
Abstract
OCR deals with the handwritten or printed character recognition with the help of digital computers and soft computing. The scanned images of characters and numbers are used as input for system which is analyzed and transformed it into character codes, normally in ASCII format, which is taken for the data processing. Presently, there are lots of issues in recognition of characters and numbers, which can degrade the performance of the system in various ways. Mainly, the rate of recognition is not improved due to distributed neighborhood pixels of an image. Also, there are some techniques used for the OCR are having lack of contrast levels which is well known by fading of the image. So in this paper, the most important concern is to take such measures to enhance the performance of the system for automatic recognition of characters. Here, the operations are performed on the handwritten English alphabets. The dataset is selected from the Chars74K with different shapes and preprocessed it which deals with filtering and edge detection. Then, in the feature extraction process, features are extracted by using independent component analysis and swarm intelligence is used for feature vector selection. Classification of images are done with the back propagation neural network which gives an effective learning approach. The precise contribution which is evaluated in this research work is the uniqueness of classifications using a combination of the feature extraction and feature optimization (instance selection) using extraction of feature vectors. The performance of the developed system is measured in terms of recognition rate, sensitivity and specificity compared with the benchmark.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Edge detection
- Feature extraction (Independent component analysis and Swarm intelligence)
- Backpropagation neural network
1 Introduction
Optical character recognition deals with the mechanical conversion of descriptions electronically, handwritten or published transcript into the machine encoded transcript, which can be from a skim through the manuscript, a picture of a manuscript or from caption text covered on an appearance. OCR is extensively used as a procedure of data entry from published paper data proceedings which includes documents like passport, invoices, statements of bank, receipts generated through computer machines, business cards, printouts of the information, or every suitable documents which is a shared routine of digitizing published manuscripts so that they can be edited electronically, examined, stored more efficiently and also recycled in machine procedures like cognitive work out, machine conversion, text-to-speech scenarios, key information and text analysis [12, 13]. OCR is a research field in artificial intelligence, recognition of patterns and computer vision. In the real world, there is a huge interest to modify over the published records into automated records for observing the security of applied information for the clients. Alongside these appearances, the necessity is to create personality acknowledgment software design agenda to achieve image analysis in terms of documents which perform deviations of records to the arrangement of electronic readings [14, 15]. Generalized real time block diagram is represented in Fig. 1.

Generalized real-time block diagram
For this process, there are diverse systems presented. In the middle of each approaches, Optical Character Recognition is available as the main crucial technique to perceive typescripts [1]. The vital goal is to quicken the technique of character response in record arrangements. Consequently, the agenda can prepare an incredible number of records within fewer periods and thus replaces the intervals. Currently, the major OCR construction which was shaped to change above the information is obtainable on papers into computers to get ready for the fit records through which the chronicles can be reusable and editable. The current outline or the past procedure of OCR is only OCR without framework practicality. That is the present outline accomplishes the homogeneous personality response or character recognition of single languages.
The paper is organized as, the related work is shortly expounded in Sect. 2. The proposed method is explained in Sect. 3, which consists of data set preparation, preprocessing, feature extraction and selection, and classifier. In Sect. 4, experimental results are shown in detail. Finally, conclusion is drawn in last Sect. 5.
2 Related Works
This section gives various researches are done for the classification of optical character recognition systems. Chaudhary, Garg, Behera et al. [1] shows the utilization of the optical character recognition concept for character recognition so as to achieve document analysis in terms of image, in which they have arranged the data in the grid form. They deal with the product agenda known as character recognition system. They have found that the need for OCR is to create the atmosphere in terms of programming framework to accomplish Document Image Analysis which shows the deviations of the records in their document organization to the electronic procedure. Hamad, Kaya et al. [6] investigated the OCR in various ways. They have given the detailed indication of the experiments that might arise in OCR phases. Additional, they have also reviewed the overall stages of an OCR scheme like preprocessing of the document or image, segmentation of the image, normalization process, feature extraction process and classification process. Then, they have also highlight growths and main uses and uses of OCR. Ahlawat et al. [2] have shown an efficient review of the processes of OCR. The author has discussed the strategies text from an image into arrangement readable format. The machines accept the typescripts through an altering method which makes work as Optical Character Recognition. Afroge, Ahmed, Mahmud et al. [7] presented an ANN-based method for the acknowledgment of characters in English among FNN named as feedforward system. Noise is measured as one of the main product that damages the presentation of CR (character recognition) system. Their net (network) has several layers named as input, hidden, output layers. The entire system is separated into two segments like training and acknowledgment segment. It comprises of acquisition of image, pre-processing and extraction of features. Lee, Osindero et al. proposed recursive RNN with consideration modeling of character recognition [8]. The main compensations of their systems deals with the usage of recursive CNN which deals with the efficient and actual extraction, learned language model, recurrent neural network, the usage of attention mechanism, image features and end-to-end preparation inside a normal back propagation structure. There are various method for omnidirectional processing of 2D images including recognizable characters [11]. Santosh et al. proposed dynamic time wrapping random based shape descriptor for pattern recognition used to match random features and avoided missing features [18,19,20,21].
3 Proposed Method
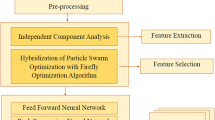
This is one of the crucial sections for the proposed implementation of the system which is based on optical character recognition system. This system deals with the automatic learning system based on training of the images. The proposed approach is mainly divided into two phases. The very first is the training phase in which the normalization of the image using filtration process and the feature extraction process is done and the last process of training deals with the feature optimization process using particle swarm optimization. The second phase deals with the classification approach which is done using back propagation neural network. The main consider which is to be kept in mind is the proper training of the system which is evaluated in terms of the mean square error rates with respect to the number of epochs. Figure 2 explains the block level flow diagram of the proposed approach. The very first block is the building of the graphical user interface for the human man made interactions.

Flow diagram
3.1 Dataset and Preprocessing
The dataset 3410 samples are selected from the Chars74K with different shapes drown using pc and tablet. This dataset is selected because of consideration of scanned images with the solved problem in constrained situations, like common character fonts and uniform background. Also, images are taken with popular cameras and hand held devices to overcome challenges in character recognition. The dataset consists of both English characters and numbers. We have considered the letters which are written in different styles for the samples. The English alphabets having total 62 classes of different styles of writing for each alphabet. Each Image consists of 900 \(\times \) 1200 pixels by size which is high in dimensions and our proposed system is able to operate these high dimension images. In the training phase, 70% of the image data sets are trained and 30% of image dataset samples are taken in the testing phase. It will tell the flexibility of our proposed system to operate on large datasets in the training phase and classification in the testing phase.
The scanned images are preprocessed in terms of binarization, filtering, and edge detection. Binarization is the process of obtaining the black and white image (0 or 1). Then, gradient filter is used for smoothing the image so that it is easy for edge detection process [3]. Edge detection of the image terms as the detection of boundaries of the image and on the basis of which all unnecessary pixels get eliminated. The boundaries are detected using an efficient technique named as the canny edge detector, instead, it can also be used different operator like sobel, log, pewit etc. [5].
3.2 Independent Component Analysis Feature Extraction
In this paper, we have used a generative approach for the observed multivariate data using Independent Component Analysis (ICA), which is normally assumed as huge operations on data to extract out the meaningful information. In the proposed model, the variables are presumed to be linear and nonlinear combinations of certain unknown variables which are also unidentified. The variables are expected non-Gaussian and equally self determined and are known as independent components of the practical information (observed data) which are also termed as sources. We have used ICA computations for the factor analysis as it’s the extension of the principle component analysis. It is a power computation process for the computations of the independent components as features to extract the feature vector which is capable of evaluating the factors analysis where the traditional processes are failed to execute. Here, the dimensions of the images are considered as a parallel set of the signals or we can say the time series. The blind source separation process is recycled in it.
The linear mixtures in terms of observing variables \(T_{1}\), ..., \(T_{n}\) having total P independent components and A is the matrix of the element \(a_{pn}\) such that
So the notation of the vector matrix is given by
The \(S_{i}\) matrix is statistically independent. In this work we have used the non-Gaussian distribution which will be used to estimate the A matrix. After the estimation process of A matrix, we will perform its inverse process, say W and will obtain the independent feature vector using
Where, ‘s’ will be the extracted independent feature values and is organized in the form of a feature vector which is closely related to the blind source separation process. Then the output of the feature vector will be the input to the optimization for the instance selection which is done using particle swarm optimization.
3.3 Particle Swarm Optimization for Selection of Features
PSO algorithm is a global algorithm, which the generalized process used to enhance the problem using iterative scenario which will offer the best explanations and clarifications from various solutions. The algorithm is developed by observing behavior of birds and fishes. In PSO, population is termed as swarm and individuals are particles. These particles will try to get nearest matching, which is termed as personal best (pbest) and global best (gbest) obtained by analyzing closeness of all particles of swarm. The gbest will gives overall best value and its location obtained by any particle in the population. It consists of changing the velocity of each particle as per values of pbest and gbest in each step. It is weighted by separate random numbers being generated for speeding up near pbest and gbest. PSO optimize random solutions particle from the population in D-dimensional space. So that, in PSO neither mutation calculation nor overlapping will be occurred. The collection of procedure limitations can put the huge effect on optimization consequences. In this paper (our research work) we are optimizing the feature set extracted from ICA which is basically known as the instance selection. It is the subset collection rate which is the process of selecting a subsection of appropriate features used in the construction of training model. The feature vector which is extracted from ICA makes new feature vector using operation on feature vector extracted using ICA. Choosing Selection of the input parameters for the PSO is one of the crucial tasks in instance selection process which deals with high performance in the problematic condition in performing optimization. The steps are as follows [9, 10].
-
1.
For every particle \(j = 1, ...\) swarm do
Swarm will be the total number of rows and columns generated using feature vector
Set the particle’s location with a consistently dispersed random vector \(X_{i}\)
Set the particle’s best recognized location to its initial location \(P_{i}\)
-
2.
If \(f (GP) < f (GB)\) then
Get the swarm updated position which is the selection of the instance or the feature value
Make the best particle speed \(V_{i}\)
-
3.
Do until all swarms do
-
4.
Evaluate the fitness function and generate the new solution for the next iteration \(T_{i}\)
-
5.
Make updates on the particle’s speed and location \(X_{i}\) and \(V_{i}\)
-
6.
Generate the global best solution which is the total set of instance selections and optimize feature vector which is the global best solution \(G_{b}\).
Where \(G_{b}\) is the subsequent global best enhanced solution until all iterations are completed.
3.4 Back Propagation Neural Networks
The backpropagation neural network algorithm is proposed in two phases. The very first phase is to set up the input pattern in terms of the layers of the network. The network is repetitive in terms of the number of iterations until it stops training. The network layer consists of the hidden layer which is connected in the form of synaptic weights for the link stability.
This algorithm has been proposed by Sharma et al. [17], to identify the text with respect to the scanned images of the documents which is the form of handwritten printed format. For training and testing purpose this algorithm is useful. After completion of the training we will move to the training phase which deals with the uploading of the test sample comprise of English character which system will automatic classifies and on the bases of which the performance will be evaluated. We have taken the training set as the number of features covered in the feature vector on which the neural perform the back propagation training for the performance evaluations to achieve low updations of weights to make the connections stable.
4 Results and Discussions
This section deals with the valuable simulation of our proposed approach which is taken place in the MATLAB environment.

Main GUI panel
The Fig. 3 shows the graphical user interface panel using MATLAB toolbox in which human machine interaction panel is taken place and the user friendly environment is created. The user will click on the buttons and the user is able to perform actions and generate some events on it.
4.1 Training and Preprocessing
The Fig. 4 shows the training sample of the image of English Alphabet (D) which is to be processed for the further edge detections and filtration for the normalization process in part (a), where as part (b) shows the edge detection of the image which finds some edges of the image and on the basis of which all unnecessary pixels get eliminated. The Canny edge detection technique is performed.

(a). Training sample and (b). Edge detection
4.2 Feature Extraction
The feature extraction process shows the uploaded sample image is extracted in the content of the image which is done using ICA (Independent Component Analysis). ICA is one of the efficient techniques which uses blind source separation concept to find out the independent components which doesn’t disturb the neighborhood pixels and find the characteristics which doesn’t affect the other intensities of the image. As shown in Fig. 5, extracted features for sample 9, indicates independent values per bit.

Features extracted
4.3 Feature Vector Selection
As particle swarm optimization is used, it optimizes feature vector which deals with the relevant instances used for the classification of the sample in the testing phase and also acts as input which is directly fed to the neural network to train the whole system and build network layered model using sigmoid function as an activation function. Figure 6 shows optimized feature values.

Optimize feature vector
4.4 Neural Network Training
As shown in Fig. 7, the training of the system using backpropagation neural network which deals with the number of iterations. It signifies the proposed system is taking total 20 iterations out of max limit of iterations which are 1000 to train the whole system which shows the robustness and also the fast response and reaction time. It also deals with the gradient decedent optimization model which decreases the loss function to achieve low mean square error rate with respect to the number of trained samples.

Neural network training

Classified outputs
4.5 Performance Evaluation
The Fig. 8 shows the classification output which is done using neural network that the uploaded sample deals with the image number 10 having the alphabet (D) in the training dataset which is automatically classified by the machine or system which shows that our proposed approach is able to perform automatic classification for optical character recognition of the English alphabets [4].
Figure 9 shows The performance evaluation in terms of sensitivity, specificity and recognition rate of the proposed system and classification results which signifies that our proposed approach is able to achieve high recognition rate probability which is 0.98216, high sensitivity which signifies the high true positive rates and high specificity which signifies high true negative rates. The recognition, sensitivity and specificity must be high for the low error rate probabilities and less classification error rates.

Performance evaluation
As recognition rate is focused, Table 1 shows 98.21 % characters are matched using this algorithm.
5 Conclusion
OCR is one of the efficient and emerging technologies in real world scenario. A variety of approaches used for optical character recognition are done by the researchers which are used for automatic classification and correlations. This paper deals with an effective and effectual approach for the evaluation of the proposed solution using an automatic classification and optimization approach which deals with the normalization and feature extraction and are achieving high recognition rates of 0.98 and high sensitivity which is 0.995 and high specificity which is 0.96 and are able to achieve low error rate and classification probabilities. From the results and discussion, it can be noticed that the neural network (backpropagation) provides high reaction and response time to perform high rate of classification based on training data and simulate the network in the testing phase to perform automatic character recognition approach.
References
Chaudhary, S., Garg, S., Sathyaraj, R., Behera, A.: An approach for optical character recognition on grid infrastructure using Kohonen neural network. Int. J. Adv. Res. Comput. Sci. 8(3) (2017). https://doi.org/10.26483/ijarcs.v8i3.3039
Ahlawat, D.: A review on character recognition using OCR algorithm. J. Netw. Commun. Emerg. Technol. (JNCET) 7(5), 56–61 (2017)
Gail, H.R., Hantler, S.L.: Method and apparatus for automatic detection of spelling errors in one or more documents. U.S. Patent 9,465,791, issued 11 October 2016
Schultz, S.: Method for the automatic material classification and texture simulation for 3D models, U.S. Patent 9,330,494, issued 3 May 2016
Zhu, Y., Yao, C., Bai, X.: Scene text detection and recognition: recent advances and future trends. Front. Comput. Sci. 10(1), 19–36 (2016)
Hamad, K.A., Kaya, M.: A detailed analysis of optical character recognition technology. Int. J. Appl. Math. Electron. Comput. 4(Special Issue–1), 244–249 (2016). https://doi.org/10.18100/ijamec.270374
Afroge, S., Raihan, M.A.: Optical character recognition using back propagation neural network. J. Image Process. Pattern Recognit. Prog. 11–18 (2016). https://doi.org/10.1109/icecte.2016.7879615
Lee, C.Y., Osindero, S.: Recursive recurrent nets with attention modeling for OCR in the wild. In: Proceedings of the IEEE Conference on CVPR, pp. 2231–2239 (2016). https://doi.org/10.1109/cvpr.2016.245
Burry, A.M., Kozitsky, V., Paul, P.: License plate optical character recognition method and system, U.S. Patent 8,644,561, issued 4 February 2014. https://books.google.co.in/books?isbn=1118971647
Naz, S., Hayat, K., Razzak, M.I., Anwar, M.W., et al.: The optical character recognition of Urdu like cursive scripts. Pattern Recognit. 47(3), 1229–1248 (2014). https://doi.org/10.1016/j.patcog.2013.09.037
Longacre, J.A.: Method for omnidirectional processing of 2D images including recognizable characters: U.S. Patent 8,682,077, issued 25 March 2014. https://patents.justia.com/inventor/andrew-longacre-jr
Bhatia, E.N.: Optical character recognition techniques: a review. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 4(5) (2014). https://pdfs.semanticscholar.org/7ca5/584576423b366ad7bdf03d5fc136a2e958e6.pdf
Mohammad, F., Anarase, J., Shingote, M., Ghanwat, P.: Optical character recognition implementation using pattern matching. Int. J. Comput. Sci. Inf. Technol. 5(2), 2088–2090 (2014). https://doi.org/10.1.1.661.1089
Grimmer, J., Stewart, B.M.: Text as data: the promise and pitfalls of automatic content analysis methods for political texts. Polit. Anal. 21(3), 267–297 (2013). https://doi.org/10.1093/pan/mps028
Mithe, R., Indalkar, S., Divekar, N.: Optical character recognition. Int. J. Recent Technol. Eng. (IJRTE) 2(1), 72–75 (2013). https://doi.org/10.1093/pan/mps028
Kumar B., Kumar N., Palai C., et al.: Optical character recognition using ant miner algorithm: a case study on oriya character recognition. IJCA 61(3) (2013). https://doi.org/10.5120/9908-4500
Sharma, N., Kumar, B., Singh, V.: Recognition of off-line hand printed English characters, numerals and special symbols. In: IEEE International Conference Confluence The Next Generation Information Technology Summit, pp. 640–645 (2014). https://doi.org/10.1109/confluence.2014.6949270
Santosh, K.C., Lamiroy, B., Wendling, L.: DTW-Radon-based shape descriptor for pattern recognition. Int. J. Pattern Recognit. Artif. Intell. (2013). https://doi.org/10.1142/S0218001413500080
Santosh, K.C., Wendling, L.: Character recognition based on non-linear multi-projection profiles measure. Front. Comput. Sci. 9(5), 678–690 (2014). https://doi.org/10.1007/s11704-015-3400-2
Santosh K.C.: Character recognition based on DTW-Radon. In: 11th International Conference on Document Analysis and Recognition - ICDAR 2011, September 2011, Beijing, China, pp. 264–268. IEEE Computer Society (2011). https://doi.org/10.1109/ICDAR.2011.61
Ukil, S., Ghosh, S., Obaidullah, S.M., Santosh, K.C., Roy, K., Das, N.: Deep learning for word-level handwritten Indic script identification. https://doi.org/10.1109/ReTIS.2015.7232880
Acknowledgment
The authors would like to express sincere gratitude to Dr. Ulhas B. Shinde, Principal, CSMSS, Chh. Shahu College of Engineering, Aurangabad, for his continuous support and encouragement to publish this article. They would also like to thank Mr. Devendra L. Bhuyar, Mr. Amit M. Rawate, Mr. Sanket R. Zanwar, and Mr. Ajit G. Deshmukh for their recurrent help in this work.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zanwar, S.R., Narote, A.S., Narote, S.P. (2019). English Character Recognition Using Robust Back Propagation Neural Network. In: Santosh, K., Hegadi, R. (eds) Recent Trends in Image Processing and Pattern Recognition. RTIP2R 2018. Communications in Computer and Information Science, vol 1037. Springer, Singapore. https://doi.org/10.1007/978-981-13-9187-3_20
Download citation
DOI: https://doi.org/10.1007/978-981-13-9187-3_20
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-9186-6
Online ISBN: 978-981-13-9187-3
eBook Packages: Computer ScienceComputer Science (R0)