
Abstract
Visual information is an important type of information in modern life. However, it is still not used by organizations in a full capacity. The major reason for that is the lack of internal structure of visual information. The existence of this structure in numerical data allows to build very effective tools for classification, storage, and retrieval of numerical information, such as a relational data management system. In case of visual information, each value of the picture is basically meaningless, but the set of pixels starts carry meaningful information. In this paper, we aim to classify different types of images based on the areas of origination and application. We also suggest the possible structure of the database management system with images as elements of it. Another objective is to propose the indexing methods, which allow to avoid the direct comparison of visual query consequently to entire database. We also introduce the idea of applying multi frame super-resolution method to development of store-retrieval procedures for a database with dynamical visual information.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Image database management
- Super-resolution
- Visual data
- Data indexing
- Hash function
- Content-based image retrieval (CBIR)
- Industrial information integration systems
- Video database
1 Introduction
Accumulations of enormous amount of visual information, such as industrial images, aerial and satellite images, medical images, and others require development of new approaches on how to store, pre-process and retrieve it. The challenge to make of use of Big Data or vast information generated by industrial information integration systems should be addressed [1,2,3]. In [4], one of the co-author of the current paper proposed a hybrid method of visual database organization and image retrieval. The main idea is to combine annotation approach with SBIR approach. In [5], authors investigated several types of visual data, and proposed indexing algorithms for each of those types.
In general, there are two major approaches to store and retrieve visual information: text-based approach and content-based image retrieval (SBIR) approach. First approach operates not with image itself, but with a text which accompanies the image (annotation). In some sense the annotation serves as an index. When descriptive and reliable annotation exists, this method is very effective and efficient. However, it is rare the case. Since annotations are produced manually most of the time, the retrieval procedures suffer with low reliability.
Another approach extracts all necessary information from images themselves [6]. As a rule, intensity histograms and RGB proportions are major components. Both characteristics are important; however, they cannot be universal measures of image differences. There are some attempts (see for example [7,8,9]) to add the scene characteristics to the retrieval process, but they are very objects specific, and it is difficult to generalize those approaches.
In the current paper, we discuss extended version of the hybrid approach, and also discuss the possibility of database organization for storage and retrieval of data based on video information.
2 Different Types of Search
Talking about visual databases, authors very often mention entirely different types of storage and retrieval procedures. First, web-based storage is completely non-organized structure, where search is stochastic and produced “hits” or something similar on the query image. Second, database type storage where all elements are allocated into some logical structure, the search is deterministic, and the results are unique (including empty output).
In the current paper, we describe approach to image information organization, storage, and retrieval related to second type. Before an image is placed into database, it is pre-processed, annotated, and indexed [5]. The process of annotation and indexing depends on the nature of images. As was discussed in [5], the numerical indexing algorithms can be produced for different types of image collections: medical, satellite, aerial, virtual show room, forensic science. In all this cases annotation can be done based on meta information associated with the image itself. Simple but effective and efficient indexed method based on explicit hash functions are described in [5].
Much more complicated situation arises, when collection of images comes from variety of non-organized sources, such as the Internet, images collections, surveillance images and videos. In this case, we propose to use B+ tree indexing algorithm [10,11,12].
3 Extended Hybrid Method
3.1 Stored Procedures
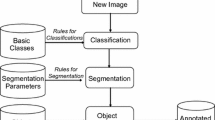
As was described in [4, 5], the hybrid method was intended to combine strengths of both approaches mentioned above. Prior the storage procedure, all images should be annotated automatically. Image processing steps can be described as shown in Fig. 1.

Image processing steps.
The main idea of the method, that the image is associated with physical object(s). The image database stores formal object descriptions (classification) and detailed categorical or numerical attributes of the object.
Annotations needs to be stored in the database for annotations together with links to the images themselves. Annotations should be converted into indexes. For medical, satellite, aerial, industrial, and surveillance databases an explicit expression of hash functions can be formulated. Using explicit formula with just a few arithmetical operations as a hash function is the most effective and efficient choice. Details are presented in [5].
In case of general image collections or for collections with a priory unknown internal logical structures a B+ tree algorithms [10, 11] is a natural choice. Image annotation needs to include the following attributes shown in Fig. 2.

Basic image attributes.
Basic image attributes should be extracted and stored on the highest level of description. Attribute “Scene” will be determined as the result of imaging analysis. Major steps of the process are shown in Fig. 3.

Image processing block diagram of storage procedure.
The following steps need to be implemented to prepare annotation:
-
Image Classification
-
Image Segmentation
-
Object Classification
-
Annotation Generation
3.1.1 Image Classification
Images can be classified according to the image types. Following classes can used [5]:
-
Photographic images
-
Medical images
-
Satellite images
-
Aerial images
-
Industrial images
-
Surveillance images
-
Unstructured and semi structured documents.
Images can be easily classified and automated by identifying the sources where these images are acquired.
3.1.2 Image Segmentation
The major purpose of the annotation process is to understand what kind of object is represented in the image. However, in general case many different objects can be presented simultaneously. It makes the segmentation of image the important step. Image segmentation is a decomposition process, when parts of image with different characteristics are separated from each other. Image segmentation provides data compression also. The techniques for data segmentation are very mature now [13,14,15,16]. However, the segmentation method which is capable of complete automation is still a challenging problem. We plan to use well known methods [13, 14] to segment images. The result of image segmentation will be a plurality of sub-images derived from an original image.
3.1.3 Object Classification
After image is segmented into set of smaller images, each of which contains individual object, these objects should be identified by comparison with examples from database. This step is critical for entire method. There were many attempts to solve this problem for different types of objects [17, 18]. We plan to use multi step hierarchical approach.
The first task is to determine an object class: building, road, person, animal, crowd, and so on. For this purpose, object database contains major features of the objects of a given class. The most popular example is a face recognition. One of the well-known method in this area [19] was tested by us for the case of multiple faces. Some of results of this procedure are shown in Fig. 4.

The areas of human faces are underlined with white circles.
To recognize other objects like mountains, buildings, animals, ships, cars and so on, should be used different algorithms. It is important that these image classification procedures can be automated completely.
3.1.4 Generating Annotations
The last step is to assign individual characteristics to the objects. It is logical to use the tree type structure to store object parameters. Typically, very general objects descriptions are stored on the top level of this structure, and individual categorical and numerical values are stored in the leaves level. The set of individual characteristics and the total number will depend on the types of image. Very often the total number of the characteristics relate to geometries. For example, the dimensions and proportions of an object. There are many different algorithms to determine categorical and numerical values of parameters: neural networks [20], regression [21], logistical regression [22], conditional probabilities approach [23], Markov chains [24], and others. Our experience shows that following methods are most effective in this case: correlation analysis [20], Lucas-Kanade algorithm [25], and conditional probability method [23].
The image description, which is based on the annotation method, can be presented as a set of attributes, such as the types of image or landscape, type of crowd. It could be rural landscape features, urban landscape features, human face or figure features, or other unique characteristics of objects.
3.2 Retrieval Procedures
The procedures described above are done over the query image. Then, the search is performed using two stages: first, search by index, second, search by image itself. This approach allows to reduce processing time dramatically. The choice of index search algorithm depends on the type of images collection. As it was stated above, explicit hash functions can be used for indexing for most cases of structured image data. However, for initially unstructured data, like a random pictures collection, B+ tree approach [11, 12] is the preferred method.
4 Video Database and Super-Resolution Method
Even more complicated case of visual information database is organization and retrieval information from movie collections. Since every individual movie is a set of mages (frames), the size of each individual element is large, and the size of all collection is extremely large. This circumstance requires using special approaches.
There are different kind of queries can be applied in case of a movie database. Queries based on textual information should be processed a traditional way. This option is widely used in our days. Visual based queries should be processed using approaches which are described above. However, there are two important differences are noted comparably with image databases.
First, there is dynamic information available in video databases. That means that some objects are moving and not just object itself but its velocity (or acceleration) could be subject of indexing [26].
Second, the fact that video is a sequence of scene which are slow changed from frame to frame opens new opportunities which were not available in case of static images. The set of frames can be used as input data for super-resolution algorithm [27]. It gives possibility to make query with depicted small object, which barely resolved in each individual frame, but becomes sufficiently resolved due to super-resolution method.
Combination of these two features can make possible to resolve and recognize a small moving object. It could be very useful for analysis of the surveillance camera or to find the image of unknown object, such as UAV (Unmanned Aerial Vehicle), for example.
5 Conclusion and Future Research
In the current paper, we investigate new possibility to construct databases which contain visual information. The description of a new indexing approach which covers the most complex case of unstructured data collection is presented. It was shown, that the data structure for image store - retrieval procedures can be built in general case. It was also shown, that object-based store-retrieval procedures can use already developed image processing functions. We provided examples of these functions.
We also propose a paradigm of the database which contains dynamical visual information. The idea is to apply multi frame super-resolution method to development of store-retrieval procedures with a higher spatial resolution. These procedures are not available on individual frame level and might be used to identify new moving objects. Using Super-Resolution Technique allows to create a database of digital movies with following advanced features comparable with static images:
-
make queries not just about objects, but about objects velocity and acceleration;
-
make query about small objects which are not resolved and recognizable on standalone images.
The future research will be focused on building a prototype of visual database applying principles described in the current paper. We plan to demonstrate that using super-resolution method can provide high resolution store - retrieval procedures capable to work in real time on the modern mass-produced hardware.
References
Xu, L.: Enterprise systems: state-of-the-art and future trends. IEEE Trans. Ind. Inform. 7(4), 630–640 (2011)
Xu, L.: Engineering informatics: state of the art and future trends. Front. Eng. Manage. 1(3), 270–282 (2014)
Xu, L.: Enterprise Integration and Information Architectures. CRC Press (2015). ISBN:978-1-4398-5024-4
Bulysheva, L., Jones, J.: A hybrid model for image databases. In: Proceedings - 2nd International Conference on Enterprise Systems, ES 2014 (2014). https://doi.org/10.1109/es.2014.48
Bulysheva, L., Jones, J., Bi, Z.: A new approach for image databases design. Inf. Technol. Manage. 18(2), 97–105 (2015). https://doi.org/10.1007/s10799-015-0224-6
Liu, Y., Zhang, D., Lu, G., Ma, W.-Y.: A survey of content-based image retrieval with high-level semantics. J. Pattern Recognit. 40(1), 262–282 (2007). https://doi.org/10.1016/j.patcog.2006.04.045
Li, Y.: Object and Content Recognition for content-based Image Retrieval. Ph.D Thesis, Washington University (2005)
Li, Y., Shapiro, G.: Object Recognition for content-based Image Retrieval. Lecture Notes in Computer Science, Washington University (2004)
Oberoi, A., Singh, M.: Content-based image retrieval system for medical databases (CBIR-MD) -lucratively tested on endoscopy, dental and skull images. IJCSI Int. J. Comput. Sci. 9 (2012). ISSN (Online): 1694–0814
Cormen, T., Leiserson, C., Rivest, R., Stein, C.: Introduction to Algorithm. MIT Press, Cambridge (1990)
Zhang, D., Lin, X., Jia, Y.: The volume cutting of three-dimensional image based on B + tree. In: Bioinformatics and Biomedical Engineering (iCBBE), 2010 4th International Conference (2010). doi: https://doi.org/10.1109/ICBBE.2010.5515679
Navathe, R.E., Shamkant, B.: Fundamentals of Database Systems, 6th edn, pp. 652–660. Pearson Education, Upper Saddle River (2010)
Bulyshev, A., Bulysheva, L.: Modeling segmentation algorithm. In: Proceedings of the 3rd World Congress on Software Engineering, WCSE 2012, Wuhan, China, 6–8 November, pp. 5–9 (2012)
Bulysheva, L., Bulyshev, A.: Segmentation modeling algorithm: a novel algorithm in data mining. Inf. Technol. Manage. 13(4), 263–271 (2012). https://doi.org/10.1007/s10799-012-0136-7
Pham, D.L., Xu, C., Prince, J.L.: Current methods in medical image segmentation. Ann. Rev. Biomed. Eng. 2, 315–337 (2000)
Florack, L., Kuijper, A.: The topological structure of scale-space images. J. Math. Imaging Vis. 12(1), 65–79 (2000)
Kumar, A., Kannathasan, N.: A survey on data mining and pattern recognition techniques for soil data mining. IJCSI Int. J. Comput. Sci. Issues 8(3) (2011). ISSN (Online): 1694-0814
Zare, M.R., Mueen, Z., Seng, W.C.: Automatic medical X-ray image classification using annotation. J. Digit. Imaging 27, 77–89 (2014)
Viola, P., Jones, M.: Robust real-time face detection. Int. J. Comput. Vis. 57(2), 137–154 (2004)
Rowley, H., Baluja, S., Kanade, T.: Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 20(1) (1998). https://doi.org/10.1109/34.655647
Dowdy, S., Wearden, S.: Statistics for Research. Wiley, New York (1983)
Dreiseit, S., Ortho-Mochado, L.: Logistic regression and artificial neural network classification models: a methodology review. J. Biomed. Inf. 35(5–6), 352–359 (2002)
Bishop, C.: Pattern Recognition and Machine Learning. Springer, Boston (2006). https://doi.org/10.1007/978-1-4615-7566-5
Chen, X., Yuille, A., Zhu, S.U.: Image parsing: unifying segmentation, detection, and recognition. Int. J. Comput. Vis. 63(2), 113–140 (2005)
Baker, S., Matthews, I.: Lucas-Kanade 20 years on: a unifying framework. Int. J. Comput. Vis. 56(3), 221–255 (2004)
Kotov, A.: Indexing of video flow based of face recognition. Master Thesis, Tomsk State University of Control Systems and Radioelectronics, Tomsk, Russia (2008). (in Russian)
Bulyshev, A., Amzajerdian, F., Roback, V., Hines, G., Pierrottet, D., Reisse, R.: Three-dimensional super-resolution: theory, modeling, and field test results. Appl. Opt. 53(12), 2583–2594 (2014)
Acknowledgments
The authors would like to thanks the IFIP Confenis 2017, General Chairs: Dr. Zhou Zou and Dr. Li Rong Zheng, IFIP WG 8.9 members for making this conference a great success.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 IFIP International Federation for Information Processing
About this paper

Cite this paper
Bulysheva, L., Bulyshev, A., Kataev, M. (2018). Image Database Management Architecture: Logical Structure and Indexing Methods. In: Tjoa, A., Zheng, LR., Zou, Z., Raffai, M., Xu, L., Novak, N. (eds) Research and Practical Issues of Enterprise Information Systems. CONFENIS 2017. Lecture Notes in Business Information Processing, vol 310. Springer, Cham. https://doi.org/10.1007/978-3-319-94845-4_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-94845-4_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-94844-7
Online ISBN: 978-3-319-94845-4
eBook Packages: Computer ScienceComputer Science (R0)