
Abstract
We conducted experiments in Vietnamese villages to determine the predictors of risk and time preferences. In villages with higher mean income, people are less loss-averse and more patient. Household income is correlated with patience but not with risk. We expand measurements of risk and time preferences beyond expected utility and exponential discounting, replacing those models with prospect theory and a three-parameter hyperbolic discounting model. Comparable risk parameter estimates have been found for Chinese farmers, using our method.
The original article first appeared in the American Economic Review 100(1):557–571, 2010. A newly written addendum has been added to this book chapter.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
A fundamental question in development economics is the extent to which economic success is linked to basic features of human preferences. If people are extremely averse to financial risk, they may be reluctant to create businesses that may have inherently risky cash flows. If people are impatient, they may be reluctant to invest and educate their children. Taken together, risk-aversion and impatience may explain, in part, why some people remain poor.
We conducted experiments in Vietnamese villages to directly measure risk and time preferences of individuals, and investigated how these preferences correlate with economic circumstances. Vietnam has several advantages as a field site:
-
1.
Access to a 2002 living standard survey enabled us to link detailed survey responses from individuals directly to experimental responses by the same individuals.
-
2.
Most Vietnamese villagers are poor but literate. As a result, it is both easy to motivate them with modest financial stakes, and to ensure they comprehend instructions.
-
3.
The rise of household businesses in the market economy has created substantial variation in income. This income variation can be correlated with preference measures.
In any cross-sectional study like this, it is difficult to infer the direction of causality from correlation: Do preferences cause economic circumstances (e.g., through business formation, for example), or do circumstances create preferences (as described by Samuel Bowles (1998))? An ideal study would use randomized assignment of individuals to economic circumstances. As an alternative, we employ an instrumental variable approach, using rainfall and household head’s ability to work at the time of survey, which are unlikely to be correlated with preferences, as instrumental variables for income.
Besides contributing new data, this chapter makes a methodological contribution to experimental development economics. Most previous experiments conducted in the field tested models of risk and time preferences that can be characterized by one parameter. (See Jeffrey Carpenter and Juan-Camilo Cardenas (2008) for a review). These models often fit experimental data in Western educated populations (Frederick et al. 2002; Starmer 2000) and field data (Camerer 2000) less well than models with multiple components of risk and time preferences. For example, in expected utility theory (EU), risk preferences are characterized solely by the concavity of a utility function for money. But if risky choices express prospect theory preferences (Daniel Kahneman and Amos Tversky 1979), then utility concavity is not the only parameter influencing risk preferences—nonlinear weighting of probabilities, and aversion to loss compared to gain, also influence risk preferences. Our instruments are designed to measure these three parameters of prospect theory, rather than just one in EU.
Similarly, we measure three parameters in a general time discounting model (Benhabib et al. 2007), rather than measuring a single exponential discount rate as in most other studies. If the exponential model is an adequate approximation, then our richer instruments will deliver parameter values of the extra variables which affirm the virtue of the simpler exponential.
Before proceeding to design details and results, it is useful to discuss how our approach compares to other field experiments. Field experiments in development are powerful tools for policy evaluation because they can randomize treatments in naturally-occurring decision making to see how well a specific policy works in a specific setting with a proper control group (see Esther Duflo (2005) for a review). For example, Ashraf et al. (2006) found that women who displayed lower discount rates in a hypothetical-question survey were more likely to open a commitment savings account offered by a bank in the Philippines.
Our approach is different. Our study is designed to collect preference measures experimentally and correlate those measures with demographic and economic variables (income, in particular) from the previous household survey. The goal is to contribute basic tools for field experimentation and to generate tentative observations about the correlation between preferences and economic circumstances. No single result will be as conclusive as more targeted studies which explore the effect of a specific policy. Nevertheless, the policy-specific approach and our broad approach are complementary. Targeted studies like Ashraf et al.’s tell broader studies like ours what to look for. Broader studies like ours give a rich set of tentative results for more targeted studies like Ashraf et al.’s to explore more carefully. Accumulation of regularity will come fastest from doing both types of studies.
2 Selection of Research Sites and Research Methods
In July–August 2005, risk and time discounting experiments were conducted with members of households who were previously interviewed during a 2002 living standard measurement survey.Footnote 1 In the 2002 survey, 25 households were interviewed in each of 142 and 137 rural villages in the Mekong Delta (in the South) and the Red River Delta (in the North).Footnote 2 From these, we chose nine villages, five villages in the south and four villages in the north, with substantial differences in mean village income and market access. Some descriptive statistics about the nine experimental village sites are given in Table 1.1. The southern villages are indexed by S1–S5 (where S1 indexes the highest village wealth and S5 indexes the lowest), and northern villages are indexed by N1–N4.Footnote 3
A week before the experiments, research coordinators contacted local government officials in each research site, and asked them to invite one person from each of the 25 previously surveyed households to the experiments. Experiments started at approximately 9 A.M. in the morning, and lasted about 4 h. Subjects were given instructions and separate record sheets for each game. Illiterate subjects (8 %) were given verbal instruction by research assistants. Subjects who had difficulty completing record sheets by themselves were also helped by research assistants who carefully avoided giving specific instructions about how to answer. The average experimental earning for three games was 174,141 dong (about 11 dollarsFootnote 4), roughly 6–9 days’ wages for casual unskilled labor.
3 Risk
3.1 Previous Findings
Ravi Kanbur and Lyn Squire (2001) describe the risk attitude of the poor as “a feeling of vulnerability”. Market fluctuations and natural disasters could put these villagers in a state of having little or losing what little they have. Empirical evidence suggests wealthier households invest in more risky productive activities, and earn higher returns (Rosenzweig and Binswanger 1993). These premises are consistent with decreasing absolute risk aversion in expected utility theory (EU); wealthier people are willing to take more risk than poorer people.
However, previous experimental studies conducted in developing countries give mixed results on wealth and risk preferences. Binswanger (1980, 1981) and Paul Mosley and Arjan Verschoor (2005) find no significant association between risk aversion and wealth. Uffe Nielsen (2001) finds positive relations between wealth and risk aversion, while Matte Wik et al. (2004) and Mahmud Yesuf (2004) find negative correlations. However, they used EU and mix gain-only and gain-loss gambles in their analysis, making it difficult to tell whether risk aversion comes solely from the concavity of utility function.
3.2 Measurement of Prospect Theory Parameters
We consider prospect theory as an alternative theoretical framework to EU, and conduct experiments with lotteries involving both gains and losses. We use cumulative prospect theory and the one-parameter form of Drazen Prelec (1998)’s axiomatically-derived weighting function. The values of prospects are v(y) + π(p) (v(x)−v(y)) (for xy > 0 and |x| > |y|) or v(y) + π(p)v(x) + π(q)v(y) where p and q are the probabilities of outcomes x and y. We assume a piecewise power function for value, v(x) = xσ for gains x > 0 and v(x) = −λ(−x)σ for losses x < 0. The probability weighting function is π(p) = 1/exp[ln(1/p)]α.
Parameters σ and λ represent concavity of the value function, and the degree of loss aversion. The probability weighting function is linear if \( \alpha =1 \), as it is in EU. If \( \alpha <1 \), the weighting function is inverted S-shaped, i.e., individuals overweight small probabilities and underweight large probabilities, as shown by Tversky and Kahneman (1992). If \( \alpha >1 \), then the weighting function is S-shaped, i.e., individuals underweight small probabilities and overweight large probabilities. The above model reduces to EU (with a reflected utility function at zero) if \( \alpha =1 \) and \( \lambda =1 \).
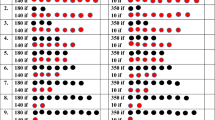
To elicit the three prospect theory parameters, we designed three series of paired lotteries as shown in Table 1.2. Each row is a choice between two binary lotteries, A or B. We enforced monotonic switching by asking subjects at which question they would “switch” from Option A to Option B in each Series. They can switch to Option B starting with the first question, and they do not have to switch to Option B at all.Footnote 5 After they completed three series of questions with the total of 35 choices, we draw a numbered ball from a bingo cage with 35 numbered balls, to determine which row of choice will be played for real money. We then put back 10 numbered balls in the bingo cage and played the selected lottery.
The difference in expected value between the lotteries (A relative to B) is shown in the right column. As one moves down the rows, the higher payoff in Option B increases and everything else is fixed. The choices are carefully designed so any combination of choices in the three series determines a particular interval of prospect theory parameter values. Table 1.3 illustrates the combinations of approximate values of σ, α and λ for each switching point. “Never” indicates the cases in which a subject does not switch to Option B (i.e., always choose A). The switching points in Series 1 and 2 jointly determine σ and α. For example, suppose a subject switched from Option A to B at the seventh question in Series 1. The combinations of (σ, α) which can rationalize this switch are (0.4, 0.4), (0.5, 0.5), (0.6, 0.6), (0.7, 0.7), (0.8, 0.8), (0.9, 0.9) or (1, 1). Now suppose the same subjects also switched from Option A to B at the seventh question in Series 2. Then the combinations of (σ, α) which rationalize that switch are (0.8, 0.6), (0.7, 0.7), (0.6, 0.8), (0.5, 0.9), or (0.4, 1). By intersecting these parameter ranges from Series 1 and 2, we obtain the approximate values of (σ, α) = (0.7, 0.7). Predictions of (σ, α) for all possible combinations of choices are given in Table 1.9 in the Appendix.
The loss aversion parameter λ is determined by the switching point in Series 3. Notice that λ cannot be uniquely inferred from switching in Series 3. Questions in Series 3 were constructed to make sure that λ takes similar values across different levels of σ. Table 1.3 shows the range of λ for each switching point for three values σ = 0.2, 0.6 and 1.
3.3 Empirical Results
Figure 1.1 shows the distributions of choices made by subjects in Series 1 and 2. The numbers in the axes correspond to the switching points in Series 1 and 2.Footnote 6 The height of a cone represents the number of subjects who switched at that particular combination of switching points in Series 1 and 2. Black cones represent the choices which are consistent with EU. There are not many subjects whose choices are consistent with EU. The mean estimated values of (σ, α) are (0.59, 0.74) and (0.63, 0.74) in the south and north, respectively. Elaine M. Liu (2013) replicated this risk experiment with Chinese farmers and estimated average values (0.48, 0.69), which are reasonably close. The average derived value of α is significantly different from 1 at the 1 % significance level by t-test, rejecting EU in favor of inverted-S shaped probability weighting (see (Hsu et al. 2009) for a review and neural measures). We regressed the curvature of the utility function (σ) using OLS regressions, and loss-aversion (λ) by interval regressions using maximum likelihood techniques against individual-specific variables.Footnote 7 We first ran regressions using household income as an independent variable.

Distribution of switching points in Series 1 & 2 (experimental data). Black denotes switching point pairs consistent with EU
The regression results are shown in columns (1) and (3) in Table 1.4. Looking first at σ (curvature of the utility function), the strongest effects suggest subjects who are more educated and older are more risk-averse. The estimation result for loss aversion (λ) shows ethnic Chinese are less loss averse and people living in the South are more loss averse. Household income is not significantly correlated with either σ or λ.
Having learned that household income does not correlate with either risk aversion (in terms of concavity of utility function) or loss aversion, we decomposed household income into two variables, mean village income and relative income within the village (subtracting the mean and dividing by the within-village standard deviation).
Columns (2) and (4) in Table 1.4 contain the regression results of the estimations. Neither relative income nor mean income of the village correlates with concavity of utility function. However, mean village income is strongly correlated with loss aversion. Nevertheless, income variables may be endogenous, and it is difficult to know whether income variables explain risk preferences or vice versa. We used rainfall and household head’s ability to work at the time of survey as exogenous instruments for income variablesFootnote 8 and conducted the Hausman and Davidson-MacKinnon tests to investigate whether OLS is an inconsistent estimator for curvature of the utility function (σ) and loss aversion (λ). The results of both tests suggest OLS is an inconsistent estimator for σ (see Table 1.4). Therefore, we conducted instrumental variable two-stage least squares (IV-2SLS) regressions for the curvature of the utility function (σ). The IV regression results are shown in Table 1.5. The variable “head can’t work ” is a dummy variable, taking the value 1 if the household head was not able to work at the time of the survey. The effect of mean income is now significant at the 10 % level, i.e., individuals living in wealthier villages are less loss averse and also less risk averse. There are no significant effects of gender, which is interesting because many studies find that men are less averse to financial risk than women (e.g., Eckel and Grossman 2008). Our findings suggest that these previous effects of gender may be due to confounds with variables that often correlate with gender, such as income and education, which can be controlled for using our household survey.
4 Time Discounting
4.1 Previous Findings
Time discounting is another fundamental preference which may affect wealth accumulation. Most studies linking discount rates to wealth in both developed and developing societies use the exponential discounting model and show richer people are more patient (lower r).Footnote 9 However, exponential discounting model is often rejected by experimental and field data (Frederick et al. 2002). For example, measured discount rates tend to decline over timeFootnote 10 (Ainslie 1992) and exhibit a “present bias” or preference for immediate reward.Footnote 11 David Laibson (1997) proposed “quasi-hyperbolic” discounting model.Footnote 12
4.2 Measurement of Time Discounting Parameters
We use a general model proposed by Benhabib et al. (2007) which allows us to test exponential, hyperbolic, quasi-hyperbolic discounting, and a more general form. The model assigns a value to reward y at time of yβ(1−(1−θ)rt)1/(1−θ) for t > 0 (or simply y for immediate reward at t = 0).
The three factors r, β and θ separate conventional time discounting (r), present-bias (β) and hyperbolicity (θ) of the discount function. When β = 1, as θ approaches 1 the discounted value reduces to exponential discounting (e−rt) in the limit. When θ = 2 and β = 1, it reduces to true hyperbolic discounting (1/(1 + rt)). When θ = 1 (in the limit) and β is free, it reduces to quasi-hyperbolic discounting (βe−rt). The three-parameter form enables a way to compare three familiar models at once.
In our experiments, subjects make 75 choices between smaller rewards delivered today, and larger rewards delivered at specified times in the future as follows: Option A: Receive x dong today; or Option B: Receive y dong in t days.
The reward x varies between 30,000 and 300,000 and the time delay t varies between 3 days and 3 months (see Table 1.10 in the Appendix).Footnote 13
Before conducting the experiment, we chose and announced a trusted agent who would keep the money until delayed delivery date to ensure subjects believed the money would be delivered. The selected trusted persons were usually village heads or presidents of women’s associations. In five villages, the trusted agents were also experimental subjects. Agreement letters of money delivery were signed between the trusted agents and the first author. Agents were instructed to deliver the money to the houses of experimental subjects, which tries to equalize the pure transaction costs of receiving money immediately (i.e., at the end of the experiment) or in the future.Footnote 14
After subjects completed all 75 questions, we put 75 numbered balls in the bingo cage and drew one ball to determine a pairwise choice. The option chosen for that pair (i.e., A or B) determined how much money was to be delivered, and when.
We denote the probability of choosing immediate reward of x over the delayed reward of y in t days by P(x > (y, t)), and use a logistic function to describe this relation as follows:
We estimate the parameters μ, β, θ and r in the above logistic equation. The variable μ is a response sensitivity or noise parameter.
4.3 Empirical Results
Estimation results comparing specific functions are given in Table 1.6. We fitted the logistic function (1) by using a nonlinear least-squares regression procedure.Footnote 15 The estimated values of (r, β, θ) are (0.078, 0.82, 5.07).Footnote 16 This implies subjects should trade 6,151 dong today for 10,000 dong in a week, and 4,971 dong today for 10,000 dong in 3 weeks.
In addition to the general model (1) (shown in the far right column), we estimated exponential, hyperbolic, and quasi-hyperbolic discounting models. Estimating the full model (1) with unrestricted θ does not improve R2 much compared with the estimation of the quasi-hyperbolic model, so we focus attention only on the quasi-hyperbolic discounting.
Next, we estimate the following logistic function (2) to see whether demographic variables correlate with individual difference in present bias (β) and discount rates (r).
where \( \beta ={\beta}_0+{\displaystyle \sum {\beta}_i{X}_i} \), \( r={r}_0+{\displaystyle \sum {r}_i{X}_i} \) and demographic variables and associated coefficients are represented by X i and β i or r i .
Table 1.7 shows the results from regressing estimates of the quasi-hyperbolic discounting model, allowing ß and r to depend on demographic variables. We conducted non-linear estimations of the logistic function (2), using household income as an independent variable for the first regression (reported in column (1)), and relative and mean village income as independent variables for the second regression (reported in column (2)).Footnote 17 The variable “trusted agent” is a dummy variable, taking the value 1 if the subject is a trusted agent for money delivery. The variable “risk payment” corresponds to the amount of money the subject received in the risk experiment.
The largest effects are on discount rates r. Household income and mean village income are positively related with patience (lower r). None of the income variables explain individual difference in present bias (β) while the estimated coefficient of β in Table 1.6 (0.644) indicates subjects are present biased. This implies people are present biased regardless of their wealth, and the degree of present bias is comparable to estimates from a variety of other studies.Footnote 18
The amount of money made in the risk game earlier in the experimental session is weakly correlated with patience: individuals who received higher payments in the risk game exhibit lower discount rates r. The choices made by the individuals who were assigned the role of money delivery were not significantly different from other subjects.Footnote 19 We also conducted regressions using instrumental variables (IV) for income variables, because the results of the Davidson-MacKinnon test suggest OLS is an inconsistent estimator. Table 1.8 shows the regression results from the IVthe regression results from the IV estimations. It indicates household income as well as mean village income correlate with lower discount rates.
5 Conclusion
We conducted experiments in Vietnamese villages to investigate how income and other demographic variables are correlated with risk and time preference.
Our results suggest mean village income is related to risk and time preferences. People living in poor villages are not necessarily afraid of uncertainty, in the sense of income variation; instead, they are averse to loss. When we introduce instrumental variables for income variables, mean village income is also significantly correlated with risk aversion (concavity of the utility function). From the time discounting experiment, we found that mean village income is correlated with lower discount rates, that is, people living in wealthy villages are not only less risk averse but also more patient.
Household income is correlated with patience (lower interest rate) but not with risk preference, which is consistent with the classic result of Binswanger (1980, 1981). Our results also demonstrate that people are present biased regardless of their income levels and economic environments.
These results are exploratory and the experimental measures are not perfect. Furthermore, in a cross-sectional study like this, it is difficult to conclude much about the direction of causality between preferences and economic circumstances because the study was not designed to do so. We used instrumental variables to deal with the income endogeneity problem. However, preferences and circumstances may be causal in both directions.
Finally, one contribution of our study is to show how to expand measurements of risk and time preferences beyond one-parameter expected utility and exponential discounting, replacing those models with prospect theory and the Benhabib et al. three-parameter discounting model. The parameters we measure are comparable to those in other studies (particularly the first direct replication using our risk preference measurement method, by Liu (2013) studying Chinese farmers) and correlate in interesting ways with household measures.
Notes
- 1.
Discrete trust game was conducted before the risk and time discounting experiments. Trust outcomes were not revealed until the end of the session and are reported elsewhere.
- 2.
The 2002 living standard survey covers total 354,360 households in Vietnam. According to the local government officials in our research sites, lists of all households in selected villages were submitted to district offices, and households were randomly selected from the lists for the survey.
- 3.
Villages S1 and S3 are in Can Tho City, Village S2 is in Ca Mau Province, Villages S4 and S5 are in Tra Vinh Province, Villages N1 and N2 are in Vinh Phuc Province, and Villages N3 and N4 are in Thai Binh Province.
- 4.
The exchange rate between Vietnamese Dong and US Dollar does not fluctuate very much. On July 23 2005, the exchange rate was 15,880 Dong for one US Dollar, while it was 15,947 Dong for one Dollar on July 23, 2002.
- 5.
The instructions gave three examples. In one example a subject switches at the sixth question, in one example the subject chooses option A for all questions, and in one example the subject chooses Option B for all questions. The three examples were given to help ensure that subjects do not feel that they are forced to switch.
- 6.
Switching point 15 implies the subject never switched in that series.
- 7.
- 8.
We tested several instrumental variables e.g., funeral costs, natural disaster relief, crop failure due to natural disaster and pests, and selected rainfall and household head’s ability to work as instruments, since these variables yield the highest F-statistic in the regression.
- 9.
Jerry Hausman (1979), Emily C. Lawrance (1991) and Harrison et al. (2002) report this relation in the United States and Denmark. John L. Pender (1996), Nielsen (2001) and Yesuf (2004) also report it in India, Madagascar, and Ethiopia, respectively. Kris N. Kirby et al. (2002) and C. Leigh Anderson et al. (2004) did not find a wealth-patience relation in Bolivia and Vietnam, but their villages did not have as much income variation as we were able to design in by handpicking villages.
- 10.
- 11.
- 12.
- 13.
The largest amount of y, 300,000 dong (about 19 dollars), is 15 days’ wages in the rural north.
- 14.
A referee suggested appropriately cautious wording: “There are many risks involved with leaving the money with the village head; one is that the village head will give out the money early, another is that the village head will keep the money for himself, another is that the village head will encourage those players who will be receiving a lot of money in the future to redistribute it within the village as earnings are no longer anonymous. These issues may affect the values of r, β, and θ in different ways. Given the difficulties in experimental design we did the best we can, and these are interesting issues for future research.”
- 15.
We excluded data from 3 subjects who made alternating responses across consecutive rows.
- 16.
t-tests of θ = 1 (quasi-hyperbolic discounting) and each of the restrictions ß = θ = 1 (exponential discounting) and ß = 1 and θ = 2 (hyperbolic discounting) reject all restrictions at p > 0.0001.
- 17.
The coefficients of explanatory variables for r (discount rates) are multiplied by 100.
- 18.
See Brown et al. (2009) for a review of quasi-hyperbolic model estimates.
- 19.
We also conducted regressions without the data of five subjects who were assigned the role of money delivery. There were few changes in regression results (see Table 1.11 in Appendix).
References
Ainslie G (1992) Picoeconomics: the strategic interaction of successive motivational states within the person. Cambridge University Press, New York
Anderson CL, Dietz M, Gordon A, Klawitter M (2004) Discount rates in Vietnam. Econ Dev Cult Chang 52(4):873–888
Angeletos GM, Laibson D, Repetto A, Tobacman J, Weinberg S (2001) The hyperbolic consumption model: calibration, simulation, and empirical evaluation. J Econ Perspect 15(3):47–68
Ashraf N, Karlan DS, Yin W (2006) Tying odysseus to the mast: evidence from a commitment savings product in the Philippines. Q J Econ 121(2):635–672
Benhabib J, Bisin A, Schotter A (2007) Hyperbolic discounting: an experimental analysis. http://homepages.nyu.edu/~as7/pshype1205withfigures.pdf. Accessed 12 Jan 2015
Benzion U, Rapoport A, Yagil J (1989) Discount rates inferred from decisions – an experimental-study. Manag Sci 35(3):270–284
Bernheim BD, Skinner J, Weinberg S (2001) What accounts for the variation in retirement wealth among U.S. households? Am Econ Rev 91(4):832–857
Binswanger HP (1980) Attitudes toward risk: experimental measurement in rural India. Am J Agric Econ 62:395–407
Binswanger HP (1981) Attitudes toward risk: theoretical implications of an experiment in rural India. Econ J 91(364):867–890
Bowles S (1998) Endogenous preferences: the cultural consequences of markets and other economic institutions. J Econ Lit 36(1):75–111
Brown AL, Camerer CF, Chua ZE (2009) Learning and visceral temptation in dynamic savings experiments. Q J Econ 124(1):197–231
Camerer CF (2000) Prospect theory in the wild: evidence from the field. In: Kahneman D, Tversky A (eds) Choices, values, and frames. Cambridge University Press, Cambridge, pp 288–300
Carpenter J, Cardenas JC (2008) Behavioral development economics: lessons from field labs in the developing world. J Dev Stud 44(3):337–364
DellaVigna S, Malmendier U (2006) Paying not to go to the gym. Am Econ Rev 96(3):694–719
Diamond P, Koszegi B (2003) Quasi-hyperbolic discounting and retirement. J Public Econ 87:1839–1872
Eckel CC, Grossman P (2008) Differences in the economic decisions of men and women: experimental evidence. In: Plott C, Smith V (eds) Handbook of experimental economics results. Elsevier, New York, pp 509–519
Esther D (2005) Field experiments in development economics. Paper presented at the world congress of the econometric society, London
Frederick S, Loewenstein G, O’Donoghue T (2002) Time discounting and time preference: a critical review. J Econ Lit 40(2):351–401
Harrison GW, Lau MI, Williams MB (2002) Estimating individual discount rates in Denmark: a field experiment. Am Econ Rev 92(5):1606–1617
Hausman J (1979) Individual discount rates and the purchase and utilization of energy-using durables. Bell J Econ 10(1):33–54
Hsu M, Krajbich I, Zao C, Camerer CF (2009) Neural response to reward anticipation under risk is nonlinear in probabilities. J Neurosci 29(7):2231–2237
Kahneman D, Tversky A (1979) Prospect theory: an analysis of decision under risk. Econometrica 47(2):263–291
Kanbur R, Squire L (2001) The evolution of thinking about poverty. In: Meier GM, Stiglitz JE (eds) Frontiers of development economics. Oxford University Press, Oxford
Kirby KN, Godoy R, Reyes-Garcia V, Byron E, Apaza L, Leonard W, Perez E, Vadez V, Wilkie D (2002) Correlates of delay-discount dates: evidence from Tsimane’ Amerindians of the Bolivian Rain Forest. J Econ Psychol 23:291–316
Laibson DI (1997) Golden eggs and hyperbolic discounting. Q J Econ 112(2):443–477
Laibson D, Repetto A, Tobacman J (1998) Self-control and saving for retirement. Brook Pap Econ Act 1:91–196
Lawrance EC (1991) Poverty and the rate of time preference: evidence from panel data. J Polit Econ 99(1):54–77
Liu EM (2013) Time to change what to sow: risk preferences and technology adoption decisions of cotton farmers in China. Rev Econ Stat 95(4):1386–1403
Liu EM, Huang JK (2013) Risk preferences and pesticide use by cotton farmers in China. J Dev Econ 103:202–215
Loewenstein G, Prelec D (1992) Anomalies in intertemporal choice: evidence and an interpretation. Q J Econ 107(2):573–597
Mosley P, Verschoor A (2005) Risk attitudes and the ‘Vicious Circle of Poverty’. Euro J Dev Res 17(1):59–88
Nielsen U (2001) Poverty and attitudes towards time and risk – experimental evidence from Madagasca. Working paper, Royal Veterinary and Agricultural University of Denmark
O’Donoghue T, Rabin M (1999) Doing it now or later. Am Econ Rev 89(1):103–124
O’Donoghue T, Rabin M (2001) Choice and procrastination. Q J Econ 116(1):121–160
Pender JL (1996) Discount rates and credit markets: theory and evidence from rural India. J Dev Econ 50:257–296
Prelec D (1998) The probability weighting function. Econometrica 66(3):497–527
Rosenzweig MR, Binswanger HP (1993) Wealth, weather risk and the composition and profitability of agricultural investments. Econ J 103(416):56–78
Starmer C (2000) Developments in non-expected utility theory: the hunt for a descriptive theory of choice under risk. J Econ Lit 38(2):332–382
Tanaka T, Camerer CF, Nguyen Q (2010) Risk and time preferences: linking experimental and household survey data from Vietnam. Am Econ Rev 100(1):557–571
Thaler R (1981) Some empirical-evidence on dynamic inconsistency. Econ Lett 8(3):201–207
Tversky A, Kahneman D (1992) Advances in prospect-theory - cumulative representation of uncertainty. J Risk Uncertain 5(4):297–323
Wik M, Kebede TA, Bergland O, Holden S (2004) On the measurement of risk aversion from experimental data. Appl Econ 36(21):2443–2451
Yesuf M (2004) Risk, time and land management under market imperfections: applications to Ethiopia. Dissertation, Göteborg University
Acknowledgments
This research was supported by a Behavioral Economics Small Grant from the Russell Sage Foundation, Foundation for Advanced Studies on International Development, and internal Caltech funds to author Camerer. Comments from participants at the ESA meeting (October 2005), SEA meeting (November 2005), SJDM (November 2005), ASSA meeting (January 2007), audiences at Columbia, NYU, Bocconi, Emory, Hawaii, Caltech, UCSC, Claremont McKenna, Guelph, Carleton, Arizona State, a conference at UT-Dallas, and five thoughtful anonymous referees were helpful. Thanks to our research coordinators, Phan Dinh Khoi, Huynh Truong Huy, Nguyen Anh Quan, Nguyen Mau Dung, and research assistants, Bui Thanh Sang, Nguyen The Du, Ngo Nguyen Thanh Tam, Pham Thanh Xuan, Nguyen Minh Duc, Tran Quang Trung, and Tran Tat Nhat. We also thank Nguyen The Quan of the General Statistical Office, for allowing us to access the 2002 household survey data.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendix
Addendum: The Impacts of Risk Preferences on Technology Adoption in Agriculture
This addendum has been newly written by Tomomi Tanaka for this book chapter.
In the chapter entitled “Risk and time preferences: Linking experimental and household survey data from Vietnam”, we examined how basic preferences, namely risk and time preferences, are linked to wealth. We hypothesized that (1) risk averse people are reluctant to enter into risky but profitable economic activities, and (2) impatient people do not engage in long-term projects such as educating their children, so thus remain poor. We conducted risk and time discounting experiments in nine villages in Vietnam and investigated whether risk and time preferences correlate with income, relative income within village, and mean income of village. We found mean village income is correlated with risk and time preferences. People living in poor villages are not necessarily risk averse but they are loss averse. They also have higher discount rates, suggesting they are less patient. These results imply economic circumstances are important in shaping people’s preferences. On the other hand, household income is not strongly related to preferences. Lower income is linked to impatience (higher discount rates) but is not correlated with risk preferences. By conducting experiments in multiple villages with various mean income levels, we were able to investigate whether mean village income (economic environments) or absolute income levels are related with wealth. Our contribution was to show how to expand measurement of risk and time preference beyond expected utility and exponential discounting models, by replacing them with prospect theory and quasi-hyperbolic discounting models with present bias. However, we could not link these preferences with economic activities and decision making in productive activities.
Using our experimental design, Elaine M. Liu (2013) examine whether risk preferences can explain the difference in adoption of agricultural technology among Chinese farmers. Liu shows the adoption of genetically modified Bt cotton is slower among risk averse and loss averse farmers. Also, the farmers who overweight small probabilities adopt genetically modified Bt cotton earlier. Elaine M. Liu and JiKun Huang (2013) further examine whether risk preferences explain overuse of pesticides among these farmers. They show risk averse farmers overuse pesticides, but loss averse farmers use less amounts of pesticides. They hypothesize loss averse farmers are more concerned about the impact of pesticides use on health. The two studies extended our study by using the experimental design we developed in our study and linking risk preferences with actual economic activities, i.e., agricultural technology adoption.
Rights and permissions
Copyright information
© 2016 Springer Japan
About this chapter
Cite this chapter
Tanaka, T., Camerer, C.F., Nguyen, Q. (2016). Risk and Time Preferences: Linking Experimental and Household Survey Data from Vietnam. In: Ikeda, S., Kato, H., Ohtake, F., Tsutsui, Y. (eds) Behavioral Economics of Preferences, Choices, and Happiness. Springer, Tokyo. https://doi.org/10.1007/978-4-431-55402-8_1
Download citation
DOI: https://doi.org/10.1007/978-4-431-55402-8_1
Publisher Name: Springer, Tokyo
Print ISBN: 978-4-431-55401-1
Online ISBN: 978-4-431-55402-8
eBook Packages: Economics and FinanceEconomics and Finance (R0)