
Abstract
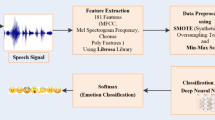
This paper describes improved research on speech emotion recognition (SER) systems. The definition, classification of the state of emotions and the expressions of emotions are introduced theoretically. In this research article, a SER system based on the CNN classifier and MFCC feature extraction are developed. Mel Frequency Cepstral Coefficients (MFCC) are excerpted from audio signals that are accustomed to train various classifiers. All seven emotions were categorized using a convolutional neural network (CNN). Surrey Audio Visually Expressed Emotion (SAVEE), Ryerson Affective Speech and Song Audiovisual Database (RAVDESS), Toronto Affective Speech Set (TESS), Crowdsourced Affective Multimodal Actor Dataset (CREMA-D) databases were used as experimental datasets. This study shows all four datasets using the CNN classifier. With 1D-CNN, the overall emotion recognition accuracy is 43%, the gender recognition accuracy is 81%, and the gender-neutral recognition accuracy of emotions is 48%. Using 2D-CNN, the overall accuracy rate for emotion recognition is 67.58%, the accuracy rate for gender recognition is 98%, and the accuracy rate for non-gender recognition of emotions is 65%.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
New TL, Foo SW, De Silva LC (2003) Speech emotion recognition using hidden Markov models. Speech Commun 41(4): 603–623
El Ayadi M, Kamel MS, Karray F (2011) Survey on speech emotion recognition: features, classification schemes, and databases. Pattern Recognit 44(3):572–587
Byun S, Lee S (2016) Emotion recognition using tone and tempo based on voice for IoT. Trans Korean Inst Electr Eng 65(1):116–121. https://doi.org/10.5370/kiee.2016.65.1.116.
Hong I, Ko Y, Kim Y, Shin H (2019) A study on the emotional feature composed of the mel-frequency cepstral coefficient and the speech speed. J Comput Sci Eng 13(4):131–140. https://doi.org/10.5626/JCSE.2019.13.4.131
Likitha MS, Gupta SRR, Hasitha K, Raju AU (2017) Speech based human emotion recognition using MFCC. In: 2017 International conference on wireless communications, signal processing and networking (WiSPNET), pp 2257–2260. https://doi.org/10.1109/WiSPNET.2017.8300161
Park S, Kim D, Kwon S, Park N (2018) Speech emotion recognition based on CNN using spectrogram. In: Information and control symposium, pp 240–241
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556
Deng J, Dong W, Socher R, Li L, Li K, Fei-Fei L (2009) Image-Net: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition (CVPR), pp 248–255. https://doi.org/10.1109/CVPR.2009.5206848
Lee J, Yoon U, Jo G (2020) CNN-based speech emotion recognition model applying transfer learning and attention mechanism. J KIISE 47(7):665–673. https://doi.org/10.5626/JOK.2020.47.7.665
Livingstone SR, Russo FA (2018) The Ryerson audio-visual database of emotional speech and song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English. PLoS One 13(5):e0196391. https://doi.org/10.1371/journal.pone.0196391
Tang W, Long G, Liu L, Zhou T, Jiang J, Blumenstein M (2020) Rethinking 1D-CNN for time series classification: a stronger baseline. arXiv: 2002.10061
Mao Q, Dong M, Huang Z, Zhan Y (2014) Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans Multimed 16:2203–2213. https://doi.org/10.1109/TMM.2014.2360798
Huang L, Dong J, Zhou D, Zhang Q (2020) Speech emotion recognition based on three-channel feature fusion of CNN and BiLSTM. In: 2020 the 4th international conference on innovation in artificial intelligence (ICIAI), pp 52–58. https://doi.org/10.1145/3390557.3394317
https://www.kaggle.com/datasets/barelydedicated/savee-database
Yoon S, Byun S, Jung K (2018) Multimodal speech emotion recognition using audio and text. In: 2018 IEEE spoken language technology workshop (SLT). https://doi.org/10.1109/SLT.2018.8639583
https://www.kaggle.com/datasets/ejlok1/toronto-emotional-speech-set-tess
https://www.kaggle.com/datasets/uwrfkaggler/ravdess-emotional-speech-audio
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mergu, R.R., Shelke, R.J., Bagade, Y., Walchale, P., Yemul, H. (2023). Speech Emotion Recognition Using Machine Learning. In: Tuba, M., Akashe, S., Joshi, A. (eds) ICT Systems and Sustainability. ICT4SD 2023. Lecture Notes in Networks and Systems, vol 765. Springer, Singapore. https://doi.org/10.1007/978-981-99-5652-4_12
Download citation
DOI: https://doi.org/10.1007/978-981-99-5652-4_12
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-5651-7
Online ISBN: 978-981-99-5652-4
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)