
Abstract
Concerning the problem of poor video transmission quality caused by wireless network fluctuation, proposes a video transmission strategy based on fountain code. Combined with the characteristics of H.264 video stream, fountain code is used as the video transmission application layer coding scheme; a rate-based bandwidth estimation model is constructed, and the encoding parameters of fountain code are dynamically adjusted according to the bandwidth estimation results. Experiments show that the proposed video transmission control strategy can effectively improve the transmission quality of video data in wireless network environment with high packet loss rate. It has high coding flexibility and can effectively improve the bandwidth utilization.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
23.1 Introduction
With the popularization of 4G network and Wi-Fi, the traffic proportion of video transmission services in the mobile Internet increases explosively [1]. How to improve the quality of video transmission services has also become the focus of research. However, the current wireless network cannot effectively adapt to the video transmission service in each application scenario. The influence of wireless network fluctuation on video transmission quality is an urgent problem to be solved.
Fountain code as a forward error-correcting code technology, through the continuous generation of coding data packets in the data source, only need to receive a certain number of coding data packets can recover the original data. These advantages make fountain code become an excellent solution to improve the quality of wireless network. Reference [2] introduced LT codes and proposed ideal soliton distribution and robust soliton distribution. Reference [3] introduced the application of fountain codes in wireless optical communication. Reference [4] optimized the degree distribution of LT codes, reduced the decoding overhead and complexity makes it more suitable for underwater acoustic communication. Reference [5] constructed a new LT codes distribution through the comprehensive Poisson distribution, which improved the reliability and effectiveness of communication in the cognitive radio link.
Most of the above optimizations for LT codes are based on the degree distribution optimization for specific communication scenarios, without considering the optimization the optimization of coding strategies in practical use. In view of the above problems, this paper uses fountain code and bandwidth measurement algorithm to construct a video transmission control strategy, determines the current wireless network state through bandwidth measurement technology, and adjusts the LT codes coding redundancy.
23.2 Video Transmission Control Strategy
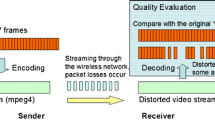
At present, the video service based on streaming media technology has become the mainstream. However, in practical applications, it is difficult to achieve good results in different application scenarios only using streaming media protocol for transmission, which often needs to be optimized in combination with application scenarios. In the network with high packet loss rate, it is important that the data can reach the receiver accurately. The video data are encoded and processed as the input symbols of LT codes, and then transmitted. Even if the original video data are lost in the transmission process, the decoder can also recover the original data from the set of generated coding symbols, avoiding data retransmission. Therefore, using LT codes to construct video transmission strategy can effectively reduce the impact of packet loss on video data, so that the quality of video stream in the network with large packet loss rate can be improved effectively.
23.2.1 Data Coding Strategy Based on LT Codes
LT codes are the first practical fountain code, and the number of coded symbols can be generated as needed. They are sent through the channel until enough coded symbols arrive at the decoder, then the decoding is completed and the recovery of lost data is realized. Since the decoder can recover data from almost the smallest number of coded symbols, LT codes are close to the best relative to any erasing channel. Reference [2] proposed two-degree distributions of LT codes, namely ISD and RSD. The ISD is a distribution that satisfies by Eq. (23.1).
In Eq. (23.1), k represents the number of input symbols, k ∈ N, N represents a positive integer, i represents the number of input symbols used for encoding selected from each input symbol, called degree, i ∈ [1, k], ρ(i) represents the ISD.
The ISD is easy to lose the output symbol of degree-1 in practical use, resulting in decoding interruption. In order to overcome this defect, based on the ISD, Reference [2] proposed RSD with stronger practical application ability, which can be expressed by Eqs. (23.2) and (23.3).
In Eqs. (23.2) and (23.3), \(R = c \cdot \ln (c/\delta ) \cdot \sqrt k { }\) represents the number of output symbols of degree-1, c > 0 and δ ∈ [0,1], \(Z = \sum\nolimits_{i = 1}^{k} {[\rho (i) + \tau (i)]}\). μ(·) represents the RSD.
H.264 Video Streams {R − 1} can be regarded as composed of multiple group of picture (GOP). Each GOP is composed of a certain number of I-frames, B-frames, and P-frames. I-frame is a complete image and does not need to refer to other frames when decoding. While B-frame and P-frame are predictive frames, which only store the motion vector rather than the complete image and need to refer to I-frame when decoding. In addition, the reference I-frame in the decoder is refreshed whenever a new I-frame arrives in the buffer, thus avoiding the spread of B-frame and P-frame decoding errors. Therefore, when encoding H.264 Video Streams, a group of GOP can be used as an independent input symbol unit, and LT codes encoding can be carried out combined with the RSD to obtain the encoded data package. In order to ensure the decoding success, there will be coding redundancy, which can be expressed by Eq. (23.4).
In Eq. (23.4), K represents the data packet encoded by the input symbol, k represents the input symbol, and ε represents the coding redundancy.
As the packet loss rate increases, the loss of correlated coded data packets will lead to an increase in the probability of decoding failure. If the video data is encoded by the fixed coding redundancy, where a fixed code redundancy is applied for video data encoding, it is necessary to adopt a large data redundancy for the purpose of successful decoding of video data. This will result in waste of resources and reduction of efficiency when the packet loss rate is low. Therefore, when using LT codes to encode the video data, the coding redundancy should be determined according to the bandwidth situation, so as to realize the adaptation of coding redundancy and network bandwidth and improve the coding flexibility and bandwidth utilization of LT codes.
23.2.2 Code Adaptive Coding Redundancy
At present, bandwidth measurement methods can be divided into active measurement and passive measurement according to whether it is necessary to inject data packets into the network. The active measurement method requires continuous injection of additional data packets into the network, which will increase the link burden in network congestion. The detected data packets cannot be guaranteed to be reliable with UDP, so it is difficult to accurately measure the available bandwidth of the network. However, the video stream transmission has the characteristics of large amount of data and long duration, which enable us to estimate the bandwidth value by measuring the video stream directly. Reference [6] proposed a model to estimate the available bandwidth by calculating the GOP sending time of each group of video files. This algorithm can simply and quickly estimate the current network bandwidth by sending rate. This paper will combine this algorithm to construct LT code redundancy adaptive strategy.
From the previous section, a GOP is a coding input unit, so the available bandwidth of wireless network can be estimated by the sending rate of a GOP. The size of a GOP is expressed as Sj, the sending time is Tj, j is the number of the current GOP, the bandwidth value Bj can be calculated by Eq. (23.5).
In Eq. (23.5), a bandwidth can be estimated according to each GOP sent. Although the redundancy of fountain codes is not directly related to the bandwidth value, it shows a certain positive correlation with the packet loss rate. Therefore, it is necessary to establish the relationship between the bandwidth value and the packet loss rate.
When the estimated bandwidth is greater than the video bit rate, it is considered that the current bandwidth meets the requirements of video stream transmission, and the packet loss probability is small. When the estimated bandwidth value is not greater than the video stream bit rate, it can be considered that the current bandwidth quality is poor and cannot satisfy the video stream transmission, and the probability of packet loss increases. Therefore, the relationship between coding redundancy ε and available bandwidth of wireless networks can be expressed by Eq. (23.6).
In Eq. (23.6), V represents the video stream rate, B represents the available bandwidth of the current wireless network, and a represents the proportional coefficient. According to experimental, a equals approximately 3. When the video bit rate is less than the current bandwidth value, it can be transmitted directly without additional coding redundancy. When the video rate is greater than the bandwidth value, it is determined that the current bandwidth is insufficient and the packet loss probability is large. The coding redundancy of LT codes is set according to the difference between the bandwidth value and the video rate. Therefore, the steps of video transmission control strategy are as follows.
23.3 Experimental Results
The test environment of this paper is as follows: an ARM embedded device as a video stream receiver, a PC as a video stream transmitter, through the LAN communication. In the PC side, the Linux kernel function module traffic control (tc) is used to control the packet loss rate and simulate the complex wireless network environment.
Select a video of 2046128 bytes for the experiment. Compare the receipt of data at receiving end under the circumstances of direct transmission and transmission after encoding using LT code in the network environments of different packet loss rates and reference [7] sets c = 0.05, δ = 0.05. The numbers of received bytes are as shown in Table 23.1.
It can be seen from Table 23.1 that when the LT codes are not used to encode the video data, due to the lack of compensation for data packet loss, the number of packet loss increases gradually as the packet loss rate increases. The video data is processed by LT codes, even if there are different degrees of packet loss in the network, the receiver can still decode the encoded data packet and recover the video data, which significantly reduces the impact of network packet loss on the video. In addition, when the packet loss rate reaches 5%, the direct transmission of video in the receiving end will incur obvious frame loss, jitter, and screen more serious. In the network environment with 5% packet loss rate, the video processed by LT codes can still be smoothly played, and the video recovery effect is good.
Fixed coding redundancy 0.5 and 1 are set, respectively, to compare with the proposed adaptive coding redundancy, as shown in Fig. 23.1.

Comparison of decoding success rates of different ε values
It can be seen from Fig. 23.1 that when the packet loss rate increases to 5%, the decoding success rate of the video data encoded by the coding redundancy 0.2 is less than 0.8 at the receiving end, while the decoding success rate of the coding group with coding redundancy 0.5 is significantly decreased when the packet loss rate is higher than 10%, which is not suitable for the environment with high packet loss rate. In the packet loss rate test environment, the proposed adaptive coding redundancy has high decoding success rate.
23.4 Conclusion
This paper proposes a video transmission control strategy suitable for wireless network environment with large packet loss rate. Specifically, it uses LT code to encode the video stream to reduce the impact of packet loss on the video stream and establishes a bandwidth estimation model on the basis of GOP transmission rate to achieve the coding redundancy adaptive of LT code, promoting the flexibility of LT Code and improving the transmission performance of video stream in the environment with large packet loss rate.
References
Li Rong, X., Ri Jing, Y., Xin, J.: Sensor-based rate control method for mobile streaming media. Comput. Sci. 45(10), 124–129 (2018)
Luby, M.: LT Codes. In Proceedings of the 43rd Annual IEEE Symposium Foundations of Computer Science (FOCS). IEEE Press, Vancouver (2002)
Yi, W., Hong-Zhan, L., Yuan, H., et al.: Development status and prospect of fountain codes in wireless optical communication. Optoelectron. Eng. 47(03), 48–57 (2020)
Ya-Chen, L., Peng-Cheng, W., De-Hong, T., et al.: Degree distribution optimization of LT codes. J. Northwest Univ. Technol. 38(03), 627–633 (2020)
Ben-Shun, Y., Wei-Qing, Y.: Improvement of LT code distribution and its application in cognitive radio link maintenance. J. Commun. 39(04), 76–83 (2018)
Chang-Hao, W., Jian, W., Li-Hua, F., et al.: Adaptive video stream selection algorithm for cloud media networks based on prediction mechanism. Comput. Appl. Res. 33(11), 3426–3429 (2016)
Ling, Y., Shi-Li, S., Guo-Chao, L., Xiao, C., et al.: Performance analysis and simulation of LT codes. Commun. Technol. 45(05), 1–3 (2012)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhou, R., Xiang, M., Liu, Y. (2022). A Video Transmission Control Strategy in Wireless Network. In: Jain, L.C., Kountchev, R., Hu, B., Kountcheva, R. (eds) Smart Communications, Intelligent Algorithms and Interactive Methods. Smart Innovation, Systems and Technologies, vol 257. Springer, Singapore. https://doi.org/10.1007/978-981-16-5164-9_23
Download citation
DOI: https://doi.org/10.1007/978-981-16-5164-9_23
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-5163-2
Online ISBN: 978-981-16-5164-9
eBook Packages: EngineeringEngineering (R0)