
Abstract
Recent years have witnessed increasing attention to fall detection, powered by the strong demands of Intelligent EmergencyAssistance Systems (IEAS), as it is crucial to reduce incidents of serious injuries caused by falls. In this paper, we propose an IEAS, a framework that integrates deep learning-based fall detection and edge computing-based local processing. First, we introduce a novel challenging benchmark dataset, called WildFall, to better evaluate fall detection models in real-world environments. The WildFall consists of 2,000 various types of video clips, involving movies, TV series, and surveillance. Then, the conceptual design, modules, and practical implementation of IEAS are described in detail. Finally, we discuss and analyze the extensibility of IEAS and future work. We believe that both the proposed IEAS and the public availability of WildFall will attract more research attention, to provide timely emergency assistance for the injured.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Falls are a common but often overlooked, cause of injury, which may end in disability or even death in a split second. Falls may occur indoors or outdoors (Fig. 1(a)), most falls may not cause serious consequences, but older people are more vulnerable, especially if they have a long-term health conditions. The impact of falls on older people is not limited to psychological problems, abrasions, fractures, but also injury-related death. Every year, more than 8 million people (including 2.8 million elderly people) are treated in emergency rooms for fall-related injuriesFootnote 1. In particular, for people over 85 years of age, falls are the leading cause of about two-thirds of all reported injury-related deaths. This situation will continue to worsen since the number of people over the age of 60 may increase from the current 1 billion to 1.2 billion by 2025.
As a developing country, many elderly people in China lack necessary care. We sent 600 questionnaires to participants covering 19 provinces in China and got 400 valid questionnaires (203 male,197 female) aged from 55 to 97Footnote 2 As shown in Fig. 1(b), the statistical results show that nearly half of the participants have experienced a fall within three years, and the probability of being injured under the age of 60 is the only 9.5%, while the probability that being injured over the age of 70 is an impressive 66.23%.
Moreover, for participants with a fall experience, the probability of people over 70 being injured indoors is 43%, and the probability of people under 60 is only 9.5%. Obviously, for the elderly without supervision, the consequences of injuries indoors are more serious than those outdoors. In addition, we found that for elderly people, falls have not only caused physical injuries but also produced a huge medical cost for fall-related injuries. The average medical expenses reached 22,491 RMB (3473 USD).
The above shocking numbers prompted researchers to design applications, algorithms, and wearable devices to detect falls for timely rescue [1,2,3]. However, most methods are inefficient in common real-world environments, let alone harsh environments where falls are more likely to occur. The major challenges are summarized as follows:
 : Most of the fall datasets are collected in constrained environments. The fall video clips captured in the laboratory could not match well real-world environments, which limits the generalization ability, predictive precision, and efficiency of existing models trained on these datasets. In a real-world surveillance network, the diversity of lighting, backgrounds, resolutions, and views of video data will obviously have an adverse effect on deep models. Many researchers have found that changing background would greatly affect the overall performance of the vision-based fall detection systems. Moreover, when encountering harsh environments such as extreme weather and excessive dust, the performance of vision-based systems will deteriorate drastically. Although many fall detection methods can achieve high performance in MobiAct, SisFall, MobiFall, UniMiB SHAR, and UP-Fall datasets, RGB-Depth, radar, or accelerometer sensors used in these datasets are constrained by many factors such as price, popularity, and privacy sensitivity [4].
: Most of the fall datasets are collected in constrained environments. The fall video clips captured in the laboratory could not match well real-world environments, which limits the generalization ability, predictive precision, and efficiency of existing models trained on these datasets. In a real-world surveillance network, the diversity of lighting, backgrounds, resolutions, and views of video data will obviously have an adverse effect on deep models. Many researchers have found that changing background would greatly affect the overall performance of the vision-based fall detection systems. Moreover, when encountering harsh environments such as extreme weather and excessive dust, the performance of vision-based systems will deteriorate drastically. Although many fall detection methods can achieve high performance in MobiAct, SisFall, MobiFall, UniMiB SHAR, and UP-Fall datasets, RGB-Depth, radar, or accelerometer sensors used in these datasets are constrained by many factors such as price, popularity, and privacy sensitivity [4].
The vision-based approach seems more feasible, but the bottleneck is also obvious: as fall events typically occur at a much lower probability, it is usually difficult to collect sufficient fall clips in real-world environments. Manually screening and extracting fall clips from surveillance videos requires massive labor costs. Therefore, it remains a very challenging problem due to the serious imbalance between normal and fall samples, and the lack of fine-grained fall labeling data.
 : Generally, an intelligent sensor system consists of hundreds of sensors. Developing a deep learning-based intelligent sensing system requires a significant amount of storage to store large media files and powerful computational devices. Therefore, computational cost, storage, and long transmission distance are also important issues that need to be considered. Traditional intelligent sensor systems rely on a centralized server to process large-scale distributed sensing data. The City-scale sensor network may produce a huge amount of data every minute, most of them are redundant and do not contain fall events. If the centralized server is far away from the sensors, and sensors cannot provide the computational capabilities for further intelligent operations, the backbone network with limited capacity would inevitably lead to unpredictable delays. Therefore, for latency-sensitive tasks, how to reduce traffic and transmission delay is a key challenge. Simply increasing the number of servers to improve computing power not only can not fundamentally solve the problem of transmission delay but also needs more cost.
: Generally, an intelligent sensor system consists of hundreds of sensors. Developing a deep learning-based intelligent sensing system requires a significant amount of storage to store large media files and powerful computational devices. Therefore, computational cost, storage, and long transmission distance are also important issues that need to be considered. Traditional intelligent sensor systems rely on a centralized server to process large-scale distributed sensing data. The City-scale sensor network may produce a huge amount of data every minute, most of them are redundant and do not contain fall events. If the centralized server is far away from the sensors, and sensors cannot provide the computational capabilities for further intelligent operations, the backbone network with limited capacity would inevitably lead to unpredictable delays. Therefore, for latency-sensitive tasks, how to reduce traffic and transmission delay is a key challenge. Simply increasing the number of servers to improve computing power not only can not fundamentally solve the problem of transmission delay but also needs more cost.
Accordingly, the above-mentioned challenges motivate us to collect a fall dataset in real-world environments and design an intelligent emergency assistance architecture to improve the reliability of fall detection.

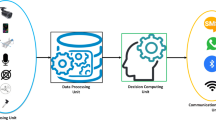
WildFall and Questionnaire statistics. Left:(a) WildFall is a large-scale benchmark for general multi-label fall detection. This screenshot of a dataset depicts a subset of videos in the dataset labeled with the fall entity.(b) questionnaires statistics aged from 55 to 97. Right: The IEAS architecture.
2 The WildFall Dataset
Various sensor devices, such as accelerometers, gyroscopes, RGB cameras, and radars, have been used to detect falling events. Among them, computer vision technology is the most straight and valid to detecting falls. However, vision-based fall detection has not received much attention due to the lack of large-scale fall datasets. Up until recently, the vast majority of computer vision research tackles fall detection or fall recognition as a subproblem of action recognition. In that case, the task is reduced to classifying the sequence into one of the relevant categories of the action. The action recognition task attempts to find a model that has low loss, on average, across all examples, which is called empirical risk minimization. However, one of the challenging factors of the multi-class classification model for fall detection is the data imbalance, meaning that the fall events are more difficult to capture than other regular events because of their scarcity in the real world. The above phenomena can be found in many motion recognition models, as the confusion matrix in [5] shows, fall instances are not only easily confused with their similar actions, such as staggering, but also misclassified into many categories with large semantic gap such as reading, tear up the paper and torch neck.
To this end, we introduce WildFallFootnote 3 a large-scale benchmark dataset with reasonable quality labels for multi-label fall detection. We gathered 50 trained volunteers for data collection. We assigned volunteers to 12 multimedia video platformsFootnote 4 to search for videos through given topics. After collecting the video, we extracted clips with complete fall events, and the maximum length of video clips is 8 s. To facilitate model training, in the pre-processing stage, we try to make the starting position of the target in the center of the image. In total, the WildFall dataset contains more than 2K video clips-over 269 min. For each fall video clip, the age range, scene (indoor or outdoor), and degree of injury are estimated and labeled. The multi-labeled data is very important to evaluate fall-related injuries, which could give the IEAS an initial warning priority. In addition to the fall video clips, we also collected five other challenging actions in real-world environments, including walking, jumping, going up, going downstairs, and creeping forward. Compared with the previous fall dataset collected in the laboratory scene, the proposed WildFall dataset is more realistic and challenging. The diversity of datasets is a necessary condition for the development of an intelligent emergency rescue system. We believe that a large scale and diverse dataset is a necessary condition for the development of an intelligent emergency rescue system.
3 Intelligent Emergency Assistance System and Implementation
Figure 1 shows the proposed IEAS architecture, which consists of four different layers: sensor layer, distributed intelligence platform, centralized layer, and service layer.
-
The sensor layer is composed of carry-on smart devices (including mobile phones, UAVs, tachographs, etc.), wired or wireless security camera devices, and network elements, which are used to generate heterogeneous sensing data from various sensing devices and then transfer to edge computing servers.
-
Distributed intelligent layer, as the core layer of IEAS, provides computing, storage, and communication resources between sensor devices and centralized mediation layers. This layer reflects the intelligent characteristics of the system, including deep learning-based pedestrian detection, fall detection, and edge processing.
-
The centralized layer includes: a cloud computing data center for aggregating perceptual data (video clips) from distributed intelligent layer; A database server that maintains historical sensory data, which can be used for incremental training of deep networks; Further, assess the injury based on the fall data provided by the distributed intelligence layer; If the sensing data comes from the mobile platform and the user cannot provide precise positioning, the centralized layer needs to request permission and use the wireless positioning technology based on the cellular network.
-
The service layer includes receiving and controlling a series of emergency requests submitted by the centralized layer, such as emergency medical rescue, emergency traffic control, etc.
In crowded scenes, passers-by can directly call or implement rescue. Therefore, an intelligent emergency rescue system is more suitable for sparsely populated or isolated scenes, where fall events are always hard to be detected, and untimely rescue will aggravate the injury or even lead to death.
4 Numerical Results
In this section, a fall detection case will be conducted on the WildFall dataset to evaluate the performance of the IEAS framework quantitatively. Firstly, in the pedestrian detection stage, we use Fast R-CNN as the backbone network to detect and estimate the bounding box of pedestrians and then rescale the image according to the size of the bounding box. Then, we use the OpenPose toolbox [6] to estimate the pose composing 18 key points for each person in the scaled images. Given the pedestrian skeleton data, we need to design a deep network that can identify fall events. As we all know, most CNN with local receptive fields may limit the ability to model the spatio-temporal context. Although RNNs can capture global context information, they are not hardware friendly requiring more resources to train. Therefore, we propose a deep network [7], named L2C (local to context) self-attention augmented model, which aims to aggregate spatial-temporal saliency of joints and frame dependencies from local-to-global.
A raw skeleton sequence can be expressed as \(X\in R^{C\times J\times F}\), where C, J, F denote the number of channels, joints, frames, separately. The coordinates of a joint in the \(f-th\) frame can be denoted as \(\left( x_{j,f},y_{j,f},z_{j,f} \right) \). The overall pipeline of the proposed model is shown in Fig. 2. The proposed whole L2C self-attention augmented model contains three self-attention augmented modules including the spatial convolution operator for encoding local information and the self-attention operator for encoding context information. The spatial convolution operator can obtain spatial features \({X_{Local}}\in R^{C_2\times J\times F}\) by aggregating local joint information. The self-attention mechanism models the global dependencies, by directly attending to all the positions in an input sequence, which can be utilized to compute the correlation between arbitrary joints of the input sequence. The input of the self-attention mechanism consists of queries \(Q\in R^{C_k}\), keys \(K\in R^{C_k}\) and values \(V\in R^{C_v}\). \({C_3}={C_v}+2{C_k}\) is the number of output channels of the previous embedding module. Then a softmax function is applied to the dot products of queries with keys and obtains a weights matrix on the values.
The attention weights here represent the correlation of each dimension’s features, which can capture long-range dependencies by explicitly attending to all the joints. In order to further complement the localness modeling and enhance the generalization ability of the model, we also use the multi-head mechanism in the self-attention block. After multi-head self-attention, we use the \(1\times 1\) convolution operator to encode the spatio-temporal features and then stack them with the output of the local convolution operator. In the experiment, the number of neurons (\(C_2\)) in the convolution operator is set to 68, and the embedding dimensional \(c3=100\); In multi-head self-attention module, the number of heads is set to 4, and the dimensional value, key, and a query is set to \({C_v}=60\), \({C_k}=20\), respectively. Before the classifier, we added the max-pooling layer to select better features for classification. We randomly split the hyperedge set into training and test sets by a ratio of 4 : 1. In addition to skeleton features, we use I3D to capture RGB features in videos. Finally, the skeleton feature and RGB feature are fused to produce the final result.

The architecture of L2C self-attention augmented model.
We first tested the proposed L2C self-attention augmented model on the NTU RGB+D dataset [8], and the detection accuracy of fall events (946 samples) can reach 96.4%. Next, we evaluate the I3D, proposed model, and Multi-modal fusion model (Pose+I3D) on the WildFall dataset. The results are shown in Table 1, which illustrates that in real-world environments, due to the influence of sensor resolution, backgrounds, illuminations, and other factors, pose features perform much better than RGB features, and feature fusion strategy can further improve the detection performance, but it still exists a certain gap with the results obtained from laboratory data. In particular, the injury estimation module of the centralized layer can also be implemented using a model with the same structure.
5 Conclusion
In this paper, we propose the IEAS to intelligently detect fall events in sparsely populated areas. First, we introduce a novel challenging benchmark dataset collected from the internet. The dataset named WildFall consists of 2,000 videos captured in real-world environments. Then, an intelligent architecture is proposed, including pedestrian detection, deep representation learning, and local processing. Finally, numerical experimental results show that the framework can intelligently detect fall events in real-world environments.
Notes
- 1.
- 2.
- 3.
The raw labeled data is publicly available and can be achieved from https://pan.baidu.com/s/1SRE4aD9iNnrmJh7AybBD7w.
- 4.
YouTube, TikTok, Tencent, iQiyi, Bilibili, Youku, Weibo, TuDou, Kuaishou, Ku6, Mango, RED Video.
References
Fáñez, M., Villar, J.R., de la Cal, E.A., Suárez, V.M.G., Sedano, J., Khojasteh, S.B.: Mixing user-centered and generalized models for fall detection. Neurocomputing 452, 473–486 (2021)
Wang, Y., Yang, S., Li, F., Wu, Y., Wang, Y.: Fallviewer: a fine-grained indoor fall detection system with ubiquitous wi-fi devices. IEEE Internet Things J. 8(15), 12455–12466 (2021)
Paolini, C., Soselia, D., Baweja, H., Sarkar, M.: Optimal location for fall detection edge inferencing. In: IEEE Global Communications Conference, GLOBECOM, pp. 1–6 (2019)
Casilari, E., Santoyo-Ramón, J.A., Cano-García, J.M.: Analysis of public datasets for wearable fall detection systems. Sensors 17(7), 1513 (2017)
Jiang, Y., Xu, J., Zhang, T.: View-independent representation with frame interpolation method for skeleton-based human action recognition. Int. J. Mach. Learn. Cybern. 11(12), 2625–2636 (2020)
Cao, Z., Hidalgo Martinez, G., Simon, T., Wei, S., Sheikh, Y.A.: Openpose: realtime multi-person 2d pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 43(1), 172–186 (2021)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Shahroudy, A., Liu, J., Ng, T., Wang, G.: NTU RGB+D: a large scale dataset for 3d human activity analysis. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR, pp. 1010–1019 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Li, Y. et al. (2023). Fall Detection in the Wild: An Intelligent Emergency Assistance System. In: Liang, Q., Wang, W., Liu, X., Na, Z., Zhang, B. (eds) Communications, Signal Processing, and Systems. CSPS 2022. Lecture Notes in Electrical Engineering, vol 872. Springer, Singapore. https://doi.org/10.1007/978-981-99-2653-4_10
Download citation
DOI: https://doi.org/10.1007/978-981-99-2653-4_10
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-2652-7
Online ISBN: 978-981-99-2653-4
eBook Packages: EngineeringEngineering (R0)