
Abstract
The rapid growth of internet has paved the way for recommender systems as users are inundated with a variety of choices. A computer system that provides recommendations/suggestions to the users is called Recommender Systems (RS). These systems are a subclass of information filtering systems that provides suitable recommendations to users about a product, movie, song, mobile applications etc. RS are being widely used in social networking sites like Facebook, Twitter, LinkedIn etc. to help users choose product/friend/job from the various recommendations. These systems analyze patterns of user interest in posting information, sharing posts or joining a new group to provide personalized recommendations that suit user’s taste. RS are popular in many areas especially for predicting/suggesting what the users want in advance and thus help in reducing search costs. Recommendations are done using either collaborative, Content-based filtering or hybrid approach. Content-based recommendation system recommends based on user profile created by analyzing the items the user has liked/rated in the past. A collaborative recommendation system, on the other hand, does suggestions based on the preferences/ratings of our previous collaborators (users whose liking was similar to ours). The popularity of social networking sites is increasing with more number of users being added daily. This paper discusses the various classification and applications of RS in some of the popular networking sites.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Background
Social networking is connecting with family, friends, customers and clients anywhere in the world using Social media sites like Facebook, LinkedIn, Twitter etc. This helps in expanding social/business contacts around the world. Social networking establishes social graphs that help people to establish beneficial contacts, which they would have unlikely met otherwise. The capacity for social interaction and collaboration is built into many of the business applications. By being a member of a social network community, it is easy to identify individuals whose likes and dislikes are similar. This ability has enabled social networking sites to have RS for their sites.
Gone are the days where users spent time searching for a product/item of their choice. A vast majority of them depend on RS in taking such decisions. By analyzing patterns of user’s interest in products/items RS provide personalized recommendations that suit a user’s taste. As they provide good selection opportunities to the users, many e-commerce leaders like Amazon, Netflix have added these systems to their websites. The presence of RS is felt not only in retail sector, but also in the entertainment industry and social networking sites. They make their presence in recommending movies, TV shows, music etc. Customers rate the movies based on their level of satisfaction, and this can be used by entertainment industries to recommend movies to particular customers. Most recommender systems use either content-based filtering or collaborative filtering. Few hybrid approaches are also seen.
Social recommender systems give personal recommendations to its users. Information filtering techniques are used for peer group recommendation, topic group recommendations, favourite movie actor/actress blog recommendations etc. Thus based on user’s taste and behavior a good social network can be created.
1.1 Collaborative Filtering (CF)
The invention of internet technology has made it possible in today’s world for anyone sitting anywhere to buy a product or a service Online. Popular E-commerce industries such as Amazon, Yahoo etc. are making use of innovative technologies that help the users know the current trends and buy products. RS play a major role in marketing by recommending a product/service to the user. Social networking sites such as Facebook, Twitter, LinkedIn etc. helps users to do a good kind of social networking by connecting with friends, relatives, colleagues through good social RS. Most of these systems use different kinds of collaborative filtering. Collaborative filtering is one of the interesting techniques that work on some assumptions. This method provides a list of recommendations to an active user by assuming that this particular user may have the same interest on a topic/item like many other users in the network. The system analyzes patterns followed by many users to predict the likelihood of this new user. For example: if A and B are friends on Facebook and if both of them liked an item ‘X’ then next time B likes ‘Y’, then RS would recommend ‘Y’ to A. The different Collaborative filtering methods are: Memory-based, Model-based and hybrid collaborative systems. Item-based and User-based algorithms are the two types of memory-based CF algorithms. Slope-one, Matrix Factorization (Dimensionality Reduction) method works for Model-based CF.
1.2 Content-Based Filtering
Content-based filtering recommends a product or a service by learning and comparing the contents of that particular product. The words that appearing as the content of a document are collected together to form a list of keywords. These keywords serve as the basis for the user’s profile by giving detailed recommendations with the same product that has been already selected by the user. The user’s profile can be built up implicitly or explicitly. Users are asked to enter their personal details, interest etc. and the keywords are explicitly generated. On the other hand keywords are implicitly generated by using techniques that can extract these keywords from the product or service descriptions.
2 Categories of Social Recommender Systems – Literature Review
Recommender systems for social networks can be divided into two categories namely: Entity based and Audience based [11]. Entity based recommendation deals with tagging, social influence, content, community and Audience based deals with friends, groups and trust recommendations are presented (Fig. 1).

Classification of Social network recommender system [1]

A typical social network recommender system
2.1 Tag-Based Recommendations
Tag-based recommendations allow users to share the items they are interested in. Tags can be assumed as a graphical model that connects different entities in the network- users and items denote the nodes of the network and the connecting lines the tags. The tag has significant meaning when it connects an item-item or user-item. Automatic tag recommendations for items such as images, videos, or documents can be done using user-based or document-based approaches [8]. User-based tagging is done by studying the tagging made by the users in their past. On the other side, document-based tagging is the method of producing tag recommendations to documents on a specific topic or on a variety of topics. Studies [8] prove that the performance of user-based tagging is not that satisfactory since it is difficult to build an appropriate model that produces good recommendations. The user-based tagging is not adaptable in monitoring the changes in the user patterns with the time. For document-based approaches, contents in documents are filled enough to provide a strong tag recommendation. In [8] authors proposed two methods for document-based tagging which showed better performance than user-based approaches. Various studies have been conducted in order to deal with the sparsity problem of tag recommendations. A single model combining content and relations analysis [18] was built to solve this problem. An approach to tag recommendation based on user’s interest based on lattice matching (UILM) algorithm which applies to the neighbourhood users and recommends tags on the basis of similarity between those users and current users is proposed in [9]. Their experiments showed that this approach was efficient and feasible showing improved personalized recommendations.
2.2 Context-Based Recommendations
Contextual information can improve the performance of recommender systems [19]. The contextual information such as user’s temporal, geographical features etc. should be considered to achieve this [3]. A scheme to provide item recommendation considering social position information is presented in [17]. A particular user is given a recommendation which is the most relevant one for the context at that moment. For e.g.: time and location. So the recommendation showed high prediction accuracy when compared to existing schemes. The user preference and the interpersonal influence, which is particularly based on a relationship between the users and the social interactions are two specific factors that can give more accurate recommendations [14]. The likelihood of a particular user u, for an item a, is find out using the naive measurement as follows \( P_{u} \left( a \right) = T_{a } \cdot \left( {\frac{1}{{\left| {A\left( {u,a} \right)} \right|}}\sum\nolimits_{{{a}^{\prime } \in A\left( {u,a} \right)}} {T_{a}^{{\prime }} } } \right) \) [14] where A(u, a) is the set of items adopted by user u excluding a, and Ta is the topic distribution of item a. The interpersonal influence from user-user interactions on social networking sites is described by calculating the percentage of recommended items adopted by u from the item a: \( I_{u} \left( a \right) = \left( {\frac{1}{{\left| {V\left( {u,a} \right)} \right|}}\sum\nolimits_{{v \in V\left( {u,a} \right)}} {\frac{{\left| {S\left( {u,v} \right) \cap A\left( u \right)} \right|}}{{S\left( {u,v} \right)}}} } \right) \) [14] where V (u, a) is the set of senders who send item a to user u, S(u, v) is the set of items sent from v to u, and A(u) is the set of items that u adopts [14].
2.3 Community-Based Recommendations
A community-based recommendation system is proposed in [20], to the real world social networking sites Twitter and Weibo. Instead of depending on the tweet content to produce recommendation (which have low precision) for a user, community-based approach is used which can even reduce data sparsity problems. It analyzes features of the community rather than a particular user. This approach proves to be scalable also. Another feature of community-based recommendation is it can resolve cold start issues [12]. The user which is new to a particular dimension but is already present in another social network will be recommended based on his historical activities or interest in that network
2.4 Content- Based Recommendations
These recommendations are particularly based on the textual information about the items (e.g.: topic based). In [10] the authors proposed a framework for content aware CF by learning the user’s information and content. They found the performance improvement in warm-start and cold-start problems. The similarities between two users are taken into account for producing the recommendations [4]. In [4] the personal recommendations are given by using recommendation score. SONAR, a social network aggregation system is used to get the user’s social network content [4]. It extracts the relationship among the users in an organization and collects them to construct a weighted network for users. Similarity network is used to find out the profile similarity such as hobbies, preferences for music, movies etc. and rating overlap [4]. Familiarity network is the network of known people to the user. The overall network was also examined. SONAR relationship score is used to find the same usage of the tags, bookmarking of the same web page, and commenting on the same post by two or more users in the networks. Recommendation score, RS can be calculated as
where t(i) is the total number of days from the date of item i is created; α is a decay factor; NT(u) consists of set of individuals in the user u’s network of type T, T ϵ {familiarity, similarity, overall}; ST[u,v] is the SONAR relationship score between u and v based on the network of type T; R(v,i) contains the set of all relationship types between user v and item i, given by the unified search system (authorship, membership, etc.); and \( W\left( r \right)\left( {r \in \text{R}\left( {\text{v},\text{i}} \right)} \right) \) is the corresponding weight for the user-item relationship type between user v and item i [4].
2.5 Social Influence-Based Recommendations
Jianming et al. [7] introduced a social network-based recommendation system (SNRS) using a probabilistic model that retrieves the information of person to person interactions from large dataset base especially focussing on the influence of friend relationships in items and ratings to find out the similar tastes of users.
2.6 Friend Recommendations
Facebook, Twitter, Google+, LinkedIn are some of the most familiar sites who are well versed in giving friend recommendations. The recommendations in the social networking sites such as Facebook is done based on the friend-of-friend method. In [6] the authors designed a recommendation system to a social networking site. The recommendations to a familiar friend in the same organization where the user exists, in his contacts are done using four algorithms: (a) a content matching algorithm used for matching the users having same interest in an item (b) content plus link algorithm to find out a link between an unknown person in the network (c) friend of friend algorithm to find a friend who is a friend of many other friends of the current user (d) an algorithm to find out the information about relations from different sources using intranet. Recommendations were done in a trustful way and the four algorithms were effective in finding a friend. In [28] authors designed a framework to online friend recommendations, using similarity measures. For this study, they identified users having the same interest and then used the k-medoid algorithm for clustering the users of same interest to provide high-quality recommendations. [21, 23] shows studies on different types of friend recommendations.
2.7 Group Recommendations
The groups in social networking are formed based on some relationships like peers, relative, co-workers, neighbourhood based on some common theme. Group recommender systems focus on recommending common information related to the group theme. For example, if it is a group of relatives the group will post information about the family discussion, family events, pictures, tagging of the members. The upcoming events for that group will be notified to all of the other group members. Group recommendations are produced considering the individual taste. Individual tastes are taken into consideration as preferences [13]. Aggregation functions are used to aggregate the preferences. The social influence and individual interests are the major factors that are taken for good group recommendation [13].
2.8 Trust-Based Recommendations
There are some classes of recommender systems which gave more emphasis on trust between the users [2, 5]. The trust between users is identified by studying the patterns, interests and likes that two users show.
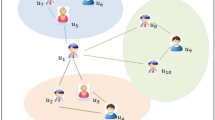
Figure 3 shows a graph model of a trust-based recommender system. Consider there are N nodes in the network where ‘N’ represents a number of users. Suppose node 1 shows a similar interest relationship on an item, with node 3 and node 3 has a similar relation with node4 then trust recommendations can be made with node 1 and node 4. The trust recommendations can be based on the item or profile on which the similarity was found. The review conducted in [15] discusses that trust is a factor based on the computing the trustworthiness with the peer.

A social graph depicting an example of a trust-based social network model.
3 Real Time Scenario of Social Recommendations
Figure 2 shows a typical social network recommender system. Facebook is structured as a graphical model built upon on a multi-dimensional array of 10 genomes such as shared friends, location, age, interests (likes and reactions), tagging, events, religion, groups, movies, education. This multi-dimensional array is filled with binary values which give information whether a user is interested in that particular genome or not. Facebook is not a kind of homogeneous social network. This nature of Facebook seriously influences the recommendations given to a user. To make better recommendations, authors [27] proposed a network topology related approach which shows the relevance to a new friend recommendation to the target user. The Pareto-optimal genetic algorithm generates a ubiquitous list of likes for each user and learns the links formed. Link recommendations are done through a refinement process by recommending a list of friends to a person with pertinent and high-class prediction accuracy. Jeff Naruchitparames et al. [27] selected 100 Facebook users and experimentally proved that their methodology provides the robust friend recommendations and learned the way the users get into the friendship in the network.
Pinterest is the another popular networking site where we can get online multimedia content, pin them and arrange them on a board under a topic. Like Facebook, a user can follow another user and can repin the multimedia content [23]. Pinterest shows a variety of interesting features which make it unique from other social networking sites [24]. The pins in the boards will display the user’s likelihood to the items because it is pinned by that person himself. The user will have a clear intention behind pinning an item. If any user finds interests in pins of this particular user he can repin that item. The repinning of items will make repeated memory refinements and save of pins [24]. This repeated saving of pins will form a chain of links to these pins which form a relationship. The item-item recommendations can be strengthened effectively by using the user curation of connected pins having a relationship. This will also solve the traffic problems in the Pinterest network [25]. Board recommendations are done by analyzing different features of the items users are pinning to a board. The individual based board relevance can also be considered. The board can be created based on a particular category. Another feature is the metadata about the pins written as labels. The individual to individual interaction with a particular board is the next key to extract the feature. Support Vector Machine (SVM) can make good recommendations to Pinterest [22].
LinkedIn, the largest job recommendation site is a social network of job providers recommends the job and job seekers can upload their resumes. CF approach for LinkedIn is known as Browsemaps [26]. LinkedIn creates recommendations based on individual, job or entity. A particular entity, user or job can be searched and found out easily because of the link flows all over the network. This model shows the co-occurrence among users in the sense that the users who are interested to see a particular person’s profile with some pattern may also like to see the current user profile which have the similar pattern. The company recommendations are also available that are provided to get updates from a particular company can follow. To produce Browsemaps graph association rule mining is used [26]. Hadoop’s batch processing is applied for whole statistical computations. Browsemaps provides the users with a variety of entity based recommendations as well as audience based. The entities will be performing different actions. When users upload the resumes for the first time the relevant job recommendations are done and users are continuously notified about the jobs. Each user can see and then apply for jobs. The recommendations are updated regularly and out-of-date job recommendations are removed. The module called Voldemort uses the Browsemaps graphs. This module stores graphs in the form of key-value pairs and helps the interface module in handling online queries [26]. An item or a user connected to LinkedIn is given a well versed navigational aid. Another application of LinkedIn is company recommendations “Company You May Want To Follow”. These are done by learning the company view graph, personal profile graphs, descriptions from profiles and they are listed as a table of < user, company > format. From this table, the high potential recommendations are taken to produce recommendations. The Browsemaps also help in increasing the number of companies by extending the current company of that person. Another application is to find out the qualified user profiles for recruiters to find out the candidates with certain qualifications [26]. Profile update notifications are another interesting feature of LinkedIn. LinkedIn recommends companies to its users even on a location basis. Lead recommendations are an application of LinkedIn for commercial recommendations.
Twitter is another social network giant. Twitter retrieves and shows all tweets posted from the person whom a particular individual is following. The individual/group of people who is/are following a particular user is/are known to be follower/s and the user followed by the users are known as followees. The impact of tweets is found to be in areas such news, education, public figures such as political leaders. Kywe, S.M et al. [16] in their survey of recommender systems in Twitter discussed that Twitter shows recommendations for the features such as tweet, retweet, follow and mention. Retweets are forwarded tweets from one to other as a means of sharing some interesting messages. Follow is the feature that makes the user–user connects so as to continuously receive updates from the follower when maintaining a social relation. Followee recommendations and hashtag recommendations will make the user receive trending and interesting information. The metadata about tweets stored as tuples that contain information about the users involved in the tweet. Mention is like tagging feature in Facebook. This feature adds those users who are involved in a specific interesting tweet. According to Wikipedia, in March 2016, Twitter’s active users have crossed 301 million. So we can assume the voluminous data each day twitter is handling. Studies are conducted to give good personalized recommendations in spite of information overload, limited tweet length etc.
4 Performance Comparison of the Different RS
The performance of RS can be understood by learning the system’s response towards the cold-start, data sparsity, scalability problem and the accuracy of the recommendations.
Cold-start user problem:
This problem arises when a number of user ratings available are not sufficient to recommend a user or an entity. Studies are carried out to solve this problem. e.g.: studying the user preferences in [12].
Scalability:
The recommender system should scale enough with the increasing amount of users joining the networks day-to-day. Some studies use personalized recommender systems, clustering methods [13] etc. solve this problem.
Sparsity problem:
Data sparsity problem shows the high impact on the standard of recommendations. A number of ratings available may be less, but these ratings will have high impact. Associative rule mining [21], finding out similar latent features [21] overcomes this problem (Table 1).
5 Conclusion
In this review, various classifications of social recommender systems and their applications are discussed. Though there are a number of RS available, they can still be improved if we are able to add Natural Language Processing capability to better understand the needs of the users. For better recommendations, RS should be designed by combining different factors that influence social networking such as social relation, trust and diversity of the domain.
References
Kautz, H., Selman, B., Shah, M.: Referral web: combining social networks and collaborative filtering. Commun. ACM 40(3), 63–65 (1997)
O’Donovan, J., Smyth, B.: Trust in recommender systems. In: 2005 Proceedings of the 10th International Conference on Intelligent User Interfaces, pp. 167–174. ACM (2005)
De Pessemier, T., Deryckere, T., Martens, L.: Context aware recommendations for user-generated content on a social network site. In: Proceedings of the Seventh European Conference on European Interactive Television Conference, pp. 133–136. ACM (2009)
Guy, I., Zwerdling, N., Carmel, D., Ronen, I., Uziel, E., Yogev, S., Ofek-Koifman, S: Personalized recommendation of social software items based on social relations. In: Proceedings of the 3rd ACM Conference on Recommender Systems, pp. 53–60. ACM, 23 October 2009
DuBois, T., Golbeck, J., Kleint, J., Srinivasan, A.: Improving recommendation accuracy by clustering social networks with trust. In: Recommender Systems & the Social Web, vol. 532, pp. 1–8 (2009)
Chen, J., Geyer, W., Dugan, C., Muller, M., Guy, I.: Make new friends, but keep the old: recommending people on social networking sites. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 201–210. ACM (2009)
He, J., Chu, W.W.: A social network-based recommender system (SNRS), pp. 47–74. Springer, US (2010)
Song, Y., Zhang, L., Giles, C.L.: Automatic tag recommendation algorithms for social recommender systems. ACM Trans. Web (TWEB) 5(1), 4 (2011)
Lee, S.S., Chung, T., McLeod, D.: Dynamic item recommendation by topic modeling for social networks. In: 2011 Eighth International Conference on Information Technology New Generations (ITNG), pp. 884–889. IEEE (2011)
Naruchitparames, J., Güneş, M.H., Louis, S.J.: Friend recommendations in social networks using genetic algorithms and network topology. In: IEEE Congress of Evolutionary Computation (CEC), pp. 2207–2214. IEEE (2011)
WWW 2011 Tutorial Social Recommender Systems (2011). http://sysun.haifa.il.ibm.com/hrl/srs2011/index.html
Sahebi, S., Cohen, W.W.: Community-based recommendations: a solution to the cold start problem. In: Workshop on Recommender Systems and the Social Web, RSWEB (2011)
Quijano-Sánchez, L., Recio-Garcıa, J.A., Dıaz-Agudo, B.: Group recommendation methods for social network environments. In: 3rd Workshop on Recommender Systems and the Social Web, 5th ACM International Conference on Recommender Systems, RecSys, vol. 11 (2011)
Jiang, M., Cui, P., Liu, R., Yang, Q., Wang, F., Zhu, W., Yang, S.: Social contextual recommendation. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, pp. 45–54. ACM (2012)
Prasad, R.V., Kumari, V.V.: A categorical review of recommender systems. Int. J. Distrib. Parallel Syst. 3(5), 73–83 (2012)
Kywe, S.M., Lim, E.P., Zhu, F.: A survey of recommender systems in twitter. In: International Conference on Social Informatics, pp. 420–433. Springer, Heidelberg (2012)
Sim, B.S., Kim, H., Kim, K.M., Youn, H.Y: Type-based context-aware service Recommender System for social network. In: 2012 International Conference on Computer, Information and Telecommunication Systems (CITS), pp. 1–5. IEEE (2012)
Zhang, Y., Zhang, B., Gao, K., Guo, P., Sun, D.: Combining content and relation analysis for recommendation in social tagging systems. Physica A: Stat. Mech. Appl. 391(22), 5759–5768 (2012)
Liu, X., Aberer, K.: SoCo: a social network aided context-aware recommender system. In: Proceedings of the 22nd International Conference on WWW, pp. 781–802.ACM (2013)
Zhao, G., Lee, M. L., Hsu, W., Chen, W., Hu, H.: Community-based user recommendation in uni-directional social networks. In: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, pp. 189–198. ACM (2013)
Agarwal, V., Bharadwaj, K.K.: A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity. Soc. Netw. Anal. Min.ng 3(3), 359–379 (2013)
Kamath, K.Y., Popescu, A.M., Caverlee, J.: Board recommendation in pinterest. In: UMAP Workshops (2013)
Nguyen, T.L., Cao, T.H.: Multi-group-based User Perceptions for Friend Recommendation in Social. In: Pacific-Asia Conference on Knowledge Discovery and Data Mining, vol. 8643, pp. 525–534. Springer (2014)
Lakshminarasimhan, V.: A Latent Factor Model for Board Recommendations in Pinterest. Diss. Texas A&M University, (2014)
Kislyuk, D., Liu, Y., Liu, D., Tzeng, E., Jing, Y.: Human Curation and Convnets: Powering Item-to-Item Recommendations on Pinterest (2015). arXiv preprint arXiv:1511.04003
Wu, L., Shah, S., Choi, S., Tiwari, M., Posse, C.: The Browsemaps: collaborative filtering at LinkedIn. In: RSWeb@ RecSys (2014)
Lian, D., Ge, Y., Zhang, F., Yuan, N. J., Xie, X., Zhou, T., Rui, Y.: Content-aware collaborative filtering for location recommendation based on human mobility data. In: 2015 IEEE International Conference on Data Mining (ICDM), pp. 261–270. IEEE (2015)
Parvazeh, F., Harounabadi, A., Naizari, M.A.: A recommender system for making friendship in social networks using graph theory and users profile. J. Curr. Res. Sci. S 1, 535–544 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this paper
Cite this paper
Revathy, V.R., Pillai, A.S. (2018). Classification and Applications of Social Recommender Systems. In: Abraham, A., Cherukuri, A., Madureira, A., Muda, A. (eds) Proceedings of the Eighth International Conference on Soft Computing and Pattern Recognition (SoCPaR 2016). SoCPaR 2016. Advances in Intelligent Systems and Computing, vol 614. Springer, Cham. https://doi.org/10.1007/978-3-319-60618-7_70
Download citation
DOI: https://doi.org/10.1007/978-3-319-60618-7_70
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-60617-0
Online ISBN: 978-3-319-60618-7
eBook Packages: EngineeringEngineering (R0)