
Abstract
Diabetic Retinopathy is a major threat to visual loss in working age adults. Microanueurysm, hard exudates, and small vessel growth (abnormalities) around optical disk are the early signs of diabetic retinopathy. Machine learning with new insights providing better results in disease detection at an early stage with given images automatically. This paper proposes a model to study the tuning of hyper parameters in transfer learning to classify different stages of diabetic retinopathy with fundus images from standard data set by extracting the features. This proposed work outperforms with KNN classifier and Adam as optimizer when compared to SGD. Experimental results show that it is the best method with low data size by tuning the hyper parameters. Model validation with an average validation accuracy of 75.21% achieved with K- fold cross validation technique using KNN classifier. Similarly, analysis of the RoC shows an accuracy of 82%.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Nowadays, diabetic retinopathy is a major threat to visual loss in humans. Early detection of the disease may reduce the risk of vision loss. Image of eyes can be captured using fundus camera, and image analysis can be done with proper machine learning algorithms to detect abnormalities at an early stage. Main abnormalities include microanueurysm, hard exudates, and abnormal vessel growth around optic disk (neovascularisation) are the reasons for visual loss in diabetic patients [1, 2]. The stages of diabetic retinopathy classified as mild, it is proposed to use machine learning algorithms to detect abnormalities in fundus images in diabetic patients for better diagnosis with accuracy. The following image shows retinal image with diabetic mellitus captured from fundus camera and different signs of diabetic mellitus. Table 1 shows diabetic retinopathy disease severity level based on the type of abnormality [3–6, 20] (Fig. 1).

source: American Optometric Association
Retinal image with diabetic mellitus (image
2 Related Work
Machine learning algorithms use supervised and unsupervised techniques for automatic detection for image classification. Conventional methods for screening of diabetic retinopathy involve pre-processing the image, segmentation, feature extraction from the segmented image and these features used to classify the image [7]. Images of diabetic retinopathy are processed for contrast enhancement [24] by CLACHE technique, which makes segmentation easier by enhancing the regions with abnormalities like microanueurysm exudates.
In literature, for segmentation of vessel, a hybrid approach is proposed using cauchy filter with an accuracy of 85%. Feature extraction is a tricky task for medical images, Haralick proposed some predominant features, for image classification task, but each image has to be converted as grey image. For detection of exudates, texture features [25] extracted using region-based local binary pattern approach retinal image classification with an accuracy of 98.7% using ANN as classifier [21]. For color fundus image classification using multiple instance learning with SIFT and SVM classifier achieved an accuracy of 78%, where as it fails to discriminate microanueurysm and neovascularisation [15]. To overcome this, a new approach is developed with a modification to extract spectrally tuned features by defining a quantizer and achieved an accuracy of 87.6%. Conventional procedure is complex in nature and needs much attention while selecting the dominant features to classify the fundus image with diabetic retinopathy.
Convolutional networks with transfer learning gives prominent results in medical image analysis without specifying any features of the abnormality explicitly [8, 9]. CNN architecture for diabetic screening provided an accuracy of 75% with Kaggle data set [10] with 80,000 images for training and 5000 images for validation to classify 4 stages of abnormality with normal image. Recently, transfer learning-based approach became popular with pretrained models Alex Net and ImageNet.
3 Proposed Method
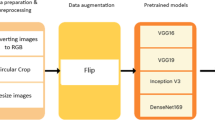
Diabetic retinopathy is causing major threat to visual loss in human beings if not diagnosed at an early stage. Fundus photography is a tool used to acquire image of an eye from diabetic patients. For automated disease detection at an early stage, machine learning tools are very flexible with limited complexity. This paper proposes transfer learning technique as a procedure with fine-tuning of hyper parameters for automated image classification to identify the given input image as normal or abnormal. Figure 2 shows the procedure used for image classification problem using transfer learning [10–13].

Procedure to classify given input image
In this proposed work, AlexNet is used as pretrained network and its architecture with different layers are used with modifications to classify the images by tuning the hyperparameters, Fig. 3 shows structure of AlexNet. The procedure for classification includes.

Structure of alex net
-
1.
Image resize to 227 × 227
-
2.
Data augmentation to make the model shift invariant
-
3.
Importing Alex Net to train the features
-
4.
Activate layers to get features and to transform in to feature vector
-
5.
Tuning of hyper parameters
-
6.
Applying KNN classifier for image classification
-
7.
Generating confusion matrix to observe the classifier efficiency (Precision, Recall & F Measure)
-
8.
Validate model using K-fold.
Input layer: Input layer is used to input images with data augmentation, and each color image is processed to have a fixed size of 227 × 227.
Convolutional Networks: Deep learning algorithms use convolutional networks to assign importance to learnable weights and biases from the input image to various tasks/objects. The pre-processing required in a CNN is much lower as compared to other classification algorithms. Convolutional networks are very efficient to capture the spatial and temporal dependencies in a given image by applying relevant filters, in other words ensemble of filters are applied to extract the features form the image for further processing. A stack of five convolution layers together used to generate extract various low level and high level features from the given image like edges, gradient orientation, shape of optical disk, nerves, and specific features related abnormality like blobs or exudates with bright red lesions. Features computed from the first layer are reused in different problem specific domain and these are general in nature for the all the images. Last layers of convolution network detect desired specific features like abnormal vessel growth and microanueurysm that related to abnormality and these were given to the classifier to perform classification task.
Rectified Linear Unit (ReLU): In deep learning network, commonly used activation function is ReLU. Activation functions help a model to consider interaction effects and nonlinear effects. Interaction effect deals with how a particular variable affects one variable while calculating the other one. Nonlinear effects means the effect of increasing the predicator by one is different at different values of that predicator. Each node in the network applies nonlinearity so ReLU RETURNS maximum value, i.e., F(x) = max {0, x}, i.e. if abnormality is in the image, it sends output as 1 else 0 [14].
Pooling Layer: The main objective of this layer is to reduce the spatial size of the convolved features by selecting the dominant features, which are position and rotational invariant. There are two types of pooling used with 2 × 2 matrix, one is average pooling and the other is maximum pooling. For example, X = {2, 5.3, 6} with average pooling X = 8 and with maximum pooling X = 6. In medical image analysis, each and every pixel is important so the pixel with maximum intensity is responsible for abnormality, so maximum pooling layer is effective in abnormal pixel identification. By using a more number of convolution and maximum pooling layers, it is observed that low-level details can be obtained from the given images with increased computational power.
Classifier: Fully connected layers usually compose classifier. The main goal of the classifier is to classify the image based on the detected features. A fully connected layer is a layer whose neurons have full connections to all activation in the previous layer. Based on these features, image classification can be achieved. The most generally used classifiers in the literature are KNN (K Nearest Neighbours) and support vector machine (SVM). In this paper, we used KNN as a classifier to achieve image classification and got good results with low data size.
Fully Convolutional Layer: Fully connected layer has three inputs (input signal, weight, bias) and one output. The best example for an end-to-end learnable network is convolutional network architecture with fully connected layers. Decisions mainly based on the learned representations from previous layers. Image classification task achieved with the help of extracted features from the convolutional networks along with SoftMax layer.
Output layer: Output layer is responsible for binary prediction of the result or multi-class prediction. SoftMax function which is a normalized exponential function, is used for predictions. It takes input as a vector of k real numbers and normalizes it into probability distribution with k probabilities. Results of this layer are used to generate a confusion matrix for calculating performance metrics of the model.
Hyperparameteres: Hyperparameteres influence the network model accuracy in machine learning. Setting these parameters is a trivial task. Mostly influenced parameters are data size, batch size; number of epochs, learning rate, and frequency are some examples for hyper parameters [16–19].
Performance Metrics: Performance metrics, like Accuracy, Recall, and Precision and F measure, are calculated using confusion matrix. Confusion matrix used to observe the types of errors in the model while classifying a multi-class problem. It summarizes the performance of a classification algorithm. The elements in this matrix are True Positive (TP), True Negative (TN), False Negative (FN), and False positive (FP). It gives the details of the model that how many times it has done the actual predictions and false predictions. The following figure shows the evaluation performance metrics from confusion matrix.
Accuracy = Total correct predictions/total predictions made * 100;
Recall = True Positive/ (True Positive + False Negative)
Precision = True Positive/(True Positive + False Positive)
F measure = 2* Recall * Precision/(Recall + Precision).
4 Implementation and Results
The standard database Diaret1TB used as data set with total 1148 images with normal images and abnormal images in this proposed model. Abnormal images consists data set with 4 stages of diabetic retinopathy. Baseline convolutional network model defined to the multiclass image classification problem using fundus images with diabetic retinopathy. Figure 4 shows diabetic retinopathy images with disease at different stages.

Stages of diabetic retinopathy
Group of convolutional layers used for front-end feature extraction. The first convolutional layer with 96 filters and 11 × 11 × 3 convolutions with 5 channels per element at stride [4], convolution 2 layer with 256 filters and 15 × 15 × 48 at stride [1] followed by maximum pooling layer were designed. These filters extracted basic features (shape of optic disk, edges, bright red lesions, and vessel structures of the fundus images from the given standard dataset. Here, the image classification is a multi-class (5 Stages) classification with four stages of diabetic retinopathy including normal image, to extract key features of microanueurysm, exudates, and small vessel growth around optical disk, which are main causes of abnormality, dense layers with classifier added to the network. These dense layers are fully connected and a SoftMax layer added before connecting to the output layer to predict probability distribution belonging to each of the five classes. The basic features from convolutional networks and fully connected layer were mapped to a feature matrix as 1 × 4096 vector and propagated to SoftMax layer to interpret probability distribution of 5 stages of fundus images. ReLU Activation function is used with all layers in this network for weight initialization. Adam optimizer is used with 0.9 momentum and at different learning rates (0, 0001, 0, 001, 0, 01) used for conservative configuration of the model. This model is evaluated using K-fold cross validation where the value of K is chosen as 5. Each test is 20% of training data set with a default size of 32 examples. Test set for each fold is used to evaluate the model both during each epoch of the training to create learning curves. Tables 2 and 3 give the details of network architecture with different layers and hyper parameters used to train the network.
The model performance through the metrics Accuracy, Recall, Precision, and F Measure were calculated using confusion matrix with different learning rates with a ratio of 80:20 as training and test data set. The experimental results are given in Table 2.
From the above results, Table 3 gives optimum parameters of proposed method to model the network for fundus image classification with existing method with comparison. The existing method not specified any hyper parameter to tune the model [23] with given data set. This paper achieved an overall accuracy of 75.21 with different hyper parameters and tested on various ratios of training and testing data set.
Figure 5 shows the image database used for training and testing of the network with proposed model. Figure 5 shows the tiled version of images used for training the network, and Fig. 6 shows test set images. Figures 7 and 8 are screen shots of MATLAB, which represents the graph of training progress of the network for different frequencies at different epochs with loss function. Figure 9 shows RoC of 82%, which is the plot between Recall (True Positive predictions) and Precision (True False Predictions).

Training set images

Test set images

Accuracy [22] and loss function curves of the model for 10 and 20 epochs with frequency 50

Accuracy and loss function curves of the model for 10 and 20 epochs with frequency 30

Analysis of RoC
5 Conclusion
With the advancements of deep learning networks and technologies, medical image analysis for automated detection of the disease at an early stage necessitates the novel methods with proper tuning of the network hyper parameters. The proposed method of transfer learning gives good results for image classification using computer-aided design for fundus images of diabetic retinopathy. In this paper, the accuracy of the model is observed using inductive transfer of features from existing model to proposed model to classify fundus images with diabetic retinopathy. With low data size i.e. total 148 images of standard data with 5 metric scales and a labeled data with 5 classes used. The accuracy is observed with different learning rates like 0.001, 0.0001, and 0.01 and at different epochs (10, 20). Tuning the hyper parameters is a trivial task to fit [1] the existing model to the proposed model using fundus images with diabetic retinopathy as input layer. This model experimented on different hyper parameters with variable training and testing data size ratio.(80:20, 70:30, 60:40, % and 50;50) It is observed that with equal size of training and test data sets network model gets biased and overall accuracy is varied between 65 and 82%. A trial and error method is applied to get the optimum values of hyper parameters to tune the model to observe maximum accuracy and positive prediction rate [3]. Among all these 80% training data and 20% test data with learning rate of 0.001 shows good average accuracy of 75% irrespective of number of epochs and validation frequency. Adam optimizer is used to optimize the network and not to stuck at local minima while training to obtain the most relevant features of microanueurysm, and improper vessel growth. It used stochastic gradient with momentum function to adapt weights dynamically to update the network layers, when compared to stochastic gradient descent (SGD). KNN is the classifier used in the proposed method to classify fundus images with abnormalities with less number of images at slow learning rate. Model validation accuracy of 75.21% is achieved with K-fold cross validation with a K value of 5. The results compared with existing method [19] with 1148 images, where there is no proper specification of hyper parameters used in the model. From the literature [21], it is observed that RoC of above 80% is good towards predictions in machine learning and the model is learning the data without overfitting. In Future, this paper tries to work on large data set of diabetic retinopathy images with cloud computing on Microsoft Azure platform to achieve of maximum accuracy.
References
Congdon N-G, Friedman D-S, Lietman T (2003) Important causes of visual impairment in the world today. JAMA 290(15):2057–2060
Kauppi T, Kalesnykiene V, Kamarainen JK, Lensu L, Sorri I, Uusitalo H, Klviinen H, Pietil J (2006) DIARETDB0: evaluation database and methodology for diabetic retinopathy algorithms. Machine vision and pattern recognition research group. Lappeenranta University of Technology , Finland
Niemeijer M, Van Ginneken B et al (2010) Retinopathy on line challenge: automatic detection of Microneurysms in digital color fundus photographs in IEEE transaction on medical imaging
Mookiah MRK, U. Rajendra R, Chua CK, Lim CM, Ng EYK, Laude A (2013) Computer-aided diagnosis of diabetic retinopathy: areview. Comput Biol Med 43(12):2136–2155
Goh JKH, Cheung CY, Sim SS, Tan PK, Tan GSW, Wong TY (2016) Retinal imaging techniques for diabetic retinopathy screening. J Diabetes Sci Technol 10(2):282–294
Antal B, Hajdu A (2012) An Ensemble-Based System for Microaneurysm Detection and Diabetic Retinopathy Grading. IEEE Transactions on Biomedical Engineering 59 (6):1720–1726
Roychowdhury S, Koozekanani SD, Parhi KK (2013) DREAM: diabetic retinopathy analysis using machine learning. IEEE J Biomed Health Inf 18(5):1717–1728
He Z, Gongy B (2018) Optimize deep conventional neural network with ternarized weights and high accuracy, arXiv 1807.07942 v1-20
Kori A, Chennamsetty S-S, Alex V (2018) Ensemble of convolutional neural networks for automatic grading of diabetic retinopathy and macular edema. In: arXiv preprint arXiv:1809.04228
Yosinski J, Clune J, Bengio Y, and Lipson H (2014) How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems 27 (NIPS ’14), NIPS Foundation
Rastegari M, Ordonez V at el (2016) XorNet: imagenet classification using binary convolutional networks, European Conference on computer 525–542
Pan SJ, Yang Q (2009) A survey on transfer learning. IEEE Trans Knowl Data Eng 22(10):1345–1359
Tang W, Hua G, Wang L (2017) How to train a compact neural network with high accuracy? In AAAI 2625–2631
Hanin B, Sellke M (2018) Approximating continuous functions by RELU nets of minimal width in Statistics of Machine learming vol 2
Venkatan R et al (2016) Classification of diabetic retinopathy images using multi class multiple instance learningon color corrolegram features., IEEE Proceedings
Wu X, Chen Y et al ( 2019) Hyperperameter optimization for machine learning model based on baysian optimisation in Journal of Electronic science & Technology
Ilievski I et al (2017) Efficient hyperparameter optimization of deep learning algorithms using deterministic RBF surrogates, 31st AAAI conference on Artificial Intelligence
Jin Q, Meng Z et al (2015) DUNet: a deformable network for retinal vessel segmentation, Journal of l atex class files 14:8
Mohammadian S, Karsaz A, Roshan YM (2017) Comparative study of fine-tuning of pre-trained convolutional neural networks for diabetic retinopathy screening. In: 24th national and 2nd international Iranian conference on biomedical engineering (ICBME) (pp 1–6) IEEE
Lavanya R, Mohanaiah P, Kishore PVV (2018) A hybrid approach to visual vessel extraction with segmentation. Mater Today: Proceed 5(1):287–293
Imran M et al (2016) Detection and classification of retinal fundus image exudates using region based LBP approach in International Conference on Control Decision & Information technology
Devi VV, Lokku G, Natarajan A (2012) Fixed width booth multiplier based on peb circuit. Int J Art Intell Appl 3(2):133
Kumar DM, Kumar LG, Kannaiah K (2020) A conceal fragment visible image broadcast through montage images with revocable colour alterations. In: Hitendra Sarma T, Sankar V, Shaik R (eds) Emerging trends in electrical, communications, and information technologies. Lecture notes in electrical engineering, vol 569. Springer, Singapore. https://doi.org/10.1007/978-981-13-8942-9_57
Swathi P, Jithendra I, Kumar LG Global image contrast enhancement algorithm using histogram-modification framework
Mohanaiah P, Sathyanarayana P, GuruKumar L (2013) Image texture extraction using gray level co-occurrence matrix (GLCM). Int J Sci Res Publications 3(5)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Rajini, G.K., Lavanya, R. (2021). Diabetic Retinopathy Image Classification Using Transfer Learning. In: Komanapalli, V.L.N., Sivakumaran, N., Hampannavar, S. (eds) Advances in Automation, Signal Processing, Instrumentation, and Control. i-CASIC 2020. Lecture Notes in Electrical Engineering, vol 700. Springer, Singapore. https://doi.org/10.1007/978-981-15-8221-9_234
Download citation
DOI: https://doi.org/10.1007/978-981-15-8221-9_234
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-8220-2
Online ISBN: 978-981-15-8221-9
eBook Packages: EngineeringEngineering (R0)