
Abstract
The goal of educational institutions is to enhance the quality of education and uplift students’ academic performance. To attain the highest level of quality, experts need to find out the most influential features affecting academic performances and must attempt to solve weakness of those features. Educational data mining (EDM) tools provide the best measure to achieve so. For educational datasets, quality of prediction results can be upgraded by using feature selection (FS) procedures. Unrelated data and attributes present in dataset can be removed by using proper FS methods which will result in more accurate results in EDM practices. Performance of prediction results can be enhanced by choosing appropriate dataset and attributes. This paper utilizes educational data mining approach through a few chosen feature selection procedures and machine learning algorithms to predict students’ final grade. Obtained results attempt to find out influence of different student-related attributes in the prediction.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
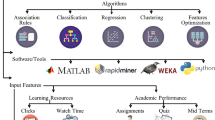
Educational upgrades play primary role in the development of a country. Quality of education in a country is the deciding factor in creating influential member of society. Students’ data kept in educational repositories need to be explored for getting hidden information which will help in finding main factors improving educational processes. Academic performance of students is observed by using various well-built prediction models which are implemented by EDM techniques. High-dimensional students’ data consisting of large number of attributes require going through dimensionality reduction before using it for prediction. This paper consists of two parts including the implementation of different feature selection procedures on the chosen dataset followed by performance prediction. Various well-known feature selection algorithms have been employed on the chosen dataset to reduce dimension to get better results. Later, multiple classification and regression methods are used on the reduced number of features to get the actual prediction output. Most promising result can be detected by comparing accuracy score of individual methods. This paper aims to observe the best combination of feature selection processes and machine learning methods which will give more accurate prediction result. Here, several fundamental algorithms found in the literature are studied to assess their performance in a controlled scenario (Fig. 1).

Performance prediction procedure [1]
2 Related Works
The literature review discloses that predicting performance at higher education level has involved substantial attention in the recent past and persists to remain focus of research and discussion. Several works have been done successfully in this domain. Many of those suitable works have been thoroughly examined to gain knowledge in this field.
The study conducted by Asif et al. in [2] shows prediction of graduation performance by only using pre-university marks and marks of first- and second-year courses without requiring any other features with reasonable accuracy. This work includes usage of well-known machine learning algorithms like decision tree, naive Bayer’s, neural network, random forest along with feature selection steps and without using feature selection.
In [3], Cortez and Silva have used data collected from two Portuguese schools to predict secondary students’ grades of two core classes by using pass school grades, demographic, and social data. This paper consists of implementation of three different data mining goals (binary classification, classification with five levels, and regression) with four well-known data mining methods (decision tree, random forest, naive Bayes method, and support vector machine). The obtained results reveal that it is possible to achieve a high predictive accuracy, provided that the first and/or second school period grades are known. Results obtained also conclude that students’ results highly depend on their previous examination performance.
In the research paper [4] by Yassein et al., clustering (using two-phase clustering technique) was done to classify data in to two clusters and then suitable classification algorithm (C5.4 algorithm) was used for prediction. This work establishes the fact that there exists a strong relation between students’ attendance in class and their success rate and between practical work and success rate of courses.
Research work [5] published by Hasan et al. used WEKA data mining tool to evaluate decision tree algorithm for discovery of students’ performance. A comparison between random forest tree algorithm and decision tree algorithm has been performed here.
Rahman and Islam’s research work in [6] has attempted to analyze the effect of students’ absence from regular class as well as students’ behavioral attributes on their academics. This paper includes application of methods like naive Bayes and artificial neural network. It has also implemented an ensemble filtering method to identify erroneous instances from dataset.
In the domain of students’ performance prediction, different kinds of machine learning algorithms have been used. Understanding the impact of various procedures through knowledge gathering on this task, an experimental approach has been taken here. This work tries to find out the effect of well-known feature selection algorithms in a random dataset consisting of students’ data and focuses on how different feature selection methods followed by different machine learning procedures can change the prediction result.
3 Proposed Work
The main objective of this research paper is to know in detail the individual effects of various attributes on the students’ performance. Educational data mining plays an important role in modern education by helping students as well as teachers to improve overall academic environment. This work tries to find out the effect of well-known feature selection algorithms in a random dataset consisting of students’ data and focuses on how different feature selection methods followed by different machine learning procedures can affect the prediction result.
Major requirement of educational data mining lies in the improvement of students’ performance. Results obtained from such machine learning procedure help educational institutions to nourish students’ educational practice. That is why such experiments require dataset of considerable size to be divided into training and test parts as required. Such database can be constructed from two sources: school reports, based on paper sheets and including few attributes and questionnaires, used to complement the previous information. Data stored in database must go through data cleaning procedures before proceeding toward actual task. Later, insignificant attributes are discovered using feature selection algorithms. Then different results obtained from different feature selection procedures are considered and passed through machine learning step. At last, prediction results are compared in terms of accuracy.
For this work, some well-known feature selection methods and machine learning procedures have been chosen. Among all features, very few plays important role in result estimation. So, feature selection algorithms are required to obtain a subset of significant features to avoid over-fitting problem. Four filtering-type feature selection methods used here include chi-square test, correlation-based feature selection method, ROC score-based method, and mean squared error (MSE)-based method. Lasso and Ridge regression procedures embody embedded feature selection method. Recursive feature selection using random forest method represents wrapper feature selection methods. In the second and most crucial part of this work, selected attributes obtained from feature selection steps were used to build models using chosen machine learning algorithms. As classification methods, logistic regression, support vector machine (SVM), K-nearest neighbor (KNN) method, naive Bayes classification, and random forest classification were applied. Linear regression was another method used on the chosen attribute set. These machine learning procedures were applied separately on the results obtained from each individual feature selection method. Finally, accuracy score was used to compare the performance of feature selection methods and machine learning procedures.
4 Result and Discussion
Proposed procedures as described in the previous section have been implemented with a system having AMD Ryzen 3 2200G processor in Windows 10 Operating System. The software tool used to implement the algorithms was python 3.7.4 in Jupyter notebook platform.
For this comparative study, the student prediction dataset from the UCI machine learning repository [7] has been used. This data was collected from the Alentejo region of Portugal from two public schools during the 2005–2006 session. The dataset has been split into the two parts one comprising the core subject of Mathematics and the other Portuguese. During a year, the student’s marks evaluation is divided into three phases G1, G2, and G3. G3 corresponds to the final grade which is our target attribute to be predicted. The data attributes include student grades, demographic, social, and school-related features, and it was collected by using school reports and questionnaires. The math dataset contains 365 examples, and the Portuguese dataset has 649 examples (Fig. 2).

Attribute description of dataset [7]
In the above-mentioned dataset with 32 attributes, feature selection and machine learning procedures have been applied. Results obtained are shown in the next section
4.1 Feature Selection Results
4.1.1 Filter Methods
In any prediction procedure, the filter method acts as a preprocessing step before going into actual result generation. It does not depend on any machine learning algorithm.
Chi-Square Ranking of the Chosen Set of Features
The chi-square method is believed to be the right choice to get the significance value of each feature. It has calculated the significant value of each feature toward the target. It determines if the association between two categorical variables of the sample would reflect their real association in the population (Table 1).
Chi-square score is given by:
Result shows the attribute ‘absences’ has got more importance than attribute ‘G1’.
Correlation Result with Target Variable
To find out the correlation between any two variables, X and Y (say), a well-known method is to use linear correlation coefficient ‘r’ given by:
Correlation is similarity measures between two features. If two features are linearly dependent, then their correlation coefficient is ±1. If the features are uncorrelated, the correlation coefficient is 0. Result shows that the previous two grades (G2 and G1) are the most important ones (Table 2).
4.1.2 Graphical Representation
See Fig. 3.

Graphical representation of correlation result
ROC Scores for Our Dataset
Receiver operating characteristic (ROC) curve tells us about how good the model can distinguish between two things (e.g., if a patient has a disease or no). Better models can accurately distinguish between the two, whereas a poor model will have difficulties in distinguishing between the two.
4.1.3 How It Works:
-
First, it builds one decision tree per feature, to predict the target.
-
Second, it makes predictions using a decision tree and the considered feature.
-
Third, it ranks the features according to the machine learning metric (ROC).
-
It selects the highest-ranked features (Table 3).
Table 3 ROC score result
4.1.4 Graphical Representation of the ROC Result
From this result, we can observe that, except G2, all other attributes have a score more than or near 0.5. So, from this observation, the ROC-AUC score concludes that G2 influences prediction model far more than other attributes does (Fig. 4).

Graphical representation of ROC score result
MSE (Mean Squared Error) Values for Our Feature Set
See (Table 4).
where Yi is the value of dependent attribute.
Using MSE, errors that present in the prediction of the target attribute are computed with respect to each feature. Depending on a particular threshold value for error, features having more error value can be removed from the feature set.
4.1.5 Graphical Representation
See Fig. 5.

Graphical representation of MSE value result
4.1.6 Embedded Methods
Embedded methods combine properties of both filter and wrapper methods. It does not separate learning from feature selection. An intrinsic model building metric is used during the learning process (Tables 5 and 6).
Lasso regression is applied on set of features which performs both variable selection and regularization to enhance prediction quality. Here G2, G1, Absence, Famrel, paid these attributes are obtained in the order of decreasing coefficient values irrespective of their sign.
Ridge regression does not attempt to select features at all, it instead uses a penalty applied to the sum of the squares of all regression coefficients. So, here we are getting two top attributes Dalc and romantic different from the ridge regression result.
4.1.7 Wrapper Methods
Wrapper methods find out the relevance of each feature in predicting the target attribute but suffers from over-fitting issues.
Recursive Feature Selection Using Random Forest
Recursive feature elimination selects predictors in a backward selection approach. In this technique, at first a model is built on the whole set of predictors and then it computes importance score for each one. Predicto r (s) having least score are removed, and procedure continues by rebuilding the model and so on. The analyst must decide on number of predictor subsets to evaluate and each subset’s size. This result has also given importance to ‘age’ and ‘goout’ attribute apart from ‘G2’ and ‘G1’ (Table 7).
So, results obtained from different feature selection algorithms provide various subset of features as they differ in methodology. Filter methods discussed show statistically that G1, G2, Absence, School, Reason, these five attributes are the most relevant ones in case of discrete target and dataset. But in case of continuous values, G2, G1, Failure, Higher education, Medu, Fedu, these are more relevant.
Among all the results obtained, G1 and G2 come out to be the most significant feature for prediction but correlation feature selection shows that G1 and G2 are highly correlated, and hence for getting good prediction result in the final work, it will be beneficial to remove G1 from the feature set.
4.2 Performance Prediction Results (G3 Being Target Attribute)
After feature selection procedure, major focus was on the selection of machine learning method for prediction. Classification methods have been used greatly. There lie certain reasons for which classification methods are better candidate for this dataset. Here G3 being target attribute contains discrete values (0 to 20). To predict future values of G3 attribute obviously classification procedures will be more beneficial to use as it works on labeled category (Figs. 6 and 7).

Prediction results

Attributes are taken into consideration during prediction
Only linear regression is used here. In case of regression methods, straight line is drawn having G3 in X-axis. Due to the general characteristics of regression method, it may happen that resulting prediction value will go below zero and above 20, but it is not possible as G3 value cannot be negative and cannot be greater than 20. That is why we have restricted our work within linear regression.
As given in result part, accuracy score is deciding factor for prediction models. For all the feature selection methods, accuracy scores obtained by using K-nearest neighbor (KNN) classifier are very low. So KNN is not at all suitable classifier to be used for this dataset. Influences of attribute combinations provided by Chi-square and Lasso regression method is very low on the prediction. Other results are almost satisfactory. However, the work can be extended to use more machine learning models to get better prediction performance.
5 Conclusion and Future Scope
The focus of the paper was to examine how the results of various feature selection tests influence different prediction model performance. Such experiments also find out the accuracy of choice of attributes during data collection. In case of any educational institution, attributes influencing their students’ performance changes as per its regional culture, habits, socioeconomic scenario. In the future, same experiment can be performed on different regional data. Depending on region (generally country), attribute choice is very important. Online data collection procedures can be chosen. As stated earlier in previous part. This work only includes the use of linear regression method. In the future, further progress in this experiment may include knowledge about other types of regression methods so that how other regression methods work on this experiment can be checked.
References
Romero C, Ventura S (2017) Educational data mining: a Survey from 1995 to 2005. Exp Syst Appl 136
Asif R, Hina S, Haque S (2017) Predicting student academic performance using data mining methods. In: Semantic scholar, vol 17, no 5. N.E.D University of Engineering & Technology /Department of Computer Science & Software Engineering
Cortez P, Silva A (2008) Using data mining to predict secondary school student performance. In: 5th annual future business technology conference. Porto, pp 5–12
Yassein NA, Helali RGM, Mohomad SB (2017) Predicting student academic performance in KSA using data mining techniques. J Inform Tech Softw Eng 7–9
Hasan R, Palaniappan S, Raziff ARA, Mahmood S, Sarker KU (2018) Student academic performance prediction by using decision tree algorithm. In: 4th international conference on computer and information sciences (ICCOINS). Kuala Lumpur, pp 1–5
Rahman MH, Islam MR (2017) Predict student’s academic performance and evaluate the impact of different attributes on the performance using data mining techniques. In: 2nd international conference on electrical & electronic engineering (ICEEE). Rajshahi, pp 1–4
Cortez P, University of Minho, Student Performance Dataset. https://archive.ics.uci.edu/ml/datasets/Student+Performance
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mitra, A., Decosta, A., Roychoudhury, N., Acharya, A. (2022). Students Performance Prediction Using Educational Data Mining. In: Dahal, K., Giri, D., Neogy, S., Dutta, S., Kumar, S. (eds) Internet of Things and Its Applications. Lecture Notes in Electrical Engineering, vol 825. Springer, Singapore. https://doi.org/10.1007/978-981-16-7637-6_16
Download citation
DOI: https://doi.org/10.1007/978-981-16-7637-6_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-7636-9
Online ISBN: 978-981-16-7637-6
eBook Packages: EngineeringEngineering (R0)