
Abstract
Context modelling is one of the stages conducted during the context life cycle. It has the aim of giving meaning and structure to the collected context’s raw data. Although there are different context models proposed in the literature, we have identified some gaps that are not fully covered, particularly related to the reusability of the models themselves and the lack of consolidated and standardized ontological resources. To tackle this problem, we adopt a three-layered context ontology perspective and we focus on this paper in the middle layer, which is defined following a prescriptive process and structured in a modular way for supporting reuse.
This work is partially supported by the Spanish project TIN2013-44641-P.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Context is a term widely used in many areas of conceptual modelling. Dey defines it as “any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between a user and an application” [1]. From this perspective, context modelling is the research topic in which the notion of context has been structured in different formalisms to represent context information, which affects positively or negatively an entity. One of its major applications is concentrated on context-aware infrastructures, i.e. areas such as Smart Cities, Pervasive Computing and Internet of Things [2].
In a previous work, we analyzed the state of the art on context modelling [3] identifying certain gaps that have motivated this work. One of the most important issues is the difficulty of reusing the context models proposed in the literature mainly due to the lack of homogeneity among their elements, as well as the shortage of their definitions. This problem calls for efforts to consolidate the context knowledge already available and to specify a clear schema of knowledge reutilization.
To contribute solving these issues, in this paper we adopt a three-level ontology approach for context modelling:
-
The upper-level provides a basic taxonomy of context classes that represent general context concepts. We have presented this upper level in a previous work [3].
-
The middle-level supports reusing and extending ontological resources of existing context models and other consolidated ontologies from a modular perspective.
-
The lower-level includes a set of detailed classes highly dependent on the domain.
The focus of this paper will be the middle-level. We propose reusing a set of ontological resources that represent structured modules selected using different strategies.
The rest of the paper is organized as follows. Sections 2 and 3 present the background and antecedents of our work. Section 4 describes in depth the proposed model focused on the middle-level ontology. Finally, Sect. 5 presents the conclusions.
2 Background
2.1 Context Modelling Approaches
Recently, Perera et al. [2] presented a comparison of the six most popular context modelling techniques and concluded that the most appropriate technique to manage context is ontology-based modelling. According to Sudhana et al. [4], Noy [5] and Chen et al. [6], ontologies are a key feature in the making of context-aware distributed systems because they support knowledge sharing, reasoning and interoperability. For all these reasons, we are adopting ontology-based modelling in our work.
2.2 Classification of Ontologies
Different designs and structures of ontologies have been proposed so far. Two usual criteria are: generality and expressiveness. Generality has the purpose of specifying general classes towards top levels and more specific classes towards lower levels [7]. This criterion supports the adoption of a layered view of ontologies [8, 9]. Expressiveness indicates the level of detail of an ontology. Usually they are classified into lightweight and heavyweight [10]. In this paper we adopt a 3-level view of abstraction with an expressivity closer to heavyweight ontologies since we want to express axioms and constraints more than only concepts, taxonomies and relationships.
2.3 Reuse in Methodologies for Developing Ontologies
A large number of methodologies have been proposed to conduct the ontology building process (e.g., [11, 12]). Generally, these methodologies specify an activity based on the reuse of existing knowledge. According to Pinto et al. [13] there are two different reuse processes: merge and integration. In a merge process, it is usually difficult to identify regions in the resulting ontology that were taken from the merged ontologies and that were left more or less unchanged. In an integration process source ontologies are aggregated, combined and assembled together, possibly after reused ontologies have suffered some changes, such as extension, specialization or adaptation. We propose integration because we are more interested on unifying modules than complete ontologies. We will apply the integration process defined by Pinto and Martins [14] since they have compiled integration activities from different methodologies.
3 Antecedents
In a previous paper [3] we included a preliminary state of the art in context. This study: (1) compiled different gaps reported by researchers in the context modelling area; (2) identified gaps through the analysis and evaluation conducted in the contributions; and (3) established a basic taxonomy of high level classes intended to serve as basis of the abstract level of a context model consolidating all these proposals. The consolidated resources encompass all the perspectives already provided in context modeling, especially, resources regarding context information vocabulary, properties and terminology definitions.
As next step, we deepened this state of art by conducting a systematic mapping study according to the guidelines proposed by Kitchenham and Charters [15].
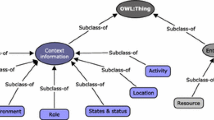
The results obtained from the review were used to evolve the taxonomy presented in [3] as depicted in Fig. 1. To populate the schema presented in the figure we considered different aspects from the surveyed models such as the most addressed classes in the surveyed proposals, definitions provided clustering those that represent a generic description of the class, common patterns identified through the proposed schemas, and alignment with foundational ontologies that were partially reused by the contributions. Hence, we adopt this taxonomy as the upper-level ontology that frames the middle-level that we are proposing in this paper.

Upper-level ontology.
4 Middle-Level Ontology for Context Modelling
The main objective of a middle-level ontology is to provide a set of modules easy to reuse and extend. In addition, we aim at building a proposal aligned with existing context ontologies, reusing the ontological resources presented in Fig. 1. To this purpose, we adopt the integration process defined by Pinto and Martins [14] which defines several tasks that are applied below. For the sake of brevity, we will present some of the tasks together.
Identify Integration Possibility.
In this first step, Pinto and Martins propose to select the framework being used to build the ontology. Following the criteria provided by Su and Ilebrekke [17], we have selected Protégé as ontology development tool. Particularly, we are interested on importing specific modules from existing ontologies in an easy way providing a clear schema of reutilization, and connection with the upper level classes. Moreover, in cases where the ontologies selected are provided in a different framework, we will translate the selected modules into the semantic of Protégé. The selection of this tool is greatly influencing the proposal given. This is unavoidable because we want an ontology that can be used in an engineering context in order to provide tangible value in the development of contextual software and services.
Identify Modules and Knowledge to be Represented in Each of Them.
As starting point, we associate a module to each of the leaves of the class hierarchy established in the upper-level ontology (see Fig. 1). We have consolidated the knowledge coming from the selected ontologies and as a result, these classes are defined as follows:
-
Time. Temporal concepts and properties common to any formalization of time [6].
-
Profile. Biographical sketch [18].
-
States and Status. A state at a particular time (e.g., a condition or state of disrepair, the current status of the arms negotiations) [18].
-
Environment. Environment in which the user interacts [19].
-
Role. Role of an agent can be used to characterize the intention of the agent [20].
-
Location. By location context, we mean a collection of dynamic knowledge that describes the location of an agent [20].
-
Activity. Represents a set of actions [6].
-
Resource. Resources describe anything used to perform the activity [21].
-
Agent. Both computational entities and human users can be modeled as agents [6].
Identify and Get Candidate Ontologies.
According to [14], this task first identifies candidate ontologies that could be used as modules of our middle-level ontology. We did this through the mapping study reported in Sect. 3. Next, we selected 64 of the context models as possible candidates to be integrated in the modules of the middle-level ontologyFootnote 1.
To obtain the candidate ontologies in an adequate form, we analyzed their knowledge and implementation levels as well as the documentation available. We realized serious problems in the detailed expression of the knowledge and the coverage of the implementation. Still, for each model we aimed at identifying and retrieving the ontological resources that we considered relevant to create or complement modules of the middle-level. It is worth to mention that we considered not only the 64 context ontologies but also other 12 ontologies that they reused. We decided to establish a common base of candidate ontologies acting as reference point to structure the modules required. To carry out this task, from these ontologies, we selected those ones more referenced by existing proposals of context modelling: CONON [9], SOUPA [6], SUMO [8], OpenCyc [22], FOAF (xmlns.com/foaf/spec), CCPP (www.w3.org/TR/CCPP-struct-vocab2/), OWL-Time (www.w3.org/TR/owl-time) and OWL-S (www.w3.org/Submission/OWL-S).
Study and Analysis of Candidate Ontologies.
In this task the candidate ontologies are analyzed to identify possible problems in the integration process. We applied the SEQUAL evaluation framework formulated by Hella and Krogstie [23]. There are 7 quality categories used to evaluate the reusability of the ontologies. For each category, they propose some values that we have mostly kept:
-
Physical (Phy). The ontology should be physically available and it should be possible to make changes to it. Available (✓); available, presenting some problems to open in Protégé (✓-); available, but too big to open (✓–); not available (X).
-
Empirical (Emp). If a visual representation of the ontology is provided it should be intuitively and easy to understand. Satisfactory (✓); less satisfactory (✓-).
-
Syntactic (Syn). The ontology should be represented according to the syntax of a preferred machine readable language. OWL full (✓); partial OWL (✓-); RDF (✓–).
-
Semantic (Sem). The ontology should cover the area of interest. Overlap, satisfactory validity (✓✓); partial overlap but not complete, satisfactory validity (-✓); partial overlap but not complete, poor validity (–); not overlapping (X). Since this category is too coarse to be applied globally, Table 2 shows its evaluation for the modules identified in the middle-level ontology.
-
Pragmatic (Prag). It should be possible to understand what the ontology contains, and being able to use it for our purpose. Satisfactory (✓); not satisfactory (X).
-
Social (Soc). The ontology should have a relatively large group of users. Mature and widely used (✓✓); assumed mature, not specified how much it is used (–); not mature, but referenced (-✓).
-
Organizational (Org). The ontology should be freely available, accessible, maintained and supported. Free, accessible, and stable (✓✓✓); free, accessible, and probably stable (✓✓-); free, not accessible, and probably stable (✓x-).
Hella and Krogstie already provided in [23] the evaluation of some of the candidate ontologies selected in the previous task, concretely FOAF, OpenCyc and SUMO. We reused this evaluation reviewing the current status of the ontologies in order to check that the results obtained remain consistent; the only change has already been reported above (currently SUMO can be opened in Protégé). The rest of ontologies were evaluated from scratch. The results obtained are depicted in Table 1.
Choosing Source Ontologies.
Given the study and analysis of candidate ontologies the final choices must be made in this task. Pinto and Martins propose two stages. In a first stage, a critical look to the characteristics analyzed in the previous task is madeFootnote 2.
Although the schema presented by SOUPA and CONON for modelling context is widely referenced in the academic research, they present major drawbacks on the availability, completeness and maintenance of the resources provided. Still, the design of the model presented here is partially inspired by the modular schema of SOUPA and the intuitive visual representation of CONON.
For the rest of the ontologies, all of them are physically available. However, SUMO and OpenCyc are big ontologies difficult to import into ontology editors. SUMO, FOAF and CCPP provide a visual representation of their schema that is easy to understand. In the semantic and pragmatic qualities, SUMO and OpenCyc are upper ontologies providing an extensive vocabulary; although it can be used for purposes of context modelling, a large set of this vocabulary is irrelevant for this purpose. The rest of the foundational ontologies are more concrete and provide a smaller set of vocabulary partially covering the context of an entity.
On the basis of this assessment, the final decision is made in a second stage. Our aim is to select the parts of each candidate ontology that cover satisfactorily a module identified from the upper-level ontology; also, we consider the overall ontology evaluation to decide whether to include it in the result or not. Table 2 provides details on the analysis that support our choice of middle-level ontology, presented in Fig. 2. As it can be seen, in the middle-level of the model we propose different modules associated to the corresponding high level classes of the upper-level ontology. These modules are selected from the candidate ontologies by means of the following considerations: (1) integrate modules fulfilling the conceptualization of a given entity or context information; (2) otherwise, a new module combining ontological resources from different sources is proposed.
Several situations have been found when selecting. For instance, the Object module is selected from SUMO since it provides the overlap required to conceptualize this module. However, this ontology does not provide at all the required resources to conceptualize a computational entity, so we complement it with resources from CONON.

The middle-level ontology and its relationships with the upper and lower levels.
Apply Integration Operations.
Once the candidate ontologies have been filtered, the final task is to perform the integration. For the sake of space we cannot provide the full process. We just illustrate it one example. The upper-level class Time can be structured by using the semantics of SUMO, SOUPA or OWL-Time as it is depicted in the semantic evaluation of Table 2. However, according to the evaluation of Table 1 it is difficult to identify certain resources from SUMO. Then, we take as a basis the semantics of time given by OWL-Time because it is particularly focused on modelling time and for other features also evaluated in Table 1. Then, we adopted the following integration operations: (1) we integrated in a module the OWL-Time as it is and then we make some modifications in the structure and vocabulary taking into account the next operation; (2) we identified the equivalent resources among the vocabulary and patterns presented in ontologies assessed where time was also modelled in order to consolidate, standardize and minimize semantic inconsistencies.
5 Conclusions
In this paper we presented a middle-level ontology with the purpose of consolidating the context knowledge already available from a modular perspective yielding a clear schema of knowledge reutilization. The main contribution has been the effort of analyzing, selecting and combining many useful vocabularies from different existing proposals. To do so, we gathered parts of different ontologies to be integrated into modules. From this perspective, we face the gaps of a generic context model allowing the instantiation of existing context knowledge in a unique and simple model easy to be extensible in the establishment of new knowledge. The implemented resources are available at: https://github.com/ocabgit/Three-LevelContextOntology.git.
Notes
- 1.
For the sake of brevity we do not specify the 64 references of the ontologies selected and other resources of the mapping study that were used in this work; you may find them at [16].
- 2.
Unlike Pinto and Martins, we base the selection on the analysis previously made.
References
Dey, A.: Understanding and using Context. Pers. Ubiquit. Comput. 5(1), 4–7 (2001)
Perera, C., Zaslavsky, A., Christen, P., Georgakopoulos, D.: Context aware computing for the internet of things: a survey. IEEE Commun. Surv. Tutorials 16(1), 414–454 (2014)
Cabrera, O., Franch, X., Marco, J.: A context ontology for service provisioning and consumption. In: IEEE RCIS (2014)
Sudhana, K.M., Raj, V.C., Suresh, R.M.: An ontology-based framework for context-aware adaptive e-learning system. In: IEEE ICCCI (2013)
Noy, N.F.: Semantic integration: a survey of ontology-based approaches. ACM SIGMOD Rec. 33(4), 65–70 (2004)
Chen, H., Perich, F., Finin, T., Joshi, A.: SOUPA: standard ontology for ubiquitous and pervasive applications. In: IEEE MOBIQUITOUS (2004)
Guarino, N.: Formal ontology and information systems. In: FOIS (1998)
Niles, I., Pease, A.: Towards a Standard Upper Ontology. In: FOIS (2001)
Wang, X.H., Zhang, D.Q., Gu, T., Pung, H.K.: Ontology based context modeling and reasoning using OWL. In: IEEE PERCOMW (2004)
Corcho, O., Fernández-López, M., Gómez-Pérez, A.: Methodologies, tools and languages for building ontologies. Where is their meeting point? Data Knowl. Eng. 46(1), 41–64 (2003)
Fernández-López, M., Gómez-Pérez, A., Juristo, N.: METHONTOLOGY: from ontological art towards ontological engineering. In: AAAI 1997 Spring Symposium Series (1997)
Uschold, M., King, M.: Towards a methodology for building ontologies. In: IJCAI 1995 Workshop on Basic Ontological Issues in Knowledge Sharing (1995)
Pinto, H.S., Gómez-Pérez, A., Martins, J.P.: Some issues on ontology integration. In: IJCAI 1999 Workshop on Ontologies and Problem Solving Methods (1999)
Pinto, H.S., Martins, J.P.: A Methodology for Ontology Integration. In: K-CAP (2001)
Kitchenham, B., Charters, S.: Guidelines for Performing Systematic Literature Reviews in Software Engineering, version 2.3. EBSE Technical Report. EBSE-2007-01 (2007)
Cabrera, O., Franch, X., Marco, J.: Appendix of: a Middle-Level Ontology for Context Modelling. http://gessi.lsi.upc.edu/threelevelcontextmodelling/ (2015)
Su, Xiaomeng, Ilebrekke, Lars: A comparative study of ontology languages and tools. In: Pidduck, A.B., Mylopoulos, J., Woo, C.C., Ozsu, M.T. (eds.) CAiSE 2002. LNCS, vol. 2348, p. 761. Springer, Heidelberg (2002)
Miller, G.A.: WordNet: a lexical database for English. Commun. the ACM 38(11), 39–41 (1995)
Preuveneers, D., Van den Bergh, J., Wagelaar, D., Georges, A., Rigole, P., Clerckx, T., Berbers, Y., Coninx, K., Jonckers, V., De Bosschere, K.: Towards an extensible context ontology for ambient intelligence. In: Markopoulos, P., Eggen, B., Aarts, E., Crowley, J.L. (eds.) EUSAI 2004. LNCS, vol. 3295, pp. 148–159. Springer, Heidelberg (2004)
Chen, H., Finin, T., Joshi, A.: An ontology for context-aware pervasive computing environments. Knowl. Eng. Rev. 18(3), 197–207 (2003)
Prekop, P., Burnett, M.: Activities, context and ubiquitous computing. Comput. Commun. 26(11), 1168–1176 (2003)
Curtis, J., Baxter, D., Cabral, J.: On the application of the Cyc ontology to word sense disambiguation. In: FLAIRS (2006)
Hella, L., Krogstie, J.: A structured evaluation to assess the reusability of models of user profiles. In: Bider, I., Halpin, T., Krogstie, J., Nurcan, S., Proper, E., Schmidt, R., Ukor, R. (eds.) BPMDS 2010 and EMMSAD 2010. LNBIP, vol. 50, pp. 220–233. Springer, Heidelberg (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Cabrera, O., Franch, X., Marco, J. (2015). A Middle-Level Ontology for Context Modelling. In: Johannesson, P., Lee, M., Liddle, S., Opdahl, A., Pastor López, Ó. (eds) Conceptual Modeling. ER 2015. Lecture Notes in Computer Science(), vol 9381. Springer, Cham. https://doi.org/10.1007/978-3-319-25264-3_11
Download citation
DOI: https://doi.org/10.1007/978-3-319-25264-3_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-25263-6
Online ISBN: 978-3-319-25264-3
eBook Packages: Computer ScienceComputer Science (R0)