
Abstract
In this work, a new hybrid approach based on offset min-sum decoding algorithm is proposed for decoding irregular low-density parity-check (LDPC) codes. In the proposed algorithm, incorporations are made in both the nodes of the Tanner graph with varying error correcting factors. In addition, to the error correcting factors, an adaptive weighting factors are utilized in CNU and VNU process to mitigate the numerical instabilities and negative correlation effects. These modifications in turn enhance the error correcting performance, which ultimately results in a better decoding efficiency. Through exhaustive simulation and comparison, it is shown that the proposed algorithm with a six-bit non-uniform quantization scheme exhibits good error correcting outcome at BER of 10−5 with an acceptable computational complexity.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Low-density parity-check (LDPC) codes [1] have been a revelation in the field of error control coding (ECC) since their comeback in early 1990s [2]. In the current scenario of LDPC decoding, the min-sum algorithm (MSA) [3] and its variants are widely employed for better noise immunity and efficient hardware realization. An innovative approach in MSA is proposed by utilizing two different modification factors in check node process (MNMSA) [4]. This methodology uses the theory of order statistics to derive suitable modification factor to enhance the bit error rate (BER) performance. This method is enhanced to a certain extent by utilizing self-adaptive error correction factors (SAMSA) instead of order statistics [5]. This process achieves good reduction in computational complexity compared to [4]. Even though this process has fewer merits, it is not preferred for larger codeword length and irregular LDPC codes. The simplified version of 2D-MSA (SDMSA) [6] is proposed with an objective to achieve good error correcting performance with minimal numerical instability. Furthermore, in this numerical instability is reduced by replacing conventional multiplication operations with addition and shifting operations. Recently, an improvement to MSA using density evolution (IMSA) was proposed by Wang et al. [7]. This algorithm has a twofold approach, first was by utilizing probability density function to calculate the suitable error correction factor. Then, the selected error correction factor is calculated using the weighted average. In summary, these algorithms show that by utilizing different methodologies ranging from high-order statistics to probability density function achieves better improvement in error correcting performance and complexity reduction. However, these algorithms do suffer from severe error floors when decoded with larger block length irregular LDPC codes.
In this paper, an improved hybrid algorithm based on [8] is presented. In order to subdue the shortcomings of the former algorithms, some new incorporations are carried out in both the nodes of bipartite graph, i.e., check node unit (CNU) and variable node unit (VNU). In general, the magnitude overestimation issue occurs when a single decoding algorithm is used to decode multiple codeword lengths of irregular LDPC codes. This often results in numerical instabilities which increases the requirement for more decoding iterations. To overcome this drawback, multiple error correction factors, along with iteration dependent compensation (weighting) factors are employed in the CNU. These error correcting factors are adaptive and are dynamically used on the switching basis to enhance the convergence speed. Also, in the bit node update process along with error correction factor a penalty (weighted) factor is used to minimize the negative correlation effects of the iterative information updating process. However, the usage of weighting factors enhances the computational complexity moderately. Furthermore, this proposed algorithm is shown to be compatible with different types of irregular LDPC codes with varying code length and rates. Also, this decoding algorithm can be employed in designing resource efficient multi-standard LDPC decoders.
2 Framework
In general, let the set of variable nodes associated to the cth check node be N(c), and the subset excluding the νth bit node from N(c) be denoted as N(c)\ν. Similarly, the set of check nodes connected to the νth bit node be M(ν), and the subset excluding the cth check node from M(ν) be denoted as M(ν)\c The following notations are utilized to signify the decoding process:
Lch: The log-likelihood ratio (LLR) information according to the received channel value.
\( \alpha_{cv}^{(i)} \): The outgoing LLR data from check node c to variable node ν.
\( \beta_{vc}^{(i)} \): The outgoing LLR information from variable node ν to check node c.
\( \beta_{v}^{(i)} \): Aposteriori LLR information computed at each iteration.
\( h_{n}^{T} = (h_{n,1} ,h_{n,2} , \ldots ,h_{n,N} ) \) n = 1, 2, …, N: Rows of the H matrix.
\( \sigma_{{d_{c} (m)}}^{(i)} \): Offset factor for check node update processing.
\( \theta_{{d_{c} (m)}}^{(i)} \): Iteration dependent weighting factor.
\( \zeta_{{d_{c} (m)}}^{(i)} \): Stifling factor in check node processing.
\( \xi_{{d_{c} (m)}}^{(i)} \): Optimally adaptive offset factor for CNU.
\( \delta_{{d_{\nu } (n)}}^{(i)} \): Offset factor for variable node processing.
\( \mu \): Iteration dependent penalty factor for variable node.
2.1 Decoding Methodology of the Proposed Algorithm
The decoding flow of the proposed algorithm is described briefly below
Step 1: Initialization Process
Step 2: Check node function
Message stifling if \( \left( {h_{n}^{T} \cdot x\, = \, = \, 1 {\text{ mod 2}}} \right) \), where x = sign \( (\beta_{v}^{(i)}) \)
Step 3: Bit node function
Step 4: Judge and terminate using end conditions
If (\( H^{T} \cdot \widehat{c} = = 0 \)) output x and the decoding process is terminated.
3 Simulation Results
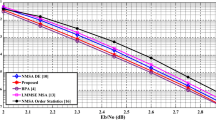
In order to validate the decoding efficiency of the proposed methodology, two different irregular rate 1/2 LDPC codes belonging to Wi-MAX and WLAN standards have been considered, respectively. Figures 1 and 2 show the error correcting performance of the proposed algorithm and its comparison with few recent decoding algorithms. For performance comparison purposes, the maximum decoding iterations are fixed at 10 and a six-bit non-uniform quantization scheme is adopted. Furthermore, in the proposed decoding algorithm with the error correction factor values are found using heuristic simulations [9] and are found to be \( \left( {\alpha_{{d_{c} (m)}}^{(i)} ,\xi_{{d_{c} (m)}}^{(i)} ,\delta_{{d_{\nu } (n)}}^{(i)} } \right)\, = \,\left( {0. 2 1, \, 0. 3 3, \, 0. 3 7} \right) \) for rate 1/2, Wi-MAX Standard and (0.18, 0.29, 0.33) for rate 1/2, WLAN Standard irregular LDPC code, respectively. In light of results illustrated in Figs. 1 and 2, it is clearly evident that the proposed scheme outperforms the recently proposed schemes convincingly in terms of BER when measured at BER of 10−5. Therefore, clearly it is demonstrated using experimental simulations that the proposed hybrid scheme achieves better error correction phenomenon with only a small increase in the implementation complexity. This outstanding error correcting phenomenon trait exhibited with irregular LDPC codes of larger codeword length is clearly suited for many emerging wireless communication standards.

BER plots for the rate 1/2 (2304,1102) irregular LDPC codes of Wi-MAX standard

BER plots for the rate 1/2 (1944,972) irregular LDPC codes of WLAN standard
4 Conclusion
In this paper, an improved hybrid offset decoding algorithm based on adaptive weighting factors is introduced. The proposed methodology is applied to irregular LDPC codes belonging to Wi-MAX and WLAN standard. Through exhaustive simulations, it is clearly seen that the intended algorithm can achieve considerable coding gain improvement with minimum increase in the computational complexity. By analyzing the performance with recent MSA-based decoding algorithms, the proposed scheme exhibit better decoding efficiency without any additional implementation overhead.
References
Richardson, T., Shokrollahi, A., Urbanke, R.: Design of capacity approaching irregular low-density parity-check codes. IEEE Trans. Inf. Theory 47(2), 619–637 (2001)
Mackay, D.J.C.: Good error-correcting codes based on very sparse matrices. IEEE Trans. Inf.Theory 45, 399–431 (1999)
Fossorier, M., Mihalijevic, M., Imai, H.: Reduced complexity iterative decoding of low-density parity-check codes based on belief propagation. IEEE Trans. Commun. 47(5), 673–680 (1999)
Xue, W., Ban, T., Wang, J.: A modified normalized min-sum algorithm for LDPC decoding using order statistics. Int. J. Satell. Commun. Netw. (Wiley) 35(2), 163–175 (2017)
Cho, K., Chung, K.-S.: Self-adaptive termination check of min-sum algorithm for LDPC decoders using the first two minima. KSII Trans. Internet Inf. Syst. 11(4), 1987–2001 (2017)
Cho, K., Chung, K.-S.: Simplified 2-dimensional scaled min-sum algorithm for LDPC decoder. J. Electr. Eng. Technol. (JEET) 12(1), 1921-718 (2017)
Wang, X., Cao, W., Li, J., Shan, L., Cao, H., Li, J., Qian, F.: Improved min-sum algorithm based on density evolution for low-density parity check codes. IET Commun. 11(10), 1582–1586 (2017)
Roberts, M.K., Jayabalan, R.: A modified optimally quantized offset min-sum decoding algorithm for low-complexity LDPC decoder. Wirel. Pers. Commun. J. 80(2), 561–570 (2015)
Chen, J., Fossorier, M.P.C.: Density evolution for two improved BP-based decoding algorithms of LDPC codes. IEEE Commun. Lett. 6(5), 208–210 (2002)
Acknowledgements
This research work is funded by the Department of Science and Technology, Government of India through Early Career Research Award (Young Scientist) scheme of Science and Engineering Research Board (SERB) (Grant no. ECR/2016/001275).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Roberts, M.K., Sunny, E. (2019). An Improved Hybrid Offset-Based Min-Sum Decoding Algorithm. In: Fong, S., Akashe, S., Mahalle, P. (eds) Information and Communication Technology for Competitive Strategies. Lecture Notes in Networks and Systems, vol 40. Springer, Singapore. https://doi.org/10.1007/978-981-13-0586-3_70
Download citation
DOI: https://doi.org/10.1007/978-981-13-0586-3_70
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-0585-6
Online ISBN: 978-981-13-0586-3
eBook Packages: EngineeringEngineering (R0)