
Abstract
Road traffic prediction offers traffic guidance for travelers and relieves traffic jams with effective information. In this paper, a real-time road traffic state prediction based on support vector machine (SVM) and the Kalman filter is proposed. In the proposed model, the well-trained SVM model predicts the baseline travel times from the historical trips data; the Kalman filtering-based dynamic algorithm can adjust travel times by using the latest travel information and the estimated values based on SVM. Experimental results show that the real-time road traffic state prediction based on SVM and the Kalman filter is feasible and can achieve high accuracy.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Road travel time provides travelers with effective information from urban traffic control departments, which conducts a reasonable traffic induction, and is the main basis of improving the utilization rate of the traffic. TTP (Travel Time Prediction) has become the research focus, and many experts and scholars both of the foreign and domestic are studying this problem.
In recent years, with the rapid development of intelligent transportation system, the related research also got great progress. At present, a lot of researches of travel time prediction at home and abroad especially is based on travel time. Deb Nath et al. [1], Chowdhury et al. [2], and Chang et al. [3], respectively adopted K means clustering method, the improved moving average method and improved Bias classifier and rule based classifier to predict travel time, but those require very large amount of data samples. Based on the historical and real-time data, Chien and Kuchipudi [4] used Kalman filter algorithm to predict the travel time, in which the accuracy is very high, but the accuracy of this method in the none peak period is low. Tu et al. [5] also considered factors of space and time respectively by using historical data of linear regression analysis and grey theory model of expressway vehicle travel time prediction, which gets the final prediction speed of the two kinds of prediction speed weighted, and gets the predicted travel time with the road length divided by the speed prediction. Zhu et al. [6] got the distribution rules of traveling time in the particular time span through adopting statistical analysis methods of historical data, from which he got the final traveling time, but poor adaptability, statistical analysis of historical data fitting based on distribution function are not known distribution function in all cases, so the prediction accuracy in this case is difficult to guarantee. Yang et al. [7] proposed a Fuzzy Expressway travel time prediction model, the application of this model to achieve high prediction accuracy of the need to consider many factors. This paper considers the impact of traffic flow and sharing, but has not formed a system of weight allocation method. Yang et al. [8] adopted the sharing data through the pattern to match the travel time to predict the traveling time of city expressway. This model is based on historical data, but when matching needs compared one by one, time consuming, and update the database in real time, it is not dynamic. Therefore, the model of anti-jamming ability is not enough.
The above methods for the prediction of travel time also have the following problems and challenges:
-
(1)
Large sample data;
-
(2)
In direct prediction, adopting other parameters in the traffic flow forecast after the travel speed and then calculating travel time;
-
(3)
The influence factors and the parameters (weight distribution) of the selected subjectivity;
-
(4)
Generality of model is poor.
To solve the above problems, this paper establishes two comprehensive prediction models based on support vector machine theory and Kalman filter algorithm to predict the travel time, which not only can overcome the dependence of the amount of training data, but also has strong anti-jamming ability. Compared the predicted results with ARIMA prediction method and Kalman filter prediction method to verify the accuracy of the model, this paper analyzes the applicability of the SVM and Kalman filter integrated forecasting model proposed in different periods.
2 Travel Time Prediction Model Based on SVM and Kalman Filtering
2.1 Initial Travel Time Prediction Model Based on Support Vector Regression Theory
The support vector machine theory includes linear support vector machine classification algorithm, nonlinear support vector machine classification algorithm and linear support vector regression algorithm, nonlinear support vector regression algorithm. Currently, these algorithms have been applied in many fields to realize the classification and regression forecast object characteristic value, and simultaneously achieves good results. The travel time of vehicles changes with time and is not a simple linear relationships, will not be increased without limit, nor without limit decreases. A given road travel time is fluctuated in a range. Therefore, using the least squares regression simple and similar methods of travel time prediction is not reasonable. And the nonlinear regression of SVM theory can solve this problem. So this paper uses the nonlinear support vector machine regression theory.
If the learning sample set (training set) \( S = \left\{ {\left( {x_{i} + y_{i} } \right),x_{i} \in R^{n} ,y_{i} \in R^{n} } \right\}_{i = 1}^{l} \) is nonlinear, change the input sample space of nonlinear transformation to another high dimensional feature space, construct the linear regression function in the feature space, and the nonlinear transform is realized by defining appropriate kernel function \( {\text{K}}\left( {x_{i} ,y_{i} } \right) \). Where \( {\text{K}}\left( {x_{i} ,y_{i} } \right) = \phi \left( {x_{i} } \right)^{T} \phi \left( {x_{j} } \right),\phi \left( x \right)y \) is a nonlinear function. Therefore, the problem of nonlinear regression function is reduced to the following optimization problem:
The constraint condition is
The lagrange dual problem for this problem is
The constraint condition is
The nonlinear function is obtained by solving the dual problem. When the constraint condition can’t be achieved, two slack variables are introduced:
The problem to be optimized should be:
The constraint condition is
In this formula C > 0 is the penalty factor, where the greater the C is, the more the errors come from the big data point. Lagrange can be used to solve the constrained optimization problem of multiplier method for Lagrange’s function is constructed as follows:
According to the optimization theory, the \( L \) respectively for \( w \), \( b \), \( \xi_{i} \), \( \xi_{i}^{ * } \) partial differential and make them 0, get
Substitute formula (11) into formula (10), the dual optimization problem solves the nonlinear regression function.
2.2 Dynamic Prediction Model Based on Kalman Filter
Kalman filtering can be described as: using the observation data vector \( y\left( 1 \right),y\left( 2 \right), \cdots y\left( n \right) \), the \( n \ge 1 \) of each component of the least squares estimation. Kalman prediction model is used to predict the travel time. First, establish the prediction model as follows:
Through the average travel time from any of \( (k,k - 1, \cdots k - n + 1) \) to predict the time of the vehicle during the \( k + 1 \) moment, this paper takes into account the specific situation of the traffic, and takes 4 times \( (k,k - 1,k - 2,k - 3) \) as the influencing factors on the prediction of the model as shown in (12):
In the formula, \( T\left( {k + 1} \right) \) is the prediction of the travel time of the road section; \( H_{i} \left( k \right)\left( {i = 0,1,2,3} \right) \) is the system parameter matrix; \( w\left( k \right) \) is the zero mean white noise, which indicates the system observation noise, and the covariance matrix is \( R\left( k \right) \). Define the state vector (13):
The formula (12) can be transformed into the state equation and observation equation of the Kalman system, such as formula (14):
In the formula, \( x\left( k \right) \) is the state vector; \( y\left( k \right) \) is the observation vector; \( \varphi \left( {k,k - 1} \right) \) is a state transition matrix; \( u\left( {k - 1} \right) \) is the process noise, and the covariance matrix is \( Q\left( {k - 1} \right) \);\( w\left( k \right) \) is the observation noise, and the covariance matrix is \( R\left( k \right) \);\( u\left( {k - 1} \right) \) and \( w\left( k \right) \) are uncorrelated zero mean white noise.
By calculating, we can get the prediction value of the travel time of the next section of the road, as shown in Eq. (15).
2.3 Dynamic Prediction Model Based on SVM-Kalman Filtering
The influence factors of road travel time are very complex, including the weather, the vehicle running time, intersection delay, road conditions, and other emergency situations, which may lead to the nonlinear variation of travel time.
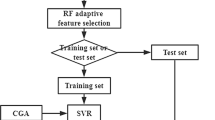
The SVM model has a strong nonlinear prediction ability and can be applied to the prediction of the model, while the real-time performance of the Kalman filter can make up the defect very well that SVM can’t effectively reflect the real time prediction (Fig. 1).

Dynamic prediction model based on SVM-Kalman filter.
The dynamic model is a combination of static and dynamic adjustment. The support vector machine (SVM) is used as the basis of forecasting, which is off-line prediction. The trained support vector machine maps out the road travel time to be predicted from a large number of historical data. However, the SVM model can’t effectively adjust the emergency, so this paper introduces the Kalman filter dynamic algorithm as the model. The link travel time predicted by support vector machine is used as the initial travel time, and then the initial travel time matrix is input to the Kalman filter to dynamically adjust the results.
The Kalman filter dynamic algorithm uses the update equation to add the latest observations into the prediction vector, which will effectively improve the prediction accuracy of the dynamic model.
The specific steps by using this model are shown as follows:
-
(1)
According to the principle of support vector machine and the influence factors of travel time, each division of the line will travel the whole line which is divided into n sub sections, with each of the two adjacent partition points away for a sub section;
-
(2)
Select the support vector machine type, kernel function and loss function. This model regards the SVM-support vector regression as the basic algorithm, with Gauss RBF kernel function, the epsilon insensitive loss function as the loss function;
-
(3)
The data are divided into two parts: the first part is for the training matrix, comprehensive training model to support vector regression; the other is for prediction matrix to the prediction and test results, the same training matrix and prediction matrix format;
-
(4)
Through cross validation to determine the parameters of support vector regression optimization, use the training matrix according to optimized parameters of support vector machine for training, and the trained support vector machine regression to predict the initial travel time;
-
(5)
The initial travel time matrix is input into the Kalman filter, and the results are adjusted dynamically.
3 Experimental Results and Analysis
3.1 Evaluating Indicator
In order to determine the SVM-Kalman filtering dynamic model, single SVM model, using two kinds of evaluation index below the forecast results for evaluation: mean absolute error, MAE, mean absolute percentage error, MAPE root mean square error, RMSE. The formula is shown in formula (16).
3.2 Data Acquisition
Two sets of road speed and volume data were adopted in this study (Table 1). To achieve a better performance, the road traffic state data under the same running mode were extracted for training and prediction. The road traffic speed and volume data captured on June 15 and 16, 2011 were extracted as historical road traffic state data to train optimal parameters. The road traffic speed and volume data captured on June 22, and 23, 2011 were extracted to make a road traffic state prediction. June 15 and 22 were Wednesday, June 16 and 23 were Thursday. Therefore, we used the training parameters based on the data of June 15 and 16 to predict in real time the road traffic speed and volume values of June 22 and 23.
The traffic speed and volume data collection interval was 2 min.
3.3 Analysis of Experimental Results
From Figs. 2, 3, 4 and 5 and Tables 2, 3, 4 and 5, we see that:

Speed prediction results of LB1170a on June 22(a), 23(b)

Speed prediction results of LB3750d on June 22(c), 23(d)

Volume prediction results of LB1170a on June 22(a), 23(b)

Volume prediction results of LB3750d on June 22(a), 23(b)
-
(1)
The road traffic state (speed and volume) predictions based on the SVM–Kalman model are superior to those according to other two algorithms. From Figs. 2, 3, 4 and 5, the accuracy and stability of speed and volume predicted based on the SVM–Kalman model are superior to those based on the other two algorithms for all the segments. We find that for all experiment road segments, the accuracy and stability of speed and volume predicted based on the SVM–Kalman model are superior to those based on the pure ARIMA model and Kalman filter. The stability of speed and volume predicted based on the SVM–Kalman model is inferior to that from expectation maximization. Tables 2, 3, 4 and 5 shows that the SVM–Kalman model is strikingly superior to the pure ARIMA model.
-
(2)
The accuracy of speed prediction is higher than that of volume prediction. The regularity of the change in volume is determined mainly by the regularity of people’s travel origin-destination (OD). However, for different dates, people’s travel OD changes randomly. So, the regularity of change in volume has a certain random property. The regularity of change in speed is affected not only by the regularity of people’s OD travel but also by the running status of road infrastructure. Thus, the change in speed shows high regularity. The accuracy of speed is consequently higher than that of volume when they are estimated on the basis the other guaranty of road traffic.
-
(3)
There are still some errors in predicting road traffic states using this algorithm. There are two main reasons for these errors:
-
(a)
Obtaining the corresponding road traffic states with a perfect match based on the SVM–Kalman model is difficult, because of the limitations of the road traffic running characteristics.
-
(b)
The parameters exhibit a certain deviation. Determining the optimal parameters is irregular, because they vary for different road traffic state data sets. The selected optimal parameters are determined based on historical road traffic state data. Therefore, the current optimal parameters maybe different from the historical optimal parameters.
-
(a)
4 Conclusions
Three conclusions can be drawn by comparing the real-time prediction analysis results of the SVM–Kalman model with those from the pure ARIMA model, the Kalman filter.
-
(1)
The mean absolute relative prediction error of speed data based on the proposed algorithm is lower than those of the pure ARIMA model and the Kalman filter, indicating that the proposed algorithm has a higher accuracy.
-
(2)
According to the maximum absolute relative error of the prediction, traffic state prediction based on the SVM–Kalman model performs admirably in tracking trends in the variation of the traffic state. The mean relative error sum of squares signifies that the proposed algorithm is more stable than the pure and Kalman filter.
-
(3)
The proposed algorithm is easy to implement on a computer, and is suitable for online prediction of the road traffic state, because it has fewer variable types and dynamic cumulative values compared with SVM–Kalman methods. Considering the remarkable performance of the proposed algorithm, we will explore traffic state prediction based on spatial–temporal correlations in our next research.
References
Deb Nath, R.P., Lee, H.-J., Chowdhury, N.K., Chang, J.-W.: Modified K-means clustering for travel time prediction based on historical traffic data. In: Setchi, R., Jordanov, I., Howlett, Robert J., Jain, Lakhmi C. (eds.) KES 2010. LNCS (LNAI), vol. 6276, pp. 511–521. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15387-7_55
Chowdhury, N.K., Nath, R.P.D., Lee, H., Chang, J.: Development of an effective travel time prediction method using modified moving average approach. In: Velásquez, Juan D., Ríos, Sebastián A., Howlett, Robert J., Jain, Lakhmi C. (eds.) KES 2009. LNCS (LNAI), vol. 5711, pp. 130–138. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04595-0_16
Chang, J., Chowdhury, N.K., Lee, H.: New travel time prediction algorithms for intelligent transportation systems. J. Intell. Fuzzy Syst. 21(1, 2), 5–7 (2010)
Chien, S.I.J., Kuchipudi, C.M.: Dynamic travel time prediction with real-time and historic data. J. Transp. Eng. 129(6), 608–616 (2003)
Tu, J., Li, Y., Liu, C.: A vehicle traveling time prediction method based on grey theory and linear regression analysis. J. Shanghai Jiaotong Univ. (Science) 14(4), 486–489 (2009)
Zhu, Y., Cao, Y.R., Du, S.: Travel time statistical analysis and prediction for the urban freeway. J. Transp. Syst. Eng. Inf. Technol. 7(1), 93–98 (2009)
Yang, Z.S., Bao, L.X., Zhu, G.H.: An urban express travel time prediction model based on fuzzy regression. J. Highway Transp. Res. Dev. 21(3), 78–81 (2004)
Yang, Z.S., Dong, S., Li, S.M., et al.: Traffic travel time forecast based on pattern match of occupancy date. In: Proceedings of the 2006 Annual Meeting of ITS, pp. 231–233 (2006)
Wen, X.S.: Pattern Recognition and Condition Monitoring. Science Press, Beijing (2007)
Yang, H., Zhu, Y.S.: Parameters selection method for support vector machine regression. Comput. Eng. 35(13), 218–220 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Qin, P., Xu, Z., Yang, W., Liu, G. (2018). Real-Time Road Traffic State Prediction Based on SVM and Kalman Filter. In: Li, J., et al. Wireless Sensor Networks. CWSN 2017. Communications in Computer and Information Science, vol 812. Springer, Singapore. https://doi.org/10.1007/978-981-10-8123-1_23
Download citation
DOI: https://doi.org/10.1007/978-981-10-8123-1_23
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-8122-4
Online ISBN: 978-981-10-8123-1
eBook Packages: Computer ScienceComputer Science (R0)