
Abstract
In this paper, a robust optimal tracking strategy is presented for linear system with systems uncertainty and bounded disturbance. Firstly, an integral sliding mode control policy is designed to guarantee system trajectories tend to a defined sliding mode surface and the influence of system uncertainty is eliminated. Then the robust tracking control problem of original system is transformed into the \(H_\infty \) control problem of an auxiliary error system. Furthermore, an off-policy integral reinforcement learning (IRL) algorithm based \(H_\infty \) controller is designed, where the optimal tracking performance is guaranteed under the adverse effect of external disturbance. Finally, simulation test for near space vehicle (NSV) attitude model is introduced to verify the effectiveness of the proposed strategy.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Nowadays, the robust control method has received considerable attention from industrial and academic areas [1]. As far as we know, there are many effective methods to deal with the uncertainty. Such as disturbance observer-based (DO) control [2] and integral sliding mode control (ISMC) [3]. Compared to DO method, ISMC method can deal with the system uncertainty which only requires to be bounded. In [4], the authors investigated ISMC controller design issue for fuzzy semi-Markov systems. In [5], a robust fault-tolerant controller was designed for robot manipulators by using ISMC. In addition, for the purposed of improving control performance, optimal control theory can be widely used [6, 7]. In [6], a novel tracking strategy using adaptive dynamic programming (ADP) algorithm was proposed for linear system with unknown dynamics. In [7], a novel value iteration based algorithm was proposed to solve the \(H_\infty \) control of linear system. The core mission of optimal control problem for linear system is to solve the algebraic Riccati equation (ARE), and reinforcement learning (RL) technique can effectively handle this issue [8]. In [9], a novel RL scheme based on incremental learning approach was proposed for continuous-time linear system. In order to obviate the requirement of system dynamics, integral RL (IRL) method was proposed [10]. For linear system with input delay, an IRL-based model free optimal control method was proposed, and only the input and output of system datas were used [11].
Inspired by the above content, in this paper, a composite \(H_\infty \)tracking control scheme is designed for continuous-time linear system with system uncertainty and bounded disturbance by using ISMC and off-policy IRL-based control methods. The sliding mode controller is designed to eliminate the effect of unknown uncertainty. The developed IRL control method is used to obtain the optimal tracking performance under the adverse effect of external disturbance. Furthermore, we introduce a NSV attitude model to show the effectiveness of the proposed control scheme.
2 Problem Description
In this paper, we consider the following uncertain system:
where \(x(t) =[x_1(t), \cdots , x_n(t)] ^{T}\in \Re ^n\) denotes the system state, \(y\left( t\right) \in \Re ^{p}\), \(\varpi (x)\in \Re ^{v}\) and \(\varsigma (t)\in \Re ^{q}\) represent system output, unknown system uncertainty and external disturbance, respectively. \(A\in \Re ^{n\times n}\), \(B\in \Re ^{n\times m}\), \(C\in \Re ^{p\times n}\), \(E\in \Re ^{n\times v}\) and \(D\in \Re ^{n\times q}\) are known system matrices. The external disturbance is assumed to belong to \(L_{2}\left[ 0,\infty \right) \) . The system uncertain \(\varpi (x)\) is bounded and satisfies \(\left\| \varpi (x)\right\| \le \varpi _{m}\).
The desired reference trajectory is generated by
where \(x_{r}\left( t\right) \in \Re ^{n_{r}}\) and \(y_{r}\left( t\right) \in \Re ^{p}\ \)are system state and output of reference trajectory system.\(\ A_{r}\) and \(C_{r}\) are constant matrices. Furthermore, the following tracking error can be defined as \(e(t) =y(t) -y_{r}(t)\)
Here, we introduce a new error variable as
where \(z \left( t\right) \in \Re ^{n} \), \(G\in \Re ^{n\times n_{r}}\) is the constant matrix satisfying \(AG+BH=GA_{r}\) and \( CG=C_{r}\). \(H\in \Re ^{m\times n_{r}}\) is the constant matrix, which is employed to model match. Furthermore, one can deduce that \(e(t) =Cz (t)\).
Then, combining (1), (2) and (3), we can obtain
The control input is designed as \(u\left( t\right) =u_{a}\left( t\right) +u_{o}\left( t\right) \), where \(u_{a}\left( t\right) \) is an integral sliding mode control policy to eliminate the influence of the system uncertainty, and \(u_{o}\left( t\right) \) is an off-policy IRL-based \( H_{\infty }\) control policy to guarantee the optimal tracking performance.
3 Controller Design
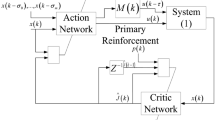
In this section, we will present the porposed control method including ISMC and of-policy IRL-based \(H_{\infty }\) control design. Moreover, the structure of the proposed control method is shown in Fig. 1.

Estimation results of the unknown disturbance D
3.1 Integral Sliding Mode Control Design
In this paper, we select the following integral sliding mode surface
where \(\varGamma \) is a positive matrix to be designed, which satisfies \(\varGamma B\) is invertible. Furthermore, the integral sliding mode control policy can be designed as
where \(\mathrm {Sgn}\left( \mathcal {S}\right) =\left[ \begin{array}{ccc} \mathrm {sgn}\left( \mathcal {S}_{1}\right)&\ldots&\mathrm {sgn}\left( \mathcal {S}_{n}\right) \end{array} \right] ^{T}\), and sgn\(\left( \cdot \right) \) is a sign function. \( \varUpsilon \) is positive matrix to be designed.
Theorem 1
Considering system (4), the integral sliding mode surface and the integral sliding mode control policy are designed as (5)–(6), respectively. Then, integral sliding surface is uniformly asymptotically stable by selecting suitable \(\varUpsilon \) and \(\varGamma \).
Proof
The Lyapunov function is selected as follows
Taking derivative of \(V\left( t\right) \) with respect to t, one can obtain that
By selecting suitable matrixes \(\varUpsilon \) and \(\varGamma \) such that \(\lambda _{\min }\left( \varUpsilon \right) >\varGamma E\varpi _{m}\), then, we have \(\dot{V} \left( t\right) <0\), which means that sliding mode surface is uniformly asymptotically stable.
3.2 Off-Policy IRL-Based \(H_{\infty }\) Control Design
Consider the following auxiliary error system
The corresponding infinite horizon performance index is
where \(Q=Q^{T}\ge 0\), \(R=R^{T}>0\) denote the state and control performance weights, respectively. \(\varphi \) is a constant, which satisfies \(\varphi \ge \varphi ^{*}\), \(\varphi ^{*}\) is the smallest \(L_{2}\) gain. We consider \(\varsigma \left( t\right) \) as opponent’s policy. The aim is to find a control policy \(\left( u_{0},\varsigma \right) \) to make system (9) is stable and meets a \(H_{\infty }\) performance.
Furthermore, the \(H_{\infty }\) control issue is equivalent to following zero-sum game problem
where \(\mathcal {V}^{*}\left( z _{0}\right) \) is the optimal value function. Control policy and disturbance policy are considered as two hostile players, where control policy desires to minimize the performance index while disturbance policy aims to damage it. Furthermore, we denote control policy \(u_{o}(t)=-Kz (t)\) and disturbance policy \(\varsigma (t)=K_{w}z (t)\), respectively. Then, the value function can be expressed as
Moreover, we can obtain the following algebraic Riccati equation
the saddle point of zero-sum game is
Then, system (9) can be rewritten as
where \(\tilde{A}=A-BK+DK_{w}\).
Furthermore, we can obtain that
Then, the left-hand of (9) can be rewritten as
where
Similarly, we can deduce
From (17) and (18), (16) can be represented as
where \(\varOmega _{i}=-\gamma _{zz}vec\left( Q\right) \) and
Furthermore, we have
Then, the online implementation of off-policy IRL-based \(H_{\infty }\) control method is presented in Algorithm 1. Moreover, the stability analysis of the system (9) can be reference to [10].

4 Simulation Results
In this section, simulation studies are employed to verified the effectiveness of the proposed method. The nonlinear attitude mode of NSV is linearized at equilibrium point \( x_{0}=[-0.0005,0.0001,0.2,0,-0.1872,0.0007]^{T}\), such the linear attitude mode of NSV is obtained.
where \(x=[\alpha ,\beta ,\mu ,p,q,r]^{T}\) is system state vector, which are attitude angles and angle rates. \(u=[\delta _{e},\delta _{a},\delta _{r},\delta _{x},\delta _{y},\delta _{z}]^{T}\) denotes control input vector. The specific information of NSV mode and matrices A, B can reference to [12]. And

Convergence of matrix P and sliding surface function.

The state responses of the open-closed system.

The responses of the attitude angles.
The reference attitude angles are selected as
For algorithm 1, the parameters are chosen as follows: \(Q=10^{4}I,\) \(R=I.\) From \(t=0\) s to \(t=2\) s, the following exploration noise is employed as system input
where \(c=1,...,100\), and \(w_{c}\) are selected from \([-500,500]\). Moreover, the weighting matrices are \(\varPi =I,Q=10^{4}I,\) \(R=I\), and \(\varphi =1.5\), \( \varGamma =2.2\), \(\varUpsilon =0.01\). Furthermore, by using Algorithm 1, the control gain K can be obtained. The convergence process of P matrix element and sliding surface function are shown in Fig. 2. From Fig. 3, it can be observed that system is unstable without the control input. Then, it can be seen from Fig. 4 that actual angles can well track the desired signals in a short time, which means that the proposed control method is effective.
5 Conclusions
In this paper, a composite \(H_\infty \)tracking control scheme is designed for continuous-time linear systems with system uncertainty and bounded disturbance. Firstly, the integral sliding mode controller has been applied to deal with unknown system uncertainty. In addition, an off-policy IRL has been provided for solving the two-player zero-sum game problem of \(H_\infty \) control. Finally, the simulation results for NSV attitude control show the effectiveness of the proposed method. In our future work, we will extend the results to nonzero-sum games for practical system.
References
Zhao, Z., He, X., Ren, Z., Wen, G.: Boundary adaptive robust control of a flexible riser system with input nonlinearities. IEEE Trans. Syst. Man Cybern. Syst. 49(10), 1971–1980 (2018)
Chen, W.H., Ding, K., Lu, X.: Disturbance-observer-based control design for a class of uncertain systems with intermittent measurement. J. Franklin Inst. 354(13), 5266–5279 (2017)
Pan, Y., Yang, C., Pan, L., Yu, H.: Integral sliding mode control: performance, modification, and improvement. IEEE Trans. Industr. Inf. 14(7), 3087–3096 (2017)
Jiang, B., Karimi, H.R., Kao, Y., Gao, C.: A novel robust fuzzy integral sliding mode control for nonlinear semi-Markovian jump T-S fuzzy systems. IEEE Trans. Fuzzy Syst. 26(6), 3594–3604 (2018)
Van, M., Ge, S.S.: Adaptive fuzzy integral sliding-mode control for robust fault-tolerant control of robot manipulators with disturbance observer. IEEE Trans. Fuzzy Syst. 29(5), 1284–1296 (2020)
Qin, C.B., Zhang, H.G., Luo, Y.H.: Online optimal tracking control of continuous-time linear systems with unknown dynamics by using adaptive dynamic programming. Int. J. Control 87(5), 1000–1009 (2014)
Jiang, H.Y., Zhou, B., Liu, G.P.: \(H_\infty \) optimal control of unknown linear systems by adaptive dynamic programming with applications to time-delay systems. Int. J. Robust Nonlinear Control 31(12), 5602–5617 (2021)
Wen, Y., Si, J., Brandt, A., Gao, X., Huang, H.: Online reinforcement learning control for the personalization of a robotic knee prosthesis. IEEE Trans. Cybern. 50(6), 2346–2356 (2019)
Bian, T., Jiang, Z.: Reinforcement learning for linear continuous-time systems: an incremental learning approach. IEEE/CAA J. Automatica Sinica 6(2), 433–440 (2019)
Moghadam, R., Lewis, F.L.: Output-feedback \(H_{\infty }\) quadratic tracking control of linear systems using reinforcement learning. Int. J. Adapt. Control Signal Process. 33(2), 300–314 (2017)
Wang, G., Luo, B., Xue, S.: Integral reinforcement learning based optimal feedback control for nonlinear continuous time systems with input delay. Neurocomputing 460, 31–38 (2021)
Yang, Q.: Robust control for near space vehicle with input saturation. Nanjing University of Aeronautics and Astronautics (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Xia, R., Wu, J., Shen, H. (2023). Integral Reinforcement Learning-Based \(H_\infty \) Tracking Control for Uncertain Linear Systems and Its Application. In: Ren, Z., Wang, M., Hua, Y. (eds) Proceedings of 2021 5th Chinese Conference on Swarm Intelligence and Cooperative Control. Lecture Notes in Electrical Engineering, vol 934. Springer, Singapore. https://doi.org/10.1007/978-981-19-3998-3_97
Download citation
DOI: https://doi.org/10.1007/978-981-19-3998-3_97
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-3997-6
Online ISBN: 978-981-19-3998-3
eBook Packages: EngineeringEngineering (R0)