
Abstract
We investigate the task of ad-hoc entity retrieval from a knowledge base. We propose a type taxonomy aware smoothing method that exploits the hierarchical type information of a knowledge base and integrates into an existing language modelling framework. Unlike most existing type-aware retrieval models, our approach does not require an explicit inference of query type. Instead, it directly encodes the type information into a term-based retrieval model by considering the occurrence of query terms in multi-fielded pseudo documents of entities whose types have connections in the type taxonomy. We conduct experiments on a recent public benchmark dataset with the Wikipedia category information. Preliminary experiment results show that our framework improves the performance of existing models.
The work described in this paper is substantially supported by a grant from the Research Grant Council of the Hong Kong Special Administrative Region, China (Project Code: 14203414).
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
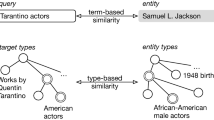
An intelligent search engine should answer either precise or vague queries from users as well as handle diverse types of returned results: documents or entities. An entity is usually described by subject-predicate-object (SPO) triples in structured knowledge base or knowledge graph, as an object that has names, attributes, types and meaningful relations to other entities. Over the past decade, the availability of large-scale knowledge base such as DBpedia or Freebase significantly motivates research in ad-hoc entity retrieval.
Most previous approaches employ standard document retrieval methods which still work under the new setting of entity retrieval via predicate folding [1] that groups fields into several predefined categories based on the type of predicates and generate a pseudo document by aggregating SPO triples in each category. These term-based methods include BM25 [2], language modeling (LM) based ones [1, 3] and its multi-fielded extensions [4]. In recent years, Markov random field based retrieval models that take term dependence into account with well-designed or adaptive fielded representation have shown their effectiveness. These works include sequential dependence model (SDM) [5], fielded sequential dependence model (FSDM) [5, 6] and its parameterized version (PFSDM) [7]. A term-based model has stable empirical performance due to its solid theoretical foundation. However, it is also difficult to improve a term-based model due to its intrinsic limitation in capturing query intents.
It has been shown in the prior work that exploiting type information improves entity retrieval [8]. These studies based on TREC Entity Track [9] and INEX Entity Ranking Track [10] benchmarking platforms assume that the type information is provided by users as part of the definition of the information need. Recent work in this direction such as [11] focused on inference of the query type in a reasonable situation that type information is usually not given explicitly.
An important feature of these type-aware entity retrieval models is that they simply contain two separate component models: type matching model and term matching model. They assume conditional independence between the term-based and type-based components. A type matching model captures the relevance between a query type and an entity type while a term matching model measures the semantic relevance between the query and the pseudo documents of an entity. This paradigm of loose coupling setting has both advantages and disadvantages. On one hand, it simplifies the technical difficulty in a way that the type matching model and term matching model can be developed in different ways. On the other hand, the overall model would generate a biased estimation if any one of them makes an incorrect guess especially when the type matching model receives unreasonable types or an empty type as its input. This strategy ignores the connection between the type information and the text information associated with an entity.
To overcome the disadvantages of term-based and type-aware retrieval models, our model considers the text information and the type information in a unified way. It directly encodes the type information into a term-based retrieval model by considering the occurrence of query terms in multi-fielded pseudo documents of entities whose types have connections in the type taxonomy.
Besides the type-aware entity retrieval, our work is related to forum post retrieval task. The idea of exploiting structure information to improve retrieval accuracy has been proposed in [12], which inspires our model.
2 Model Description
In this section, we first introduce the Mixture of Language Models (MLM) for entity retrieval task which is based on the language modelling framework. Then we discuss our proposed extension for exploiting the type information. After that, we discuss the representation and processing of Wikipedia category information, which is the type taxonomy we consider in the experiment.
2.1 Mixture of Language Models
The Mixture of Language Models (MLM) is one of the state-of-the-art language modelling based models for the entity retrieval task [4]. Given an entity \( E \) and a query \( Q \), the goal of MLM is to score the pseudo documents \( D \) of the entity \( E \) by the ranking function \( f\left( {Q,D} \right) \):
where \( f_{T} \left( \cdot \right) \) is a feature functions for individual terms formulated as follows:
where \( q_{i} \) is the \( i \)-th query term and \( D_{f} \) is the pseudo document in the field \( f \). \( tf_{{q_{i} ,D_{f} }} \) denotes the term frequency of \( q_{i} \) in the \( D_{f} \). The parameters \( w_{f}^{T} \) are weights for each field such that \( \mathop \sum \nolimits_{f} w_{f}^{T} = 1 \). The smoothing parameter \( \mu_{f} \) is set to the average length of the collection in field \( f \). When each entity has only one field, the Mixture of language models degenerates into a standard language model (LM).
2.2 Smoothing by Exploiting Type Information
Following but also simplifying the entity retrieval assumption made in [13], we assume that a user generates an entity-targeted query via selecting several words to describe the types of entities plus some descriptive words. To encode the type information into the language modelling framework, we first consider a scoring function concerning types and find a maximum estimation:
where \( D \) is the pseudo documents of the entity \( E \). \( types\left( D \right) \) is the collection of types that belongs to the entity \( E \).
Due to the nature of language, a query may not always be accurate enough to describe the most specific type of targeted entities. It is natural to consider the ancestors of the type i.e. a path in the type taxonomy. Therefore, we consider path as a variable in the feature functions, which are set as follows:
where \( Paths\left( c \right) \) is the collection of directed paths starting from type \( c \) in the type taxonomy.
To incorporate the relatedness into the term-based retrieval model between a query term and a type path, we add a path-aware smoothing component to the feature function formulated as follows:
where \( V\left( p \right) \) is the vertex set of the path \( p \). The Function \( idx\left( \cdot \right) \) returns the indexing set of the vertex set i.e. the set of indices \( 1 \ldots \left| {V\left( p \right)} \right| \). \( \alpha \) is the reduction coefficient. \( n\left( {a,p} \right) \) is used to normalize the weights \( \left\{ {\alpha^{i} } \right\} \), which equals to \( (1 - \alpha )/(1 - \alpha^{{\left| {V(p)} \right|}} ) \). \( v_{i} \) represents the \( i \)-th vertex in the path \( p \). \( cf_{{ \cdot ,f , v_{i} }} \) is the collection frequency of a query term in the collection of documents in the field \( f \) of entities that share the same type \( v_{i} \) and the smoothing parameter \( \mu_{{v_{i} ,f}} \) is set to the average length of the collection.
2.3 Wikipedia Category Representation and Processing
A Wikipedia category is intended to group together articles on a similar subject. The Wikipedia category system is periodically maintained by editors following the Wikipedia key policies and guidelines to achieve high quality.
By the end of 2015, there are about 1.4 million Wikipedia categories. It is commonly believed that the Wikipedia category system can be represented by a directed acyclic graph (DAG) where each vertex represents a category that connects to its parental categories. However, it is in fact a directed graph that contains many small strongly connected components (SCCs) due to the existence of disambiguation categories and editing errors. To process the category system, two different methods have been proposed in previous literature. The first method simply forces each category connects to single parent category using a heuristic strategy, which results in a tree representation [11]. The second method represents each category as a pair of head word and qualifiers, which transforms the system into a forest by defining a partial order on those pairs [14]. Both of them simplify the structure and show their effectiveness to some extent. In our model, we propose a graph-based approach that keeps the DAG structure of the Wikipedia category system by removing SCCs. We divide the graph into SCCs. For each SCC that is not a single vertex, we find its elementary cycles. A SCC is then reduced by removing common edges shared by intersected elementary cycles or one edge of a sole circle. To reduce computational complexity, a big SCC that contains more than one thousand vertices is dropped directly i.e. all edges in this SCC are removed.
3 Experimental Evaluation
3.1 Experiment Setup
We use DBpedia 2015-10 as our knowledge base along with the DBpedia-entity v2 test collection [15] which contains four query sets (INEX_LD, SemSearch ES, ListSearch and QALD2) with 467 queries in total. We use the same entity representation scheme with five fields: names, attributes, categories, similar entity names and related entity names as described in [5]. We use Python 3.6 and PyLucene 6.5 to implement our model and construct the index. The index contains an extra catchall field that simply aggregates contents of all fields. We use NLTK toolkit to remove stop words of all contents in the index. All index terms are stemmed using the Snowball stemmer. When constructing the graph representation of the Wikipedia category system, we consider the top 5 parental categories for each category in lexicographical order of their names. For each entity, we consider the first 30 categories in Wikipedia editors’ order and the first 500 paths in length 3 in order of depth first search. Moreover, we consider the first 300 articles in lexicographical order of their titles in the collection that shares the same category.
For all experiments, we employ a two-stage retrieval method: First we use Lucene’s default search engine to retrieve top 1000 results as candidates. After that we rank the candidates with the specific retrieval model. The reduction coefficient \( \alpha \) is set to 0.75. We report results for standard language model (LM), MLM-tc concerning the field names and the field attributes with weights 0.2 and 0.8 as well as their variants that consider the type taxonomy aware smoothing method (denoted by identifier ‘TAS’). We also report results from a variant of fielded sequential dependence model (FSDM*) [6] for reference. Following the guideline of the test collection in [15], we report normalized discounted cumulative gain at rank 10 (NDCG@10) as the main evaluation metric using 5-fold cross validation. To measure statistical significance, we employ a two-tailed paired t-test and denote differences at the 0.05 level.
3.2 Experimental Results
Table 1 summarizes retrieval results on the test collection. Our approach helps improve the LM model on all datasets except SemSearch ES. MLM-tc + TAS achieves improvements on all datasets except SemSearch ES. The negative effects brought by our method on SemSearch ES is probably because that most of the queries in this dataset are short and vague that tend to describe a large class of entities related to an entity instead of some distinguishing facts. Consequently, exploring the type paths may not help our model capture their actual intents. Compared to FSDM* which is one of the state-of-the-art models, results of our framework are reasonable. LM + TAS outperforms FSDM* on INEX-LD and their results on ListSearch and QALD2 are almost tied.
4 Conclusions
We propose a type taxonomy aware smoothing method that exploits the hierarchical type information of a knowledge base for entity retrieval. Experiment results show our framework improves the performance of existing models. Future work may include investigating the extension of our method to the MRF based framework and reducing the computational complexity.
References
Neumayer, R., Balog, K., Nørvåg, K.: On the modeling of entities for ad-hoc entity search in the web of data. In: Baeza-Yates, R., de Vries, A.P., Zaragoza, H., Cambazoglu, B.B., Murdock, V., Lempel, R., Silvestri, F. (eds.) ECIR 2012. LNCS, vol. 7224, pp. 133–145. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-28997-2_12
Tonon, A., Demartini, G., Cudré-Mauroux, P.: Combining inverted indices and structured search for ad-hoc object retrieval. In: Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 125–134 (2012)
Elbassuoni, S., Blanco, R.: Keyword search over RDF graphs. In: Proceedings of the 20th ACM International Conference on Information and Knowledge Management, pp. 237–242 (2011)
Neumayer, R., Balog, K., Nørvåg, K.: When simple is (more than) good enough: effective semantic search with (almost) no semantics. In: Baeza-Yates, R., de Vries, A.P., Zaragoza, H., Cambazoglu, B.B., Murdock, V., Lempel, R., Silvestri, F. (eds.) ECIR 2012. LNCS, vol. 7224, pp. 540–543. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-28997-2_59
Zhiltsov, N., Kotov, A., Nikolaev, F.: Fielded sequential dependence model for ad-hoc entity retrieval in the web of data. In: Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 253–262 (2015)
Hasibi, F., Balog, K., Bratsberg, S. E.: Exploiting entity linking in queries for entity retrieval. In: Proceedings of the 2016 ACM on International Conference on the Theory of Information Retrieval, pp. 209–218 (2016)
Nikolaev, F., Kotov, A., Zhiltsov, N.: Parameterized fielded term dependence models for ad-hoc entity retrieval from knowledge graph. In: Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 435–444 (2016)
Balog, K., Neumayer, R.: Hierarchical target type identification for entity-oriented queries. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, pp. 2391–2394 (2012)
Balog, K., de Vries, A., Serdyukov, P., Westerveld, T., Thomas, P.: Overview of the TREC 2009 entity track (2009)
de Vries, A.P., Vercoustre, A.-M., Thom, J.A., Craswell, N., Lalmas, M.: Overview of the INEX 2007 entity ranking track. In: Fuhr, N., Kamps, J., Lalmas, M., Trotman, A. (eds.) INEX 2007. LNCS, vol. 4862, pp. 245–251. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-85902-4_22
Garigliotti, D., Balog, K.: On type-aware entity retrieval. arXiv preprint arXiv:1708.08291. (2017)
Duan, H., Zhai, C.: Exploiting thread structures to improve smoothing of language models for forum post retrieval. In: Clough, P., Foley, C., Gurrin, C., Jones, Gareth J.F., Kraaij, W., Lee, H., Mudoch, V. (eds.) ECIR 2011. LNCS, vol. 6611, pp. 350–361. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-20161-5_35
Lu, C., Lam, W., Liao, Y.: Entity retrieval via entity factoid hierarchy. In: ACL, vol. 1, pp. 514–523 (2015)
Chen, Y., Gao, L., Shi, S., Du, X., Wen, J.R.: Improving context and category matching for entity search. In: AAAI, pp. 16–22 (2014)
Hasibi, F., Nikolaev, F., Xiong, C., Balog, K., Bratsberg, S.E., Kotov, A., Callan, J.: DBpedia-entity v2: a test collection for entity search. In: Proceedings of SIGIR, vol. 17 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Lin, X., Lam, W. (2018). Entity Retrieval via Type Taxonomy Aware Smoothing. In: Pasi, G., Piwowarski, B., Azzopardi, L., Hanbury, A. (eds) Advances in Information Retrieval. ECIR 2018. Lecture Notes in Computer Science(), vol 10772. Springer, Cham. https://doi.org/10.1007/978-3-319-76941-7_75
Download citation
DOI: https://doi.org/10.1007/978-3-319-76941-7_75
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-76940-0
Online ISBN: 978-3-319-76941-7
eBook Packages: Computer ScienceComputer Science (R0)