
Abstract
This chapter brings forth the practical aspect of using genetic algorithms (GAs) in aiding PID (Proportional-Integral-Derivative) control design for real world industrial processes. Plants such water tanks, heaters, fans and motors are usually hard to tune on-site, especially after prolonged use of the equipment when degradation of performances is inevitable, while plants like seismic dampers have inherent nonlinear behaviors that make formal controller design difficult at best. Therefore, this chapter introduces a series of practical steps that can be taken by control engineers in order to (re)design viable PID controllers for their plants. This chapter describes how genetic algorithms can be applied to problems in control systems and model identification. Considering the plant inputs and outputs that can be observed during functioning, we offer a quick method for identifying model parameters, which can be used later by the genetic algorithm to find a suitable controller. While, in formal control theory, a raw estimation of the model parameters can significantly reduce the performance of a real-world system, the genetic algorithm method can find suitable controllers quickly and efficiently, offering access even to performance criteria that is hard to quantify in classical design procedure, such as integral indexes. The applicability of the GAs in real world problems is outlined through case studies that take into account the particularities of each system, from first to second order responses, the absence or presence of time delay, nonlinearities, constraints and controller performance. The steps performed in the case studies show how GAs have made the jump from their origins to a practicing engineer’s toolbox (GAOT-ECM in this case, a Genetic Algorithm Optimization Toolbox Extension for Control and Modeling). Moreover, a comprehensive analysis is performed, that takes into account both the various performance criteria, and the tuning parameters of the genetic algorithm, over the obtained models and controllers. The influence of the GA parameters is discussed in order to help practitioners choose the best suited GA configuration for their particular problem. In all, this chapter offers a comprehensive step-by-step application of genetic algorithms in industrial setting, from plant modeling to controller design.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
From the beginning of the computer age, scientists have been oriented toward developing intelligent techniques to outline the adaptive capabilities of computers and software entities. Over the years, these research endeavors have materialized into a variety of methods like expert systems, neural networks, fuzzy techniques, intelligent agents, evolutionary systems. In the field of computer science, evolutionary algorithms (EAs) are a subfield of artificial intelligence that is defined by algorithms that are generally based on Darwin’s “survival of the fittest” principle. Nowadays, a few categories of this field are: evolution strategies (ESs), genetic programming (GP), and genetic algorithms (GAs). From these classes, GAs and GP are particularly suitable in problems in which conventional optimizers are inefficient or inappropriate.
For this chapter, the considered EA class is genetic algorithms (GAs) [1], that are computer-based search methods patterned after the genetic evolution mechanisms of biological organisms that have adapted in highly competitive environments for millions of years. In technology and science, GAs have been used as adaptive algorithms and computational models of natural evolution systems [2]. GAs have been successfully applied to problems in various areas of study, and their popularity continues to increase because of their effectiveness, applicability, and ease of use. It has been shown that GAs are efficient for problems in control systems design [3] for both feedback [4, 5] and feedforward controllers [6], model selection [7, 8], and estimation of model parameters [9, 10]. GAs are used for a variety of problems, from experimental video identification [11], to instrument recognition [12], either stand-alone or in combinations with other intelligent methods [13], like fuzzy systems [14–18], neural networks [19–22], or even cooperative optimization [23].
Genetic algorithms are one of the most common heuristic methods of parameter tuning based on the minimization of computed or measured error signals. In practice, a dependence of the returned solutions on the particular specifications of the GA procedure (such as population size, mutation rate and so on) is observed, which enhances the need for better calibration of the GA parameters. These efforts can be categorized in three approaches [24]: (a) deriving the optimal values of a solution from empirical experiments, (b) controlling the GA parameters by varying them according to how often improvement of the current solution has been registered or including the GA running parameters in the chromosome codification, and (c) dimensional analysis and theoretical modeling. Also, the premature convergence of GAs has been another issue that has been discussed [25], together with the effects of non-random initial populations [26], and even genomic diversity [27, 28].
In order to overcome the shortcomings of the classic GAs [29–34] in tuning PID parameters, some applications have used a combination of genetic and interval algorithms [35], GA and immune system mechanism which introduce some recognition, immune memory and antibodies self-adjusting functions for main steam temperature control system [36], self-organizing genetic algorithms [37], adaptive genetic algorithms [38]. Another interesting approach regarding the increase of stabilization of a rotational inverted pendulum uses a variant of multi-objective genetic algorithms called Global Criterion Genetic Algorithm [39]. The good performances of the classic approach for tuning PID parameters with GAs is presented in [40], where a comparison with a variable parameter nonlinear PID (NL-PID) is made.
GAs are heuristic search algorithms based on the principles of natural selection. Their basic concept is designed to simulate processes in natural systems necessary for evolution. Their capabilities to find high performance solutions in large domains make them the ideal choice for optimization problems. However, GAs do not always guarantee an optimal solution. A new approach of the classic GA is presented in [41], in which the authors use the immune operator. Using this improved GA, they tune a set of PID parameters. The classic implementation of a PID controller is developed in [42], by analyzing the performance with mean square error (MSE) and integral absolute error (IAE) indexes using a classic GA and differential evolution (DE). An interesting approach is presented in [43] where the authors presents a new methodology for PID control tuning by coupling the Gain-Phase Margin method with GAs in which the micro population concept and adaptive mutation probability are applied.
Similar to finding a set of parameters specifically for controller design, GAs are also used in finding model parameters [44]. In [45] an improved version of the simple GA is presented, where the weights of the cost function are not taken as constant values, but varied throughout the procedure for parameter identification. This modified version of GA is applied to an induction motor as an example of nonlinear system. A consistent implementation using GAs is presented in [46], where authors have developed a model identification and controller design procedure for temperature control.
Some difficulties in the research for this type of problems using genetic algorithms are related to the implementation aspect. There are few frameworks and toolboxes that can help researchers continue existing work. A useful toolbox that implements genetic algorithms is presented in [47]. The toolbox is developed under MATLAB and is tested on a series of non-linear, multi-modal, non-convex test problems. In [48], numerical experiments based on heuristic approaches are conducted in order to reveal the characteristics of certain models, and then improved using artificial bee colonies and GAs. The proposed heuristic optimization algorithms were implemented in Microsoft Visual C++ using the .NET Framework. An interesting implementation designed for the modeling and simulation of Earth population evolution, on a global scale, throughout multiple historical eras is presented in [27]. The development of this software application has been made using JGAP [49], a genetic algorithms and genetic programming component provided as a Java framework.
This chapter brings forth the practical aspect of using genetic algorithms in aiding plant modeling and PID control design for real world industrial processes. Some plants are usually hard to model or tune on-site, especially after prolonged use of the equipment when degradation of performances is inevitable. Along with this presentation, a toolbox is offered (GAOT-ECM) in order to help researchers model processes, and (re)design viable PID controllers for their plants.
2 Principles of Evolutionary Computing
2.1 Evolutionary Computing Concepts
Evolutionary computing fits into the intelligent systems core idea of developing (more or less) intelligent computer systems by implementing simple rules for simple entities whose interaction will derive complex behaviors. In this case, complexity is achieved through artificial evolution, with application to search methods for problem solving. The possible solutions to a considered problem are coded into a population, which then is artificially evolved through the core mechanisms of selection, mutation and recombination.
Evolutionary algorithms (EAs) are heuristic search methods suitable for a wide range of optimization problems, specifically those that deal with high uncertainties and gross approximations, strict constraints or multiple criteria, vast solution spaces or high computational requirements.
Some of the more known categories of the evolutionary computing field are classified by the way the population is created. In genetic algorithms (GAs) the population represents potential solutions of the problem, being suitable for evolution through both mutation and crossover. For genetic programming (GP), the population represents potential programs, or procedures that can help solve a problem, whereas in evolutionary programming (EP) the population is formed from finite state automata. Other categories include evolution strategies (ES), gene expression programming (GEP), differential evolution (DE), and so on.
Evolution is controlled through a performance evaluation function which measures the adequacy/fitness of each individual to the environment to which it belongs. The steps for solving a problem using evolutionary computing are:
-
Setting the coding mode of individuals from a population
-
Choosing a method for generating a new population
-
Setting the evaluation method for each individual
-
Choosing the evolution operators and associated parameters
To run an EA, a series of steps are followed (Fig. 1): (1) the solution population is initialized, along with its fitness evaluation function; (2) as long as a previously declared termination condition is not met, for each generation, based on their computed fitness, some individuals are selected and recombined to generate offspring; and (3) the fitness of the current population is evaluated to be used in the next cycle.

Evolutionary algorithm steps
In order to find the solution amongst a given population, EAs perform parallel searches on multiple directions by evaluating the adequacy of each individual, as a fitness variable, computed using a criterion or index that models a desired objective. Moreover, multi-criteria searches can be performed in order to find a desired solution amongst a given population of possible solutions. Used to model the general objective of the procedure, the description of the fitness function is problem-specific, whereas its purpose is to eliminate inadequate solutions from the gene pool. This function returns the value of the performance criteria (for example, a minimization index) which in turn will be used for selecting the parents of the new generation. The performance of the entire algorithm is given by the fitness of the best population during its run, or by the fitness of the final solution returned.
In order to obtain viable models and/or control laws for the considered plants and industrial processes, there are various selection mechanisms for the evaluated population. For instance, the roulette wheel selection generates a roulette wheel in which each individual is proportionally represented according to its fitness. The larger the fitness value, the more space it will occupy on the wheel. Thus, the individuals with higher fitness are more likely to be selected. The ranking selection mechanism uses a fitness-based sorted population list, from which the extreme values have been eliminated. This method has a slower convergence than roulette wheel selection. Tournament selection involves running several competitions or tournaments among a specified number of individuals randomly chosen from the population that is evaluated. The winner of each tournament is considered to be the one with the best fitness value, thus being selected for the subsequent recombination.
2.2 Genetic Algorithms
Genetic algorithms (GAs) are a subclass of evolutionary computing and are stochastic search algorithms inspired by natural selection and genetics. The principle of the GA is: given a population formed of individuals (chromosomes) that represent possible solutions to a problem, they are set to compete with each other for survival. Through evaluation, each individual is assigned a fitness value (describing its adequacy as a possible problem solution). The more fit ones are given a higher chance to participate in the reproductive process (through crossover and mutation), thus propagating more suitable solutions into the next generation, where, the resulting children will compete with each other and, possibly, also with their parents. In time, the population will be increasingly closer to the desired problem solution.
For GAs, the preparation steps are specific to the field of the problem, and are set by the user before launching into execution. The execution steps are independent of the problem itself, being executed by the computer that runs the procedures chosen for solving the problem.
The preparation steps must be specified by the user and consist of:
-
1.
The set of independent, global, constant variables
-
2.
Operators and their type
-
3.
The fitness function
-
4.
Execution parameters
-
5.
Termination criteria
The execution steps are:
-
Generation of the initial population
-
Sequential execution of the next sub-steps until the termination criteria is met:
-
Creating a new population by applying two primary operations:
-
Copying of existing individuals into the new population
-
Creation of new individuals through the recombination (crossover) of certain parts from two individuals
-
-
Evaluating each individual from the new population and association of a fitness value depending on how well suited it is for solving the problem
-
Selecting the best individuals from the population.
-
-
Selection of one, best individual from the population that represents the solution to the problem.
The fitness function provides the means to determine if an individual of the population is a better candidate than another, assigning a numeric value (the fitness value) that reflects the extent to which an individual meets the requirements of the problem at hand. In other words, this function is used to generate a partial order of candidates in the population, which is used in the execution steps of genetic recombination. A fitness function for a real world problem usually has multiple goals. This means that there could be more than one element to consider in the choice of fitness value assignment for an individual compared to others in a population.
The operators used in the development of genetic algorithms are: selection, crossover, and mutation. Depending on the nature of the problem, there are other operators that can be used (inversion/reversal, reordering, special operators). The most commonly used GA operators are:
-
The operator of selection, based on fitness value
-
The genetic operator of crossover
-
The mutation operator, applied to a small number of individuals, either randomly or through a probability distribution function
Selection
An important role in designing a GA belongs to the selection operator. This operator decides which individuals are allowed to participate in the creation of the new population. The purpose of selection is to ensure greater chances of reproduction to selected individuals in a given population, thus seeking a maximization of their performance. Based on its purpose, this operator can be normalizing (this selection eliminates individuals with extreme fitness values), directional (a type of selection that aims to increase or decrease the average fitness of the entire population), or segregating (eliminates individuals with average fitness values). Many of the GAs implemented in practice use directional selection because it aims to achieve an optimal population. In this case, the difficulty consists in maintaining diversity inside a population, a task that is being left to the others operators. However, segregation is also used, on the premise that an individual with a very low fitness can become a potential solution at the next iteration, after crossover and mutation.
Selection can have zero tolerance, when only individuals identical with the current best are allowed to survive, it can have infinite tolerance, in which case all individuals survive regardless of their fitness, or a combination of both.
There are a few types of selection, from which some of the most popular are roulette, tournament, and ranking.
Roulette selection implies that individuals are chosen for recombination proportionally with their fitness value. Thus, the chromosomes with good fitness have better chances to spread their characteristics in future populations.
The tournament is one of the most popular and efficient schemes of selection, because, although very simple, it offers good performance in practice. It operates by randomly choosing individuals who will compete in a simulated game (by comparing fitness for example). The best of them will be selected for crossover.
Ranking selection is similar to roulette, only that it takes into account the presence of vastly different orders of magnitude for fitness. For example, if the fitness of one chromosome occupies 90 % of the roulette wheel, then the other chromosomes will have small chances of being selected. Therefore, ranking selection orders the individuals based on fitness and assigns a selection probability to each based on their place in the list.
Crossover
The crossover operator mimics natural inter-chromosomal recombination and is applied on individuals from intermediary generations. Two individuals are chosen randomly from the intermediary generation (which is also called crossover group/lot, resulted from selection), then certain parts of these individuals are interchanged. Most commonly, crossover operators of type (2, 2) are used, meaning two parents generate two descendants. Crossover exchanges information between the two parents, propagating their characteristics to the descendants. Crossover can be applied in one or two points, can be uniform, arithmetic or cut-and-splice, and so on.
One point crossover is at the core of recombination for GAs (Fig. 2). First, two chromosomes are chosen from the intermediary population. Second, they are split into the left and right chromosome parts, the cut being made at one random point. Third, each of the children receives the left chromosome from one of the parents and the right one from the other.

One point crossover
Two point crossover is similar, the only difference being that two random cutting points are chosen. In uniform crossover, the chromosome genes (for instance, the bits for the binary representation) are interchanged randomly between the two parents according to an uniform probability distribution. In arithmetic crossover, a boolean or arithmetical operation is applied to the parents (for example, a logic AND in binary representation). The cut and splice method leads to changes of the resulting children lengths. This type of crossover is used when the chromosome codification has variable length.
Mutation
Through mutation, individuals who could not be obtained by other mechanisms are introduced into the population. The mutation operator’s role is to maintain population diversity, and it acts on genes regardless of their position in the chromosome, by altering their value. Any gene of the chromosome can mutate. Mutation is a highly sensitive probabilistic operator that is applied according to a mutation rate chosen by the user. This value should be tuned, as a small mutation rate cannot maintain diversity, while a high mutation rate prevents or slows down the convergence to the optimal solution.
2.3 The Genetic Algorithm Optimization Toolbox Extension for Control and Modeling (GAOT-ECM)
In order to show how genetic algorithms can be applied to model identification and controller design, a toolbox was created, GAOT-ECM (an extension of the GAOT toolbox for control and modeling available for download at [50]). Both GAOT [47] and the extension presented GAOT-ECM are developed under MATLAB. GAOT is a good example of implementation of a genetic algorithm that can be used in many optimization problems.
From the types of selection presented in Sect. 2.2, this toolbox implements the roulette wheel, tournament and ranking methods. From the genetic operators (used to create new individuals inside populations) the toolbox implements some types of crossover and mutation. Both crossover and mutation operators are classified and implemented for float and binary representations of chromosomes, float and order-based representation. The types of crossover methods implemented in the GAOT package are: single and two points cut, arithmetic, uniform, cyclic (takes two parents P1 and P2 and performs cyclic crossover on permutation strings), linear order and order based. There are several types of mutation methods implemented in GAOT, from which the most popular are binary, uniform, boundary (randomly selects one gene and sets it equal to either its lower or upper bound), non-uniform (randomly selects one gene and sets it equal to an non-uniform random number), multi-non-uniform (applies the non-uniform method to all of the genes in the parent chromosome).
Beside the selection of the operators and their type, the implementation of a genetic algorithm also includes the initialization, termination, and evaluation functions. As mentioned in Fig. 1, an initial population must be provided before running the genetic algorithm. The GA iterates from generation to generation until a termination criterion is met. The most frequently used criterion for termination is a specified number of generations. Another condition refers to the convergence of population. The termination methods implemented in GAOT are: (a) reaching the maximum number of generations, and (b) reaching the maximum number of generation or finding a specified optimal fitness value. The evaluation functions can be implemented custom depending on the optimization problem. More details about the implementation of the GAOT toolbox are presented in [47].
Based on the GAOT toolbox, we have implemented an extension for this chapter in order to show how GAs can be used in model identification and controller design for plants like water tank, air blower, and motor. Another system on which GAOT-ECM is applied is the magnetorheological damper [51]. GAOT-ECM is implemented in a modular manner, therefore, depending on the user’s level of experience, to be easy to configure and test. For more details about the GAOT-ECM implementation see Sect. 3.3.
3 Application of Genetic Algorithms to Model Identification and Controller Design
3.1 Plant Model Identification
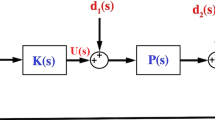
In what concerns system identification with the aid of GAs, a structure of the model is chosen based on experimental data collected from the plant. The basic principle behind this method (Fig. 3) requires computing an approximation error ε between the model output y m and the plant output y exp (with the same system/model input u), which will be then used by the GA alongside its performance criterion I in order to find the best fitting model for the experimental data y exp . The output of the GA is a vector of model parameters π that are coded into chromosomes as potential problem solutions.

Model identification using genetic algorithms
Three performance criteria based on approximation error have been chosen for this study (Table 1). A detailed description of these three indexes is given in Sect. 3.2.
Step response plant analysis for linear time invariant models
In plant identification, static analysis is first used to obtain the domain for which the plant behavior is modeled. For linear time systems with time invariant parameters, the plant has approximately the same behavior for the entire interval in which its static characteristic is linear. Using this tool, a nominal operating point can be identified for the plant. The static characteristic y(u) is obtained by gradually increasing the plant input u within its admissible domain, and then reading the measured output y in steady-state.
A series of nominal operating points can be chosen, usually toward the middle of the linearity interval, around which there is high confidence that the plant behavior will remain within the description of the model.
For the dynamic analysis of the plant, a step input around the nominal operating point can be chosen, with an initial value u 0 , and a final value u 1 . The response of the system to this step input will yield the y exp experimental plant output that will be used by the GA for identification.
In order to perform system identification with a linear time invariant transfer function, the experimental output data y exp needs to be normalized:
-
1.
convert data to percentages (if necessary)
-
2.
shift data vertically so response starts in zero
-
3.
scale data by input step size u 1 − u 0
This data will describe how the real system would respond to an ideal 0 to 1 step, if such an input were possible to be applied.
A real challenge is choosing the search domain. Caution is recommended in choosing the parameter bounds, through dynamic analysis: look at output steady state mean value for gain factor and settling time for time constants.
GA performance analysis
In order to quantify the performance of the GAOT-ECM tool, a performance index has been defined for the genetic algorithm:
for a simulation time of t and an approximation error ε(t).
Beside this index, a series of other parameters have been chosen to evaluate the genetic algorithm, such as run time and number of generations.
3.2 Controller Design
For the problem of controller design using GAs, the concept of the method, illustrated in Fig. 4, uses a chosen controller structure (in this case, a PID class controller) set in closed loop with either the model, in offline design, or the actual plant, in an online setting. Based on the control deviation ε (the error between setpoint r and controlled variable y), the genetic optimization technique will minimize a performance criterion I in order to find the best suited controller for the system at hand (whereas u is the command signal). The output of the GA is a vector of controller parameters γ that are coded into chromosomes as potential solutions of the controller design problem.

Controller design using genetic algorithms
Thus, through this method, the parameters of the chosen PID controllers can also be fine-tuned in a simulated environment and then tested on the real world plant. There are a few performance indexes that are commonly used in the design process, each with their own advantages and disadvantages.
The ISE (Integral of Square Error)
performance criterion is a general error minimizing index, making use of the quadratic error values obtained at a step response simulation. The main disadvantage of this index is that it does not take into account the overshoot. Instead, it just follows to quickly reduce the error values, thus reducing the overall settling time. In order to obtain low overshoot values, an addition to the fitness evaluation function of the GA is necessary.
The IAE (Integral of Absolute Error)
performance criterion is a general error minimizing index, making use of the absolute error values obtained at a step response simulation. The second performance index presents the same disadvantages as the first, but requires fewer processor operations, as instead of computing the square of error, only a removal of the sign is performed in order to obtain the absolute values.
The ITAE (Integral of Time multiplied by the Absolute value of Error)
performance criterion is one that minimizes the settling time, by using the absolute value of error obtained at a step response simulation and the actual value of time. The main disadvantage of this performance index is its high sensibility to any parameter variation, even if it produces lower overshoots that the first two indexes. Another issue of ITAE is the use of time values, which, for numeric systems, are subjected to processor clock communication delays.
The IEC (Integral of Error and Command)
performance criterion makes use of the command values in order to ensure minimization of the overshoot. This index successfully eliminates the overshoot. However, an increase in settling time is expected. Also, IEC requires more computing capacity than the first three indexes and is subject to the choice of the penalty factor ρ (strict positive).
Custom performance criteria
can also be chosen. For step response performance, the most common requirements deal with overshoot (usually it is desired to be none at all or very small), settling time (a maximum is commonly set, but realistic results require setting a minimum also), rise time, and of course zero steady state error.
Choosing the controller parameter bounds is a challenge in this case as well. For example, when dealing with first order closed loop requirements and a first order plant, the integral time constant of the controller would be of the same size as the plant time constant. There are no recipes to be followed in this case. Usually, an experienced engineer would be able to estimate the size of the controller parameters and then manually tune them (going by the usual rules), but for higher order plants this initial estimation becomes less and less reliable. In the fortunate case that the plant model is extremely well identified, the theoretical methods (pole placement, frequency response, etc.) might work. It is however the norm, in industry, that the plant models are inaccurate due to reasons ranging from measurement noise to strict input restrictions.
3.3 Implementation
Both methods for model identification and controller design are implemented in the GAOT-ECM package. The toolbox is organized as follows: (1) identification and (2) control. A content overview file is provided so the users can easily identify the files that are necessary to test or customize it to their own problem. Depending on the users’ experience, the configuration of this toolbox, i.e. the configuration of the proposed GA, was designed on three levels:
-
1.
Level 1 (for inexperienced users): represents the configurations that can be made inside the demonstration scripts (ECMidentification and ECMcontrol files); users can modify fitness function, plant model, performance criteria.
-
2.
Level 2: represents some more advanced configurations that can be made in the main functions for control and modeling (GAOT_ECM_ModelIdentification and GAOT_ECM_ControllerDesign files); the parameters that can be modified refer to population size, optimal fitness value based on which the GA can end the execution.
-
3.
Level 3: refers to the configuration that can be made regarding the GA, like number of generation, accepted tolerance, selection methods, crossover and mutation operators; these parameters can be changed inside the GA functions (GAOT_ECM_ModelIdentification_GA, GAOT_ECM_ControllerDesign_GA).
3.3.1 Model Identification
To demonstrate the usage of this functionality, a script is offered as an example (ECMidentification.m) that calls the main function that deals with model identification (GAOT_ECM_ModelIdentification.m). In order to run the main function some parameters must be set before calling it. These parameters represent the first level of configuration of the GA. If the user doesn’t have any experience with genetic algorithms, and doesn’t know how the GA could be tuned best, they should stop at this level.
Input parameters that must be set at the first level of configuration:
-
Simulink model (*.mdl file) of the plant whose parameters need to be identified; GAOT-ECM provides plant models for: water tank, motor, and air blower.
Note: GAOT-ECM provides all the necessary parameters and variables for the above models (detailed in the included case studies of this chapter). Regardless of the chosen model, these function are called and configured similarly.
-
A *.mat file that is used in the identification process; it must contain the following variables:
-
Initial and general bounds for each parameter of the plant model (named initBounds/generalBounds).
-
Array containing the input and output data obtained experimentally using the hardware platform (named in/out).
-
-
Fitness function (*.m file).
-
Desired performance criteria used in computing the fitness function (the provided performance criteria are described in Table 1 from Sect. 3.1).
Output parameters:
-
bestIndividual: the best solution found during the course of the run
-
endPop: the final population
-
bPop: a trace of the best population
-
PerformanceIndex: quantifies the performance of the obtained model by computing the integral of square approximation error over simulation time
-
NumberOfGenerations: a scalar value that represents the number of generations in which the GA has found the best solution
-
Fitness: a scalar value that represents the fitness value of the best individual found
Based on the above configuration, the main function is called as presented below (having the input parameters defined as shown above):
Inside the main function lies the second configuration level. More experienced users can modify this function in order to change some of the GA parameters (termination conditions, population size). In this function, the main GA function is called (GAOT_ECM_ModelIdentification_GA.m), and an analysis of the algorithm output is realized.
Input parameters for the GA main function:
-
criteria: a scalar value that represents the user’s choice regarding the performance criteria they want to use.
-
evalFN: the name of the *.m file that represents the fitness function.
-
termFNOptimalValue: a scalar value representing a constraint for the termination of the GA before a number of generations could be reached.
-
initBounds: an array containing the initial bounds for each parameter of the model; each line of the array represents the bounds for one parameter.
-
varBounds: an array containing the general bounds for each parameter of the model; each line of the array represents the bounds for one parameter.
-
populationSize: a scalar value representing the number of individuals per generation.
The output parameters are almost the same with those of the main function. Based on the output, another simulation of the model is realized, with the best individual (the simulation time is another parameter that can be set at this configuration level) and two figures are generated: the model output using the proposed genetic algorithm and the convergence of the GA.
Based on the specified input and output parameters, the main GA can be called:
From the body of the GA, three steps can be identified (this is the deeper level of configuration):
-
Initializing the first population (users can choose the number of generations, a tolerance value and other display options).
-
Setting essential parameters for the GA (the user can choose from the options that GAOT provides; for more details see Sect. 2 or [47]):
-
The function used to terminate the GA: default setting evaluates if the maximum number of generations or desired fitness value was reached (variable: termFN).
-
Selection function: default setting is normal selection (variable: selectFN).
-
Crossover operator: an arithmetic method is chosen as default (variable: xOverFNs).
-
Mutation operator: an uniform mutation method is applied as default (variable: mutFNs).
-
-
Iterating the GA (calling the function ga.m developed in GAOT [47]).
The fitness function has the same structure for all plants: given a certain individual, whose positions are occupied by the model parameters, the Simulink model is executed. Then, based on its output and the selected performance criterion, the fitness value of the evaluated model is computed.
Some specific settings for the implemented plant models, useful to the identification procedures in the case studies can be observed in Table 2.
3.3.2 Controller Design
To demonstrate the usage of this functionality, a script is offered as an example (ECMcontrol.m) that calls the main function that deals with PID (Proportional-Integral-Derivative) controller design (GAOT_ECM_ControllerDesign.m). In order to run the main function, some parameters must be set before calling it. The input parameters are those presented in the model identification procedure, to which the imposed performance conditions that the controller must fulfill are added:
-
Simulink model (*.mdl file) of the controller whose parameters need to be identified. GAOT-ECM provides Simulink files for: water tank, motor, and air blower.
Note: GAOT-ECM provides all the necessary parameters and variables for the above files. Regardless of the chosen model these function are called and configured similarly.
-
A *.mat file that must contain the following variables:
-
Fitness function (*.m file).
-
Desired performance criteria used in computing the fitness function (the provided performance criteria are described in Sect. 3.2).
-
Maximum settling time (in seconds).
-
Minimum settling time (in seconds).
-
Overshoot (percentage).
The configuration levels are split like in the case of model identification. Regardless of the configuration level, the parameters and variables that the user can modify are the same as in the first case. The difference between the main function for control and the one for model identification is given by the output analysis. Some additional parameters are computed (specific to controller behavior, like settling time, overshoot, and steady state error), based on which the system closed loop response is plotted. The GA parameters (population size, number of generations, selection, crossover, and mutation methods) are set like in the model identification case.
The fitness function has the same structure for all controllers: given a certain individual, whose genes are occupied by the controller parameters, the Simulink control structure is executed. Based on its output, selected performance criteria and imposed performance for the controller, the fitness value is computed.
Some specific settings for the implemented controllers, relevant to the design procedure in the case studies included in this chapter are shown in Tables 3 and 4.
4 Case Study 1: Water Tank Experimental Model and Level Control
This case study presents the experimental modeling of a water tank as a second order model, by collecting experimental data which is fitted over a transfer function using genetic algorithms. The plant has one pole significantly larger than the other, the dominant behavior of the tank obscuring the delay introduced by water traveling through pipes. This is the basic sort of plant in industrial applications, whose model is then used to design a PID class controller, using the previously described evolutionary methodology.
Platform setup
The water tank used in this case study is part of a FESTO [52] laboratory installation, dedicated to the study of automation processes. The platform is comprised of two water tanks, one (tank A) mounted higher than the other (tank B), connected through pipes. For the level control functionality (in tank A), the platform makes use of a water pump as actuator, an ultrasonic transducer and the possibility of varying the evacuation water flow as disturbance. The water pump is mounted at the tank B level, using it as a water source. Between the water pump and the entry point into tank A, there are 0.97 m of pipes through which the water must travel. The platform is connected to a specialized application through an RS232 communication port and allows two main behaviors:
-
manual control: in which the operator sets a specific command and can visualize the measured plant output
-
automatic control: in which the operator sets a specific setpoint and can visualize the computed command and the measured plant output
The available application emulates a standard industry interface, allowing for visualization and input of various parameters. However, the application only allows for setting the parameters of a PID class controller, as is the case in many industrial settings, Kr (the PID proportional gain), Ti (the PID integral time constant) and Td (the PID derivative time constant), in the form:
where u(t) is the command and ε(t) is the control deviation.
Admissible command domains for actuators are dependant on physical characteristics (Table 5). In this case, the water pump has a lower saturation limit at 30 % command, while, due to the water fueling access point, maximum safe command is at 75 %, in order to avoid drawing air into the pump.
Static analysis
For this water tank, collected data yields the characteristic presented in Fig. 5. The linear domain of 40–70 % has been obtained by searching for a first degree polynomial fit. In this case, a nominal operating point has been chosen:

Water tank static characteristic
Dynamic analysis
For the dynamic analysis of the plant, a step input around the nominal operating point can be chosen, with an initial value u 0, and a final value u 1:
The measured output data has been collected over time. The normalized step response of the water tank is presented in Fig. 6. A very important observation is the high disturbance present in the measured output. Tank A of the system has a peculiarity in the form of a rubber stopper protruding from its wall inward, causing ripple effects on the surface of the water as it rises, which are being registered by the transducer. This effect is too severe to be eliminated from the data through a filtering mechanism. For its compensation, the tank would have to be replaced, which is not feasible. Therefore, when faced with this situation, caution is required when trying to estimate the plant model.

Water tank experimental step response
Upon initial inspection, this plant presents a first order behavior. However, there is also a small delay caused by water traveling from the pump to tank A through the existing pipe configuration, which can be either modeled as a time delay, or as a first order delay. This characteristic is obscured by the dominant pole of the plant which yields a settling time of approximately 165 s (with a corresponding time constant of approximately 55 s). If a first order model is estimated and then a PI controller is designed, in all cases an overshoot of approximately 10 % can be observed each time. In these cases, the closed loop step response has the shape of the canonical step response of a second order function, which would not happen if the pipes were to introduce a time delay. Thus, a second order model with one dominant time constant T 1 significantly larger than the other one T 2 is chosen (with K as gain factor):
This sort of decision is deeply rooted in one’s experience as an automation engineer. If the model chosen initially is not suitable for the considered plant, then it can be easily replaced with adding/removing poles or zeroes, and/or time delays.
Model identification with GAOT-ECM
Using the GAOT-ECM toolbox, the best model obtained for this plant is:
The model response fitted over experimental data is shown in Fig. 7. The criterion used for this solution is ITAE, while the performance index of the run is J = 1.4327 × 10−4, showing this is a very good approximation of the real plant.

Model and experimental responses
Each GA run is affected by the input parameters of the algorithm, by the criterion chosen, and even by the computing system it runs on. In what follows, a series of comparative results are presented. All simulations have been run on a system equipped with an Intel Core i5 CPU @ 2.50 GHz and 4 GB of installed memory. Table 6 shows results for the three criteria ISE, IAE and ITAE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic. It is expected that the criteria values would be rather high, due to the disturbances observed in measured data. The most significant difference in results is, however, observed when using the ISE criterion, which yields a model that takes into account this output variation. For the other two criteria, the approximated models respond how the water tank should, if there were no constructive peculiarities, and thus no measured disturbance.
Table 7 presents the comparative performance of the genetic algorithm for various input parameters and settings, while using criterion ISE. As expected, a higher population size will yield good results faster, but requires more computing power. A too high mutation rate will degrade performances, as will a too relaxed stop condition. Restricting the search domain, naturally offers better results, but expanding it will yield various results, some better, some worse.
PID controller design with GAOT-ECM
Due to significant disturbances observed at the plant output, it is unwise to use a derivative component in the controller, as it has an unwanted amplification effect. Therefore, a PI controller is designed with parameters: Kr and Ki = Kr/Ti. For required performance of settling time between 80 and 100 s, no steady state error and no overshoot, the best controller found using GAOT-ECM is:
The platform application’s interface only allows for one decimal place, therefore forcing an approximation of the controller parameters:
-
Kr ≈ 10
-
Ti ≈ 70.3 s
Figures 8 and 9 show the performance of this controller, in simulation and platform implementation. The performances of both cases are included in Table 8.

Simulated closed loop response

Experimental closed loop response
Table 9 shows results for the other four criteria ISE, IAE, ITAE, and ICE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic.
As expected, using these criteria offers no real management of settling time and overshoot. While steady state errors are indeed zero, the system will respond in closed loop with overshoot, as the design process minimizes settling time without regard to a minimum of time the plant can realistically offer. These criteria, however, are extremely useful when searching for a closed loop response in which the setpoint is not a step, but a (randomly) variable signal.
5 Case Study 2: C.C. Motor Experimental Model and Speed Control
This case study presents the experimental modeling (and subsequent control system design) of a c.c. motor as a second order plant with both time constants of approximately the same order, which yields a particular time response of the system without overshoot. This sort of plant is difficult to model formally, as there is no viable correspondence between settling time of the response and the damping factor of the second order model when the latter is larger than one.
Platform setup
Experimental data is obtained using an in-house developed laboratory c.c. motor, dedicated to the study of motor speed control. The platform makes use of a digital encoder as transducer and a generator (AC to DC) to emulate the actuator (Table 10). The group transforms electrical energy received via the electrical grid into mechanical movement of the motor shaft. An RS232 communication port allows connection to a monitoring workstation.
The platform is connected to a specialized application implemented on an Intel MCS-51 microcontroller, and allows two main behaviors:
-
manual control: in which the operator sets a specific command and can visualize the measured plant output
-
automatic control: in which the operator sets a specific setpoint and can visualize the computed command and the measured plant output
The available application only allows for setting the parameters of a PID class controller, as is the case in many industrial settings, Kr (the PID proportional gain), Ki (the PID integral gain) and Kd (the PID derivative gain), in the form:
where u(t) is the command and ε(t) is the control deviation.
Static analysis
For this plant, collected data yields the characteristic presented in Fig. 10. The linear domain of 30–90 % has been obtained by searching for a first degree polynomial fit. In this case, a nominal operating point has been chosen:

Motor static characteristic
Dynamic analysis
For the dynamic analysis of the plant, a step input around the nominal operating point can be chosen, with an initial value u 0 , and a final value u 1 :
The measured output data has been collected over time. The normalized step response of the motor is presented in Fig. 11.

Motor experimental step response
Here, a very important initial observation is the right and downward inflexion of the response around the origin. If this were a first order plant, its response would curve left and upward. This sort of response belongs to second order plants for which the damping factor is higher than 1, whereas its poles are close. For these plants, estimation of time constants based on observed settling time has no theoretical foundation. Running GAOT-ECM to find these parameters is time efficient and more precise than trying to find the model through trial and error.
The chosen model is second order with two time constants T 1 and T 2 of the same order of magnitude, and gain factor K:
This sort of decision is deeply rooted in one’s experience as an automation engineer. If the model chosen initially is not suitable for the considered plant, then it can be easily replaced with adding/removing poles or zeroes, and/or time delays.
Model identification with GAOT-ECM
Using the GAOT-ECM toolbox, the best model obtained for this plant is:
The model response fitted over experimental data is shown in Fig. 12. The criterion used for this solution is ITAE, while the performance index of the run is J = 1.6182 × 10−4, showing this is a very good approximation of the real plant.

Model and experimental responses
Each GA run is affected by the input parameters of the algorithm, by the criterion chosen, and even by the computing system it runs on. In what follows, a series of comparative results are presented. All simulations have been run on the same system as in the previous case. Table 11 shows results for the three criteria ISE, IAE and ITAE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic.
Table 12 illustrates the comparative performance of the GA for several input parameters and settings, and criterion ISE. Results confirm the findings of Table 7, in terms of population size, mutation rate, search domain, and so on.
PID controller design with GAOT-ECM
A PID controller is designed with parameters: Kr, 1/Ki, and Kd. For required performance of settling time between 2 and 10 s, no steady state error and no overshoot, the best controller found using GAOT-ECM is:
The platform application’s interface only allows for one decimal place, therefore forcing an approximation of the controller parameters:
-
Kr ≈ 1
-
1/Ki ≈ 1.5 s
-
Kd ≈ 0.4 s
Figures 13 and 14 show the performance of this controller, in simulation and platform implementation. The performances of both cases are shown in Table 13.

Simulated closed loop response

Experimental closed loop response
Table 14 shows results for the other four criteria ISE, IAE, ITAE, and ICE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic.
Here the run time is significantly higher than in the previous case study due to the presence of the derivative in the controller, which increases the evaluation time for each individual, as it requires more operations to compute. The results offered by the integral indexes are the same as in the previous case study.
6 Case Study 3: Air Blower Experimental Model and Control
This case study takes into account the presence of time delay for an air flow plant of first order. The plant model is obtained using experimental data from a laboratory air blower actuated by a fan. As in the other case studies, a PID class controller is obtained, this time taking account of the inherent time delay of the system, then validated in closed loop.
Platform setup
The ELWE LTR701 air blower [53] is a laboratory installation dedicated to the study of automation processes. The platform is comprised of a long tubular nozzle, in which air is drawn using a motor actuated fan (Table 15). The air pressure sensor is installed at the other end of the nozzle, thus introducing a time delay in the system, whereas the rest of the plant behavior is that of a first order system. The platform is connected to a specialized application through an RS232 communication port and allows two main behaviors:
-
manual control: in which the operator sets a specific command and can visualize the measured plant output
-
automatic control: in which the operator sets a specific setpoint and can visualize the computed command and the measured plant output
The available application emulates a standard industry interface, allowing for visualization and input of various parameters. However, the application only implements a PI controller for the air pressure functionality, with Kr (the PI proportional gain), and Ki (the PI integral gain), in the form:
where u(t) is the command and ε(t) is the control deviation.
Static analysis
For this plant, collected data yields the characteristic presented in Fig. 15. The linear domain has been estimated to 25-100 [%]. In this case, a nominal operating point has been chosen:

Air blower static characteristic
Dynamic analysis
For the dynamic analysis of the plant, a step input around the nominal operating point can be chosen, with an initial value u 0, and a final value u 1:
The measured output data has been collected over time. The normalized step response of the air blower is presented in Fig. 16. A first order model with one time constant T 1 and a time delay T 2 is chosen, with K as gain factor:

Air blower experimental step response
This sort of decision is deeply rooted in one’s experience as an automation engineer. If the model chosen initially is not suitable for the considered plant, then it can be easily replaced with adding/removing poles or zeroes, and/or time delays.
Model identification with GAOT-ECM
Using the GAOT-ECM toolbox, the best model obtained for this plant is:
The model response fitted over experimental data is shown in Fig. 17. The criterion used for this solution is IAE, while the performance index of the algorithm run is J = 3.7685 × 10−6, showing this is a very good approximation of the real plant.

Model and experimental responses
Each GA run is affected by the input parameters of the algorithm, by the criterion chosen, and even by the computing system it runs on. In what follows, a series of comparative results are presented. All simulations have been run on the same system as before. Table 16 shows results for the three criteria ISE, IAE and ITAE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic.
Table 17 presents the comparative performance of the GA for various input parameters and settings (with criterion ISE). As expected, the results of Tables 7 and 12 are confirmed, amongst which: a too low mutation rate will degrade performances, whereas a higher mutation rate is beneficial. This happens due to the too fast convergence of the algorithm toward the stop condition, which can be also observed. Adding a stricter condition (for example request that a viable individual must have a value of ISE at most 0.002) will avoid the premature stop of the GA run. Restricting the search domain doesn’t necessarily improve the model due to the fast convergence, but expanding it will yield both better and worse results.
PID controller design with GAOT-ECM
Due to significant disturbances observed at plant output, it is unwise to use a derivative component in the controller, as it has an unwanted amplification effect. Therefore, a PI controller is designed with parameters: Kr and Ki. For required performance of settling time between 3 and 10 s, no steady state error and no overshoot, the best controller found using GAOT-ECM is:
The platform application’s interface allows several decimal places, therefore no further approximation was made for the controller parameters.
Figures 18 and 19 show the performance of this controller, in simulation and platform implementation. The performances of both cases are shown in Table 18.

Simulated closed loop response

Experimental closed loop response
Table 19 shows results for the other four criteria ISE, IAE, ITAE, and ICE. The GA is set to run for a population size of 100, and for a maximum of 100 generations. The selection mechanism is ranking based on normalized geometric distribution, mutation is 8 % uniform, while the crossover operator is arithmetic.
Results confirm the conclusions drawn from the previous case studies regarding the use of integral criteria. However, even if the closed loop response is not entirely satisfactory, its shape can still be changed by manipulating the search domains for the controller parameters (for instance, increasing the integral factor will lower the overshoot, but increase the settling time). Here, it is also very important to note that minimizing deviation error will also lead invariably to closed loop stable control systems, the time delay of the plant notwithstanding.
7 Case Study 4: Magnetorheological Damper Control
A magnetorheological (MR) damper is a hydraulic-class actuator used in seismic protection systems design [54]. This device is used to generate the necessary control forces using as an input a command current and the velocity of the story on which it is mounted. The damper is a hydraulic cylinder whose damping coefficient is controlled by the variation of a magnetic field which changes the fluid from viscous to semi-solid in milliseconds [55].
For the successful vibration control of a given structure, it is necessary that the actuators perform inside a set of strict performance criteria, such as response time and robustness versus uncertainties [56]. The output forces generated by seismic dampers are required to be maintained between specific limits, so they do not cause instability to the structure, breaks support beams and so on. Therefore, a control loop for the actuator is required, that will receive the desired control forces computed by higher algorithms (such as robust laws, intelligent controllers, adaptive, modal, etc.) as setpoints and ensure that they are precisely reproduced by the actual damper output force.
The behavior of the MR damper used in this case study is given by [57]:
where F is the force generated by the damper, u is the command signal, u V is the command voltage, \( \dot{x} \) is the velocity of the structure. This case study makes use of the following values [58]: c 0a = 0.0064 Ns/cm, c 0b = 0.0052 Ns/cm V, a a = 8.66 N/cm, a b = 8.86 N/cm V, δ = 300 cm−2, β = 300 cm−2, A = 120, n = 2 and η = 80 s−1.
For the purpose of this case study, a base isolation system is considered for a three story building. The damper is mounted in the base of the structure, which is controlled via an LQR law on the outer loop of a cascaded control system. The design on the LQR law, the building model and its state space representation are described in [55]. In order to maintain the computational requirements of the control system to a minimum, a PID controller is chosen to be designed using GAs for the inner loop containing the damper. This configuration is presented in Fig. 20, where: x is the displacement of the structure; \( \dot{x} \) and \( \ddot{{x}} \) are the velocity and acceleration of the structure, respectively; F is the control force as damper output; u LQR is the desired control force, u is the command signal, ε is the control deviation of the inner loop; a and v are the ground acceleration and velocity, respectively.

Cascaded control structure for building equipped with MR damper
The PID damper controller is chosen to be of the form:
where u(t) is the command, ε(t) is the control deviation, Kr is the PID proportional gain, Ki the integral gain, and Kd the derivative gain.
For this system, the only relevant performance criteria are ISE, IAE, ITAE, and IEC, as the setpoints will never be step, but quick variations of a signal computed based on similarly quasi-random signals, like seismic ground motion. The purpose of the inner control loop is to follow the setpoint precisely. Thus, one of the best controller found using GAOT-ECM wit the ISE criterion is:
Figure 21 shows the PID controller performance for a 3 s timeframe: the force output is superimposed onto the given setpoint, as requested. The fitness of this solution is given by the criterion value: ISE = 0.0193.

PID controller performance for a 3 s timeframe
In order to validate this control system, a look at the entire structural response is required. In what follows, a set of evaluation criteria [59] has been chosen:
where x i (t) and \( \ddot{{x}}_{i}(t) \) are the relative displacement and acceleration of the i-th story, while d i (t) is the interstory drift; the notation open designates the overall maximum absolute displacements, accelerations and drifts of the uncontrolled structure.
Figure 22 presents the structural response (overall maximum displacements, interstory drifts, and accelerations) of the cascaded control system compared to both the standard non-cascaded control loop, and the uncontrolled structure when subjected to the Northridge (1994) earthquake. Since the LQR control law is computed using the linearized model of the structure, it doesn’t take into account the nonlinear behaviour of the damper. Results show that without the inner PID control loop, the structural response is only improved in what concerns accelerations, even worsens when it comes to interstory drifts. The beneficial effects of the inner control loop are obvious in an overall considerable reduction of the structural response: 54.31 % reduction in displacements, 63.09 % reduction of interstory drifts, and 15.87 % reduction of structure accelerations.

Comparative displacements, interstory drifts, and accelerations
Table 20 presents the results of GA runs using various configuration parameters and performance criteria. The expected closed loop performances for the structural system with MR damper base isolation are preserved. Naturally, due to computational requirements for running the nonlinear damper model, the run times are longer than in the previous case studies. For the ITAE criterion, expected fitness values are considerably larger than for the other three, due to its dependence to length of simulation. The fast convergence of the runs using criteria ISE and IAE is not premature, but obtained through large enough search domains and a carefully chosen stop condition. For requirements related to obtaining smaller admissible values for the PID controller parameters, the IEC criterion is the best choice, but it’s highly sensitive to the value of the ρ factor.
An implementation of this case study is available for download at [51]. The file uses the GAOT-ECM extension described in Sect. 3.3. Along with the genetic algorithm functions, the file includes the simulation models for the MR damper and the structure (open and with base isolation). Seismic data for the Northridge (1994) earthquake is provided, as well as a previously computed command matrix for the LQR law for validation purposes.
8 Conclusions
This chapter offers an applicative view of evolutionary computing, specifically genetic algorithms, in regards to the modeling and control of industrial plants. From measurement noise to time delays, from inflexible control interfaces to restrictions on system-wide reconfigurations, and even from equipment wear to unforeseeable uncertainties, practicing automation engineers are sometimes faced with difficult choices when it comes to tuning PID class controllers on-site, especially during system functioning. It is a running pun in the control community that “automation is the art of approximation”: there is a seed of truth in this, as most practitioners rely heavily on personal experience when performing the final tuning of controllers during installation. This chapter comes to the aid of those practitioners who have not yet built this base of knowledge, or those who want to enrich their expertise.
Running a genetic algorithm equates with a multi-directional search in easily expandable or retractable parameter domains, for both models and controllers. Suitable controllers, or at least suitable parameter domains for on-site tuning, are hard to find. Genetic algorithms (GAs) offer this search quickly and safely, without damaging the plant. With possible implementations that can run in under a minute on a mobile device, GAs have become a useful tool in control engineering practice.
For this work, a MATLAB extension to the Genetic Algorithm Optimization Toolbox has been implemented, GAOT-ECM (Extension for Control and Modeling) and made available through MATLAB Central’s File Exchange service. The four case studies included can be run and used in simulations, extended to other systems, or even used for educational purposes.
The four case studies include the modeling and control of a water tank, c.c. motor, an air blower, and a magnetorheological damper each with its own peculiarities that can be observed in real world industrial systems. After the successful plant identification and subsequent PID design (with validation on the physical system), a series of comparative results have been discussed. The usefulness of performance criteria is highly dependant on the problem at hand, while an increase in population size yields better solutions, but increases computing time. In what concerns modeling, a highly disturbed output will affect any identification algorithm, but the GA can offer both approximations that seem formally viable, and approximations that emulate the seemingly intuitive response tracing of an engineer’s experienced hand. Moreover, GAs can find plant models that are not easily identified formally, for instance when a response is second order LTI, but overdamped. The same happens when a dominant time constant obscures a much smaller one, which would significantly affect the closed loop response of any formally designed controller.
Our parallel research directions have included successful GA model identification for human heart rate during aerobic training, GA search for PID controllers for semi-active seismic dampers (from the electrohydraulic and magnetorheological classes), and even GA tuning of multiple input multiple output PID controllers for nonlinear plants (a 3D crane). For the immediate future, we are looking at applying GA optimization to multi-agent control systems, to path reconfiguration in real world environments for emergency vehicles in high urban traffic, and last, but not least, to optimal damper distribution in tall buildings for mitigating seismic response.
In closing, we are issuing a challenge to our readers to add their own plants, linear or nonlinear, stable or not, simulated or experimental, to the long list of applications that GAs stand to offer.
References
Malhotra, R., Singh, N., Singh, Y.: Genetic algorithms: Concepts, design for optimization of process controllers. Comput. Inf. Sci. 4(2), 39 (2011)
Mitchell, M.: An Introduction to Genetic Algorithms. MIT Press, Cambridge (1998)
Fleming, P.J., Purshouse, R.C.: Evolutionary algorithms in control systems engineering: a survey. Control Eng. Pr. 10(11), 1223–1241 (2002)
Fonseca, C.M., Fleming, P.J.: Multiobjective genetic algorithms. In IEE Colloquium on Genetic Algorithms for Control Systems Engineering, pp. 1–6 (1993, May)
Lewin, D.R.: A genetic algorithm for MIMO feedback control system design. Adv. Control Chem. Process. 1994, 101 (2014)
Lewin, D.R.: Multivariable feedforward control design using disturbance cost maps and a genetic algorithm. Comput. Chem. Eng. 20(12), 1477–1489 (1996)
Acosta-González, E., Fernández-Rodríguez, F.: Model selection via genetic algorithms illustrated with cross-country growth data. Empir. Econ. 33(2), 313–337 (2007)
Huang, C.F.: A hybrid stock selection model using genetic algorithms and support vector regression. Appl. Soft Comput. 12(2), 807–818 (2012)
Gray, G.J., Murray-Smith, D.J., Li, Y., et al.: Nonlinear model structure identification using genetic programming. Control Eng. Pr. 6(11), 1341–1352 (1998)
Bush BO, Hosom JP, Kain A et al.: Using a Genetic Algorithm to Estimate Parameters of a Coarticulation Model. In: INTERSPEECH, pp. 2677–2680 (2011)
Castiglione, A., Cattaneo, G., Cembalo, M., et al.: Experimentations with source camera identification and Online Social Networks. J. Ambient Intell. Humaniz. Comput. 4(2), 265–274 (2013)
Vatolkin, I., Preuß, M., Rudolph, G., et al.: Multi-objective evolutionary feature selection for instrument recognition in polyphonic audio mixtures. Soft. Comput. 16(12), 2027–2047 (2012)
De Santis, A., Castiglione, A., Fiore, U., et al.: An intelligent security architecture for distributed firewalling environments. J. Ambient Intell. Humaniz. Comput. 4(2), 223–234 (2013)
Alcalá-Fdez, J., Alcalá, R., Gacto, M.J., et al.: Learning the membership function contexts for mining fuzzy association rules by using genetic algorithms. Fuzzy Sets Syst. 160(7), 905–921 (2009)
Shook, D.A., Roschke, P.N., Lin, P.Y., et al.: GA-optimized fuzzy logic control of a large-scale building for seismic loads. Eng. Struct. 30(2), 436–449 (2008)
Linkens, D.A., Nyongesa, H.O.: Genetic algorithms for fuzzy control. 1. Offline system development and application. IEE Proc.-Control Theor. Appl. 142(3), 161–176 (1995)
Karr, C.L., Gentry, E.J.: Fuzzy control of pH using genetic algorithms. IEEE Trans. Fuzzy Syst 1(1), 46 (1993)
Herrera, F., Lozano, M., Verdegay, J.L.: A learning process for fuzzy control rules using genetic algorithms. Fuzzy Sets Syst. 100(1), 143–158 (1998)
Tao, Q., Liu, X., Xue, M.: A dynamic genetic algorithm based on continuous neural networks for a kind of non-convex optimization problems. Appl. Math. Comput. 150(3), 11–820 (2004)
Javadi, A.A., Farmani, R., Tan, T.P.: A hybrid intelligent genetic algorithm. Adv. Eng. Inform. 19(4), 255–262 (2005)
Leung, F.H., Lam, H.K., Ling, S.H., et al.: Tuning of the structure and parameters of a neural network using an improved genetic algorithm. IEEE Trans. Neural Netw. 14(1), 79–88 (2003)
Schaffer, J.D., Whitley, D., Eshelman, L.J.: Combinations of genetic algorithms and neural networks: a survey of the state of the art. In: International Workshop on Combinations of Genetic Algorithms and Neural Networks, 1992., COGANN-92, pp. 1–37 (1992, June)
Zheng, Y.J., Ling, H.F.: Emergency transportation planning in disaster relief supply chain management: a cooperative fuzzy optimization approach. Soft. Comput. 17(7), 1301–1314 (2013)
Gibbs, M.S., Dandy, G.C., Maier, H.R.: A genetic algorithm calibration method based on convergence due to genetic drift. Inf. Sci. 178(14), 2857–2869 (2008)
Chang, P.C., Huang, W.H., Ting, C.J.: Dynamic diversity control in genetic algorithm for mining unsearched solution space in TSP problems. Expert Syst. Appl. 37(3), 1863–1878 (2010)
Togan, V., Daloglu, A.T.: An improved genetic algorithm with initial population strategy and self-adaptive member grouping. Comput. Struct. 86(11), 1204–1218 (2008)
Patrascu, M., Stancu, A.F., Pop, F.: HELGA: a heterogeneous encoding lifelike genetic algorithm for population evolution modeling and simulation. Soft. Comput. 18(12), 2565–2576 (2014)
Lässig, J., Sudholt, D.: Design and analysis of migration in parallel evolutionary algorithms. Soft. Comput. 17(7), 1121–1144 (2013)
Mitsukura, Y., Yamamoto, T., Kaneda, M.: A genetic tuning algorithm of PID parameters. In: IEEE International Conference on Systems, Man, and Cybernetics, 1997. Computational Cybernetics and Simulation, 1997, vol. 1, pp. 923–928 (1997, October)
Ding, Y.M., Wang, X.Y.: Real-coded adaptive genetic algorithm applied to PID parameter optimization on a 6R manipulators. In: Fourth International Conference on Natural Computation, 2008. ICNC’08, vol. 1, pp. 635–639 (2008, October)
Chen, Y., Wu, Q.: Design and implementation of PID controller based on FPGA and genetic algorithm. In: 2011 International Conference on Electronics and Optoelectronics (ICEOE), vol. 4, pp.4–308 (2011, July)
Juang, J.G., Huang, M.T., Liu, W.K.: PID control using presearched genetic algorithms for a MIMO system. IEEE Trans. Syst. Man Cybern. Part C: Appl. Rev. 38(5), 716–727 (2008)
Valarmathi, R., Theerthagiri, P.R., Rakeshkumar, S.: Design and analysis of genetic algorithm based controllers for non linear liquid tank system. In: 2012 International Conference on Advances in Engineering, Science and Management (ICAESM), pp. 616–620 (2012, March)
Bi, J., Liu, D., Zhan, K.: PID parameters optimization for liquid level control system based on genetic algorithm. JDCTA: Int. J. Digital Content Technol. Appl. 6(1), 361–368 (2012)
Xiao-Gen, S., Li-Qing, X., Cheng-Chun, H.: Optimization of PID parameters based on genetic algorithm and interval algorithm. In: Control and Decision Conference, 2009. CCDC’09. Chinese, pp. 741–745 (2009, June)
Yuan, G., Xue, Y.G., Liu, J.: Adaptive immune genetic algorithm and its application in PID parameter optimization for main steam temperature control system. In: 2010 Third International Workshop on Advanced Computational Intelligence (IWACI), pp. 304–309 (2010)
Zhang, J., Zhuang, J., Du, H.: Self-organizing genetic algorithm based tuning of PID controllers. Inf. Sci. 179(7), 1007–1018 (2009)
Lin, G., Liu, G.: Tuning PID controller using adaptive genetic algorithms. In: 2010 5th International Conference on Computer Science and Education (ICCSE), pp. 519–523 (2010)
Rani, M.R., Selamat, H., Zamzuri, H. et al.: PID controller optimization for a rotational inverted pendulum using genetic algorithm. In: 2011 4th International Conference on Modeling, Simulation and Applied Optimization (ICMSAO), pp. 1–6 (2011)
Korkmaz, M., Aydogdu, Ö., Dogan, H.: Design and performance comparison of variable parameter nonlinear PID controller and genetic algorithm based PID controller. In: 2012 International Symposium on Innovations in Intelligent Systems and Applications (INISTA), pp. 1–5 (2012)
Ohri, J., Kumar, N., Chinda, M.: An improved genetic algorithm for PID parameter tuning. In: Proceedings of the 2014 International Conference on Circuits, Systems, Signal Processing (2014)
Saad, M.S., Jamaluddin, H., Darus, I.Z.: PID controller tuning using evolutionary algorithms. Wseas Trans. Syst. Control 7(4), 139–149 (2012)
Jaen-Cuellar, A.Y., Romero-Troncoso, R.D.J., Morales-Velazquez, L., et al.: PID-controller tuning optimization with genetic algorithms in servo systems. Int. J. Adv. Rob. Syst. 10, 324 (2013)
Sadasivan, J., Mammen, O.: Genetic algorithm based parameter identification of three phase induction motors. Reproduction 31(10) (2011)
Megherbi, A.C., Megherbi, H., Benmahamed, K., et al.: Parameter Identification of Induction Motors using Variable-weighted Cost Function of Genetic Algorithms. J. Electr. Eng. Technol. 5(4), 597–605 (2010)
Nithya Rani, N., Giriraj Kumar, S.M., Anantharaman, N.: Modeling and control of temperature process using genetic algorithm. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2(11) (2013)
Houck, C.R., Joines, J., Kay, M.G.: A genetic algorithm for function optimization: a Matlab implementation. NCSU-IE TR, 95(09) (1995)
Guldogan, E.U., Bulut, O., Tasgetiren, M.F.: A dynamic berth allocation problem with priority considerations under stochastic nature. In: Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence, pp. 74–82. Springer, Berlin Heidelberg (2012)
Meffert, K., Rotstan, N., Knowles, C. et al.: Jgap-java genetic algorithms and genetic programming package. http://jgap.sf.net (2012)
Patrascu, M., Ion, A.: GAOT-ECM: Extension for Control and Modeling. http://www.mathworks.com/matlabcentral/fileexchange/51072-gaot-ecm–extension-for-control-and-modeling (2015). Accessed 7 Jul 2015
Patrascu, M., Ion, A. GAOT-ECM Seismic Vibration Case Study. http://www.mathworks.com/matlabcentral/fileexchange/51131-gaot-ecm-seismic-vibration-case-study (2015). Accessed 7 Jul 2015
Festo: Festo Water Tank Workstation. http://www.festo-didactic.com (2015). Accessed 7 Jul 2015
LD DIDACTIC Group: ELWE Technik Air Mass and Temperature System. http://www.elwe-technology.com (2015). Accessed 7 Jul 2015
Sims, N.D., Stanway, R., Johnson, A.R.: Vibration control using smart fluids: a state-of-the-art review. Shock Vib. Dig. 31(3), 195–203 (1999)
Patrascu, M., Dumitrache, I., Patrut, P.: A comparative study for advanced seismic vibration control algorithms. UPB Sci. Bull. Series C, 74(4):3–16 (2012)
Patrascu, M., Dumitrache, I. Hybrid geno-fuzzy controller for seismic vibration control. In: 2012 UKACC International Conference on Control (CONTROL), pp. 52–57 (2012, September)
Spencer, Jr B.E., Carlson, J., Sain, M.K. et al. (1997, June). On the current status of magnetorheological dampers: seismic protection of full-scale structures. In American Control Conference, 1997. Proceedings of the 1997, vol. 1, pp. 58–462
Yan, G., Zhou, L.L.: Integrated fuzzy logic and genetic algorithms for multi-objective control of structures using MR dampers. J. Sound Vib. 296(1), 368–382 (2006)
Patrascu, M.: Genetically enhanced modal controller design for seismic vibration in nonlinear multi-damper configuration. Proc. Inst. Mech. Eng. Part I: J. Syst. Control Eng. 229(2), 158–168 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Patrascu, M., Ion, A. (2016). Evolutionary Modeling of Industrial Plants and Design of PID Controllers. In: Espinosa, H. (eds) Nature-Inspired Computing for Control Systems. Studies in Systems, Decision and Control, vol 40. Springer, Cham. https://doi.org/10.1007/978-3-319-26230-7_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-26230-7_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-26228-4
Online ISBN: 978-3-319-26230-7
eBook Packages: EngineeringEngineering (R0)