
Abstract
NER which is known as Named Entity Recognition is an application of Natural Language Processing (NLP). NER is an activity of Information Extraction. NER is a task used for automated text processing for various industries, a key concept for academics, artificial intelligence, robotics, Bioinformatics and much more. NER is always an essential activity when dealing with chief NLP activity such as machine translation, question-answering, document summarization etc. Most NER work has been done for other European languages. NER work has been done in few Indian constitutional languages. Not enough work is possible due to some challenges such as lack of resources, ambiguity in language, morphologically rich and much more. In this paper, to identify various named entities from a text document, rules are defined using Rule-based approach. Based on defined rules, three different test cases computed on the training dataset and achieved 70% of accuracy.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
The phrase Named Entity (NE) was coined during the 6th Message Understanding Conference (MUC-6) in 1995. Many NER systems were developed after that. Foremost work has been done in European languages and all systems were highly precise [6]. Named Entity is the structured information mentioning to predefined proper names like persons, locations, and organizations, year, date, month, monetary amounts, percentages as well as temporal and numeric expressions from text [2].
Named Entity Recognition (NER) systems proved to be very significant for many tasks in Natural Language Processing (NLP) such as information retrieval, machine translation, information extraction, question answering systems. The objectives of NER is to classify each word of a document into predefined target named entities classes.
1.1 Existing NER Approaches
Present NER systems have been built using mainly knowledge-based or linguistic, and machine learning approach.
1.1.1 Rule-Based Approach
The linguistic approach or Knowledge-based approach is basically called as a rule-based approach which uses a set of hand-crafted rules deliberate and described by human experts, especially linguists. This approach considers a set of patterns containing grammatical, syntactic, linguistic and orthographic features in a grouping with dictionaries. It is a prerequisite to have a thorough knowledge of target language as it is a time-consuming task to develop such kind of system.
1.1.2 Statistical Approach
Machine Learning or a Statistical approach is a swift way to build an NER system which fundamentally supports rule-based systems or use sequence labeling algorithms to collect knowledge from a collection of training examples. The accuracy of this approach is purely dependent upon the training dataset. Various Machine Learning models used for NER systems like Hidden Markov Model, Conditional Random Field, and Maximum Entropy.
1.1.3 Hybrid System
Use of Statistical tools as well as linguistic rules and combinations of both approaches make a system more precise and effective.
1.2 About the Gujarati Language
Basically, Among the Indo-European language family, Gujarati is well-known Indo-Aryan language and it was tailored from the Devanagari script. Alphabets of this language mainly include 34 consonants and 14 vowels. [1] A language is very widespread and spoken by more than 50 million people across the India. It is the official language of the Gujarat state of India.
2 Related Work on Different Indian Languages in NER
Among the constitutional Indian languages, NER work has been done in some languages. NER approaches used in various Indian languages with their accuracies are mentioned in Table 1 as follows:
3 Rule-Based Approach
A morphological analyzer for the Hindi language analyze Hindi sentences and produce its features with its root words. [7] As Rule-based approach is a domain specific, rules define for one language will not apply for other languages. Some Rules used to identify different tags in the Gujarati language are as follows:
3.1 Date and Time
This Rule is applied on given input which contains the various date and Time formats. Regular Expressions are used to identify these kinds of tags [15]. Following are date and time tagset examples:
3.1.1 Year 

-
 (Samvat) refers to the epoch of the several Hindu calendar systems in India and also in Nepal. There are three most significant
(Samvat) refers to the epoch of the several Hindu calendar systems in India and also in Nepal. There are three most significant  (Samvat): Vikrama era, Old Shaka era and Shaka era of 78 AD [15].
(Samvat): Vikrama era, Old Shaka era and Shaka era of 78 AD [15].
 (Samvat) refers to the epoch of the several Hindu calendar systems in India and also in Nepal. There are three most significant
(Samvat) refers to the epoch of the several Hindu calendar systems in India and also in Nepal. There are three most significant  (Samvat): Vikrama era, Old Shaka era and Shaka era of 78 AD [
(Samvat): Vikrama era, Old Shaka era and Shaka era of 78 AD [3.1.2 Month Names
-


-
The names of the Indian months diverge by region. Hindu calendars are based on lunar cycle and usually phonetic variants of each other.
-

 [15].
[15].



 [
[3.1.3 Days

The Hindu calendar has two measures of a day, one based on the lunar movement and the other on solar. The solar day or civil day is called divas  and the lunar day is called tithhi (
and the lunar day is called tithhi ( ). A lunar month has 30 tithhi. Lunar month starts with Kartak (
). A lunar month has 30 tithhi. Lunar month starts with Kartak ( ).
).



 [16].
[16].
3.2 Location
Suffix matching is used for types of location names and terms. Different suffix makes different location names of Indian States and Cities are as follows: [17]
-
Location names that end with ‘pure’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘Ghar’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘stan’ (
 ) i.e. -
) i.e. - 

-
Location names that end with ‘bad’ (
 ) i.e. –
) i.e. – 

-
Location names that end with ‘Nagar’ (
 ) i.e. –
) i.e. – 

-
Location names that end with ‘pat’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘nath’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘mer’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘kot’ (
 ) i.e. -
) i.e. - 
-
Location names that end with ‘Ishwar’ (
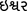 ) i.e. -
) i.e. - 

-
Location names that end with ‘Wada’ (
 ) i.e. -
) i.e. - 

-
Location names that end with ‘giri’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘Puram’ (
 ) i.e. –
) i.e. – 

-
Location names that end with ‘uru’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘patnam’ (
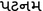 ) i.e. –
) i.e. – 

-
Location names that end with ‘guri’ (
 ) i.e. –
) i.e. – 

-
Location names that end with ‘tal’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘Dwar’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘Wada’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘Palli’ (
 ) i.e. –
) i.e. – 
-
Location names that end with ‘Malai’ (
 ) i.e. –
) i.e. –  ,
, 
 ) i.e. -
) i.e. - 
 ) i.e. -
) i.e. - 
 ) i.e. -
) i.e. - 

 ) i.e. –
) i.e. – 

 ) i.e. –
) i.e. – 

 ) i.e. -
) i.e. - 
 ) i.e. -
) i.e. - 
 ) i.e. -
) i.e. - 
 ) i.e. -
) i.e. - 
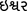 ) i.e. -
) i.e. - 

 ) i.e. -
) i.e. - 

 ) i.e. –
) i.e. – 
 ) i.e. –
) i.e. – 

 ) i.e. –
) i.e. – 
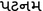 ) i.e. –
) i.e. – 

 ) i.e. –
) i.e. – 

 ) i.e. –
) i.e. – 
 ) i.e. –
) i.e. – 
 ) i.e. –
) i.e. – 
 ) i.e. –
) i.e. – 
 ) i.e. –
) i.e. –  ,
, 
3.3 To Identify Some Abbreviations in Date and Time Tag Entities
Abbreviations point to an original name. Some words used in their abbreviated form for a date, month and year entities. Examples: 
 [15].
[15].
3.4 For Numerals
There is a difference between mentioning numbers. Two types of number system we used: Hindu Arabic Numerals and Gujarati Numerals. Numbers have different number names in different languages. Number 0 to 100 written in both format is different and their Gujarati names also [18] (Table 2).
4 Research Methodology
We have developed various rules using a rule-based approach which helps to recognize various named entities. For Identification of Named Entity, we have collected document in the Gujarati language as a corpus from E-newspaper ‘Gujarat Samachar’. There are various categories of news as Entertainment, Sports, Religious and much more. Among them, we have gathered 100 sports category documents to identify various Named Entity tagset.
-
A.
Preparation of Database
Based on various categories of tagset, following dictionaries are created.
Date Dictionary: Date tagset contains Day, Month number and name, and Year. The day is also categorized based on Hindu calendar and Panchang ( ). Tithis (
). Tithis ( ) and days (
) and days ( ) stored in gazetteer list.
) stored in gazetteer list.
Location Dictionary: Here Location names are only within a limited range of area or for a specific country. 21 Suffix stripping rules are created for Location Names as City or State or Village names of India.
Abbreviation Dictionary: Various abbreviations of date, month, day are listed in it.
Number-names dictionary: Based on Hindu-Arabic numerals, Gujarati number names listed for 0 to 100 digits (Fig. 1).

Flowchart for Rule based NER for Gujarati language
-
B.
Architecture of System
-
Step – 1 Input text - Through file upload, upload a file which is a text file comprising raw data in the Gujarati language.
-
Step – 2 Preprocessing – Prepare Gujarati text document for preprocessing.
-
Step – 3 Tokenization - Input text tokenized word by word for pattern matching.
-
Step – 4 Entity detection - Detection of Date, Time and Location entities based on created rules and if any rules matched go to step 7.
-
Step – 5 Detection of Abbreviation Names, if matches are found and compared with gazetteer list, go to step 7.
-
Step – 6 Detection of Numbers and its Number names from Non-numerals practice and if found any matches then go to step 7.
-
Step – 7 Display tagged output generated by the system with the untagged result to the user.
-
Step – 8 End
5 Experimental Result and Analysis
The core objectives of such experiment are to identify the kinds of patterns of named entities by the proposed NER algorithm. We have collected documents of Sports category to recognize various Named Entities such as date, Day names, Month Names, Tithhi ( ), Location and numerals (Table 3).
), Location and numerals (Table 3).
Among the given 363 words, 194 entities are correctly identified by applying various test cases and achieved 70% of accuracy.
6 Conclusions
An innovative technique can be build up to develop the performance of NER in the Gujarati language. We have developed rules to identify various named entities which is a very beneficial in many significant applications. We have studied various existing approaches of NER and analyzed that among the various constitutional Indian languages, lots of scopes is for NER in Indian languages. By implementing various rules on given dataset we attained 70% of accuracy. As a future work, we can build more precise rules for much more named entities to achieve good accuracy.
References
Athavale, V., Bharadwaj, S., Pamecha, M., Prabhu, A., Shrivastava, M.: Towards Deep Learning in Hindi NER: An approach to tackle the Labelled Data Scarcity (2016)
Jiandani, K.S.D., Bhattacharyya, P.: Hybrid inflectional stemmer and rule-based derivational stemmer for Gujarati. In: Proceedings of the 2nd Workshop on South and Southeast Asian Natural Language Processing (WSSANLP 2011), November 2011
Amarappa, S., Sathyanarayana, S.V.: Kannada named entity recognition and classification (nerc) based on multinomial naïve Bayes (MNB) classifier. Int. J. Nat. Lang. Comput. (IJNLC) 4, 39–52 (2015)
Alfred, R., Leong, L.C., On, C.K., Anthony, P.: Malay named entity recognition based on rule-based approach. Int. J. Mach. Learn. Comput. 4(3), 300–306 (2014)
Sathyanarayana, S.A.: A hybrid approach for named entity recognition, classification and extraction (NERCE) in Kannada documents. In: Proceedings of International Conference on Multimedia Processing, Communication, and Info. Tech., MPCIT (2013)
Singh, A.K.: Named entity recognition for south and south east asian languages: taking stock. In: Proceedings of the IJCNLP Workshop on NER for South and South East Asian Languages, pp 5–16 (2008)
Agarwal, A., Singh, S.P., Kumar, A., Darbari, H.: Morphological analyser for hindi-a rule-based implementation. Int. J. Adv. Comput. Res. 4(1), 19 (2014)
Sharma, L.K., Mittal, N.: Named entity based answer extraction from hindi text corpus using n-grams. In: 11th International Conference on Natural Language Processing, p. 362, December 2014
Sasan, T.S., Jamwal, S.S.: Transliteration of name entities using rule-based approach. Int. J. Adv. Res. Comput. Sci. Soft. Eng., 6(6) (2016)
Jahan, N., Morwal, S., Chopra, D.: Named entity recognition in Indian languages using gazetteer method and hidden Markov model: a hybrid approach. IJCSET, March 2012
Abinaya, N., Kumar, M.A., Soman, K.P.: Randomized kernel approach for named entity recognition in Tamil. Indian J. Sci. Technol. 8(24), 1–7 (2015)
Kaur, Y., Kaur, E.: Named Entity Recognition system for Hindi Language using a combination of rule-based approach and list lookup approach. Int. J. Sci. Res. Manag. (IJSRM) 3(3), 2300–2306 (2015)
Aboaoga, M., Ab Aziz, M.J.: Arabic person names recognition by using a rule-based approach. J. Comput. Sci. 9(7), 922 (2013)
Bhalla, D., Joshi, N., Mathur, I.: Rule-based transliteration scheme for English to Punjabi (2013)
To download. Guj-Ind-StyleGuide. http://download.microsoft.com/download/7/2/0/720b015e-94f9-4b6e-911f-539f38c60774/guj-ind-styleguide.pdf
Tithi (Internet). https://en.wikipedia.org/wiki/Tithi
Indian Place Names (Internet). http://www.irfca.org/docs/place-names.html
Gujarati Number names for Digits (Internet). https://www.omniglot.com/language/numbers/gujarati.htm
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Shah, D.N., Bhadka, H.B. (2018). Named Entity Recognition from Gujarati Text Using Rule-Based Approach. In: Abraham, A., Muhuri, P., Muda, A., Gandhi, N. (eds) Intelligent Systems Design and Applications. ISDA 2017. Advances in Intelligent Systems and Computing, vol 736. Springer, Cham. https://doi.org/10.1007/978-3-319-76348-4_76
Download citation
DOI: https://doi.org/10.1007/978-3-319-76348-4_76
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-76347-7
Online ISBN: 978-3-319-76348-4
eBook Packages: EngineeringEngineering (R0)