
Abstract
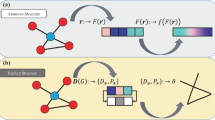
The development of experimental and simulation technologies has afforded us access to material science data on a more massive scale than that in the past. For such large-scale data on various materials, effective and efficient analysis methods have been developed using applied mathematics and data science. For analyzing structural order, statistical analysis approaches based on chemical bonding are used. This approach can evaluate the structural order on a short-range scale. However, it cannot analyze structural order on the scale over the length of the chemical bonding referred to as the intermediate range, which is essential for understanding amorphous or glassy materials. This chapter introduces two useful characterization approaches based on applied mathematics for a geometric structure, which are useful to identify hyperordered structures in intermediate-range scale. The first approach is based on the topological structure of an atomic configuration (or point cloud) based on persistent homology. The second approach is based on the network topology of chemically bonded atoms based on rings. This chapter introduces the applied analyses of amorphous materials using these methods.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
The development of experimental and simulation technologies has afforded us access to material science data on a more massive scale than that in the past. For such a large-scale data on various materials, effective and efficient analysis methods have been developed using applied mathematics and data science. This research area that focuses on developing such analytical methods is referred to as material informatics. It includes methods for efficient data mining from experimental microscopic data [1, 2], material property predictions, and quantitative evaluations of structural orders in disordered materials [3].
The characterization of a material structure is critical for understanding its structural order. A basic chemical characterization approach is based on chemical bonding, wherein coordination numbers (the number of chemical bonds of each atom) and angles of chemical bonds are evaluated statistically. However, the characterization evaluates the structural order only on a short-range scale; the scale over the length of the chemical bonding is referred to as the intermediate range. For amorphous or glassy materials categorized in disordered materials, it is necessary to evaluate the structural order in the intermediate-range scale for understanding the structural and material properties. The conventional approach allows us to conduct a pair distribution function (PDF) analysis that utilizes experimental diffraction measurements for computing the distribution function between atom pairs. However, such an analysis limits the information on the two atoms although the intermediate-range structural order comprises larger units, which include more than three atoms.
This chapter introduces two useful characterization approaches based on applied mathematics for a geometric structure, which are useful to identify hyperordered structures hidden in intermediate-range scale. The first approach is based on the topological structure of an atomic configuration (or point cloud) based on persistent homology [4,5,6]. The second approach is based on the network topology of chemically bonded atoms based on rings [7,8,9,10,11,12]. This chapter introduces the applied analyses of amorphous materials using these methods.
The above-mentioned characterizations are useful for investigating how these structures correlate with the physical parameters and properties of materials. The quantitative characterizations of the structural order can be used as inputs (or descriptors) of machine learning models for predicting material properties expected to be more effective than direct inputs of microscopic images or atomic configurations in many cases. In addition, prediction models based on these descriptors are more interpretable than the direct inputs for understanding the relationship between the structural order and material properties.
2 Persistence Homology
In this section, we introduce persistent homology (PH) [4,5,6], which is an emerging data analysis method based on the mathematical concept of topology. PH allows us to characterize the shape of data at multiple scales using topological structures such as holes, rings, and hollows. Further, PH is widely applied in various scientific research fields such as network systems [13], life science [14,15,16], geology [17], medical image analysis [18], and materials science [19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36].
2.1 Foundation of PH
As the first example, we consider a point cloud (a collection of data points) as shown in Fig. 11.1a. The point cloud shown in Fig. 11.1a has no rings because all points are separated; however, it appears to have two rings because of the proximity of the points. Discs are placed on all points whose radii are the same to construct topological structures on the data; the rings appeared on the points as shown in Fig. 11.1b–e. We can count the number of rings in these figures using the mathematical theory of topology.
Here, we focus on the problem of determining the radii r. The number of rings changes with changes in the radii, and the fundamental idea of PH is to examine the changing process in the topology as radii change. The radii r is gradually increased from 0, as shown in Fig. 11.1a–e. From the left to the right, a ring X appears at \(r = b_1\), and another ring Y appears at \(r = b_2\). The ring Y disappears at \(r = d_2\) as its interior fills up, and finally, X disappears at \(r = d_1\). The theory of PH makes pairs of appearance and disappearance of rings; in this example, \((b_1, d_1)\) and \((b_2, d_2)\) are paired together. The radii when a ring appears and disappears are referred to as the birth time and death time, respectively; the pairs of birth and death times are referred to as birth-death pairs. The collection of birth-death pairs is called a persistence diagram (PD), and it is visualized using a scatter plot (Fig. 11.1f) or 2D histogram. Intuitively, the birth time contains information about the density of the points on the ring, and the death time contains information about the size of the ring. The information on the two ring structures shown in Fig. 11.1a is summarized in the two birth-death pairs. We remark that the PH community often uses the squares of radii instead of radii, as indicated in Fig. 11.1f, where radii \(b_1, b_2, d_1,\) and \(d_2\) are squared. We also follow this convention.

Persistence diagram. a Input point cloud; b Point cloud with discs of radii \(r = b_1\); c \(r = b_2\); d \(r = d_2\); e \(r = d_2\); f Persistence diagram
2.2 Mathematical Idea
In the above-mentioned example, we need to identify the rings shown in Fig. 11.1a–e. Although identifying the rings seems to be an easy task, this is not the case. The basic mathematical theory for a deeper understanding of PH is worth discussing.
We counted the number of rings in Fig. 11.2a, which is a regular tetrahedron without faces. How do we count the number of rings in the figure? The figure has four triangles, and therefore, it seems to have four rings; however, when this figure is viewed from above, the number of rings appears to be three (Fig. 11.2b). The theory of homology, which is a part of the topology theory, provides a solution to the problem using linear algebra. The homology theory states that (4) = (1) + (2) + (3), which means that the four rings (1), (2), (3), and (4) in Fig. 11.2c are linearly dependent, and the number of linearly independent rings is three, not four. This idea solves the ambiguity of counting the rings.

a Tetrahedron without faces; b View of a from top; c Four linearly dependent rings
Further, the homology theory computes the number of hollows (cavities). A tetrahedron with four faces has one hollow interior. In homology theory, rings are classified as one-dimensional holes, and hollows are classified as two-dimensional holes. Therefore, the homology theory states that a tetrahedron with faces has one 2D hole. Table 11.1 summarizes the number of holes.
PH can be applied to 3D data using balls instead of discs. Rings and hollows appear and disappear when the radii of the balls are increased gradually. We can capture the pairs of appearance and disappearance of rings (1D holes) and hollows (2D holes) using the PH theory; this information is summarized in a 1D PD and a 2D PD.
2.3 Toy Examples
It is worthwhile to examine the PD for simple examples before applying PH to real data. To this end, we consider regular tetrahedral and octahedral point clouds as examples (Fig. 11.3). The distance between the two nearest points is denoted by a.

Regular tetrahedral and octahedral point clouds and their PDs. The numbers on PDs indicate the multiplicities of the birth-death pairs. a Regular tetrahedral point cloud; b 1D PD of the tetrahedral point cloud; c 2D PD of the tetrahedral point cloud; d Regular octahedral point cloud; e 1D PD of the octahedral point cloud; f 2D PD of the octahedral point cloud
The three birth-death pairs at \((a^2/4, a^2/3)\) in Fig. 11.3b correspond to the three regular triangles of the tetrahedron. The birth and death times are determined as shown in Fig. 11.4. The ring appears at \(r = a/2\) and disappears at \(r = a/\sqrt{3}\); the squared values are used for the PDs. The multiplicity of the birth-death pairs in Fig. 11.3b is three instead of four because the four triangular rings in Fig. 11.2a are not linearly independent, as explained in Sect. 11.2.2. The birth-death pair at \((a^2/3, 3a^2/8)\) in Fig. 11.3c corresponds to a hollow tetrahedron (Fig. 11.3a). The hollow appears at \(r = a/\sqrt{3}\) when the balls fill all faces of the tetrahedron; it disappears at \(r = a\sqrt{3/8}\) when the balls fill its internal structure. The birth and death times are identical to (the square of) the circumradius of the faces of the tetrahedron and the circumradius of the tetrahedron, respectively.

Birth and death of a ring in the regular triangular point cloud
Figure 11.3d shows eight regular triangular rings and one regular tetragonal ring, but 1D PD (Fig. 11.3e) has only seven birth-death pairs. The seven pairs correspond to the seven triangles of the octahedron. The 1D PD does not contain information on one triangular or tetragonal ring because of the linear independence rule. This rule tends to make PDs count fewer rings than that when using other methods. The birth-death pair at \((a^2/3, a^2/2)\) in Fig. 11.3f corresponds to the hollow in the octahedron. The birth and death times are determined in a manner similar to that in the tetrahedron example.
2.4 Toward Applications in Materials Science
PH is currently used to investigate the structures of various materials such as granular materials [21], network formers [19, 20], metallic glass [22, 23], and polymers [24, 25, 36]. To apply PH, the atomic configurations or particle positions are considered as point clouds.
One important issue in materials science is to explain the physical properties of materials based on their structures. To this end, we quantify the geometric structures of the materials; in other words, appropriate descriptors are required.
Thus far, various descriptors have been proposed to analyze totally ordered structures such as crystals, and these descriptors are effective. Mathematical theories such as the Fourier analysis and group theory effectively describe such periodic structures. Other types of descriptors that use statistical information work efficiently for analyzing totally disordered structures such as gases. The probabilistic theory and mathematical models are used to describe totally disordered systems.
This approach has been successful for these two extremes; however, it is difficult to find appropriate descriptors for intermediately disordered systems such as amorphous systems because it is difficult to quantify complex systems. PDs can be used as descriptors of such intermediately disordered structures, and the topology theory from mathematics can help describe such structures.
From a practical point of view, we compare PH with conventional methods such as radial distribution functions, ring statistics, and Voronoi analysis. The following list illustrates the advantages of PDs over other descriptors:
-
1.
Ability to encode multiscale geometric structures
-
2.
Ability to capture the relationship of many bodies
-
3.
Robustness to noise
-
4.
Interpretability
Considering the increasing number of balls, we can encode the information of multiscale geometric structures in PDs. Further, we can describe the diversity of the target complex system as a distribution of birth-death pairs on PDs. The radial distribution function has this feature; however, it does not have the second feature.
PH considers rings or hollows, and therefore, it can summarize many-body relationships easily. This is advantageous over the radial distribution function, which is sufficiently effective for describing crystalline and liquid structures but unsatisfactory for analyzing complex structures such as amorphous structures.
Robustness to noise is another important feature of PDs. Conventional methods such as Voronoi analysis and ring statistics provide discrete outputs; therefore, the output is sensitive to noise. In contrast, the effect of noise on the PD is mathematically formalized, and therefore, robustness to noise is ensured.
One other advantage of PH is interpretability. PH has a useful feature called inverse analysis, which can identify the ring or hollow corresponding to each birth-death pair. Inverse analysis helps understand the analysis by PH, which is a functionality that is well utilized in the following applications.
It is difficult to find a descriptor with all the above features, which is a significant advantage of PDs. The first two features make PD useful as a descriptor for intermediately disordered systems, and the last two features make it easy to use.
2.5 Data Analysis Using HomCloud
This subsection aims to learn the procedure for analyzing atomic configuration data using HomCloud [37],Footnote 1 which was developed by Ippei Obayashi, one of the authors of this chapter. We analyze the open material data for practice. HomCloud has already been used in various material research studies [23, 24, 26,27,28,29,30,31,32,33,34,35,36].
We demonstrate HomCloud on Google Colaboratory, which is a data science environment provided by Google.Footnote 2 Collaboratory allows you to write and execute Python in your browser with the required zero configuration; we use HomCloud from Python. Before attempting this demonstration, readers should learn the basic usage of Python, Google Colaboratory, and Numpy.Footnote 3 The demonstration code is available on the authors’ website.Footnote 4
In this demonstration, we analyze crystalline copper, which has a face-centered cubic (FCC) structure. The structural data can be downloaded from The Materials Project websiteFootnote 5; you will need to create an account on this website before starting this demonstration.
After logging in, the CIF file of the crystal copper can be downloaded from the mp-30Footnote 6 webpage. Click on the “Export as” icon of the web page and select “CIF” to download the file.
The following code makes Colab install HomCloud and ASE (Atomic Simulation Environment) [38]. ASE is required to read the CIF file. Please input the following code into a notebook cell and run it:

After installation, you can upload copper’s CIF file to Colaboratory’s environment. Please execute the following code in a new cell and select “Cu.cif” for the upload:

Next, HomCloud, ASE, and other libraries are imported.

You read the CIF file using the code

The following code shows the atomic positions.

OUTPUT:

The unit cell had only four Cu atoms, and the number of atoms is too small to analyze using PH. Therefore, the unit cell is repeated using the following code:

The number of atoms in the repeated cell is \(4 \times 8 \times 8 \times 8 = 2048\).
Now, we add a small amount of noise to the atomic configuration. For computing PDs, the input point cloud should be in a general position because Delaunay triangulation is used internally. For example, any three points in a point cloud should not lie on the same line. A small amount of noise is required because no crystal structure satisfies this condition. A small noise has been mathematically proven to have no significant effect on the PH analysis. The following code adds uniform \(\pm 10^{-5}\) noise to the atomic configuration.

Now, let us compute the PDs.

The PDs are stored in a file called cu.pdgm. “save_boundary_map=True” is required to use inverse analysis later.
The following code loads the 1D and 2D PDs from the file and plots them (Fig. 11.5):


1D and 2D PDs
Argument (1, 4) specifies the range of the PD histogram, and 32 specifies the number of bins; both these parameters can be changed freely. HomCloud automatically determines the range from the minimum and maximum birth and death times if the range is not specified.
The birth-death pairs near the diagonal are less important because the corresponding rings or hollows quickly disappear immediately after appearing in the ball-increasing process. Therefore, in Cu PDs, the pairs around (3.3, 3.3) in the 1D PD and around (3.4, 3.4) in the 2D PD are not very important. Thus, we focus on the birth-death pairs around (1.65, 2.2) in the 1D PD, pairs around (2.2, 2.5) in the 2D PD, and pairs around (2.2, 3.3) in the 2D PD.
We collected the pairs around (1.65, 2.2) in 1D PD using the code pairs_in_rectangle, which provides a list of all pairs in a specified rectangle.

The following code shows the number of pairs and the first pair in the list.

OUTPUT:

We apply an inverse analysis method called stable volume [39]; this method identifies the geometric origins that correspond to the birth-death pairs. We apply this method to ten randomly sampled birth-death pairs in the list. A noise-bandwidth parameter larger than the noise scale and smaller than the effective scale of the system is required to apply stable volumes. In the following code, we chose \(10^{-3}\) as the noise-bandwidth parameter because we added \(\pm 10^{-5}\) noise to the atomic configuration before computing PDs.

We attempt to visualize the stable volumes in the configuration space. We use plotlyFootnote 7 for 3D visualization.


Result of inverse analysis a for birth-death pairs around (1.65, 2.2) in 1D PD; b for birth-death pairs around (2.2, 2.5) in 2D PD; c for birth-death pairs around (2.2, 3.3) in 2D PD
Figure 11.6a shows these results, which indicate that these pairs correspond to regular triangles in an FCC structure. We computed the distances between the three vertices of a triangle to verify this fact numerically. The coordinates of the vertices were obtained using the code

OUTPUT:

We used Scipy’s distance matrix function to compute all pairwise distances.

OUTPUT:

The distances are almost the same, and therefore, we conclude that the triangle is regular.
Further, we applied inverse analysis to the birth-death pairs in the 2D PD. The birth-death pairs around (2.2, 2.5) are collected by running the code

OUTPUT:

The total number of pairs is 3375. The stable volumes are also applied, as shown in Fig. 11.6b.

For pairs around (2.2, 3.2), the following code is available (Fig. 11.6c).

OUTPUT:

The birth-death pairs in the 2D PD are considered to correspond to the tetrahedral and octahedral sites of the FCC structure. We verify this by comparing them with PDs for tetrahedral and octahedral sites in Sect. 11.2.3. Further, we compute \((\text {death time}) / (\text {birth time})\) of the birth-death pairs.
-
In the 1D PD for a regular triangle (Fig. 11.3b, e): \(\frac{a^2/3}{a^2/4} = \frac{4}{3} = 1.3333\ldots \)
-
In the 2D PD for a regular tetrahedron (Fig. 11.3c): \(\frac{3a^2/8}{a^2/3} = \frac{9}{8} = 1.125\)
-
In the 2D PD for a regular octahedron (Fig. 11.3f): \(\frac{a^2/2}{a^2/3} = \frac{3}{2} = 1.5\)
These ratios coincide with those of the copper PDs. The following code is used to compute the ratios:

OUTPUT:

At the end of this demonstration, we remark on the regular tetragonal rings in the FCC structure. The 1D PD of the copper crystal has only one type of birth-death pair besides the diagonal; the birth-death pairs correspond to a regular triangle in the FCC structure. However, the FCC structure has another type of ring: a regular tetragonal ring. The copper PD does not have a birth-death pair corresponding to a regular tetragonal ring because of the linear independence rule, which is the same as that for the octahedral point cloud.
This section presents the PH analysis of an FCC crystal using HomCloud. Information on the triangles in the structure is encoded in the 1D PD, and information on the tetrahedral and octahedral sites is encoded in the 2D PD. We applied inverse analysis to examine PD in more depth. Please refer to review papers[6, 37] for more details.
3 Ring Analysis
This section introduces analysis methods for a network topology comprising chemically bonded atoms. In this network, the nodes and edges (or links) are the atoms and chemical bonds, respectively. The network topology analysis is useful for evaluating the structural order of crystalline and amorphous (or glassy) materials. A descriptor for network topology is the node degree, which is the number of edges connected to the node, i.e. the coordination number in chemistry. The distribution of the node degrees has been analyzed for WWW, social networks, and biological networks [40,41,42]. These analyses concluded that hub nodes, whose degrees are much larger than those of other nodes, play crucial roles in the system. However, such a simple descriptor may not be useful for distinguishing networks in material structures because the node degrees are almost the same in chemically bonded networks. Therefore, other descriptors computed from a larger number of atoms are necessary for analyzing material structures. This section focuses on statistical analysis based on rings, which are closed paths in a chemically bonded network.
3.1 Notation and Preliminaries
A network (or a graph) structure is defined by a set of nodes \(\mathcal {V}\) and a set of edges \(\mathcal {E}\). A node is a point in a graph, which corresponds to an atom in the material structure. An edge is a linkage between a pair of nodes, which corresponds to a chemical bonding between a pair of atoms. Network topology can be analyzed using tools in graph theory, which is a subcategory in mathematics.
The path in a network is a sequence of edges. It can also be described as a sequence of nodes when there are no multiple edges between the same pair of nodes. For simplicity, this section uses the latter description. A path is called simple if all nodes are distinct; a path is closed if the start and end nodes are the same. A simple closed path is known as a cycle, and it is also called a ring in network topology analysis of materials science. The size of a ring is defined by its number of nodes (atoms). In some cases, the ring size is defined by the number of network-forming atoms in the ring; e.g. Si atoms in SiO\(_2\) and Ge atoms in GeO\(_2\).
The distance between two nodes in a network is defined as the shortest distance between these nodes. The shortest distances and their paths can be computed automatically by efficient algorithms such as Dijkstra’s algorithm, which was developed in graph theory. The diameter of a network is defined as the maximum distance between any pair of nodes, i.e. the longest distance over all shortest distances in the network.

Examples of networks. a The network includes nine nodes and ten edges. It has three rings: \(r_{a1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{a2} = (v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), and \(r_{a3} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_8\rightarrow v_9)\). Guttman rings are \(r_{a1}\) and \(r_{a2}\); further, they are also primitive rings. King rings are \(r_{a1}\), \(r_{a2}\), and \(r_{a3}\). b The network includes nine nodes and twelve edges; it has at least eight rings: \(r_{b1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_1)\), \(r_{b2} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_3)\), \(r_{b3} = (v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_5)\), \(r_{b4} = (v_7\rightarrow v_8\rightarrow v_1\rightarrow v_9\rightarrow v_7)\), \(r_{b5} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{b6} = (v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{b7} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_7\rightarrow v_8\rightarrow v_1)\), and \(r_{b8} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_8)\). Guttman rings are \(r_{b1}\), \(r_{b2}\), \(r_{b3}\), and \(r_{b4}\); they are primitive rings. King rings are \(r_{b1}\), \(r_{b2}\),..., \(r_{b8}\)
Figure 11.7 shows examples of these networks. The network in Fig. 11.7a includes nine nodes: \(\mathcal {V} = \{v_1, v_2, \dots , v_9\}\) and ten edges: \(\mathcal {E}=\{ (v_1, v_2), (v_2, v_3),\dots ,\)
\( (v_1, v_8), (v_1, v_9), (v_5,v_9) \}\). The distance between nodes \(v_1\) and \(v_5\) is two because the shortest length among the possible simple paths is \((v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5)\), \((v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5)\), and \((v_1\rightarrow v_9\rightarrow v_5)\). The graph diameter is four because the longest path between a node pair is \(v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\). The graph includes three rings: \(r_{a1}=(v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{a2}=(v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), and \(r_{a3}=(v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_8\rightarrow v_9)\). For the network in Fig. 11.7b, describing network descriptors such as nodes, edges, and rings is an exercise for readers.
3.2 Ring Criteria Based on the Shortest Distance
The maximum size of the ring can be twice the graph diameter, and therefore, we can enumerate the large rings from a large network. The large rings in which nodes overlap are redundant. In addition, such rings are too large for analyzing the structural order in the intermediate-range scale. Therefore, we need to enumerate the relatively smaller rings, which contribute to the structural order of the materials.
The graph in Fig. 11.7a shows that ring \(r_{a3}\), whose size is eight, could be considered redundant because it can be decomposed into \(r_{a1}\) and \(r_{a2}\), whose sizes are six. Ring analysis should consider only nonredundant rings that satisfy certain criteria based on the shortest distance. This section introduces the four major ring criteria and their enumeration algorithms.
The ring definition proposed by Guttman [7] consists of one of the shortest paths between two atoms connected by an edge, and it starts from one of these two atoms to the other and does not use the direct path between them. A ring that satisfies this criterion is called the Guttman ring. An efficient algorithm for enumerating Guttman rings first selects a pair of atoms connected by an edge. The edges between the atoms from the network are removed, and the shortest paths starting from one of these atoms to the other are then enumerated. By connecting one of the shortest paths to the removed edge, a Guttman ring is enumerated. If there are other shortest paths between these atoms, they are used to enumerate other Guttman rings. Then, the edge is returned to the network. Next, another pair of atoms was selected to enumerate the other Guttman rings. The algorithm may enumerate the same rings, which consist of the same set of atoms, multiple times; such redundant rings must be removed from the list of enumerated rings.
In the network shown in Fig. 11.7a, two Guttman rings \(r_{a1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\) and \(r_{a2} = (v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\) are enumerated. However, ring \(r_{a3} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_8\rightarrow v_9)\) is not a Guttman ring. For the network in Fig. 11.7b, there are four Guttman rings: \(r_{b1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_1)\), \(r_{b2} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_3)\), \(r_{b3} = (v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_5)\), and \(r_{b4} = (v_7\rightarrow v_8\rightarrow v_1\rightarrow v_9\rightarrow v_7)\).
King proposed a definition of a ring [8, 9] as a cycle that consists of the shortest path between a pair of atoms connected by a center atom. An algorithm for enumerating King’s rings first chooses an atom that connects to at least two atoms as the center atom. Next, two atoms connected to the center atom are selected, and the edges between the center and two selected atoms are removed from the network. Next, the shortest paths starting from one of these neighbor atoms to the other are enumerated. A King ring is enumerated by connecting one of the shortest paths and two edges between the center and neighbor atoms. If there are other shortest paths, they are used to enumerate the other King rings. Subsequently, the removed edges are returned to the network. Next, another atom as the center and two neighbor atoms are selected to enumerate the other King rings. After enumeration, redundant rings that comprise the same sets of atoms have to be removed; this is similar to the enumeration algorithm for Guttman rings.
In the network in Fig. 11.7a, King rings are \(r_{a1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{a2} = (v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), and \(r_{a3} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_8\rightarrow v_9)\). In the network in Fig. 11.7b, King rings are \(r_{b1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_1)\), \(r_{b2} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_3)\), \(r_{b3} = (v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_5)\), \(r_{b4} = (v_7\rightarrow v_8\rightarrow v_1\rightarrow v_9\rightarrow v_7)\), \(r_{b5} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{b6} = (v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\), \(r_{b7} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_7\rightarrow v_8\rightarrow v_1)\), and \(r_{b8} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_8)\).
A ring is primitive if all paths between any pair of nodes in the ring are the shortest, which implies that there are no shorter paths in the external path [10,11,12]. This definition is equivalent to the criterion that a ring cannot be decomposed into two smaller rings. A ring that satisfies the above criterion is called a primitive ring. The enumeration algorithm for primitive rings first computes the distances of all atom pairs in the network using the shortest distance algorithm. Next, all atom pairs with distances less than the threshold are enumerated; the threshold is set to half the maximum size of the primitive rings to be enumerated in a subsequent analysis. Then, all shortest paths between the enumerated pair of nodes whose distance is less than the threshold are enumerated. Ring candidates are generated by connecting two shortest paths that do not share any internal nodes. Next, the primitive criterion is inspected for the generated ring candidates and only candidates that satisfy the criterion as primitive rings remain. This procedure can enumerate primitive rings with an even number of nodes. To enumerate primitive rings with an odd number of nodes, the shortest paths between the neighbor node from one of the two nodes and the other node are enumerated. Next, the cycle through one of the original pair, the other, the neighbor, and the start node is enumerated as a primitive ring.
In the network in Fig. 11.7a, two primitive rings \(r_{a1}=(v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_1)\) and \(r_{a2}=(v_1\rightarrow v_8\rightarrow v_7\rightarrow v_6\rightarrow v_5\rightarrow v_9\rightarrow v_1)\) are enumerated. In Fig. 11.7b, four primitive rings \(r_{b1} = (v_1\rightarrow v_2\rightarrow v_3\rightarrow v_9\rightarrow v_1)\), \(r_{b2} = (v_3\rightarrow v_4\rightarrow v_5\rightarrow v_9\rightarrow v_3)\), \(r_{b3} = (v_5\rightarrow v_6\rightarrow v_7\rightarrow v_9\rightarrow v_5)\), and \(r_{b4} = (v_7\rightarrow v_8\rightarrow v_1\rightarrow v_9\rightarrow v_7)\) are enumerated.
A ring is strong if it cannot be decomposed into smaller rings. Based on this definition, a strong ring is always primitive; therefore, the strong criterion is a generalization of the primitive criterion. An algorithm for strong rings first enumerates the primitive rings as candidates. Next, a strong criterion is inspected for each enumerated candidate, and only candidates that satisfy the criterion as strong rings remain. In this algorithm, the computation for inspecting the criterion is difficult when the network is large because it requires a combinatorial computation. Thus, enumeration can be implemented only for small networks.
The importance of the strong criterion is illustrated in Fig. 11.8a. In this example, the largest ring with six nodes, indicated by bold lines, is enumerated as a primitive ring. However, it is not a strong ring because it can be decomposed into three small rings with four nodes. Smaller rings are considered essential components of this network. Figure 11.8b shows another example. In this example, the large ring with nine nodes (indicated by bold lines) is a primitive ring but it is not a strong ring because it can be decomposed into several smaller rings with five or six nodes. This result may not fit with our intuition. These examples indicate that there is no perfect criterion that fits everyone’s intuition. Thus, we should carefully select the ring criterion for the network topology analysis.

Networks that include a ring which is a primitive but not strong in both network a and b. The ring is indicated by bold lines
3.3 Statistical Analysis Using Enumerated Rings
We assume the two networks shown in Fig. 11.9. Both networks have 16 nodes, but their topologies (connectivity patterns) are different. Figure 11.9a shows that this network has one ring with four nodes: \(r_1=(v_2\rightarrow v_3\rightarrow v_4\rightarrow v_7\rightarrow v_2)\), and two rings with six nodes: \(r_2=(v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_1)\) and \(r_3=(v_1\rightarrow v_2\rightarrow v_7\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_1)\). All rings in the network satisfy Guttman, King, and primitive criteria. In contrast, as shown in Fig. 11.9b, there is one ring with four nodes: \(r_1=(v_7\rightarrow v_8\rightarrow v_9\rightarrow v_10\rightarrow v_7)\), and two rings with six nodes: \(r_2=(v_1\rightarrow v_2\rightarrow v_3\rightarrow v_4\rightarrow v_5\rightarrow v_6\rightarrow v_1)\) and \(r_3=(v_{11}\rightarrow v_{12}\rightarrow v_{13}\rightarrow v_{14}\rightarrow v_{15}\rightarrow v_{16}\rightarrow v_{11})\). All rings in the network satisfy Guttman, King, and primitive criteria. The distributions of the number of rings in these networks are the same; however, their topologies are clearly different. Therefore, another descriptor is necessary to distinguish between these network topologies.

Networks to compare their topologies
There are two major methods for counting rings. The first \(R_c\) represents the number of rings per cell, which counts all different rings corresponding to the property we are looking for, e.g. a criterion and ring size, in a unit cell (or a simulation box). The counting method is straightforward.
The second method \(R_n\) represents the number of rings per node, which counts the rings for each node that is a starting point during ring enumeration. Thus, this method counts the same ring multiple times. Both methods normalize the counted numbers by the number of nodes to compare networks of different sizes.
The computed results for \(R_c\) and \(R_n\) for the networks in Fig. 11.9 are summarized in Tables 11.2 and 11.3. Table 11.2 shows that the distribution of \(R_c\) cannot distinguish these networks because all three criteria are the same. \(R_n\) shown in Table 11.3 distinguishes these networks using the distributions for Guttman or King criteria because the \(R_n\) of six nodes in the graph of Fig. 11.9a is ten, while that of Fig. 11.9b is twelve. These differences are caused by the overlap of rings, and the resulting rings with six nodes are not counted when node 3 or 7 is a start node for enumerating the Guttman and King rings.
Another descriptor of network topology is a connectivity matrix, which evaluates the connectivity between rings. This matrix is defined as
where the diagonal elements P(n) represent the proportion of nodes that are the starting nodes of the rings with n nodes. The off-diagonal elements P(i, j) represent the proportion of nodes that are the start nodes of both rings with i and j nodes. The smallest size r is three because the smallest size of a ring is three when there is no self-loop in a network. Table 11.4 summarizes the connectivity matrices of the two networks shown in Fig. 11.9. The off-diagonal elements of the network in Fig. 11.9a are larger than those in Fig. 11.9b; this implies that rings with different numbers of nodes in the former network are more densely connected than those in the latter. In this demonstration, the connectivity matrix can be used for distinguishing between network topologies.
4 Application for the Structural-Order Analysis of Amorphous Silica
This section provides examples of the structural-order analysis of disordered materials. An amorphous material includes order within a disorder. Thus, structural-order analyses like PH and ring analyses have been most actively applied to these materials. The first practical example of the application of PH is amorphous silica (\({\text {SiO}}_{2}\)), which is a typical network-forming amorphous material. PH was first applied to amorphous silica by Nakamura et al. [19], followed by Hiraoka et al. [20]. We introduce topics from these two studies.
Before applying PH, we explained known facts about the structure of amorphous silica. The building blocks of amorphous silica are \({\text {SiO}}_{4}\) tetrahedrons comprising four oxygen atoms, with one silicon atom at the center. The vertex-sharing network of the tetrahedrons forms a complex structure of amorphous silica. Tetrahedrons correspond to the short-range order (SRO) of amorphous silica. The network appears random; however, it is believed to have a medium-range order (MRO), which has a longer length scale than SRO.
Figure 11.10 shows the 1D PD of amorphous silica obtained from the molecular dynamics simulations. The PD has outstanding features \(C_T, C_P, C_O\), and \(B_O\).

We found that \(C_T\) mainly corresponds to the triangles formed by Si–O–Si by applying the inverse analysis to \(C_T\). This triangle is part of the tetrahedral structure of four oxygens; therefore, we can say that \(C_T\) corresponds to the SRO of amorphous silica.
\(C_P, C_O\), and \(B_O\) correspond to the more complicated structures. An inverse analysis can be used to clarify the geometric origins of these features (Fig. 11.10). \(C_P\) corresponds to a ring with alternating Si and O atoms. In other words, \(C_P\) represents the network structure of the chemical bonds. The birth times correspond to the length scale of the chemical bonds, and the number of deaths equals the ring size. Therefore, the distribution of the death time in \(C_P\) indicates the diversity of the rings in the networks.
\(C_O\) corresponds to triangles formed by the three oxygens appearing in the \(\cdots \)–O–Si–O–Si–O–\(\cdots \) network; \(B_O\) corresponds to a quadrangle or pentagon formed by four or five oxygens. The analysis shows that \(C_T, C_O\), and \(B_O\) are the substructures of the network structures of chemical bonds that correspond to \(C_P\) and 1D PD; such substructures have a specific order. \(C_P, C_O\), and \(B_O\) can be considered to correspond to MRO because \(C_P, C_O\), and \(B_O\) contain information on scales longer than \(C_T\).
We discuss the relationship between \(C_P, C_O, B_O\), and the first sharp diffraction peak (FSDP) of the structure factor S(q) to understand the relationship between MRO and PD (see 2.2 for detailed background on structure factor and FSDP). The FSDP of amorphous silica is characteristic and is thought to be related to MRO. The FSDP was observed for the configuration data obtained by the molecular dynamics simulation of amorphous silica (Fig. 11.10 (bottom right)). Figure 11.10 upper right panel shows a histogram of the death times of \(C_P, C_O\), and \(B_O\) as a function of the wave number (see [20] for how to compute these curves). These figures indicate that the length scale of MRO originates from a mixture of the length scales of \(C_P, C_O\), and \(B_O\). This discussion shows that structures extracted by PH correspond to MRO.
At the end of this example, we note the following three points. The first is the origin of the curvilinear distribution of birth-death pairs; this distribution indicates the existence of geometric constraints on the atomic configuration. The distribution of \(C_P\) is restricted by the Si–O bond lengths; the distribution of \(C_T\) is restricted by the \({\text {SiO}}_{4}\) tetrahedron. Constraint \(C_O\) is more complex. The details are provided in [20]. This constraint is considered part of the source of MRO. The second point is the initial radii of the atoms. In Sect. 11.2.1, the radii of all balls are identical. The initial radii of the points can be changed to reflect the atomic types in the PH analysis. In the analysis of amorphous silica, two initial radii, \(r_{\text {O}}\) and \(r_{\text {Si}}\) are used (see the supporting information of [20]). Finally, we remark that not all rings detected by PH are formed by chemical bonds; for example, there is no chemical bond between the two oxygens in the triangles corresponding to \(C_O\). The ability of PH to detect rings without bonds using increasing balls allows us to capture geometric features that conventional methods cannot find.
We introduce another analysis of densified amorphous silica reported by Onodera et al. [27]. They synthesized four amorphous silica by different processing conditions designated by a combination of temperature and pressure for the process: RT/7.7 GPa, 400 \({}^\circ \)C/7.7 GPa, 1200 \({}^\circ \)C/7.7 GPa, and RT/20 GPa. For example, 1200 \({}^\circ \)C/7.7 GPa refers to the material recovered after hot compression at 1200 \({}^\circ \)C. The densities of 1200 \({}^\circ \)C/7.7 GPa and RT/20 GPa are almost the same, and they are larger than those of RT/7.7 GPa and 400 \({}^\circ \)C/7.7 GPa [27]. In addition, we generated structural models using molecular dynamics simulations followed by refinement using the reverse Monte Carlo techniques to reproduce experimental diffraction data. (See [27] for the detailed procedure.)
We first compared the distributions of ring sizes in these glasses. Figure 11.11a shows the distributions of the primitive rings. For comparison, the results for the silica crystals of \(\alpha \)-cristobalite, \(\alpha \)-quartz, and coesite are shown in Fig. 11.11b. The density of \(\alpha \)-cristobalite, which is the same as the density of normal amorphous silica, is the smallest among these crystals. In contrast, the density of the coesite was the highest. The sizes of all rings in \(\alpha \)-cristobalite are, while those in coesite vary. This implies that \(\alpha \)-cristobalite is topologically ordered, whereas coesite is disordered. For the distributions of glasses, all peak positions are six or seven, which is similar to that of \(\alpha \)-cristobalite. The distribution of 1200 \({}^\circ \)C/7.7 GPa is skewed toward larger sizes; this indicates that glass under 1200 \({}^\circ \)C/7.7 GPa is more disordered than other densified glasses.

Distributions of multiplicity (relative counts) of the ring size. Rings are enumerated by the primitive criterion. Ring size n is measured by the number of Si atoms in a ring. a Distributions obtained for glassy SiO\(_2\) from the MD-RMC models: RT/7.7 GPa (black), 400 \({}^\circ \)C/7.7 GPa (red), 1200 \({}^\circ \)C/7.7 GPa (blue), and RT/20 GPa (cyan). b Distributions obtained from the crystal structures of \(\alpha \)-cristobalite (green), \(\alpha \)-quartz (magenta), and coesite (gray) (Modified version of Fig. 6 of [27], CC-BY 4.0)

Persistent diagrams computed from a point cloud of Si atoms for densified amorphous silica of a RT/7.7 GPa, b 400 \({}^\circ \)C/7.7 GPa, c 1200 \({}^\circ \)C/7.7 GPa, d RT/20 GPa, and e crystals. Crystal polymorphs visualized in e are \(\alpha \)-cristobalite (green), \(\alpha \)-quartz (magenta), and coesite (gray). The multiplicity per Si atom is indicated by the color bar. f Distributions of the multiplicity in the boxed regions colored magenta along the death axis. The bars in the top panel represent the crystalline polymorphs and the curves in the bottom panel represent the densified glasses (Modified version of Figs. 7 and 8 of [27], CC-BY 4.0)
Next, we computed persistent diagrams from a point cloud of Si atoms in densified amorphous silica and crystal polymorphs. The computed results are shown in Fig. 11.12a–e. In these figures, the boxed regions parallel to the death axis highlight persistent cycles. Histograms with respect to the death values in these regions are shown in Fig. 11.12f. These figures demonstrate that the death value of the persistent cycles decreases with increasing density in both densified glasses and crystal polymorphs. For the hot-compressed glass (1200 \({}^\circ \)C/7.7 GPa), a sharp peak in the PD is accompanied by a loss of the long-death tail in the histogram shown in Fig. 11.12f. These analyses using persistent homology and ring analysis concluded that the network topology is disordered in the hot-compressed glass, but the homology (the shape of voids) is more ordered than in other densified glasses, which is consistent with the sharpest FSDP of the hot-compressed glass in the diffraction data.
References
Kalinin SV, Ophus C, Voyles PM, Erni R, Kepaptsoglou D, Grillo V, Lupini AR, Oxley MP, Schwenker E, Chan MK, Etheridge J, Li X, Han GGD, Ziatdinov M, Shibata N, Pennycook SJ (2022) Nat. Rev. Methods Primers 2:1–28
Muto S, Shiga M (2020) Microscopy 69:110–122
Friederich P, Häse F, Proppe J, Aspuru-Guzik A (2021) Nat. Mater. 20:750–761
Edelsbrunner H, Letscher D, Zomorodian A (2000) Proceedings of 41st annual symposium on FOCS, pp 454–463
Zomorodian A, Carlsson G (2005) Discrete Comput Geom 33:249–274
Otter N, Porter MA, Tillmann U, Grindrod P, Harrington HA (2017) EPJ Data Sci 6:17
Guttman L, Non-Cryst J (1990) Solids 116:145–147
King SV (1967) Nature 213:1112–1113
Franzblau D (1991) Phys Rev B 44:4925
Goetzke K, Klein HJ, Non-Cryst J (1991) Solids 127:215–220
Yuan X, Cormack A (2002) Comput Mater Sci 24:343–360
Wooten F (2002) Acta Crystallogr A 58:346–351
Silva VD, Ghrist R (2007) Algebr Geom Topol 7:339–358
Chan JM, Carlsson G, Rabadan R (2013) Proc Natl Acad Sci USA 110:18566–18571
Giusti C, Pastalkova E, Curto C, Itskov V (2015) Proc Natl Acad Sci USA 112:13455–13460
Ichinomiya T, Obayashi I, Hiraoka Y (2020) Biophys J 118:2926–2937
Suzuki A, Miyazawa M, Minto JM, Tsuji T, Obayashi I, Hiraoka Y, Ito T (2021) Sci Rep 11:1–13
Koseki K, Kawasaki H, Atsugi T, Nakanishi M, Mizuno M, Naru E, Ebihara T, Amagai M, Kawakami E, Syst NPJ (2020) Biol Appl 6:40
Nakamura T, Hiraoka Y, Hirata A, Escolar EG, Nishiura Y (2015) Nanotechnology 26:304001
Hiraoka Y, Nakamura T, Hirata A, Escolar EG, Matsue K, Nishiura Y (2016) Proc Natl Acad Sci USA 113:7035–7040
Saadatfar M, Takeuchi H, Robins V, Francois N, Hiraoka Y (2017) Nat Commun 8:1–11
Hosokawa S, Bérar JF, Boudet N, Pilgrim WC, Pusztai L, Hiroi S, Maruyama K, Kohara S, Kato H, Fischer HE, Zeidler A (2019) Phys Rev B 100:054204
Hirata A, Wada T, Obayashi I, Hiraoka Y (2020) Commun Mater 1:98
Shimizu Y, Kurokawa T, Arai H, Washizu H (2021) Sci Rep 11:2274
Ichinomiya T, Obayashi I, Hiraoka Y (2017) Phys Rev E 95:012504
Onodera Y, Kohara S, Tahara S, Masuno A, Inoue H, Shiga M, Hirata A, Tsuchiya K, Hiraoka Y, Obayashi I, Ohara K, Mizuno A, Sakata O (2019) J Ceram Soc Jpn 127:853–863
Onodera Y, Kohara S, Salmon PS, Hirata A, Nishiyama N, Kitani S, Zeidler A, Shiga M, Masuno A, Inoue H, Tahara S, Polidori A, Fischer HE, Mori T, Kojima S, Kawaji H, Kolesnikov AI, Stone MB, Tucker MG, McDonnell MT, Hannon AC, Hiraoka Y, Obayashi I, Nakamura T, Akola J, Fujii Y, Ohara K, Taniguchi T, Sakata O (2020) NPG Asia Mater 12:85
Koyama C, Tahara S, Kohara S, Onodera Y, Småbråten DR, Selbach SM, Akola J, Ishikawa T, Masuno A, Mizuno A, Okada JT, Watanabe Y, Nakata Y, Ohara K, Tamaru H, Oda H, Obayashi I, Hiraoka Y, Sakata O (2020) NPG Asia Mater 12:43
Onodera Y, Takimoto Y, Hijiya H, Taniguchi T, Urata S, Inaba S, Fujita S, Obayashi I, Hiraoka Y, Kohara S (2019) NPG Asia Mater 11:75
Murakami M, Kohara S, Kitamura N, Akola J, Inoue H, Hirata A, Hiraoka Y, Onodera Y, Obayashi I, Kalikka J, Hirao N, Musso T, Foster AS, Idemoto Y, Sakata O, Ohishi Y (2019) Phys Rev B 99:045153
Pedersen MC, Robins V, Mortensen K, Kirkensgaard JJK (2020) Proc Math Phys Eng Sci 476:20200170
Ando I, Mugita Y, Hirayama K, Munetoh S, Aramaki M, Jiang F, Tsuji T, Takeuchi A, Uesugi M, Ozaki Y (2021) Mater Sci Eng A 828:142112
Hong S, Kim D (2019) J Phys Condens Matter 31:455403
Landuzzi F, Nakamura T, Michieletto D, Sakaue T (2020) Phys Rev Res. 2:033529
Minamitani E, Shiga T, Kashiwagi M, Obayashi I ArXiv:2107.05865
Yoshimoto Y, Sugiyama S, Shimada S, Kaneko T, Takagi S, Kinefuchi I (2021) Macromolecules 54:958–969
Obayashi I, Nakamura T, Hiraoka Y (2022) J Phys Soc Jpn 91:091013
Larsen AH, Mortensen JJ, Blomqvist J, Castelli IE, Christensen R, Dułak M, Friis J, Groves MN, Hammer B, Hargus C, Hermes ED, Jennings PC, Jensen PB, Kermode J, Kitchin JR, Kolsbjerg EL, Kubal J, Kaasbjerg K, Lysgaard S, Maronsson JB, Maxson T, Olsen T, Pastewka L, Peterson A, Rostgaard C, Schiøtz J, Schütt O, Strange M, Thygesen KS, Vegge T, Vilhelmsen L, Walter M, Zeng Z, Jacobsen KW (2017) J Phys Condens Matter 29:273002
Obayashi I arXiv:2109.11711
Albert R, Jeong H, Barabási AL (1999) Nature 401:130–131
Barabási AL, Albert R (1999) Science 286:509–512
Barabasi AL, Oltvai ZN (2004) Nat Rev Genet 5:101–113
Acknowledgements
This work was also supported by JSPS KAKENHI Grant Numbers JP19H00834 (to I.O.), JP19KK0068 (to I.O.), JP20H05878 (to M.S.), JP20H05884 (to M.S. and I.O.), JP20H04241 (to M.S.), and JP22H05106 (to I.O.) and JST PRESTO Grant Number JPMJPR16N6 (to M.S.) and JPMJPR1923 (to I.O.).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 Materials Research Society, under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Shiga, M., Obayashi, I. (2024). Structural-Order Analysis Based on Applied Mathematics. In: Hayashi, K. (eds) Hyperordered Structures in Materials. The Materials Research Society Series. Springer, Singapore. https://doi.org/10.1007/978-981-99-5235-9_11
Download citation
DOI: https://doi.org/10.1007/978-981-99-5235-9_11
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-5234-2
Online ISBN: 978-981-99-5235-9
eBook Packages: Chemistry and Materials ScienceChemistry and Material Science (R0)