
Abstract
In this paper, we propose a new lifetime distribution based on the generalized DUS transformation by using Weibull distribution as the baseline distribution. This new distribution exhibits various behaviour of hazard function like increasing, decreasing and inverse bathtub. Here we try to study the characteristics of the new distribution and also analyse a real data set to illustrate the flexibility of the model.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
For analysing the lifetime data, there are number of models available in the literature. Earlier, only the constant, increasing and decreasing hazard rates received serious consideration. But, in real-life problem, a situation does arise when the hazard rate is expected to be non-monotone, for example, human life. To model such problems, several non-monotone hazard rate distributions were introduced. Mudholkar and Srivastava [7], Xie and Lai [10], Gupta et al. [4] and Xie et al. [11] are notable research works related to the non-monotone hazard rate data.
There is a growing interest in the study of inverse bathtub hazard rates nowadays. A study of head and neck cancer data, [2] showed inverse bathtub hazard rates, in which the hazard rate initially increased, attained a maximum, and then decreased before it finally stabilized due to therapy. Log-normal, log-logistic, Burr Type XII, Burr Type III, log-Burr Type XII and the inverse Weibull distributions are some of the statistical distributions that show inverse bathtub hazard rates.
In the present study, we used a transformation called DUS transformation proposed by Kumar et al. [5]. If F(x) is the cdf of some baseline distribution, then the cdf G(x) of new distribution is given by,
Maurya et al. [6] introduced a new class of distribution by using the generalization of DUS transformation. The cdf of Generalized DUS (GDUS) transformation is
where F(x) be the cdf of some baseline distribution. In both these papers, they used exponential distribution as the baseline distribution.
Our main objective in this paper is to introduce a new class of distribution which includes all types of failure rates for suitable choice of parameter. By using GDUS transformation, the obtained distribution is expected to possess both monotone and non-monotone failure rates depending on the values of the parameter. The Weibull distribution has wide application in reliability and survival analysis. Depending on the shape parameter, Weibull models show different types of observed failures of components. Therefore here we consider Weibull distribution with parameters λ and k as the baseline distribution in GDUS transformation. The cdf and pdf of Weibull distribution are, respectively, \(G(x)=1-e^{-(\frac {x}{\lambda })^{k}}\) and \(g(x)=(\frac {k}{\lambda })(\frac {x}{\lambda })^{k-1}e^{-(\frac {x}{\lambda })^{k}},\) x > 0, λ, k > 0.
Using GDUS and Weibull distribution, the cdf and pdf of the new distribution, i.e., GDUS Weibull Distribution (GDUSWD) can be obtained as
The hazard function of the distribution is,
The paper deals with the selected topics as follows: In Sect. 2, we plot the pdf and hazard rates for different values of parameters of the GDUSWD. Various statistical characteristics of proposed distribution like moments, quantile function order statistic and Reńyi entropy are included in Sect. 3. The parametric estimation for the new distribution is discussed in Sect. 4. In Sect. 5 we illustrate the flexibility of the proposed model for a real data set by using AIC (Akaike information criterion) and BIC (Bayesian information criterion), and finally recapitulate the conclusions in Sect. 6.
2 Shape of the pdf and Hazard Function
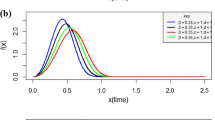
The distribution function may seem complicated, so we plot it to gain a better understanding of the nature of the distribution. Using Eq. (2), the plots of pdf for various values of the parameters α, λ and k are given in Fig. 1.

The probability density plot of GDUSWD. (Red) α = 0.5, k = 1.5, λ = 1.5; (blue) α = 1.5, k = 2, λ = 1.5; (green) α = 0.8, k = 2, λ = 1.5
The term \(\eta (x)=\frac {-f'(x)}{f(x)}\), where f(x) is the density function of the distribution and f′(x) is the first derivative of f(x) with respect to x, is defined by Glaser [3] for the study of the shapes of the hazard rate. He stated the following theorem:
Theorem 1
-
1.
If η ′(x) > 0 for all x > 0, then the distribution has increasing failure rate (IFR).
-
2.
If η ′(x) < 0 for all x > 0, then the distribution has decreasing failure rate (DFR).
-
3.
Suppose there exists x 0 > 0 such that η ′(x) > 0 for all x ∈ (0, x 0), η ′(x 0) = 0, and η ′(x) < 0 for all x > x 0 and 𝜖 =limx→0f(x) exists. Then if
-
(i)
𝜖 = 0, the distribution has inverse bathtub failure rate.
-
(ii)
𝜖 = ∞, the distribution has DFR.
-
(i)
In GDUSWD,
and
The obtained expression of η ′(x) is too complicated, so we have used the software MATHEMATICA for checking the conditions mentioned in Theorem 1. Here we have observed that
-
When α ≤ 0.5, we have η ′(x) < 0 for all x > 0, hence the distribution has DFR
-
When α ≥ 1, we have η ′(x) > 0 for all x > 0, hence the distribution has IFR
-
When 0.5 < α < 1, there exists a x 0 such that η ′(x) > 0 when x ∈ (0, x 0), η ′(x 0) = 0 and η ′(x) < 0 for all x > x 0, where x 0 depends on the value of α, λ and k.
From Eq. (2), we can easily verify that limx→0f(x) = 0, hence the distribution has inverse bathtub shaped failure rate. Figure 2 shows the different shapes of hazard rates.

The hazard rate plots of GDUSWD. (a) (Blue) α = 0.3, k = 2, λ = 0.1, (red) α = 0.4, k = 2, λ = 0.3. (b) (Blue) α = 0.8, k = 2, λ = 4, (red) α = 0.6, k = 2, λ = 3. (c) (Green) α = 1.5, k = 2, λ = 1.5, (blue) α = 2, k = 2, λ = 1.5
3 Some Analytical Characteristics
Different statistical characteristics like moments, quantile function, order statistic and Reńyi entropy of our proposed distribution are discussed below.
3.1 Moments
The moments are used to understand the various characteristics of the proposed distribution. The rth raw moment of the GDUSWD is
Expanding the exponential term \(e^{x}=\sum _{i=0}^{\infty }\frac {x^{i}}{i!}\), we get
Here the summation is absolutely convergent, we can interchange the summation and integral.
Using the expansion of series, \((1-y)^{b}=\sum _{i=0}^{\infty }(-1)^{i} {b \choose i}y^{i}\) and simplifying
This expression of rth raw moment gives variance and other higher order central moments.
3.2 Quantile Function
The pth quantile function Q(p) of our proposed distribution is obtained from the equation,
3.3 Order Statistic
Order statistics are sample values placed in ascending order. The study of order statistics deals with the applications of these ordered values and their functions. Let X 1, X 2, …, X n be a random sample of size n from the GDUSWD distribution and X (1), X (2), …, X (n) denote the corresponding order statistics. The pdf and cdf of the rth order statistics f r(x) and F r(x) are given by
and
The pdf f r(x) and cdf F r(x) of rth order statistic of our proposed distribution are obtained by using Eqs. (1) and (2) as,
and
The pdf of smallest and largest order statistics X (1) and X (n) is obtained by putting r = 1 and r = n, respectively, in Eq. (6). The cdf of X (1) and X (n) is obtained by putting r = 1 and r = n, respectively, in Eq. (7).
3.4 Entropy
Entropy is interpreted as the degree of disorder or randomness in the system. Reńyi entropy [8] is one of the well-known entropy measures. If random variable X has the pdf f(x), then the Reńyi entropy is defined as,
where γ > 0 and γ ≠ 1. From Eq. (2), we get,
after some algebra, which is used in Sect. 3.1
With this, Eq. (7) becomes,
4 Estimation
Maximizing the logarithm of likelihood function is the most common method for finding the estimates—called MLE (Maximum Likelihood Estimates)—of the parameters involved in the given distribution. In this section, we use this method for obtaining the maximum likelihood estimates of the parameters α, λ and k of the proposed distribution. The log-likelihood function is,
Differentiating this function with respect to the parameters we get,
and
Equating these partial derivatives to zero yields three non-linear equations, and their solutions provide the maximum likelihood estimate of the parameters α, λ and k. Newton–Raphson method can be used to solve these equations with the help of the available statistical packages.
5 Application
In this section, we have checked the flexibility of the proposed distribution and compared it with some well-known distributions namely, Inv. Lindley, Inv. Exponential, Gn. Inv. Lindley, Inv. Weibull, Inv. Gamma, Inv. Gaussian and Gn. Inv. Exponential, see Vikas et al. [9]. For the purpose of comparison, we have considered a set of real data of flood levels [1],
-
0.654, 0.613, 0.315, 0.449, 0.297, 0.402, 0.379, 0.423, 0.379, 0.324,
-
0.296, 0.740, 0.418, 0.412, 0.494, 0.416, 0.338, 0.392, 0.484, 0.265.
Many authors have used this data for checking the flexibility of their proposed distributions. We have used AIC (Akaike information criterion) and BIC (Bayesian information criterion) for comparing our model with other models. AIC and BIC are defined as,
and
where n is the sample size, k is the number of parameters and L is the maximum value of the likelihood function for the considered distribution. A minimum value of AIC and BIC is a sign of better fit of distributions.
From Table 1, it can be seen that the proposed distribution gives the lowest AIC and BIC values. So we can conclude that GDUSWD provides the best fit for the data set compared to the other distributions given in this study.
6 Conclusion
In the present study, we have introduced a new lifetime distribution exhibiting increasing, decreasing and inverse bathtub failure rates. We then derived its moments, quantile function, order statistic and Reńyi entropy. We have considered a real dataset and compared our proposed distribution with some other well-known distributions. It is seen that among the distributions considered, the one proposed here fits best with the data. Thus, we can say that the GDUSWD is more flexible compared to the distributions mentioned in this study.
References
Dumonceaux, R., Antle, C.: Discrimination between the lognormal and the Weibull distributions. Technometrics 15, 923–926 (1973)
Efron, B.: Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 83, 414–425 (1988)
Glaser, R.E.: Bathtub and related failure rate characterizations. J. Am. Stat. Assoc. 75, 667–672 (1980)
Gupta, R.C., Gupta, P.L., Gupta, R.D.: Modeling failure time data by Lehmann alternatives. Commun. Stat. Theory Methods 27, 887–904 (1998)
Kumar, D., Singh, U., Singh, S.K.: A method of proposing new distribution and its application to bladder cancer patient data. J. Stat. Appl. Probab. Lett. 2, 235–245 (2015)
Maurya, S.K., Kaushik, A., Singh, S.K., Singh, U.: A new class of distribution having decreasing, increasing, and bathtub-shaped failure rate. Commun. Stat. Theory Methods 46(20), 10359–10372 (2017)
Mudholkar, G., Srivastava, D.: Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 42, 299–302 (1993)
Renyi, A.: On measures of entropy and information. In: Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, vol. 1, pp. 547–561. University of California Press, Berkeley (1961)
Sharma, V.K., Singh, S.K., Singh, U., Merovci, F.: The generalized inverse Lindley distribution: a new inverse statistical model for the study of upside-down bathtub data. Commun. Stat. Theory Methods 45(19), 5709–5729 (2016)
Xie, M., Lai, C.: Reliability analysis using an additive Weibull model with bathtub shaped failure rate function. Reliab. Eng. Syst. Saf. 52, 87–93 (1996)
Xie, M., Goh, T., Tang, Y.: A modified Weibull extension with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 76, 279–285 (2002)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 The Editor(s) (if applicable) and The Author(s), under exclusive licence to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Kavya, P., Manoharan, M. (2020). On a Generalized Lifetime Model Using DUS Transformation. In: Joshua, V., Varadhan, S., Vishnevsky, V. (eds) Applied Probability and Stochastic Processes. Infosys Science Foundation Series(). Springer, Singapore. https://doi.org/10.1007/978-981-15-5951-8_17
Download citation
DOI: https://doi.org/10.1007/978-981-15-5951-8_17
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-5950-1
Online ISBN: 978-981-15-5951-8
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)