
Abstract
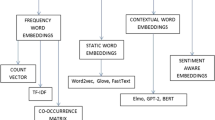
Word embeddings are fundamentally a form of word representation that links the human understanding of knowledge meaningfully to the understanding of a machine. The representations can be a set of real numbers (a vector). Word embeddings are scattered depiction of a text in an n-dimensional space, which tries to capture the word meanings. This paper aims to provide an overview of the different types of word embedding techniques. It is found from the review that there exist three dominant word embeddings namely, Traditional word embedding, Static word embedding, and Contextualized word embedding. BERT is a bidirectional transformer-based Contextualized word embedding which is more efficient as it can be pre-trained and fine-tuned. As a future scope, this word embedding along with the neural network models can be used to increase the model accuracy and it excels in sentiment classification, text classification, next sentence prediction, and other Natural Language Processing tasks. Some of the open issues are also discussed and future research scope for the improvement of word representation.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
El-Din DM (2016) Enhancement bag-of-words model for solving the challenges of sentiment analysis. Int J Adv Comput Sci Appl (IJACSA)7(1):244-252
Soumya George K, Joseph S (2014) Text classification by augmenting bag of words (BOW) representation with co-occurrence feature. IOSR J Comput Eng (IOSR-JCE) 16(1):34–38
Enríquez F, Troyano JA, López-Solaz T (2016) An approach to the use of word embeddings in an opinion classification task. Exp Syst Appl 66:1–6
Tripathy A, Agrawal A, Rath SK (2015) Classification of sentimental reviews using machine learning techniques. Proc Comput Sci 57:821–829
Qu S, Wang S, Zou Y (2008) Improvement of text feature selection method based on TFIDF. In: 2008 international seminar on future information technology and management engineering. Leicestershire, United Kingdom, pp 79–81
Dadgar SMH, Araghi MS, Farahani MM (2016) A novel text mining approach based on TF-IDF and support vector machine for news classification. In: IEEE international conference on engineering and technology (ICETECH), Coimbatore, pp 112–116
Jing L-P, Huang H-K, Shi H-B (2002) Improved feature selection approach TFIDF in text mining. In: Proceedings of the first international conference on machine learning and cybernetics. IEEE, vol 2, pp 944–946
Kuang Q, Xu X (2010) Improvement and application of TF⋅IDF method based on text classification. In: 2010 international conference on internet technology and applications. Wuhan, pp 1–4
Matsuo Y, Ishizuka M (2004) Keyword extraction from a single document using word co-occurrence statistical ınformation. Int J Artif Intell Tools 13(01):157–169
Albathan M, Li Y, Algarni A (2012) Using patterns co-occurrence matrix for cleaning closed sequential patterns for text mining. In: Li Y, Zhang Y, Zhong N (eds) Proceedings of the IEEE/WIC/ACM international conference on web ıntelligence and ıntelligent agent technology, vol 1, pp 201–205
Kadhim AI, Cheah Y-N, Ahamed NH, Salman LA (2014) Feature extraction for co-occurrence-based cosine similarity score of text documents. In: 2014 IEEE student conference on research and development, pp 1–4
Lott B (2012) Survey of keyword extraction techniques. UNM Educ 50:1–11
Wang LH (2014) An ımproved method of short text feature extraction based on words co-occurrence. Appl Mech Mater 519:842–845 (Trans Tech Publications Ltd.)
Wartena C, Brussee R, Slakhorst W (2010) Keyword extraction using word co-occurrence. In: 2010 workshops on database and expert systems applications. IEEE, pp 54–58
Ge L, Moh T-S (2017) Improving text classification with word embedding. In: 2017 IEEE ınternational conference on big data (big data), Boston, MA, pp 1796–1805
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Reem A, O’Keefe S (2019) Deep learning and word embeddings for tweet classification for crisis response. In: The 3rd national computing colleges conference. arXiv preprint arXiv:1903.11024.
Zhou S, Ling TW, Guan J, Hu J, Zhou A (2003) Fast text classification: a training-corpus pruning based approach. In: Eighth international conference on database systems for advanced applications, 2003 (DASFAA 2003). Proceedings, Kyoto, Japan, pp 127–136
Joulin A, Grave E, Bojanowski P, Mikolov T (2017) Bag of tricks for efficient text classification. In: Proceedings of the 15th conference of the European chapter of the association for computational linguistics, vol 2, Short Papers, pp 427–431
Kuyumcu B, Aksakalli C, Delil S (2019) An automated new approach in fast text classification (fastText). A case study for Turkish text classification without pre-processing. In: Proceedings of the 2019 3rd international conference on natural language processing and ınformation retrieval, pp 1-4
Rezaeinia SM, Ghodsi A, Rahmani R (2017) Improving the accuracy of pre-trained word embeddings for sentiment analysis. arXiv preprint arXiv:1711.08609
Lilleberg J, Zhu Y, Zhang Y (2015) Support vector machines and Word2Vec for text classification with semantic features. In: IEEE 14th international conference on cognitive informatics & cognitive computing (ICCI*CC), Beijing, pp 136–140
Vora P, Khara M, Kelkar K (2017) Classification of tweets based on emotions using word embedding and random forest classifiers. Int J Comput Appl 178(3):1–7
Stein RA, Jaques PA, Valiati JF (2019) An analysis of hierarchical text classification using word embedding. Inf Sci 471:216–232 (Elsevier)
Tezgider M, Yıldız B, Aydın G (2018) Improving word representation by tuning Word2Vec parameters with deep learning model. In: 2018 international conference on artificial intelligence and data processing (IDAP), Malatya, Turkey, pp 1–7
Elsaadawy A, Torki M, Ei-Makky N (2018) A text classifier using weighted average word embedding. In: 2018 international Japan-Africa conference on electronics, communications and computations (JAC-ECC). Egypt, pp 151–154
Mikolov T, Grave E, Bojanowski P, Puhrsch C, Joulin A (2017) Advances in pre-training distributed word representations. arXiv preprint arXiv:1712.09405
Raunak V, Gupta V, Metze F (2019) Effective dimensionality reduction for word embeddings. In: Proceedings of the 4th workshop on representation learning for NLP (RepL4NLP-2019), pp 235–243
Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations. arXiv preprint arXiv:1802.05365 [cs.CL]
Manoharan S (2019) A smart image processing algorithm for text recognition, information extraction and vocalization for the visually challenged. J Innov Image Process (JIIP) 1(01):31–38
Maslennikova E (2019) ELMo word representations for news protection. In CLEF (Working Notes).
Alsentzer E, Murphy J, Boag W, Weng W-H, Jindi D, Naumann T, McDermott M (2019) Publicly available clinical BERT embeddings. In: Proceedings of the 2nd clinical natural language processing workshop, pp 72–78
Wu X, Lv S, Zang L, Han J, Hu S (2019) Conditional BERT contextual augmentation. In: Rodrigues J et al (eds) Computational science—ICCS 2019. Lecture notes in computer science, vol 11539. Springer, Cham
Chang W-C, Yu H-F, Zhong K, Yang Y, Dhillon I (2019) X-BERT: eXtreme multi-label text classification using bidirectional encoder representations from transformers. arXiv preprint arXiv:1905.02331 [cs.LG]
Schwartz A (2020) Combining word embeddings for binary classification tasks
Jwa H, Oh D, Park K, Kang JM, Lim H (2019) exBAKE: automatic fake news detection model based on bidirectional encoder representations from transformers (BERT). Appl Sci 9:4062
Han X, Eisenstein J (2019) Unsupervised domain adaptation of contextualized embeddings for sequence labeling. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing, pp 4238–4248. arXiv:1904.02817 [cs.CL]
Chakraborty R, Elhence A, Arora K (2019) Sparse victory—a large scale systematic comparison of count-based and prediction-based vectorizers for text classification. In: Proceedings of the international conference on recent advances in natural language processing (RANLP 2019), pp 188–197
Felipe A, Xexéo G (2019) Word embeddings: a survey. arXiv preprint arXiv:1901.09069
Ethayarajh K (2019) How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. arXiv preprint arXiv:1909.00512
Liu X, He P, Chen W, Gao J (2019) Multi-task deep neural networks for natural language understanding. arXiv preprint arXiv:1901.11504
Hou Y, Zhou Z, Liu Y, Wang N, Che W, Liu H, Liu T (2019) Few-shot sequence labeling with label dependency transfer. arXiv preprint arXiv:1906.08711
Sun Y, Wang S, Li Y, Feng S, Tian H, Wu H, Wang H (2019) Ernie 2.0: a continual pre-training/framework for language understanding. arXiv preprint arXiv:1907.12412
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Selva Birunda, S., Kanniga Devi, R. (2021). A Review on Word Embedding Techniques for Text Classification. In: Raj, J.S., Iliyasu, A.M., Bestak, R., Baig, Z.A. (eds) Innovative Data Communication Technologies and Application. Lecture Notes on Data Engineering and Communications Technologies, vol 59. Springer, Singapore. https://doi.org/10.1007/978-981-15-9651-3_23
Download citation
DOI: https://doi.org/10.1007/978-981-15-9651-3_23
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-9650-6
Online ISBN: 978-981-15-9651-3
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)