
Abstract
Shapelets have recently been proposed as a new primitive for time series classification. Shapelets are subseries of series that best split the data into its classes. In the original research, shapelets were found recursively within a decision tree through enumeration of the search space. Subsequent research indicated that using shapelets as the basis for transforming datasets leads to more accurate classifiers. Both these approaches evaluate how well a shapelet splits all the classes. However, often a shapelet is most useful in distinguishing between members of the class of the series it was drawn from against all others. To assess this conjecture, we evaluate a one vs all encoding scheme. This technique simplifies the quality assessment calculations, speeds up the execution through facilitating more frequent early abandon and increases accuracy for multi-class problems. We also propose an alternative shapelet evaluation scheme which we demonstrate significantly speeds up the full search.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


1 Introduction
Time series classification (TSC) is a subset of the general classification problem. The primary difference is that the ordering of attributes within each instance is important. For a set of n time series, \(\mathbf{T}= \{T_1,T_2,...,T_n\}\), each time series has m ordered real-valued observations, \(T_i = \{t_{i1},t_{i2},...,t_{im}\}\) and a class value \(c_i\). The aim of TSC is to determine a function that relates the set of time series to the class values.
One recently proposed technique for TSC is to use shapelets [1]. Shapelets are subseries of the series \(\mathbf{T}\) that best split the data into its classes. Shapelets can be used to detect discriminatory phase independent features that cannot be found with whole series measures such as dynamic time warping. Shapelet based classification involves measuring the similarity between a shapelet and each series, then using this similarity as a discriminatory feature for classification. The original shapelet-based classifier [1] embeds the shapelet discovery algorithm in a decision tree, and uses information gain to assess the quality of candidates. A shapelet is found at each node of the tree through an enumerative search. More recently, we proposed using shapelets as a transformation [2]. The shapelet transform involves a single-scan algorithm that finds the best k shapelets in a set of n time series. We use this algorithm to produce a transformed dataset, where each of the k features is the distance between the series and one shapelet. Hence, the value of the \(i^{th}\) attribute of the \(j^{th}\) record is the distance between the \(j^{th}\) record and the \(i^{th}\) shapelet. The primary advantages of this approach are that we can use the transformed data in conjunction with any classifier, and that we do not have to search sequentially for shapelets at each node. However, it still requires an enumerative search throughout the space of possible shapelets and the full search is \(O(n^2m^4)\). Improvements for the full search technique were proposed in [1, 3] and heuristics techniques to find approximations of the full search were described in [4,5,6].
Our focus is only on improving the exhaustive search. One of the problems of the shapelet search is the quality measures assess how well the shapelet splits all the classes. For multi-class problems measuring how well a shapelet splits all the classes may confound the fact that it actually represents a single class. Consider, for example, a shapelet in a data set of heartbeat measurements of patients with a range of medical conditions. It is more intuitive to imagine that a shapelet might represent a particular condition such as arrhythmia rather than discriminating between multiple conditions equally well. We redefine the transformation so that we find shapelets assessed on their ability to distinguish one class from all, rather than measures that separate all classes. This improves accuracy on multi-class problems and allows us to take greater advantage of the early abandon described in [1].
A further problem with the shapelet transform is that it may pick an excessive number of shapelets representing a single class. By definition, a good shapelet will appear in many series. The best way we have found to deal with this is to generate a large number of shapelets then cluster them [2]. However, there is still a risk that one class is generally easier to classify and hence has a disproportionate number of shapelets in the transform. The binary shapelet allows us to overcome this problem by balancing the number of shapelets we find for each class.
Finally, we describe an alternative way of enumerating the shapelet search that facilitates greater frequency of early abandon of the distance calculation.
2 Shapelet Based Classification
The shapelet transform algorithm described in [2] is summarised in Algorithm 1. Initially, for each time series, all candidates of length min to max are generated (i.e. extracted and normalised in the method generateCandidates). Then the distance between each shapelet and the other \(n-1\) series are calculated to form the order list, \(D_S\). Distance between a shapelet S of length l and a series T is given by
where \(W_l\) is the set of all l length subseries in T and dist is the Euclidean distance between the equal length series S and w. The order list is used to determine the quality of the shapelet in the assessCandidate method. Quality can be assessed by information gain [1] or alternative measures such as the F, moods median or rank order statistic [7]. Once all the shapelets for a series are evaluated they are sorted and the lowest quality overlapping shapelets are removed. The remaining candidates are then added to the shapelet set. By default, we set \(k=10n\) with the caveat that we do not accept shapelets that have zero information gain.

Once the best k shapelets have been found, the transform is performed with Algorithm 2. A more detailed description can be found in [8].
Extensions to the basic shapelet finding algorithm can be categorized into techniques to speed up the average case complexity of the exact technique and those that use heuristic search. The approximate techniques include reducing the dimensionality of the candidates and using a hash table to filter [4], searching the space of shapelet values (rather than taking the values from the train set series) [5] and randomly sampling the candidate shapelets [6]. Our focus is on improving the accuracy and speed of the full search. Two forms of early abandon described in [1] can improve the average case complexity. Firstly, the Euclidean distance calculations within the sDist (Eq. 1) can be terminated early if they exceed the best found so far. Secondly, the shapelet evaluation can be abandoned early if assessCandidate is updated as the sDist are found and the best possible outcome for the candidate is worse than the current top candidates.
A speedup method involving trading memory for speed is proposed in [3]. For each pair of series \(T_i,T_j\), cumulative sum, squared sum, and cross products of \(T_i\) and \(T_j\) are pre-calculated. With these statistics, the distance between subseries can be calculated in constant time, making the shaplet-discovery algorithm \(O(n^2m^3)\). However, pre-calculating of the cross products between all series prior to shapelet discovery requires \(O(n^2m^2)\) memory, which is infeasible for most problems. Instead, [3] propose calculating these statistics prior to the start of the scan of each series, reducing the requirement to \(O(nm^2)\) memory, but increasing the time overhead. Further refinements applicable to shapelets were described in [9], most relevant of which was a reordering of the sequence of calculations within the dist function to increase the likelihood of early abandon. The key observation is that because all series are normalized, the largest absolute values in the candidate series are more likely to contribute large values in the distance function. Hence, if the distances between positions with larger candidate values are evaluated first, then it is more likely the distance can be abandoned early. This can be easily implemented by creating an enumeration through the normalized candidate at the beginning, and adds very little overhead. We use this technique in all experiments.

3 Classification Technique
Once the transform is complete we can use any classifier on the problem. To reduce classifier induced variance we use a heterogenous ensemble of eight classifiers. The classifiers used are the WEKA [10] implementations of k Nearest Neighbour (where k is set through cross validation), Naive Bayes, C4.5 decision tree [11], Support Vector Machines [12] with linear and quadratic basis function kernels, Random Forest [13] (with 100 trees), Rotation Forest [14] (with 10 trees) and a Bayesian network. Each classifier is assigned a weight based on the cross validation training accuracy, and new data are classified with a weighted vote. The set of classifiers were chosen to balance simple and complex classifiers that use probabilistic, tree based and kernel based models. With the exception of k-NN, we do not optimise parameter settings for these classifiers via cross validation. More details are given in [8].
4 Alternate Shapelet Techniques
4.1 Fast Shapelets
The fast shapelet (FS) algorithm was proposed in 2013 [4]. The algorithm is a refinement of original decision tree shapelet selection algorithm. It employs a number of techniques to speed up the finding and pruning of shapelet candidates at each node of the tree [15]. The major changes made to the enumerative search is the introduction of symbolic aggregate approximation (SAX) [16] as a means for reducing the length of each series as well as smoothing and discretising the data. The other major advantage of using the SAX representation is that shapelet candidates can be pruned by using a collision table metric which highly correlates with Information Gain to reduce the amount of work performed in the quality measure stage. In the description in Algorithm 3 the decision tree has been omitted to improve clarity.
The first stage of the shapelet finding process is to create a list of SAX words [16]. The basic concept of SAX is a two stage process of dimension reduction and discretisation. SAX uses piece-wise aggregate approximation (PAA), to transform a time series into a number of smaller averaged sections before z normalization. This reduced series is discretised into a given alphabet size. Breakpoints are defined by equally likely areas of a standard normal distribution and each series forms a single string of characters. These strings are much smaller in length compared to the original series, so finding shapelets is faster. To increase the likelihood of word collisions a technique called random projects is employed. Given some SAX words random projection reduces their dimensionality by masking a number of their letters. The SAX words are randomly projected a number of times, the projected words are hashed and a frequency table for all the SAX words is built.
From this frequency table a new set of tables can be built which represent how common the SAX word is with respect to each class. A score for each SAX word can be calculated based on these grouping scores, and this value is used for assessing the distinguishing power of each SAX word. From this scoring process a list of the top k SAX shapelets can be created. These top k SAX shapelets are transformed back into their original series, where the shapelets information gain can be calculated. The best shapelet then forms the splitting rule in the decision tree.

4.2 Learn Shapelets
Learn shapelets (LS) was proposed by Grabocka et al. in 2014 [5]. Rather than uses subseries in the data as candidate shapelets, LS searches the space of all possible shapelets using a gradient descent approach on an initial set of shapelets found through clustering. An set of series is taken from the data and clustered using k-Means. The resulting centroids are refined with a two stage gradient descent model of shapelet refinement and logistic regression assessment. The learning is continued until either the model has converged or the number of iterations has exceeded a hard limit (maxIter). We show a high level overview of the algorithm presented in [5] in Algorithm 4.

5 Shapelet Transform Refinements
5.1 Binary Shapelets
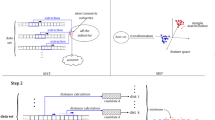
The standard shapelet assessment method measures how well the shapelet splits up all the classes. There are three potential problems with this approach when classifying multi-class problems. The problems apply to all possible quality measures, but we use information gain to demonstrate the point. Firstly, useful information about a single class may be lost. For example, suppose we have a four class problem and a shapelet produces the order line presented in Fig. 1, where each colour represents a different class.

An example order line split for two shapelets. The top shapelet discriminates between class 1 and the rest perfectly, yet has lower information gain than the orderline shown below it.

The first shapelet groups all of class 1 very well, but cannot distinguish between classes 2, 3 and 4 and hence has a lower information gain than the split produced by the second shapelet in Fig. 1 which separates class 1 and 2 from class 3 and 4. The more classes there are, the more likely it is that the quantification of the ability of a shapelet to separate out a single class will be overwhelmed by the mix of other class values. We can mitigate against this potential problem by defining a binary shapelet as one that is assessed by how well it splits the class of the series it originated from all the other classes. The second problem with searching all shapelets with multi-class assessment arises if one class is much easier to classify than the others. In this case it is likely that more shapelets will be found for the easy class than for the other classes. Although our principle is to find a large number of shapelets (ten times the number of training cases) and let the classifier deal with redundant features, there is still a risk that a large number of similar shapelets for one class will crowd out useful shapelets for another class. If we use binary shapelets we can simply allocate a maximum number of shapelets to each class. We adopt the simple approach of allocating a maximum of k/c shapelets to each class, where c is the number of classes. The final problem is that the shapelet early abandon described in [1] is not useful for multi-class problems. Given a partial orderline and a split point, the early abandon works by upper bounding the information gain by assigning the unassigned series to the side of the split that would give the maximum gain. However, the only way to do this with multi-class problems is to try all permutations. The time this takes quickly rises to offset the possible benefits from the early abandon. If we restrict our attention to just binary shapelets then we can take maximum advantage of the early abandon. The binary shapelet selection is described by Algorithm 5.

An example of Euclidean distance early abandon where the sDist scan starts from the beginning (a) and from the place of origin of the candidate shapelet (b). For the scan from the beginning, there are no early abandons until the scan has passed the best match. Because the best match is close to the location of the candidate shapelet, starting from the shapelets original location allows for a greater number of early abandons.
5.2 Changing the Shapelet Evaluation Order
Shapelets are phase independent. However, for many problems the localised features are at most only weakly independent in phase, i.e. the best matches will appear close to the location of the candidate. Finding a good match early in sDist increases the likelihood of an early abandon for each dist calculation. Hence, we redefine the order of iteration of the dist calculations within sDist so that we start with the index the shapelet was found at and move consecutively left and right from that point. Figure 2 demonstrates the potential benefit of this approach. The scan from the beginning is unable to early abandon on any of the subseries before the best match. The scan originating at the candidates location finds the best match faster an hence can early abandon on all the distance calculations at the beginning of the series. Hence, if the location of the best shapelet is weakly phase dependent, we would expect to observe an improvement in the time complexity. The revised function sDist, which is a subroutine of findDistances (line 9 in Algorithm 5), is described in Algorithm 6.
6 Results
We demonstrate the utility of our approach through experiments using 74 benchmark multi-class datasets from the UCR Time Series Classification archive [17]. In common with the vast majority of research in this field, we present results on the standard train/test split. The min and max size of the shapelet are set to 3 and m (series length). As a sanity check, we have also evaluated the binary shapelets on two class problems to demonstrate there is negligible difference. On 25 two class problems, the full transform was better on 6, the binary transform better on 19 and they were tied on 1. All the results and the code to generate them are available from [18, 19].
6.1 Accuracy Improvement on Multi-class Problems
Table 1 gives the results for the full shapelet transform and the binary shapelet transform on problems with 2-50 classes. Overall, the binary shapelet transform is better on 48 data sets, the full transform better on 21 and on 4 they are equal. On multi class problems, the binary shapelet transform is better on 29 problems compared with the full shapelet transform being better on 15. The difference between the full and the binary shapelet transform is significant at the 5% level using a paired T test.


Number of classes plotted against the difference in error between the full shapelets and the binary shapelets. A positive number indicates the binary shapelets are better. The dotted line is the least squares regression line.
Figure 3 shows the plot of the difference in accuracy of the full and binary shapelet transform plotted against the number of classes. There is a clear trend of increasing accuracy for the binary transform as the number of classes continues. This is confirmed in Table 2, which presents the same data grouped into bins of ranges of number of classes.
6.2 Accuracy Comparison to Other Shapelet Methods
To establish the efficacy of the binary shapelet approach we wanted to thoroughly compare it to other shapelet approaches within the literature, Fast Shapelets (FS) [4] and Learn Shapelets (LS) [5]. The 85 datasets from the updated repository [18] were stratified and resampled 100 times, to produce 8500 problems. All folds and results are reproducible within our common Java WEKA [10] framework [19]. Where possible we tried to match the experimental procedure for parameter searching outlined in the original work. We performed very extensive tests and analysis on the algorithms implemented to make sure they were identical to the available source code, and provide statistically similar results as published. This often required working with the original authors to help replicate and fix errors.

The critical difference diagram of the Shapelet Transform, Fast Shapelets and Learn Shapalets, the data is presented in 3
We present the results of the mean accuracy for the binary shapelet transform, FS and LS in Table 3. We found that binary shapelets was better than FS and LS on 67 problems, and on a pair wise t-test was significantly better at the 5% level. We show the critical difference of the three approaches in Fig. 4.
6.3 Accuracy Comparison to Standard Approaches
Using the same methodology for comparing shapelet methodsm we compared the shapelet approach to more standard approaches. These were 1-nearest neighbour using Euclidean distance, 1 nearest neighbour with dynamic time warping and lastly rotation forest. We present the results in Table 4 showing that on the 85 datasets, the binary shapelet wins on 55 problems and is significantly better than other the standard approaches. We show the comparison of these classifiers in the critical difference diagram in Fig. 5.
6.4 Average Case Time Complexity Improvements
One of the benefits of using the binary transform is that it is easier to use the shapelet early abandon described in [3]. Early abandon is less useful when finding the best k shapelets than it is for finding the single best, but when it can be employed it can give real benefit. Figure 6 shows that on certain datasets, using the binary shapelet discovery means millions of fewer sDist evaluations.
We assess the improvement from using Algorithm 6 by counting the number of point wise distance calculations required from using the standard approach, the alternative enumeration, and the state of art the enumeration in [2].
For the datasets used in our accuracy experiments, changing the order of enumeration reduces the number of calculations in the distance function by 76% on average. The improvement ranges from negligible (e.g. Lightning7 requires 99.3% of the calculations) to substantial (e.g. Adiac operations count is 63% of the standard approach). This highlights that the best shapelets may or may not be phase independent, but nothing is lost from changing the evaluation order and often substantial improvements are achieved. This is further highlighted in Fig. 7 where the worst dataset Synthetic control does not benefit from the alternate enumeration. For the average and the best case we see a reduction of approx. 15% fewer operations required. On the Olive Oil dataset we see a 99% reduction in the number of distance calculations required.
Full results, all the code and the datasets used can be downloaded from [18, 19]. The set of experiments, and results are constantly being expanded and evaluated against the current state of the art.

The critical difference diagram showing the comparison of the new Shapelet Transform compared with a number of standard benchmark classifiers; 1 Nearest Nieghbour with Euclidean Distance, 1 Nearest Neighbour with Dynamic Time Warping setting the windows size through cross-validation and Rotation Forest, results are shown in Table 4

Number of sDist measurements that were not required because of early abandon (in millions) for both full and binary shapelet discovery on seven datasets.

Percentage of operations performed of Full search, compared with previous sDist optimisations, and our two new speed up techniques.
We define the opCounts as the number of operations performed in the Euclidean distance function when comparing two series. This enables us to estimate the improvements of new techniques. We show in Table 5 the op counts in millions for 40 datasets. The balancing in some rare cases can increase the number of operations performed. Typically these datasets have a large number of a class swamping the shapelet set. The balancer has individual lists for each class, and thus the shapelet being compared to for early abandon entropy pruning is different for each class, and in some cases can mean more work is done. In these experiments we wanted to show the progression of op count reduction as we combined techniques. When comparing to the previous best early abandon technique, the combination of the new methods proposed has seen a reduction of on average 35% of the required operations, to find and evaluate the same shapelets.
7 Conclusion
Shapelets are useful for classifying time series where the between class variability can be detected by relatively short, phase independent subseries. They offer an alternative representation that is particularly appealing for problems with long series with recurring patterns. The downside to using shapelets is the time complexity. The heuristic techniques described in recent research [4, 5] offer potential speed up (often at the cost of extra memory) but are essentially different algorithms that are only really analogous to shapelets described in the original research [1]. Our interest is in optimizing the original shapelet finding algorithm within the context of the shapelet transform. We describe incremental improvements to the shapelet transform specifically for multi-class problems. Searching for shapelets assessed on how well they find a single class is more intuitive, faster and becomes more accurate than the alternative as the number of classes increases. We demonstrated that the binary shapelet approach is significantly more accurate than other shapelet approaches and is significantly more accurate than conventional approaches to the TSC problem.
References
Ye, L., Keogh, E.: Time series shapelets: a novel technique that allows accurate, interpretable and fast classification. Data Min. Knowl. Disc. 22(1–2), 149–182 (2011)
Hills, J., Lines, J., Baranauskas, E., Mapp, J., Bagnall, A.: Classification of time series by shapelet transformation. Data Min. Knowl. Disc. 28(4), 851–881 (2014)
Mueen, A., Keogh, E., Young, N.: Logical-shapelets: an expressive primitive for time series classification. In: Proceeding 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2011)
Rakthanmanon, T., Keogh, E.: Fast-shapelets: a fast algorithm for discovering robust time series shapelets. In: Proceeding 13th SIAM International Conference on Data Mining (SDM) (2013)
Grabocka, J., Schilling, N., Wistuba, M., Schmidt-Thieme, L.: Learning time-series shapelets. In: Proceeding 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2014)
Gordon, D., Hendler, D., Rokach, L.: Fast randomized model generation for shapelet-based time series classification. arXiv preprint arXiv:1209.5038 (2012)
Lines, J., Bagnall, A.: Alternative quality measures for time series shapelets. In: Yin, H., Costa, J.A.F., Barreto, G. (eds.) IDEAL 2012. LNCS, vol. 7435, pp. 475–483. Springer, Heidelberg (2012). doi:10.1007/978-3-642-32639-4_58
Hills, J.: Mining time-series data using discriminative subsequences. PhD thesis, School of Computing Sciences, University of East Anglia (2015)
Rakthanmanon, T., Bilson, J., Campana, L., Mueen, A., Batista, G., Westover, B., Zhu, Q., Zakaria, J., Keogh, E.: Addressing big data time series: mining trillions of time series subsequences under dynamic time warping. ACM Trans. Knowl. Disc. Data, 7(3) (2013)
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.: The WEKA data mining software: an update. SIGKDD Explor. 11(1), 10–18 (2009)
Quinlan, J.R., et al.: Bagging, boosting, and c4.5. In: AAAI/IAAI, vol. 1, pp. 725–730 (1996)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Rodriguez, J.J., Kuncheva, L.I., Alonso, C.J.: Rotation forest: a new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 28(10), 1619–1630 (2006)
Lines, J., Davis, L., Hills, J., Bagnall, A.: A shapelet transform for time series classification. In: Proceeding of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2012)
Lin, J., Keogh, E., Li, W., Lonardi, S.: Experiencing SAX: a novel symbolic representation of time series. Data Min. Knowl. Disc. 15(2), 107–144 (2007)
Chen, Y., Keogh, E., Hu, B., Begum, N., Bagnall, A., Mueen, A., Batista, G.: The UCR time series classification archive (2015). http://www.cs.ucr.edu/~eamonn/time_series_data/
Bagnall, A., Lines, J., Bostrom, A., Keogh, E.: The UCR/UEA TSC archive. http://timeseriesclassification.com
Bagnall, A., Bostrom, A., Lines, J.: The UEA TSC codebase. https://bitbucket.org/TonyBagnall/time-series-classification
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer-Verlag GmbH Germany
About this chapter
Cite this chapter
Bostrom, A., Bagnall, A. (2017). Binary Shapelet Transform for Multiclass Time Series Classification. In: Hameurlain, A., Küng, J., Wagner, R., Madria, S., Hara, T. (eds) Transactions on Large-Scale Data- and Knowledge-Centered Systems XXXII. Lecture Notes in Computer Science(), vol 10420. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-55608-5_2
Download citation
DOI: https://doi.org/10.1007/978-3-662-55608-5_2
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-662-55607-8
Online ISBN: 978-3-662-55608-5
eBook Packages: Computer ScienceComputer Science (R0)