test the performance of the pure local planner, the obstacles that are subsequently introduced into the environment are not added to the global path. While TEB and DWA planners are not successful in avoiding obstacles, our model is able to pass the obstacle easily in all scenarios. If the model does not learn the entire space, local minimum points may occur. In addition, if the robot and the obstacle start parallel movement in the same direction and at a similar speed, they will move together forever. However, our current model is trained in a specific environment and so works in a small world. More complex environments can be selected for training in later models. The action space of our model is also exceedingly small. It includes forward, turn right, and turn left actions. A subspace of each action can be created with a certain resolution. Moreover, only a fully connected network is used in our model. While teaching more complex spaces, training can be continued with networks such as Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM) network. As another future work it is planned also to include the dynamic objects’ direction and speed values in the state space, in order to enable the robot to learn not to move in a crossing path with the dynamic object and let the robot move away from the obstacle in an efficient way.
References
Fragapane, G., De Koster, R., Sgarbossa, F., Strandhagen, J.O.: Planning and control of autonomous mobile robots for intralogistics: literature review and research agenda. Eur. J. Oper. Res. 294, 405–426 (2021)
Durrant-Whyte, H., Bailey, T.: Simultaneous localization and mapping: part I. IEEE Robot. Autom. Mag. 13, 99–110 (2006)
Betke, M., Gurvits, L.: Mobile robot localization using landmarks. IEEE Trans. Robot. Autom. 13, 251–263 (1997)
Leonard, J.J., Durrant-Whyte, H.F.: Mobile robot localization by tracking geometric beacons. IEEE Trans. Robot. Autom. 7, 376–382 (1991)
Biswas, J., Veloso, M.: Depth camera based indoor mobile robot localization and navigation. In: 2012 IEEE International Conference on Robotics and Automation (2012)
Ruan, X., Ren, D., Zhu, X., Huang, J.: Mobile robot navigation based on deep reinforcement learning. In: 2019 Chinese Control and Decision Conference (CCDC) (2019)
Heimann, D., Hohenfeld, H., Wiebe, F., Kirchner, F., Quantum deep reinforcement learning for robot navigation tasks, arXiv preprint arXiv:2202.12180 (2022)
François-Lavet, V., Henderson, P., Islam, R., Bellemare, M.G., Pineau, J., et al.: An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 11, 219–354 (2018)
Watkins, C.J.C.H., Dayan, P.: Q-learning. Mach. Learn. 8, 279–292 (1992)
Mnih, V., et al.: Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Küçükyılmaz, M., Uslu, E. (2024). ROS Compatible Local Planner and Controller Based on Reinforcement Learning. In: Şen, Z., Uygun, Ö., Erden, C. (eds) Advances in Intelligent Manufacturing and Service System Informatics. IMSS 2023. Lecture Notes in Mechanical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-99-6062-0_37
Download citation
DOI: https://doi.org/10.1007/978-981-99-6062-0_37
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-6061-3
Online ISBN: 978-981-99-6062-0
eBook Packages: EngineeringEngineering (R0)