
Abstract
pymorphy2 is a morphological analyzer and generator for Russian and Ukrainian languages. It uses large efficiently encoded lexicons built from OpenCorpora and LanguageTool data. A set of linguistically motivated rules is developed to enable morphological analysis and generation of out-of-vocabulary words observed in real-world documents. For Russian pymorphy2 provides state-of-the-arts morphological analysis quality. The analyzer is implemented in Python programming language with optional C++ extensions. Emphasis is put on ease of use, documentation and extensibility. The package is distributed under a permissive open-source license, encouraging its use in both academic and commercial setting.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
- Morphological analyzer
- Russian
- Ukrainian
- Morphological generator
- Open source
- OpenCorpora
- LanguageTool
- pymorphy2
- pymorphy
1 Introduction
Morphological analysis is an analysis of internal structure of words. For languages with rich morphology like Russian or Ukrainian using the morphological analysis it is possible to figure out if a word can be a noun or a verb, or if it can be singular or plural. Morphological analysis is in an important step of natural language processing pipelines for such languages.
Morphological generation is a process of building a word given its grammatical representation; this includes lemmatization, inflection and finding word lexemes.
pymorphy2 is a morphological analyzer and generator for Russian and Ukrainian language widely used in industry and in academia. It is being developed since 2012; Ukrainian support is a recent addition. The development of its predecessor, pymorphyFootnote 1 started in 2009. The package is availableFootnote 2 under a permissive license (MIT), and it uses open source permissively licensed dictionary data.
The rest of this paper is organized as follows. In Sect. 2 pymorphy2 software architecture and design principles are described. Section 3 explains how pymorphy2 uses lexicons and how analysis and morphological generation work for vocabulary words. In Sect. 4 methods used for out-of-vocabulary words are explained and compared with approaches used by other morphological analyzers. Section 5 is dedicated to a problem of selecting correct analysis from all possible analyses, and a role of morphological analyzer in this task. In Sect. 6 evaluation results are presented. Section 7 outlines a roadmap for future pymorphy2 improvements.
2 Software Architecture
pymorphy2 is implemented as a cross-platform PythonFootnote 3 library, with a command-line utility and optional C++ extensions for faster analysis. Both Python 2.x and Python 3.x are supported. An extensive testing suite (600+ unit tests) ensures the code quality; test coverage is kept above 90%. There is online documentationFootnote 4 available.
When optional C++ extension is used (or when pymorphy2 is executed using PyPyFootnote 5 Python interpreter) the parsing speed is usually in tens of thousands of words per second; in some specific cases in can exceed 100000 words per second in a single thread. Without the extension parsing speed is in thousands of words per second. The memory consumption is about 15MB, or about 30MB if we account for Python interpreter itself.
Users are provided with a simple API for working with words, their analyses and grammatical tags. There are methods to analyze words, inflect and lemmatize them, build word lexemes, make words agree with a number, methods for working with tags, grammemes and dictionaries. Inherent complexity of working with natural languages is not hidden from the user. For example, to lemmatize the word correctly it is necessary to choose the correct analysis from a list of possible analyses; pymorphy2 provides P(analysis|word) estimates and sorts the results accordingly, but requires user to choose the analysis explicitly before normalizing the word.
Analysis of vocabulary words and out-of-vocabulary words is unified. There is a configurable pipeline of “analyzer units”; it contains a unit for vocabulary words analysis and units (rules) for out-of-vocabulary words handling. Individual units can be customized or turned off; some rules are parametrized with language-specific data. Users can create their own analyzer units (rules). This all makes it possible to perform morphological analysis experiments without changing pymorphy2 source code, develop domain-specific morphology analysis pipelines and adapt pymorphy2 to work with languages other than Russian. The latter point is validated by introducing an experimental support for Ukrainian language.
3 Analysis of Vocabulary Words
pymorphy2 relies on large lexicons for analysis of common words. For Russian it uses OpenCorpora [3] dictionary (\(\sim \!5*10^6\) word forms, \(\sim \!0.39*10^6\) lemmas) converted from OpenCorpora XMLFootnote 6 format to a compact representation optimized for morphological analysis and generation tasks. End users don’t have to compile the dictionaries themselves; pymorphy2 ships with prebuilt periodically updated dictionaries.
Any dictionary in OpenCorpora XML format can be used by pymorphy2. For Ukrainian there is such experimental dictionary (\(\sim \!2.5*10^6\) word forms) being developedFootnote 7 by Andriy Rysin, Dmitry Chaplinsky, Mariana Romanyshyn and other contributors; it is based on LanguageToolFootnote 8 data.
Source dictionary contains word forms with their tags, grouped by lexemes. For example, a lexeme for lemma  (a hedgehog) looks like this:
(a hedgehog) looks like this:

In source dictionaries there could also be links between lexemes. For example, lexemes for infinitive, verb, gerund and participle forms of the same lemma may be connected. Currently pymorphy2 joins connected lexemes into a single lexeme for most link types.
3.1 Morphological Analysis and Generation
Given a dictionary, to analyze a word means to find all possible grammatical tags for a word. Obtaining of a normal form (lemmatization) is finding the first word form in the lexeme. To inflect a word is to find another word form in the same lexeme with the requested grammemes.
As can be seen, all these tasks are simple. With an XML dictionary analysis of known words can be performed just by running queries on XML file.
The problem is that querying XML is O(N) with large constant factors, raw data takes quite a lot of memory, and the source dictionary is not well suited for morphological analysis and generation of out-of-vocabulary words.
To create a compact representation and enable fast access pymorphy2 encodes lexeme information: all words are stored in a DAFSA [5] using the dawgdicFootnote 9 C++ library [11] via Python wrapperFootnote 10; information about word tags and lexemes is encoded as numbers. Storage scheme is close to the scheme described in aot.ru [10], but it is not quite the same.
Paradigms. Paradigm in pymorphy2 is an inflection pattern of a lexeme. It consists of \(prefix_i, suffix_i, tag_i\) triples, one for each word form in a lexeme, such as that each word form i can be represented as \(prefix_i + stem + suffix_i\) where stem is the same for all words in a lexeme.
This representation allows us to factorize a lexeme into a stem and a paradigm.
Paradigm prefixes, suffixes and tags are encoded as numbers by pymorphy2; lexeme stems are discarded. It means that a paradigm is stored as an array of numbers (prefixes, suffixes and tags IDs), and lexemes are not stored explicitly - they are reconstructed on demand from word and paradigm information.
There are no paradigms provided in the source dictionary; pymorphy2 infers them from the lexemes. For Russian there are about 3200 paradigms inferred from 390000 lexemes.
Word Storage. Word forms with their analysis information are stored in a DAFSA. Other storage schemes were tried, including two tries scheme similar to described in [9] (but using double-array tries), and succinct (MARISAFootnote 11) tries. For pymorphy2 data DAFSA provided the most compact representation, and at the same time it was the fastest and had the most flexible iteration support.

DAFSA encoding example. Encoded (word, paradigmId, formIndex) triples: (
For each word form pymorphy2 stores (word, paradigmId, formIndex) triples:
-
word form, as text;
-
ID of its paradigm;
-
word form index in the lexeme.
DAFSA doesn’t support attaching values to leaves; the information is encoded like the following: \(<word>SEP<paradigmId> <formIndex>\) (see an example on Fig. 1)Footnote 12.
The storage is especially efficient because words with similar endings often have the same analyses, i.e. the same (paradigmId, formIndex) pairs; this allows DAFSA to use fewer nodes/transitions to represent the data. DAFSA for Russian OpenCorpora dictionary (\(5*10^6\) analyses, about \(3*10^6\) unique word forms) enables fast lookups (hundreds thousand lookups/sec from Python) and takes less than 7MB of RAM; source XML file is about 400MB on disk.
To get all analyses of a word, DAFSA transitions for word are followed, then a separator SEP is followed, and then the remaining subtree is traversed to get all possible (paradigmId, formIndex) pairs.
Given (paradigmId, formIndex) pair one can find the grammatical tag of a word: find a paradigm in paradigms array by paradigmId, get \((prefix_i, suffix_i, tag_i)\) triple from a paradigm by using \(i:=formIndex\). Given \((paradigmId, formIndex)\) pair and the word itself it is possible to restore the lexeme and lemmatize or inflect the word - from word, \(prefix_i\) and \(suffix_i\) we can get the stem, and given a stem and \((prefix_k, suffix_k, tag_k)\) it is possible to restore a full word for k-th word form.
3.2 Working with  and
and 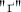 Characters Efficiently
Characters Efficiently
 and
and 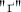 Characters Efficiently
Characters EfficientlyThe usage of  letter is optional in Russian; in real texts it is often replaced with
letter is optional in Russian; in real texts it is often replaced with  letter. There rules for
letter. There rules for  /
/  substitutions are different in Ukrainian, but in practice there are real-world texts with
substitutions are different in Ukrainian, but in practice there are real-world texts with  letters replaced with
letters replaced with  .
.
The simplest way to handle it is to replace  /
/  with
with  /
/  both in the input text and in the dictionary. However, this is suboptimal because it discards useful information, makes the text less correct (in Ukrainian
both in the input text and in the dictionary. However, this is suboptimal because it discards useful information, makes the text less correct (in Ukrainian  instead of
instead of  can be seen as a spelling error) and increases the ambiguity: there are words which analysis should depend on
can be seen as a spelling error) and increases the ambiguity: there are words which analysis should depend on  . For example, the word
. For example, the word  should be parsed as plural, but the word
should be parsed as plural, but the word  shouldn’t.
shouldn’t.
pymorphy2 assumes that  /
/  usage in dictionary is mandatory, but in the input text it is optional. For example, if a Russian input word contains
usage in dictionary is mandatory, but in the input text it is optional. For example, if a Russian input word contains  letter then only analyses with this letter are returned; if there are
letter then only analyses with this letter are returned; if there are  letters in the input word then possible analyses both for
letters in the input word then possible analyses both for  and
and  are returned.
are returned.
An easy way to implement this would be to check each combination of  and
and  replacement for the input word. It is not how pymorphy2 works. To do the task efficiently, pymorphy2 exploits DAFSA [5] dictionary structure: the result is built by traversing the word character graph and trying to follow
replacement for the input word. It is not how pymorphy2 works. To do the task efficiently, pymorphy2 exploits DAFSA [5] dictionary structure: the result is built by traversing the word character graph and trying to follow  transitions in addition to
transitions in addition to  transitions (for Russian) and
transitions (for Russian) and  transitions in addition to
transitions in addition to  transitions (for Ukrainian).
transitions (for Ukrainian).
4 Analysis of Out-of-Vocabulary Words
It is not practical to try incorporate all the words in a lexicon - there is a long tail of rarely used words, new words appear; there is morphological derivation, loanwords, it is challenging to add all names, locations and special terms to the dictionary. Empirically, Zipf’s Law seems to hold for natural languages [14]; one of the consequences is that even doubling the size of a lexicon could increase the coverage only slightly [6].
For languages without rich morphology it may be practical to assume that if word is not in a dictionary then it can be of any class from the open word classes, and then disambiguate the results on later processing stages, using e.g. a contextual POS tagger or a syntactic parser. For Slavic languages doing this on later stages is challenging because of large tagsets - for example, OpenCorpora [3] words have more than 4500 different tags. Morphological analyzer solves it by limiting the number of possible analyses based on word shape.
pymorphy2 uses a set of rules (analyzer units) to handle unknown words. Some of the rules are described in literature [4, 6, 8–10]; the resulting combination is novel. The order of in which the rules are applied is language-specific.
4.1 Common Prefixes Removal
There is a set of immutable prefixes which can be attached to words of open classes (nouns, verbs, adjectives, adverbs, participles, gerunds) without affecting the word grammatical properties. Examples of such prefixes for Russian:  ,
,  ,
,  ; pymorphy2 provides language-specific lists of these prefixes.
; pymorphy2 provides language-specific lists of these prefixes.
When a words starts with one of these prefixes, pymorphy2 removes the prefix, parses the reminder and re-attaches the prefix. A similar rule is described in [8]. Note that full analysis is performed on the reminder, so the reminder can be an out-of-vocabulary word itself. To speedup prefix matching built-in lists of prefixes are encoded to DAFSAs.
4.2 Words Ending with Other Dictionary Words
When all the following apply pymorphy2 assumes the whole word can be parsed the same way as the “suffix” word:
-
a word being analyzed has another word from a dictionary as a suffix;
-
the length of this “suffix” word is no less than 3;
-
the length of the word without the “suffix” is no greater than 5;
-
“suffix” word is of an open class (noun, verb, adjective, participle, gerund)
To search for suffixes pymorphy2 tries to consider 1st letter as a prefix, then two first letters as a prefix, etc., and lookups the reminder in a dictionary.
This rule is the same as described in [10]. A similar rule is described in [8], though its induction for concrete prefixes is different.
4.3 Endings Matching
In many languages, including Russian and Ukrainian, words with common endings often have the same grammatical form.
To exploit this, pymorphy2 first collects the information from the dictionary: for each word all endings of length 1 to 5 are extracted, and all possible analyses for these endings are stored. Then this \(ending \rightarrow \{analyses\}\) mapping is cleaned up:
-
only the most frequent analyses for each POS tag are kept;
-
analyses from non-productive paradigms (currently these are paradigms which produced less than 3 lexemes in a dictionary) are discarded;
-
rare endings (currently the ones which occur once) are also discarded.
The resulting mapping is encoded to DAFSA for fast lookups. Storage scheme is the following: \(<ending>SEP<analysisInfo>\), where analysisInfo consists of three 2-byte numbers: (frequency, paradigmId, formIndex) - analysis frequency (a number of times a word with this ending had this analysis), ID of analysis paradigm and the form index inside the paradigm.
At prediction time pymorphy2 checks word endings from length 5 to 1, stopping at the first ending with some analyses found. To get possible analyses for a given ending pymorphy2 first follows all DAFSA transitions for the ending, then follows a separator, and then traverses the remaining subtree to get possible analysisInfo triples. The result is then sorted by analyses frequencies.
Recall that a word and a (paradigmId, formIndex) pair is all what is needed to restore the lexeme and inflect the word. Lexemes are created on fly, so it doesn’t matter word is not from the vocabulary as soon as we have (paradigmId, formIndex) pair. It means morphological generation (lemmatization, inflection) works here.
Only analyses with open-class parts of speech (noun, verb, adjective, participle, gerund) are produced. Special care is taken to handle  letter properly. Also, special care is required to handle paradigm prefixes properly - in fact, there are several \(ending \rightarrow \{analyses\}\) DAFSAs built, one per each paradigm prefix.
letter properly. Also, special care is required to handle paradigm prefixes properly - in fact, there are several \(ending \rightarrow \{analyses\}\) DAFSAs built, one per each paradigm prefix.
This rule is based on [10]; similar approaches are also used in [4, 9]. [8] uses similar rules, but derives them differently.
4.4 Words with a Hyphen
Unlike some other morphological analyzers, pymorphy2 opts to handle words with a hyphen.
In [7] it is argued that in most cases the parts of compound words should be handled as separate words if they are joined using a hyphen. A similar decision is made in OpenCorpora tokenization module [2]; it considers words like  as three tokens which should be analyzed separately and joined back at later processing stages. In both cases the decisions are not motivated by linguistic considerations; it is the technical difficulty which prevents analyzing and processing such words as single entities.
as three tokens which should be analyzed separately and joined back at later processing stages. In both cases the decisions are not motivated by linguistic considerations; it is the technical difficulty which prevents analyzing and processing such words as single entities.
Currently pymorphy2 handles adverbs with a hyphen, particles separated by a hyphen and compound words with left and right parts separated by a hyphen.
Adverbs with a Hyphen. Russian words are parsed as adverbs if they
-
start with a
 prefix;
prefix; -
have total length greater than 5;
-
can be parsed as a full singular adjective in dative case when
 is removed
is removed
 prefix;
prefix; is removed
is removedExamples:  ,
,  .
.
Particles Separated by a Hyphen. Though it is not clear if words with a particle separated by a hyphen (e.g.  or
or  ) should be handled as a single word or as two words, pymorphy2 supports parsing of such words. There are language-specific lists of common particles which can be attached, and if a word ends with one of these particles then it is parsed without the particle, and then the particle is re-attached to the result.
) should be handled as a single word or as two words, pymorphy2 supports parsing of such words. There are language-specific lists of common particles which can be attached, and if a word ends with one of these particles then it is parsed without the particle, and then the particle is re-attached to the result.
4.4.1 Compound Words with a Hyphen
The main challenge in analysis of the compound words which parts are separated by a hyphen (like  and
and  ) is to figure out if the left part should be inflected together with the right part, or if it is a fixed prefix.
) is to figure out if the left part should be inflected together with the right part, or if it is a fixed prefix.
To do this, pymorphy2 parses left and right parts separately (they don’t have to be dictionary words). Then it tries to find matching analyses. If there is a “left” analysis compatible with one of the “right” analyses then the resulting analysis is built where both word parts are inflected. After that, an analysis with a fixed left part is added to the result, regardless of whether a compatible “left” analysis was found or not. A similar method was used in [4].
Only words with a single hyphen are handled using heuristics described above. Words with multiple hyphens are likely represent different phenomena in Russian and Ukrainian languages; they could be interjections or phrases [13].
4.5 Other Tokens
Initial is an abbreviation of person’s first or patronymic name. In most cases an initial is a single upper-cased character (language-specific). pymorphy2 parses such characters as fixed singular nouns, with variants for all possible gender and case combinations. For person first names (Name) two different lexemes are built for male and female names. For patronymic names (Patr) a single lexeme is returned. Unlike all other analyzer rules, detection of initials is case-sensitive. It is a way to decrease ambiguity.
The following tags are assigned to non-lexical tokens: PNCT for punctuation, LATN for tokens written in Latin alphabet, NUMB, intg for integer numbers, NUMB, real for floating-point numbers, ROMN for Roman numbers.
When analyzing the text, it is common to classify tokens during the tokenization step. The reason pymorphy2 handles non-lexical tokens during the morphological analysis step is that this allows users to use a simpler tokenizer when classifying tokenizer is not available; also, it means that information about all tokens is available in a common format.
4.6 Morphological Generation of Out of Vocabulary Words
Inflection is fully supported for out of vocabulary words. To achieve this pymorphy2 keeps track of the analyzer units (rules and their parameters) used to parse the word, requires each analyzer unit to provide a method for getting a lexeme, and calls this method for the last analyzer unit. To compute the lexeme analyzer unit can look at the analysis result, and it can ask previous analyzer units for the lexeme.
For example, Common Prefixes Removal analyzer removes the prefix from a word, then gets a lexeme from the previous analyzer, and then attaches the prefix to each word form in a lexeme to build a resulting lexeme.
5 Probability Estimation
Morphological analyzer may return multiple possible word parses. The problem of choosing the right analysis from a list of possible options is called disambiguation. Generally, to select the correct analysis it is required to take word context in account. Morphological analyzer takes individual words as an input, so it can’t disambiguate the result robustly. However, it can provide an estimation for P(analysis | word) conditional probability. Such probability estimations can be used in absence of a dedicated disambiguator to select the more probable analysis. In addition to that, these probabilities can be used on later stages of text analysis, for example by a disambiguator.
To estimate P(analysis | word) conditional probability for Russian words pymorphy2 uses partially disambiguated OpenCorpora corpus [3] and assumes that \(P(analysis | word) = P(tag | word)\). The conditional probability is estimated for words which have multiple analysis according to pymorphy2, but have occurrences with a single remaining analysis in the OpenCorpora corpus; the estimation is a maximum-likelihood estimation with Laplace (add-one) smoothing.
Counts are computed based on OpenCorpora corpus data; all words with a single remaining analysis are taken in account.
Once estimated, the result is stored on disk as a DAFSA; keys are
For words without \(P_{MLE}(tag | word)\) estimates the probabilities are assigned uniformly during the parsing.
For Ukrainian language probabilities are assigned uniformly because at the moment of writing there is no a freely available Ukrainian corpus similar to OpenCorpora.
6 Evaluation
Evaluating analysis quality of different morphological analyzers for Russian is not straightforward because most analyzers (as well as annotated corpora) use their own incompatible tagsets. And when a corpus and a dictionary have a compatible tagset it usually means that the dictionary was enhanced from the corpus, and it is a problem because quality numbers obtained on a corpus the dictionary was enhanced from shouldn’t be relied on - they are too optimistic.
pymorphy2 analysis quality was compared to an analysis quality of a well-known morphological analyzerFootnote 13, Mystem 3.0 [9]. Testing corpus consists of 100 randomly selected sentences (1405 tokens) from OpenCorpora (microcorpusFootnote 14) and 100 randomly selected sentences (1093 tokens) from ruscorpora.ru - 2498 manually disambiguated tokens in total.
Full details for this evaluation can be found onlineFootnote 15.
OpenCorpora (pymorphy2) tagset is not the same as ruscorpora.ru tagset, and ruscorpora.ru tagset differs from Mystem tagset. For evaluation purposes all tags were converted to Mystem format using a set of automatic rules. Quality was evaluated on full morphological tags, i.e. tags must match exactly to be considered correct, with a few exceptions related to tags conversion problems. All reported errors were checked manually to filter out false positives (Table 1).
Both pymorphy2 and Mystem made less than 1% errors (without disambiguation, i.e. in less than 1% cases the correct analysis was not in a set of analyses returned by an analyzer). It should be noted that 9 out of 19 pymorphy2 errors and 14 out of 23 Mystem errors were related to abbreviation handling. Mystem handled first and last names better (1 mistake versus 4 for pymorphy2); pymorphy2 made less mistakes for “regular” words (4 versus 6 for mystem). Mystem can’t parse many hyphenated words as a single token; such words were not considered. Punctuation, numbers and non-Russian words were also removed from the input.
It is hard to draw a quantitative conclusion because the corpus size is small. Both analyzers has a similar analysis quality, and the resulting numbers depend on evaluation minutiae: whether abbreviations are considered or not, should we require hyphenated words to be parsed, do we require verb transitivity to be predicted correctly, is it important to distinguish adverbs from parenthesis, etc.
Several human annotation errors were found by parsing OpenCorpora data with mystem (1 error) and ruscorpora data with pymorphy2 (6 errors). OpenCorpora shares a dictionary with pymorphy2, and ruscorpora annotation is related to mystem; this shows an utility of using cross-corpora tools to check the annotations.
The most sophisticated Russian morphological parser evaluation so far is [1]; it happened in 2010. Previous version of pymorphy2 (pymorphy) participatedFootnote 16 in tracks without disambiguation; it finished 1st on Full Morphology Analysis, 3rd on Lemmatization, 3rd on POS tagging and 5th on the Rare Words track. pymorphy haven’t participated in disambiguation tracks.
pymorphy used some pymorphy2 rules (not all) and a different dictionary (extracted from [10] instead of [3]). Generally, pymorphy2 should work better than pymorphy because of an improved dictionary and rules, but this has not been not measured quantitatively yet.
7 Conclusion and Future Plans
Permissive open-source license (MIT) is used for pymorphy2. All the dictionaries and corpora pymorphy2 depends on are also available under permissive open-source licenses. This encourages usage and contributions. There are volunteers working on Russian and Ukrainian dictionaries and corpora, related tools and pymorphy2 itself.
Development of pymorphy2 is by no means finished. There are word classes for which pymorphy2 analysis can be improved. Some of them: people last and patronymic names, foreign people names, diminutive first names, locations, uppercase and other abbreviations, some classes of hyphenated words, ordinal numbers (including ordinal numbers written in digit notation like  ). According to [1], similar issues are common for Russian morphological analyzers.
). According to [1], similar issues are common for Russian morphological analyzers.
Non-contextual P(tag | word) estimates can be made better by transferring some information about similar words and by improving the corpora.
A better comparison between pymorphy, pymorphy2, Mystem and other morphological analyzers could require a robust tagset conversion library.
The support for Ukrainian is experimental. The dictionary requires work, pymorphy2 needs more Ukrainian-specific rules for handling of out of vocabulary words, and for better P(tag | word) estimates an annotated Ukrainian corpus is needed: even a small corpus (or even a manually crafted frequency list) should fix a substantial amount of “obvious” errors.
There are plans to add Belarusian language support to pymorphy2 based on Belarusian N-korpusFootnote 17 grammar database.
Although pymorphy2 is already fast enough for many use cases (tens of thousands words per second in a single thread), there is a room for further speed improvements.
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
Conversion utilities: https://github.com/dchaplinsky/LT2OpenCorpora.
- 8.
- 9.
- 10.
- 11.
- 12.
pymorphy2 encodes words to UTF-8 before putting them to DAFSA, so in practice there are more nodes than shown on Fig. 1. It is an implementation detail.
- 13.
- 14.
- 15.
- 16.
Anonymized results: http://ru-eval.ru/tables_index.html.
- 17.
References
Astaf’eva, I., Bonch-Osmolovskaya, A., Garejshina, A., Ju, G., D’jachkov, V., Ionov, M., Koroleva, A., Kudrinsky, M., Lityagina, A., Luchina, E., Sidorova, E., Toldova, S., Lyashevskaya, O., Savchuk, S., Koval’, S.: NLP evaluation: Russian morphological parsers. In: Kibrik, A. (ed.) Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference “Dialouge”, vol. 1 (2010)
Bocharov, V.V., Granovsky, D.V., Surikov, A.V.: Probabilistic Tokenization model in the OpenCorpora project [Veroyatnastnaya model’ tokenizacii v proekte Otkritiy Korpus]. In: New Information Technology in Automated Systems: Proceedings of the 15th Seminar [Noviye informacionnie tehnologii v avtomatizirovannih sistemah: materiali pyatnadcatogo nauchno-prakticheskogo seminara] (2012)
Bocharov, V.V., Alexeeva, S.V., Granovsky, D.V., Protopopova, E.V., Stepanova, M.E., Surikov, A.V.: Crowdsourcing morphological annotation. In: Selegey, V. (ed.) Computational Linguistics and Intellectual Technologies. Papers from the Annual International Conference “Dialogue”, vol. 1 (2013)
Bolshakov, I.A., Bolshakova, E.I.: An automatic morphological classifier of noun phrases in Russian. In: Kibrik, A. (ed.) Computational Linguistics and Intellectual Technologies. Papers from the Annual International Conference “Dialogue”, vol. 1 (2012)
Daciuk, J., Watson, B.W., Mihov, S., Watson, R.E.: Incremental construction of minimal acyclic finite-state automata. Comput. Linguist. 26(1), 3–16 (2000)
Daciuk, J.: Treatment of unknown words. In: Boldt, O., Jürgensen, H. (eds.) WIA 1999. LNCS, vol. 2214, p. 71. Springer, Heidelberg (2001)
Krylov, S.A., Starostin, S.A.: Current morphological analysis and synthesis challanges in the STARLING system [Aktualniye zadachi morfologicheskogo analiza i sinteza v integrirovannoy informacionnoy srede STARLING]. In: Proceedings of the International Conference “Dialog 2003” (2003)
Mikheev, A.: Automatic rule induction for unknown word guessing. Comput. Linguist. 23(3), 405–423 (1997)
Segalovich, I.: A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine. In: Proceedings of MLMTA 2003, Las Vegas (2003)
Sokirko, A.: Morphological modules on the web-site www.aot.ru [Morphologicheskie Moduli na saite www.aot.ru]. In: Computational Linguistics and Intelligent Technologies: Proceedings of the International Conference “Dialog 2004” (2004)
Yata, S., Morita, K., Fuketa, M., Aoe, J.: Fast string matching with space-efficient word graphs. In: Innovations in Information Technology (Innovations 2008), Al Ain, United Arab Emirates, pp. 79–83, December 2008
Zaliznjak, A.A.: Grammaticeskij slovar’ russkogo jazyka, Moscow, Russia (1977)
Zanegina, N.N.: Improvised-temporary-compounds as a new expressive mean in Russian. In: Kibrik, A. (ed.) Computational Linguistics and Intellectual Technologies. Papers from the Annual International Conference “Dialogue”, vol. 1 (2012)
Zipf, G.K.: Selected Studies of the Principle of Relative Frequency in Language. Harvard University Press, Cambridge (1932)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Korobov, M. (2015). Morphological Analyzer and Generator for Russian and Ukrainian Languages. In: Khachay, M., Konstantinova, N., Panchenko, A., Ignatov, D., Labunets, V. (eds) Analysis of Images, Social Networks and Texts. AIST 2015. Communications in Computer and Information Science, vol 542. Springer, Cham. https://doi.org/10.1007/978-3-319-26123-2_31
Download citation
DOI: https://doi.org/10.1007/978-3-319-26123-2_31
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-26122-5
Online ISBN: 978-3-319-26123-2
eBook Packages: Computer ScienceComputer Science (R0)