
Abstract
Automatic parallelization is necessary for all system. Every person wants the program to execute as soon as possible. Now Days, programmer want to get run faster the sequential program. Automatic parallelization is the greatest challenge in now days. Parallelization implies converting the sequential code to parallel code to getting better utilization of multi-core processor. In parallelization, multi-core use the memory in sharing mode or massage passing. Now day’s programmers don’t want to take extra overheads of parallelization because they want it from the compiler that’s called automatic parallelization. Its main reason is to free the programmers from manual parallelization process. The conversion of a program into parallelize form is very complex work due to program analysis and an unknown value of the variable during compile time. The main reason of conversion is execution time of program due to loops, so the most challenging task is to parallelize the loops and run it on multi-core by breaking the loop iterations. In parallelization process, the compiler must have to check the dependent between loop statements that they are independent of each other. If they are dependent or effect the other statement by running the statement in parallel, so it does not convert it. After checking the dependency, test converts it into parallelization by using OpenMP API. We add some line of OpenMP for enabling parallelization in the loop.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Today’s multi-core processor dominate the market of computer processors. Traditional sequential program not utilize the processing power of multi-core architecture, not able to achieve speed up through multi-core processor. Availability of multi-core architecture enable execution of program in parallel and result in great speed up, which can’t be achieved in single core architecture. Parallelization of program can be done in two ways, either programmer can develop program with adding parallel constraints in a program by him self or parallelization is done with automatically parallelize compiler. Second approach ease task of programming, thus programmer doesn’t need to pay a lot attention on parallelizing construct while development of program. In sequential program loops consume a large amount of complete execution time. So our main aim is to break the loop to different processes and parallelization [1] of loop can reduce execution time significantly, thus great performance is gained and maximum utilization of core in processors [2].
Parallel processing is used to increase performance of systems. We can apply parallelization on single processor as well as multiprocessor. Applying it on multiprocessor is achieving more speedup. Automatic parallelization of loop will give us high performance computers.
Now days, the speed of processor is increased and now multiprocessor are shipped in the every personal computer. In the last decade most of compilers are working on sequential programming model. This is very time consuming process. Now, User doesn’t want to wait for long time to run a program. Parallelization is more necessary in the systems. Programmers want to write a code in sequential manner and don’t want to take overhead of parallelization [3] so it is want from compilers. So due to parallelization we get speedup in our program execution time. So implementation based the main purpose is to break the loop in to different thread so we achieve the maximum utilization of multi processors. In parallelization shared memory is also important concern.
Objective of this work is to generate a automatic compiler that automatically convert C code to parallelize one. Automatic parallelization is used to achieve proper utilization of resources or processors. In C programming, parallelization achieving is more tough so we add some thread to easy the process. Automatic compiler takes c program and apply OpenMP construct to given loop to parallelize it. Our main concern is to break the loop and send it onto different threads so, each thread perform their execution separately, but we have to take care of variable that are used in loop and shared to each thread a copy. We give the automatic conversion of serial program to parallel without taking the knowledge of parallelization to the user. So user easily write a program in sequential language but it run on parallel compiler and give output with better speed-up.
We are trying to develop a compiler that automatically generate a parallel code for sequential program. First, in this we generate the equation from loop statements, after that we reduce the problem to simpler way and apply dependence test to find the dependence between loop statements to convert it on parallelize. For dependency we apply gcd test for check the coefficients and after that we apply banergee test to check their lower bound or upper bound of loop to find it in range. So we add OpenMP construct to the code for parallelization to achieve maximum speedup. In this we take a sequential C program as a input and parallelize code is generated that can run on multi-core processors. So we achieve some level of processor utilization. In this work we use lex and yacc [4] tool to generate token and parsed the token to meaning full statements. Using this tool we easily get the position where we have to put OpenMP construct and check the dependence. So our compiler is getting input of C program then convert it on parallelize form where is requirement and give maximum speedup. We implement some as to shared variable and some as private for as per use in run time Whereas, array variable is always declared in shared. We use some mathematical forms to test the dependence in loop statements like echelon and uni-modular matrix. Using mathematical forms it easy to understand the loop statements and easily perform action on statements. So at last we make a compiler that covert automatically sequential program to parallelize without knowledge of this to user.
In this section, we describe the problem of sequential program and requirement of parallelization. In the second section, we discuss about OpenMP language. OpenMP constructs, how to used it and what about threads? In third section we classifies the dependency and different test of dependency. In fourth section, we discuss about this purpose work, algorithm, flow graph of process and give a conversion of sequential program to parallelize program. In last section, we write conclusion and future work of project.
2 OpenMP
OpenMP (Open Multi Processor) OpenMP is shared memory API (Application Program Interfaces) that facilitate shared memory parallelism in programming [5]. It is used to create shared memory parallel programs. It’s not a new programming language. It’s notation can be bind with different languages like FORTRAN, C, C++, etc. The used of OpenMP code at desired position it is very beneficial for parallel with minimal modification in the code. The advantage of OpenMP is that the responsibility of working out in parallel is up to the compiler. OpenMP have to declare both shared and private variable. In this we don’t required to change the most of the program but more important work is to identifying the parallel code.
OpenMP execute a program by groups of threads. But in multiple threads is working then we had to share the resources. Each individual thread also needs their own resources. Multiple threads run on a single processor to execute a code in parallel with context switching. We have to shared a copy of variable to each threads. The program run with single thread as master thread then the multiple thread is fork when parallel code is begin and at the end it convert it again initial thread. Figure 1 shows, the team of threads activated when the code is able to run in parallel and after completion of threads it combined it on master thread. In OpenMP program, we write a parallel code without changing the sequential code that used if we not getting better performance then we can use sequential program. The omp_get_thread_num value 0 shows that its master thread. And if our compiler is not supported for OpenMP Api, so we used this statement that not give error [5].

Fork join programming model
3 Introduction to Data Dependence’s
In Sequential program their are group of statement. Their is an action that perform on certain sequence. After converting it onto parallelization their is no sequence because any sentence can execute before any other statement. So we have to check that their is no reflect in the output after this [6] So we check the variable that modifying or accessing the another variable because any variable in first statement is getting read and in second statement is writing to the same memory location [7]. If we interchange the order of these statements then reading variable statement gives incorrect output. So, this is called Dependence. So after changing the order of statements does not reflect the output of main program means there is no dependence [8].
In this we classified different type of dependency like flow, anti, output, etc. We also discuss about dependency test that used to check the dependency for loop statements.
3.1 Data Dependence
There are two statements S1 and S2. Then S2 is depends on S1 if they came in one of three condition.
-
S1 is reading and S2 is writing
-
S1 is writing and S2 is reading
-
S1 and S2 both are in writing
and there is a path from S1 to S2 in the block. It classified in three categories
-
Flow Dependence(RAW)
Statement S1 is writing into a memory location and later on is read by S2 statement.

-
Anti Dependence(WAR)
Statement S1 is reading into a memory location and later on is writes by S2 statement.

-
Output Dependence(WAW)
Statement S1 is writing into a memory location and later on is also write by S2 statement.




When executing a parallel program than the order of execution is change according to sequential execution. So the result of execution may also change, so we have to check all the case of statements. This is known by dependence analysis [9].
3.2 GCD Test
GCD (Greatest Common Divisor) test is used for finding the dependence between loop statements. In this test we take the gcd of all coefficients in the equation and then it should be divide to constant part of equation. If it’s not divisible then we say their is no dependency. Below we show gcd test in two part for one dimensional and two dimensional equations problem [10, 11].
3.3 Banergee’s Test
Banergee’s test find the dependency using intermediate value. In this we compute the lower bound and the upper bound of the equations [10].
3.4 Omega Test
The omega test is used for find the exact dependency between the statement. This test determine whether their is integer solution or not. In this our input is linear equations in the form of linear equalities and inequalities [12]. This process is goes on different steps.
-
Normalizing constraints
-
Equalities Constraints
-
Dealing With Inequalities Constraints
4 Proposed Work
In the starting chapters we introduce some data dependency tests, information about OpenMP. In this we show the full technique of my project that we have applied in my project from starting to the end. In this chapter we are explaining flow graph, algorithm, example of Dependence test and conversion of sequential c code to parallelize C Code. In this work, we have used some tool like Lex and Yacc for parsing of input c program after then we used mathematical form to solve out the big equations and then apply dependence test for parallelization. In the last we generate output file of parallelize code.

Flow chart of my project
4.1 Flow Diagram
Flow graph is used for showing the flow of program. In Fig. 2, we show the flow of whole process of the project. In the starting we generate the token of input file using Lexical analyzer. Then we parser for parsing the token stream into meaning full sentence. So, now we can find out the loop statements where we have separate the code for parallelization and generate equations for applying dependence test. In the above chapter we have explained a dependence test and find the dependency of loop after that we check that is true or false. If dependence is exist then we add the code of OpenMP into input file and also defined the shared and private variable during run time of code. At last we display the output file with OpenMP binding.
4.2 Algorithm
We implement an algorithm for whole process that we done in my project. It takes an input file of C code that we have to parallelize. In the output we generate the parallelize code of input file to achieve maximum utilization of processor. Inside the algorithm we have used some more function like echelon reduction method for simplified the equations. We use dependence algorithm word in algorithm that is basically telling that its applying dependence test that is describe on last chapter.

4.3 Example of Dependency Test
Now we are taking an loop with one nested level and check the dependency using data dependence algorithm by gcd test and banergee test. In this first we generate input matrix, continue with generation of Echelon and Uni-modular matrix and then apple test to find the dependency of statements.
4.4 Example of Conversion of C Code Using OpenMP
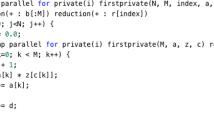
Here we explaining the conversion of sequential C code to parallelize version using OpenMP api. In this we taking a two matrix value multiplication in input and after parallelize we used thread to do sum in shared mode. In this program first we check where we have to apply parallelization. So using lex and yacc tool we find the loop in the program and apply dependence test to loop statements. After checking dependence we add OpenMP constraints in sequential program before each loop. At last we check that the variable are in which mode like sharing or personal copy of each variable to each thread.

In above example we add OpenMP directive in both loop because in upper loop we just initialize the array variable with integer value so there is no dependence and both array are in sharing mode during multiple thread run. Example: Consider the problem of finding the dependence between S1 and S2 in the loop nest

caused by the two variables shown.
The output variable of S1 and the input variable of S2 are elements of a two-dimensional array arr. The variable \(arr(2i-1,i+j)\) can be written as \(arr(IA+a_{0})\) where \(I=i+j\),
since
Similarly, the variable \(arr(3I_{2},I_{1}+2)\) can be written as \(arr(IB+b_{0})\), where
The instance of \(arr(IA+a_{0})\) for an index value i is \(arr(iA+a_{0})\), and the instance of \(arr(IB+b_{0})\) for an index value j is \(arr(jB+b_{0})\). They will represent the same memory location iff
This is the dependence equation for the above loop. It also be write as
where (i;j) is the result of adding the components of j to i, and \(\begin{pmatrix} A \\ -B \end{pmatrix} \) is the result of adding the rows of −B to lower part in the rows of A. after generating it can use for input in echelon reduction algorithm, we get the system:
There are n equations in 2m variables, where n is the number of dimensions of the array X, and m is the number of loops in the loop nest; here \(n=2\) and \(m=2\).
To solve this system, we apply Algorithm 1, find two matrices
such that U in unimodular, S is echelon, and U\(\begin{pmatrix} A \\ -B \end{pmatrix} =S\). The system has an (integer) solution in the variable \(i_{1},i_{2},j_{1},j_{2}\) iff the system shown below has an (integer) solution in \(v_{1},v_{2},v_{3},v_{4}\) to multiply with echelon matrix and get the vector (1,2)
If the equation has no solution, then two instances of the variables of S1 and S2 can never represent the same memory location, and hence they cannot cause a dependence between S1 and S2. However, we find that equation does have a solution. The general solution is given by to solving the matrix.
Note that the number of integer parameters \((v_{1},v_{2},v_{3},v_{4})\) whose values are determined by equation is \(\rho \) where
The general solution to system can be written as
Let \(U_{1}\) denote the matrix formed by the first two columns of U and \(U_{2}\) the matrix formed by the last two columns. Then we have
Next, consider the constraints of the dependence problem. The index variables \(I_{1}\) and \(I_{2}\) must satisfy the inequalities:
or
In matrix notation, we can write
where \(p_{0}=(1,1),P=I_{2},q_{0}=(100,0),\) and \(Q= \begin{pmatrix} 1 &{} -1 \\ 0 &{} 1 \\ \end{pmatrix}\) Since \((i_{1},i_{2})\) and \((j_{1},j_{2})\) are values of \(I=(I_{1},I_{2}),\) they must satisfy
we generate the equation for \((v_{3},v_{4})\) follow as.
of using graph problem we can find out the value of \(v_{3}\) and \(v_{4}\).
For each solution \((i_{1},i_{2},j_{1},j_{2})\) to system that satisfies above, the corresponding integer vector \((v_{3},v_{4})\) must satisfy just above, Conversely, for each (integer) solution \((v_{3},v_{4})\) to (5.1), we get from (5.3) and (integer) solution \((i_{1},i_{2},j_{1},j_{2})\) to (5.1) satisfying the constraints (5.5). If a solution to (5.6) exists, then that would indicate the existence of two iterations \((i_{1},i_{2})\) and \((j_{1},j_{2})\) of the loop nest, such that the instance \(S1(i_{1},i_{2})\) of S1 and the instance \(S2(j_{1},j_{2})\) of S2 reference the same memory location.
5 Conclusion and Future Work
This work is to achieve automatic parallelization, maximum utilization of resource, time saving from running program in sequential mode. In this we use OpenMP API for C language to achieve automatic parallelization. In our work, we generate a output file that consist of sequential code and OpenMP Statement that add threads in a program. In this our main aim to relive the programmer to overhead of parallelization because we are generating automatic compiler that convert automatically sequential program to parallelize one. Using OpenMP api we get maximum utilization of multi-core architecture systems, because sequential code never get proper utilization of multi-core process. We convert sequential C program to parallelize one which containing input C program with OpenMP directive to add parallelism. To achieve the parallelization we first find out where we apply parallelization or achieve maximum utilization of resource using lex and yacc tool to parse the input program. Then we apply OpenMP directive before for loop starting after check the dependency between loop statements. Our future work is to exceed the parallelization by adding advanced form of OpenMP to reduce the running time. In this we can increase the level of parallelization by applying it to on functions, pointer etc.
References
Li, Z., Yew, P.C., Zhu, C.Q.: An efficient data dependence analysis for parallelizing compilers. IEEE Trans. Parallel Distrib. Syst. 1(1), 26–34 (1990)
Eigenmann, R., Hoeflinger, J., Padua, D.: On the automatic parallelization of the perfect benchmarks. IEEE Trans. Parallel Distrib. Syst. 9(1), 5–23 (1998)
Banerjee, U.K.: Loop Parallelization. Kluwer Academic Publishers, Norwell (1994)
Levine, J.R., Mason, T., Brown, D.: lex & yacc O’Reilly & Associates. Sebastopol (1990)
Chapman, B., Jost, G., Van Der Pas, R.: Using OpenMP: portable shared memory parallel programming, vol. 10. MIT press, Cambridge (2008)
Pugh, W., Wonnacott, D.: Eliminating false data dependences using the omega test. In: ACM SIGPLAN Notices, vol. 27, pp. 140–151. ACM (1992)
Kyriakopoulos, K., Psarris, K.: Efficient techniques for advanced data dependence analysis. In: Proceedings of the 14th International Conference on Parallel Architectures and Compilation Techniques, PACT 2005, pp. 143–156, Washington, DC, USA. IEEE Computer Society (2005)
Burke, M., Cytron, R.: Interprocedural dependence analysis and parallelization. SIGPLAN Not. 21(7), 162–175 (1986)
Psarris, K., Kyriakopoulos, K.: An experimental evaluation of data dependence analysis techniques. IEEE Trans. Parallel Distrib. Syst. 15(3), 196–213 (2004)
Pugh, W.: A practical algorithm for exact array dependence analysis. Commun. ACM 35(8), 102–114 (1992)
Psarris, K.: The Banerjee-Wolfe and GCD tests on exact data dependence information. J. Parallel Distrib. Comput. 32(2), 119–138 (1996)
Pugh, W.: The omega test: a fast and practical integer programming algorithm for dependence analysis. In: Proceedings of the 1991 ACM/IEEE Conference on Supercomputing, Supercomputing 1991, pp. 4–13, New York, NY, USA. ACM (1991)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Singal, G., Gopalani, D., Kushwaha, R., Badal, T. (2019). Automatic Parallelization of C Code Using OpenMP. In: Somani, A., Ramakrishna, S., Chaudhary, A., Choudhary, C., Agarwal, B. (eds) Emerging Technologies in Computer Engineering: Microservices in Big Data Analytics. ICETCE 2019. Communications in Computer and Information Science, vol 985. Springer, Singapore. https://doi.org/10.1007/978-981-13-8300-7_25
Download citation
DOI: https://doi.org/10.1007/978-981-13-8300-7_25
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-8299-4
Online ISBN: 978-981-13-8300-7
eBook Packages: Computer ScienceComputer Science (R0)