
Abstract
Standards like Long Term Evolution (LTE) employ Turbo coded QAM systems in order to achieve high data rates. Despite the fact that several mechanisms have been proposed in order to enhance the error performance of Turbo coded QAM systems, there is still the need to come up with novel or hybrid systems which can contribute towards further improved error performances. In this paper, a comparative analysis has been performed between symmetric and asymmetric LTE Turbo codes with the incorporation of techniques such as prioritization and regression based extrinsic information scaling. Results demonstrate that significant enhancement in the error performance throughout the whole Eb/N0 range can be obtained with high order modulation when these techniques are used. With both symmetric and asymmetric LTE Turbo codes employing 64-QAM and a code-rate of 1/3, an average gain of 0.3 dB below BERs of 10−1 is obtained over symmetric and asymmetric LTE Turbo codes.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Ever since Berrou et al. came up with Turbo codes - the powerful and near Shannon-limit [1] error correcting code [2, 3], several standards in the realm of digital communications have approved their deployment. The Long Term Evolution (LTE) [4, 5] and CDMA 2000 [6] standards have exploited Turbo coded QAM systems with the aim of obtaining high data rates and reliable transmission. The significant impact of Turbo codes has led the research community to unearth several techniques such as asymmetric Turbo encoding [7,8,9,10], prioritisation in Quadrature Amplitude Modulation (QAM) constellation mapping [9, 11, 12], scaling of extrinsic information and iterative detection [13,14,15] which have contributed towards the improvement in error performance and computational complexity reduction. An overview of these different techniques is presented next.
Interesting modifications have been proposed for conventional Turbo codes over the years. In [10], the authors have studied the error performance of asymmetric Turbo codes and demonstrated an improved performance in the pre-error floor as well as the error floor regions. In view to proceed with the work of [10], an evaluation of the performance of asymmetric and symmetric Turbo codes in a channel with Additive White Gaussian Noise (AWGN) was done in [16]. The results of the simulations presented in [16], have demonstrated that asymmetric Turbo codes can provide better performance than symmetric Turbo codes in addition to lower complexity of the decoder, provided a proper selection of the generator polynomials is made. Additionally, in [7], the authors have proposed a novel kind of Turbo codes with un-identical encoders specifically for interleavers of medium size. This scheme has been devised using the selection algorithm for the generation of polynomials corresponding to the largest spread Quadrature Permutation Polynomial (QPP) interleaver.
The prioritised QAM constellation mapping impacts the error performance of Turbo codes positively. This is achieved by making use of the Unequal Error Protection (UEP) property of the QAM constellation such that an increased protection is provided to the systematic information bits. Lüders et al. have applied this technique in [9]. The authors of [11] have proposed a system combining prioritised constellation mapping, adaptive Sign Difference Ratio (SDR) based extrinsic information scaling, and Joint Source Channel Decoding (JSCD) in order to enhance the error performance of Turbo coded 64-QAM. The results demonstrate that combining these techniques can help achieve a gain of 2.5 dB on average compared to conventional system of Turbo coded 64-QAM at Bit Error Rates (BERs) above 10−1. As an extended work of [11], the work in [12] studies the error performance of LTE Turbo codes with the same combination of techniques. Additionally, the prioritised constellation mapping is investigated with both 16-QAM and 64-QAM. The results presented demonstrate that with 16-QAM, the combination of all the techniques can help achieve an average gain of 1.7 dB over the conventional scheme at BERs above 10−1. With 64-QAM, a performance gain of 3 dB on average is obtained compared to the conventional scheme.
The objective of extrinsic information scaling is to improve the performance of the Turbo decoder by scaling its extrinsic information using a scale factor. For instance, the authors of [14] have deployed a constant scale factor in order to enhance the Max-Log-MAP Turbo decoding algorithm, while in [17], a modified MAP algorithm which uses a constant scale factor has been proposed. Interestingly though, in [13], a scaling scheme extending the Sign Difference Ratio (SDR) mechanism in [15] to dynamically obtain a scaling factor at each iteration for each data block has been proposed. In [18], a novel early stopping mechanism and extrinsic information scaling based on regression analysis for LTE Turbo codes was proposed. The results demonstrate an improved error performance in addition to reduced number of average iterations as compared to both the conventional scheme and the one making use of SDR based stopping and scaling.
The work presented in this paper aims at analysing the performance of LTE Turbo coded QAM systems integrating: asymmetric encoders, prioritisation in QAM constellation mapping, and regression analysis based extrinsic information scaling. At the transmitter side, the symmetric/asymmetric encoder operates on the input systematic information to output the encoded bits. Prioritised constellation mapping is then performed such that the highest priority is allocated to the systematic bits on the QAM constellation. Finally, a regression based extrinsic information scaling mechanism is used in the decoding mechanism at the receiver side. The performance of both symmetric and asymmetric Turbo codes was found to be almost similar but they outperformed the conventional LTE Turbo codes when prioritization and scaling were incorporated.
The organisation of this paper is as follows. The complete system model is described in Sect. 2. The simulation results and analysis are described in Sect. 3. Section 4 concludes the paper and provides some future works.
2 System Model
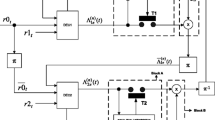
The system’s transmitter block diagram is shown in Fig. 1. The information bits are sent through the encoder in blocks of length equal to the interleaver size to output the systematic information S0 and the two parity information P1 and P2. The asymmetric encoding is achieved with the different generator polynomials for RSC1 and RSC2 [7, 10, 16]. After the sub-block interleaving, a prioritization QAM constellation mapping is performed so as to provide more protection to the systematic information bits. The modulated symbols are then transmitted over the AWGN channel.

Transmitter system.
The receiver side is shown in Fig. 2. \( P0_{t} ,P1_{t} \) and \( P2_{t} \) are the soft information which are forwarded to the turbo decoders. \( P0_{t} \) corresponds to the systematic bits while \( P1_{t} \) and \( P2_{t} \) correspond to the parity bits.

Receiver system [18].
The equations of the Max-Log-MAP algorithm [3, 19] for conventional turbo decoding are given next. The probability pertaining to the branch transition for DEC 1 at time instant \( t \), starting in state \( l' \) and ending in state \( l \) with an input bit i(i = 0 or 1) is:
Where,
\( P0_{t} \) and \( P1_{t} \) are the de-mapped soft-information bits corresponding to the bipolar equivalent of the transmitted systematic bits \( S_{{0_{t} }} \) and first parity bits, \( P_{{1_{t} }} \) respectively;
\( log(p_{t}^{1} \left( i \right)) \) is the natural logarithm of the a-priori probability corresponding to input bit \( i \) computed from the extrinsic information of the channel and fed to the first decoder;
\( \sigma^{2} \) is the noise variance.
The forward recursive variable, \( \alpha_{t}^{1} \left( l \right) \), at state \( l \) and time \( t \) for a decoder with \( {\text{M}}_{S} \) states is computed as:
The backward recursive variable,\( \beta_{t}^{1} \left( l \right) \), at state \( l \) and time \( t \) is computed as the following:
The Log-Likelihood Ratio (LLR), \( \wedge_{1}^{\left( n \right)} \left( t \right) \) at time \( t \) and \( n^{\text{th}} \) iteration for the first decoder is given as:
The extrinsic information, \( \wedge_{1e}^{\left( n \right)} \left( t \right) \) at time \( t \) and iteration \( n \) for the first decoder is given as:
Where,
\( \overline{ \wedge }_{2e}^{{\left( {n - 1} \right)}} (t) \) is the de-interleaved extrinsic information at time \( t \) and the \( (n - 1)^{\text{th}} \) iteration for the second decoder.
The same decoding operations are performed by DEC 2 using the inputs \( \overline{P0}_{t} \), \( P2_{t} \) and \( p_{t}^{2} \left( i \right) \).
Where,
\( p_{t}^{2} \left( i \right) \) is the a-priori probability with input bit \( i \) and computed from the channel extrinsic information to be sent to the second decoder;
\( \overline{P0}_{t} \) and \( P2_{t} \) are the de-mapped soft-information bits corresponding to the bipolar equivalent of the interleaved systematic bits \( \overline{{S_{{0_{t} }} }} \) and second parity bits, \( P_{{2_{t} }} \) respectively.
Additionally, at the Turbo decoder side, an extrinsic information scaling mechanism based on regression analysis is deployed. The Regression Analyser [18], outputs \( r_{d}^{2(n)} \) which is the factor for scaling. This factor is computed by measuring the linear correlation between the A-Posteriori LLR \( \left( {\Lambda _{d}^{\left( n \right)} \left( t \right)} \right) \) and the Extrinsic LLR \( \left( {\Lambda _{de}^{\left( n \right)} \left( t \right)} \right) \), where, the decoder number is \( d = \left\{ {1, 2} \right\} \); \( r_{d}^{2(n)} \) is the factor used to scale the extrinsic information from decoder d at iteration n; N is the packet length which is 6144 [4] in this simulation; \( \Lambda _{d}^{\left( n \right)} \left( t \right) \) is the t th a-posteriori LLR of the decoder d at time t and iteration n; The mean a-posteriori LLR, \( \widehat{\Lambda }_{d}^{\left( n \right)} \), of decoder d at iteration n and is computed as [18]:
\( \Lambda _{de}^{\left( n \right)} \left( t \right) \) is the t th extrinsic LLR at iteration n of decoder d; \( \widehat{\Lambda }_{de}^{\left( n \right)} \) is the mean extrinsic LLR at iteration n of decoder d and is computed as [18]:
n is the number of half-iterations and take values in {½, 1, … I max (maximum number of iterations)}.
The scale factor, \( r_{d}^{2(n)} \), is computed as follows:
3 Simulation Results and Analysis
The performance of the following schemes for LTE Turbo codes have been evaluated through simulation:
-
1.
Scheme 1: This scheme employs the symmetric LTE Turbo codes only.
-
2.
Scheme 2: This scheme employs the asymmetric LTE Turbo codes only.
-
3.
Scheme 3: This scheme employs the symmetric LTE Turbo codes with regression based scaling only.
-
4.
Scheme 4: This scheme employs the asymmetric LTE Turbo codes only with scaling based on regression.
-
5.
Scheme 5: This scheme employs the symmetric LTE Turbo codes with scaling based on regression and prioritization.
-
6.
Scheme 6: This scheme employs the asymmetric LTE Turbo codes with scaling based on regression and prioritization.
The generator polynomial in octal for both upper and lower encoders of the symmetric LTE Turbo code is given as G = [1, g1/g2], where g1 = 15 and g2 = 13. The generator polynomial of the upper encoder in the asymmetric LTE Turbo code is identical to that of the symmetric LTE Turbo code while that for the lower encoder is given as G = [1, g1/g2], where g1 = 13 and g2 = 15. The parameters of the QPP interleaver are: f 1 = 263; f 2 = 480; packet size, N = 6144 bits; maximum number of iterations, I max = 12; Code-rates: 1/3 and 1/2; Modulations: 16-QAM and 64-QAM; Channel: complex AWGN.
Figure 3 shows the BER performance of the six schemes with code-rate = 1/3 and 16-QAM. It can be observed that Schemes 3 and 4 outperform all the other schemes for BERs below 10−1. Schemes 3 and 4 provide an average gain of 0.3 dB below BERs of 10−1 as compared to Schemes 1 and 2 and an average gain of 0.25 dB below BERs of 10−1 compared to Schemes 5 and 6. Schemes 5 and 6 outperform Schemes 1 and 2 only for BERs above 10−4 and Schemes 3 and 4 only for BERs above 10−1.

BER performance of the schemes with code-rate = 1/3 and 16-QAM.
Figure 4 shows the BER performance for the schemes with code-rate = 1/2 and 16-QAM. It can be observed that Schemes 3 and 4 outperform all the other schemes for BERs below 10−1. Schemes 3 and 4 provide an average gain of 0.15 dB below BERs of 10−1 as compared to Schemes 1 and 2 and an average gain of 0.2 dB below BERs of 10−4 compared to Schemes 5 and 6. Schemes 5 and 6 outperform Schemes 1 and 2 only for BERs above 10−5.

BER performance for the schemes with 16-QAM and code-rate = 1/2.
Figure 5 shows the BER performance of the six schemes with code-rate = 1/3 and 64-QAM. It can be observed that Schemes 3, 4, 5 and 6 outperform Schemes 1 and 2 for BERs below 10−1. Schemes 3, 4, 5 and 6 provide an average gain of 0.3 dB below BERs of 10−1 as compared to Schemes 1 and 2.

BER performance of the schemes with code-rate = 1/3 and 64-QAM.
Figure 6 shows the BER performance for the schemes with code-rate = 1/2 and 64-QAM. It can be observed that Schemes 3, 4, 5 and 6 outperform Schemes 1 and 2 for BERs below 10−1. Schemes 3 and 4 provide an average gain of 0.4 dB below BERs of 10−1 as compared to Schemes 1 and 2. Schemes 5 and 6 outperform Schemes 1 and 2 for BERs above 10−6 and Schemes 3 and 4 only for BERs above 10−3.

BER performance for the schemes with 64-QAM and code-rate = 1/2.
4 Conclusion
In this paper, a comparative analysis has been performed between symmetric and asymmetric LTE Turbo codes with the incorporation of techniques such as prioritization and regression analysis based extrinsic information scaling. At the transmitter side, a symmetric/asymmetric encoder is used and a re-ordering technique is employed to prioritise the systematic information bits by placing them on the positions of the QAM constellation with highest protection. At the receiver side, an extrinsic information scaling mechanism based on regression analysis is used. Results demonstrate that significant enhancement in the error performance throughout the whole Eb/N0 range can be obtained with high order modulation schemes when prioritization and regression analysis based extrinsic information scaling techniques are used. With both symmetric and asymmetric LTE Turbo codes employing 64-QAM and a code-rate of 1/3, an average gain of 0.3 dB below BERs of 10−1 is obtained over symmetric and asymmetric LTE Turbo codes. The main contribution of this work is the performance analysis comparison of schemes with symmetric/asymmetric LTE Turbo encoders with prioritization and regression analysis based extrinsic information scaling. The comparison shows that the performance of both symmetric and asymmetric Turbo codes are similar but outperform the conventional LTE Turbo codes when prioritization and scaling are incorporated. Some interesting future works can be proposed based on the analysis in this work. A straightforward extension would be to assess the usability of the proposed combinations with non-binary Turbo codes. A more challenging future work would be to come up with a mathematical equation which would show the relationship between the error performance, modulation order, code-rates and channel quality. Further investigations can be performed for improving the performance of asymmetric Turbo codes with medium interleaver size.
References
Shannon, C.E.: A mathematical theory of communications. Part I Ann. Telecommun. Bell Syst. Tech. J. 27, 379–423 (1948)
Berou, C., Glavieux, A., Thitimajshima, P.: Near Shannon limit error-correcting coding and decoding: Turbo-codes. In: IEEE International Conference on Communications, Geneva (1993)
Vucetic, B., Yuan, J.: Turbo Codes: Principles and Applications. Kluwer Academic Publications, Boston (2000)
3GPP: Technical Specifications Rel. 8 (2009)
3GPP2: CDMA 2000 High Rate Packet Data Air Interface Specification. (2006). http://www.3gpp2.org/Public_html/specs/C.S0024-B_v1.0_060522.pdf. Accessed Nov 2012
Seisa, S., Toufik, I., Baker, M.: LTE - The UMTS Long Term Evolution: From Theory to Practice. John Wiley & Sons Ltd., New York (2009)
Cojocariu, D.T., Lazar, A.G.: Asymmetric turbo codes for LTE systems with medium frame length. In: Proceedings of SPAMEC, Cluj-Napoca, Romania (2011)
Khan, F.: LTE for 4G Mobile Broadband Air Interface Technologies and Performance. Cambridge University Press, New York (2009)
Lüders, H., Minwegen, A., Vary, P.: Improving UMTS LTE performance by UEP in high order modulation. In: 7th International Workshop on Multi-Carrier Systems & Solutions (MC-SS). Herrsching, Germany (2009)
Takeshita, Y., Collins, M., Massey, P., Costello, D.: A note on asymmetric turbo-codes. IEEE Comm. Letters 3(3), 69–71 (1999)
Fowdur, T.P., Beeharry, Y., Soyjaudah, K.M.S.: Performance of turbo coded 64-QAM with joint source channel decoding, adaptive scaling and prioritised constellation mapping, CTRQ. In: 6th International Conference on Communication Theory, Reliability, and Quality of Service, Venice, Italy (2013)
Fowdur, T.P., Beeharry, Y., Soyjaudah, K.M.S.: Performance of LTE turbo codes with joint source channel decoding, adaptive scaling and prioritised QAM constellation mapping. Int. J. Adv. Telecommun. 6(3&4), 143–152 (2013)
Lin, Y., Hung, W., Lin, W., Chen, T., Lu, E.: An efficient soft-input scaling for turbo decoding. In: IEEE International Conference on Sensor Networks, Ubiquitous and Trustworthy Computing Workshops (2006)
Vogt, J., Finger, A.: Improving the MAX-Log-MAP turbo decoder. Electr. Lett. 36(23), 1937–1939 (2000)
Wu, Y., Woerner, B., Ebel, J.: A simple stopping criterion for turbo decoding. IEEE Commun. Lett. 4(8), 258–260 (2000)
Kumar, M., Khedia, D.: Comparative performance evaluation of symmetric and asymmetric turbo codes for AWGN channel. Int. J. Comput. Electron. Electr. Eng. 2(3), 1–6 (2012)
Gnanasekaran, T., Duraiswamy, K.: Performance of unequal error protection using MAP algorithm and modified MAP in AWGN and fading channel. J. Comput. Sci. 2, 585–590 (2008)
Fowdur, T.P., Beeharry, Y., Soyjaudah, K.M.S.: A novel scaling and early stopping mechanism for LTE turbo code based on regression analysis. Ann. Telecommun. 1–20 (2016)
Fowdur, T.P., Soyjaudah, K.M.S.: Performance of joint source-channel decoding with iterative bit-combining and detection. Ann. Telecommun. 63(7–8), 409–423 (2008)
Acknowledgments
The authors would like to thank the University of Mauritius for providing the necessary facilities for conducting this research and the Tertiary Education Commission for its financial support.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Beeharry, Y., Fowdur, T.P., Soyjaudah, K.M.S. (2017). Performance Analysis of Symmetric and Asymmetric LTE Turbo Codes with Prioritisation and Regression Based Scaling. In: Fleming, P., Vyas, N., Sanei, S., Deb, K. (eds) Emerging Trends in Electrical, Electronic and Communications Engineering. ELECOM 2016. Lecture Notes in Electrical Engineering, vol 416. Springer, Cham. https://doi.org/10.1007/978-3-319-52171-8_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-52171-8_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-52170-1
Online ISBN: 978-3-319-52171-8
eBook Packages: EngineeringEngineering (R0)