
Abstract
This paper proposes a multi-region WR-Inception network model for face detection based on the Faster RCNN framework. Firstly, we utilize multi-region features to obtain better face representation and introduce block loss to enable our model to be robust to occluded faces. Then we adopt WR-Inception network with shallower and wider layers as our base feature extractor. Finally, we apply a new pre-training strategy to learn representation more suitable for face detection, and exploit soft-nms for the post processing. Specially, experimental results show that our method achieves recall rate of 85.1% on FDDB dataset.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Face detection is a classical problem in computer vision, which has been widely studied over the past few decades. However, due to large variations in pose, blur, occlusion and illumination condition, face detection is still confronted with some challenges. Recently, Faster RCNN [1] and its improvement have been demonstrated impressive performance on object detection. Jiang and Learned-Miller [2] just trained a Faster RCNN model and achieved the state-of-the-art performance on FDDB benchmark [3]. Besides, Xiaomi [4] exploited the idea of hard negative mining and iteratively update the Faster RCNN based face detector, and also achieved prominent success. Instead of adding some tricks of training based on Faster RCNN for face detection, this paper proposed a multi-region WR-Inception network model for face detection based on the Faster RCNN framework. Firstly, we utilized multi-region features in Sect. 2.1 to obtain better face representation, and introduced block loss in Sect. 2.2 to enable our model to be robust to occluded faces. Then we adopted WR-Inception network [5] with shallower and wider layers as our base feature extractor. Finally, we applied a new pre-training strategy to learn representation more suitable for face detection, and exploited soft-nms for the post processing. Specially, experimental results show that our method can not only cope with faces with small scale and pose variations, but also handle occlusion and blur.
The rest of this paper is organized as follows: Sect. 2 describes our face detector in details. Experimental settings and results are presented in Sect. 3. And conclusions of our paper are drawn in Sect. 4.
2 The Proposed Method
Compared with hand-crafted design pipeline of traditional computer vision approaches, deep learning methods could automatically extract better features from data, and achieve the state-of-the-art performance in many computer vision tasks. One of the lessons learned from this is that feature matters a lot in computer vision. And based on this, better face representation of our method is obtained from two aspects: (1) multi-region features and block loss (2) adoption of WR-Inception network and concatenation of features. The following will discuss the procedure in details.
2.1 Multi-region Feature Extractor
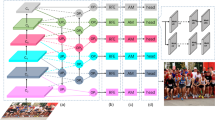
For face detection, face representation should capture not only whole appearance of a face but distinct appearance of different face parts and contextual appearance. And we believe that such rich representation would help face detector to improve performance under complex conditions. In order to achieve this, we proposed a multi-region model including six regions, each of which focused on a different part of a face to collect discriminative face representations. We will describe six regions in Fig. 1.

Illustration of six regions used in our model (Red rectangles represent the original RoI, and green rectangles represent the regions proposed in this paper) (Color figure online)
Details and roles of six regions above are described as follows:
-
(1)
Original RoI: it is obtained by RPN network in Faster RCNN framework. And it could guide model to capture the whole appearance information of the whole face.
-
(2)
Contextual region: it is obtained by scaling the original RoI by factor of 2. And it could guide model to capture the contextual appearance information that surrounds a face, which aims to make the representation more robust to small faces.
-
(3)
Half part regions: they are up/bottom/left/right half parts of the original RoI. They could guide model to capture the appearance information of each half part of a face, which aims to make the representation more robust to faces with occlusion.
Features consisted by six regions above combine local information with contextual information to gain richer face representation. And experimental results in Sect. 3 show that it helps our method to achieve good performance on face detection under unconstrained conditions.
2.2 Block Loss in Our Face Detector
Due to information loss by occlusion, problem of partially occluded faces is still challenging in detection. And detection of a partially occluded face heavily relies on positive response of its certain parts. Therefore, inspired by Opitz et al. [6] we regard (c)(d)(e)(f) in Fig. 1 as four blocks, which would produce positive response for a face. And margin of each block is set to 0.5, which weights the discrimination of the block to the whole RoI. Block loss is defined in function (1).
where \( z_{i} \) is output of our model corresponding to block i. \( y_{j} \in \{ 0,1\} \) denotes the class label of the RoI (whether it contains any face or not).
Due to negative responses of certain blocks corresponding to less discriminative face parts, we also need to utilize output of the whole RoI for holistic classification. Therefore, we concat features of region (a) (original RoI) and region (b) (contextual region) for holistic classification. And our final classification loss is defined as follows:
where \( \eta \) weights the block classifiers vs. the holistic classifier and is set to 1. Compared with direct division of the RoIs in [6], we adopted four blocks to form more block classifiers and help our model to pay more attention on less discriminative blocks. Experiments in Sect. 3 show that this strategy helps our model to be robust to faces with occlusion.
2.3 Our Whole Model
For feature extraction network, we adopted WR-Inception-l2 [5] with shallower and wider layers, which captured objects in various sizes on the same feature map based on a residual inception structure. Meanwhile, we concatenated features of conv3_2 and conv4_4 for multi-scale representation.
After feature extraction and obtaining RoIs by RPN network, we can get two 7 × 7 × 384-dimensional feature maps corresponding to (a) and (b) in Fig. 1 for every RoI, and we shared the weights between region (a)(b) and other four regions (c)(d)(e)(f) on account of runtime and memory. And finally we fed them into our model as follows (Fig. 2):

Our multi-region model with WR-Inception network as feature extraction network
3 Experiments
3.1 Experimental Settings
New Pre-training Strategy.
Due to millions of parameters of network, it is common for detection task to carry out pretraining on large-scale image classification data and then to finetune on detection datasets. However, difference between classification task and detection task leads to less effective pretraining. For classification task, which recognizes the object within an image, learned features would be robust to change on location and size of the object. However, detection task not only recognizes the object within an image but also locate where the object is, which requires learned features to be sensitive to change on location and size of the object. Therefore, for pretraining of our network, we replaced image classification data with face recognition database after alignment to focus on better face representation.
We choose casia webface database [7] which contains 10,575 subjects and 494,414 images for the pretraining. Ratio of training set and validation set is 9:1. And all faces without alignment were cropped and resized into 100 × 100 as input of our network. And in training process, we adopted SGD with a batch size of 32 and momentum of 0.9. The learning rate was initially set to 0.01. And our model performed 1M iterations. And effect of new pre-training strategy is shown in Fig. 3.

Illustration of effect of new pre-training strategy ((a) is an image from FDDB dataset, and (c) is cropped from (a). (b) and (d) are corresponding visualization of feature maps of (a) and (c) after our feature extraction network)
As shown in Fig. 3, model pretrained on our new pre-training strategy is able to represent face with different size and location, which could help our detector to get tight box for the face.
Finetuning Strategy.
Our model was finetuning with training set of WIDER face dataset [8], which contains 12,880 images and 159,424 faces. Experimental settings of fine-tuning were set as follows: (1) Restricting fg/ bg ratio for RPN. The number of negative samples is no more than 1.5 times of the number of positive ones to further mitigate data imbalance; (2) New scales for WIDER face dataset. We used 4 scales (64, 128, 256, 512) for WIDER face dataset, leading to k = 12 anchors at each location. Then we re-scaled the images such that their shorter side is 600 pixels, and limited the maximum side to 1000 pixels. Our face detector was trained for 60 k iterations with a base learning rate of 0.0001 which is reduced by 10 times for every 20 k iterations.
3.2 Experimental Results
Test stage.
We took FDDB [3] dataset as test sets. FDDB dataset, which has in total 5,171 faces with occlusions, difficult poses, and various scene in 2,845 images, is released with rich annotation and a standard performance evaluation scheme for face detection. We adopted soft-nms [9] for the post processing. And comparisons of experimental results are conducted on FDDB dataset.
Analysis of Experimental Results.
Firstly, we compared the performance of our model with and without multi-region features and block loss on FDDB dataset in Table 1.
Table 1 illustrates that multi-region features and block loss lead to richer representation of images and it outperforms the model without adding them.
Then we compared the performance of our model with other state-of-the-art face detectors on FDDB dataset. In particular, we compared recall rate of our method with XZJY [10], PEP-Adapt [11], Face++ [12], and DDFD [13] in Table 2. True positive rate-False positive curve is shown in Fig. 4.

Comparison of performance of our model with other state-of-the-art face detectors
Some detection results are shown in Fig. 5.

Some detection results of our face detector on FDDB dataset
Table 2 and Fig. 4 illustrate our method illustrate that our method outperforms other state-of-the-art face detectors and achieves great improvements of face detection under unconstrained conditions. Detection results in Fig. 5 show that our method can not only cope with faces with small scale and pose variations, but also handle occlusion and blur.
4 Conclusion
This paper proposed a multi-region WR-Inception network model for face detection based on the Faster RCNN framework. Specially, we adopted multi-region features, block loss, WR-Inception network and new pre-training strategy to obtain better face representation, which helped our face detector to be robust to faces with small scales, heavy occlusion, blur and other complex situations. Experimental results show that our method achieves recall rate of 85.1% on FDDB dataset.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
Ren, S., He, K., Girshick, R., et al.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2015)
Jiang, H., Learned-Miller, E.: Face detection with the faster R-CNN. arXiv preprint arXiv:1606.03473 (2016)
Jain, V., Learned-Miller, E.: Fddb: a benchmark for face detection in unconstrained settings. UMass Amherst Technical report (2010)
Wan, S., Chen, Z., Zhang, T., et al.: Bootstrapping Face Detection with Hard Negative Examples. arXiv preprint arXiv:1608.02236 (2016)
Lee, Y., Kim, H., Park, E., et al.: Wide-Residual-Inception Networks for Real-time Object Detection. arXiv preprint arXiv:1702.01243 (2017)
Opitz, M., Waltner, G., Poier, G., Possegger, H., Bischof, H.: Grid loss: detecting occluded faces. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 386–402. Springer, Cham (2016). doi:10.1007/978-3-319-46487-9_24
Yi, D., Lei, Z., Liao, S., et al.: Learning face representation from scratch. arXiv preprint arXiv:1411.7923 (2014)
Yang, S., Luo, P., Loy, C.C., et al.: Wider face: a face detection benchmark. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, pp. 5525–5533. IEEE Press, United States (2016)
Bodla, N., Singh, B., Chellappa, R., et al.: Improving Object Detection with One Line of Code. arXiv preprint arXiv:1704.04503 (2017)
Shen, X., Lin, Z., Brandt, J., et al.: Detecting and aligning faces by image retrieval. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3460–3467. IEEE Press, United States (2013)
Li, H., Hua, G., Lin, Z., et al.: Probabilistic elastic part model for unsupervised face detector adaptation. In: 2013 IEEE International Conference on Computer Vision and Pattern Recognition, pp. 793–800. IEEE Press, United States (2013)
Face++. https://www.faceplusplus.com/
Farfade, S.S., Saberian, M.J., Li, L.J.: Multi-view face detection using deep convolutional neural networks. In: Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, pp. 643–650. ACM, China (2015)
Acknowledgment
This work is supported by the Fundamental Research Funds for the Central Universities (Grant No. N160504007) and supported by the National Natural Science Foundation of China (Grant No. 31301086).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Yang, L., Li, Y., Duan, X., Zhang, X. (2017). Face Detection with Better Representation Using a Multi-region WR-Inception Network Model. In: Zhou, J., et al. Biometric Recognition. CCBR 2017. Lecture Notes in Computer Science(), vol 10568. Springer, Cham. https://doi.org/10.1007/978-3-319-69923-3_17
Download citation
DOI: https://doi.org/10.1007/978-3-319-69923-3_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-69922-6
Online ISBN: 978-3-319-69923-3
eBook Packages: Computer ScienceComputer Science (R0)