
Abstract
We propose a new method for group decision making by using trapezoidal fuzzy numbers to describe decisions. A team of decision makers (or experts) must choose the most appropriate alternative using fuzzy logic. Each expert will give his opinion about every alternative in accordance with the criteria of choice by a fuzzy number. The decisions taken are aggregated respecting the similarity and dissimilarity (distance) between each pair of opinions, in addition to the hierarchical weights (importance) of each decision-maker (DM). The result is a fuzzy number representing the general appreciation of each alternative. In order to able to choose one, an appropriate ranking method is proposed. In this article we treat four issues, namely, similarity and distance between opinions represented by fuzzy numbers, aggregation of opinions while preserving similarity and in accordance with the hierarchical weight, and finally ranking fuzzy numbers.
Abridged version.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
- Multi criteria decision making
- Fuzzy set theory
- Similarity
- Distance
- Ranking
- Aggregating
- Trapezoidal number
- Consistency degree
1 Introduction
In a decision-making situation, conflicting and agreeing opinions emerge. The main problem is how to find a reasonable method to aggregate individual opinions into a group consensus opinion. In the fuzzy logic framework, several methods aim to reach the consensus by fuzzy preference relation. Otherwise, two methods have been studied by computing the cohesion between each pair of DMs. Firstly, Hsu and Chen [1] proposed the similarity aggregation method (SAM). One of its weaknesses is that it requires the intersection of the estimations to a certain level in order to calculate the similarity between each pair of opinions. Secondly, the approach of Lu et al. [2] computes the consistency on the basis of similarity and distance. Our work concerns some variations and improvements of these approaches. First, each DM will evaluate each alternative under the criteria of evaluation, and the importance of each criterion by a trapezoidal fuzzy number or a linguistic variable. Then the individual fuzzy opinions will be aggregated according to the proposed method in order to obtain the fuzzy collective opinions for each alternative. After that, a ranking method is proposed to classify the alternatives. Many systematic comparisons with earlier works are given to show the effectiveness of our method.
This abridged version is organized as follows. Section 2 introduces some notations. Section 3 defines our notions of distance, similarity, aggregation, ranking and their properties. In Sect. 4, we give comparisons with earlier works. Section 5 summarizes the steps of our Multi-criteria Decision Making (MCDM) method with a numerical example. Section 6 concludes the paper.
2 Preliminaries
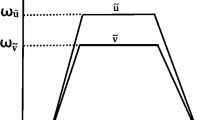
A fuzzy number \( \tilde{A} \) [3] is a fuzzy set defined by its membership function \( \mu_{{\tilde{A}}} \): \( {\mathbb{R}} \to [0,1] \). We restrict ourselves to trapezoidal fuzzy numbers (cf. Fig. 1) given by 4-tuples (a, b, c, d) where a \( \leqslant \) b \( \leqslant \) c \( \leqslant \) d and represented by:

Trapezoidal fuzzy number
Considering two trapezoidal fuzzy numbers \( \tilde{A} \) (a 1, b 1, c 1, d 1) and \( \tilde{B} \) (a 2, b 2, c 2, d 2), the inverse Eq. (1), the fuzzy addition Eq. (2), multiplication Eq. (3), and division Eq. (4) are defined as follows:
Note that these operations preserve the trapezoidal shape. Furthermore we suppose our fuzzy numbers have positive supports and are normalized.
Each DM will make his opinion either by constructing his own trapezoidal fuzzy number or by linguistic variables that will be converted into a trapezoidal fuzzy number as shown in the next figures. Figure 2 is to qualify the importance of each criterion. Figure 3 is to qualify alternatives in accordance to the criteria.

Linguistic variables for each criterion

Linguistic variables for ratings
3 Similarities, Aggregation and Ranking
Lu et al. [2] noted that similarity should not only contain the commonalities as calculated by Eq. (5), but also dissimilarity which can be represented by a distance D 1. So they proposed the coherence Eq. (6) which is extremely depending on the parameter of calculation.
where 0 \( \leqslant \) β \( \leqslant \) 1.
For \( \tilde{R}_{1} = \left( {a_{1} ,b_{1} ,c_{1} ,d_{1} } \right), \tilde{R}_{2} = (a_{2} ,b_{2} ,c_{2} ,d_{2} ) \) two trapezoidal fuzzy numbers, set
We introduce the following distance
In order to normalize D 1, we must divide it by a parameter M = 10 which is the maximum of the notation scale. In the sequel we will continue to denote by D 1 the normalized distance.
For p a positive real number, we define the new parameterized similarity defined by:
The similarities (8) are quasi-equivalent regarding the parameter p which is not the case of the similarities (6) regarding the parameter β. Quasi-equivalent fuzzy similarities where defined in [4]. The individual global cohesion of the ith DM 1 \( \leqslant \) i \( \leqslant \) n is calculated by the equation:
where t, s are positive real numbers, \( e_{1} , \ldots ,e_{n} \) are hierarchical weights with 0 \( \leqslant \) e i \( \leqslant \) 1 and \( \sum\nolimits_{i = 1}^{n} {e_{i} = 1.} \)
The consistency of the ith decision maker, is calculated by the equation:
The collective decision for an alternative according to one criterion is given by:
In the context of MCDM we have n decision makers, m criteria and K alternatives. We will denote by \( \tilde{w}_{{c_{1} }} , \ldots ,\tilde{w}_{{c_{m} }} \) the fuzzy trapezoidal weights of the m criteria.
For the needs of ranking we introduce the score of each alternative as
where 1 \( \leqslant \) i \( \leqslant \) m and \( \tilde{R}(i) \) is calculated by (12). For each trapezoidal number \( \tilde{A}(a,b,c,d) \) we define the following rank:
where M = 10. We have:
We denote by \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \) if and only if \( F(\tilde{A}_{1} ) \ge F(\tilde{A}_{2} ) \), and \( \tilde{A}_{1} \sim \tilde{A}_{2} \) if and only if \( F(\tilde{A}_{1} ) = F(\tilde{A}_{2} ) \). Here, the symbol \( \underline{\succ } \) means better than and the symbol ~ means the same ranking.
Let \( \tilde{A}_{1} ,\tilde{A}_{2} \;{\text{and}}\; \tilde{A}_{3} \) three fuzzy numbers it is easy to verify the following six reasonable ordering properties introduced in [5, 6].
Property 1:
if \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \) and \( \tilde{A}_{2} \,\underline{\succ }\, \tilde{A}_{1} \) then \( \tilde{A}_{1} \sim \tilde{A}_{2} \).
Property 2:
if \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \) and \( \tilde{A}_{2} \,\underline{\succ }\, \tilde{A}_{3} \) then \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{3} \).
Property 3:
if \( \tilde{A}_{1} \, \cap \,\tilde{A}_{2} \, = \,\emptyset \;{\text{and}}\;\tilde{A}_{1} \) is at the right of \( \tilde{A}_{2} \) then \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \).
Property 4:
the order of \( \tilde{A}_{1} \;{\text{and}}\;\tilde{A}_{2} \) is not affected by the other fuzzy numbers under comparison.
Property 5:
if \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \) then \( \tilde{A}_{1} \oplus \tilde{A}_{3} \,\underline{\succ }\, \tilde{A}_{2} \oplus \tilde{A}_{3} . \)
Property 6:
if \( \tilde{A}_{1} \,\underline{\succ }\, \tilde{A}_{2} \) then \( \tilde{A}_{1} \otimes \tilde{A}_{3} \,\underline{\succ }\, \tilde{A}_{2} \otimes \tilde{A}_{3} . \)
It is easy to prove that the aggregation method proposed fulfils the properties presented in [2]. If all values are crisp, or if there is no intersection between each couple of the fuzzy opinions of DMs in order that the similarity term S w will have no influence on the coherence, we will choose p → +∞ leading to:
4 Comparisons with Earlier Works
In this section, we will compare at first the proposed coherence based on similarities, with existing similarity methods. Figure 4 shows the compared sets, and Table 1 the numerical values of the similarities under comparison, in addition to the proposed method with different values of its parameter p.

Compared fuzzy sets (similarity)
Lee’s method [7] fails to calculate the similarity of the 2nd configuration because of the denominator required by the method, as it does not distinguish between the 5th, 6th and 7th configurations even though they are clearly different.
Chen’s method [8] produces the same result for the 5th, 6th and 12th configurations and configurations from 7 to 11, even though they are all different from each other.
Chen’s method [9] does not distinguish the 9th and 10th configurations even if they are different. It presents a brutal jump as soon as there is intersection between the compared fuzzy numbers, the last remark is valid for the method proposed in [11] as well as Young’s method [10], that can be illustrated by the 7th and 8th configurations.
Observing the configurations 5 and 6, one realizes that they are very similar, resulting in values of similarity nearby for all methods otherwise identical, the method proposed by Allahivandro et al. [11] offers very distinct values, while the 5th configuration is more similar to the 6th as the 3rd or the 7th configuration, unlike the values proposed by the method.
Several methods were proposed to rank fuzzy numbers [12,13,14,15,16,17,18,19,20,21,22]. In this section, we use six sets to compare the method proposed to rank fuzzy numbers (Fig. 5). The Table 2a and b show the results for the six sets.
-
Set 1: it is obvious that \( \tilde{B} \) should be greater than \( \tilde{A}, \) however the method proposed by Cross and Setness in [17] fails to distinguish the compared fuzzy numbers. The method proposed by Ramli and Mohamad in [19] is extremely depending on the parameter of calculation, and occur in an incorrect ranking if the parameter is not well-chosen.
-
Set 2: from Set 2 we can see that the figure shows two different fuzzy numbers. However the methods proposed in [12, 13, 15, 17, 21, 22] and [19] for β = 0.5 fail to distinguish them. The method proposed in [19] for β = 0 get incorrect ranking.
-
Set 3: from Set 3 we can see that the figure shows two different fuzzy numbers however the methods proposed in [12,13,14,15, 17, 20,21,22] and [19] β = 0.5 fail to distinguish them. The method proposed in [19] for β = 1 results in incorrect ranking.
-
Set 4: the methods proposed in [12,13,14,15, 17, 19] cannot calculate the ranking value for the second fuzzy number under comparison.
-
Set 5: except the method proposed in [17, 19] all other methods result in correct ranking.
-
Set 6: recent methods proposed in [21, 22] propose the ranking \( \tilde{A} \,{<}\, \tilde{B} \,{<}\, \tilde{C} \) which is the same order proposed in [12, 13, 18] and in our method. The other methods [14,15,16,17, 19, 20] result in a wrong ranking.

Compared fuzzy sets (ranking)
5 Steps of the Proposed MCDM Method
The successive steps of our MCDM are:
-
Step 1: Each DM assesses the importance of each criterion either by linguistic variable as shown in Fig. 2 that will be translated into trapezoidal fuzzy number, or by building its own trapezoidal fuzzy number.
-
Step 2: each DM evaluates each alternative depending on the assessment criteria. This evaluation also is either by linguistic variable as shown in Fig. 3 that will be translated into trapezoidal fuzzy number, or by building its own trapezoidal fuzzy number.
-
Step 3: calculate the similarity \( S_{w} \left( {\tilde{R}_{i} ,\tilde{R}_{j} } \right) \) between each couple of DMs by Eq. (5) for each alternative under the chosen criteria.
-
Step 4: calculate the distance \( D_{1} \left( {\tilde{R}_{i} ,\tilde{R}_{j} } \right) \) between each couple of DMs by Eq. (7) for each alternative under the chosen criteria.
-
Step 5: choose the parameter p and calculate the coherence \( r_{p} \left( {\tilde{R}_{i} ,\tilde{R}_{j} } \right) \) between each couple of DMs by Eq. (8) for each alternative under the chosen criteria.
-
Step 6: choose the parameters t and s and calculate the individual global coherence GC i for each expert by Eq. (9) for each alternative under the chosen criteria.
-
Step 7: calculate the consistency of each decision C i for each expert by Eq. (10) for each alternative under the chosen criteria.
-
Step 8: aggregate the fuzzy decision in accordance to Eq. (11) to obtain the collective appreciation for each alternative under the chosen criteria.
-
Step 9: calculate the final score for each alternative \( \tilde{N}_{i} \) by Eq. (12).
-
Step 10: deffuzify the final value according to Eq. (14) to obtain the ranking.
We illustrate the proposed method by using the example given by Chen [23]. A company desires to select the suitable supplier from 5 alternatives (A 1, A 2, A 3, A 4, A 5). Three decision makers with the following hierarchical weight (e 1 = 0.42; e 2 = 0.25; e 3 = 0.33) are responsible for making the choice, using five criteria (C 1, C 2, C 3, C 4, C 5) adopting the notations of Figs. 2 and 3 (cf. the Tables 3a and b and 4 below).
6 Conclusion
In this article, we presented an approach to decision-making by introducing new distance, consistency, aggregation and ranking methods. The general idea is that the opinion of each DM would have larger weight in aggregation if it is more consistent with other opinions taking into account the hierarchical weights. The ranking is based on the idea of the TOPSIS method: the alternative with the score closest to the ideal goal and farthest possible from the worst solution would be the best one. We have implemented our MCDM method which compares favorably with earlier works.
References
Hsu, H.M., Chen, C.T.: Aggregation of fuzzy opinions under group decision making. Fuzzy Sets Syst. 79, 279–285 (1996)
Lu, C., Lan, J., Wang, Z.: Aggregation of fuzzy opinions under group decision-making based on similarity and distance. J. Syst. Sci. Complex. 19, 63–71 (2006)
Skalna, I., Rębiasz, B., Gaweł, B., Basiura, B., Duda, J., Opiła, J., Pełech-Pilichowski, T.: Advanced in Fuzzy Decision-Making, Studies in Fuzziness and Soft Computing. Springer, New York (2015)
Maria, R.: Mesures de similarité, raisonnement et modélisation de l’utilisateur: habilitation à diriger des recherches de l’université Pierre ET Marie CURIE. Sorbonne University, Paris (2010)
Wang, X., Kerre, E.E.: Reasonable properties for the ordering of fuzzy quantities (I). Fuzzy Sets Syst. 118, 375–385 (2001)
Wang, X., Kerre, E.E.: Reasonable properties for the ordering of fuzzy quantities (II). Fuzzy Sets Syst. 118, 387–405 (2001)
Lee, H.S.: An optimal aggregation method for fuzzy opinions of group decision. Proc. IEEE Int. Conf. Syst. Man Cybern. 3, 314–319 (1999)
Chen, S.M.: New methods for subjective mental workload assessment and fuzzy risk analysis. Cybren. Syst. 27, 449–472 (1996)
Chen, S.J., Chen, S.M.: Fuzzy risk analysis based on similarity measures of generalized fuzzy numbers. IEEE Trans. Fuzzy Syst. 114, 1–9 (2003)
Yong, D., Wenkang, S.H., Feng, D., Qi, L.: A new similarity measure of generalized fuzzy numbers and its application to pattern recognition. Pattern Recogn. Lett. 25, 875–883 (2004)
Allahviranloo, T., Abbasbandy, S., Hajighasemi, S.: A new similarity measure for generalized fuzzy numbers. Neural Comput. Appl. 21(Suppl 1), S289–S294 (2012)
Cheng, C.H.: A new approach for ranking fuzzy numbers by distance method. Fuzzy Sets Syst. 95(3), 307–317 (1998)
Chu, T., Tsao, C.: Ranking fuzzy numbers with an area between the centroid point and original point. Comput. Math Appl. 43, 111–117 (2002)
Murakami S., Maeda, S., Imamura, S.: Fuzzy decision analysis on the development of centralized regional energy control systems. In: Proceedings of the IFAC Symposium on Fuzzy Information, Knowledge Representation and Decision Analysis, pp. 363–368. Pergamon Press, New York (1983)
Yager, R.R.: On a general class of fuzzy connectives. Fuzzy Sets Syst. 4(6), 235–242 (1980)
Chen, S.J., Chen, S.M.: Fuzzy risk analysis based on the ranking of generalized trapezoidal fuzzy numbers. Appl. Intell. 26, 1–11 (2007)
Cross, V.V., Setnes, M.: A generalized model for ranking fuzzy sets. IEEE World Congr. Comput. Intell. 1, 773–778 (1998)
Chen, S.M., Chen, J.H.: Fuzzy risk analysis based on ranking generalized fuzzy numbers with different heights and different spreads. Expert Syst. Appl. 36(3), 6833–6842 (2009)
Ramli, N., Mohamad, D,: On the Jaccard index with degree of optimism in ranking fuzzy numbers. In: Soft Computing and Pattern Recognition, SOCPAR 2009 (2009)
Bakar, A.S.A., Mohamad, D., Sulaiman, N.H.: Ranking fuzzy numbers using similarity measure with centroid. In: International Conference on Science and Social Research (CSSR 2010), Kuala Lumpur, 5–7 December 2010
Chen, S.M., Sanguansat, K.: Analyzing fuzzy risk based on a new fuzzy ranking method between generalized fuzzy numbers. Expert Syst. Appl. 38(3), 2163–2171 (2011)
Chen, M., Munif, A., Chen, G.S., Liu, H.C., Kuo, B.C.: Fuzzy risk analysis based on ranking generalized fuzzy numbers with different left heights and right heights. Expert Syst. Appl. 39, 6320–6334 (2012)
Chen, C.T., Lin, C.T., Huang, S.F.: A fuzzy approach for supplier evaluation and selection in supply chain management. Int. J. Prod. Econ. 102, 289–301 (2006)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this paper
Cite this paper
El Alaoui, M., Ben-Azza, H., Zahi, A. (2018). New Multi-criteria Decision-Making Based on Fuzzy Similarity, Distance and Ranking. In: Abraham, A., Haqiq, A., Ella Hassanien, A., Snasel, V., Alimi, A. (eds) Proceedings of the Third International Afro-European Conference for Industrial Advancement — AECIA 2016. AECIA 2016. Advances in Intelligent Systems and Computing, vol 565. Springer, Cham. https://doi.org/10.1007/978-3-319-60834-1_15
Download citation
DOI: https://doi.org/10.1007/978-3-319-60834-1_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-60833-4
Online ISBN: 978-3-319-60834-1
eBook Packages: EngineeringEngineering (R0)