
Abstract
In the clinical diagnosis and treatment of traditional Chinese medicine (TCM), The classification of pulse is an important diagnostic method. The pulse signal of patients with cardiovascular disease is quite different from that of normal people. In pulse classification, traditional methods generally need to manually extract feature information of the time domain and frequency domain, and then perform pulse classification through machine learning methods such as KNN and SVM. However, the manually extracted features may not really represent the true features of the signal. Convolutional neural network (CNN) can automatically extract local features through different convolution kernels, and it can extract the original features of the signal very well. This paper designs a one-dimensional convolution (1D-CNN) residual neural network structure to identify the pulse signal. First, the original data is sliced and normalized, and then the data set is divided into training set and test set, Then take the processed pulse signal directly as input. This allows the computer to perform feature self-learning through the network structure, Finally, it is classified through the fully connected layer. The final classification accuracy rate can reach 97.14\(\%\), which is better than traditional machine learning classification methods such as SVM and KNN, It provides new ideas and methods for the classification and objectification of pulse signals.
Supported by key project at central government level (2060302).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Pulse diagnosis is very important in traditional Chinese medicine. Most researches focus on obtaining objective evidence of Chinese medicine. Pulse diagnosis analysis is an important objective method of traditional Chinese medicine [1]. Early research found that pulse signal can reflect some symptoms of hypertensive patients. Research found that pulse signal can reflect some symptoms of hypertensive patients. This proves that the pulse condition can be used to predict whether a person suffers from hypertension, which shows that hypertension has a very important relationship with pulse signal. In the theory of traditional Chinese medicine, it is believed that the pulse of most patients with cardiovascular disease is relatively weak [3,4,5]. It is possible to classify and identify the pulse of patients with cardiovascular disease and the pulse of normal people to achieve the prediction of cardiovascular disease and carry out early intervention treatment.

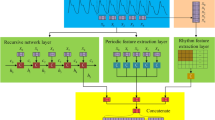
The overall framework of the system.
In the traditional pulse classification methods, most scholars use artificial definition of features, Then use traditional machine learning classification methods such as KNN and SVM to conduct pulse recognition research, However, there is a relatively complex non-linear mapping relationship between the pulse category and the pulse characteristics, and it is difficult to find a suitable characteristic data set for pulse recognition. In recent years, convolutional neural networks have developed rapidly due to their ability to automatically extract features, If there are enough data sets and labels, convolutional neural network (CNN) has a very excellent performance one-dimensional convolutional neural network (1D-CNN) can process time series signals very well, and has good performance in fault detection and other fields. Since 1D-CNN only performs scalar multiplication and addition, 1D-CNN has very good real-time performance and low hardware requirements [6]. This paper proposes a 1D-CNN-based pulse recognition network structure, which is implemented by the deep learning framework Pytorch. The overall research block diagram is shown in Fig. 1.
2 Pulse Data Collection and Processing
2.1 Pulse Data Collection
In the traditional Chinese medicine theory, the collection and analysis of pulse signal are generally divided into three different positions: Cun, Guan and Chi. The Guan pulse signal is the position with the strongest signal among the three positions, and the influence of the Guan pulse signal by the noise signal is relatively small. And the signal is also the easiest to observe and obtain. Therefore, in order to ensure the stability and reliability of the pulse data, The data collected in this article are all signals at the Guan position, and the collection equipment used is ZM-300, and the collection frequency of the pulse diagnosis instrument 200 Hz. The pulse signal collection objects are the students of Zhengzhou University and the patients with cardiovascular disease in the Affiliated Hospital of Zhengzhou University. The pulse signal of patients suffering from cardiovascular disease is generally weak. In traditional Chinese medicine theory, this kind of pulse signal is generally called Xuan mai. The pulse conditions of college students and those of cardiovascular patients are shown in Fig. 2 and Fig. 3.

Pulse of college students.

Pulse of a patients with cardiovascular disease.
After data collection and data screening, the pulses of 60 college students and 54 cardiovascular disease patients were obtained.
2.2 Data Preprocessing and Expansion
The sampling frequency of the acquisition instrument used in this article 200 Hz, and each individual collects the left and right hand pulse signal. Each signal has a length of 10 s and a total of 2000 sampling data points. For pulse signal classification, generally a single cycle pulse signal is used for identification research, However, the period of the pulse signal is difficult to identify and determine. For the deep learning network structure, a certain amount of data set is required, so this article adopts a method of directly slicing the original data, This not only solves the problem that the pulse cycle is difficult to identify, but also maintains the original characteristics of the data, Each set of slice data basically contains three pulse cycle signals [8], and the acquisition time is set to 3.2 s. Because the data samples are too less, the overlapped part can be appropriately increased during the data slicing process. Since the patient’s sample data is lower than the university student’s sample data, in order to ensure the consistency of the data, the repetition rate of the patient’s signal during the sectioning process is slightly higher. This expanded data is more conducive to the training of deep learning networks, The process of data processing is shown in Fig. 4.

The process of data slice processing.
After slicing the data, there are a total of 500 sample data. The pulse data of students and cardiovascular disease patients are shown in Table 1.
Finally, normalize the sliced data, which is more conducive to the computer training network. And it is necessary to label the processed data, using 0 and 1 to represent normal college students and patients with cardiovascular disease. The pulse data processed in this way can be directly used as the original input of the network structure. The network is trained through the training set and the classification accuracy of the network is verified on the test set.
3 Neural Network Structure of Pulse Classification
3.1 The Difference Between 1D-CNN and 2D-CNN
With the rapid improvement of computer hardware and computing power, deep convolutional neural networks such as “AlexNet” and “GogleNet” appeared, these convolutional neural networks have excellent performance on public data sets. Convolutional neural networks can automatically extract features, while traditional machine learning methods are to manually define features, these manually defined features are sub-optimal, Convolutional neural networks can extract optimized features from the original data to obtain high Accuracy [6]. However, most of the above network structures are for processing two-dimensional signals, and these neural network structures cannot be directly used to process one-dimensional time series signals. To solve this problem, Kiranyaz et al. in 2015 proposed the first compact adaptive 1D-CNN that can directly manipulate patient-specific ECG data. Pranav Rajpurkar [9] developed an algorithm that surpasses cardiologists in detecting widespread arrhythmia using electrocardiogram. 1D-CNN has a great advantage when processing time series signals, and pulse signal is a typical time series signal, so this paper designs a neural network structure based on 1D-CNN. The working principles of 1D-CNN and 2D-CNN are shown in Fig. 5 and Fig. 6. The main differences between 1D-CNN and 2D-CNN are as follows:
-
The convolution kernel of 1D-CNN only moves in one direction, and the data of input and output are two-dimensional, mainly used to deal with time series problems; the convolution kernel of 2D-CNN moves in two directions, both input and output data Is three-dimensional, mainly used to process image signals
-
1D-CNN generally uses a lower network depth than the 2D-CNN network structure, and fewer parameters need to be learned during the training process, making it easier to obtain training results
-
1D-CNN usually only uses the computer’s CPU to run, while 2D-CNN usually requires a special GPU for accelerated calculations. Compared with 2D-CNN, 1D-CNN has better real-time performance and lower hardware Equipment requirements.

The working principle of 2D-CNN.

The working principle of 1D-CNN.
3.2 Network Structure
In convolutional neural networks, it is not purely increasing the depth of the network to increase the accuracy of prediction. In the process of training the network, it is necessary to use the backpropagation algorithm to continuously pass the gradient to the front network. When the gradient is passed to the front network, the gradient value will be very small, so that the weight value of the front network cannot be effectively adjusted. In order to avoid the problem of gradient disappearance, a residual network structure is added to the hidden layers. The residual network structure connects the input directly to the output part, so that the learning target can be changed to the difference between the desired output H(x) and the input x [10] The network structure is mainly composed of one-dimensional convolution layer, activation function layer, batch normalization layer, dropout layer, and residual block. The specific network structure diagram is shown in Fig. 7.
Input Layer: It directly converts the sliced signal into a two-dimensional signal as input. The two-dimensional signal represents the number of channels and the length of the signal. The signal dimension of the input layer is 1 * 640 in this article, where 1 represents only one input channel, and 640 represents the length of the signal. The specific structure diagram is shown in Fig. 8.

Block diagram of neural network.

Structure diagram of the input layer.
Convolutional Layer: The convolutional layer is the most important layer in the neural network. The core part of the convolutional layer is the convolution kernel. Various local features of the original signal can be extracted through convolution kernels. The convolution kernel has two attributes of size And the number, The size and number of the convolution kernel are manually specified, and these weight values of convolution kernels are constantly adjusted during the training process, so that the convolution kernel can learn the optimal weight value. Convolution operation also has the advantages of local connection and weight sharing, The number of parameters is only related to the size and number of the convolution kernel and the number of channels of the input signal. The calculation method of the size of the output signal is shown in formula 1:
L represents the length of the output signal; L1 represents the length of the input signal; F represents the length of the convolution kernel, P represents the number of zero padding at the end, and S represents the step length of the convolution kernel.
As shown in Fig. 9, the size of the convolution kernel is 1 * 3, where the value [0.1, 0] in the convolution kernel represents the weight value of the convolution kernel. During the training process, the convolution kernel will be adjusted continuously. The weight value will finally get an optimal model.

Principle of 1D-CNN calculation.
Batch Normalization Layer: In deep learning, the main task is to train the neural network to obtain the distribution law of the data. The function of the batch normalization layer is to distribute the data as close to the origin as possible, make the data distribution meet the normal distribution as much as possible, reduce the absolute difference between the data, and highlight the relative difference of the data, so as to accelerate the training of the network, It will perform well in classification tasks.
Activation Function Layer: There is a complex nonlinear mapping relationship between the input and output of the network. If only linear multiplication of the matrix or array is used, then the deep network Will become meaningless, In order to map the nonlinear relationship between input and output, an activation function layer is generally added after the convolutional layer. Commonly used activation functions are sigmoid and Relu.
Pooling Layer: The pooling layer is mainly to maintain the invariance of signal characteristics, improve the robustness of signal characteristics, while reducing the number of parameters and reducing the amount of calculation, which can effectively prevent overfitting, while the pooling layer is generally Including maximum pooling and average pooling, etc. The principle of average pooling is shown in Fig. 10.

Principle of average pooling.
Fully Connected Layer: A series of detailed features of the signal will be extracted from the front convolutional layer and pooling layer, and the function of the fully connected layer is to combine these detailed features to determine whether it is a feature of a signal. The number of neurons in the last layer is the number of classified categories.
4 The Results and Analysis of the Experiment
4.1 Prepare the Data Set
The original pulse data was screened, and a total of 114 data samples were obtained, Data labels are marked by experts from China Academy of Chinese Medical Sciences. Divide the sliced data set into two parts: test set and training set. In order to ensure that the trained model has sufficient generalization ability, the sample of training set and the test set are completely independent, and the distribution of the training set and the test set is shown in Table 2.
4.2 Analysis of Results
In the classification model, the test set will be divided into two types, positive and negative, which will produce the following four situations respectively [11]:
-
True Positive (TP): The true label of the sample is positive, and the model predicts that the label of the sample is positive
-
False Negative (FN): The true label of the sample is positive, but the model predicts that the sample label is negative
-
False Positive (FP): The true label of the sample is negative, but the model predicts that the sample label is positive
-
True Negative (TN): The true label of the sample is negative, and the model predicts that the label w of the sample is negative
According to the above four situations, the following indicators can be introduced:
True Positive Rate (TPR), also known as Sensitivity: The ratio of the number of correctly classified positive samples to the total number of positive samples: as shown in formula (2):
True Negative Rate (TNR): the ratio of the number of correctly classified negative samples to the number of negative samples, as shown in formula (3)
Accuracy: the proportion of the number of correctly classified samples to the number of all samples [11], as shown in formula (4)
Precision: The proportion of the number of correctly classified positive samples to the number of positive samples in the classifier, as shown in formula (5)
F1-Score: the harmonic average of precision rate and recall rate, the calculation method is shown in formula (6)
The cross entropy function is selected as the loss function in the training process, and the optimization algorithm uses the batch gradient descent algorithm. The cross entropy function is shown in formula (7).
The indicators and parameters of the classifier are shown in Table 3.
The hardware platform used to train the neural network model is CPU i5-4210H@2.9 GHZ, the memory is 12G running memory, the operating system platform is Windows10, the deep learning framework based on Pytorch. The classification accuracy rate can reach about 97.14\(\%\). The loss function and accuracy rate of the training set and test set are shown in Fig. 11. The ROC curve describes the relationship between the True Positive Rate (TPR) and the False Positive Rate (FPR) of the classifier [12]. The ROC curve of the classifier designed in this paper is shown in Fig. 12.

The change curve of the accuracy rate and the loss function of the training set and the test set.

Curve of ROC.
Compared with the traditional manual definition of features, and finally classification with machine learning methods[7], The accuracy of traditional classification methods such as SVM and KNN is basically around 85\(\%\) [2]. The one-dimensional convolutional neural network used in this paper can automatically identify features [13] and has a 97.14\(\%\) accuracy rate. Compared with traditional methods, the neural network in this article has lower computational complexity and higher accuracy.
5 Conclusion
Pulse diagnosis occupies an important position in traditional Chinese medicine. The pulse signal can reflect the physical condition of the human body to a certain extent. In this paper, a 1D-CNN pulse classification is proposed by analyzing the pulse conditions of cardiovascular disease patients and normal people. In the test set, a classification accuracy rate of 97.14\(\%\) is achieved, which proves that the pulse signal has a certain relationship with cardiovascular disease, and has certain practical value for future clinical diagnosis of Chinese medicine. However, because the data samples in this article are not particularly large, the trained model may not have sufficient generalization ability. Therefore, the next step is to obtain as many data samples as possible to improve the generalization ability of the model.
References
Hu, X.J., Zhang, J.T., Xu, B.C., Liu, J., Wang, Y.: Pulse wave cycle features analysis of different blood pressure grades in the elderly. In: Evidence-Based Complementary and Alternative Medicine 2018, pp. 1–12 (2018)
Wang, Y., Li, M., Shang, Y.: Analysis and classification of time domain features of pulse manifestation signals between different genders. In: Chinese Automation Congress, pp. 3981–3984 (2019)
Wang, N.Y., Yu, Y.H., Huang, D.W., Xu, B., Liu, J.: Pulse diagnosis signals analysis of fatty liver disease and cirrhosis patients by using machine learning. Sci. World J. 2015, 1–9 (2015)
Moura, N.G.R., Cordovil, I., Ferreira, A.S.: Traditional Chinese medicine wrist pulse-taking is associated with pulse waveform analysis and hemodynamics in hypertension. J. Integr. Med. 14(2), 100–113 (2016)
Cogswell, R., Pritzker, M., De, M.T.: Performance of the REVEAL pulmonary arterial hypertension prediction model using non-invasive and routinely measured parameters. J. Heart Lung Transpl. 33(4), 382–387 (2014)
Kiranyaz, S., Avci, O., Abdeljaber, O.: 1D convolutional neural networks and applications: a survey. arXiv preprint arXiv:1905.03554 (2019)
Zhang, D., Zuo, W., Wang, P.: Generalized feature extraction for wrist pulse analysis: from 1-D time series to 2-D matrix. In: Computational Pulse Signal Analysis, pp. 169–189. Springer, Singapore (2018). https://doi.org/10.1007/978-981-10-4044-3_9
Urtnasan, E., Park, J.-U., Joo, E.-Y., Lee, K.-J.: Automated detection of obstructive sleep apnea events from a single-lead electrocardiogram using a convolutional neural network. J. Med. Syst. 42(6), 1–8 (2018). https://doi.org/10.1007/s10916-018-0963-0
Hannun, A.Y., Rajpurkar, P., Haghpanahi, M., Tison, G.H., Bourn, C.: Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 25(1), 65 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, pp. 770–778 (2016)
Kiranyaz, S., Zabihi, M., Rad, A.B., Ince, T., Hamila, R., Gabbouj, M.: Real-time phonocardiogram anomaly detection by adaptive 1D convolutional neural networks. Neurocomputing (2020)
Arji, G., Safdari, R., Rezaeizadeh, H., Abbassian, A., Mokhtaran, M., Ayati, M.H.: A systematic literature review and classification of knowledge discovery in traditional medicine. Comput. Methods Programs Biomed. 168, 39–57 (2019)
Li, F., et al.: Feature extraction and classification of heart sound using 1D convolutional neural networks. EURASIP J. Adv. Signal Process. 2019(1), 1–11 (2019). https://doi.org/10.1186/s13634-019-0651-3
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Jiao, Y., Li, N., Mao, X., Yao, G., Zhao, Y., Huang, L. (2021). Pulse Recognition of Cardiovascular Disease Patients Based on One-Dimensional Convolutional Neural Network. In: Pan, L., Pang, S., Song, T., Gong, F. (eds) Bio-Inspired Computing: Theories and Applications. BIC-TA 2020. Communications in Computer and Information Science, vol 1363. Springer, Singapore. https://doi.org/10.1007/978-981-16-1354-8_20
Download citation
DOI: https://doi.org/10.1007/978-981-16-1354-8_20
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-1353-1
Online ISBN: 978-981-16-1354-8
eBook Packages: Computer ScienceComputer Science (R0)