
Abstract
Handwriting recognition has always been an active and challenging research area with various applications in daily life and also in area of pattern recognition. Some of the applications are reading tool for blind people, reading handwritten bank cheques, by converting it into properly structured text which can be easily detected by the designed algorithms. This paper gives brief analysis of various handwritten recognition techniques, such as Optical Character Recognition (OCR), Artificial Neural Network (ANN), Intelligent Character Recognition (ICR), and Intelligent Word Recognition (IWR). Accuracy rates of all these methods were compared, and the comparative analysis demonstrates that OCR method is the best among them for the recognition of English handwritten characters. Merits and demerits are also discussed for the methods of recognition. Basic steps involved in the handwritten recognition process are also briefed.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Optical Character Recognition (OCR)
- Neural network topologies
- Back propagation algorithm
- Feature extraction process
1 Introduction
With the growing computational power, demand for character recognition methodologies has increased for various applications. It is a difficult task to develop a practical system of handwritten character recognition with high accuracy of recognition. In the existing systems, the accuracy of recognizing the text depends immensely on the quality of the input document. The process of scanning and recognizing static images of the characters is generally called as Offline Character Recognition and also called as Optical Character Recognition (OCR) [1]. To increase the accuracy of system, different classifiers use uppercase and lowercase English alphabets. Handwriting recognition can be divided into two types: online and offline. As discussed in [2], online method is based on the pen trajectory data while offline method relies on the pixel data only. Online method has an advantage that for spatially overlapped characters, segmentation is comparatively easier than offline method. First, the handwritten or printed text is converted into the machine-readable form with the help of OCR system. Basic steps of character recognition are:
1.1 Preprocessing
Preprocessing is the first and the major step of OCR software. At this stage, certain operations are performed on the scanned image, i.e., de-skew, converting an image from color to black and white, cleans up non-glyph boxes and lines, identifies columns, paragraphs, captions as different blocks, and normalization.
1.2 Segmentation
The process of assigning a label for every available pixel in a particular image, so that same set of pixel possessing some common visual characteristics shares same type of label, is called segmentation. This process is generally used for finding the boundaries in a particular image like curves and lines in image. Edge detection is used in this as a method of segmentation.
1.3 Feature Extraction
For acquiring the main traits of input symbols, feature extraction process is used. This process leaves some unimportant traits and extracts the main features. For achieving high recognition performance, the key factor is selection of appropriate feature extracting method [3].
1.4 Classification and Recognition
Classification is the process of choosing character and then assigning it to proper character class to which it belongs. Classification is done by the decision-making unit which uses the features previously extracted by earlier processes [4].
1.5 Postprocessing
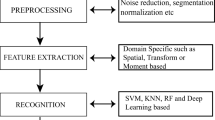
The main function of this block is to print the text which is already recognized in previous stages. This is done by finding the ASCII value of input samples available [5] (Fig. 1).

OCR block diagram
2 Literature Review
Earlier, creating reading devices and expanding telegraphy for the blind people were done by OCR method [6]. Emanuel Goldberg, a renowned scientist in 1914, designed a new device which converts the character (by reading) into some standard codes (telegraphs). During that time, scientist put hard in process of developing a portable machine or scanner-type device which if moved over the written material generated some unique sounds or tones, which help in recognizing the character in handwritten material. But it failed to read non-optical characters for which different researches are done in past. M. Sheppard in 1951 [7] developed Intelligent Character Recognition (ICR), which is one of the specific recognition systems that can be used for variety of fonts and different kind of handwriting samples and helps in increasing the recognition rate and accuracy of designed system.
Most ICR systems are incorporated with a self-learning mechanism called as Artificial Neural Network, ANN, which basically updates the database for every handwritten samples received. It improves the system by detecting handwritten samples in place of printed samples, which is the main function of OCR [8]. It can achieve 97%+ accuracy rates; sometime the accuracy is not good in reading the handwritten data in structured forms. Intelligent Word Recognition (IWR) is very effective system not only for printed handwritten material but also for various types of handwriting forms like cursive writing and others [3].
Some of the recently used techniques are listed below:
2.1 Artificial Neural Networks
Various topologies such as Radial Basis Function, Back Propagation, and Nearest Neighbor Network of Neural Network are used for the process of classification. ANN basically learns from the various image training sets available [9]. After training, it is used for the process of character identification. Then for the new image entered, ANN basically finds the similarity with the training images and then conclude the result on the basis of similar factors. The neural network has three layers: an input layer consisting of 100 nodes (for the 10 by 10 letter input), a hidden layer which consists of 50 nodes, and an output layer with 26 nodes (each letter) as shown in Fig. 2.

Artificial Neural Network
2.2 Radial Basis Function
It is a type of function which depends on a point which is basically distance from particular location. For getting good results, it requires 1800 neurons on validation data sets [10].
2.3 Statistical Methods
Character recognition fields are mainly divided in two types: nonparametric and parametric [11]. In nonparametric recognition, the pattern is identified by the usage of cluster, which has a center at particular short distance from the pattern over the set of clusters. Any prior information about the data is not required. In parametric recognition, some priori information is available, and by that a parametric model for each and every character can be obtained.
2.4 Structural Methods
In the area of structural recognizing, a method called syntactic is considered one of the most prevalent approaches. Concept of grammar can be used to find the similarity content in structural components. The character composition is given on the basis that each individual class of variable is having its own grammar definition. The strings or trees representation can be used to represent grammar.
2.5 Feature Extraction Techniques
For specifically handwritten character, Diagonal-Based Technique is used for the feature extraction [4]. Gupta et al. [10] used the potential feature like Horizontal/Vertical strokes and end points for recognition and reported an accuracy of about 90.50% for handwritten Kannada numerals. Zoning, Template matching, N-tuples, Moments, Crossing, and Distances are some of the widely used techniques.
Above section gives the brief description of various handwritten detection techniques used in past followed by some recent techniques used for detection of handwritten data of various types of languages other than English also. Accuracy of methods and other parameters is also compared.
3 Conclusion
This paper gives an analysis of various recognition techniques for handwritten text images. For character recognition, the use of ANNs has also been described which results in high noise tolerances at the output as compared to other methods. Comparative analysis shows that excellent results are obtained by using these systems. Most important step of OCR is feature extraction. A set of features should be properly chosen to yield good neural network classification rates. While analyzing all methods, it is found that among the other methods, OCR method is one of the best methods specifically for English text and cannot be replaced with other methods. In this by using the distance among the connected component, probability of word boundary is estimated. This is done by combining segmentation and recognition distance. The past work discussed will provide the better understanding of the method and will help the new researchers who are keen to work in this field for the betterment of the new technology.
References
V.L. Sahu, B. Kubde, Offline handwritten character recognition techniques using neural network: a review. Int. J. Sci. Res. (IJSR) 2(1), (Jan 2013)
R. Seiler, M. Schenkel, E. Eggimann, Off-line cursive handwriting recognition compared with on-line recognition, in IEEE Proceedings of ICPR ’96, 1015-4651/96 (1996)
J. Pradeep, E. Srinivasan, S. Himavathi, Diagonal based feature extraction for handwritten alphabets recognition system using neural network. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 3(1) (Feb 2011)
N. Arica, F. Yarman-Vural, An overview of character recognition focused on off-line handwriting. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 31(2), 216–233 (2001)
K. Prasad, D.C. Nigam, A. Lakhotiya, D. Umre, Character recognition using matlab’s neural network toolbox. Int. J. u- and e- Serv. Sci. Technol. 6(1) (Feb 2013)
N. Arica, F.T. Yarman-Vural, An overview of character recognition focused on off-line handwriting. IEEE Trans. Syst. Man Cybern.—Part C: Appl. Rev. 31(2) (May 2001)
B. Verma, M. Blumenstein, S. Kulkarni, Recent achievements in offline handwriting recognition systems
R. Plamondon, S.N. Srihari, On-line and off-line handwriting recognition: a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell. 22(1) (Jan 2000)
J. Pradeep, E. Srinivasan, S. Himavathi, Neural network based recognition system integrating feature extraction and classification for English handwritten. Int. J. Eng. 25(2), 99–106 (May 2012)
A. Gupta, M. Srivastava, C. Mahanta, Offline handwritten character recognition using neural network, in International Conference on Computer Applications and Industrial Electronics (ICCAIE-2011)
T. Ahmad, A. Jameel, B. Ahmad, Pattern recognition using statistical and neural techniques. 978-1-61284-941-6/11/$26.00<S>20 11 IEEE
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Tiwari, U., Jain, M., Mehfuz, S. (2019). Handwritten Character Recognition—An Analysis. In: Singh, S., Wen, F., Jain, M. (eds) Advances in System Optimization and Control. Lecture Notes in Electrical Engineering, vol 509. Springer, Singapore. https://doi.org/10.1007/978-981-13-0665-5_18
Download citation
DOI: https://doi.org/10.1007/978-981-13-0665-5_18
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-0664-8
Online ISBN: 978-981-13-0665-5
eBook Packages: EngineeringEngineering (R0)