
Abstract
Continuous speech recognition for a particular language is always an area which relies, for its performance, on these major aspects: acoustic modelling and language modelling. Gaussian mixture model-hidden Markov model (GMM–HMM) is a part of acoustic modelling. These components are applied at the back end of ASR design to accurately and efficiently convert continuous speech signal to corresponding text. Triphone-based acoustic modelling makes use of two different context-dependent triphone models: word-internal and cross-word models. In spite of active research in the field of automatic speech recognition for a number of Indian and foreign languages, only few attempts have been made for Punjabi language, specially, in the area of continuous speech recognition. This research paper is aimed at analysing the impact of GMM–HMM-based acoustic model on the Punjabi speaker-independent continuous speech recognition. Recognition accuracy has been determined at word and sentence levels, respectively, with PLP and MFCC features by varying Gaussian mixtures from 2 to 32.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

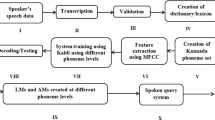
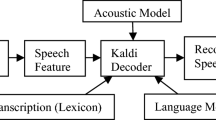
References
R.K. Aggarwal, M. Dave, Using Gaussian mixtures for Hindi speech recognition system. Int. J. Signal Process. Image Process. Pattern Recogn. 4(4) (2011)
Audacity 2.0.0, retrieved June 15, 2012 from http://download.cnet.com/Audacity/
S. Lata, Challenges for design of pronunciation lexicon specification (PLS) for Punjabi language (2011). http://hnk.ffzg.hr/bibl/ltc2011/book/papers/MPLRL-4.pdf
HTK Book, Retrieved on Mar 18, 2012 from http://htk.eng.cam.ac.uk
L. Rabiner, et al., Fundamentals of Speech Recognition (Pearson Publishers, 2010)
N. Souto, et al., Building language models for continuous speech recognition systems. L2 F—Spoken Language Systems Laboratory, Portugal, 2001. http://12f.inesc-id.pt/
B.J. Hsu, Generalized linear interpolation of language models, in ASRU (2007). ISBN: 978-1-4244-1746-9/07
M. Sanda et al., Acoustic modelling for croatian speech recognition and synthesis. INFORMATICA 19(2), 227–254 (2008)
H. Ney et al., On structuring probabilistic dependences in stochastic language modeling. Comput. Speech Lang. 8(1), 38 (1994)
M.N. Stuttle, A Gaussian Mixture Model Spectral Representation for Speech Recognition (University Engineering Department, Hughes Hall and Cambridge, 2003)
W. Ghai, N. Singh, Continuous speech recognition for Punjabi language. Int. J. Comput. Appl. 72(14), 422–431 (2013)
S. Sinha, et al., Continuous density hidden markov model for hindi speech recognition. GSTF Int. J. Comput. (JoC), 3(2) (2013). https://doi.org/10.7603/s40601-013-0015-z
M. Vyas, A gaussian mixture model based speech recognition system using MATLAB. Signal Image Process. Int. J. 4(4) (2013)
G.S. Sharma et al., Development of application specific continuous speech recognition system in Hindi. J. Sign. Inf. Process. 3, 394–401 (2012)
M. Dua et al., Punjabi automatic speech recognition using HTK. Int. J. Comput. Sci. Issues (IJCSI) 9(4), 359 (2012)
V. Kadyan et al., Refinement of HMM model parameters for Punjabi automatic speech recognition (PASR) system. IETE J. Res. 64(5), 673–688 (2018)
S. Saraswathi, T.V. Geetha, Building language models for tamil speech recognition system. Springer 3285, 161–168 (2004)
J.B. Graber, Language models. March 2011, Creative Commons Attribution-non Commercial-share Alike 3.0 United States. http://creativecommons.org/licenses/by-nc-sa/3.0/us/
E.W.D. Whittaker, Statistical language modelling for automatic speech recognition of Russian & English, Thesis, Trinity College, University of Cambridge, 1998
T.R. Niesler, P.C. Woodland, A variable-length category-based n-gram language model, in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (Atlanta, USA, 1996)
HTK-3.4.1, retrieved July 7, 2012 from http://htk.eng.cam.ac.uk
P.P. Singh, Sidhantak Bhasha Vigiyaan (Madaan Publication, Patiala, 2010)
R. Weerasinghe, T. Nadungodage, Continuous Sinhala speech recognition, in Conference on Human Language Technology for Development (Alexandria, Egypt, 2011), 2–5
Acknowledgements
Our study aimed at investigating the impact of Gaussian mixtures on triphone-based acoustic model with two different types of features: MFCC and PLP. In spite of active research in the field of automatic speech recognition for number of Indian and foreign languages, only few attempts have been made for Punjabi language, specially, in the area of continuous speech recognition. All participants (speakers) involved are authors of the paper and given their consent for the study done. It is not important to increase the number of speakers with reference to presented work.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ghai, W., Kumar, S., Athavale, V.A. (2021). Using Gaussian Mixtures on Triphone Acoustic Modelling-Based Punjabi Continuous Speech Recognition. In: Gao, XZ., Tiwari, S., Trivedi, M., Mishra, K. (eds) Advances in Computational Intelligence and Communication Technology. Advances in Intelligent Systems and Computing, vol 1086. Springer, Singapore. https://doi.org/10.1007/978-981-15-1275-9_32
Download citation
DOI: https://doi.org/10.1007/978-981-15-1275-9_32
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-1274-2
Online ISBN: 978-981-15-1275-9
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)