
Abstract
Feature dimensionality reduction can remove redundant and useless information in data and improve the accuracy of pattern recognition. Based on this, a face image recognition algorithm based on singular value decomposition is proposed. Firstly, the feature extracted data is decomposed by SVD, and the top N values with the largest feature are retained, and the sample data after feature reduction is obtained. Then, through calculation, the category corresponding to the maximum similarity is determined, and the similarity recognition of face images based on data dimensionality reduction is realized. Through experiments on the face image data set, the experimental results show that the algorithm has a good effect.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


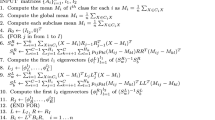
Keywords
1 Introduction
Face recognition [1] is a biometric identification technology [2] based on human facial feature information, which uses computer technology for analysis and comparison to identify faces. In the application of face recognition, the required facial feature information can be extracted by the computer. The quality of the image features determines the expression of the image information and the accuracy of the final recognition. In order to improve the effectiveness of feature expression, fine-grained description of images is required, but with the deepening of image analysis, the problem of increased feature dimension will arise, resulting in a dimensional disaster. The increase of the image dimension will also face the increase of invalid features. In order to solve this problem, it is necessary to perform feature dimension reduction [3, 4] on the collected features. In order to improve the features in the image and improve the stability of the feature information expression. Singular Value Decomposition (SVD) [5,6,7] is used to reduce the dimension of face image features, and transform the original features by transforming the original features.
In terms of image classification, ORL face image dataset is used, and each dataset corresponds to a label category. A face image recognition algorithm based on singular value decomposition is proposed. Firstly, SVD is used to calculate the singular value of the original image feature data, and the first k singular values are selected to realize feature dimension reduction. Then, the data after dimensionality reduction is used as input, and the calculation is carried out through the cosine similarity model. The final maximum similarity is the category corresponding to the predicted image. The experimental results show that the algorithm can effectively predict the image category and realize the calculation of the similarity measure of the image.
2 Related Works
2.1 SVD Algorithm
Assuming that there is a training matrix \(A\in {R}^{m\times n}\) containing m samples and n features, there is a decomposition that satisfies:
So the original matrix A is decomposed into the product of \(U\), \(\Sigma\), \({V}^{T}\) matrices, we define this as singular value decomposition. This decomposition process is called singular value decomposition. According to the principle of principal components, the larger the value of SVD, the more information it contains. Based on this idea, only the first k features are important, and the rest are unimportant features. Therefore, singular value decomposition can be used for dimensionality reduction or denoising processing of data to achieve the extraction of important features in the data.
2.2 Cosine Similarity Metrics
Two vectors are determined by calculating the cosine value of the cosine similarity [8] to determine whether they are similar. For two vectors A and B, \({A}_{i}\) and \({B}_{i}\) are the respective components of A and B, and the calculation formula is:
Since the similarity between images is only positive correlation, the cosine value of cosine similarity is [0,1]. The higher the similarity of two vectors, the closer the cosine value is to 1. The more the cosine value tends to 0, the lower the similarity of the vector.
3 Face Image Recognition Based on SVD and Cosine Similarity
3.1 Face Image Data Dimensionality Reduction Processing Based on SVD
For the image features matrix R, R is an m × n face feature matrix, and the SVD decomposition method is used to decompose the matrix R into the product of three matrices, as shown in formula (3):
Among them, U is regarded as an m \(\times\) r orthogonal matrix, V is regarded as an r \(\times\) n orthogonal matrix, S is regarded as a diagonal matrix, and the elements on the diagonal are singular values. The first singular value is the largest, which represents the direction that contains the most information. With the change of the singular value, the content of useful information in the data also changes. Therefore, using the first k values can effectively describe the sample data set and realize the dimensionality reduction of the data set.
In the data dimensionality reduction method, the matrix singular value feature can realize local feature extraction and dimensionality reduction of high-dimensional features. At the same time, singular value decomposition has the data processing ability under the global optimum, because the top 20% to 30% of the largest eigenvalues can effectively retain most of the information of the data set, so this paper uses SVD for the face [9, 10] image feature data set to realize the data analysis. The dimensionality reduction process of SVD calculates the eigenvalues of the multi-label feature data, and retains the top 20% of the largest eigenvalues to realize the dimensionality reduction of the feature data by SVD.
The original data set R is an m \(\times\) n matrix, which becomes RD after feature dimension reduction, and RD is an m \(\times\) k matrix, where k \(\ll\) n.
3.2 Image Classification Algorithm Based on Cosine Similarity
The algorithm selects the most similar class by measuring the similarity between the test images and target images. The basic idea is: for a given set of test images, through the cosine similarity measure [11], the features of the test images are compared with the features of the target images, and then the nearest k data are found as judgments, and the categories of these neighboring data are judged by probability accumulation. Finally, the label with the highest probability is given.
The matching experiments on images are designed to evaluate the similarity of images by optimizing the cosine similarity. The experiment is to calculate the cosine similarity of a test label corresponding to other labels, calculate all cosine similarities according to the label, and sum up the cosine similarity values of each label. Then, all labels are reordered to establish the horizontal axis, and the sum of cosine similarity is used to establish the vertical axis to generate a probability map similar to the label distribution. When inputting image data, the output is the image corresponding to the maximum value of the sum of cosine similarity.
4 Experiment and Result Analysis
4.1 Experimental Dataset
In order to analyze the experimental performance of the algorithm, the ORL dataset (http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html) of Cambridge University is selected for experiments in this paper. The dataset contains 40 face images of different ages and genders. Each group represents 10 different pose photos of the same person. These 10 face images are collected from the same person with different facial expressions and from different angles.
4.2 Experimental Results and Analysis
Experimental Program 1:
Experiments are performed on real datasets. Choose one image from each category as the test set, and all the remaining images as the comparison data. In order to show the difference between the original data and the dimensionality reduction data, the prediction results of each category are displayed. The experimental results are shown in Figs. 1, 2.

Experimental comparison of different data on test image 31

Experimental comparison of different data on test image 32
Figures 1, 2 show the experimental results of the original data and the dimensionality reduction data on the test images. For intuitive display, the pictures of the same group of prediction categories are displayed, which can more intuitively explain the accuracy of the prediction results. The experimental results in Fig. 1 show that the use of SVD algorithm for data dimensionality reduction can accurately predict the category of the image, which shows that face image recognition based on SVD algorithm can effectively improve the model prediction accuracy. The experimental results in Fig. 2 show that both the original data and the dimensionality reduction data can be used to accurately predict the experimental results, but through the analysis of the predicted numerical distribution [12, 13], it can be seen that the data processed by dimensionality reduction has better distinguishability and can be accurately segment the predicted category with other categories to better complete data prediction.
Experimental Program 2:
Experiments were compared on the ORL dataset using 10-fold cross-validation. The dataset was randomly divided into 10 parts for experiments. Record the mean and standard deviation of the original data and the dimensionality-reduced data in terms of prediction accuracy, and the results are as follows.

10-fold cross-experiment comparison between different data (plot)

10-fold cross-validation experiment comparison with different data dimensions
Figures 3, 4 show the experimental results of ten-fold crossover between the original data and the reduced-dimensional data. Figure 3 shows the result display of the original data and the dimensionality reduction data by means of ten-fold crossover. The experiment shows that in the ten experiments, the SVD feature dimensionality reduction data is better than the original results 5 times, and the other 4 times the results are the same as the original results. Figure 4 shows the experimental comparison between original data and dimensionality-reduced data in different dimensions. Experiments show that in the data dimension reduction experiment, when the dimension is 14, the prediction accuracy of the original data and the dimension-reduced data is the same. When the dimension is greater than 15, the experimental precision of the matrix factorization dimension reduction is better than the original data, and with the dimension increases, the prediction accuracy approaches 1 and tends to stabilize.
5 Conclusion
In this paper, a similarity metric recognition of face images based on singular value decomposition is proposed. Attribute reduction is performed on the original data through SVD, and similarity measurement is performed on the processed features. Compared with the original data set, the results show that the algorithm has a good effect, and can accurately predict the label of the image in the real prediction.
This paper focuses on the impact of data dimensionality reduction on the results of image similarity measurement. In the follow-up research, different methods will be considered for dimensionality reduction analysis of image features.
References
Zhi, H., Liu, S.: Face recognition based on genetic algorithm. J. Vis. Commun. Image Represent. 58, 495–502 (2019)
Kute, R., Vyas, V., Anuse, A.: Transfer learning for face recognition using fingerprint biometrics. Journal of King Saud University - Engineering Sciences (2021)
Zebari, R., Abdulazeez, A., Zeebaree, D., et al.: A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J. Appl. Sci. Technol. Trends 1(2), 56–70 (2020)
Espadoto, M., Martins, R.M., Kerren, A., et al.: Toward a quantitative survey of dimension reduction techniques. IEEE Trans. Visual Comput. Graphics 27(3), 2153–2173 (2019)
Akritas, A.G., Malaschonok, G.I.: Applications of singular-value decomposition (SVD). Math. Comput. Simul. 67(1–2), 15–31 (2004)
Henry, E.R., Hofrichter, J.: [8] Singular value decomposition: Application to analysis of experimental data. Methods Enzymol. Academic Press 210, 129–192 (1992)
Chen, R., Pu, D., Tong, Y., et al.: Image-denoising algorithm based on improved K-singular value decomposition and atom optimization. CAAI Trans. Intell. Technol. 7(1), 117–127 (2022)
Gu, F., Lu, J., Xia, G., et al.: Face verification technology based on FaceNet similarity recognition network. In: 2021 IEEE 10th Data Driven Control and Learning Systems Conference (DDCLS), pp. 1362–1367. IEEE (2021)
Li, J., Qiu, T., Wen, C., et al.: Robust face recognition using the deep C2D-CNN model based on decision-level fusion. Sensors 18(7), 2080 (2018)
Kortli, Y., Jridi, M., Al Falou, A., et al.: Face recognition systems: a survey. Sensors 20(2), 342 (2020)
Saha, S., Ghosh, M., Ghosh, S., et al.: Feature selection for facial emotion recognition using cosine similarity-based harmony search algorithm. Appl. Sci. 10(8), 2816 (2020)
Wang, M., Feng, T., Shan, Z., et al.: Attribute and label distribution driven multi-label active learning. Appl. Intell. 52, 1–16 (2022)
Wang, Y., Tian, W., Cheng, Y.: Heterogeneous ensemble learning algorithm based on label distribution learning 32(10), 945–954 (2019)
Acknowledgment
This work was supported by Domestic Visiting Program for Outstanding Young Teachers in Colleges and Universities (gxgnfx2021154); Suzhou University Scientific Research Platform Open Project (2020ykf01); Key disciplines of computer science and technology (2019xjzdxk1); Top talent project of colleges and universities in Anhui Province (gxbjZD43); Natural science research project of Anhui Provincial Department of Education (KJ2018A0453); School-Level Scientific Research Platform of Suzhou University (2021xjpt51); Provincial Industrial College (2021cyxy069); Key project of Natural Science Research of Anhui Provincial Department of Education (KJ2021A1110); School level Industrial College of Suzhou University (szxy2021cxxy04); Anhui Province Natural Science Foundation (2022AH051372); Key Project of Natural Science Research in Universities of Anhui Province (2022AH051372).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Li, S., Tian, W., Tan, C., Lu, B. (2023). Research on Similarity Recognition of Face Images Based on Data Dimensionality Reduction. In: Liang, Q., Wang, W., Liu, X., Na, Z., Zhang, B. (eds) Communications, Signal Processing, and Systems. CSPS 2022. Lecture Notes in Electrical Engineering, vol 872. Springer, Singapore. https://doi.org/10.1007/978-981-99-2653-4_24
Download citation
DOI: https://doi.org/10.1007/978-981-99-2653-4_24
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-2652-7
Online ISBN: 978-981-99-2653-4
eBook Packages: EngineeringEngineering (R0)