
Abstract
Population studies worldwide have suggested that urban population densities generally follow an exponential decay pattern as one travels outwards from the central business district (CBD). Dhaka has experienced phenomenal population growth over the past two decades. This chapter uses econometric and GIS techniques to map and model recent population dynamics using census data for three successive census years (1991, 2001 and 2011) aggregated at the lowest level of census geography. Linear and non-linear regression models were tested to examine urban density form. The study found that a negative exponential function was best suited for the study area since it produced the highest coefficient of determination (R 2). Additionally, temporal trends of the population density gradient for the study area revealed gradual flattening. Further, it was found that the y-axis intercept (an indicator of CBD density) did not drop over time as general theories for cities experiencing economic growth would suggest. The visualisation of population change was conducted through standard deviational ellipses and simple spatial analysis. The results revealed that, with the exception of a few census tracts, the magnitude of population change is (are) still high in the area, and that a suburbanisation trend has set in over the period since the penultimate census.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others
Keywords
3.1 Introduction
The spatial distribution of human population is a key factor in assessing the causes and impacts of global environmental change (Tian et al. 2005; Elvidge et al. 1997). Accurate and timely information on the variation of population distribution both within and between urban areas is crucial for a number of social, economic and environmental applications (Liu et al. 2008; Sutton 1997). The analysis of population distribution can support planners and policy makers in identifying impacts related to social and environmental functionality of the city (Millward and Bunting 2008) and subsequently assist in formulating relevant policy measures. The density and spatial patterning of human population has, therefore, been a subject of academic research in a number of disciplines for many years (Fonseca and Wong 2000).
Geospatial techniques have been extensively used in estimating population in urban areas around the world, as is shown by a recent review of the topic (Patino and Duque 2013). Whilst remotely sensed data has been used to estimate population which can then be correlated with census or ground-based measurement through regression techniques (Wu et al. 2005), Geographic Information Systems (GIS), on the other hand, are used to illustrate the spatial patterning of population via spatial analysis. The major objective of GIS-based population study is to examine urban density gradients and to capture urban spatial structuring with econometric and spatial analyses following the pioneering work of Clark (1951). The basic premise of Clark’s work is that density in urban areas declines, in a negative exponential manner, with the improvement of transportation and communication over time. Thus, urban population distribution reduces with distance from a central point and flattens with time as people become vehicle dependent. Inspired by Clark’s work, others have tested and refined his classic work to examine the geographical distribution of population and employment density in urban areas over time. For example, Newling (1969) conceptualised four stages of density gradients as youth, early maturity, late maturity and old age. Batty and Kim (1992) argued that an inverse power function is the most appropriate to model urban population density, whilst Parr (1985) suggested that an inverse power function is more appropriate to the urban fringe and hinterland, with a negative exponential function being more suitable for explaining density in an urban area. Nonetheless, the goodness of fit varies according to the place studied (Wu et al. 2005).
Of the studies that use econometric and spatial analytical techniques to model and map urban population distribution, most are from developed countries with only a few from developing countries (Feng et al. 2009; Suárez and Delgado 2009; Millward and Bunting 2008; Griffith and Wong 2007; Mennis 2003; Wang and Zhou 1999; Wang and Meng 1999; Sutton 1997; Martin 1996, 1989; Gordon et al. 1986; Alperovich 1982; Griffiths 1981; Krakover 1985; Berry and Kasarda 1977; Newling 1969). The majority of studies look at one of two density function approaches, monocentric models and polycentric models. The monocentric model investigates how density varies with distance within an urban area with an assumption that a city has only one centre (e.g. central business district) in which population and economic activities are concentrated, whilst the latter model assumes that a city has a number of sub-centres other than the city centre and urban residents have access to all centres. Thus, population densities are functions of distances to all these centres (Small and Song 1994). As noted by Wang and Meng (1999), the polycentric model examines the influence of each sub-centre on the distribution of urban population in a given area. A somewhat differing result was reported by McMillen and McDonald (1997) in their study on Chicago’s employment density, suggesting bicentric density patterns. By contrast, McDonald (1989) reviewed urban density studies and made two general findings: (1) that the density gradients flatten over time and (2) the rate of flattening of the density curve depends on the size of the urban area. Adam (1970) noted that the density pattern is related to the age of the city. In other words, older cities have a higher central density, whereas younger cities tend to be steeper in density gradients. Studies in developing countries yielded different results when compared to those from developed countries. For instance, Berry and Kasarda (1977) reported that, in Calcutta, the density gradient did not flatten over time and central density increased contemporaneously with expansion of urban areas. This result is contrary to findings from China which showed that Beijing’s density gradient flattened over time (Wang and Zhou 1999), and attributed this to the polycentric nature of the city, which is partly the result of China’s reforms towards market economy (Feng et al. 2009). These two examples from China and India suggest that there is no clear pattern to the trends of urban population distribution in developing countries, whilst the results from developed countries are almost identical.
Since its independence from Pakistan in 1971, Bangladesh has experienced rapid growth in human population (see Chap. 1). This growth has impacted upon some cities more than others due mainly to the economic disparity between rural and urban areas (BBS 2010). As a result, there has been considerable conspicuous growth in the urban population, severely affecting the social and environmental sustainability of major cities, particularly the megacity of Dhaka. Siddiqui and his colleagues (2010) suggest that as a result of this rapid population growth, most of Dhaka, except for a few high-class residential areas, appears to be either slums or near-slums.
Despite the fact that population increase is an ever-present phenomenon in Bangladesh, research with respect to its distribution is mainly confined to temporal analysis (Rouf and Jahan 2007; Islam 2002; Khan and Rahman 2000; Eusuf 1996). Based on population and the rank-order method, Eusuf (1996), for instance, demonstrated the changing patterns of urban centres in Bangladesh between 1872 and 1991 which showed that both the number and size of urban centres in the country had increased noticeably as a function of population growth. Similarly, other researchers have also used change in population count in urban areas through time to demonstrate population increase in the cities, particularly in Dhaka (Rana 2011; Siddiqui et al. 2010; Islam 2009, 2005). The major objective of these temporal studies is to quantify the rate of urbanisation or urban growth of cities. Though these studies are useful for understanding population growth in urban areas over time, they lack the spatial component that is essential to predicting the environmental consequences of population growth in urban areas (Shoshany and Goldshleger 2002; Elvidge et al. 1997). Moreover, temporal studies alone are unable to examine the pattern of increase or decrease in population distribution. Since population is the primary factor that is driving urban expansion and environmental changes in Dhaka (Dewan et al. 2012), mapping and modelling of population distribution is of great importance to urban planners and policy makers who are often charged with monitoring urban growth and developing adequate land-use policies.
Although many studies of population distribution over space have been carried out to date, particularly in post-industrial cities, work is required to determine whether the urban density models found to be applicable in developed countries can also be applied to less developed countries, especially to cities with totally different population dynamics such as in Dhaka. This chapter seeks to better understand the population dynamics of Dhaka megacity through quantifying temporal changes in population density and exploring its spatial distribution across the study area (see Chap. 1). Of particular interest is the investigation of the well-established theory that population density is generally inversely related to distance from a city’s central business district (CBD).
3.2 Data and Methods
3.2.1 Data Preparation
The data used for the analysis consisted of both spatial and aspatial data. One of the biggest problems in working with spatially referenced data in Bangladesh is the unavailability of updated census boundary information, and even when available, they are often inaccessible to the public because of the so-called security concern of relevant organisations and the national government. Although, socioeconomic and demographic data from the census are available in tabular format, they are not accompanied by a spatial database such as the TIGER files in the USA. As a result, it is extremely difficult for anyone to study spatially referenced population distribution.
To overcome this, a spatial database of the census tracts was created by digitising the small area atlas of the Bangladesh Bureau of Statistics (BBS), with input from the digital database of SPARRSO, Center for Environmental and Geographic Information Services (CEGIS) and numerous field visits. It should be noted that neither of the databases contained up-to-date digital census tract boundaries, and around 2 % of the census tracts were missing. That is, 25 new census districts were created between the decennial censuses of 1991 and 2001. To overcome this problem, the names of the 1991 census tracts were first matched with the 2001 names using the BBS community series publications. The additional census polygons in the 2001 census are the result of subdivision, due to population increase, of polygons used in the previous census. To create the polygons for the 2001 census, the digitised polygon files were re-referenced to the street grid, which is an up-to-date street network from the Detailed Area Plan (DAP) of the Capital Development Authority (RAJUK). Census units created between 1991 and 2001 were then demarcated and mapped out in the field. This work was guided by a hard copy of a map which highlighted the road networks that were used to split the original census tracts into those use for the 2001 population census and was obtained from BBS. Additionally, a high-resolution mobile-mapping GPS device (Trimble Nomad 800GXE) was used to confirm the road locations. The editing of the census tracts was performed in ArcGIS (v. 10). The final census tract file consists of 1,212 polygon features, which include 441 rural communities (mauza) and 771 urban communities (mahalla) (Dewan 2013). Again between the 2001 and 2011 censuses, some of the census tracts were subdivided. Since no spatial data was available for these new tracts, the older geography (2001) was used and the demographics for the new constituent tracts were amalgamated.
Demographic attributes were obtained from the BBS community series (BBS 1993, 2003, 2012), which represent the population censuses of 1991, 2001 and 2011. These data were encoded in a spreadsheet because digital versions were not available for the 1991 and 2001 censuses, and then linked with the census tract boundary using a unique ID. Population density was calculated as the total number of people residing in a census tract divided by its total area (km2).
3.2.2 Modelling Urban Population Density
The central business district (CBD) is critical to population density modelling. In order to test different models of urban population on the data for Dhaka, the CBD had to be identified beforehand. With reference to previous research, Motijheel was chosen as the CBD since it has featured prominently in previous population-related studies of Dhaka (Barter 2012; Islam et al. 2009). Whilst some studies have used mathematical techniques to choose CBD (see Alperovich 1982), this research has opted to rely on expert knowledge instead. Using the Euclidean distance function within a GIS, distance to other areas was calculated, and four regression models, namely, linear, reverse exponential, negative exponential and power, were constructed to identify whether the urban density gradient is similar or dissimilar to that of other cities in the world. To minimise the impact of outliers on density gradient analysis, statistical outliers were removed from the data using the method proposed by Iglewicz and Hoaglin (1993) which detects outliers based on modified Z-score values, M i:
where MAD = median absolute deviation and \( \bar{x} \) = median. In this method, modified Z-scores with an absolute value of greater than 3.5 are considered outliers. For this study, the observations (x i) were the population densities for each of 3 years. Further, units with zero values of population density and the CBD itself were disregarded from the analysis. This was done to ensure that logarithmic models did not fail since the logarithm of zero is undefined. It was also thought unreasonable for an entire mahalla to have a population of zero. The following equations were used to derive an urban density gradient for the 3 years considered:
where r = distance from centre of urban area (km), b = slope and a = intercept.
where a = maximum population density (km−2), r = distance from centre of urban area and b = exponential decay coefficient or density gradient (km−1).
where r = distance from centre of urban area, ρ(r) = population density at distance r from CBD (km−2), a = intercept (population density (km−2) at distance zero from CBD) and b = growth/decay rate.
where r = distance from centre of urban area (km), a is the intercept and b(ln) = slope.
The linear and logarithmic models were estimated using ordinary least squares regression (OLS), whilst the negative exponential and power models were estimated using non-linear least squares (NLS) regression. The NLS approach ensured that the dependent variable (population density) was not log-transformed and remained the same in all cases hence making the different models comparable (Feng et al. 2009; Wang and Meng 1999). This technique is an extension of OLS which has the advantage of being able to fit a broad range of functions and the disadvantage of requiring iterative optimisation procedures to compute parameter estimates (NIST/SEMATECH 2003).
3.2.3 Mapping Population Distribution
To determine the distribution of population in the three census years, we first used the standard deviational ellipse to gain a better understanding of the geographical aspects of population. The standard deviational ellipse (SDE) examines the standard deviation of the features from the mean centre separately from the x-coordinates and the y-coordinates to define the axes of the ellipse (Mitchell 2005), and it is very useful to assess the orientation of a dataset (Wong and Lee 2005). Using population density as a weight field for each year, three weighted ellipses with a radius of one standard deviation were derived to identify those areas with the highest concentrations of population.
To map the magnitude of population change between the three census years, we considered the population count in each census tract. We then computed percentage of change for each tract for the periods of 1991–2001, 2001–2011 and 1991–2011. Next, the direction of change was labelled as positive or negative (depending on the sign of percentage population change values). Standardised Z-scores of the percentage change values were computed for the three periods. The scores were subsequently classified on the basis of their standard deviation. Finally, a series of change maps were produced to show the amount and direction of population change for each spatial unit. The maps measured change direction as negative and positive and magnitude of change as scaled values (1–4): 1 (Z-score <−1.96), 2 (Z-score between −1.96 and 0), 3 (Z-score between 0 and 1.96) and 4 (Z-score >1.96).
3.3 Results and Discussion
Table 3.1 shows the population characteristics in the study area. Census tracts have an average area of 0.72 km2, ranging from 0.001 to 11.05 km2. The population shows an increasing trend, suggesting that the highest population of a census tract was 72,836 in 1991 which grew 174,048 in 2011, an increase of 101,212 within 20 years time. Population density is also extreme in the study area which may be attributed to vertical expansion of the city in recent years. Another explanation could be the existence of slums in the many census tracts which are usually places of high density (CUS et al. 2006). The average size of the population is also increasing so as the average density (Table 3.1).
We fitted the monocentric density function using both linear and non-linear least square models after excluding zero-density spatial units and outliers. The best model was chosen as one with the highest overall R 2 value (Wang and Zhou 1999). It can be seen from the estimated models in Table 3.2 that the negative exponential function was dominant and therefore provided the best fit in all 3 years relative to the others. This finding is in agreement with Clark’s (1951) theory that urban population densities decay exponentially with increasing distance from the city centre. This finding is also in agreement with other studies in China (Feng et al. 2009; Wang an Meng 1999) but differs from the study of Calcutta (Berry and Kasarda 1977), another city in a developing country. As noted above, the model fit depends on the area being analysed. Additionally, the steady decline in the absolute value of the estimated density gradient parameter (b) of the negative exponential function in three census years confirms the econometric model that predicts flattening of population density gradients as cities grow and economies develop (McDonald 1989).
Whilst the steady decline in population density gradients over the three census years in the study area suggests the onset of suburbanisation, particularly very recently, it was also noticed that the model intercept (a) increased with every subsequent year. Since the model intercept predicts population density of the CBD, the data shows that the population density of the CBD has not yet peaked. Contrary to expectations, this research found that the y-axis intercept does not drop over time. This trend is peculiar since one would expect the density to fall in the presence of suburbanisation and economic growth. Since Dhaka is 400 years old, the increase in model intercept could be related to age of the city (Adam 1970). However, we do not have a method to justify this claim. Further study is, therefore, needed to examine this phenomenon.
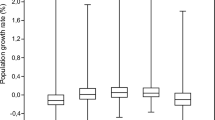
As shown in Table 3.1, a noticeable feature is that the density per unit area is increasing with time. For instance, the highest density was 170,692 persons/km2 in 1991 which rose to 177,434 and 179,215 in 2001 and 2011, respectively. Note that the density gradually reduces away from the city centre, suggesting horizontal dispersal since 2001, but the rate appears to be very slow. As low-lying flood-prone areas surround the main part of Dhaka, this may have influenced the geographic distribution of population. Further grouping of density by distance category shows that the population density is highest between 0 and 5 km from the CBD and it is still rising (Fig. 3.1). A reasonable explanation is that the concentration of educational and administrative organisations and economic activities is very high in this zone compared to other distance categories. In 1991, the density of the 0–5 distance category was 27,912 persons/km2 (aggregated) which increased to 38,094 and 47,522 in 2001 and 2011, respectively, revealing that the consolidation of old core areas (known as Old Dhaka) is still continuing (see Chap. 2).

Density of population between 1991 and 2011, by distance category
The second highest density by distance measure can be found between 5 and 10 km from CBD (Fig. 3.1). Instead of decreasing in density, especially at the city centre, the result showed that the rate of increase in aggregated population density is increasing with each 5 km increment from the CBD. This trend became highly pronounced in 2011, which is clearly linked with the population pressure in Dhaka.
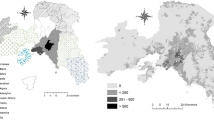
Three weighted standard deviational ellipses (SDE) have been derived for three census years and shown in Fig. 3.2a–c. These provide an overview of the standard deviation of the population distribution and the direction of the ellipses. It can be seen that the rotation of ellipses has increased between 1991 and 2011, suggesting the ellipses are becoming skewed towards the northwest-southeast. In addition, it gives an illustration of the location of the main population concentration which is in agreement with econometric analysis of population density function above. The same figure also shows three choropleth maps of total population according to census tracts, from which it is easily seen that the population concentration in the peripheral areas is increasing with time owing to the fact that there is little space left in the old core areas. However, this type of development is known to have serious implications for the environment as peripheral areas are mostly floodplain and wetlands in Dhaka (Dewan and Yamaguchi 2009a, b; 2008).

Population distribution and SDE in three census periods (a) 1991, (b) 2001, (c) 2011
The spatial distribution of population change is shown in Fig. 3.3. This indicates that most of the spatial units in the study area have registered population growth, whereas a few of them showed a decrease in total population. For example, in 2001 a total of 247 census tracts experienced decline in population relative to their 1991 population. Whilst a few census tracts located in the central part of the city registered decline in population in 2001, this number reduced by 2011. At the same time, the population in the peripheral areas increased between 2001 and 2011, indicating that the suburbanisation process is of relatively recent origin, but fairly slow. This might be attributed to the existence of flood-prone lands in the study area. Apart from that, land value and other factors such as accessibility to urban centres may have important roles to play in the spatial distribution of population (Dewan 2013).

Changes in population between 1991 and 2011, by census tracts
Although the change maps are useful for identifying the magnitude of population change, they are unable to show how fast this change has occurred over a specific period of time in a given spatial unit. To answer this question, a population change rate map was calculated for a 20-year period between 1991 and 2011 by subtracting the 1991 population in each census tract from the 2011 population and then dividing the derived value by 20 to get the population change each year. This map shows an average population change (decrease/increase) over 20-year period and useful to identify which areas grew rapidly and which slowly (Fig. 3.4). The result reveals that out of 1212 census tracts, 83.4 % tracts (1010) have registered an increase in population in terms of average population growth. However, a few of the census tracts adjacent to the CBD registered a decrease in average population in 20-year period as shown in the inset map of Fig. 3.4 (box).

Average change in population each year, 1991–2011
3.4 Conclusions
The objective of this chapter was to analyse changes in urban density gradient and spatial distribution of population. Using the census tract as the spatial unit of study, population data from the last three census years have been considered and analysed. Econometric modelling and spatial analysis techniques were used to map and model the population distribution within a GIS framework.
The results of this study corroborated many of the findings of previous research on the subject of urban population density functional forms. In addition, changes in population over time revealed that most of the census tracts have experienced population growth, indicating the ongoing pressure on land resources in the study area. The latest data from the 2011 population and housing census showed that the suburbanisation process has started, albeit at a slow rate. This can be attributed jointly to ever-increasing population combined with recent improvement of transport arteries and the fact that the inner urban area is reaching saturation.
This study could be improved by investigating the polycentric model theory as the monocentric model is unable to accurately estimate population in peripheral areas. We also acknowledge that availability of spatial data for the subdivided census tracts used in 2011 would help to improve this study.
References
Adam JS (1970) Residential structure of Midwestern city. Ann Assoc Am Geogr 60(1):32–62
Alperovich G (1982) Density gradients and the identification of the central business district. Urban Stud 19(3):313–320
Bangladesh Bureau of Statistics (BBS) (1993) Population census – 2001, Community series, Dhaka, Gazipur and Narayanganj. Bangladesh Bureau of Statistics, Ministry of Planning, Dhaka
Bangladesh Bureau of Statistics (BBS) (2003) Population census – 2001, Community series, Dhaka, Gazipur and Narayanganj. Bangladesh Bureau of Statistics, Ministry of Planning, Dhaka
Bangladesh Bureau of Statistics (BBS) (2010) Compendium of environment statistics of Bangladesh 2009. Bangladesh Bureau of Statistics, Ministry of Planning, Dhaka
Bangladesh Bureau of Statistics (BBS) (2012) Population and housing census – 2011, Community series, Dhaka, Gazipur and Narayanganj. Bangladesh Bureau of Statistics, Ministry of Planning, Dhaka
Barter PA (2012) Off-street parking policy surprises in Asian cities. Cities 29(1):23–31
Batty M, Kim KS (1992) Form follows function: reformulating urban population density functions. Urban Stud 29(7):1043–1070
Berry BJL, Kasarda J (1977) Contemporary urban ecology. McMillan, New York
Center for Urban Studies (CUS), National Institute of Population, Research and Training (NIPORT) and Measure Evaluation (2006) Slums in urban Bangladesh: mapping and census 2005. CUS, Dhaka
Clark C (1951) Urban population densities. J R Stat Soc A 114(4):490–496
Dewan AM (2013) Floods in a megacity: geospatial techniques in assessing hazards, risk and vulnerability. Springer, Dordrecht
Dewan AM, Yamaguchi Y (2008) Effects of land cover changes on flooding: example from Greater Dhaka of Bangladesh. Int J Geoinform 4(1):11–20
Dewan AM, Yamaguchi Y (2009a) Land use and land cover change in Greater Dhaka, Bangladesh: using remote sensing to promote sustainable urbanization. Appl Geogr 29(3):390–401
Dewan AM, Yamaguchi Y (2009b) Using remote sensing and GIS to detect and monitor land use and land cover change in Dhaka Metropolitan of Bangladesh during 1960–2005. Environ Monit Assess 150(1–4):237–249
Dewan AM, Kabir MH, Nahar K, Rahman MZ (2012) Urbanization and environmental degradation in Dhaka metropolitan area of Bangladesh. Int J Environ Sustain Dev 11(2):118–146
Elvidge CD, Baugh KE, Kihn EA, Kroehl HW, Davis ER (1997) Mapping city lights with nighttime data from the DMSP operational linescan system. Photogramm Eng Remote Sens 63(6):727–734
Eusuf AZ (1996) Urban centres in Bangladesh: their growth and change in rank-order. In: Islam N, Ahsan RM (eds) Urban Bangladesh: geographical studies. Department of Geography, University of Dhaka, Dhaka, pp 7–20
Feng J, Wang F, Zhou X (2009) The spatial restructuring of population in metropolitan Beijing: toward polycentricity in the post-reform era. Urban Geogr 30(7):779–802
Fonseca JW, Wong DWS (2000) Changing patterns of population density in the United States. Prof Geogr 52(3):504–517
Gordon P, Richardson H, Wong H (1986) The distribution of population and employment in a polycentric city: the case of Log Angeles. Environ Plann A 18(2):161–173
Griffith DA (1981) Modelling urban population density in a multi-centred city. J Urban Econ 9(3):298–310
Griffith DA, Wong DW (2007) Modeling population density across major US cities: a polycentric spatial regression approach. J Geogr Syst 9(1):53–75
Iglewicz B, Hoaglin D (1993) How to detect and handle outliers. In: Mykytka EF (ed) The ASQC basic references in quality control: statistical techniques. ASQC Quality Press, Milwaukee
Islam N (2002) Urbanization in Bangladesh: current trends. In: Islam N, Baqee A (eds) Nagarayane Bangladesh. Department of Geography and Environment, University of Dhaka, Dhaka, pp 13–24 (in Benagli)
Islam N (2005) Dhaka now: contemporary urban development, Golden Jubilee series no. 2. The Bangladesh Geographical Society (BGS), Dhaka
Islam N (2009) Dhaka in 2025 AD. In: Ahmed S (ed) Dhaka: past, present and future, 2nd edn. The Asiatic Society of Bangladesh, Dhaka, pp 608–621
Islam I, Sharmin M, Masud F, Moniruzzaman M (2009) Urban consolidation approach for Dhaka City: prospects and constraints. Glob Built Environ Rev 7(1):50–68
Khan JR, Rahman MR (2000) Urbanisation and the trend and spread of urban poverty: a study on Rajshahi city. In: Khan JR, Rumi SRA, Shaikh AH (eds) Geography of Bangladesh: selected articles. Department of Geography and Environmental Studies, University of Rajshahi, Rajshahi, pp 185–214
Krakover S (1985) Spatial-temporal structure of population growth in urban regions: the cases of Tel-Aviv and Haifa, Israel. Urban Stud 22(4):31–328
Liu XH, Kyriakidis PC, Goodchild MF (2008) Population-density estimation from using regression and area-to-point residual kriging. Int J Remote Sens 22(4):431–447
Martin D (1989) Mapping population data from zone centroid locations. Trans Inst Br Geogr 14(1):90–97
Martin D (1996) An assessment of surface and zonal models of population. Int J Geogr Inf Syst 10(8):973–989
McDonald JF (1989) Econometric studies of urban population density. J Urban Econ 26(3):361–385
McMillen DP, McDonald JF (1997) A nonparametric analysis of employment density in a polycentric city. J Reg Sci 37(4):592–612
Mennis J (2003) Generating surface models of population using dasymetric mapping. Prof Geogr 55(1):31–42
Millward H, Bunting T (2008) Patterning in urban population densities: a spatiotemporal model compared with Toronto 1971-2001. Environ Plann A 40(2):283–302
Mitchell A (2005) The Esri guide to GIS analysis, vol. 2: spatial measurements & statistics. Esri Press, Redlands
National Institute of Standards and Technology (NIST) and International SEMATECH (2003) Engineering statistics handbook, NIST/SEMATECH. Available at: NIST/SEMATECH e-Handbook of Statistical Methods, http://www.itl.nist.gov/div898/handbook/
Newling BE (1969) The spatial variation of urban population densities. Geogr Rev 59(2):242–252
Parr JB (1985) A population-density approach to regional spatial structure. Urban Stud 22(4):289–303
Patino JE, Duque JC (2013) A review of regional science applications of satellite remote sensing in urban settings. Comput Environ Urban Syst 37:1–17
Rana MMP (2011) Urbanization and sustainability: challenges and strategies for sustainable urban development in Bangladesh. Environ Dev Sustain 13(1):237–256
Rouf MA, Jahan S (2007) Spatial and temporal patterns of urbanization in Bangladesh. In: Jahan S, Maniruzzaman KM (eds) Urbanization in Bangladesh: patterns, issues and approaches to planning. Bangladesh Institute of Planners, Dhaka, pp 1–24
Shoshany M, Goldshleger N (2002) Land-use and population density changes in Israel – 1950 to 1990: analysis of regional and local trends. Land Use Policy 19(2):123–133
Siddiqui K, Ahmed J, Siddiqui K, Huq S, Hossain A, Nazimud-Doula S, Rezawana N (2010) Social formation in Dhaka, 1985–2005: a longitudinal study of society in a third world megacity. Ashgate Publishing Group, Surrey
Small KA, Song S (1994) Population and employment densities: structure and change. J Urban Econ 36(3):292–313
Suárez M, Delgado J (2009) Is Mexico city polycentric? A trip attraction capacity approach. Urban Stud 46(10):2187–2211
Sutton P (1997) Modelling population density with night-time satellite imagery and GIS, Computers. Environ Urban Syst 21(3/4):227–244
Tian Y, Yue T, Zhu L, Clinton N (2005) Modeling population density using land cover data. Ecol Model 189(1–2):72–88
Wang F, Meng Y (1999) Analysing urban population change patterns in Shenyang, China 1982-90: density function and spatial association approaches. Geogr Inf Sci 5(2):121–130
Wang F, Zhou Y (1999) Modelling urban population densities in Beijing 1982–90: suburbanization and its causes. Urban Stud 36(2):271–287
Wong DWS, Lee J (2005) Statistical analysis of geographic information with ArcView GIS and ArcGIS. Wiley, Hoboken
Wu S-S, Qiu X, Wang L (2005) Population estimation methods in GIS and remote sensing: a review. GISci Remote Sens 42(1):58–74
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer Science+Business Media Dordrecht
About this chapter
Cite this chapter
Corner, R.J., Ongee, E.T., Dewan, A.M. (2014). Spatiotemporal Patterns of Population Distribution. In: Dewan, A., Corner, R. (eds) Dhaka Megacity. Springer Geography. Springer, Dordrecht. https://doi.org/10.1007/978-94-007-6735-5_3
Download citation
DOI: https://doi.org/10.1007/978-94-007-6735-5_3
Published:
Publisher Name: Springer, Dordrecht
Print ISBN: 978-94-007-6734-8
Online ISBN: 978-94-007-6735-5
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)