
Abstract
Hyperspectral images (HSIs) have far more spectral bands than conventional RGB images. The abundant spectral information provides very useful clues for the followup applications, such as classification and anomaly detection. How to extract discriminant features from HSIs is very important. In this work, we propose a novel spatial-spectral features extraction method for HSI classification by Multi-Scale Depthwise Separable Convolutional Neural Network (MDSCNN). This new model consists of a multi-scale atrous convolution module and two bottleneck residual units, which greatly increase the width and depth of the network. In addition, we use depthwise separable convolution instead of traditional 2D or 3D convolution to extract spatial and spectral features. Furthermore, considering classification accuracy can benifit from multi-scale information, we introduce atrous convolution with different dilation rates parallelly to extract more discriminant features of HSIs for classification. Experiments on three standard datasets show that the proposed MDSCNN has got the state-of-the-art accuracy among all compared methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Recently, hyperspectral imaging technology has attracted widespread attention in the remote sensing society. The hyperspectral imager can capture accurate spectral response characteristics and spatial details of surface materials, which makes it possible to identify and classify the landcovers. HSI classification aims to assign a unique category to each pixel in the image, enabling automatic identification of categories and serving for following applications. However, due to the limit of labeled samples, the existence of mixed pixels, and the Houghes phenomenon, HSI classification is a very challenge problem.
Based on traditional machine learning methods, many HSI classification approaches such as support vector machine (SVM) [1], multiple logistic regression [2], decision trees [3], etc. are proposed for pixel-level classification of HSI. However, HSIs usually provide hundreds of spectral bands, which contain a large amount of redundant information. Therefore, using raw spectral information directly not only results in high computational cost, but also reduces classification performance. Consequently, there are some methods that focus on mitigating the redundancy of HSIs with principal component analysis (PCA) [4] or linear discriminant analysis (LDA) [5]. Furthermore, spatial information has been reported to be very helpful in improving the representation of HSI data [6]. Thus more and more classification frameworks based on spatial-spectral features have been presented [7, 8]. Although these spatial-spectral classification methods have achieved some progress, they all need to perform feature extraction engineering through human prior knowledge, which limits these methods in different scenarios.
Deep learning has become an important tool for big data analysis, and has made great breakthroughs in many computer vision tasks, such as image classification, object detection and natural language processing. Recently, it has been introduced into the HSI classification as a powerful feature extraction tool and shows great performance. Compared with the traditional artificial feature extraction methods, deep convolutional neural network can extract rich features from the original data through a series of layers. Since the learning process is completely automatic, deep learning is more suitable for dealing with complex scenes. Chen et al. [9] first applied the Stacked Autoencoder (SAE) to the HSI classification which is composed of multiple sparse autoencoders. Mughees et al. [10] proposed a Spectral-Adaptive Segmentation DBN (SAS-DBS) for HSI classification that exploits the spatial-spectral features by segmenting the original spectral bands into small sets and processing each group separately by local DBNs. However, deep neural networks such as SAE are based on the fully connected layer. Although the above-mentioned deep neural network models can effectively extract deep features in HSIs, they may ignore the spatial information of HSIs. Unlike SAE, Convolutional Neural Networks (CNN) can directly extract spatial and spectral features of HSIs while keeping the input shape. For this reason, most of the current HSI classification networks with spatial-spectral features are based on CNN structure. They can be divided into two main categories. The first is to extract spatial and spectral features separately and then combine them and feed to the classifier [11]. Another strategy is to extract the spatial-spectral joint features of HSIs simultaneously by 3D convolution [12, 13]. Although these methods can effectively extract the spatial spectral information of HSIs, they all ignore the multi-scale characteristics. Because of the complexity and diversity of HSI scenery, it is often difficult to extract spatial information from a single scale.
In this work, we propose a Multi-Scale Depthwise Separable Convolutional Neural Network (MDSCNN) for HSI classification which can effectively exploit spatial-spectral features and achieve competitive HSI classification performance. This new model consists of a multi-scale atrous convolution module and two bottleneck residual units, which greatly increase the width and depth of the network. In addition, we use depthwise separable convolution instead of traditional 2D or 3D convolution, which leads to extract spectral features poorly or has high computational complexity. In contrast, the depthwise separable convolution can not only extract spatial-spectral features separately, but also greatly reduce the amount of training parameters. Furthermore, considering classification accuracy can benifit from multi-scale information, we introduce atrous convolution with different dilation rates parallelly to extract more discriminant features of HSIs. Experiments on three standard datasets show that the proposed MDSCNN has got the state-of-the-art accuracy among all compared methods.
The remainder of this paper is organized as follows: In Sect. 2 several related techniques are described. Section 2 introduces the proposed MDSCNN model. The experiments and results analysis are shown in Sect. 3, A conclusion is made in Sect. 4.

Overview of the proposed Multi-Scale Depthwise Separable CNN (MDSCNN) model.
2 Method
In this section, we have discussed the overall architecture of the proposed MDSCNN firstly. Then we provide a detailed explanation about each module.
2.1 Overall Architecture
We have constructed a wide and deep network with a specially developed multi-scale atrous convolution module and two depthwise separable bottleneck residual units for HSI classification. As shown in Fig. 1, the proposed MDSCNN is a fully convolutional network (FCN) [19] without any fully connected layers, so that it can handle any input patches with arbitrary size and produce the same size output. Let’s denote \(I_H\) and \(I_L\) as the input HSI patch and predicted labels of MDSCNN.
The input to the spectral pixel based methods usually is a pixel vector \(x^{1\times 1\times M}\), where M is the number of spectral bands. In order to simultaneously exploit the spatial and spectral features, it is necessary to introduce a three-dimensional approach to incorporate the contextual information. In this method, we feed the network with a \(d\times d\) patch P centered on x, where d is the width and height of the patch. In this way, the original spatial and spectral features can be considered simultaneously. Especially, the model is designed to predict the label of center pixel, whose position index is \([d/2 + 1, d/2 + 1, M] \). Meanwhile, we need to select the value of d carefully. It will result in lacking spatial information if d is too small. On the other hand, when we set d too large, it may introduce some pixels that are not belong to the same class. Furthermore, a multi-scale atrous convolution module is introduced to extract rich spatial and spectral features. It extracts multi-scale features \(F_M\) from \(I_H\)
where \(H_{MAC}(\cdot )\) denotes multi-scale atrous convolution operation. \(F_M\) is a joint maps with multi-scale features, then \(F_M\) is concatenated together via one \(1\times 1 \) Conv layer
where \(W_{CAT}(\cdot )\) and \(F_{CAT}\) denote the weight set to the Conv layer and joint features respectively. The following are backbone of the network, two specially designed Depthwise Separable bottleneck Residual (DSR) units, implemented with depthwise separable convolution
where \(H_{DSR}(\cdot )\) denotes our residual unit, \(F_{DF}\) is the obtained deep discriminative feature. The end of the model are three convolutional layers for classification, and we insert the dropout layer (p = 0.5) during training to prevent overfitting
where \(H_{CLS}(\cdot )\) and \(I_{L}\) denate classification module and label map predicted by MDSCNN.

The developed multi-scale atrous convolution module.
In this paper, we select the cross-entropy as the loss function to train the network, which can be formulated as:
where T denotes the total number of training samples, \(y_i\) is the ground truth of \(x_i\), and \(h(\cdot )\) denotes the softmax function which is computed as:
where \(z_i\) is the features learned from sample \(x_i\), and C is the number of label categories.
We have summarized the proposed MDSCNN in Table 1, which includes the number of channels, kernel size, padding value and parameters for each convolution or pooling layer of each module.

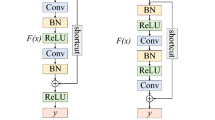
Different residual unit architectures. (Left) Traditional residual units, (Middle) Bottleneck residual units, (Right) The developed Depthwise Separable bottleneck Residual (DSR) units.
2.2 Multi-scale Feature Extraction with Atrous Convolution
It has been proved that classification can benifit from abundant contextual features [20]. Inspired by the Atrous Spatial Pyramid Pooling (ASPP) module [15] which is commonly used in semantic segmentation, we design a multi-scale atrous convolution module based on depthwise separable convolution. As shown in Fig. 2, it consists of four filters: \(1\times 1 \), \(3 \times 3\) \((r=1)\), \( 3\times 3\) \((r=2)\), \(3\times 3\) \((r=3)\), and an ImagePooling branch. Atrous convolution can enlarge the receptive field of the filter while maintaining the amount of parameters. These convolutions are extracted in parallel with different dilation rates, and then the generated feature maps are concatenated together. Therefore, we pad the input patches to ensure the shape of generated feature maps are same. Early studies have shown that a \(3 \times 3\) atrous convolution with an extremely large rate will degenerate into a simple \(1 \times 1\) convolution. In this way, it will not be able to capture long range information due to image boundary effects [15]. Therefore, considering the spatial size d of input patch is generally between 9–25, we set the maximum dilation rate to 3. In addition, The pooling filter preserves the image-level features of the original HSIs and enriches the diversity of features.
2.3 BottleNeck Residual Block with Depthwise Separable Convolution
Deep convolutional neural networks often appear degradation phenomenon due to inadequate training, therefore, He et al. [21] constructed an identity mapping to ease the training process. The basic idea is that if E is a perfect network with best performance, the T is a deeper network with some redundant layers, so the goal is to make redundant layer become an identical transformation. That is to say, T’s performance is the same as E. Therefore, the network needs to learn a residual \(F(x) = H(x) - x\), where x is original feature, H(x) denotes the features learned from x. H(x) will be equivalent with x if the network learns nothing, i.e. \(F(x) = 0\). Since fitting the residual F(x) is easier than fitting the original H(x), residual network can effectively avoid degradation of network. The design of the residual units becomes a point worth exploring, as we can see, there are three different residual units showed in Fig. 3. Basic residual unit (Left) contains two convolutional layers. Bottleneck residual unit (Middle) [22] is more economical than the conventional residual block, and its input and output feature maps dimension is first reduced and then restored, which reduces the calculation amount of the middle layer and allows a faster execution.

Classification maps for IP dataset. (a) Simulated RGB composition of the scene. (b) Ground-Truth classification map. Classification maps obtained by (c) MLP, (d) SVM, (e) 2D-CNN, (f) 3D-CNN, (g) HybridSN, (h) MDSCNN
As we know, these traditional residual units mainly focus on the spatial features of RGB images, the spectral features are not well extracted. Inspired by bottleneck, here we have specially designed a DSR unit for HSI classification as shown in Fig. 3 (Right). It mainly consists of three convolutional layers, which extract spatial features using depthwise convolution firstly, and then convolute point by point to extract spectral features. After the first convolutional layer, the feature map dimension is reduced (from the number of channels point of view). A nonlinear activation function is introduced between the first and second convolutional layers
where \( W_{pw}\) and \(W_{dw}\) denate the weights of pointwise convolution and depthwise convolution respectively. \(\sigma (\cdot )\) denotes the ReLu activation function. \(F_{MID}\) is the feature map after the second Conv layer in DSR. Since the depthwise convolution’s output is shallow, in order to retain as much information as possible, a linear output is put between the second and third convolutional layers without adding any nonlinear activation function. Thus a output \(F_{DF}\) is obtained via the shortcut connection:
where \(+\) is an elementwise addition that does not change the size of the feature map.
The experimental results show that adding two depthwise separable convolutional units improves the classification accuracy while using limited training samples.

Classification maps for UP dataset. (a) Simulated RGB composition of the scene. (b) Ground-Truth classification map. Classification maps obtained by (c) MLP, (d) SVM, (e) 2D-CNN, (f) 3D-CNN, (g) HybridSN, (h) MDSCNN
3 Experiments
3.1 Experimental Datasets
We have evaluated our model on three well-know HSI datasets, which are widely used for HSI classification, Indian Pines (IP), University of Pavia (UP) and Salinas Valley (SV).
IP: This scene was gathered by AVIRIS sensor in North-western Indiana, which consists of \(145\times 145\) pixels and 224 spectral reflectance bands in the wavelength range from 400 nm to 2500 nm. We have also reserved the number of bands to 200 by removing 24 damaged bands.

Classification maps for UP dataset. (a) Simulated RGB composition of the scene. (b) Ground-Truth classification map. Classification maps obtained by (c) MLP, (d) SVM, (e) 2D-CNN, (f) 3D-CNN, (g) HybridSN, (h) MDSCNN
UP: This dataset captured the urban area around the University of Pavia, Italy. The spatial resolution of the image is 1.3 m per pixel, the spectral coverage ranges from 0.43 m to 0.86 m. After 12 bands is removed due to noise, there are 103 bands left. The image consists of \(610 \times 340\) pixels, but it contains many background pixels.
SV: The SV dataset was captured by an onboard visible/infrared imaging spectrometer over Salinas Valley,California. The image has \(512 \times 217\) pixels with a spatial resolution of 3.7 m per pixel. The image originally contained 224 bands, but the remaining 204 bands were usually used for experiments after removing 20 water absorption bands.
In this paper, we implement the proposed method with Pytorch framework. Before training, we have enhanced the data by randomly flipping and adding noise. We use the Adam optimizer to train the network with a batch size of 64 and initially set a base learning rate as 0.001 then reduce it with poly (0.9).
3.2 Experimental Results
We compare the proposed MDSCNN with several classical and state-of-the-art HSI classification methods. (1) SVM; (2) MLP; (3) 2D-CNN [23]; (4) 3D-CNN [12]; (5) HybidSN [13]. SVM and MLP both are spectral-based methods. 2D-CNN is based on spatial features. 3D-CNN utilizes spatial-spectral features of HSIs with 3D convolution, which consists of two 3D convolutional layers and one fully connected layer. The HybridSN firstly get a low-dimensional data with PCA as input, and it contains three 3D convolutional layers, one 2D convolutional layer, and three fully connected layers in the end of model. We evaluate all of these methods on three standard datasets described above. In order to evaluate the proposed MDSCNN and demonstrate the effectiveness of the multi-scale strategy, we have conducted the following three experiments.
-
(1)
In our first experiment: the first step is to randomly divide the original IP,UP and SV dataset respectively into two subsets: the training set and testing set, whose sample numbers are shown in the first column of Tables 2, 3 and 4. We train all methods mentioned above with some optimal parameters. In addition, for our model, the input patch size is set to \(15 \times 15 \times M\).
-
(2)
In our second experiment: intuitively, different spatial size of patch has significant effect on the classification performance of model. We takes three different sizes of patch as input: \(9 \times 9, 15 \times 15, 21 \times 21\) and \(15\%\) of the available training data for experiment.
-
(3)
In our third experiment: to verify the effectiveness of the multi-scale atrous convolution module used to jointly extract the mutli-scale spatial-spectral features, we compare the proposed MDSCNN to the network without the multi-scale module. To verify the effectiveness of the DSR units, we also compare the performance of the proposed MDSCNN to a similar network with the DSR unit replaced with traditional two convolutional layers residual unit.
To evaluate the performance of different methods, three objective metrics: overall accuracy (OA), average accuracy (AA), and the Kappa coefficient, are adopted in these experiments.
Experiment 1: Tables 2, 3 and 4 show the quantitative results, moreover, the best result is highlighted in bold font. As shown, the results of traditional spectral-based pixel-level classification methods are not satisfactory, like SVM and MLP, which are far worse than spatial-spectral based methods like 2D-CNN, 3D-CNN, HybridSN. The proposed MDSCNN achieves the best classification accuracy on each dataset. Furthermore, the proposed MDSCNN has improved the OA value 0.5% at least compared to the suboptimal method on all testing sets, and there are surprising improvements in AA and Kappa. In addition to the qualitative results, the Figs. 4, 5 and 6 show three visual classification maps of the different methods on three datasets respectively. It can be observed that the traditional single-pixel-based methods have a lot of noise due to the lack of spatial information. Meanwhile, the classification maps obtained by the spatial-spectral based methods are smoother, and the most of the ewrong classified pixels exist around the boundaries of some categories. Taking all these observations into account, it is possible to state that the MDSCNN provides a more accurate and robust classification result than all of the other tested methods.
Experiment 2: Table 5 shows the classification results of the proposed MDSCNN when using different spatial size patches as input. The OA, AA, and Kappa values all increase firstly and then decrease on the three datasets. The highest score was reached as the spatial size is set to \(15 \times 15\). It is not difficult to understand that increasing the spatial size of the patch will introduce a certain amount of spatial information at first. But as the spatial size continues to increase, a lot of noise or pixels with different classes will be also introduced.
Experiment 3: As shown in Table 6, the multi-scale atrous convolution module outperforms the network without it (by 4.55% for the UP dataset, 9.68% for the IP dataset in OA classification performance). Beyond that, our developed DRS units achieve better performance than traditional residual units.
4 Conclusion
In this paper, a novel multi-scale separable convolutional network for HSI classification is proposed, the model leverages a multi-scale atrous convolutional module to extract spatial-spectral features from a HSI patch. In addition, a specially designed depthwise separable bottleneck residual unit is applyed to increase the depth of the network and improve classification performance. The proposed MDSCNN is deep while it doesn’t introduce large quantities of training parameters because of the depthwise separable convolution. The final experimental results show that our method achieves outstanding classification performance with a relative small number of training samples. Although multi-scale features fusion has been adopted in our MDSCNN, the features at different stages of the network is not considerated. In the future, we will continue to explore some new multi-stage information fusion ways for HSI classification.
References
Mercier, G., Lennon, M.: Support vector machines for hyperspectral image classification with spectral-based kernels. In: 2003 IEEE International Geoscience and Remote Sensing Symposium. Proceedings (IEEE Cat. No. 03CH37477), IGARSS 2003, vol. 1, pp. 288–290, July 2003
Li, J., Bioucas-Dias, J.M., Plaza, A.: Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 48(11), 4085–4098 (2010)
Li, S., Zhang, B., Gao, L., Zhang, L.: Classification of coastal zone based on decision tree and PPI. In: 2009 IEEE International Geoscience and Remote Sensing Symposium, vol. 4, pp. IV-188–IV-191, July 2009
Chen, H., Chen, C.H.: Hyperspectral image data unsupervised classification using Gauss-Markov random fields and PCA principle. In: IEEE International Geoscience and Remote Sensing Symposium, vol. 3, pp. 1431–1433, June 2002
Bandos, T.V., Bruzzone, L., Camps-Valls, G.: Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans. Geosci. Remote Sens. 47(3), 862–873 (2009)
Demir, B., Ertürk, S.: Improving SVM classification accuracy using a hierarchical approach for hyperspectral images. In: 2009 16th IEEE International Conference on Image Processing (ICIP), pp. 2849–2852, November 2009
Fauvel, M., Tarabalka, Y., Benediktsson, J.A., Chanussot, J., Tilton, J.C.: Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 101(3), 652–675 (2013)
Wang, J., Jiao, L., Wang, S., Hou, B., Liu, F.: Adaptive nonlocal spatial-spectral kernel for hyperspectral imagery classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 9(9), 4086–4101 (2016)
Chen, Y., Lin, Z., Zhao, X., Wang, G., Gu, Y.: Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 7(6), 2094–2107 (2014)
Mughees, A., Tao, L.: Multiple deep-belief-network-based spectral-spatial classification of hyperspectral images. Tsinghua Sci. Technol. 24(2), 183–194 (2019)
Yang, G., Gewali, U.B., Ientilucci, E., Gartley, M., Monteiro, S.T.: Dual-channel DenseNet for hyperspectral image classification. In: 2018 IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2018, pp. 2595–2598, July 2018
Hamida, A.B., Benoit, A., Lambert, P., Amar, C.B.: 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 56(8), 4420–4434 (2018)
Roy, S.K., Krishna, G., Dubey, S.R., Chaudhuri, B.B.: HybridSN: exploring 3D–2D CNN feature hierarchy for hyperspectral image classification. ArXiv, abs/1902.06701 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. CoRR, abs/1406.4729 (2014)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. CoRR, abs/1606.00915 (2016)
LeCun, Y., et al.: Backpropagation applied to handwritten zip code recognition. Neural Comput. 1(4), 541–551 (1989)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems, NIPS 2012, vol. 1, pp. 1097–1105. Curran Associates Inc., USA (2012)
Szegedy, C., et al.: Going deeper with convolutions. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9, June 2015
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. CoRR, abs/1411.4038 (2014)
Huang, G., Chen, D., Li, T., Wu, F., van der Maaten, L., Weinberger, K.Q.: Multi-scale dense convolutional networks for efficient prediction. CoRR, abs/1703.09844 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. CoRR, abs/1512.03385 (2015)
Tishby, N., Zaslavsky, N.: Deep learning and the information bottleneck principle. CoRR, abs/1503.02406 (2015)
Liu, B., Yu, X., Zhang, P., Tan, X., Yu, A., Xue, Z.: A semi-supervised convolutional neural network for hyperspectral image classification (2017)
Acknowledgements
This work is supported by the National Science Foundation under Grant Nos. 61922027, 61672193, and 61971165.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Yan, J., Zhai, D., Niu, Y., Liu, X., Jiang, J. (2020). Multi-Scale Depthwise Separable Convolutional Neural Network for Hyperspectral Image Classification. In: Zhai, G., Zhou, J., Yang, H., An, P., Yang, X. (eds) Digital TV and Wireless Multimedia Communication. IFTC 2019. Communications in Computer and Information Science, vol 1181. Springer, Singapore. https://doi.org/10.1007/978-981-15-3341-9_15
Download citation
DOI: https://doi.org/10.1007/978-981-15-3341-9_15
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-3340-2
Online ISBN: 978-981-15-3341-9
eBook Packages: Computer ScienceComputer Science (R0)