
Abstract
The automated operation of Unmanned Aerial Vehicles (UAVs) has become increasingly important, and one key step in the procedure is the accurate landing of such vehicles. A major problem is that when trying to design a control algorithm for the landing procedure, it is difficult to accurately measure the 3D pose of the vehicle with respect to the local environment. Three dimensional pose estimation and subsequent corrections in velocity to design the control system was omitted by using an image-based visual servoing controller. Another important development is choosing the appropriate visual features which ensures convergence to desired position. The proposed controller with image moments as features was able to converge and land the vehicle accurately using only the image moments as the visual features from two fiducial markers without any local position or global position information. The proposed method has been verified using simulations considering an existing model of UAV.
Riby Abraham Boby and Alexandr Klimchik were supported by RSF research grant No. 22-41-02006.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Unmanned aerial vehicles (UAVs) have many useful applications ranging from surveillance [1], search [2], agriculture [3] to border patrol [4], and mapping [5]. In these applications, fully autonomous UAVs play an important and key role, because they perform tasks without the guidance of humans. The majority of drones come with a variety of sensors, including Inertial Measurement Units (IMUs), GPS, compasses, barometers, monocular, stereo cameras, and LIDAR sensors, among others. These sensors are used to localize the drone and to gather information about the surroundings in order to map or avoid the various obstacles around the drone. The key point is to ensure that the drone has a high autonomy level with the use of robust and reliable navigation systems [6] and accurate localization. An important requirement to achieving this level of autonomy is to guarantee the takeoff as well as the landing phases to be totally autonomous. More importantly during the landing phase, the vehicle has to land safely on the landing platform [7]. There are two kinds of landing sites, the first one is that which is known to the vehicle before hand and the vehicle should reach it with the local positioning information [8]. The second kind is that where the vehicle has to land in unseen or unknown environments [9]. In the first kind, the landing site is made from easily recognizable marker or markers so that it can be easily detected when the vehicle has reached the boundary of the landing site. The landing phase then is activated when the camera detects the special characteristics of the marker. In the second kind, the criteria of flatness, spaciousness, and surface robustness are used to determine the best landing places. Landing platforms are used for the first case where we know before hand the special characteristics of the platform and use it to perform the landing strategy. One of the most promising methods for extending the operational range of UAVs with the least amount of vehicle modification is to use landing platforms. Additionally, automatic landing platforms could carry out tasks like picking up or loading goods, data exchange and processing, etc., in addition to the battery charge or replacement function [10]. There are two types of landing platforms which are the stationary type and the moving type. This work will focus on the first kind of landing site, which will be a set of markers known beforehand, and the platform will be stationary.
There are solutions in the literature based on motion capture systems [11] or other sensors [12]. Additionally, several articles on moving targets focused on how a flying aircraft and a ground vehicle worked together to plan the landing maneuver [14, 15]. In this work however, it is assumed that the vehicle has no communication with the platform. Another article [16] demonstrates an onboard computer vision system for estimating a UAV’s pose in relation to a landing target based on a coarse-to-fine approach using a monocular camera. Different methods can be thought of to land the drone after detecting the marker of the landing platform such as image-based visual servoing [17, 18] which involves the use of computer vision data to regulate a robot’s movements. Though popularly used methods rely on calculating the pose of the drone after detecting the landmark and then transforming the pose from 3D camera coordinates into 3D world coordinates, it might lead to unnecessary errors if the camera is not calibrated properly. Some of these steps can be skipped with the help of visual servoing. The control needs to be modified to get the 2D image coordinates as input; this will make the process more robust to tiny calibration errors, which will be significant while transforming into world coordinates.
2 Methodology
In Image Based Visual Servoing (IBVS) [17, 18], the time variation \(\boldsymbol{\dot{s}}\) of the visual features \(\textbf{s}\) can be linearly expressed with respect to the relative velocity of the camera \(\mathbf {v_c}\). The control is created to ensure that the visual features decouple exponentially to reach the required value \(\mathbf {s^*}\), where \(\mathbf {L_s}\) is the interaction matrix associated with \(\textbf{s}\), and considering an eye-in-hand system observing a static object, then
where \( {\mathbf {\widehat{L}_s}^\dagger }\) is an approximation of \(\mathbf {L_s}\) and its pseudo-inverse, \(\lambda \) is a positive gain responsible for the time to convergence. Given the mounting details and the UAV’s center of mass, this velocity twist vector needs to be rotated and translated.
The key here is the selection of the visual features to ensure the convergence of the controller to the desired position, one might select the individual corner points of an aruco markers as visual features, but the image moments of that marker were chosen instead. The reason is that image moments provide general representation of any object that can be segmented in an image. They are also more intuitive and meaningful than just the corners of an object [19, 20]. For a discrete set of n image points, the moments \(m_{ij}\) and and the centered moments \(\mu _{ij}\) are defined by [21]:
where n is the number of image points, \(x_g = \frac{m_{10}}{n}\), \(y_g = \frac{m_{01}}{n}\) and \(m_{00} = n\). It is known that these centered moments are invariant to 2D translational motion.
Next, interaction matrix may be defined. If planar objects are taken into account and for each object point, the degenerate case when the camera optical center is on the plane is excluded \(1/Z = A x + B y + C\). For any point in the image, the velocity \(\boldsymbol{x_k}\) is given from [17]. Using 1 to set \(s = \boldsymbol{x_k}\) we obtain:
The first two components of the interaction matrix that relate \(x_g\) and \(y_g\):
From the observations taken from [21], the centered moments will be invariant to tranlsational motions if \(A = B = 0\) that happens when the object and the image plane are parallel to each other.
In [19, 22], to control the three translational motions these visual features have been selected: \(x_g\), \(y_g\) the center of gravity and the area of the object in the image a. Based on [21] the interaction matrix can be expressed as
A modification to this interaction matrix will be made by adding normalization in the form \(a_n = z^* \sqrt{\frac{a^*}{a}}, \, \,x_n = a_n x_g , \, \, \text {and} y_n = a_n y_g\), where \(a^*\) is the desired area of the object in the desired image, and \(z^*\) is the desired depth between the camera and the object in the image. The resulting interaction matrix elements after the modification will be
This new interaction matrix has a decoupling property to control the three translational velocities, and the three features have the same dynamics. For discrete objects, since \(\mu _{20} + \mu _{02}\) is invariant to 2D rotation and translation [21] \(a = \mu _{20} + \mu _{02}, \, \, a^* = \mu _{20}^* + \mu _{02}^*\). Since the high-level control of the drone can only control 4 dofs, \(v_x\), \(v_y\), \(v_z\) and yaw rate, so we will keep only those columns from the full interaction matrix resulting in
In [19, 22], to control the three rotational motions, these visual features have been selected: the orientation of the object in the image \(\alpha = \frac{1}{2} \arctan 2({{2\mu _{11}},({\mu _{20}-\mu _{02}}}))\) and two moment invariants \(c_i\), \(c_j\) chosen from combination of image momments that are invariant to 2D translation, rotation, and scale. A modification to the general form of the orientation of the object has been made to be specific to the orientation of the fiducial marker. The algorithm detects the four corners with a fixed order, the new angle will be the angle between the first corner, and the third corner of the detected marker: \( \alpha = \arctan 2(({y_2 - y_1}),({x_2 - x_1}))\). The interaction matrix has the following form:
Since we only need to control the yaw rate, only the last row with the 4th and 5th columns removed will be used i.e., \( L_{\alpha } = \begin{bmatrix} 0 & 0 & 0 & -1 \end{bmatrix}\). Finally, the following interaction matrix will be used in the IBVS approach based on our 4 DOFs high-level control:
The full set of new visual features \( s = [x_n,\, y_n,\, a_n,\, \alpha ] \) and the corresponding error vector \(e = \begin{bmatrix} x_n - z^*x_g^* & y_n - z^*y_g^* & a_n - z^* & \alpha - \alpha ^*. \end{bmatrix}^T\)
The following approximation to the interaction matrix has proven to have a good performance in practice [18, 23] \( {\mathbf {\widehat{L}_s}^\dagger } = \frac{1}{2} ( L_{s(s)}^\dagger + L_{s(s^*)}^\dagger ) \), where \(L_{s(s)}^\dagger \) is the interaction matrix computed from the measured features, while \(L_{s(s*)}^\dagger \) is computed from the desired features.
According to the findings of [26], the velocity components created by the controller employing this interaction matrix do not have significant oscillations and give a smooth trajectory in the image and in three dimensions. The gain \(\lambda \) in the proposed controller is adaptive, which means the error value controls the magnitude of the gain \(\lambda = (\lambda _{\max } - \lambda _{\min })(\frac{||{e}||}{||{e_{\max }}||}) + \lambda _{\min }\), where \(\lambda _{\max }\), \(\lambda _{\min }\) are the maximum and minimum values of the gain respectively. At time t, \(||{e}||\) is the norm of the error vector and at the start of the program, \(||{e_{\max }}||\) is defined as the max. error in the control loop according to [25], where the authors show the effect and smoothness of adaptive gains in different visual servoing scenarios. This was adopted in this work.

Iris drone and fiducial markers
3 Evaluation and Discussion
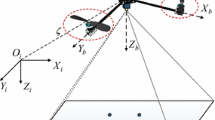
The current environment contains an Iris drone [27] inside a Gazebo world, equipped with a down-facing camera and two ArUcO markers with sizes 0.176 and 0.05 m, respectively, the code was written as a ROS package [24]. The environment is depicted in Fig. 1. The first marker will localize the drone at a \(h= 0.6\) m and centered with respect to the marker, and the second marker will localize it with \(h=0.25\) m and centered. The threshold of the norm of error was empirically chosen as 0.1 m and 0.015 m.
The algorithm will do the following: Firstly, detect the larger ArUcO marker in order to localize the drone at the desired \(h=0.6\) m. Once detected, the IBVS module will initialize and recursively guide the drone to the desired location until the error threshold is reached. Second, once the first error threshold is reached and the second marker is detected, the IBVS module will initialize again with the new parameters to recursively guide the drone to the next desired location at \(h=0.25\) m. Later, once the second error threshold is reached, the motors are turned off for landing.

Landing algorithm with IBVS
In the main experiment, the value of the parameters: \(\lambda _{\max } = 1.0 \) and \(\lambda _{\min } = 0.5\). The drone starts at the world position \(x = \begin{bmatrix} 0.2 & 0.2 & 2 \end{bmatrix}\), with the positions measured in meters. The desired height for the first marker is \(h=0.6\) m and the final position of the drone is \(x = \begin{bmatrix} 0.205 & 0.203 & 0 \end{bmatrix}\). The results of the IBVS algorithm for each marker in the experiment are shown in Fig. 2a–c for marker 1 and Fig. 2d–f for marker 2.

Simulation results
In case of rough localization, we can see that the controller converges with decoupled error and reaches the error threshold in about 8 s with the low maximum gain, the trajectories are also smooth and there are no irregularities in the control signal. While using second marker in the stage of fine localization, from the data in the graphs we can notice the noisy nature of the drone and the problem becomes much harder for the controller due to the low error signal and the fine-positioning required to land. The system is converged in about 6 s.
4 Conclusion
This article proposed an image-based visual servoing controller for UAV that was able to converge and land the vehicle accurately using only the image moments as the visual features from two fiducial markers. This could be done without any local position or global position information helping the controller. The only step needed before the deployment of the controller is the learning step of the desired height and image moments that will be used as a reference for the controller. Once the desired image moments and height are known, the controller will stabilize and guide the drone to land on the predefined set of markers. The convergence of the UAV to the desired position has been verified through simulations. In the future, the methodology may be extended to handle a moving platform and land on it.
References
Geng L, Zhang Y, Wang J, Fuh J, Teo A (2013) Mission planning of autonomous UAVs for urban surveillance with evolutionary algorithms. In: 10th IEEE international conference on control and automation (ICCA), pp 828–833
Waharte S, Trigoni N (2010) Supporting search and rescue operations with UAVs. In: Emerging security technologies (EST), pp 142–147
Herwitz S, Johnson L et al (2004) Imaging from an unmanned aerial vehicle: agricultural surveillance and decision support. Comput Electron Agric 44(1):49–61
Girard AR, Howell AS, Hedrick JK (2004) Border patrol and surveillance missions using multiple unmanned air vehicles. In: 43rd decision and control, vol 1, pp 620–625
Nagai M, Chen T, Shibasaki R, Kumagai H, Ahmed A (2009) UAV-borne 3-d mapping system by multisensor integration. IEEE Trans Geosci Rem Sens 47(3):701–708
Kendoul F (2012) Survey of advances in guidance, navigation, and control of unmanned rotorcraft systems. J Field Rob 29(2):315–378
Kong W, Zhou D, Zhang D, Zhang J (2014) Vision-based autonomous landing system for unmanned aerial vehicle: a survey. In: 2014 MFI, pp 1–8
Lange S, Sunderhauf N, Protzel P (2009) A vision based onboard approach for landing and position control of an autonomous multirotor UAV in Gps denied environments. In: 2009 international conference on advanced robotics, pp 1–6
Mukadam K, Sinh A, Karani R (2016) Detection of landing areas for unmanned aerial vehicles. In: ICCUBEA, pp 1–5
Feng Y, Zhang C, Baek S, Rawashdeh S, Mohammadi A (2018) Autonomous landing of a UAV on a moving platform using model predictive control. Drones 2:34
Mellinger D, Shomin M, Kumar V (2010) Control of quadrotors for robust perching and landing. In: International powered lift conference, pp 205–225
Sharp CS, Shakernia O, Sastry S (2001) A vision system for landing an unmanned aerial vehicle. ICRA 2:1720–1727
Herisse B, Russotto F, Hamel T, Mahony R (2008) Hovering flight and vertical landing control of a vtol unmanned aerial vehicle using optical flow. In: IROS, pp 801–806
Daly JM, Ma Y, Waslander SL (2015) Coordinated landing of a quadrotor on a skid steered ground vehicle in the presence of time delays. Auton Robots 38(2):179–191
Ghamry KA, Dong Y, Kamel MA, Zhang Y (2016) Real-time autonomous take-off, tracking and landing of UAV on a moving UGV platform. In: 24th mediterranean conference on control and automation, pp 1236–1241
Patruno C, Nitti M, Petitti A, Stella E, D’Orazio T (2019) A vision-based approach for unmanned aerial vehicle landing. J Intell Robot Syst 95
Hutchinson S, Hager G, Corke P (1996) A tutorial on visual servo control. IEEE Trans Robot Autom 12:651–670
Chaumette F, Hutchinson S (2007) Visual servo control. I. Basic approaches. Robot Autom Mag 13:82–90
François C (2004) Image moments: a general and useful set of features for visual servoing. IEEE Trans Robot 20(4):713–723
Chaumette F (2002) First step toward visual servoing using image moments. IROS 1
Omar T, Francois C (2005) Point-based and region-based image moments for visual servoing of planar objects. IEEE Trans Robot 21(6):1116–1127
Corke Peter I, Hutchinson Seth A (2001) A new partitioned approach to image-based visual servo control. IEEE Trans Robot Autom 17(4):507–515
Malis E (2004) Improving vision-based control using efficient second-order minimization techniques. In: ICRA, vol 2
Anis K (ed) (2017) Robot operating system (ROS), vol 1. Springer, Cham
Olivier K, François C (2013) Dealing with constraints in sensor-based robot control. IEEE Trans Robot 30(1):244–257
Bastourous M et al (2020) Image based visual servoing for multi aerial robots formation. In: 28th mediterranean conference on control and automation (MED)
Pisa S et al (2018) Evaluating the radar cross section of the commercial IRIS drone for anti-drone passive radar source selection. In: 22nd international microwave and radar conference
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Hegazy, M., Boby, R.A., Klimchik, A. (2024). Localization of a Drone for Landing Using Image-Based Visual Servoing with Image Moments. In: Ghoshal, S.K., Samantaray, A.K., Bandyopadhyay, S. (eds) Recent Advances in Industrial Machines and Mechanisms. IPROMM 2022. Lecture Notes in Mechanical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-99-4270-1_13
Download citation
DOI: https://doi.org/10.1007/978-981-99-4270-1_13
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-4269-5
Online ISBN: 978-981-99-4270-1
eBook Packages: EngineeringEngineering (R0)