
Abstract
Automatic speaker recognition (ASR) is one type of biometric recognition of human, known as voice biometric recognition. Among plenty of acoustic features, Mel-Frequency Cepstral Coefficients (MFCCs) and Gammatone Frequency Cepstral Coefficients (GFCCs) are used popularly in ASR. The state-of-the-art techniques for modeling/classification(s) are Vector Quantization (VQ), Gaussian Mixture Models (GMMs), Hidden Markov Model (HMM), Artificial Neural Network (ANN), Deep Neural Network (DNN). In this paper, we cite our experimental results upon three databases, namely Hyke-2011, ELSDSR, and IITG-MV SR Phase-I, based on MFCCs and VQ/GMM where maximum log-likelihood (MLL) scoring technique is used for the recognition of speakers and analyzed the effect of Gaussian components as well as Mel-scale filter bank’s minimum frequency. By adjusting proper Gaussian components and minimum frequency, the accuracies have been increased by 10–20% in noisy environment.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
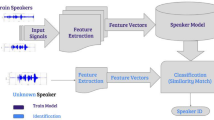
Automatic speaker recognition (ASR) system was first introduced by Pruzansky et al. [7]. There are two primary tasks within the speaker recognition (SR), namely speaker identification (SI) and speaker verification (SV). This paper concerns with SI and we have used the terms SI and SR synonymously. A general block diagram for SI and SV is shown in Fig. 1a. The SR can also be classified as text-dependent and text-independent recognition and further divided into open-set and closed-set identification.

Block diagram a for SR and b for MFCC feature extraction
An immense number of features are invented, but at present day the features that are popularly used for robust SR are Linear Predictive Cepstral Coefficient (LPCC) and Perceptual Linear Predictive Cepstral Coefficient (PLPCC) [9], Gammatone Frequency Cepstral Coefficient (GFCC) [11], Mel-Frequency Cepstral Coefficient (MFCC), combination of MFCC and phase information [6], Modified Group Delay Feature (MODGDF) [5], Mel Filter Bank Energy-Based Slope Feature [4], i-Vector [3], Bottleneck Feature of DNN (BF-DNN). In some cases to increase robustness, combined features are developed by fusion of some of these robust features. Some of combined features are LPCC+MFCC, MFCC+GFCC, PLPCC+MFCC+GFCC. The state-of-the-art methods for modeling/classification are Vector Quantization (VQ) [10], Hidden Markov Model (HMM), Gaussian Mixture Model (GMM) [8], GMM-Universal Background Model (GMM-UBM) [1], Support Vector Machine (SVM), Deep Neural Network (DNN) and hybrid models like VQ/GMM, SVM/GMM, HMM/GMM. Among these, the hybrid model HMM/GMM is very useful for SR in noisy environment because HMM isolates the speech feature vectors from the noisy feature vectors and then estimates the multivariate probability density function using GMM in the feature space.
2 Feature Extraction
The first step of SR is feature extraction, also known as front-end processing. It transforms(maps) the raw speech data into the featurespace. The features like MFCC and GFCC are computed using frequency domain analysis and Spectrogram. In our experiment, the MFCC feature is used for SR. The block diagram for extracting MFCC feature is shown in Fig. 1b. The computation of MFCC is discussed briefly as follows:
Pre-emphasis: The speech signal is passed through a HPF to increase the amplitude of high frequency. If s(n) is the speech signal, then it is implemented as \(\tilde{s}(n) = s(n)-\alpha s(n)\), where \(0.9<\alpha <1.\) Generally, the typical value of \(\alpha \) is 0.97.
Framing: To compute MFCC, short time processing of speech signal is required. The whole speech signal is broken into overlapping frames. Typically, 25–60 ms frame is chosen with the overlap of 15–45 ms.
Window: For Short Time Fourier Transform (STFT) for x(n), where x(n) be a short time frame, we must choose a window function h(n). A typical window function h(n) is given by
where N is the window length. Here, \(\beta = 0.54\) for Hamming window and \(\beta = 0.5\) for Hanning window.
DFT and FFT: The Discrete Fourier Transform (DFT) for the windowed signal is computed as \(X(\omega ,n) = \sum _{m=-\infty }^{\infty }x(m)h(n-m)e^{-j\omega n}, ~where~ 0 \le n \le N\). For discrete STFT, continuous \(X(\omega ,n)\) is sampled with N (length of windowed signal) equal points in frequency (\(\omega \)) as \(X(k,n)= X(k) = X(\omega ,n)|_{\omega = \frac{2 \pi }{N}k}, ~where~ 0 \le k \le N\). The graphical display of |X(k, n)| as color intensity is known as Spectrogram. Fortunately, two previous equations can be simplified with the help of Fast Fourier Transform (FFT) as \(X(k) = \mathcal {FFT}\{x(n)h(n)\}, where~ 0 \le k \le N\). To facilitate FFT, we must make N as power of 2. To do so, it is required to pad zeros with the frame to make frame length a nearest power of 2 if N is not a power of 2, otherwise zero padding is not required.
Magnitude Spectrum: The squared magnitude spectrum is computed as \(S(k) = |X(k)|^2\), where \(0 \le k \le N\)
Mel-Scale Filter Bank: In Mel scale, \(n_B\) number of overlapping triangular filters are set between \(M(f_{min})\) and \(M(f_{max)}\) to form a filter bank. The relation between Mel scale (mel) and Linear scale (Hz) is given by
where f in Hz and M(f) in mel. A filter in filter bank is characterized by start, center, and end frequencies, i.e., \(M(f_s)\), \(M(f_c)\), and end \(M(f_e)\), respectively. Using inverse operation of (2), we can compute \(f_s\), \(f_c\), and \(f_e\) using the following equation:
where f in Hz and M(f) in mel. Next, we map the frequencies \(f_s\), \(f_c\), and \(f_e\) to the corresponding nearest FFT index numbers given by \(f_{bin}^s\), \(f_{bin}^c\), and \(f_{bin}^e\), respectively, which are called FFT bins by using the following equation:
Here, \(F_s\) is the sampling frequency of the speech signal. The filter weight is maximum at center bin \(f_{bin}^c\) which is 1, and zero weight is assumed at start and end bins, \(f_{bin}^s\) and \(f_{bin}^e\). The weights are calculated as follows:
Filter Energy: The filter bank is set over the squared magnitude spectrum S(k). For each filter in the filter bank, the filter weight is multiplied with the corresponding S(k) and summed up all the products to get the filter energy, denoted by \(\{\tilde{S}(k)\}_{k=1}^{k=n_B}\). Taking logarithm, we get log energies, \(\{log(\tilde{S}(k)\}_{k=1}^{k=n_B}\).
DCT: To perform Discrete Cosine Transform (DCT), the following operation is carried out.
Here, \(D=n_B\) is the dimension of the vector \(C_n\) which is called MFCC vector.
3 Speaker Model
The models that are used frequently in SR are Linear Discriminative Analysis (LDA), Probabilistic LDA (PLDA), Gaussian Mixture Model (GMM), GMM-Universal Background Model (GMM-UBM), Hidden Markov Model (HMM), Artificial Neural Network (ANN), Deep Neural Network (DNN), Vector Quantization, Dynamic Time Warping (DTW), Support Vector Machine (SVM). GMM is the most popular model used in SR. These models are used to build speaker templates. Score domain compensation aims to remove handset-dependent biases from the likelihood ratio scores. The most prevalent methods include H-norm, Z-norm, and T-norm.
3.1 Vector Quantization (VQ)
It is used as a preliminary method for clustering data, so that the process of Vector Quantization(VQ) can be applied more suitably. The grouping is done by minimizing Euclidean distance between vectors. If we get V number of vectors after the feature extraction phase, then after VQ we will get K vectors where K < V. This set of K vectors is called codebook which represents the set of centroids of the individual clusters. In the modeling section, the GMM model is built upon these K vectors.
3.2 Gaussian Mixture Model (GMM)
Let for \(j\mathrm{{th}}\) speaker there are K number of quantized feature vectors of dimension D, viz. \({\mathcal {X}}\) = \( \{ \varvec{x_t} \in \mathbb {R}^D : 1 \le t \le K \}\). The GMM for \(j\mathrm{{th}}\) speaker, \(\lambda _j\), is the weighted sum of M component D-variate Gaussian densities where mixture weights \(w_i ~\{i=1 ~to~M\}\) must satisfy \(\sum _{i=1}^{M} w_i = 1\). Hence, the GMM model \(\lambda _j\) is given by \(p(\varvec{x_t} | \lambda _j) = \sum _{i=1}^{M}w_i \mathcal {N}(\varvec{x}_t; \varvec{\mu _i},{{\varvec{\varSigma }}_i})\) where \(\mathcal {N}\) (\(\varvec{x}_t\); \(\varvec{\mu _i}\),\({{\varvec{\varSigma }}_i}\)) \(\{i=1 ~to~M\}\) are D-variate Gaussian density functions given by

with mean vector \(\varvec{\mu }_i\) \(\in \) \(\mathbb {R}^D\) and covariance matrix \({\varvec{\varSigma }}_i\) \(\in \) \(\mathbb {R}^{D \times D}\). (\(\varvec{x}_t\) - \(\varvec{\mu }_i)'\) represents the transpose of vector (\(\varvec{x}_t\) - \(\varvec{\mu }_i\)). The GMM model for \(j\mathrm{{th}}\) speaker \({\lambda _j}\) is parameterized by weight \({w_i}\), mean vector \(\varvec{\mu }_i\), and covariance matrix \({ {\varvec{\varSigma }}_i}\). Hence, \( {\lambda }_j = \{w_i,\varvec{\mu }_i,{{\varvec{\varSigma }}}_i \}\).

A block diagram of GMM
These three parameters are computed with the help of EM algorithm. In the beginning of the EM iteration, the three parameters are required to initialize per Gaussian component. Initialization could be absolutely random, but in order to converge faster one can use k-means clustering algorithm also. A block diagram for GMM is shown in Fig. 2.
3.2.1 Maximum Likelihood (ML) Parameter Estimation (MLE):
The aim of the EM algorithm is to re-estimate the parameters after initialization, which give the maximum likelihood (ML) value given by
The EM algorithm begins with an initial model \(\lambda _0\) and re-estimate a new model \(\lambda \) in such a way that it always provides a new \(\lambda \) for which \(p(\mathcal {X}|\lambda ) \ge p(\mathcal {X}|\lambda _0)\).
To estimate the model parameters, mean vector \({\varvec{\mu }}_i\) is initialized using k-means clustering algorithm and this mean vector is used to initialize covariance matrix \({\varvec{\varSigma }}_i\). \({w_i}\) is assumed to 1 / M as its initial value. In each EM iteration, three parameters are re-estimated according to the following three equations to get the new model \(\lambda _{new}\).
The iteration continues until a suitable convergence criteria holds. For the covariance matrix \({\varvec{\varSigma }}_i\), only diagonal elements are taken and all off-diagonal elements are set to zero. The probability \(\mathcal P(i|\varvec{x}_t, \lambda _j)\) is given by
4 Speaker Identification with MLL Score
Let there are S speakers \(\mathcal {S}\) = {1, 2, 3, ........., S} and they are represented by the GMM’s \(\lambda _1\), \(\lambda _2\), \(\lambda _3\),......, \(\lambda _S\). Now, the task is to find the speaker model with the maximum posteriori probability for the set of feature vectors \(\mathcal {X}\) of test speaker. Using minimum error Bayes’ decision rule, the identified speaker is given by
Here, \(\hat{S}\) is the identified speaker and \(k\mathrm{{th}}\) speaker’s log-likelihood (LL) score is given by \(\sum _{t=1}^{K}log(p(\varvec{x}_t|\lambda _k))\) [8]. The identified speaker \(\hat{S}\) has the maximum log-likelihood (MLL) score.
5 Experimental Results and Discussion
We conducted the SR experiment extensively over the three databases, namely IITG Multi-Variability Speaker Recognition Database (IITG-MV SR), ELSDSR, and Hyke-2011. The IITG-MV SR database contains recorded speech from five recording devices, namely digital recorder (D01), Headset (H01), Tablet PC (T01), Nokia 5130c mobile (M01), and Sony Ericsson W350i mobile (M02), in noisy environment. However, ELSDSR and Hyke-2011 contain clean speech; i.e., noise level is very low and the speeches are recorded with a microphone. The sampling frequency for D01, H01, T01 is 16 kHz, for M01, M02 is 8 kHz, and for ELSDSR, Hyke-2011 is 8 kHz. We chose frame size about 25 ms and overlap about 17 ms, i.e., frameshift is \((25-17)=8\) ms for 16 kHz speech signal and 50 ms frame size and about 34 ms overlap; i.e., frameshift is \((50-34)=16\) ms for 8 kHz speech signal. The pre-emphasis factor \(\alpha \) is set to 0.97. To compute FFT 512-point, FFT algorithm is used. For mel-scale frequency conversion, maximum and minimum linear frequencies are \(f_{min} = 0, 300\) Hz and \(f_{max} = 5000\) Hz. The frequency, \(f_{min}\), has significant effect on the accuracy of ASR. Number of triangular filters in filter bank is \(n_B = 26\) which produces 26 MFC coefficients, and among them first 13 MFCC are chosen to create MFCC feature vector of dimension \(D=13\). The accuracy rate for the mentioned databases is shown in Table 1. In VQ, we consider 512 clusters, to reduce large number of vectors, upon which GMM is built using 5 EM iteration.
It is clearly shown that the accuracy rate is low for noisy speech as compared to the clean speech. This is because the noise level distorts the frequency spectrum of the signal considerably and vectors in the feature space are shifted and distorted from the original vectors. All the databases show the highest accuracy with vector dimension equal to 13, no. of Gaussian components equal to 32, and accuracy degrades beyond this limits. Another observation is that the bandwidth of the filters in the filter bank in linear scale (Hz) also influences the accuracy rate. The SR under mismatch and reverberant conditions are more challenging tasks, because in these cases, performance of SR system degrades drastically. Other important issues for SR are language dependency and device mismatch. It has been seen that the accuracy rate degrades if there is a mismatch of language between training and testing data. Specially, for the device mismatch between training and testing data, the accuracy rate degrades drastically. Though GMM shows satisfactory accuracy rate, HMM is more robust than GMM and provides better result in environmental mismatch . Hybrid HMM/GMM-based SR in noisy environment performs better than only GMM-based SR. In noisy environment, the accuracy of GMM-based SR degrades more rapidly than the HMM/GMM-based SR.
6 Conclusion
SR has a very close relation with the speech recognition. Emotion extraction from speech data using corpus-based feature and sentiment orientation technique could be thought of as an extension of SR experiment [2]. In this paper, we cite SR experiment and analyze feature extraction and modeling/classification steps. It is very important to mention that number of GMM components and Mel filter bank’s minimum frequency \(f_{min}\) have significant influence on the recognition accuracy. Since there are sufficient differences in accuracies between clean speech data and noisy speech data, we can infer that noise level shifts the data from its true orientation. Various normalization techniques in feature domain and modeling/classification domain could be applied to combat with the unwanted shift of data in feature space. Indeed, before transforming data into feature space various filtering techniques to reduce the effect of noise are also available.
References
Campbell, W.M., Sturim, D.E., Reynolds, D.A.: Support vector machines using gmm supervectors for speaker verification. IEEE Signal Process. Lett. 13(5), 308–311 (2006)
Jain, V.K., Kumar, S., Fernandes, S.L.: Extraction of emotions from multilingual text using intelligent text processing and computational linguistics. J. Comput. Sci. (2017)
Kanagasundaram, A., Vogt, R., Dean, D.B., Sridharan, S., Mason, M.W.: I-vector based speaker recognition on short utterances. In: Proceedings of the 12th Annual Conference of the International Speech Communication Association, pp. 2341–2344. International Speech Communication Association (ISCA) (2011)
Madikeri, S.R., Murthy, H.A.: Mel filter bank energy-based slope feature and its application to speaker recognition. In: Communications (NCC), 2011 National Conference on, pp. 1–4. IEEE (2011)
Murthy, H.A., Yegnanarayana, B.: Group delay functions and its applications in speech technology. Sadhana 36(5), 745–782 (2011)
Nakagawa, S., Wang, L., Ohtsuka, S.: Speaker identification and verification by combining MFCC and phase information. IEEE Trans. Audio Speech Lang. Process. 20(4), 1085–1095 (2012)
Pruzansky, S.: Pattern-matching procedure for automatic talker recognition. J. Acoust. Soc. Am. 35(3), 354–358 (1963)
Reynolds, D.A., Rose, R.C.: Robust text-independent speaker identification using gaussian mixture speaker models. IEEE Trans. Speech Audio Process. 3(1), 72–83 (1995)
Sapijaszko, G.I., Mikhael, W.B.: An overview of recent window based feature extraction algorithms for speaker recognition. In: Circuits and Systems (MWSCAS), 2012 IEEE 55th International Midwest Symposium on, pp. 880–883. IEEE (2012)
Soong, F.K., Rosenberg, A.E., Juang, B.H., Rabiner, L.R.: Report: a vector quantization approach to speaker recognition. AT&T Techn. J. 66(2), 14–26 (1987)
Zhao, X., Wang, D.: Analyzing noise robustness of MFCC and GFCC features in speaker identification. In: Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, pp. 7204–7208. IEEE (2013)
Acknowledgements
This project is partially supported by the CMATER laboratory of the Computer Science and Engineering Department, Jadavpur University, India, TEQIP-II, PURSE-II, and UPE-II projects of Government of India. Subhadip Basu is partially supported by the Research Award (F.30-31/2016(SA-II)) from UGC, Government of India. Bidhan Barai is partially supported by the RGNF Research Award (F1-17.1/2014-15/RGNF-2014-15-SC-WES-67459/(SA-III)) from UGC, Government of India.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Barai, B., Das, D., Das, N., Basu, S., Nasipuri, M. (2018). Closed-Set Text-Independent Automatic Speaker Recognition System Using VQ/GMM. In: Bhateja, V., Coello Coello, C., Satapathy, S., Pattnaik, P. (eds) Intelligent Engineering Informatics. Advances in Intelligent Systems and Computing, vol 695. Springer, Singapore. https://doi.org/10.1007/978-981-10-7566-7_33
Download citation
DOI: https://doi.org/10.1007/978-981-10-7566-7_33
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7565-0
Online ISBN: 978-981-10-7566-7
eBook Packages: EngineeringEngineering (R0)