
Abstract
This paper describes the development of intelligent fault diagnosis for electromechanical systems (EMS) and examines various combinations of mechanical and electrical faults in such systems. Specifically, the study focuses on a three-phase asynchronous motor (IM) with an outer rotor bearing system. The faults investigated in this study include a healthy system (F1), healthy motor with outer bearing faults (F2), healthy motor with unbalance in outer rotor (F3), bearing fault in the motor with healthy outer rotor (F4), inner motor bearing and outer rotor bearing fault (F5), motor bearing fault with outer unbalanced rotor (F6), motor stator fault with outer healthy rotor (F7), motor stator fault with outer unbalanced rotor (F8), motor stator fault with outer bearing fault (F9), and motor bearing fault with outer bearing fault and unbalanced rotor (F10). In order to detect combined faults in the motor-rotor-bearing assembly, the paper proposes using wavelet characteristics extracted from the current and vibration signals, which are used to develop a support vector machine (SVM)-based defect detection system. Finally, the paper concludes with a discussion of the research results.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
EMS comprises electrical and mechanical components and is extensively used in light as well as heavy industry. EMS is exposed to various kinds of stresses that cannot be avoided at work, resulting in various types of electrical and mechanical breakdown of the body. A minor fault of these, if not detected and rectified in a timely manner, can cause serious damage to the EMS, resulting in downtime of the entire production process, loss of production, and sometimes serious injury. Therefore, early diagnosis of EMS failure is important to avoid its serious consequences [1, 2].
In the last two decades, multiple diagnostic techniques have been developed to prevent any kind of malfunction in EMS, including FFT, high-resolution spectral analysis, wavelet transform, Hilbert transform, Park vector method, and Hilbert-Hong transform [3, 4]. These tests are based on signal analysis and utilize a range of signals such as vibration, stator current, induced voltage, air gap torque, acoustics, and others [5]. Note that current and vibration techniques are most prevalent and favored due to its higher accuracy and simplicity of measurement [6]. It is important to remember that traditional methods are not always consistent because they are influenced by many factors such as defect levels, motor running conditions, noise, and others [4]. Another fault diagnosis method based on mathematical modeling of the machine has also been developed. However, many assumptions need to be made to construct reliable mathematical models to deal with nonlinear and stochastic systems, but this is still weak in the presence of distortions and noise [7].
In order to diagnose defects in machines using signals and computational models, one needs to have adequate knowledge and experience gained through practice. However, with the constant rotation of machines for all kinds of industries, it is challenging to fulfill the need for skilled professionals. Consequently, in the last decade, new diagnostic methods utilizing machine learning (ML) technology have been developed and adopted in the machinery field. These methods aim to automate traditional diagnostic techniques, increase reliability and accuracy, and lower costs [8]. ML techniques are data-driven techniques that do not involve knowledge of models. Several AI techniques, including ANN, fuzzy logic, hidden Markov model, genetic algorithm (GA), and SVM, have been applied in the identification of system defects [9, 10]. In ML, the support vector machine has attractive features such as classification efficiency, short duration, and strong flexibility compared to other ML techniques [11].
To use ML-based diagnostics, different processing methods have been developed for example time-domain, frequency-domain, and multi-time frequency methods such as wavelets. Time domain and frequency domain theory assumes signal stability and system linearity; However, differences and inconsistencies and/or changes in electronic components may occur during normal operation of the EMS. Due to many faults, EMS operates in unstable conditions. Time–frequency or wavelet-based feature extraction methods are also used to solve complex and non-local problems [12]. For defect detection, three types of wavelets, namely, WPT, CWT, and DWT are employed [13]. In all the above studies, fault detection is determined at constant speed of the motor and less diagnostic for ramp speed problem. In addition, fault identification of EMS is limited in the literature. In addition, fault detection of electrical and mechanical defects is rare in AI-based EMS [14,15,16].
Therefore, in the current study, defect detection of EMS is attempted based on wavelet and SVM. Ten different combinations of EMS defects are considered. Wavelets (continuous wavelets) are considered for diagnosis due to their special properties of simultaneously processing time and frequency information. SVMs are used with RBF kernel. Since the accuracy of the SVM is influenced by the kernel & SVM parameters, the optimal values of parameters are selected by grid search & cross-validation algorithm. Also, performance evaluation also depends on the input, so here three important wavelet properties are measured for research. Lastly, identification was performed to confirm the effectiveness of the method at various motor operating conditions.
2 SVM Introduction
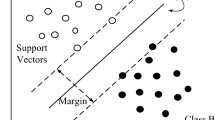
SVM is a statistical learning method that leverages examples to assign labels to data points [17]. It was proposed by Vapnik in 1995 and is characterized by four main points: the hyperplane with the maximum margin, the separating hyperplane, the flexible margin, and the kernel function. In high-dimensional space, a separating hyperplane is a boundary that divides two object classes. The objective of SVM is aimed to determine the hyperplane that provides the maximum or best separation between the classes. The margin, as depicted in Fig. 1, is defined as the gap between the separator hyperplane and the data point which is closer to it from each class.

The maximum-margin hyperplane
The optimal hyperplane is achieved using the subsequent optimization problem;
where training datasets is defined by \(\left\{ {(x_{j} ,y_{j} )} \right\}_{j = 1}^{m} x_{j} \in R^{l} , \, y_{j} \in \left\{ { - 1,1} \right\},\) input vectors is defined by \(x_{j}\), label of \(x_{j}\) is defined by \(y_{j}\), w represents normal direction of a hyperplane, scaler is defined by b, positive slack variables is defined by \(\xi_{j}\), and C represents the generalization parameter. Linear discriminate function for SVM training can be written as
The optimization problems mentioned above are designed for linearly separable data only. However, real-world data may not always be linearly separable and may exhibit complex patterns in the input space. In such cases, Support Vector Machine (SVM) algorithms can generate hyperplanes that allow for larger margin of separation even in nonlinearly separable data. One of the key advantages of support vector machines (SVMs) is their ability to transform data from an input space with a lower number of dimensions to a feature space with a higher number of dimensions, using kernel functions. This enables more flexible decision boundaries and facilitates the capture of complex relationships between data points. Various kernel functions \(k\left( {x,x_{i} } \right) = \phi \left( x \right)\phi \left( {x_{i} } \right)\), including Gaussian RBF, polynomials, and sigmoid functions, can be utilized to map data into higher-dimensional spaces. This transformation can aid in reducing computational load by retaining the effects of Multidimensional transformations. In the present study, the RBF (Radial Basis Function) kernel, which is a popular and widely used option, is employed.
The parameter σ in the RBF kernel represents the width of the kernel. While basic SVMs are designed for binary classification tasks, in reality, there may be scenarios where multiple classes need to be classified. Several methods have been proposed to tackle this issue, including the OAO, OAA, and DAGS algorithms [18]. These approaches break down multinomial classification problem into a sequence of bivariate classification problems. The OAA method involves training k-SVM models, where k represents the number of classes, while the OVO method requires training k(k − 1)/2 SVM models, with each model differentiating between two classes. Hsu and Lin [18] compared the hybrid method with three binary classification-based methods (OVO, OAA, and DAGS) and concluded from their experiments that OAO and DAGS are effective in practice.
3 Experimental Setup
Tests were conducted using a Mechanical Failure Simulator (MFS) as illustrated in Fig. 2. The MFS consists of a 0.5 hp, 50 Hz three-phase asynchronous motor induction motor connected to a rotor bearing system through an elastic coupling. A pulley connects the motor shaft to the gearbox, and an electromagnetic brake clutch is connected to the gearbox to deploy external load to the IM. A speed controller is connected to the IM for changing the speed. Three AC current probes and a triaxial accelerometer are used to record the current and vibration signals, respectively. Data acquisition was carried out using a National Instruments data acquisition system (DAQ). A tachometer with constant DC power was used to measure motor speed. The acquired data were analyzed using NI-LabVIEW data acquisition software.

Experimental test-rig
The tests were conducted to simulate various fault conditions, including healthy system (F1), healthy motor with outer bearing faults (F2), healthy motor with unbalance in outer rotor (F3), bearing fault in the motor with healthy outer rotor (F4), inner motor bearing and outer rotor bearing fault (F5), motor bearing fault with outer unbalanced rotor (F6), motor stator fault with outer healthy rotor (F7), motor stator fault with outer unbalanced rotor (F8), motor stator fault with outer bearing fault (F9), and motor bearing fault with outer bearing fault and unbalanced rotor (F10). Raw data was collected at a sampling rate of 20,480 Hz in the time domain, resulting in a total of 80 raw data sets (80 × 20,480 sampling points) for all the defect conditions. Data was recorded for different motor running conditions, including ramp-up speeds up to 10, 20, 30, and 40 Hz, under two different torque conditions: without load and high load (0% of rated load; 0.55% of rated load).
4 Feature Calculation Based on CWT
In order to achieve accurate results, this article employs the inference method based on Continuous Wavelet Transform. CWT is a significant approach for analyzing time–frequency information as it transforms time-domain information into time–frequency information. The fundamental concepts of CWT and its application for defect identification have been extensively discussed in numerous articles [19, 20]. CWT is utilized by combining the signal with the wavelet family, and it can be described as follows:
with
Among these, the master wavelet, also known as the window function, is denoted by ψ(t). The parameter “s” that controls the scale is related to the frequency characteristics of the compressed or expanded signal, with higher scales indicating lower frequencies and vice versa. The parameter “τ” that controls the translation is used to determine the position of the window as it moves through the signal, analogous to the direction of the red light. The wavelet transform utilizes the master wavelet function to break down the signal into a weighted set of scaled wavelet energies. While wavelets and Fourier transforms share similarities, the wavelet family differs in that it employs an infinite number of fundamental functions to transform sine and cosine functions.
Time–frequency information can be extracted from time-series data [19]. In this study, HAAR wavelets are utilized to obtain time–frequency information. The time-series data is initially decomposed into 2^7 sub-signals, yielding wavelet coefficients that are associated with each parameter. Each individual data point, for instance, containing 10,000 data points, encompasses the wavelet coefficients for each parameter, resulting in a matrix of coefficients for the dataset. It is important to note that calculating wavelet coefficients for each parameter requires significant storage space and time due to the large amount of data involved. Furthermore, choosing the appropriate wavelet scale can be challenging as an indicator chosen from a negative (or positive) scale may not fully capture the wave, while other scales might be overlooked. Hence, in this study, relative wavelet power (RWE) was employed as a criterion for selecting a suitable scale. Based on the RWE criteria, the wavelet scale with the highest energy is considered as the appropriate scale. RWE is a time–frequency measure that can describe specific events in the time–frequency domain. Mathematically, RWE is defined as the energy allocation given by
where \(\sum\limits_{m} {p_{m} } = 1,\) & overall energy is
where \(C_{n,j}\) represents “j” denotes the wavelet coefficient corresponding to the “n”th scale, “m” represents the quantity of wavelet coefficients, where m = 1, …, n,. Total energy of detail signal can be represented by
Power is now calculated for each scale. Then, the RWE of each parameter was calculated by Eq. (7). Select the ratio with the largest RWE as the best ratio. Now the wavelet coefficients of all data corresponding to the best measurement are obtained. Wavelet features may be extracted from the wavelet coefficients. This function uses three parameters such as standard deviation (σ), skewness (χ), and kurtosis (к).
5 Results and Discussion
In this study, one-on-one SVM is utilized to complement the diagnosis of multiple faults in EMS. A total of 80 datasets containing statistical data are split into training and testing subsets, with 80% utilized for training and 20% for testing. SVM training is conducted for each speed and load condition, using the training data for each fault. It should be noted that the RBF kernel is employed for SVM training, which involves two initial hyperparameters: kernel parameter γ and Lagrangian multiplier C. These parameters need to be optimized for error detection. In this study, grid search and cross-validation methods are used to fine-tune these two measures. Various combinations of (C, γ) are attempted, and the one that produces the greatest level of accuracy or education is chosen. This optimization process is performed for each wavelet feature one at a time. Figure 3 illustrates the optimization of (C, γ) during training at 10 Hz ramp-up and high torque condition, showing that the SVM training accuracy is 82.5%. It should be noted that the final estimate may be influenced by the training of the distributor. Once the best (C, γ) pair is selected, it is used for the final training. The SVM model that has been trained is then utilized to categorize or detect ten faults. The SVM prediction function is represented by the percentage of the predictive value, which is the number of successful test data among all the test data.

Cross-validation accuracy for 40 Hz and T2 load
In the next step, the SVM model is evaluated at the same velocity and load conditions as during training. The selected wavelet features are fed one by one, and diagnosis is performed. The solution is evaluated by checking the performance of various functions of the IM, including four ramp-up and two torque conditions. Three main features, namely, standard deviation (σ), kurtosis (к), and skewness (χ) are utilized in this work. Fault detection is initially carried out in the zero load environment, and the outcomes are presented in Fig. 4a. The lowest accuracy achieved is 70.7%, while the highest accuracy is 99.3%, both of which are obtained at 40 and 10 Hz. All faults, except SWF_HR and SWF_UR, were successfully classified for all speeds with more than 80% accuracy. The average classification accuracy based on the no-load condition is 87.3%.

Result for present diagnosis
The analysis was also performed for high load conditions, and the results are presented in Fig. 4b. The lowest and highest classification accuracies achieved were 94% and 66%, which were obtained at 20 and 40 Hz ramp-up conditions, respectively. All faults, except MBF_UR, MBF_HR, and SWF_HR, were successfully classified for all speeds with more than 80% accuracy. The overall mean performance at high torque conditions was 85.5%. This indicates that the dispersion of misclassifications is slightly higher, by around 2%, in high torque conditions compared to no-torque conditions. In general, the identification of faults using the three main features of Haar wavelets was successful in predicting the faults even at different load levels.
6 Conclusions
Here, Haar wavelet features are calculated to evaluate combined defects of EMS using OAO SVM technique. Three characteristic standard deviations, skewness, skewness, and signal current are used for EMS diagnostics. Finally, diagnostics were performed for various speed tests at mechanical loads under different engine conditions, to determine the diagnostics of the EMS in an emergency. The average performance is 85.5 and 87.5% for high and zero load environment, individually. This study presents that the integration of wavelet properties & SVM can detect EMS defects at all loads, even at ramp-up speeds. Here, single Haar wavelet was utilized in EMS defect analysis, but Shannon, Gaussian, and other wavelet functions may be further utilized.
References
Bazzi AM, Krein PT. Review of methods for real-time loss minimization in induction machines. IEEE Trans Ind Appl. 2010;46(6):2319–28.
Henao H, Capolino GA, Fernandez-Cabanas M, Filippetti F, Bruzzese C, Strangas E, Hedayati-Kia S. Trends in fault diagnosis for electrical machines: a review of diagnostic techniques. Ind Electron Mag IEEE. 2014;8(2):31–42.
Nandi S, Toliyat HA, Li X. Condition monitoring and fault diagnosis of electrical motors-a review. IEEE Trans Energy Convers. 2005;20(4):719–29.
Lee S, Bryant MD, Karlapalem L. Model-and information theory-based diagnostic method for induction motors. J Dyn Syst Meas Contr. 2006;128(3):584–91.
Alsaedi MA. Fault diagnosis of three-phase induction motor: a review. Optics. Special Issue: Appl Opt Signal Process. 2015;4(1–1):1–8.
Thomson WT, Orpin P. Current and vibration monitoring for fault diagnosis and root cause analysis of induction motor drives. In: Proceedings of the thirty-first turbomachinery symposium. 2002. p. 61–7.
Bilski P. Application of support vector machines to the induction motor parameters identification. Measurement. 2014;51:377–86.
Siddique A, Yadava GS, Singh B.. Applications of artificial intelligence techniques for induction machine stator fault diagnostics: review. In: Diagnostics for electric machines, power electronics and drives, 2003. SDEMPED 2003. In: 4th IEEE international symposium on. IEEE; 2003. p. 29–34.
Tran VT, Yang BS, Oh MS, Tan ACC. Fault diagnosis of induction motor based on decision trees and adaptive neuro-fuzzy inference. Expert Syst Appl. 2009;36(2):1840–9.
Li L, Mechefske CK. Induction motor fault detection and diagnosis using artificial neural networks. Int J COMADEM. 2006;9(3):15.
Salem SB, Bacha K, Chaari A. Support vector machine based decision for mechanical fault condition monitoring in induction motor using an advanced Hilbert-Park transform. ISA Trans. 2012;51(5):566–72.
Gangsar P, Tiwari R. Diagnostics of mechanical and electrical faults in induction motors using wavelet-based features of vibration and current through support vector machine algorithms for various operating conditions. J Braz Soc Mech Sci Eng. 2019;41(2):71.
Ali Z, Gangsar P, Chouksey M, Parey A. Intelligent and robust fault diagnostics for an electromechanical system using vibration and current signals. In: International conference on future technology (ICOFT)-2020. NIT; Puducherry:2020.
Yu M, Xiao C, Jiang W, Yang S, Wang H. Fault diagnosis for electromechanical system via extended analytical redundancy relations. IEEE Trans Industr Inf. 2018;14(12):5233–44.
Gangsar P, Tiwari R. Signal based condition monitoring techniques for fault detection and diagnosis of induction motors: a state-of-the-art review. Mech Syst Signal Process. 2020;1(144): 106908.
Chouhan A, Gangsar P, Porwal R, Mechefske CK. Artificial neural network–based fault diagnosis for induction motors under similar, interpolated and extrapolated operating conditions. Noise Vib Worldw. 2021;6:09574565211030709.
Vapnik VN. An overview of statistical learning theory. IEEE Trans Neural Netw. 1999;10(5):988–99.
Hsu CW, Lin CJ. A comparison of methods for multiclass support vector machines. IEEE Trans Neural Netw. 2002;13(2):415–25.
Rafiee J, Rafiee MA, Prause N, Tse PW. Application of Daubechies 44 in machine fault diagnostics. In: 2nd international conference on computer, control and communication, 2009. IC4 2009. IEEE;2009. p. 1–6.
Peng ZK, Chu FL. Application of the wavelet transform in machine condition monitoring and fault diagnostics: a review with bibliography. Mech Syst Signal Process. 2004;18(2):199–221.
Acknowledgements
We are thankful to NPIU (a project of Education ministry of India & the World Bank) for funding research through the Collaborative Research Program. The ID number is 1-5770792503.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Gangsar, P., Singh, V., Chouksey, M., Parey, A. (2023). Machine Learning-Based Fault Prediction of Electromechanical System with Current and Vibration Signals. In: Tiwari, R., Ram Mohan, Y.S., Darpe, A.K., Kumar, V.A., Tiwari, M. (eds) Vibration Engineering and Technology of Machinery, Volume I. VETOMAC 2021. Mechanisms and Machine Science, vol 137. Springer, Singapore. https://doi.org/10.1007/978-981-99-4721-8_21
Download citation
DOI: https://doi.org/10.1007/978-981-99-4721-8_21
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-4720-1
Online ISBN: 978-981-99-4721-8
eBook Packages: EngineeringEngineering (R0)