
Abstract
With malicious traffic occurring all the time, network intrusion detection remains a critical task. However, data imbalance in the network and the increasing number of unknown attack types make the detection difficult. Therefore, in this study, we propose an anomalous traffic detection method named CNN-CGAN, which achieves data equalization by a modified generative adversarial network (GAN) and uses an convolutional neural network (CNN) as the detection model. First, chi-square test is used to extract various types of features from network attack data to accelerate the convergence of the model. Then, we use a improved generative adversarial network to generate data with similar distribution to the small sample data to complete the data equalization. Finally, CNN effectively extracts data features for attack detection and classification. Experiments on the network security dataset NSL-KDD prove that the CNN-GAN model in this paper outperforms the classical detection models in performance indicators such as F1 score, precision and recall. In addition to this, the detection rate of unknown attacks and attack types is also higher with fewer samples.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
As modern technology develops by leaps and bounds and the continuous expansion of the network scale to the world, cyberspace has been in an important position as the fifth dimension [1]. However, more and more user devices access the network, which bring huge difficulty to the cyberspace. The emergence of complex and volatile cyber attacks makes the network security situation remains critical. Therefore, how to effectively detect and differentiate various intrusionshas become the key topic of network security researches.
Intrusion detection systems, as an active form of security protection, can carry out real-time monitoring of the network. It can better detect network attacks and provide relevant personnel with important response decisions [2]. In addition, it can also actively defend against network attacks, make corresponding actions before the network is compromised, and effectively maintain network security. In recent years, many new algorithms have been applied in the field of IDS to build relatively stable and high-accuracy intrusion detection systems. However, with the dramatic increase of network data, the bandwidth has enhanced significantly. In addition, the complex features and the diversity of information show an increasing number of new forms of attacks. Shallow machine learning (ML) that relies too much on feature learning is no longer able to handle massive network intrusion data [3]. Deep learning (DL) builds a nonlinear network system containing many hidden layers to learn the underlying laws of sample information. It not only satisfies high-dimensional research, but also has high efficiency. Therefore, deep learning has important value for processing traffic in the network.
In the face of increasingly sophisticated network attacks and massive amounts of high-dimensional data, traditional security techniques are gradually failing, and deep learning algorithms are gradually being applied to the field of network intrusion detection [4]. DL techniques can solve the problems of shallow learning algorithms in detection, effectively extract deep features in network data, and speed up model convergence. In recent years, DL-based intrusion detection methods have made phased progress, but a number of unresolved issues remain. For one thing, the traffic of normal behavior is often significantly larger than the traffic of abnormal behaviors in real network environments. In addition, the number of different attack types is unbalanced, resulting in poor detection of rare data by the model. For another thing, the complexity and diversity means of network attacks makes the existing detection techniques not well adapted to the current changing types of network attacks. Some new types of attacks also pose a major threat to network security, which has become a major problem in the application of deep learning in the field of intrusion detection [5, 6].
With the aim of solving the problem of low detection accuracy caused by new types of attacks and data imbalance in the network, this paper proposes an effective network anomaly detection model, CNN-CGAN, which combines the improved GAN with CNN. CNN-CGAN solves the class distribution imbalance problem by data augmentation and extracts the deep features in the network data by CNN, thus effectively improving the accuracy of the model in detecting attack data. The contributions of CNN-CGAN model proposed in the atricle are as follows:
-
(1)
Chi-square test performs feature screening on network data, extracts effective features in the network, and reduces confusion among various attack categories. In addition, feature selection can also accelerate model convergence and improve model training efficiency.
-
(2)
CGAN takes the real data and preset labels in the network as input, and completes data augmentation by generating specific types of attack data, thereby reducing the imbalance of the training set. In addition, synthetic data can be used to simulate unknown cyberattacks, helping to improve the performance of detection models in identifying minority and unknown attacks.
The rest of the study is structured as follows. We present the related work of intrusion detection. Section 3 presents an anomaly detection framework combining GAN and CNN. Section 4 analyzes the experimental results and the performance of the CNN-CGAN model. In Sect. 5, a conclusions is given.
2 Related Works
As machine learning develops by leaps and bounds, its classification techniques have been introduced as detection models for various network security monitoring. The authors in [7] introduced the detection performance and experimental results of various machine learning models including decision trees in intrusion detection. Reference [8] compared the differences between traditional ML and DL in intrusion detection, and showed that traditional methods can no longer effective in dealing with the big data environment, while deep learning can analyze large data and has a good classification effect. In [9], the authors proposed a recurrent neural network-based method for abnormal traffic identification, and investigated the effect of different learning rates on accuracy and training time in binary and multi-classification. Literature [10] realized an intrusion detection model based on gated recurrent unit (GRU) by analyzing the characteristics of intrusion detection data, which achieved detection accuracy comparable to Long short-term memory, and had shorter training and detection time.
However, the data in the network is unbalanced, with significantly more normal behavior traffic than abnormal traffic. This means that the detection model will focus more on normal behavior and less on the correct identification of a small number of samples. To address these issues, the methods used in existing research are generally to increase small number of samples, that is, oversampling technology, such as, random oversampling [11], SMOTE [12] and adaptive synthesis [13]. Reference [14] proposed a small-sample oversampling technique based on Radius-SMOTE, which used a safe radius distance to create synthetic data, reducing the overlapping problem of synthetic data. Besides, the authors of [15] studied an anomaly detection methods based on GAN and RF, and it successfully solved the overfitting problem in traditional oversampling techniques and exhibited good detection performance.
In a conclusion, the researches show that it is vital to obtain good training data to solve the sample imbalance problem, which remains a very challenging job in the current network traffic anomaly identification.
3 Methods
The intrusion detection method combining improved generative adversarial network and CNN proposed in the paper consists of two main parts: data processing and model training. The overall block-diagram is shown in Fig. 1.
3.1 Data Processing
This module consists of three parts, including data standardization, feature selection, sample equalization and data enhancement. The main role of this module is to perform feature selection and data balancing for the dataset used for the training of the model.

Overall block diagram of intrusion detection
Data Normalization. Data normalization mainly completes data cleaning, one-hot encoding, and data normalization, thus laying the foundation for later training. First, we remove the missing and invalid values from the dataset. Then, we convert the text types to numeric types since datasets often contain both numeric and string-type features, and machine learning cannot train on string-type data. Finally, some numerical data have large numerical differences, which may lead to problems such as slowing network convergence. Therefore, in order to reduce the influence of inter-indicator dimensions on the data analysis results, the data need to be normalized. The eigenvalues of the data are restricted between [0, 1] by using the max-min normalization method which can be described as follows:
where D is the original data that needs to be normalized, \({{D}_{\max }}\) and \({{D}_{\max }}\) are the feature minimum and maximum values in the dataset, respectively.
Feature Selection. The second step in data processing part of this paper is feature selection. According to the NSL-KDD dataset selected in the article, the attack data is divided into four types, namely, denial-of-service attack, port monitoring or scanning, unauthorized access from remote host, and privileged access by unauthorized local super users. Each piece of data in the dataset used in this paper consists of 41 features and 1 label.
Feature selection can improve model efficiency and detection accuracy, it removes label-independent features and reduces computational burden. The method chosen in this paper is the chi-square test, which can calculate the degree of deviation between the observed value of the statistical sample and the expected value, and reflect the degree of correlation between the label and the feature, so as to obtain the feature that needs to be retained. As shown in Eq. (2), M means the observed value, and E means the expected value. Features in the sample can correspond to the observed value, and the label category can correspond to the expected value. The stronger the correlation between observed and theoretical values indicates that the feature will have a greater impact on the label and the more important the feature is likely to be. Therefore, feature selection can be performed by calculating the cardinality value between the label and category and ranking them.
Data Imbalance. Data imbalance is the third step of data processing, which is used to solve the data imbalance problem that normal traffic is larger than abnormal traffic in the network data. In this paper, CGAN is used to generate rare data and to mix synthetic data with real data to disrupt the order for subsequent model training.
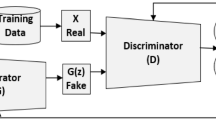
Generative Adversarial Network [16] draws on the idea of zero-sum game and consists of generator and discriminator, the specific structure is described in Fig. 2. The discriminator is a binary classifier consisting of a neural network that discriminates whether the input sample is real or fake. Similarly, the generator learns the latent distribution of real samples and is able to generate fake samples that approximate the distribution of real samples.

The network structure of GAN
The G and D of the GAN are trained by minimizing the Jensen-Shannon scatter between the false and true distributions, with the following objective function.
where \(\tilde{x} = G(z)\) is the synthetic data generated by the generator. z denotes the random noise data sampled from p(z). The original data distribution and the data distribution of the generated samples are represented by \({p_r}\) and \({p_g}\) respectively. The two neural networks are confronted with each other and iteratively optimized. First, the discriminator D is trained to improve the accuracy of the discriminated true and false data, and generator G is optimized to produce more realistic synthetic dates and deceive the discriminator D.
The generator of GAN can synthesize data based on random noise, but cannot generate specific types of data. Therefore, we add conditional constraints to the generator and discriminator based on GAN, which can use data and corresponding labels for training. As shown in Fig. 3, the generator and discriminator of CGAN add a label to the input, which can be specified to generate the desired type of samples, so the loss function of CGAN can be described as:
where y is the unique heat coded data for each attack category label in the data.

The network structure of CGAN
The CGAN model is built with keras. First, a generator for synthesizing data and a discriminator for judging the authenticity of the data are constructed, and then the model is connected and trained. Details as follows:

The network structure of generator and discriminator
-
(1)
Construction of generator and discriminator: The generator and discriminator in CGAN use fully connected networks, which mainly include Dense, LeakyReLU and BatchNormalization layer. As we can see, Fig. 4(a) is the network structure of the G, and its output layer uses the tanh function. Meanwhile, Fig. 4(b) is the structure of the discriminator, and its output layer is the sigmoid function. In this paper, random noise and labels are used as inputs to the generator, and synthetic samples are used as outputs. Specifically, it uses the embedding layer to convert the label into a dense vector with the same length as the random noise vector, and then uses the Multiply layer to multiply the label and the random noise vector as the generator’s input. The input of discriminator is a sample-label pair, and the output is the probability of whether the sample-label pair is true. The discriminator will take a label, use the Embedding layer to turn the label into a dense vector of sample length, and then use the Multiply layer to multiply the label and the sample as the input to the discriminator.
-
(2)
Model connection and training: The constructed generator and discriminator are trained against each other to build a complete CGAN model. The specific training process is as follows. First, we randomly initialize the model parameters, and control the generator G to remain unchanged, train the discriminator D, and use the Adam optimization algorithm as the optimizer to update the parameters in the network. Then, the training of the discriminator is suspended and the generator uses the feedback from the loss to the generator to complete the parameter update. Finally, when the loss value and cycle frequency do not reach the set thresholds, the steps of the first two steps are repeated, and the optimization gradient is updated using the Adam optimizer.
3.2 Model Training
This part uses CNN to complete the training of binary-class and multi-class model. The binary classification realizes the classification of normal traffic and abnormal traffic. Multi-classification identifies various attack types, and compares the detection accuracy of small samples before and after data balance. In addition, we continuously tune and optimize for better training results, improving the model’s accuracy and generalization ability.
4 Experiments
4.1 Metrics of Performance Evaluation
In order to study the impact of different optimization methods on the classifier, and effectively evaluate the performance of the classifier, we select 4 performance indicators that are widely used in most works, including accuracy, precision, detection rate (DR), F1 score. In addition, the confusion matrix is demonstrate in Table 1.
The accuracy is the most commonly used and most intuitive performance indicator. It represents the ratio of the correct samples predicted by the detection model to all samples. The higher the accuracy of the model classification, the better the classification performance. Its definition is described as Eq. (5):
DR or Recall represents the proportion of all actual positive samples that are predicted to be positive. The definition of DR is as Eq. (6):
The precision rate represents the proportion of all the samples classified as positive examples that are truly positive examples. The higher the accuracy, the better the performance of the classification model. It is described as Eq. (7):
F1 score is the recall and precision weighted harmonic average, also known as F-Score. In an imbalanced dataset, F1 can better measure the performance of the model (\(F1 \in [0,1]\)). F1 is defined as Eq. (8):
4.2 Dataset
The dataset selected in the experiment is the NSL-KDD dataset consisting of five categories, and the data distribution of each category is shown in Table 2. We can see that the original testing set and training set are highly unbalanced, with the least category in training set accounting for only 0.04%, and the test set data of R2L and U2R is much larger than the training set data. At the same time, there are many categories that do not emerge in the training set, which places a demand on the generalization ability of the model. The above problems further highlight the role of sample balancing and feature selection.
4.3 Model Performance Comparison
We split the NSL-KDD dataset into a training set and a test set for training and evaluating the model, respectively. The evaluation metrics of different classifier models on the dataset are shown in Fig. 5. We can see that the CNN-CGAN model proposed in this paper is higher than other intrusion detection systems in terms of accuracy, recall and F1 score. So the detection method proposed in this paper can effectively classify the anomalous traffic in the network and the accuracy of the classification is improved by 3%.

Performance comparison under different classification
Figure 6 displays the improvement of detection performance by different data enhancement models. It can be seen that data enhancement techniques have improved the detection accuracy and other performance. The detection effect of the model proposed in this paper is significantly improved. The experimental results show that the data equalization effect of CGAN is more effective than other methods.

Effects comparison of different data enhancement methods for detection.
From Fig. 7, we can see that CGAN has improved detection performance for all four categories. The smaller number of R2L and U2R categories have a larger performance improvement. Therefore, it can be concluded that cGAN has a high improvement in improving the detection accuracy of small samples.

Comparison of the detection performance of different models for various types of attacks
5 Conclusion
In this paper, we propose an anomaly identification method based on an improved generative adversarial network, which solves the problem of low attack data detection accuracy caused by data imbalance in existing networks. First, we perform feature screening through the chi-square distribution, which speeds up the training of the model. Then, we use CGAN to generate designated attack data with similar distribution to the original data based on the categories of input labels to achieve data augmentation and reduce training data imbalance. Finally, our detection method is verified to have better detection performance on the NSL-KDD dataset. In addition, our detection method improves detection accuracy for minority classes and unknown attack types more than the other five baseline methods. This method effectively alleviates the problems caused by changes in attack types and data imbalance in the network.
References
Zhong-hua, W., Jian-feng, M., Wen-sheng, N., Ya-hui, L.: Architecture of security protection technology for aviation cyberspace. In: 2020 7th International Conference on Dependable Systems and Their Applications (DSA), pp. 21–24 (2020). https://doi.org/10.1109/DSA51864.2020.00009
Jamalipour, A., Murali, S.: A taxonomy of machine-learning-based intrusion detection systems for the Internet of Things: a survey. IEEE Internet Things J. 9(12), 9444–9466 (2022). https://doi.org/10.1109/JIOT.2021.3126811
Shone, N., Ngoc, T.N., Phai, V.D., Shi, Q.: A deep learning approach to network intrusion detection. IEEE Trans. Emerg. Top. Comput. Intell. 2(1), 41–50 (2018). https://doi.org/10.1109/TETCI.2017.2772792
Shu, J., Zhou, L., Zhang, W., Du, X., Guizani, M.: Collaborative intrusion detection for VANETs: a deep learning-based distributed SDN approach. IEEE Trans. Intell. Transp. Syst. 22(7), 4519–4530 (2021). https://doi.org/10.1109/TITS.2020.3027390
Bao, F., Deng, Y., Kong, Y., Ren, Z., Suo, J., Dai, Q.: Learning deep landmarks for imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst. 31(8), 2691–2704 (2020). https://doi.org/10.1109/TNNLS.2019.2927647
Liang, W., Hu, Y., Zhou, X., Pan, Y., Wang, K.I.K.: Variational few-shot learning for microservice-oriented intrusion detection in distributed industrial IoT. IEEE Trans. Ind. Inf. 18(8), 5087–5095 (2022). https://doi.org/10.1109/TII.2021.3116085
Ahmad, I., Basheri, M., Iqbal, M.J., Rahim, A.: Performance comparison of support vector machine, random forest, and extreme learning machine for intrusion detection. IEEE Access 6, 33789–33795 (2018). https://doi.org/10.1109/ACCESS.2018.2841987
Dong, B., Wang, X.: Comparison deep learning method to traditional methods using for network intrusion detection. In: 2016 8th IEEE International Conference on Communication Software and Networks (ICCSN), pp. 581–585 (2016). https://doi.org/10.1109/ICCSN.2016.7586590
Yin, C., Zhu, Y., Fei, J., He, X.: A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 5, 21954–21961 (2017). https://doi.org/10.1109/ACCESS.2017.2762418
Javed, A.R., Ur Rehman, S., Khan, M.U., Alazab, M., Reddy, T.: CANintelliIDS: detecting in-vehicle intrusion attacks on a controller area network using CNN and attention-based GRU. IEEE Trans. Netw. Sci. Eng. 8(2), 1456–1466 (2021). https://doi.org/10.1109/TNSE.2021.3059881
Lemaître, G., Nogueira, F., Aridas, C.K.: Imbalanced-learn: a Python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Lear. Res. 18(1), 559–563 (2017)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357 (2002)
He, H., Bai, Y., Garcia, E.A., Li, S.: ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), pp. 1322–1328. IEEE (2008)
Pradipta, G.A., Wardoyo, R., Musdholifah, A., Sanjaya, I.N.H.: Radius-SMOTE: a new oversampling technique of minority samples based on radius distance for learning from imbalanced data. IEEE Access 9, 74763–74777 (2021). https://doi.org/10.1109/ACCESS.2021.3080316
Huang, S., Lei, K.: IGAN-IDS: an imbalanced generative adversarial network towards intrusion detection system in ad-hoc networks. Ad Hoc Netw. 105, 102177 (2020). https://doi.org/10.1016/j.adhoc.2020.102177. www.sciencedirect.com/science/article/pii/S1570870519311035
Zhang, G., Wang, X., Li, R., Song, Y., He, J., Lai, J.: Network intrusion detection based on conditional Wasserstein generative adversarial network and cost-sensitive stacked autoencoder. IEEE Access 8, 190431–190447 (2020). https://doi.org/10.1109/ACCESS.2020.3031892
Acknowledgements
This paper is supported by the Fundamental Research Funds for the Central Universities under Grant No. 2020JBM013.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ji, Z., Gao, X. (2023). CNN-CGAN: A New Approach for Intrusion Detection Based on Generative Adversarial Networks. In: Quan, W. (eds) Emerging Networking Architecture and Technologies. ICENAT 2022. Communications in Computer and Information Science, vol 1696. Springer, Singapore. https://doi.org/10.1007/978-981-19-9697-9_26
Download citation
DOI: https://doi.org/10.1007/978-981-19-9697-9_26
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-9696-2
Online ISBN: 978-981-19-9697-9
eBook Packages: Computer ScienceComputer Science (R0)