
Abstract
Content-based image retrieval (CBIR) comprises recovering the most outwardly comparative images to a given question image from a database of images. CBIR from therapeutic image databases does not plan to supplant the doctor by anticipating the sickness of a specific case however to help him/her in analysis. The visual attributes of an ailment convey analytic data, and periodically outwardly comparative images relate to a similar infection class. By counseling the yield of a CBIR framework, the doctor can acquire trust in his/her choice or considerably think about different potential outcomes. With high-dimensional information in which every point of view on information is of high spatiality, determination of highlights is imperative to further build the aftereffects of bunching and characterization. To ease the enthusiastic miscellany in the precision of image retrieval, we developed another graph-based learning strategy technique to successfully recover images from remote detecting. The proposed strategy utilizes a four-layered framework that joins the feature level fusion of Gabor and ripplet Transform of selected query along with SVR. In the first layer two image sets are retrieved utilizing the Gabor and Ripplet-based wavlet Decomposition separately, and the besides, the top ranked retrieved images from both the top up are further used to find their queries. Using each individual part, the chart grapples recoup six image sets from the image database as an augmentation request in the subsequent layer. The photos in the six image sets are evaluated for positive and negative data age in the third layer, and Simple MKL is associated with gain proficiency with the proper inquiry subordinate combination loads to accomplish the last consequence of image recuperation. This research is based on building fully-automatic four layer systems capable of performing large-scale image search based on texture information. An effective four layer architecture with the application of SVR was proposed in this study for the purpose of retrieving images from CIFAR dataset.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Graph-based learning
- Content-based image retrieval
- Color co-occurrence feature
- Ordered dither block truncation coding
- Rotation invariant
1 Introduction
Because of its capacity to search and index multimedia images, the ever-increasing amount of digital images on the internet makes the image retrieval based on content shine golden. Content-based picture recovery methods are inherent requirements in multimedia apps through Internet use. Most probably, CBIR systems use color, texture, shape or any other data that is automatically obtained from query and database pictures. The retrieved pictures are refined by ranking in perspective of the proximity between the initial and database pictures. Inefficiency of CBIR systems is anticipated in the gap between highlights of small dimensions and semantic characteristics. Numerous papers are acquainted which demonstrate the assortment of client communication with the question image, and the assortment of inquiry and database image highlights preparing plans. It is conceivable to isolate the CBIR plans into couple of significant classes. Anybody with information of these classifications can receive their advantageous CBIR framework with the sorts of system, gadget and image.
Ripplet and Gabor highlights are two sorts of image portrayal descriptors. Ripplet highlights are particularly fit for taking care of nearby picture examples or surfaces, while Gabor highlights depict a picture's general format. One drawback of considering two features is that the image regain consistently take after the other the same yet may be irrelevant to the request since image classification regularly address large texture of natural scenes containing inexhaustible and complex visual objects. The extreme noise from irrelevant objects are more often than region of interest. Unmistakably, recovery precision can be tremendously improved by coordinating their qualities. Since the element and algorithmic methods are essentially one of a kind, it is definitely not a brilliant idea to straightforwardly join particular segment vectors into one vector to improve image recuperation precision. In spite of the fact that inquiry development can accomplish precise recovery results, because of false positive recorded records, the show of inquiry augmentation will all in all degrade.
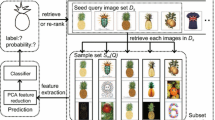
Spurred by the characteristics of the inquiry expansion and the particular technique for combination of positions, we propose a four-layered diagram-based learning approach for remote detecting images. We separate the Gabor include and the ripplet highlight in this methodology. Next, there are four layers of the image recuperation process. Utilizing the Gabor learning calculation in the primary layer, a image rundown is recovered from the remote detecting picture database in which each image is like the question. As needs be, we acquire another image list by utilizing the ripplet highlight learning calculation.
We first re-rank the pictures in the over two records in the subsequent layer and afterward get three kinds of chart grapples: PH, PL, and PC. PH and PL are the two records ‘top-positioned pictures.’ PC contains comparable normal pictures of the two records. Utilizing the Gabor include or the ripplet highlight learning calculation, we take PH, PL, and PC as the inquiries for recovering information base pictures. Along these lines, it is possible to get six records containing recovered pictures. In the third level, by assessing the pictures in the six records, positive and negative sets are chosen. The parameters in Simple MKL are prepared to meld the eventual outcomes of the recovery, and we get the last pictures that have been recovered.
The fundamental commitments of this paper are abridged as pursues.
-
1.
A tale, four-layered diagram-based learning approach is being created to recover remote detecting images. The methodology refines the first inquiry contribution by uniting it with the recovered images which got top-positioned. The nature of the outcomes got using ripplet or Gabor highlight strategies is checked, and the arranged picture sets are intertwined to produce the last consequence of the recovery. The exactness of the recovery is fundamentally improved without giving up the adaptability of the technique proposed.
-
2.
Another strategy for extension inquiry is acquainted that is strong with concentrate insecure highlights. Its primary bit of leeway is that numerous significant images are mined by a solitary info images as opposed to requiring multi-pertinent pictures to be contribution by clients. An increasingly extreme expansion request images set is formed as before learning for the accompanying recuperation by getting the recouped images together with the main inquiry. The exactness of images recuperation can be improved through the set. The proposed methodology can dispense with the inadequacy of the single picture-based recovery.
-
3.
To engage accurate assessment of the nature of each arrival, a novel methodology is exhibited to combine diverse image recovery results. For Gabor and ripplet highlights, Simple MKL is connected to learn appropriate inquiry subordinate combination loads. Various consequences of the image recuperation are intertwined to improve the precision of the recuperation.
In CBIR tasks, various feature extraction methods are documented. Sparse based methods are most popular due to their compact representation of image pixels. DWT transforms are good example of sparse methods, but the failed to represent the texture when edges ames in picture. Gabor features are well known for its predictability. It extract the texture in various scales and directions [1]. Ridglet transforms are mostly used for curvilinear texture [2, 3] but it needs more coefficient to represent the image and also it has more complex representation [4]. To overcome those limitation curvelet features are used [5]. Thus the documented method failed to extract fully detail textures in the image such as curves. To overcome the problem Cuve features are extracted which is capable to extract the all the ridges in an image [6]. Ripplet transform is used for represent the image with this non linear singularities at different scales and orientation. This issue in giving accurate recovery images and minimizing the assistance to the analyst to utilize (CBIR) framework.
The strategy in [7] demonstrated the all-encompassing portrayal of the spatial envelope with extremely low dimensionality to make the picture of the occurrence. This methodology introduced an outstanding outcome in the classification of the scene. To achieve a perfect result, the system in [8] proposed a propelled approach to manage picture portrayal with open field structure and the possibility of over-satisfaction technique as revealed in [8], this methodology achieved the best execution in characterization with much lower spatiality contrasted with the past plans in the undertaking of arrangement of pictures. Tiwari et al. developed a US-based patent database CBIR framework [PATSEEK] as a patent comprising of a picture and literary data. The client must enter catchphrases alongside the question picture that may show up in the patent content for closeness search [9]. Krishnan et al. made concrete setup with CBIR based on the edge, texture and color histogram in the image, which just gives the image’s semantics. By using this along with edge orientation greatly reduce time. By using frontal territory challenges alone, overpowering concealing distinctive confirmation can recoup number of similar pictures paying little regard to gauge, considering the bleeding edge concealing. Higher typical precision and survey rates were cultivated adequately appeared differently in relation to the standard dominant color strategy [10]. The image is addressed in another structure by a fuzzy attributed relational graph (FARG) depicting everything in the image, its properties and spatial relationship. The qualities of surface and concealing are resolved to demonstrate the human vision system (HSV) [11]. Using Gabor wavelets, the semantics of surface is recouped. Use gradient vector flow fields to isolate the shape incorporate. It shows the makers in [12] a precision of 60.7 percent; anyway, the inconvenience is that it has incredibly low accuracy. In [13], the makers propose a system that uses an image's concealing characteristics to outline a vector of features. Computer-based intelligence classifiers by then use these features to arrange the photos, yet texture and shape features are not considered.
2 Proposed System
2.1 Holistic Descriptor (HD)
Over the last few years, different approaches have been proposed to improve holistic methods for feature extraction. One of the most successful strategies has shown to be the use of Gabor representation of the images. HD features are a extension of holistic feature descriptor. The Gabor channel (Gabor wavelet) speaks to a band-pass direct channel whose motivation reaction is characterized by a symphonious capacity increased by a Gaussian capacity. Along these lines, a bidimensional Gabor channel establishes a complex sinusoidal plane of specific recurrence and direction adjusted by a Gaussian envelope [1]. Gabor features have been known to be effective for representation. But, only a few approaches utilize phase feature, and they usually perform worse than those using magnitude feature. For this reason, only the magnitudes of the Gabor coefficients are thought of as being useful for feature extraction. It accomplishes an ideal goals in both spatial and recurrence areas.
Our methodology structures 2D odd-symmetric Gabor filter, having the accompanying structure:
2.2 Nonlinear Approximated Ripplet Transform (NART)
To defeat the confinement of wavelet, ridgelet change [2, 3] was presented. Ridgelet change can resolve 1D singularities along a self-assertive heading (counting level and vertical bearing). Ridgelet change gives data about direction of straight edges in pictures since it depends on radon change [4], which is fit for extricating lines of subjective direction. Since ridgelet change cannot resolve 2D singularities, Candes and Donoho proposed the original curvelet change dependent on multi-scale ridgelet [5, 6]. Afterward, they proposed the second era curvelet change [7, 8]. Curvelet change can resolve 2D singularities along smooth bends. Curvelet change utilizes an illustrative scaling law to accomplish anisotropic directionality. From the point of view of microlocal investigation, the anisotropic property of curvelet change ensures settling 2D singularities along C2 bends [9, 7, 8, 10]. Like curvelet, contourlet [11, 12] and bandlet [13] were proposed to determine 2D singularities.
Be that as it may, it is not clear why allegorical scaling was picked for curvelet to accomplish anisotropic directionality. With respect to, we have two inquiries: Is the explanatory scaling law ideal for a wide range of limits? If not, what scaling law will be ideal? To address these two inquiries, we plan to sum up the scaling law, which results in another change called ripplet change Type I. Ripplet change Type I sums up curvelet change by including two parameters, i.e., bolster c and degree d; thus, curvelet change is only an extraordinary instance of ripplet change Type I with c = 1 and d = 2. The new parameters, i.e., bolster c and degree d, give ripplet change anisotropy ability of speaking to singularities along self-assertively formed bends.
Substitute with discrete parameters
Forward transform
Nonlinear approximation (NLA).
Sort coefficient in descending order
Approximate signal by n-largest coefficients
The ripplet change has the accompanying capacities:
Multi-goals: Ripplet change gives a progressive portrayal of pictures. It can progressively rough pictures from coarse to fine goals.
-
Good restriction: Ripplet capacities have minimized help in recurrence area and rot exceptionally quick in spatial space. So ripplet capacities are all around restricted in both spatial and recurrence areas.
-
High directionality: Ripplet capacities situate at different headings. With the expanding of goals, ripplet capacities can acquire more headings.
-
General scaling and backing: Ripplet capacities can speak to scaling with subjective degree and backing.
-
Anisotropy: The general scaling and bolster result in anisotropy of ripplet capacities, which certifications to catch singularities along different bends.
-
Fast coefficient rot: The sizes of ripplet change coefficients rot quicker than those of different changes, which means higher vitality focus capacity.
2.2.1 First Layer
We only consider the query image as the labeled image, and the remaining images are considered unlabeled.
For each query image, a weighted cum directed chart is constructed from each individual feature-based retrieval method, where the retrieval quality or the relevance is modeled by the weights on the edges, where
v is a lot of vertices,
e is a lot of edges and
w is a lot of edge weights.
Each database image corresponds to a vertex in C. For each image, we identify its k-nearest neighbors and connect the corresponding vertices in C with edges that are associated with the distance between the two vertices.
Given an image dataset Y = {y1, ..., yl, yl + 1, ..., yn}.For each image, we identify its k-nearest neighbors and connect the corresponding vertices in C with edges (E) that are associated with the distance between the two vertices (V).E corresponds to the similarity among vertices with the weight W defined by,
where d(\({V}_{i}\), \({V}_{j}\)) denotes the feature distance between the vertices \({V}_{i}\) and \({V}_{j}\), and \({W}_{ij}\) is the edge weight of \({E}_{ij}\). σ is a constant that controls the strength of the weight, and it is set as the median distance among all images. After that, pairwise relevance is obtained through maximum correlation algorithm.
We have obtained two retrieval image lists by using the graph-based holistic and local feature learning algorithms. The two lists represent different retrieval results and have different image arrangements.
2.2.2 Second Layer Graph
We select the top-positioned pictures from the lists as the new input to further refine the retrieval results. To achieve this, we utilize the re-ranking method to obtain the top-positioned pictures as graph anchors. Then, these anchors are taken as new queries to further improve the recovery exactness.
To generate accurate graph anchors for learning the joint relevance of the holistic and local features, it is necessary to precisely measure the similarity among the images. We define the similarity degree of the two images as the relative similarity score (RSS). RSS can be computed by using the following re-ranking method.
where
Q is the question picture.
N is used to represent the retrieved image matrix.
A1, A2, ..., Am are the top-positioned pictures in the retrieval results in the first layer, which are stored in a list LQ.
The images in LQ are further used as queries to perform the search. For example, N11, N12, ..., N1m are the query results of A1. Similarly, each of the other images in LQ retrieves the m best matching database images. Finally, m + 1 lists are generated.
We compute the normalized similarity score (NSS) between two images. The SS between the retrieved images Nij and Q is derived by,
When NSS (Q, Nij) is computed, we first consider the relationship between Q and Ai. If they are very similar, many common images exist in the lists LQ and LAi, and the spatial distributions of the image features are similar between the two lists.
After the images in H_LQ and L_LQ are re-ranked, the top retrieved images are taken as the prior knowledge for further image retrieval. In the following, we obtain three types of graph anchors: PH, PL and PC. PH and PL are the top re-ranked images of H_LQ and L_LQ, respectively, whereas PC contains the common imagesin both of the top re-ranked lists (H_LQ and L_LQ). If PC is no smaller than the given similarity threshold, the corresponding common image in the lists is taken as a graph anchor in PC. The aforementioned process is continued until all of the common images in H_LQ and L_LQ are traversed.
We take PH, PL and PC as query images to retrieve images from the image database using the learning algorithm of holistic and local features introduced in the first layer. We label these queries as the prior knowledge, where the values of the graph anchors are all equal to 1.
Thus, we obtain six retrieval lists through the two graphs GH and GL. That is, through the graph GH, we separately derive three retrieved results (LHH, LHL, and LHC) corresponding to the queries PH, PL and PC. Accordingly, we also obtain other three retrieved results (LLH, LLL and LLC) by GL. LHH and LLL are the results of reinforcement learning. LHL, LLH, LHC and LLC are the results of the preliminary fusion. We know that LHL and LHC are the retrieval results corresponding to the graph GH of the holistic feature, but the queries are the graph anchors PL and PC which are not generated from GH. Similarly, LLH and LLC are the retrieval results corresponding to GL, but the queries are the graph anchors PL and PC which are not generated from GL. LHC and LLC are also the results of the graph-based learning algorithm of holistic and local features, which use the common graph anchors as the queries. This approach can reduce the influence of some inappropriate graph anchors on the retrieval result to a certain extent.
2.2.3 Third Layer
To generate the fusion retrieval result of different features, we assess the exhibition of the retrieved images in the aforementioned six lists and find similar and dissimilar images. Then, we gain proficiency with the loads of holistic and local features and related parameters of the fusion. For the fusion process, positive data and negative data are needed. Thus, we introduce an image list (LG) that contains similar images (positive data), as well as a second one (LD) that contains the dissimilar images (negative data).
To create LD, we randomly selected a certain number of images from the bottom of LHH, LHL, LHC, LLH, LLL and LLC separately and stored them in LD.
The images in LHH, LHL, LHC, LLH, LLL and LLC are re-ranked separately. The top-positioned pictures are usually very similar to the query image and have a place with a similar class. We apply the retrieval consistency to evaluate the aforementioned re-ranked results. For example, we select the cn top-ranked images from re-ranked LHH as the graph anchors for an expansion query. From the retrieved result LHH, we can obtain a specific number of the top-ranked images by using the retrieval result evaluation. These images are stored in the aforementioned image list LG.
The evaluation processes of other retrieval lists are the same as the process of LHH. To the retrieved results LHL, LHC, LLH, LLL and LLC, we compute their consistency degree and choose the good retrieval results for the fusion of the final result. These images are also stored in LG.
After the evaluation, we need to address the problem of obtaining the best fusion weights. In the image lists LG, the images are taken as the positive data, and the images in LD with low similarity are taken as negative data. By using distance metric, we rearrange LG & LD according to query.
2.2.4 Fourth Layer
We train the parameters of ISVR through these data and the two features. ISVR determines the combination of the feature weights by solving a standard SVM advancement issue dependent on a gradient descent method.
2.3 Computational Complexity Analysis
The regular method to express the multifaceted nature of one calculation is utilizing enormous o documentation. Assume that we have n database images. The computational cost of the proposed method mainly lies in the four layers. In the first layer, the image retrieval is computed with the cost of O(n3 + n2). In the second layer, since the number of re-ranking is far not exactly n, the complexity of the re-ranking process can be negligible. The cost for the second layer is O(n3 + n2). In the third and fourth layer, the main computational cost is for optimizing the parameters in distance metric and ISVR with the time complexity of O(N3 + lN2 + dlN), where d is the feature dimension, l is the number of training samples and N is the quantity of help vectors. Since d << n and l<< n, in the third layer, different features can be fused quickly.
2.3.1 Incremental Support Vector Regression:
SVM can be utilized as a relapse show, keeping up all the primary highlights that contribute to maximal edge. ISVR utilizes indistinguishable standards from the SVM for grouping, with just a couple of minor changes. As a matter of first importance, since yield is a genuine number, it ends up being exceptionally hard to anticipate the current data, which has limitless conceivable outcomes. On account of relapse, an edge of resistance (epsilon) is set in estimation to the SVM which would have effectively asked for from the issue. Yet, other than this reality, there is likewise a more confused reason, and the calculation is more convoluted in this manner to be taken in thought. Notwithstanding, the principle thought is dependably the same: to limit mistake, individualizing the hyperplane which augments the edge, remembering that piece of the blunder is endured.
Kernel functions:
For Polynomial
3 Experiments and Results
The CIFAR-100 dataset is a collection of images with 32 × 32 size and that are commonly used for classification purpose. It is one of the most widely used datasets for image retrieval method validation. The CIFAR-100 dataset contains 60,000 (32 × 32) color images in 10 different classes. In our case, we test algorithm for 500 images and calculated accuracy as number of images retrieved from a class.
3.1 Retrieval Accuracy:
Retrieval accuracy is delineated as the competency to distinguish the relevant as well as irrelevant images. The accuracy is a gauge of the extent of the closeness of a calculated or measured value to its original value. Accuracy also stands as the degree to which the outcome of a calculation, specification or measurement matches to the standard (correct) value. The accuracy of retrieval is ascertained utilizing the equation.
Retrieval Accuracy = [Correctly Retrieved Images]/[Total No of Retrieved Images].
Retrieval Time = Feature Extraction Generation Time + Similarity Measurement Time.
The following table shows class-wise accuracy (Figs. 1–2 and Tables 1– 2).

Class-wise accuracy for different methods

Comparison of several methods for precision versus recall
The above table shows accuracy of the proposed method with other method; from the figure, it is clear that our method gets 94% accuracy, which is very far from the traditional method (Table 3).
In the confusion matrix, table shows 10 classes used for testing reability of our project. We take 10 classes from CIFAR-100 database; out of that each class, we took 500 images for testing. The above table shows the correctly retrieved images out of 500 proposed method retrieve 471 images correctly for fish, 453 images for flowers, etc.
4 Conclusion
During the previous decade, exceptional advancement has been made in both hypothetical research and framework improvement. The driving force behind substance-based image recovery is given by the wide accessibility of computerized sensors, the Internet and the falling cost of capacity gadgets. Given the extent of these main impetuses, it is to us that content-based recovery will keep on developing toward each path: new crowds, new purposes and new styles of utilization, new methods of association, bigger informational collections and new strategies to take care of the issues. A wide investigation has been made on image recovery. Each work has its very own methods, commitment and impediments. This paper is generalizable to other categorization tasks, and is applicable to any Dataset. Experimental results endeavour that proposed method significantly outperforms the baselines including deep learning models based on coarse and fine categories.
We proposed a four-layered remote detecting image recuperation technique dependent on ripplet and Gabor qualities in this paper. In contrast to the past techniques for recovering pictures, which frequently link a wide range of highlights into one vector to recover image, we have broadened the inquiry and connected another four-layered way to deal with recovering images to meld various highlights. The proposed methodology refines the first information inquiry to broaden the question by joining it with the top-positioned recovery results acquired utilizing strategies dependent on the Gabor and ripplet highlights. For further recovery of six image sets, the extension inquiry images are taken as chart grapples.
To create positive information and negative information, the images in each set are assessed. For the Gabor and ripplet highlights, Simple MKL is associated with learn suitable request subordinate blend loads. Assessments were coordinated in each layer, demonstrating that the exactness in the present layer surpasses those in the past layers. The created system for remote distinguishing picture recuperation is in this manner sensible and adaptable. Examinations of our technique with different strategies further demonstrated that our strategy produces extremely aggressive recuperation execution with a solitary information question image.
References
Movellan JR Tutorial on Gabor filters. https://mplab.ucsd.edu/tutorials/gabor.pdf.
Candes EJ, Donoho DL (1999) Ridgelets: a key to higher-dimensional intermittency? Philos Trans Math Phy Eng Sci 357(1760):2495–2509
Do M, Vetterli M (2003) The finite ridgelet transform for image representation. IEEE Trans Image Process 12(1):16–28
Deans SR (1983) The radon transform and some of its applications. Wiley, New York
Starck JL, Candes EJ, Donoho DL (2002) The curvelet transform for image denoising. IEEE Trans Image Process 11:670–684
Donoho DL, Duncan MR (2000) Digital curvelet transform: strategy, implementation and experiments. In: Proceedings of the aerosense 2000, Wavelet Applications VII. SPIE, vol 4056, pp 12–29.
Candes E, Donoho D (2005a) Continuous curvelet transform: I. Resolution of the wave front set. Appl Comput Harmon Anal 19(2):162–197
Candes E, Donoho D (2005b) Continuous curvelet transform: II. Discretization and frames. Appl Comput Harmon Anal 19:198–222
Hormander L (2003) The analysis of linear partial differential operators. Springer, Berlin
Candes EJ, Donoho DL (2003) New tight frames of curvelets and optimal representations of objects with piecewise c2 singularities. Commun Pure Appl Math 57(2):219–266
Do MN, Vetterli M (2005) The contourlet transform: an efficient directional multire solution image representation. IEEE Trans Image Process 14(12):2091–2106
Do MN, Vetterli M (2003) Contourlets. In: Welland GV (ed) Beyond Wavelets. Academic Press, New York
Le Pennec E, Mallat S (2005) Sparse geometric image representations with bandelets. IEEE Trans Image Process 14(4):423–438
Bosch SPAA, Zisserman A, Munoz X (2007) Representing shape with a spatial pyramid kernel. In: Proceedings of international conference on image video retrieval. New York, NY, USA, pp 401–408
Xia S, Hancock E (2008) 3-D object recognition using hyper-graphs and ranked local invariant features. In: Structural S, Recognition StatisticalPattern (eds) New York. Springer-Verlag, NY, USA, pp 117–126
Lazebnik S, Schmid C, Ponce J (2006) Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: Proceedings of IEEE conference on computer vision pattern recognition, pp 2169–2178
Kavitha S, Varuna S, Ramya R (2016) A comparative analysis on linear regression and support vector regression. In: Online international conference on green engineering and technologies (IC-GET), IEEE
Nhat HTM, Hoang VT (2019) Feature fusion by using LBP, HOG, GIST descriptors and canonical correlation analysis for face recognition. In: International conference on telecommunications (ICT)
Ali Z, Christofides N, Polycarpou A (2017) Performance enhanced RES current controller with reduced computational complexity. In: International conference on modern power systems (MPS 2017)
Wang C, Zhang B, Qin Z, Xiong J (2013) Spatial weighting for bag-of-features based image retrieval. In: Integrated uncertainty in knowledge modelling and decision making. Springer, pp 91–100
Mehmood Z, Anwar SM, Ali N, Habib HA, Rashid M (2016) A novel image retrieval based on a combination of local and global histograms of visual words
Wu P, Hoi SCH, Xia H, Zhao P, Wang D, Miao C (2013) Online multimodal deep similarity learning with application to image retrieval. ACM Multimedia 153–162
Vadivel SP, Yuvaraj D, Krishnan SN, Mathusudhanan SR (2019) An efficient CBIR system based on color histogram, edge, and texture features. Concurrency Comput: Pract Experience 31(12)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Salunkhe, S., Gaikwad, S.P., Gengaje, S.R. (2021). A Novel Approach for CBIR Using Four-Layered Learning. In: Merchant, S.N., Warhade, K., Adhikari, D. (eds) Advances in Signal and Data Processing . Lecture Notes in Electrical Engineering, vol 703. Springer, Singapore. https://doi.org/10.1007/978-981-15-8391-9_44
Download citation
DOI: https://doi.org/10.1007/978-981-15-8391-9_44
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-8390-2
Online ISBN: 978-981-15-8391-9
eBook Packages: EngineeringEngineering (R0)