
Abstract
Breast cancer is one of the most commonly diagnosed cancer in women worldwide, and is commonly diagnosed via histopathological microscopy imaging. Image analysis techniques aid physicians by automating some tasks involved in the diagnostic workflow. In this paper, we propose an integrated model that considers images at different magnifications, for classification of breast cancer histopathological images. Unlike some existing methods which employ a small set of features and classifiers, the present work explores various joint colour-texture features and classifiers to compute scores for the input data. The scores at different magnifications are then integrated. The approach thus highlights suitable features and classifiers for each magnification. Furthermore, the overall performance is also evaluated using the area under the ROC curve (AUC) that can determine the system quality based on patient-level scores. We demonstrate that suitable feature-classifier combinations can largely outperform the state-of-the-art methods, and the integrated model achieves a more reliable performance in terms of AUC over those at individual magnifications.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
- Histopathological images
- Joint colour-texture features
- Receiver operating characteristics (ROC)
- Area under the ROC curve (AUC)
1 Introduction
Breast cancer (BC) is the most common type of cancer and the fifth most common cause of cancer mortality among women globally [1]. While, different types of imaging technologies, have been employed for diagnosis of BC, histopathology biopsy imaging has been a ‘gold standard’ in diagnosing breast cancer because it captures a comprehensive view of effect of the disease on the tissues [2].
However, image examination by pathologists is often subjective and may not be easily quantified. Thus, computer-aided diagnosis (CADx) systems provide valuable assistance for physicians and specialists. These help in overcoming the subjective interpretation and relieve some workload of pathologists. An important part of such CADx systems is the automation of image analysis to determine whether a tissue sample is malignant or a benign. Due to automated image analysis some tasks involved in diagnostic workflow can be made more efficient and precise.
However, automated image analysis can be challenging as inconsistency in histopathology slide preparation such as differences in fixation, staining protocol, non-standard imaging condition, etc. can cause variability in tissue appearance (colour and texture). The texture variation is typically captured by classifiers employing traditional texture features. To mitigate the effect of colour variability, a straightforward approach is to use gray-scale images [3, 4]. On the other hand, a stain (or colour) normalization preprocessing can be performed, which is typically a more sophisticated process involving methods such as histogram matching, colour transfer, colour map quantile matching approach and spectral matching etc. [5, 6].
However, it is observed that some inter-image colour variation might be informative [5]. Similarly, recent research in digital histopathology has indicated significance of colour information in quantitative analysis on histopathology [7, 8]. As can be seen from Fig. 1, along with texture, colour information is also available in images which can be utilized to get a more discriminating representation.

Sample of histopathological images (first row: benign tumor, second row: malignant tumor) from BreakHis dataset at magnification factor of 40X.
From a machine learning perspective, various methods which do not employ normalization have also been proposed [9,10,11]. Our proposed method falls in this category where features are directly extracted from image (without normalization). This follows the philosophy that instead of reducing the colour variation, we learn the colour variation (along with the texture variation) as a part of the classification process.
We believe that the colour-texture variability can be better captured with joint colour-texture features [12]. Such features consider the mutual dependency between colour channels and texture information. These features can be defined with individual colour channels, or with correlated pairs of colour channels. Such jointly defined colour-texture features can locally adapt to the variation in the image content [13].
In addition, different from existing works where a small set of classifier was utilized, here a total of 22 classification frameworks experimented with. These classification frameworks include Quadratic Discriminant, Subspace Discriminant, RUSBoosted Trees, Boosted Tree, Coarse Gaussian SVM, Weighted KNN etc. We argue that such an exploration of joint colour-texture features and various classifiers leads to the selection of better suited features and classifiers to this specific problem. Due to space-constraints, we report the features and classifiers which correspond to top five results for each image magnification.
1.1 Related Work
In recent years, a number of methods have been investigated for BC histopathology classification. However, most of these method use traditional morphology and texture features. Kowal et al. [14] utilized four different clustering algorithms for nuclei segmentation and extracted 21-dimensional feature vector. In [14], three different classifiers are reported for each clustering algorithm separately. This s carried out on a dataset which contained 500 images of cytological samples that were extracted from 50 patients. Filipczuk et al. [15] presented a diagnosis system where nuclei were estimated by the Hough transform. Four different classifiers trained on 25-dimensional feature vector was used for classification using 737 images of cytological sample which had drawn from the same place as [14]. Based on above discussed methods, it is realized that for accurate system nuclei should be segmented properly as subsequent analysis is based on segmentation. However, segmentation of histological images is not a trivial task and is prone to mistakes. Instead of relying on the accurate segmentation, [16] investigated multiple image descriptors along with random subspace ensembles and proposed two-stage cascade framework with a rejection option using a dataset composed of 361 images. In another work [17], an ensembles of one-class classifiers were assessed by the same authors on the same dataset.
The works in [9, 10] also propose the use colour information in addition to texture. Milagro et al. [9] combinations of traditional texture features and colour spaces is considered. Furthermore, they have also considered different classifiers such as Adaboost learning, bagging trees, random forest, Fisher discriminant and SVM. In [10], authors utilized colour and differential invariants to assign class posterior probabilities to pixels and then performs a probabilistic classification. While our intuition of using colour information and a set of classifiers is similar to [9], our integrated joint colour-texture features also consider dependency between colour channels and texture, rather than extracting traditional texture features independently from colour channels. Moreover, unlike ours, and similar to the above discussed works, [9, 10] do not consider experimentation with respect to different optical magnifications, which is an important aspect [4]. Furthermore, we report our results on a public benchmark dataset, unlike all the above approaches.
With regards to the concern of benchmarking, it has been observed that the dataset used in the above works are not publicly available to the scientific community, and such datasets contain rather small number of images. Spanhol et al. [4] introduced the BreakHis dataset which intended to take away the impediment of publicly available data set. The BreakHis dataset contains fairly large amount of microscopic biopsy images (7909) that were collected from 82 patients in four different magnifications (40x, 100x, 200x, 400x). The details of dataset are provided in Table 1. Figure 1 shows the images of benign and malignant tumor given in different magnifications.

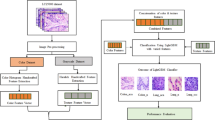
An Integrated model for BC image classification.
In the same study, a series of experiments utilizing six different texture descriptors and four different classifiers were evaluated and showed the accuracy at patient-level. In [18], Alexnet [19] was used for extracting features, and classification was reported on image-level as well as patient-level, using this dataset. Bayramoglu at el. [20] proposed a magnification independent model utilizing deep learning and reported accuracies for both multi-task network which predicts magnification factor and malignancy (benign/malignant) simultaneously, and single task network which predicts malignancy.
1.2 Salient Aspects of This Work
Considering that the area of BC histopathology image analysis is still an emerging one, as new approaches are developed, the evaluation and comparison among such frameworks is of increasing importance from a clinical perspective. In this context we consider the following aspects about methodology and evaluation which drives our work.
-
(a)
As implied above, there is scope for further exploration of suitable features and classifiers for this problem, which can better capture the discriminative information to address the classification task. Thus, in this work we look into employing joint colour-texture features for this task. Motivated from [4], where conventional texture features (GLCM, CLBP, PFTAS etc.) along with small set of well known classifiers were utilized, in this work we explore a relatively larger set of classifiers for the joint-color texture features. This provides their comparative performance under one roof, and indeed, for some classifiers we demonstrate an improved performance over the state-of-the-art.
-
(b)
The above discussed methods yield a continuous value for a scoring, rather than single value for making decisions. In the discussed methods [4, 18], patient and image level score were used as performance measures. However, it is also important to convert a patient score to a decision (benign or malignant), using a decision threshold on the patient-level scores, and finally comment on the quality of the diagnostic test in the context of the accuracy of such patient-level decisions. For such a quality check, the receiver operating characteristics (ROC) curve that includes all the decision threshold, offers a more compressive assessment. In diagnostic test assessment, area under the ROC curve (AUC) can be used to judge the quality of approaches. A value of AUC that lies in range 0 to 1, where 0 and 1 correspond to inaccurate and accurate test respectively. A value of 0.5 for AUC indicates no discrimination, 0.7 to 0.8 is considered acceptable, 0.8 to 0.9 taken as fair or good or some time excellent test, and more than 0.9 is considered as outstanding [21]. In light of this, we suggest an integrated model using all magnifications (as elaborated below), that uses the AUC as a performance measure.
-
(c)
In some previous work [4, 18] a model corresponding to each magnification was built independently based on different combinations of features and classifiers. We believe that instead of just relying on the individual scores correspond to each magnifications, assessment of overall score calculated as the ratio of total images classified to total images of patient, can also yield useful information with respect to a beneficial decision. For instance, for a patient who has large variation in scores, the decision cannot be made reliably by just looking at the highest score. In this work, while we report results on individual magnifications, we also suggest an integrated model that makes use of all magnifications, and can yield a more reliable system in terms of the AUC. Figure 2 depicts the proposed integrated model, wherein, x1, x2, x3, and x4 are the total number of input images of four different magnifications, and y1, y2, y3, and y4 are the corresponding classified images.
2 Methodology
In this section, we briefly discuss about the images descriptors and classifiers we have utilized for this study.
2.1 Joint Colour-texture Features
In order to find suitable feature for each magnification various features are utilized. Due to space constraints, we provide only a short introduction of features which are included in combinations that yields the top results. For more details please refer [12].
-
1.
Normalized colour space representation [22]: The matrix of complex numbers (C1+iC2), where C1 and C2 are the normalized colour channel chosen based on the range and average values of the colour channels is used to extract textural (Gabor filter) features.
-
2.
Multilayer coordinate clusters representation [23]: To describe the textural and colour content of an image, it splits the original colour image into a bundle of binary images, where each binary image represents a colour code based on a predefined palette (quantized colour space). Patches of such binary patters are then clustered and the method computes the histograms of occurrence of the binary patches based on the cluster centres. This process is repeated for each layer, and the resulting histograms are concatenated. Depending on, how many samples (n) are taken on each axis of the colour space, resulting palettes (N=\( n^{3} \)) will be 8, 27 and 64 levels.
-
3.
Gabor features on Gaussian colour model [24]: The following two stages are used to extract color-texture: (1) Measurement of color in transformed space (based on a Gaussian colour model), (2) Utilization of Gabor filter bank for texture measurement.
-
4.
Complex wavelet features and chromatic features [25]: Dual Tree Complex Wavelet Transform (DT-CWT) is applied to each color channel separately. The final feature vector is a concatenation of all DT-CWTS from different channels.
-
5.
Opponent colour local binary pattern (OCLBP) [26]: This is an extension of standard Local Binary Pattern (LBP) which developed as the joint colour-texture operator for colour images. It is a concatenation of all LBPs extracted from different channels including colour channels separately (intra channel) and opponent colour channel ((\(c_{1},c_{2}\)), (\(c_{1},c_{3}\)) and (\(c_{2},c_{3}\))) jointly.
2.2 Classifiers
We explore various supervised classifiers, for which we provide a short description below [27].
-
1.
Support Vector Machine (SVM): It is a supervised machine learning algorithm that learns a hyperplane which separates a samples of one class from samples of other class with maximum margin. Depending on the type of the kernel and, its scale that used to make the distinction between classes, a variety of SVMs exists.
-
(a)
Linear SVM
-
(b)
Quadratic SVM (Quadratic kernel)
-
(c)
Cubic SVM (Cubic kernel)
-
(d)
Fine Gaussian SVM (Radial Basis Function (RBF) kernel, kernel scale set to \(\sqrt{P}\)/4)
-
(e)
Medium Gaussian SVM (RBF kernel, kernel scale set to \(\sqrt{P}\))
-
(f)
Coarse Gaussian SVM (RBF kernel, kernel scale set to 2\(\sqrt{P}\))
where P is the number of predictors.
-
(a)
-
2.
Decision Tree: It is a top-down approach that uses a tree-like graph of possible solutions including resource costs, and utility. Several variations of tress are exist based on maximum number of splits utilized in the tree.
-
(a)
Simple Tree (maximum number of splits is 4)
-
(b)
Medium Tree (maximum number of splits is 20)
-
(c)
Complex Tree (maximum number of splits is 100)
-
(a)
-
3.
Nearest Neighbors Classifier: It does not make any underlying assumptions about the distribution of data. It locates the data into some clusters, or groups and classified an unclassified point into the cluster for which it has a higher probability of getting classified based on distance metrics. Depending on number of neighbors and metric used, a variety of k-NN exists.
-
(a)
Fine KNN (number of neighbors is set to 1, euclidean metric)
-
(b)
Medium KNN (number of neighbors is set to 10, euclidean metric)
-
(c)
Coarse KNN (number of neighbors is set to 100, euclidean metric)
-
(d)
Cosine KNN (number of neighbors is set to 10, Cosine distance metric)
-
(e)
Cubic KNN (number of neighbors is set to 10, cubic distance metric)
-
(f)
Weighted KNN (number of neighbors is set to 10, distance based weight)
-
(a)
-
4.
Discriminant Analysis: It assumes that different classes generate data based on different gaussian distributions and predicts membership in a group or category based on observed values. We consider two types of discriminant analysis based on boundary type formed between classes.
-
(a)
Linear Discriminant (linear boundaries)
-
(b)
Quadratic Discriminant (non-linear boundaries such as ellipse, parabola)
-
(a)
-
5.
Ensemble Classifier [28]: It is a set of classifiers trained to solve same problem and, their output are combined to classify a new sample. The employment of logistics to make different schemes (combination) leads to different ensemble methods:
-
(a)
Boosted Tree
-
(b)
Bagged Tree
-
(c)
RUSBoosted Trees
-
(a)
3 Experimental Results and Discussion
For fair comparison with existing approach [4, 18, 20], we have randomly chosen 58 patients (70%) for training and remaining 25 for testing (30%). We train the above mentioned classifiers using image representations of chosen 58 patients, and also used five trials of random training-testing data selection. These trained models are tested using remaining image representations of 25 patients. Due to the disproportionate ratio of normal and abnormal cases, the same procedure is repeated for five trails (each time different patients for training and testing are chosen) and average results are reported. The discussed protocol is followed for all magnification, i.e. same patients are used for training for all magnifications. In subsequent subsections, we will discuss the evaluation metrics used to discuss the present work, performance evaluation of each magnification as well as for integrated model, AUC performance evaluation and performance comparison.
3.1 Evaluation Metric
There can be various ways to evaluate the model when the observed variable lies in continuous range (discussed in introduction section). In some previous work [4, 18], patient recognition rate (PRR) that further depends on patient score (PS), and image recognition rate (IRR) were used to report the results. The first measure takes the decision patient-level while second at image-level (i.e. without using patient information) The definition of these measures are given as follows:
where N is the total number of patients (available for testing). The patient score is define as follows,
\( N_{rec}\) and \( N_{P} \) are the correctly classify and total cancer image of patient P respectively.
where, TCCI and TI are the total correctly classified image and total images respectively.
In addition, we also employ the ROC curve and AUC computation [29] to grade quality of the framework as a system for patient-level diagnosis.
3.2 Performance Evaluation
Tables 2, 3, 4 and 5 illustrate the performance of the models corresponding to each magnification. For each magnification, results are reported for five best combinations which are ranked based on the obtained patient score.
In proposed study, we compute the AUC based on the ROC obtained using the patients scores. Hence, in Tables 2, 3, 4 and 5, we give more prominence to the patient score. In each table, fourth and the fifth row shows the patient and the image score obtained for top combinations and the corresponding features and classifiers are given in the second and third row.
It is observed from the tables that, all the features are not appropriate for same classifier. Hence, suitable combinations of features and classifiers are more advantageous to quantify the images of different magnification.
We also suggest an integrated model, where we consider best feature-classifier combination (based on the patient score) for each magnification. The integrated model yields a patient-level score of 88.40% and image-level score of 88.09%. We note that the integrated model is performing similar to the individual magnifications in terms of score. However, as we demonstrate next, the integration can be considered more reliable, based on the AUC analysis.
3.3 AUC Evaluation
As discussed in Sect. 1.2, it is important to take decisions on patients (rather than images), and that ROC and the related AUC is an effective way to rate such diagnostic systems. Here, we consider the same in context of reliability of the test for patient-level decisions, by thresholding patient-level scores. Note that this ROC computation on patient-level scores is different from the traditional ROC analysis for in pattern classifiers (e.g. for image-level classification).
Table 6 details the value of AUC obtained for all magnification levels as well as for integrated model. A threshold on the real-valued scores determines a final label (benign or malignant). The ROC curve is computed using different values of threshold. We also compute the optimal threshold for the ROC curve [30]. Table 6 illustrates the range of this optimal threshold estimated using five trials.
From the reported results in Table 6, it is clear that the AUC for models corresponding to single magnification, is lower than that for the integrated model, thus ascertaining the good quality of inference of the integrated model. The value of 81.92 for AUC for the integrated model signifies a good quality test [21]. We also note that the variation of the optimum threshold among the five trials is one of the lowest. This suggests that the integrated model yields a stable value of the optimum threshold.
3.4 Performance Comparison
Table 7 compares the proposed method with state-of-the-art methods which use same dataset and also the same protocol. We can observe from the table that, except for the 40x magnification case, the proposed framework outperforms the others approaches. Furthermore, one can also observe that the proposed work yields the least variance in scores. Thus, we demonstrate that suitable joint colour-texture features and classifier combination are effective for BC histopathology image classification.
4 Conclusion
This study proposes an integrated model over multiple magnifications for breast cancer histopathological image classification. In this work, we employ a wide range of joint colour-texture features and classifiers. We demonstrate that some of these features and classifiers are indeed effective for a superior classification performance. In addition, the present study also focuses on measuring the performance of the integrated model based on the AUC criteria, and deduce that the this yields better results than the classification at individual magnifications.
References
American Cancer Society: Breast cancer facts & figures 2011–2012. American Cancer Society INC., vol. 1, no. 34 (2011)
Gurcan, M.N., Boucheron, L.E., Can, A., Madabhushi, A., Rajpoot, N.M., Yener, B.: Histopathological image analysis: A review. IEEE Rev. Biomed. Eng. 2, 147–171 (2009)
Basavanhally, A.N., Ganesan, S., Agner, S., Monaco, J.P., Feldman, M.D., Tomaszewski, J.E., Bhanot, G., Madabhushi, A.: Computerized image-based detection and grading of lymphocytic infiltration in HER2+ breast cancer histopathology. IEEE Trans. Biomed. Eng. 57(3), 642–653 (2010)
Spanhol, F.A., Oliveira, L.S., Petitjean, C., Heutte, L.: A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 63(7), 1455–1462 (2016)
Sethi, A., Sha, L., Vahadane, A.R., Deaton, R.J., Kumar, N., Macias, V., Gann, P.H.: Empirical comparison of color normalization methods for epithelial-stromal classification in H and E images. J. Pathol. Inform. 7, 17 (2016). doi:10.4103/2153-3539.179984
Li, X., Plataniotis, K.N.: A complete color normalization approach to histopathology images using color cues computed from saturation-weighted statistics. IEEE Trans. Biomed. Eng. 62(7), 1862–1873 (2015)
Gorelick, L., Veksler, O., Gaed, M., Gómez, J.A., Moussa, M., Bauman, G., Fenster, A., Ward, A.D.: Prostate histopathology: Learning tissue component histograms for cancer detection and classification. IEEE Trans. Med. Imaging 32(10), 1804–1818 (2013)
Nguyen, K., Sarkar, A., Jain, A.K.: Structure and context in prostatic gland segmentation and classification. In: Ayache, N., Delingette, H., Golland, P., Mori, K. (eds.) MICCAI 2012. LNCS, vol. 7510, pp. 115–123. Springer, Heidelberg (2012). doi:10.1007/978-3-642-33415-3_15
Fernández-Carrobles, M.M., Bueno, G., Déniz, O., Salido, J., García-Rojo, M., González-López, L.: Influence of texture and colour in breast TMA classification. PloS one 10(10), e0141556 (2015)
Amaral, T., McKenna, S., Robertson, K., Thompson, A.: Classification of breast-tissue microarray spots using colour and local invariants. In: 2008 5th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, ISBI 2008, pp. 999–1002. IEEE (2008)
Tabesh, A., Teverovskiy, M.: Tumor classification in histological images of prostate using color texture. In: 2006 Fortieth Asilomar Conference on Signals, Systems and Computers: ACSSC 2006, pp. 841–845. IEEE (2006)
Bianconi, F., Harvey, R., Southam, P., Fernández, A.: Theoretical and experimental comparison of different approaches for color texture classification. J. Electron. Imaging 20(4), 043006 (2011)
Ilea, D.E., Whelan, P.F.: Image segmentation based on the integration of colour-texture descriptorsa review. Pattern Recogn. 44(10), 2479–2501 (2011)
Kowal, M., Filipczuk, P., Obuchowicz, A., Korbicz, J., Monczak, R.: Computer-aided diagnosis of breast cancer based on fine needle biopsy microscopic images. Comput. Biol. Med. 43(10), 1563–1572 (2013)
Filipczuk, P., Fevens, T., Krzyzak, A., Monczak, R.: Computer-aided breast cancer diagnosis based on the analysis of cytological images of fine needle biopsies. IEEE Trans. Med. Imaging 32(12), 2169–2178 (2013)
Zhang, Y., Zhang, B., Coenen, F., Wenjin, L.: Breast cancer diagnosis from biopsy images with highly reliable random subspace classifier ensembles. Mach. Vis. Appl. 24(7), 1405–1420 (2013)
Zhang, Y., Zhang, B., Coenen, F., Xiao, J., Lu, W.: One-class kernel subspace ensemble for medical image classification. EURASIP J. Adv. Signal Process. 2014(1), 17 (2014)
Spanhol, F.A., Oliveira, L.S., Petitjean, C., Heutte, L.: Breast cancer histopathological image classification using convolutional neural networks. In: 2016 International Joint Conference on Neural Networks (IJCNN), pp. 2560–2567 IEEE (2016)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
Bayramoglu, N., Kannala, J., Heikkilä, J.: Deep learning for magnification independent breast cancer histopathology image classification, 2440–2445 (2016)
Hanley, J.A., McNeil, B.J.: The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 143(1), 29–36 (1982)
Vertan, C., Boujemaa, N.: Color texture classification by normalized color space representation. In: 2000 Proceedings of the 15th International Conference on Pattern Recognition, vol. 3, pp. 580–583. IEEE (2000)
Bianconi, F., Fernández, A., González, E., Caride, D., Calviño, A.: Rotation-invariant colour texture classification through multilayer CCR. Pattern Recogn. Lett. 30(8), 765–773 (2009)
Hoang, M.A., Geusebroek, J.-M., Smeulders, A.W.M.: Color texture measurement and segmentation. Signal Process. 85(2), 265–275 (2005)
Barilla, M.E., Spann, M.: Colour-based texture image classification using the complex wavelet transform. In: 2008 5th International Conference on Electrical Engineering, Computing Science and Automatic Control, CCE 2008, pp. 358–363. IEEE (2008)
Mäenpää, T., Pietikäinen, M.: Texture analysis with local binary patterns. In: Handbook of Pattern Recognition and Computer Vision, vol. 3, pp. 197–216 (2005)
Classification-learner-app. https://in.mathworks.com/help/stats/classification-learner-app.html
Rokach, L.: Ensemble-based classifiers. Artif. Intell. Rev. 33(1–2), 1–39 (2010)
Rosner, B.: Fundamentals of Biostatistics. 6th ed. Duxbury (2005). Chapter 3
Briggs, W.M., Zaretzki, R.: The skill plot: a graphical technique for evaluating continuous diagnostic tests. Biometrics 64(1), 250–256 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Gupta, V., Bhavsar, A. (2017). An Integrated Multi-scale Model for Breast Cancer Histopathological Image Classification with Joint Colour-Texture Features. In: Felsberg, M., Heyden, A., Krüger, N. (eds) Computer Analysis of Images and Patterns. CAIP 2017. Lecture Notes in Computer Science(), vol 10425. Springer, Cham. https://doi.org/10.1007/978-3-319-64698-5_30
Download citation
DOI: https://doi.org/10.1007/978-3-319-64698-5_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-64697-8
Online ISBN: 978-3-319-64698-5
eBook Packages: Computer ScienceComputer Science (R0)