
Abstract
This paper presents a hybrid method for automatic stress prediction that we apply to GLAFF-IT, a large-scale Italian lexicon we extracted from GLAW-IT, a Machine-Readable Dictionary grounded on Wikizionario. Our approach combines heuristic rules and a logistic model trained on the words’ sets of phonological features. This model reaches a 98.1% accuracy. The resulting resource is a large lexicon for the Italian language that we release under a free licence. It includes morphological and phonological information for each of its 457,702 entries. As of today, it is the only Italian lexicon featuring both large coverage and indication of stress position.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
As a consequence of the expansion of corpus and data-driven approaches to language, lexical resources (LRs) are nowadays essential for quantitative and qualitative studies of the language. Despite the linguistic richness available in existing LRs (morphological, morpho-syntactic annotations, semantic relations, etc.), phonological information such as the phonemic transcriptions of lexical forms and stress markers, is often not reported by such resources. This lack is problematic for data-based phonological analysis of the language and for phonetic and prosodic studies. Phonologists are interested in the sounds that are distinctive in a given language and on the rules that govern these sounds. In this context, the availability of a phonological lexicon tagged with stress placement is a prior condition for any investigations in the phonological domain. Phonological and stress information are also necessary in psycholinguistics where researchers manipulate a large set of word properties in order to design experimental protocols. Moreover, phonological lexicons reporting word stress and prosodic information are crucial in language acquisition analysis [12] and in the study of word recognition [16]. In a more practical perspective, phonological lexicons may integrate with other modules in NLP applications as, for example, text-to-speech systems [7].
Most resources conceived for the Italian language do not provide any word stress information and, more generally, they do not report phonological transcriptions at all [3, 4, 14, 17]. An exception is represented by PhonItalia [8], an Italian lexicon designed for researchers working in the psycholinguistic domain. Besides the orthographic forms and their lemmas, PhonItalia also reports the phonological encoding of words with the stress placement. Although the resource provides a comprehensive range of phonological and distributional information, its limited coverage (120,000 entries) constitutes a serious deterrent for its utilisation in quantitative/descriptive language analysis and for its exploitation in the NLP domain.
In this paper, we present a hybrid method for the prediction of Italian stress and we apply it to a large-scale morpho-phonological lexicon. Our method combines phonologically-motivated rules with a logistic regression model (henceforth logit model) for the automatic prediction of stressed/unstressed vowels. By exploiting this method we enrich s present in a large Italian lexicon, GLAFF-IT, with the word stress placement. Besides the lexical resource itself, a significant contribution of this work is the method we developed for stress prediction. Used here to complete the current version of the lexicon, the method will also prove useful in the future to generate the transcriptions and stress placements of the neologisms that are regularly added to Wikizionario (or potentially originating from other sources). The paper describes the creation of GLAFF-IT from a machine-readable dictionary that encodes the Wikizionario’s micro- and macrostructure (Sect. 2). We present the lexicon and explain how we complete it with the missing forms by exploiting the systematic regularities of the Italian language regarding the orthography and the phonology. Section 3 focuses on the phonological transcriptions of GLAFF-IT and the problematic issue of Italian stress. In this section, we propose a hybrid method adopted for the stress assignment. The evaluation of the predictions and some conclusions are given in Sect. 4.

General structure of the article danno in GLAW-IT
2 GLAFF-IT, a Large-Scale Italian Lexicon
2.1 GLAW-IT
In a previous paper [6], we introduced GLAW-IT, a free machine-readable dictionary (MRD) that encodes in a workable XML format the micro- and macrostructure of Wikizionario, the Italian edition of Wiktionary.Footnote 1 The method used to convert Wikizionario into GLAW-IT is similar to the conversion process from Wiktionnaire (the French language edition of Wiktionary) to GLAWI [10, 15]. GLAW-IT contains all the lexical knowledge found in Wikizionario. Articles may include fields reporting etymologies, definitions, lemmas and inflected forms, lexical semantic and morphological relations, hyphenations, translations and phonological transcriptions. GLAW-IT does not report systematically all this kind of information. The basic unit of GLAW-IT is the wordform and when some homographs correspond to the same wordform, the article contains a separate POS section for each one of them. An example is reported in Fig. 1 for the entry danno, which is both the lemma (masculine singular) of danno ‘damage’ and the inflected forms (indicative present, 3rd person plural) of the verb dare ‘to give’. As we can see, the stress placement is reported independently in the hyphenation field (dàn|no) as well as in the phonological transcription ( ). It may also occur in only one of the two fields or be missing. Conceived as a general-purpose MRD, GLAW-IT is intended to be to used as such or as a starting point to tailor specific lexicons. In the section below, we explain how we derived GLAFF-IT (which stands for Un Grande Lessico ‘Tuttofare’ dell’Italiano, ‘A Large Versatile Italian Lexicon’) from GLAW-IT.
). It may also occur in only one of the two fields or be missing. Conceived as a general-purpose MRD, GLAW-IT is intended to be to used as such or as a starting point to tailor specific lexicons. In the section below, we explain how we derived GLAFF-IT (which stands for Un Grande Lessico ‘Tuttofare’ dell’Italiano, ‘A Large Versatile Italian Lexicon’) from GLAW-IT.
2.2 From GLAW-IT to GLAFF-IT
A first step in the creation of GLAFF-IT is filtering GLAW-IT by all the morphosyntactic and phonological tags and collecting all the inflected forms related to each lemma. In GLAW-IT, for a given lemma not all the inflected forms of the paradigm are present. This compels us to complete the missing forms by exploiting the systematic variations of Italian inflection with respect to each grammatical class. In particular, given some orthographic preconditions, certain inflected forms are totally predictable from other forms of the same paradigm. For example, for a particular set of missing nouns, we have generated the Plural Masculine forms from their Singular forms. Specifically, we have applied the general rule governing the alternation Masculine Singular/Masculine Plural for those nouns ending in -o, like allomorfo (‘allomorph’), which change the last letter in -i for the Plural (Masculine) forms (allomorfi, ‘allomorphs’). We report below the main deterministic inflection rules we implemented for the generation of the missing forms:
Nouns:
-
lemma’s Feminine Singular ending = -a \(\rightarrow \) -e for the Feminine Plural, as in casa ‘home’ \(\rightarrow \) case ‘homes’
-
lemma’s Feminine Singular ending = -e \(\rightarrow \) -i for the Feminine Plural, as in siepe ‘hedge’ \(\rightarrow \) siepi ‘hedges’
-
lemma’s Feminine Singular ending = -ista \(\rightarrow \) -iste for the Feminine Plural, as in rivista ‘magazine’ \(\rightarrow \) riviste ‘magazines’
Adjectives:
-
lemma’s (Singular Masculine) ending = -ico \(\rightarrow \) -ici, -ica, -iche respectively for the Masculine Plural, Feminine Singular and Plural, as in magnifico ‘magnificent’ \(\rightarrow \) magnifici, magnifica, magnifiche
-
lemma’s (Singular Masculine) ending = -go or -co (but not -ico) \(\rightarrow \) -(c)(g)hi, -(c)(g)a, -(c)(g)he respectively for the Masculine Plural, Feminine Singular and Plural, as in metallico ‘metallic’ \(\rightarrow \) metallici, metallica, metalliche
Verbs:
-
for the highly regular conjugation -are, we generate the missing verbal forms by adding regular inflectional suffixes to the stem base of the verb (which is always detectable). For example the Gerund and the Singular and Plural Present Participle of the verb manipolare ‘to manipulate’ are created by adding respectively -ando, -ante and -anti to the stem base manipol: manipolando, manipolante and manipolanti. When missing, we create 54 verbal forms of the paradigm by exploiting the regular inflectional suffixes of the Italian conjugation.
The aforementioned inflection rules enabled us to generate 42,845 new wordforms which are integrated into GLAFF-IT. Table 1 reports the number of lemmas extracted from GLAW-IT and the number of forms generated by the aforementioned rules. The current version of GLAFF-IT counts 37,320 lemmas for 457,702 wordforms and includes nouns, verbs, adjectives and adverbs.Footnote 2 Each entry of the lexicon includes a wordform, a tag in MULTEXT-GRACE format [13] specifying the main syntactic category and inflection features, a lemma and API phonological transcriptions with the stress placement when present in GLAW-IT. An extract of GLAFF-IT is reported in Fig. 2. This version has been converted into Lexical Markup Framework, as illustrated in Fig. 3.

An extract of GLAFF-IT.

Extract of GLAFF-IT in Lexical Markup Framework
As is the case for the inflected forms, phonological information may be absent from GLAW-IT. The next section describes the automatic generation of missing phonological transcriptions and stress placements.
3 The Problematic Italian Stress Issue
3.1 Phonological Transcriptions and Stress in GLAW-IT
Only 4.2% of GLAW-IT’s wordforms (corresponding to 17,720 articles) include phonological transcriptions. 98.5% of these transcriptions also report stress placement. The stress information has been taken either from the phonological field or from the hyphenation field (cf. Sect. 2.1). Table 2 provides a breakdown with respect to the four grammatical classes.
In order to assess GLAW-IT’s phonological transcriptions, we compare them to those of PhonItalia. We first build the intersection of their entries, resulting in 66,371 orthographic forms (that corresponds to 15% of GLAW-IT and 57% of PhonItalia’s vocabularies). The number of wordforms per POS contained in this intersection, as well as the proportion of forms having transcriptions and stress placements in GLAW-IT, are reported in Table 3.
We then compared the 11,410 shared entries in order to check the correspondence of their transcriptions and stress placements. The results of the comparison are given in Table 4: GLAW-IT and PhonItalia present a 87% agreement both for the transcriptions and the stress placement. The main differences stem from the inventory of phonems used by the two resources. For example, in the group of the nasal consonants, GLAW-IT marks the velar nasal  (as in <anche> ‘also’
(as in <anche> ‘also’  ), which is absent in PhonItalia (where <anche> is transcribed
), which is absent in PhonItalia (where <anche> is transcribed  ). In such a case, our comparison, based on the exact matching of phonemes, leads to a disagreement.
). In such a case, our comparison, based on the exact matching of phonemes, leads to a disagreement.
3.2 Automatic Generation of Phonological Transcriptions in GLAFF-IT
This section describes a method to generate phonological transcriptions from orthographic forms. We used this method to transcribe each wordform from GLAFF-IT when no transcription is given in GLAW-IT.
Knowing the pronunciation of an Italian word is enough to know its orthography (with very few exceptions, e.g.  in some words is written as <cu> - e.g. <cuore> ‘heart’
in some words is written as <cu> - e.g. <cuore> ‘heart’  - instead of the more common <qu> - e.g. <quale> ‘which’
- instead of the more common <qu> - e.g. <quale> ‘which’  ). The opposite is not true in general: if most of the Italian graphemes are mapped one-to-one to phones, some cases do not allow automatic conversion. Here are some representative examples:
). The opposite is not true in general: if most of the Italian graphemes are mapped one-to-one to phones, some cases do not allow automatic conversion. Here are some representative examples:
-
a written <e> can be realised as
 or
or  when stressed. This distinction is crucial because it enables to differentiate homographic words having the same stress such as <pesca> =
when stressed. This distinction is crucial because it enables to differentiate homographic words having the same stress such as <pesca> =  ‘fishing’ and
‘fishing’ and  ‘peach’
‘peach’ -
a written <o> can be realised as
 (as in <asino> ‘donkey’
(as in <asino> ‘donkey’  ) or
) or  when stressed (as in <rosa> ‘rose’
when stressed (as in <rosa> ‘rose’ 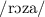 )
) -
a written <z> can be the voiced affricate
 as in <zaino> ‘backpack’
as in <zaino> ‘backpack’  or unvoiced affricate
or unvoiced affricate  as in <canzone> ‘song’
as in <canzone> ‘song’ 
-
a written <s>, intervocalic or after suffixes, can be realised as
 or
or  as <casa> =
as <casa> =  ‘home’, <rosa> =
‘home’, <rosa> =  ‘rose’, <transatlantico> =
‘rose’, <transatlantico> =  ‘transatlantic’, <transiberiano> =
‘transatlantic’, <transiberiano> =  ‘trans-Siberian’)
‘trans-Siberian’) -
<j>, <y> and <w>, mostly found in loanwords (as in ‘jazz’, ‘yacht’, ‘know-how’), can represent a wide range of phonemes:
 ,
,  ,
,  ,
,  ,
,  ,
,  , etc.
, etc.
 or
or  when stressed. This distinction is crucial because it enables to differentiate homographic words having the same stress such as <pesca> =
when stressed. This distinction is crucial because it enables to differentiate homographic words having the same stress such as <pesca> =  ‘fishing’ and
‘fishing’ and  ‘peach’
‘peach’ (as in <asino> ‘donkey’
(as in <asino> ‘donkey’  ) or
) or  when stressed (as in <rosa> ‘rose’
when stressed (as in <rosa> ‘rose’ 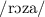 )
) as in <zaino> ‘backpack’
as in <zaino> ‘backpack’  or unvoiced affricate
or unvoiced affricate  as in <canzone> ‘song’
as in <canzone> ‘song’ 
 or
or  as <casa> =
as <casa> =  ‘home’, <rosa> =
‘home’, <rosa> =  ‘rose’, <transatlantico> =
‘rose’, <transatlantico> =  ‘transatlantic’, <transiberiano> =
‘transatlantic’, <transiberiano> =  ‘trans-Siberian’)
‘trans-Siberian’) ,
,  ,
,  ,
,  ,
,  ,
,  , etc.
, etc.To set up a letter-to-phoneme mapping, henceforth orth2phon, we distinguished unambiguous from ambiguous cases:
- Unambiguous cases.:
-
We adopted the conversion rules grapheme(s)-to-phoneme only for the unambiguous cases in which we distinguished transparent and opaque conditions. For example, some cases of transparent grapheme-to-phoneme mapping are given by <p> \(\rightarrow \)
 (<pane> ‘bread’
(<pane> ‘bread’  ), <l> \(\rightarrow \)
), <l> \(\rightarrow \)  (<lino> ‘linen’
(<lino> ‘linen’ 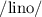 ) or <t> \(\rightarrow \)
) or <t> \(\rightarrow \)  (<tutto> ‘all’
(<tutto> ‘all’  ). Less transparent cases of mapping are <gli> \(\rightarrow \)
). Less transparent cases of mapping are <gli> \(\rightarrow \)  (<figlio> ‘son’
(<figlio> ‘son’  ) and <gli> \(\rightarrow \)
) and <gli> \(\rightarrow \)  (<siglare> ‘to initial’
(<siglare> ‘to initial’  ). Conversely, opaque cases need the orthographic context to be converted in phonemes. Opaque cases are for example <ch> \(\rightarrow \)
). Conversely, opaque cases need the orthographic context to be converted in phonemes. Opaque cases are for example <ch> \(\rightarrow \)  (<anche> ‘also’
(<anche> ‘also’  ), <q> \(\rightarrow \)
), <q> \(\rightarrow \)  (<quadri> ‘paintings’
(<quadri> ‘paintings’  ), <c> \(\rightarrow \)
), <c> \(\rightarrow \)  (<casa> ‘home’
(<casa> ‘home’  ). In many cases the stressed vowel reported in the hyphenation information can be used for the disambiguation of some ambivalent phonemes such as <e> or <o> that are respectively realised as
). In many cases the stressed vowel reported in the hyphenation information can be used for the disambiguation of some ambivalent phonemes such as <e> or <o> that are respectively realised as  and
and  when stressed.
when stressed. - Ambiguous cases.:
-
We encoded by a ad hoc capital letter all the cases which are not unambiguously convertible. For example, an intervocalic <s> may lead to the two different phonemes
 or
or  and cannot be automatically predicted. We choose to encode such cases into capital letters (here, intervocalic <s> \(\rightarrow \) S). We define eight different ambiguous cases:
and cannot be automatically predicted. We choose to encode such cases into capital letters (here, intervocalic <s> \(\rightarrow \) S). We define eight different ambiguous cases:(1) E =
 or
or  ; (2) O =
; (2) O =  or
or  ; (3) I =
; (3) I =  ,
,  or \(\emptyset \); (4) U =
or \(\emptyset \); (4) U =  or
or  ; (5) S =
; (5) S =  or
or  ; (6) Z =
; (6) Z = 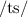 or
or  ; (7) J =
; (7) J =  or
or  ; (8) W =
; (8) W =  or
or 
 (<pane> ‘bread’
(<pane> ‘bread’  ), <l>
), <l>  (<lino> ‘linen’
(<lino> ‘linen’ 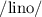 ) or <t>
) or <t>  (<tutto> ‘all’
(<tutto> ‘all’  ). Less transparent cases of mapping are <gli>
). Less transparent cases of mapping are <gli>  (<figlio> ‘son’
(<figlio> ‘son’  ) and <gli>
) and <gli>  (<siglare> ‘to initial’
(<siglare> ‘to initial’  ). Conversely, opaque cases need the orthographic context to be converted in phonemes. Opaque cases are for example <ch>
). Conversely, opaque cases need the orthographic context to be converted in phonemes. Opaque cases are for example <ch>  (<anche> ‘also’
(<anche> ‘also’  ), <q>
), <q>  (<quadri> ‘paintings’
(<quadri> ‘paintings’  ), <c>
), <c>  (<casa> ‘home’
(<casa> ‘home’  ). In many cases the stressed vowel reported in the hyphenation information can be used for the disambiguation of some ambivalent phonemes such as <e> or <o> that are respectively realised as
). In many cases the stressed vowel reported in the hyphenation information can be used for the disambiguation of some ambivalent phonemes such as <e> or <o> that are respectively realised as  and
and  when stressed.
when stressed. or
or  and cannot be automatically predicted. We choose to encode such cases into capital letters (here, intervocalic <s>
and cannot be automatically predicted. We choose to encode such cases into capital letters (here, intervocalic <s>  or
or  ; (2) O =
; (2) O =  or
or  ; (3) I =
; (3) I =  ,
,  or
or  or
or  ; (5) S =
; (5) S =  or
or  ; (6) Z =
; (6) Z = 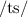 or
or  ; (7) J =
; (7) J =  or
or  ; (8) W =
; (8) W =  or
or 
We first applied orth2phon to the entries from the intersection between GLAW-IT and PhonItalia described in Table 3. We then compared the agreement between the two resources on their phonological transcriptions and stress placements. As can be seen in the Table 5, the orth2phon coding increases GLAW-IT and PhonItalia’s agreement on transcriptions from 86% (cf. Table 4) to 92% and the agreement on stress placement (from 86% to from 90%).
Finally, the orth2phon method enabled us to generate all the phonological transcriptions missing from GLAFF-IT. In the next section we introduce our method for the prediction of the stress placement in the phonological transcriptions of GLAFF-IT.
3.3 A Hybrid Method for Stress Prediction in GLAFF-IT
Stress placement is lexically marked in Italian [1, 11] and has a contrastive function: capito  ‘I happen by’ vs. capito
‘I happen by’ vs. capito  ‘understood’ vs. capitò
‘understood’ vs. capitò  ‘it happened’. This means that a priori the speaker should have a phonological knowledge of the word to pronounce it correctly (unless the stress is on the last vowel: in this case, the stress is orthographically marked as in capitò).
‘it happened’. This means that a priori the speaker should have a phonological knowledge of the word to pronounce it correctly (unless the stress is on the last vowel: in this case, the stress is orthographically marked as in capitò).
As Fig. 1 shows, GLAW-IT can report word stress information in two different sections: (a) in the phonological transcriptions and (b) in the hyphenation of the word in which the stressed vowel is orthographically marked. By gathering information from both these sections we collect 59,891 wordforms presenting a stress marker (Table 6). In this section, we present a hybrid method which allows us to complete the stress information for the remaining 397,812 wordforms of GLAFF-IT by combining heuristic rules and predictions performed by a logit model.
Heuristic Rules
In some known cases, stress placement in Italian is deterministic. We design a set of heuristic rules in order to predict words’ stress in such situations:
-
Stress position is generated for the words in which the stressed vowel is orthographically marked, as in <liquidità> ‘liquidity’
 or <avrò> ‘I will have’
or <avrò> ‘I will have’  .
. -
Bisyllabic words in which the last vowel is not graphically marked always have the stress on the first vowel, as <gonna> ‘skirt’
 or <casa> ‘home’
or <casa> ‘home’  .
. -
Some verbs with particular endings have regular stress patterns. For example, it is the case of the verbal ending
 which identifies the 1st person imperfect indicative as in <amavamo> ‘we were loving’
which identifies the 1st person imperfect indicative as in <amavamo> ‘we were loving’  or the ending of 3rd person present conditional
or the ending of 3rd person present conditional  as in <amerebbero> ‘(they) would love’
as in <amerebbero> ‘(they) would love’  . We distinguished 15 verbal endings (mostly coming from the subjunctive and conditional mood) exhibiting predictable stressed vowels.
. We distinguished 15 verbal endings (mostly coming from the subjunctive and conditional mood) exhibiting predictable stressed vowels.
 or <avrò> ‘I will have’
or <avrò> ‘I will have’  .
. or <casa> ‘home’
or <casa> ‘home’  .
. which identifies the 1st person imperfect indicative as in <amavamo> ‘we were loving’
which identifies the 1st person imperfect indicative as in <amavamo> ‘we were loving’  or the ending of 3rd person present conditional
or the ending of 3rd person present conditional  as in <amerebbero> ‘(they) would love’
as in <amerebbero> ‘(they) would love’  . We distinguished 15 verbal endings (mostly coming from the subjunctive and conditional mood) exhibiting predictable stressed vowels.
. We distinguished 15 verbal endings (mostly coming from the subjunctive and conditional mood) exhibiting predictable stressed vowels.By exploiting the heuristic rules, we determine the stress placement for 289,717 forms. Table 6 reports the details of this stress generation. This processing mainly involves the verbal entries (288,095 stress placements generated) and a limited number of nouns and adjectives. This fact is quite unsurprising, given that Italian stress is lexically marked and so the application of possible heuristics is highly constrained for nouns and adjectives.
Machine Learning
Stress prediction has been performed for the 108,095 remaining wordforms for which no heuristic rule has been applied. We use a model that has learned the phonological contexts for stressed and unstressed Italian vowels. Orthographic and phonological context-based approaches have been extensively used in the text-to-speech domain for stress detection [2, 7] and for accenting unknown words in a specialised language [18]. The rationale behind our approach is that the exploitation of the phonological neighbourhood of a vowel helps estimate its probability of being stressed or unstressed.
We trained a feed-forward (one hidden layer) neural network, using a logistic activation function, encoding the phonological neighbourhoods of the unstressed and the stressed vowel (respectively 0 and 1). Such a method has been used successfully in similar settings for the syllabification of Italian words [5]. In our model, the representation of the input data was constituted by each vowel composing the word with its left and right phonological context. The Fig. 4 reports the representation for two Italian words, <decadere> ‘to decay’  and <decidere> ‘to decide’ /
and <decidere> ‘to decide’ / /. Although phonologically quite similar and with identical syllabic structure, the two words present different stress placement: on the third vowel for <decadere> and on the second for <decidere>. In the input representation, the binary response unstressed/stressed vowel (0/1) is mapped to the left (L) and right (R) phonological context of the vowels (which are in Focus position). Each context defines the phonemes occurring in a given position with respect to the vowel in Focus. For example, the \(L_{1}\) and \(R_{1}\) contexts indicate respectively the phonemes occupying the first position on the left and the first position on the right with reference to the Focus. There are as many rows as the number of vowels in the word. The number of contexts considered is determined by the phonological length of the words: the longest word imposes the final number of contexts that will be equal to its number of phonemes N - 1 for L and R. In our input representation, each phoneme is encoded as a set of binary features defining the place and the manner of articulation. Although some authors report a clear correlation between stress patterns and phonological similar words [9], our choice was largely motivated by phonological reasons, with the rationale of taking into account the specific phonemic nature of each phoneme according to a set of phonologically-based features. We distinguished 14 features for all the Italian phonemes:
/. Although phonologically quite similar and with identical syllabic structure, the two words present different stress placement: on the third vowel for <decadere> and on the second for <decidere>. In the input representation, the binary response unstressed/stressed vowel (0/1) is mapped to the left (L) and right (R) phonological context of the vowels (which are in Focus position). Each context defines the phonemes occurring in a given position with respect to the vowel in Focus. For example, the \(L_{1}\) and \(R_{1}\) contexts indicate respectively the phonemes occupying the first position on the left and the first position on the right with reference to the Focus. There are as many rows as the number of vowels in the word. The number of contexts considered is determined by the phonological length of the words: the longest word imposes the final number of contexts that will be equal to its number of phonemes N - 1 for L and R. In our input representation, each phoneme is encoded as a set of binary features defining the place and the manner of articulation. Although some authors report a clear correlation between stress patterns and phonological similar words [9], our choice was largely motivated by phonological reasons, with the rationale of taking into account the specific phonemic nature of each phoneme according to a set of phonologically-based features. We distinguished 14 features for all the Italian phonemes:
-
1.
Voicing (VO): marks that the phonemes is voiced - or not
-
2.
Bilabial (BI): consonants articulated with both lips
-
3.
Labiodentals (LD): consonants articulated with the lower lip and the upper teeth
-
4.
Dental-alveolar (DA): consonants articulated with a flat tongue against the alveolar ridge and upper teeth
-
5.
Palato-alveolar (PA): consonants articulated with the blade of the tongue behind the alveolar ridge
-
6.
Palatal (PL): consonants articulated with the body of the tongue raised against the hard palate
-
7.
Velar (VE): consonants articulated with the back part of the tongue against the soft palate
-
8.
Nasal (NA): consonants produced with a lowered velum, allowing air to escape freely through the nose
-
9.
Stop (SP): consonants in which the vocal tract is blocked, so that all airflow ceases
-
10.
Affricate (AF): consonants that begins as a stop and conclude with a sound of friction
-
11.
Fricative (FR): consonants produced by the friction of breath in a narrow opening
-
12.
Glides (GL): consonants which have is a sound that is phonetically similar to a vowel
-
13.
Liquid (LQ): consonants produced when the tongue approaches a point of articulation within the mouth but does not come close enough to obstruct
-
14.
Vowel (VW): marks that the phoneme is a vowel, without any specifications

Input representation for two Italian words, <decadere> (/ /) ‘to decay’ and <decidere> (/
/) ‘to decay’ and <decidere> (/ /) ‘to decide’.
/) ‘to decide’.
Features 2 to 7 specify the place of articulation of the phonemes, while the manner is given by features 8–13. Feature 1 concerns voiced consonants and feature 14 marks the presence of a vowel. Table 7 reports the phonological feature encoding for the phonemes of the word <decadere> (/ /) ‘to decay’. Although the three phonemes
/) ‘to decay’. Although the three phonemes  and
and  are different, they share common phonological features as, for example, Stop for
are different, they share common phonological features as, for example, Stop for  and
and  or Voicing and Dental-alveolar for
or Voicing and Dental-alveolar for  and
and  .
.
 /) ‘to decay’, see Table 4.
/) ‘to decay’, see Table 4.We designed our test sets by sampling respectively 10,000 stressed wordforms from GLAFF-IT and absent from PhonItalia, and 10,000 stressed wordforms from PhonItalia and absent from GLAFF-IT. Our training dataset is composed of all the stressed wordforms reported in Table 6, excluding those used for the test sets. We implemented different architectures for the model by varying the number of neurons of the hidden layer. For a set of architectures, POS information have also been considered as features in the input words. A detailed evaluation of the stress prediction output is reported in the next section.

ROC curves for the four architectures. Testing dataset: 10,000 stressed wordforms from GLAFF-IT. Solid lines represent models integrating POS information about the word, dotted lines represent models excluding this information.
4 Evaluation and Conclusions
We designed four architectures by varying the size of the hidden layer (5, 10, 20 and 40 neurons). For each architecture, we trained and evaluated two models, including or excluding the POS information of the word. In our approach, a word presents one (and only one) stressed vowel. During the testing phase, we identify the vowel in the word with the highest probability of being stressed: this vowel represents the stressed vowel and thus determines the stress position of the word. Selecting the vowel with the highest probability is computationally convenient because we do not have to identify the probability threshold for separating stressed and unstressed vowels. The Fig. 5 displays the behaviour of the four architectures by ROC curves with respect to the 10,000 GLAFF-IT test wordforms. The ROC curves show the trade-off between the true positive rate (sensitivity, y-axis) and the false positive rate (1 - specificity, x-axis). Sensitivity refers to the proportion of the stressed vowels whereas specificity refers to the proportion of the unstressed vowels. The closer the curve follows the left-hand border, from the origin of axes (0.0 and 0.0) to the top left corner (0.0 and 1.0) and then to the top right corner (1.0 and 1.0), the more accurate the classification. The 5- and 10-neuron models exhibit a substantial false positive rate for the test data, meaning that the model predicts unstressed vowels wrongly categorised as stressed. The 20- and 40-neuron models are very good at classifying with a nearly perfect separation between the stressed and the unstressed vowels. The POS information (dotted lines in Fig. 5) does not seem to significantly affect the prediction. The Table 8 reports the percentages of correct stress prediction for the 10,000 words of the two testing datasets. We observe that the POS information does not improve the prediction (in some cases models without POS information exhibit a better prediction than the models with POS). The grammatical class was a crucial factor for the applicability of the heuristic rules used to predict the stress placement. We can see here that this is not true the stress prediction by the logit model. The 20-neuron model with POS information performs the best prediction and reaches more than 98% of correct stress predicted. We also notice a difference in terms of stress prediction between the two testing sets: the evaluation performed against the PhonItalia test reaches 89.1% of correct predictions by the best model (20-POS). This difference can be explained by the nature of the two test sets. For instance, the PhonItalia test lists a great number of loanwords such as <fairplay>, <academy> or <mission> which have a phonotactic structure totally different from the words of the training dataset. Moreover, the PhonItalia test contains verbs with clitic pronouns as <mangiarlo> ‘to eat it’ or locative clitic as <andateci> ‘you (2nd person plural) go there’ which are totally absent from the training data.
In this article, we have described the design of GLAFF-IT, a large-scale morphological and phonological lexicon for Italian language. In order to build this lexicon, we have implemented a set of methods to automatically (i) complete inflectional paradigms by generating the missing forms (ii) generate missing phonological transcriptions from the orthographic forms and finally (iii) predict the stress placement.
The hybrid method we designed for automatic stress prediction, based on a set of heuristic rules and the responses of a logit model, reliably predicts stressed and unstressed vowels. Applied to GLAFF-IT, it reaches an accuracy of 98.12%. To our knowledge, GLAFF-IT is the only free Italian lexicon featuring a large coverage (457,702 entries) and reporting phonological transcription with stress markings. Moreover, this model will be useful when updating the resource with the new entries regularly added to Wikizionario. Indeed, if contributors are prone to add new entries, they often neglect to provide inflectional and phonological information.
In the near future, we plan to add syllable boundaries to the phonological transcriptions of GLAFF-IT. Regarding the stress prediction, we intend to evaluate the adaptability of our model to other languages presenting variable stress placement. In a psycholinguistic perspective, the model’s responses could be compared to the responses provided by speakers with respect to the same set of stimuli, in order to assess the possible correlation between speakers and automatic predictions.
Notes
- 1.
Available at: http://redac.univ-tlse2.fr/lexicons/glawit.html.
- 2.
GLAFF-IT is freely available at: http://redac.univ-tlse2.fr/lexicons/glaffit.html.
References
Bafile, L.: Antepenultimate stress in italian and some related dialects: Metrical and prosodic aspects. Rivista di linguistica 11(2), 201–229 (1999)
Behravan, H., Hautamäki, V., Siniscalchi, S.M., Kinnunen, T., Lee, C.H.: i-Vector modeling of speech attributes for automatic foreign accent recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 24(1), 29–41 (2016)
Bel, N., Busa, F., Calzolari, N., Gola, E., Lenci, A., Monachini, M., Ogonowski, A., Peters, I., Peters, W., Ruimy, N., Villegas, M., Zampolli, A.: SIMPLE: a general framework for the development of multilingual lexicons. In: Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2000), Athens, Greece (2000)
Bertinetto, P.M., Burani, C., Laudanna, A., Lucia Marconi, D.R., Rolando, C.: Corpus e Lessico di Frequenza dell’Italiano Scritto (CoLFIS) (2005). http://linguistica.sns.it/CoLFIS/Home.htm
Calderone, B., Bertinetto, P.M.: From phonotactics to syllables. a psycho - computational approach. In: 46th Annual Meeting of the Societas Linguistica Europaea, Split, Croatia (2013)
Calderone, B., Sajous, F., Hathout, N.: GLAW-IT: a free large Italian dictionary encoded in a fine-grained XML format. In: Proceedings of the 49th Annual Meeting of the Societas Linguistica Europaea (SLE 2016), Naples, Italy, pp. 43–45 (2016)
Dou, Q., Bergsma, S., Jiampojamarn, S., Kondrak, G.: A ranking approach to stress prediction for letter-to-phoneme conversion. In: Proceedings of the 47th Annual Meeting of the ACL, pp. 118–126. Association for Computational Linguistics, Suntec, Singapore (2009)
Goslin, J., Galluzzi, C., Romani, C.: PhonItalia: a phonological lexicon for Italian. Behav. Res. Methods 46(3), 872–886 (2014)
Guion, S.G.: Knowledge of English word stress patterns in early and late Korean-English bilinguals. Stud. Second Lang. Acquisiti 27, 503–533 (2005)
Hathout, N., Sajous, F.: Wiktionnaire’s Wikicode GLAWIfied: a workable French machine-readable dictionary. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia (2016)
Krämer, M.: The Phonology of Italian. Oxford University Press, Oxford (2009)
Peperkamp, S.: Lexical exceptions in stress systems: arguments from early language acquisition and adult speech perception. Language 80(1), 98–126 (2004)
Rajman, M., Lecomte, J., Paroubek, P.: Grace GTR-3-2.1. Technical report, EPFL and INaLF (1997)
Roventini, A., Alonge, A., Calzolari, N., Magnini, B., Bertagna, F.: ItalWordNet: a large semantic database for Italian. In: Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2000), Athens, Greece, pp. 783–790 (2000)
Sajous, F., Hathout, N.: GLAWI, a free XML-encoded machine-readable dictionary built from the French Wiktionary. In: Proceedings of the of the eLex 2015 Conference, Herstmonceux, England, pp. 405–426 (2015)
Slowiaczek, L.M.: Stress and context in auditory word recognition. J. Psycholinguist. Res. 20(6), 465–481 (1991)
Talamo, L., Celata, C., Bertinetto, P.M.: derIvaTario: an annotated lexicon of Italian derivatives. Word Struct. 9(1), 72–102 (2016)
Zweigenbaum, P., Grabar, N.: Accenting unknown words in a specialized language. In: Proceedings of the ACL 2002 Workshop on Natural Language Processing in the Biomedical Domain, Philadelphia, PA, pp. 21–28 (2002)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Calderone, B., Pascoli, M., Sajous, F., Hathout, N. (2017). Hybrid Method for Stress Prediction Applied to GLAFF-IT, a Large-Scale Italian Lexicon. In: Gracia, J., Bond, F., McCrae, J., Buitelaar, P., Chiarcos, C., Hellmann, S. (eds) Language, Data, and Knowledge. LDK 2017. Lecture Notes in Computer Science(), vol 10318. Springer, Cham. https://doi.org/10.1007/978-3-319-59888-8_3
Download citation
DOI: https://doi.org/10.1007/978-3-319-59888-8_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-59887-1
Online ISBN: 978-3-319-59888-8
eBook Packages: Computer ScienceComputer Science (R0)